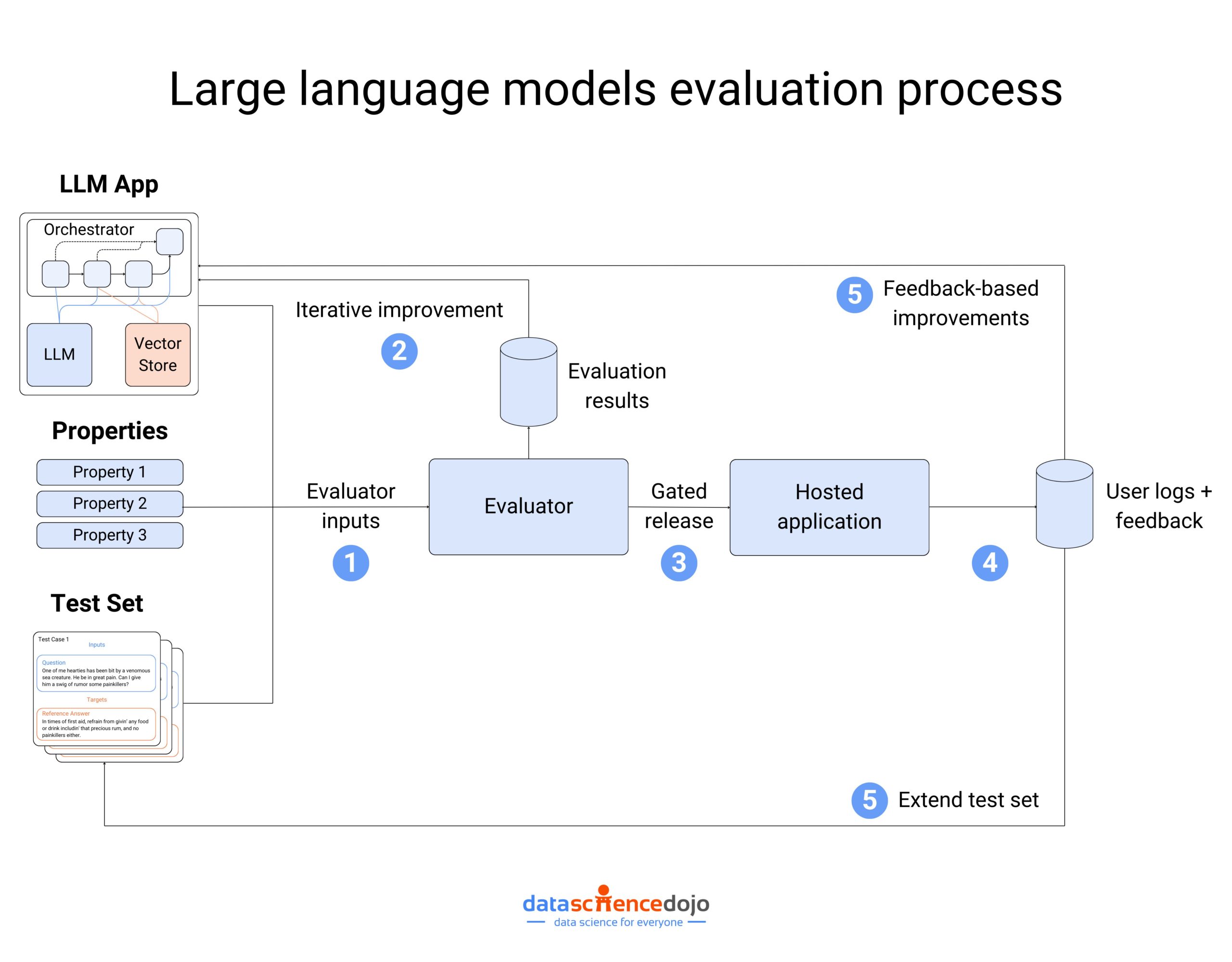
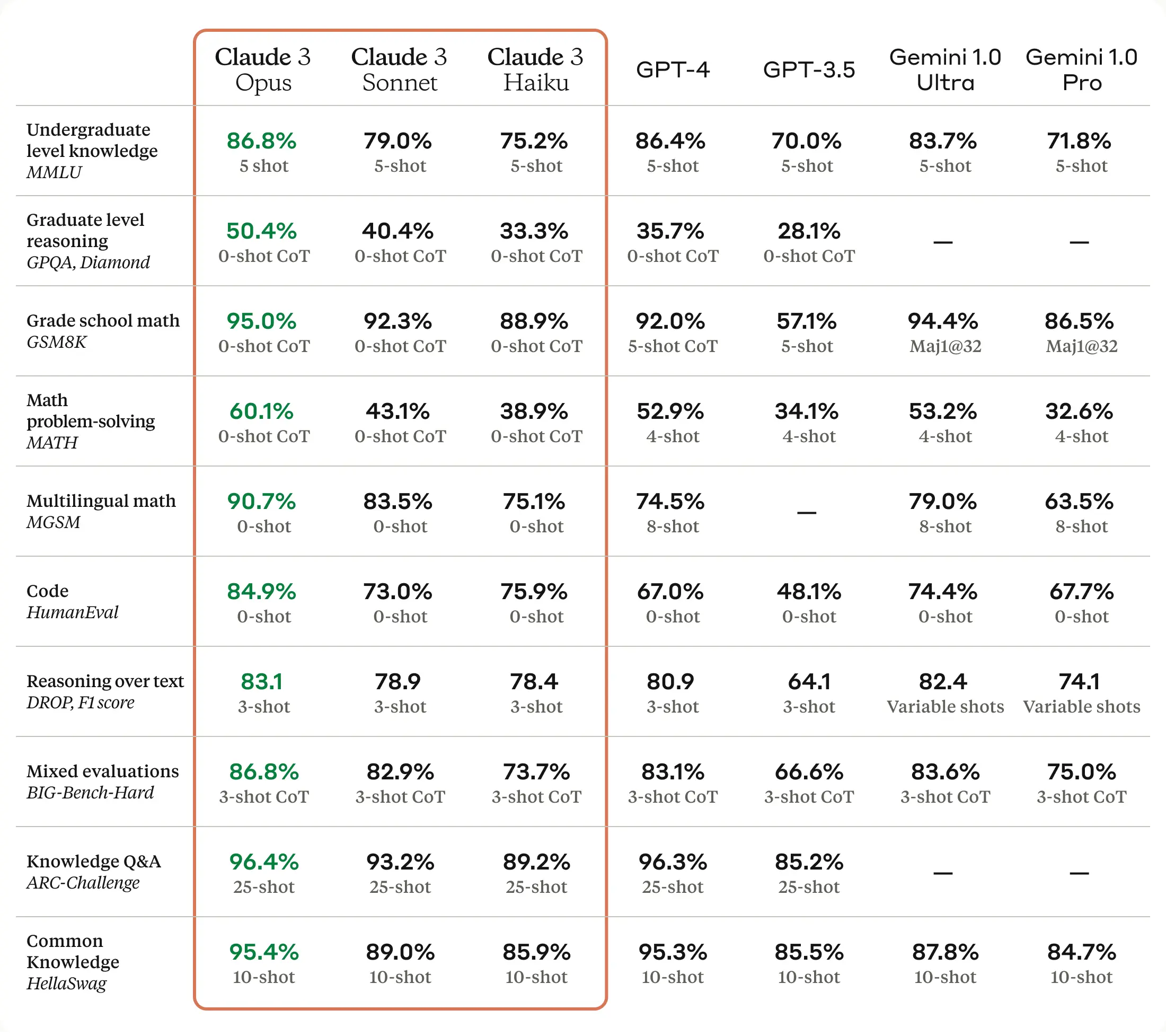
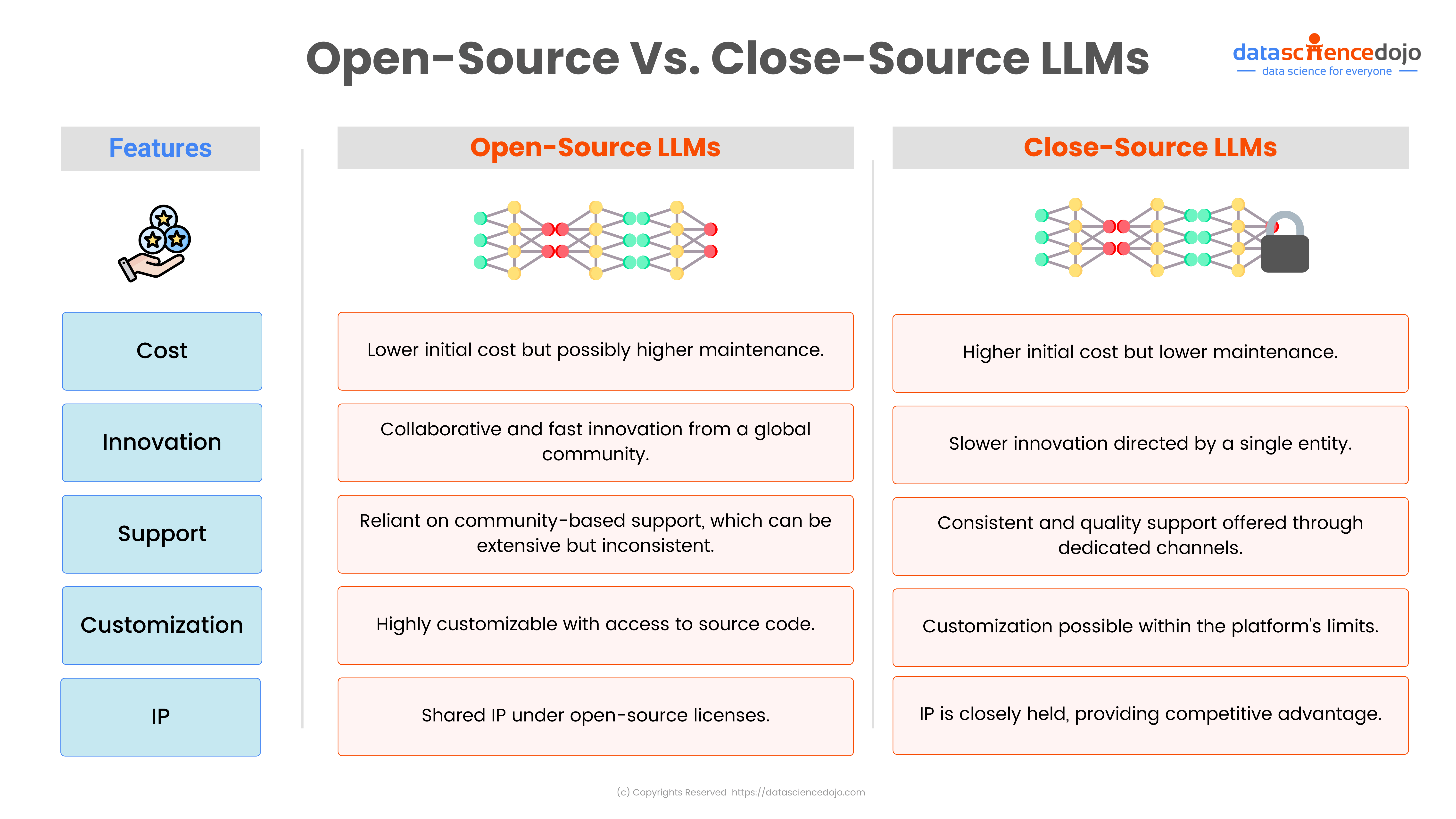
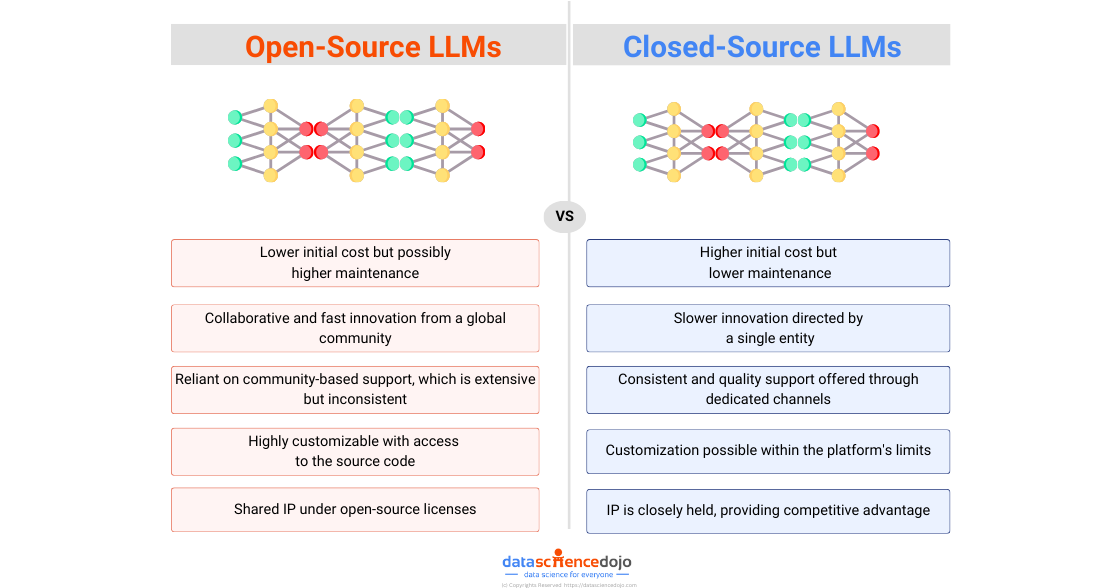
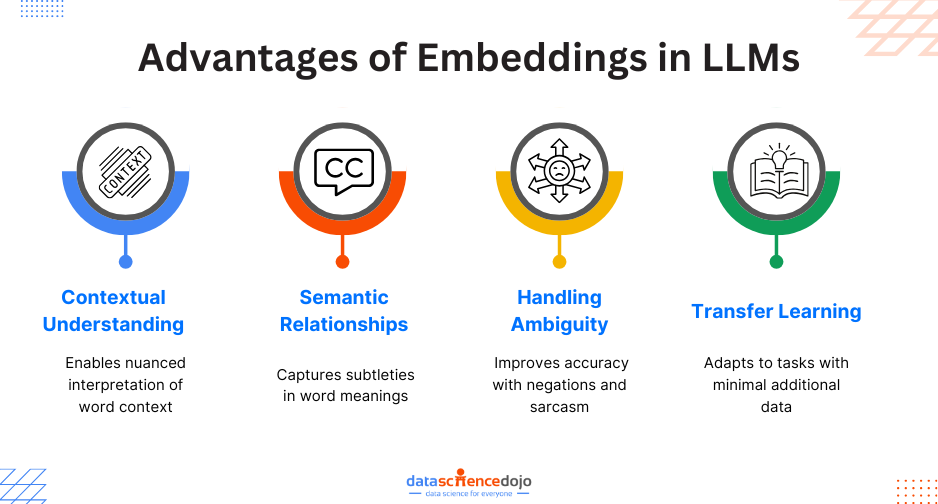
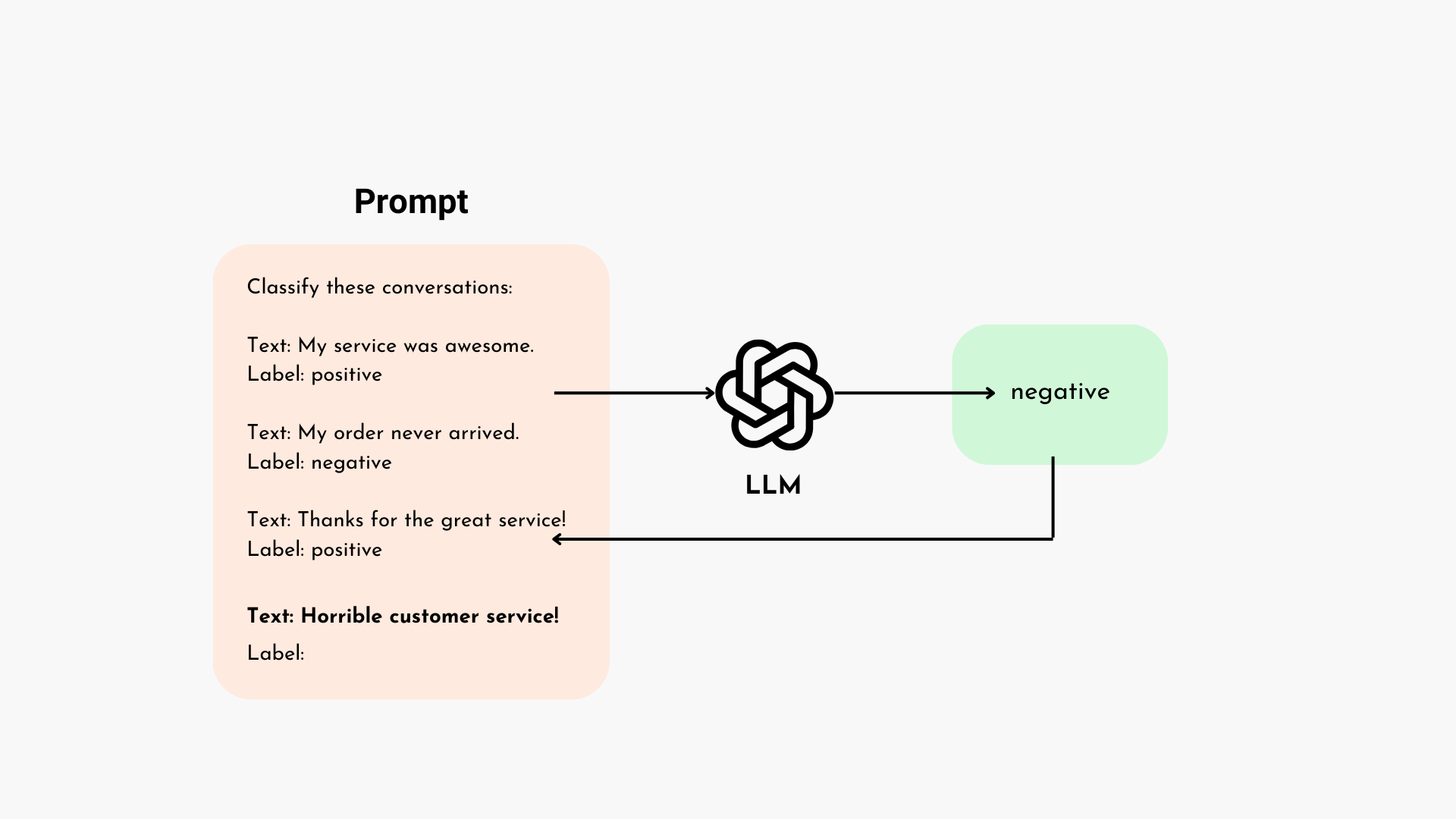
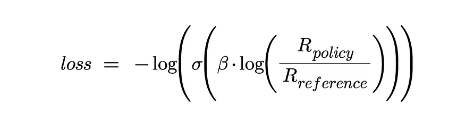Large language models (LLMs) are trained on massive textual data to generate creative and contextually relevant content. Since enterprises are utilizing LLMs to handle information effectively, they must understand the structure behind these powerful tools and the challenges associated with them.
One such component worthy of attention is the llm context window. It plays a crucial role in the development and evolution of LLM technology to enhance the way users interact with information.
In this blog, we will navigate the paradox around LLM context windows and explore possible solutions to overcome the challenges associated with large context windows. However, before we dig deeper into the topic, it’s essential to understand what LLM context windows are and their importance in the world of language models.
What Are LLM Context Windows?
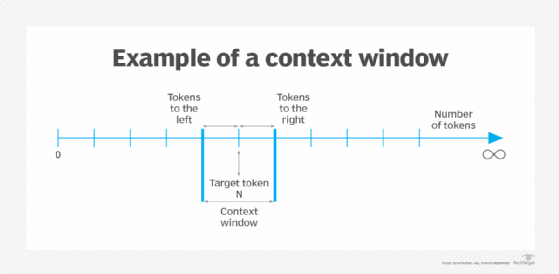
An LLM context window acts like a lens providing perspective to a large language model. The window keeps shifting to ensure a constant flow of information for an LLM as it engages with the user’s prompts and inputs. Thus, it becomes a short-term memory for LLMs to access when generating outputs.
A visual to explain context windows – Source: TechTarget
The functionality of a context window can be summarized through the following three aspects:
Focal word – Focuses on a particular word and the surrounding text, usually including a few nearby sentences in the data
Contextual information – Interprets the meaning and relationship between words to understand the context and provide relevant output for the users
Window size – Determines the amount of data and contextual information that is quickly accessible to the LLM when generating a response
Thus, context windows bae their function on the above aspects to assist LLMs in creating relevant and accurate outputs. These aspects also lay down a basis for the context window paradox that we aim to explore here.
It is a dilemma that revolves around the size of context windows. While it is only logical to expect large context windows to be beneficial, there are two sides to this argument.
Join Jerry Liu, CEO of LlamaIndex, as he simplifies the Curse of Dimensionality, Context Window Paradox, and more in LLMs.
Tune in to our podcast now!
Side One
It elaborates on the benefits of large context windows. With a wider lens, LLMs get access to more textual data and information. It enables an LLM to study more data, forming better connections between words and generating improved contextual information.
Thus, the LLM generates enhanced outputs with better understanding and a coherent flow of information. It also assists language models to handle complex tasks more efficiently.
While larger windows give access to more contextual information, it also increases the amount of data for LLMs to process. It makes it challenging to identify useful knowledge from irrelevant details in large amounts of data, overwhelming LLMs at the cost of degraded performance.
Thus, it makes the size of LLM context windows a paradoxical matter where users have to look for the right trade-off between improved contextual information and the high performance of LLMs. It leads one to decide how much information is a good amount for an efficient LLM.
Before we elaborate further on the paradox, let’s understand the role and importance of context windows in LLMs.
LLM context windows are important in ensuring the efficient working of LLMs. Their multifaceted role is described below.
Understanding Language Nuances
The focused perspective of context windows provides surrounding information in data, enabling LLMs to better understand the nuances of language. The model becomes trained to grasp the meaning and intent behind words. It empowers an LLM to perform the following tasks:
Machine Translation
An LLM uses a context window to identify the nuances of language and contextual information to create the most appropriate translation. It caters to the understanding of context within an entire sentence or paragraph to ensure efficient machine translation.
Question Answering
Understanding contextual information is crucial when answering questions. With relevant information on the situation and setting, it is easier to generate an informative answer. Using a context window, LLMs can identify the relevant parts of the conversation and avoid irrelevant tangents.
LLMs use context windows to generate text that aligns with the preceding information. By analyzing the context, the model can maintain coherence, tone, and overall theme in its response. This is important for tasks like:
Chatbots
Conversational engagement relies on a high level of coherence. It is particularly used in chatbots where the model remembers past interactions within a conversation. With the use of context windows, a chatbot can create a more natural and engaging conversation.
Here’s a step-by-step guide to building LLM chatbots.
Creative Textual Responses
LLMs can create creative content like poems, essays, and other texts. A context window allows an LLM to understand the desired style and theme from the given dataset to create creative responses that are more relevant and accurate.
Contextual Learning
Context is a crucial element for LLMs which becomes more accessible with context windows. Analyzing the relevant data with a focus on words and text of interest allows an LLM to learn and adapt their responses. It becomes useful for uses like:
Virtual Assistants
Virtual assistants are designed to help users in real time. Context window enables the assistant to remember past requests and preferences to provide more personalized and helpful service.
Open-Ended Dialogues
In ongoing conversations, the context window allows the LLM to track the flow of the dialogue and tailor its responses accordingly.
Hence, context windows act as a lens through which LLMs view and interpret information. The size and effectiveness of this perspective significantly impact the LLM’s ability to understand and respond to language in a meaningful way. This brings us back to the size of a context window and the associated paradox.
The Context Window Paradox: Is Bigger, Not Better?
While a bigger context window ensures LLM’s access to more information and better details for contextual relevance, it comes at a cost. Let’s take a look at some of the drawbacks for LLMs that come with increasing the context window size.
Information Overload
Too much information can overwhelm a language model just like humans. Too much text leads to an information overload that includes irrelevant information that can become a distraction for an LLM.
It makes it difficult for LLMs to focus on key knowledge aspects within the context, making it difficult to generate effective responses to queries. Moreover, a large textual dataset also requires more computational resources, resulting in more expense and slower LLM performance.
Getting Lost in Data
Even with a larger window for data access, an LLM can process limited information effectively. In a wider span of data, an LLM can focus on the edges. It results in LLMs prioritizing the data at the start and end of a window, missing out on important information in the middle.
Moreover, mismanaged truncation to fit a large window size can result in the loss of essential information. As a result, it can compromise the quality of the results produced by the LLM.
A wider LLM context window means a larger context that can lead to poor handling and management of information or data. With too much noise in the data, it becomes difficult for an LLM to differentiate between important and unimportant information.
It can create redundancy or contradictions in produced results, harming the credibility and efficiency of a large language model. Moreover, it creates a possibility for bias amplification, leading to misleading outputs.
Long-Range Dependencies
With a focus on concepts spread far apart in large context windows, it can become challenging for an LLM to understand relationships between words and concepts. It limits the LLM’s ability for tasks requiring historical analysis or cause-and-effect relationships.
Thus, large context windows offer advantages but with some limitations. The best approach is to find the right balance between context size, efficiency, and the specific task at hand is crucial for optimal LLM performance.
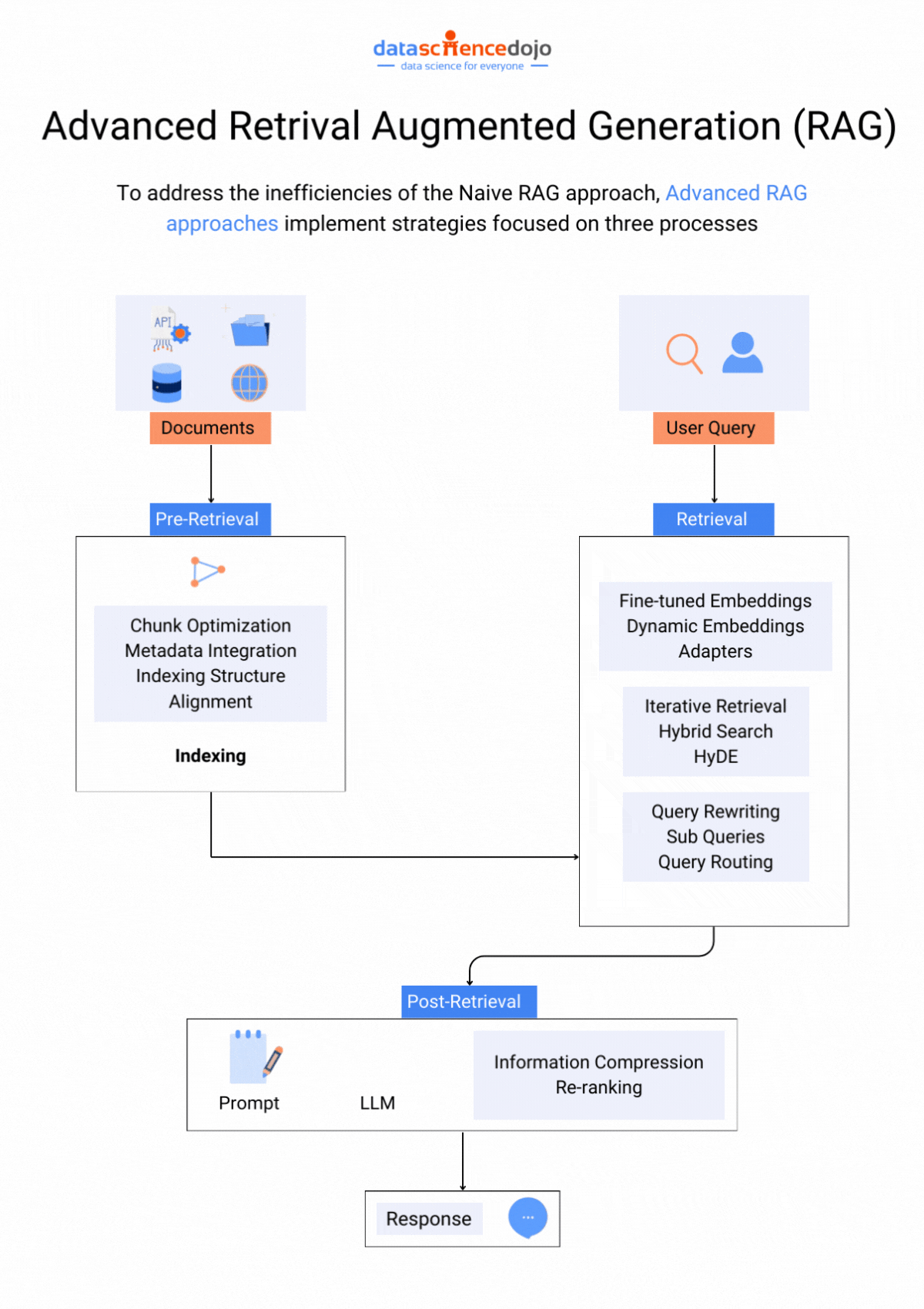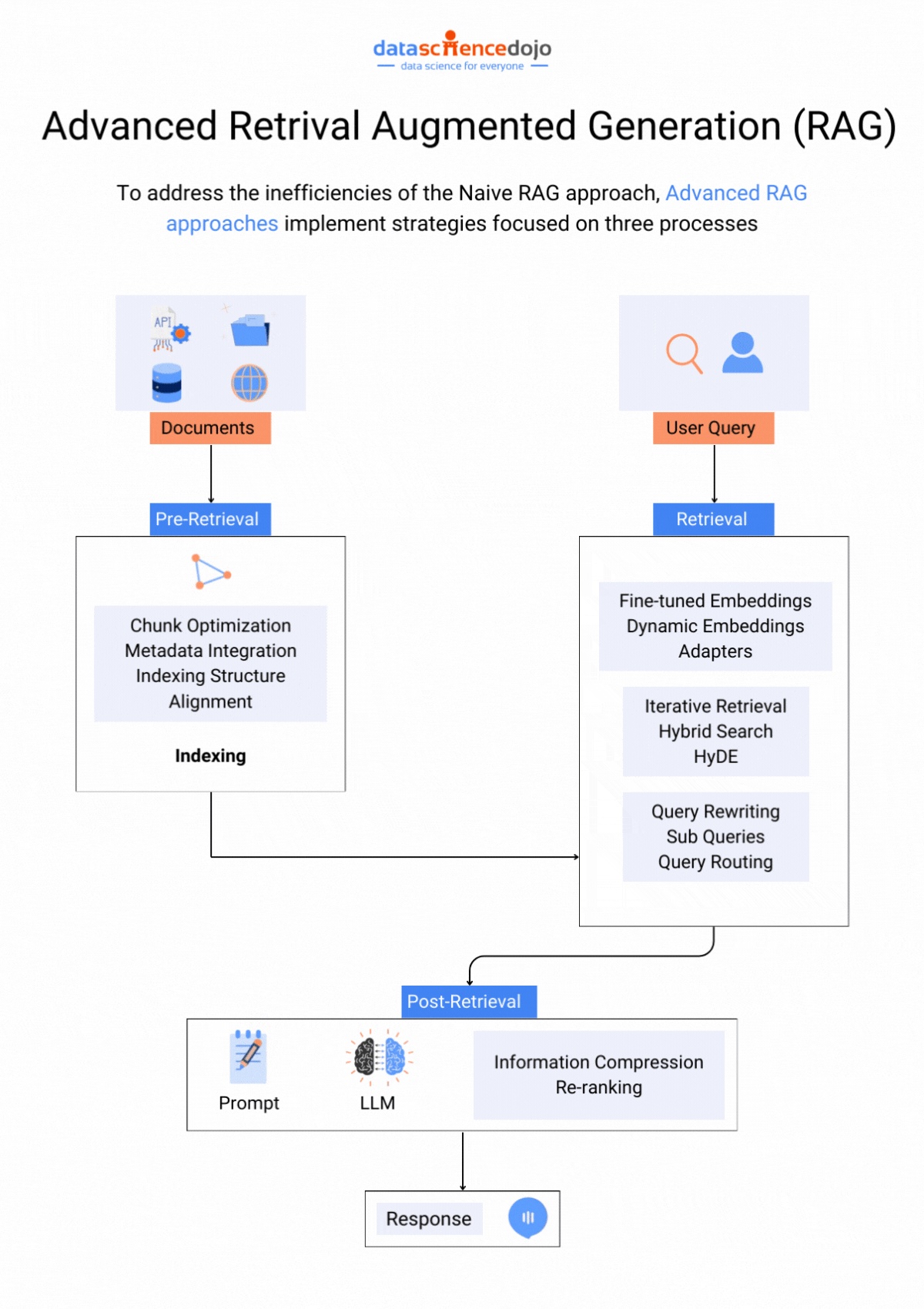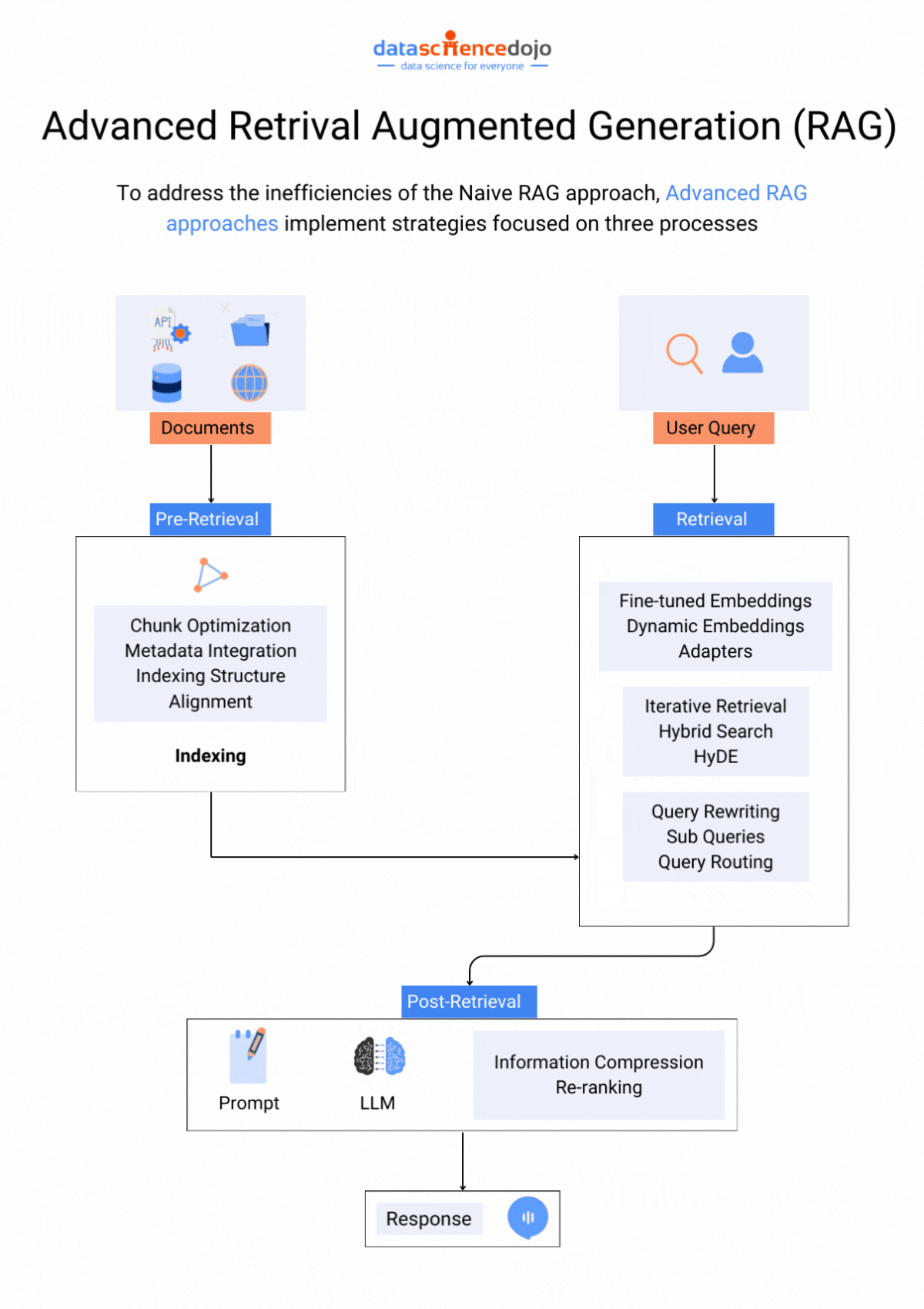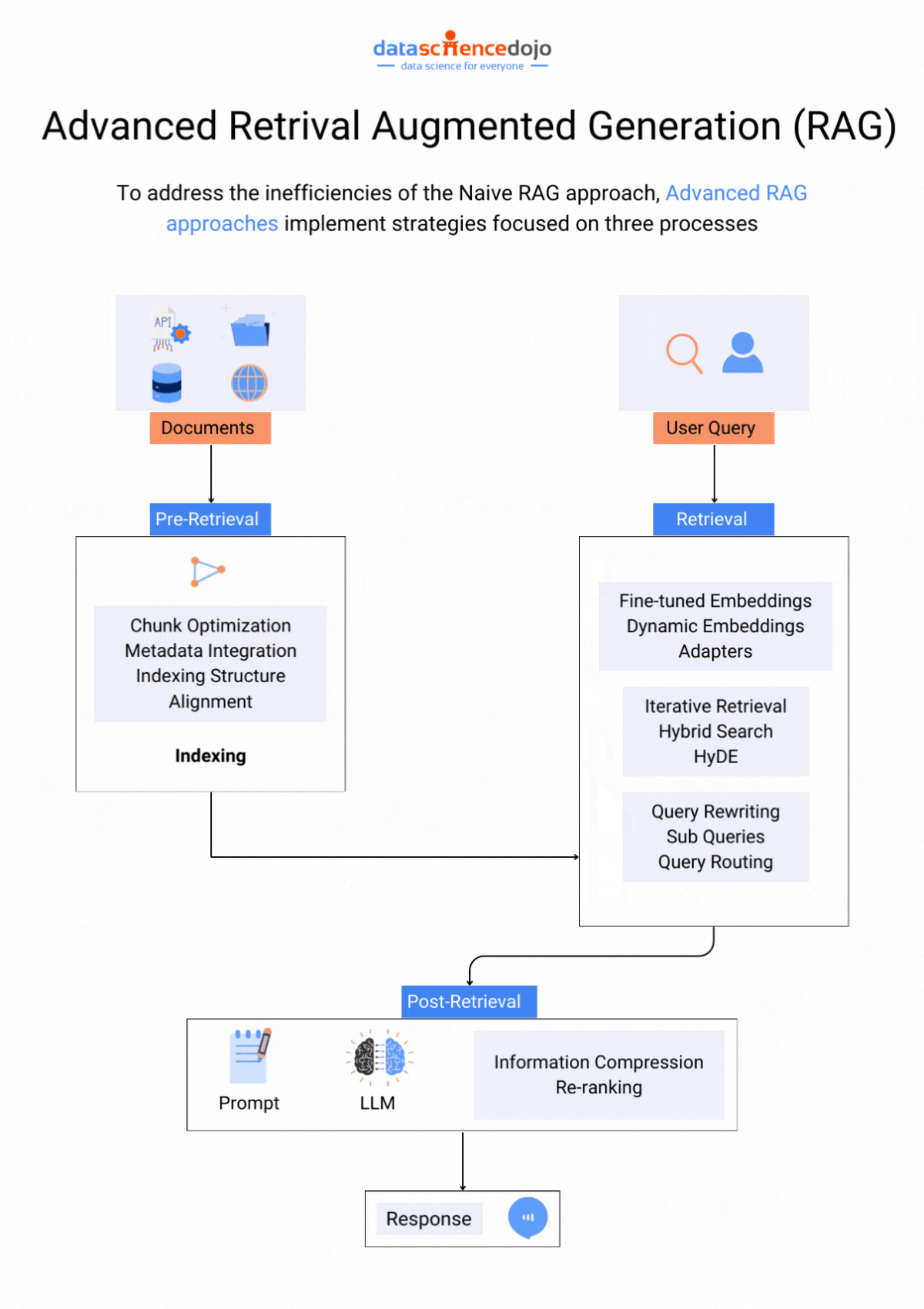
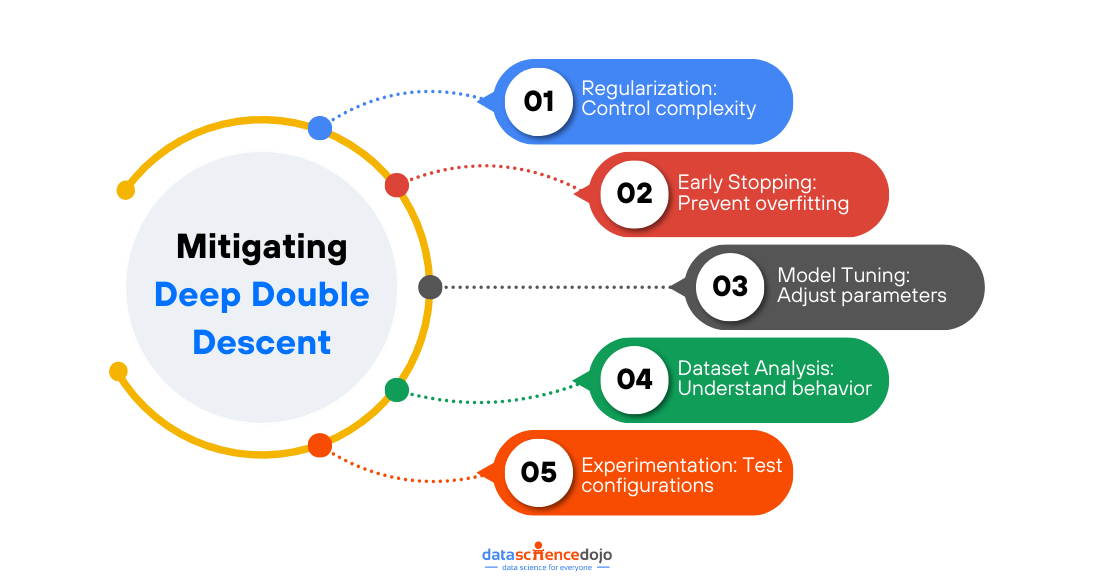
Techniques to Address Context Window Paradox
Let’s look at some techniques that can assist you in optimizing the use of large context windows. Each one explores ways to find the optimal balance between context size and LLM performance.
Prioritization and Attention Mechanisms
Attention mechanism techniques can be used to focus on crucial and most relevant information within a context window. Hence, an LLM does not have to deal with the entire flow of information and can only focus on the highlighted parts within the window, enhancing its overall performance.
Since all the information within a context window is not important or equally relevant, truncation can be used to strategically remove unrelated details. The core elements of the text needed for the task are preserved while the unnecessary information is removed, avoiding information overload on the LLM.
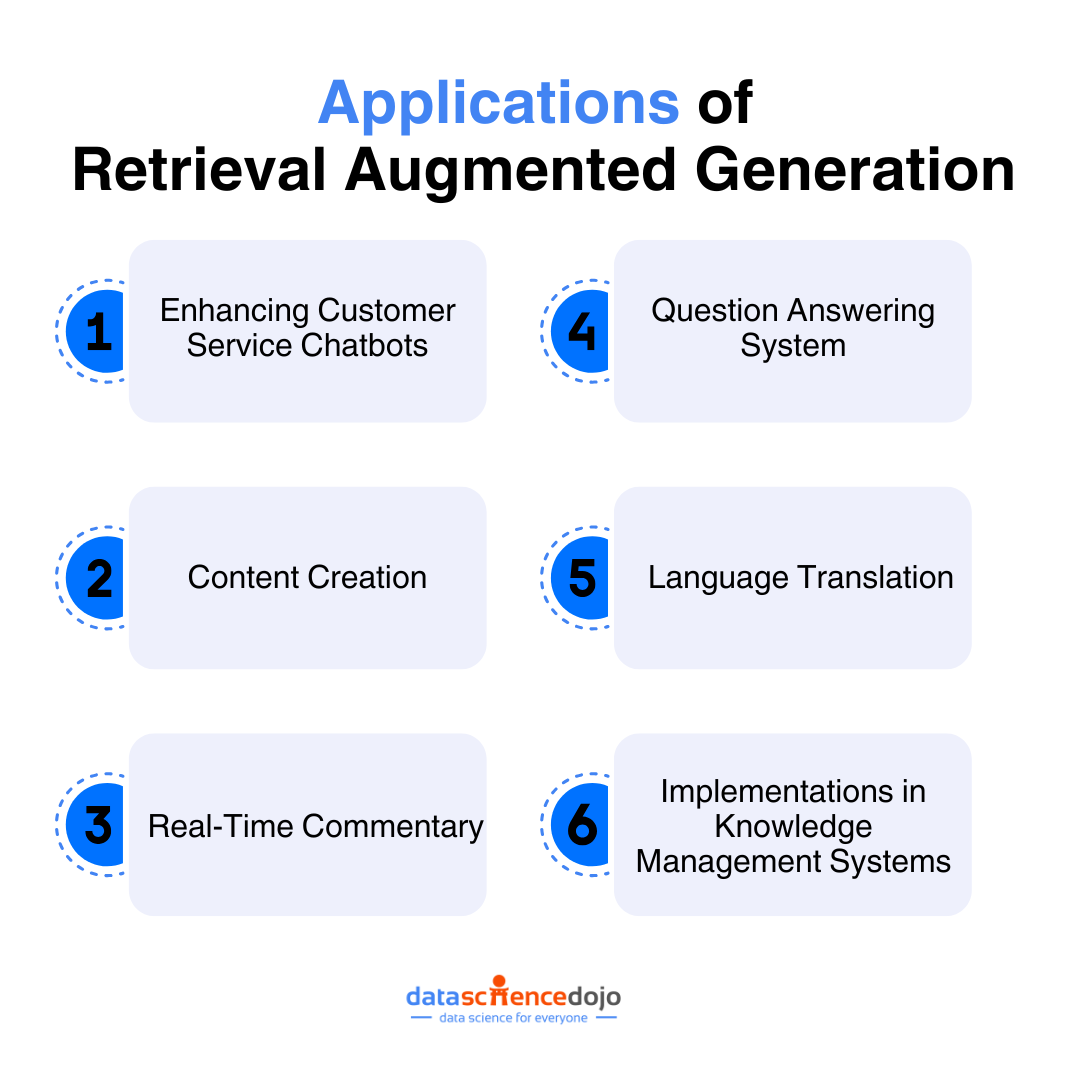
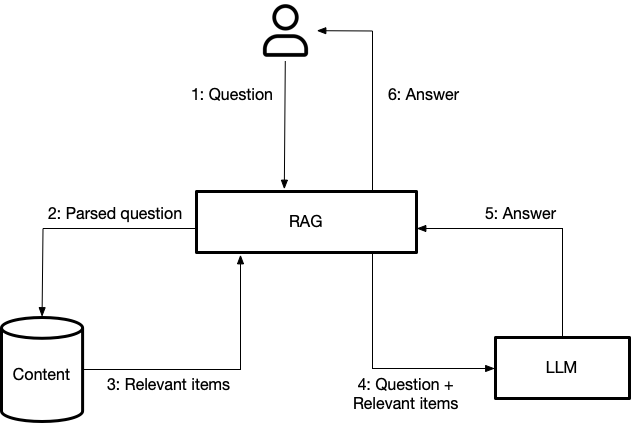
Retrieval Augmented Generation (RAG)
This technique integrates an LLM with a retrieval system containing a vast external knowledge base to find information specifically relevant to the current prompt and context window. This allows the LLM to access a wider range of information without being overwhelmed by a massive internal window.
It focuses on crafting clear instructions for the LLM to efficiently utilize the context window. Clear and focused prompts can guide the LLM toward relevant information within the context, enhancing the LLM’s efficiency in utilizing context windows.
Here’s a 10-step guide to becoming a prompt engineer
Optimizing Training Data
It is a useful practice to organize training data, creating well-defined sections, summaries, and clear topic shifts, helping the LLM learn to navigate larger contexts more effectively. The structured information makes it easier for an LLM to process data within the context window.
These techniques can help us address the context window paradox and leverage the benefits of larger context windows while mitigating their drawbacks.
The Future of Context Windows in LLMs
We have looked at the varying aspects of LLM context windows and the paradox involving their size. With the right approach, technique, and balance, it is possible to choose the optimal context window size for an LLM. Moreover, it also highlights the need to focus on the potential of context windows beyond the paradox around their size.
The future is expected to transition from cramming more information into a context window to ward smarter context utilization. Moreover, advancements in attention mechanisms and integration with external knowledge bases will also play a role, allowing LLMs to pinpoint truly relevant information regardless of window size.
Ultimately, the goal is for LLMs to become context masters, understanding not just the “what” but also the “why” within the information they process. This will pave the way for LLMs to tackle even more intricate tasks and generate responses that are both informative and human-like.
Language is the basis for human interaction and communication. Speaking and listening are the direct by-products of human reliance on language. While humans can use language to understand each other, in today’s digital world, they must also interact with machines.
The answer lies in large language models (LLMs) – machine-learning models that empower machines to learn, understand, and interact using human language. Hence, they open a gateway to enhanced and high-quality human-computer interaction.
Let’s understand large language models further.
What are Large Language Models?
Imagine a computer program that’s a whiz with words, capable of understanding and using language in fascinating ways. That’s essentially what an LLM is! Large language models are powerful AI-powered language tools trained on massive amounts of text data, like books, articles, and even code.
By analyzing this data, LLMs become experts at recognizing patterns and relationships between words. This allows them to perform a variety of impressive tasks, like:
Creative Text Generation
LLMs can generate different creative text formats, crafting poems, scripts, musical pieces, emails, and even letters in various styles. From a catchy social media post to a unique story idea, these language models can pull you out of any writer’s block. Some LLMs, like LaMDA by Google AI, can help you brainstorm ideas and even write different creative text formats based on your initial input.
Speak Many Languages
Since language is the area of expertise for LLMs, the models are trained to work with multiple languages. It enables them to understand and translate languages with impressive accuracy. For instance, Microsoft’s Translator powered by LLMs can help you communicate and access information from all corners of the globe.
Information Powerhouse
With extensive training datasets and a diversity of information, LLMs become information powerhouses with quick answers to all your queries. They are highly advanced search engines that can provide accurate and contextually relevant information to your prompts.
Like Megatron-Turing NLG from NVIDIA can analyze vast amounts of information and summarize it in a clear and concise manner. This can help you gain insights and complete tasks more efficiently.
As you kickstart your journey of understanding LLMs, don’t forget to tune in to our Future of Data and AI podcast!
LLMs are constantly evolving, with researchers developing new techniques to unlock their full potential. These powerful language tools hold immense promise for various applications, from revolutionizing communication and content creation to transforming the way we access and understand information.
As LLMs continue to learn and grow, they’re poised to be a game-changer in the world of language and artificial intelligence.
While this is a basic concept of LLMs, they are a very vast concept in the world of generative AI and beyond. This blog aims to provide in-depth guidance in your journey to understand large language models. Let’s take a look at all you need to know about LLMs.
A Roadmap to Building LLM Applications
Before we dig deeper into the structural basis and architecture of large language models, let’s look at their practical applications and understand the basic roadmap to building them.
Explore the outline of a roadmap that will guide you in learning about building and deploying LLMs. Read more about it here.
LLM applications are important for every enterprise that aims to thrive in today’s digital world. From reshaping software development to transforming the finance industry, large language models have redefined human-computer interaction in all industrial fields.
However, the application of LLM is not just limited to technical and financial aspects of business. The assistance of large language models has upscaled the legal career of lawyers with ease of documentation and contract management.
While the industrial impact of LLMs is paramount, the most prominent impact of large language models across all fields has been through chatbots. Every profession and business has reaped the benefits of enhanced customer engagement, operational efficiency, and much more through LLM chatbots.
Here’s a guide to the building techniques and real-life applications of chatbots using large language models: Guide to LLM chatbots
LLMs have improved the traditional chatbot design, offering enhanced conversational ability and better personalization. With the advent of OpenAI’s GPT-4, Google AI’s Gemini, and Meta AI’s LLaMA, LLMs have transformed chatbots to become smarter and a more useful tool for modern-day businesses.
Hence, LLMs have emerged as a useful tool for enterprises, offering advanced data processing and communication for businesses with their machine-learning models. If you are looking for a suitable large language model for your organization, the first step is to explore the available options in the market.
Top Large Language Models to Choose From
The modern market is swamped with different LLMs for you to choose from. With continuous advancements and model updates, the landscape is constantly evolving to introduce improved choices for businesses. Hence, you must carefully explore the different LLMs in the market before deploying an application for your business.
Below is a list of LLMs you can find in the market today.
ChatGPT
The list must start with the very famous ChatGPT. Developed by OpenAI, it is a general-purpose LLM that is trained on a large dataset, consisting of text and code. Its instant popularity sparked a widespread interest in LLMs and their potential applications.
While people explored cheat sheets to master ChatGPT usage, it also initiated a debate on the ethical impacts of such a tool in different fields, particularly education. However, despite the concerns, ChatGPT set new records by reaching 100 million monthly active users in just two months.
This tool also offers plugins as supplementary features that enhance the functionality of ChatGPT. We have created a list of the best ChatGPT plugins that are well-suited for data scientists. Explore these to get an idea of the computational capabilities that ChatGPT can offer.
Here’s a guide to the best practices you can follow when using ChatGPT.
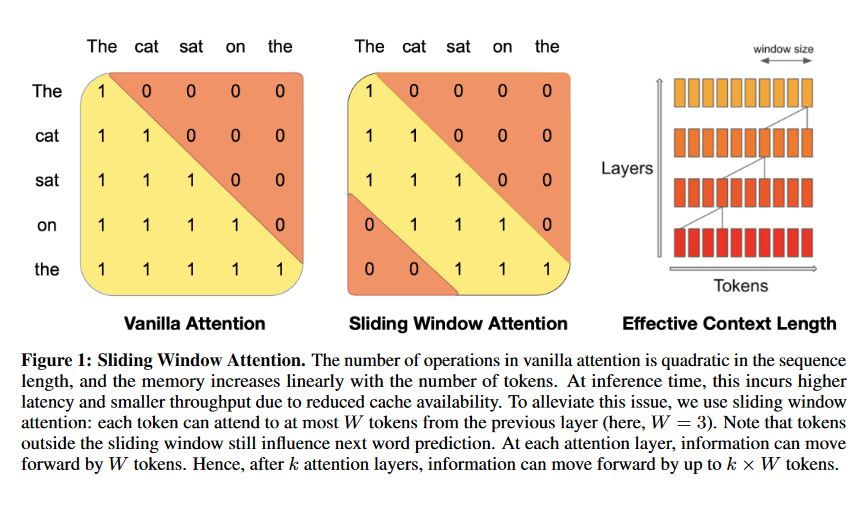
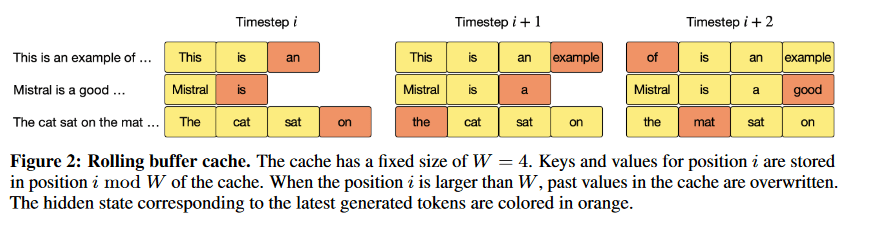
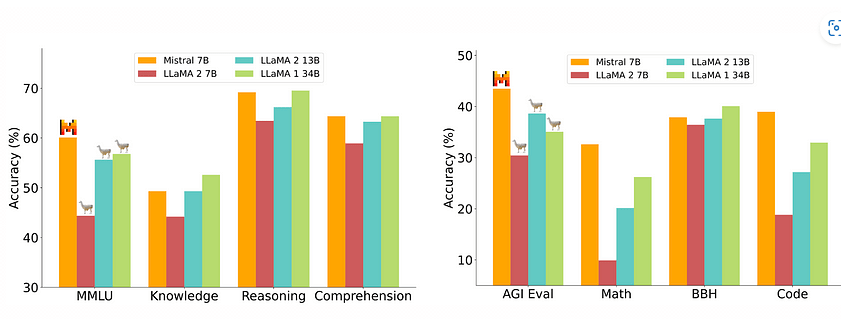
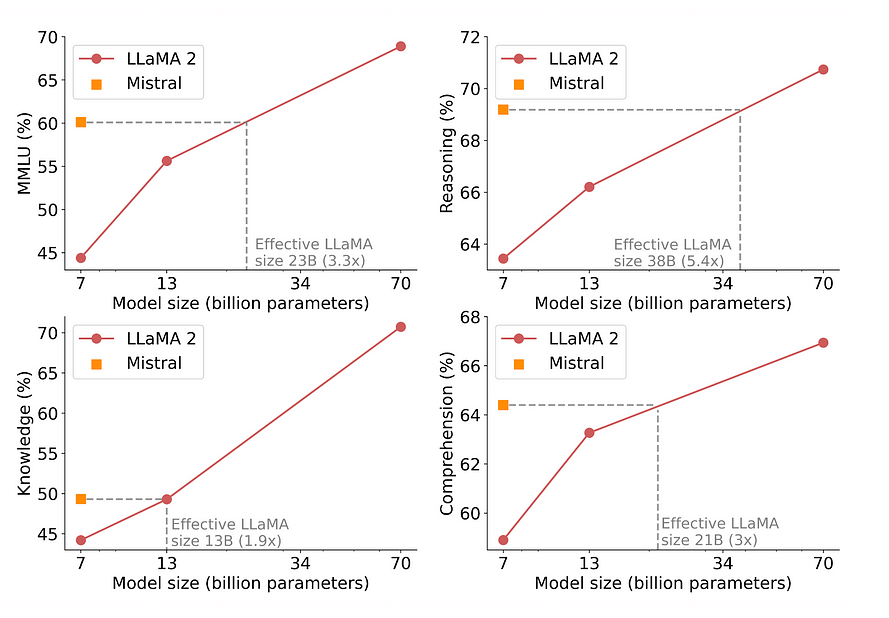
Mistral 7b
It is a 7.3 billion parameter model developed by Mistral AI. It incorporates a hybrid approach of transformers and recurrent neural networks (RNNs), offering long-term memory and context awareness for tasks. Mistral 7b is a testament to the power of innovation in the LLM domain.
Here’s an article that explains the architecture and performance of Mistral 7b in detail. You can explore its practical applications to get a better understanding of this large language model.
Phi-2
Designed by Microsoft, Phi-2 has a transformer-based architecture that is trained on 1.4 trillion tokens. It excels in language understanding and reasoning, making it suitable for research and development. With only 2.7 billion parameters, it is a relatively smaller LLM, making it useful for research and development.
You can read more about the different aspects of Phi-2 here.
Llama 2
It is an open-source large language model that varies in scale, ranging from 7 billion to a staggering 70 billion parameters. Meta developed this LLM by training it on a vast dataset, making it suitable for developers, researchers, and anyone interested in their potential.
Llama 2 is adaptable for tasks like question answering, text summarization, machine translation, and code generation. Its capabilities and various model sizes open up the potential for diverse applications, focusing on efficient content generation and automating tasks.
Now that you have an understanding of the different LLM applications and their power in the field of content generation and human-computer communication, let’s explore the architectural basis of LLMs.
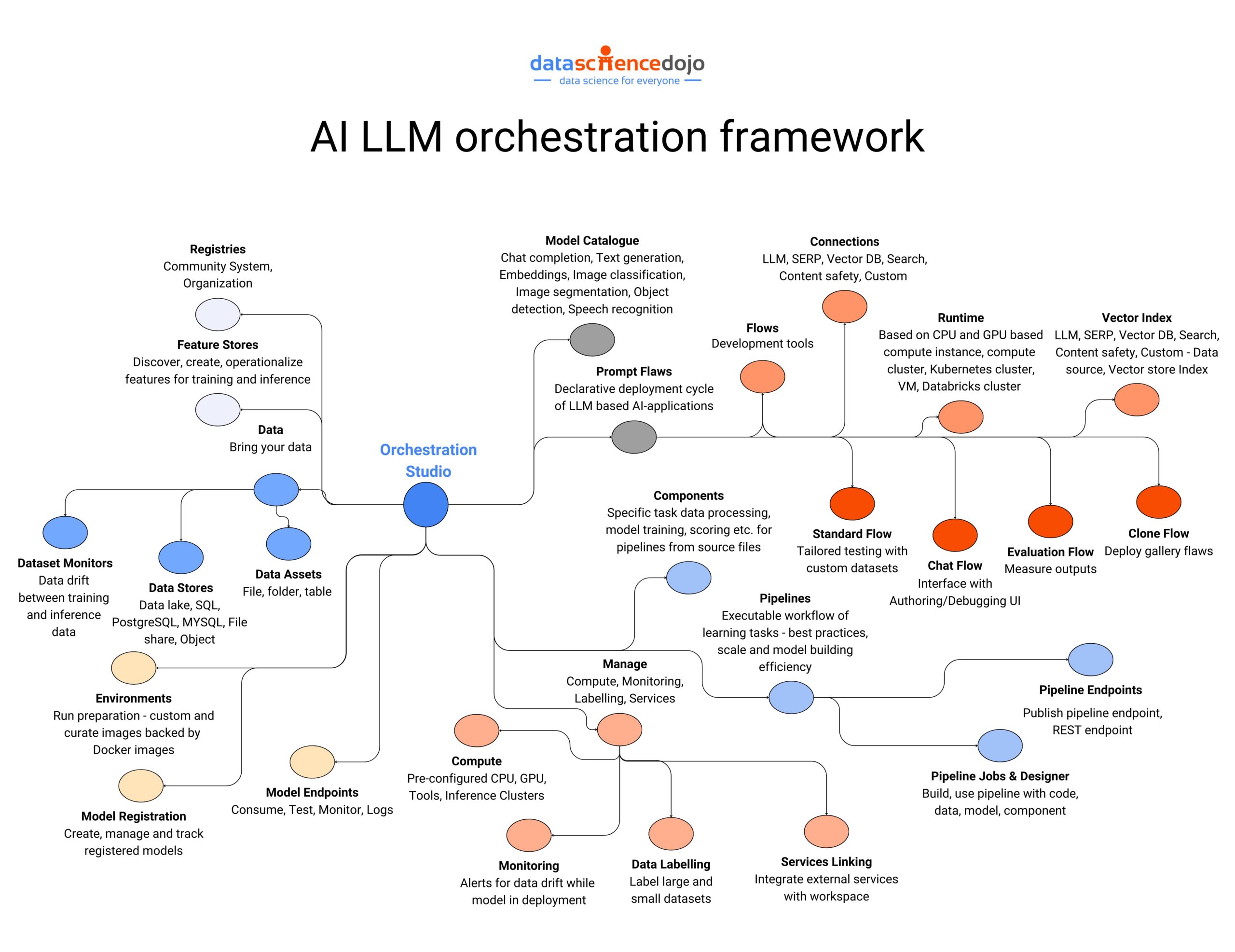
Emerging Frameworks for Large Language Model Applications
LLMs have revolutionized the world of natural language processing (NLP), empowering the ability of machines to understand and generate human-quality text. The wide range of applications of these large language models is made accessible through different user-friendly frameworks.
An outlook of the LLM orchestration framework
Let’s look at some prominent frameworks for LLM applications.
LangChain for LLM Application Development
LangChain is a useful framework that simplifies the LLM application development process. It offers pre-built components and a user-friendly interface, enabling developers to focus on the core functionalities of their applications.
LangChain breaks down LLM interactions into manageable building blocks called components and chains. Thus, allowing you to create applications without needing to be an LLM expert. Its major benefits include a simplified development process, flexibility in data integration, and the ability to combine different components for a powerful LLM.
With features like chains, libraries, and templates, the development of large language models is accelerated and code maintainability is promoted. Thus, making it a valuable tool to build innovative LLM applications. Here’s a guide exploring the power of LangChain to build custom chatbots.
Here’s a complete guide to learn all about LangChain
LlamaIndex for LLM Application Development
It is a special framework designed to build knowledge-aware LLM applications. It emphasizes on integrating user-provided data with LLMs, leveraging specific knowledge bases to generate more informed responses. Thus, LlamaIndex produces results that are more informed and tailored to a particular domain or task.
With its focus on data indexing, it enhances the LLM’s ability to search and retrieve information from large datasets. With its security and caching features, LlamaIndex is designed to uncover deeper insights in text exploration. It also focuses on ensuring efficiency and data protection for developers working with large language models.
Tune in to this podcast featuring LlamaIndex’s Co-founder and CEO Jerry Liu, and learn all about LLMs, RAG, LlamaIndex and more!
Moreover, its advanced query interfaces make it a unique orchestration framework for LLM application development. Hence, it is a valuable tool for researchers, data analysts, and anyone who wants to unlock the knowledge hidden within vast amounts of textual data using LLMs.
Hence, LangChain and LlamaIndex are two useful orchestration frameworks to assist you in the LLM application development process. Here’s a guide explaining the role of these frameworks in simplifying the LLM apps.
Here’s a webinar introducing you to the architectures for LLM applications, including LangChain and LlamaIndex:
Understand the key differences between LangChain and LlamaIndex
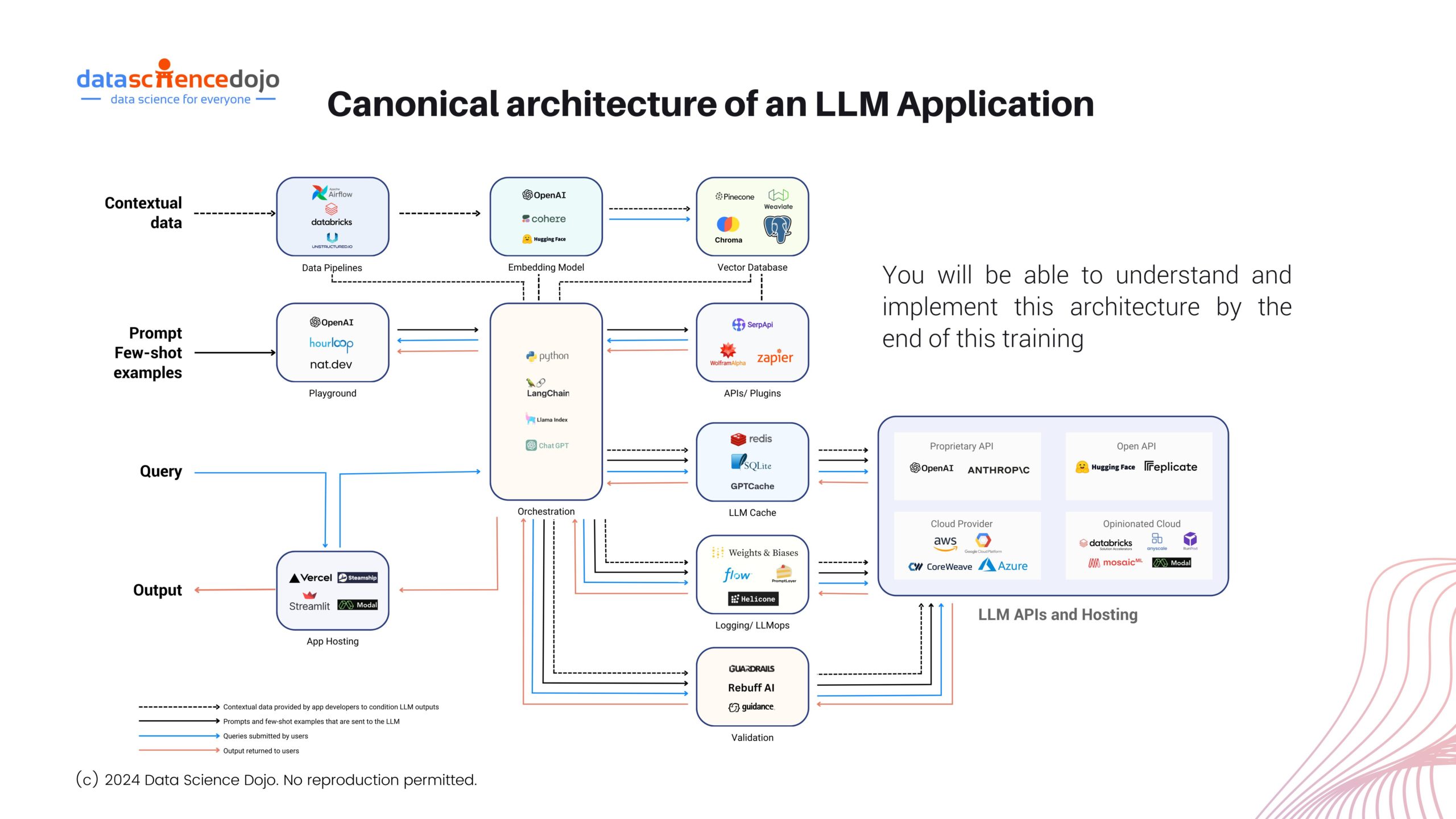
The Architecture of Large Language Model Applications
While we have explored the realm of LLM applications and frameworks that support their development, it’s time to take our understanding of large language models a step ahead.
An outlook of the LLM architecture
Let’s dig deeper into the key aspects and concepts that contribute to the development of an effective LLM application.
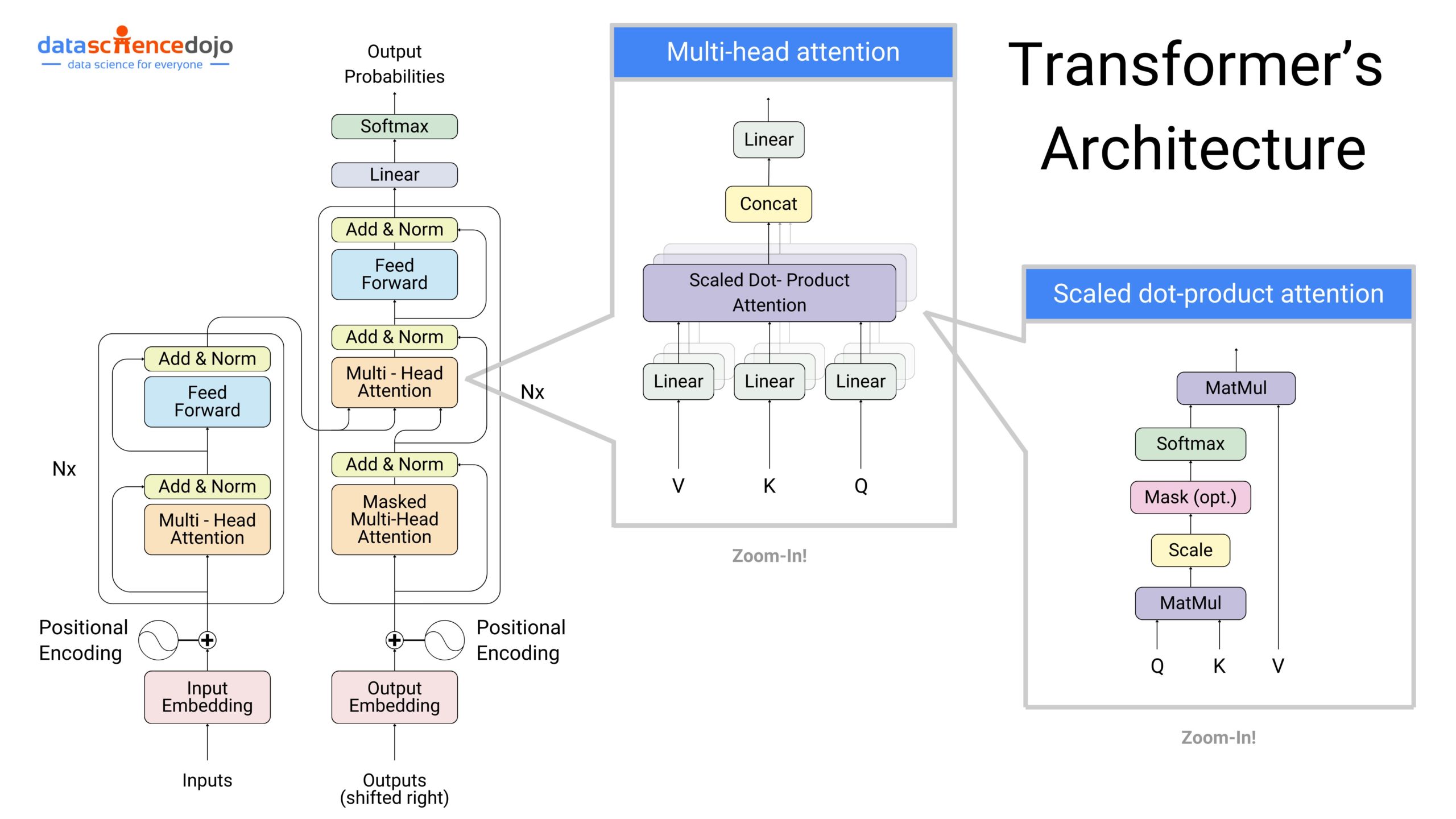
Transformers and Attention Mechanisms
The concept of transformers in neural networks has roots stretching back to the early 1990s with Jürgen Schmidhuber’s “fast weight controller” model. However, researchers have constantly worked towards the advancement of the concept, leading to the rise of transformers as the dominant force in natural language processing
It has paved the way for their continued development and remarkable impact on the field. Transformer models have revolutionized NLP with their ability to grasp long-range connections between words because understanding the relationship between words across the entire sentence is crucial in such applications.
While you understand the role of transformer models in the development of NLP applications, here’s a guide to decoding the transformers further by exploring their underlying functionality using an attention mechanism. It empowers models to produce faster and more efficient results for their users.
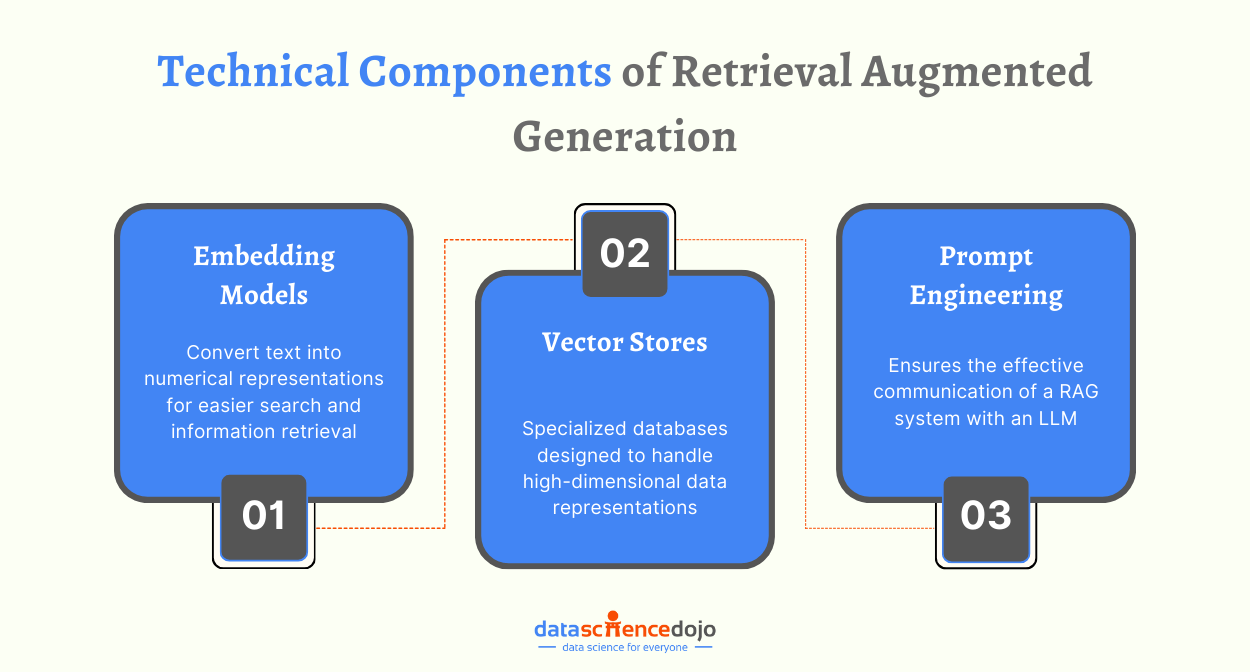
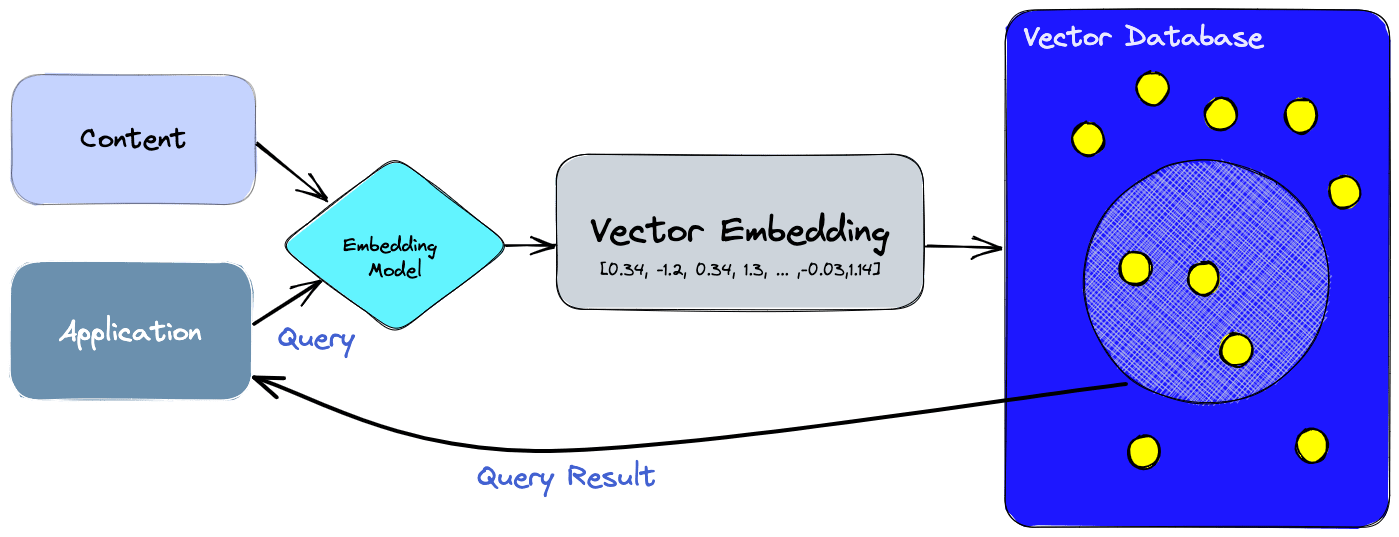
Embeddings
While transformer models form the powerful machine architecture to process language, they cannot directly work with words. Transformers rely on embeddings to create a bridge between human language and its numerical representation for the machine model.
Hence, embeddings take on the role of a translator, making words comprehendible for ML models. It empowers machines to handle large amounts of textual data while capturing the semantic relationships in them and understanding their underlying meaning.
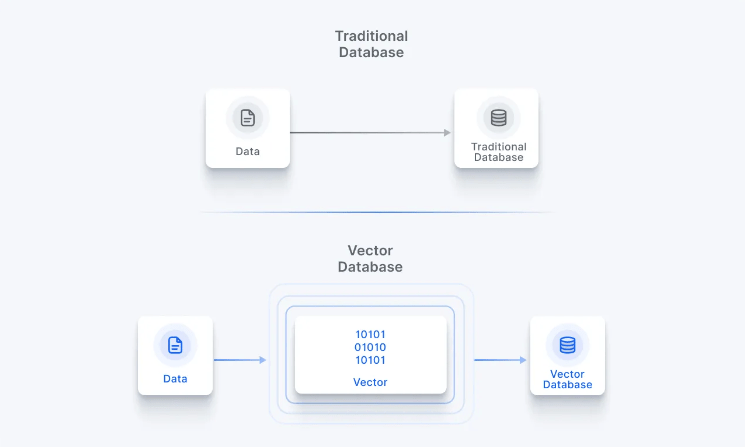
Thus, these embeddings lead to the building of databases that transformers use to generate useful outputs in NLP applications. Today, embeddings have also developed to present new ways of data representation with vector embeddings, leading organizations to choose between traditional and vector databases.
While here’s an article that delves deep into the comparison of traditional and vector databases, let’s also explore the concept of vector embeddings.
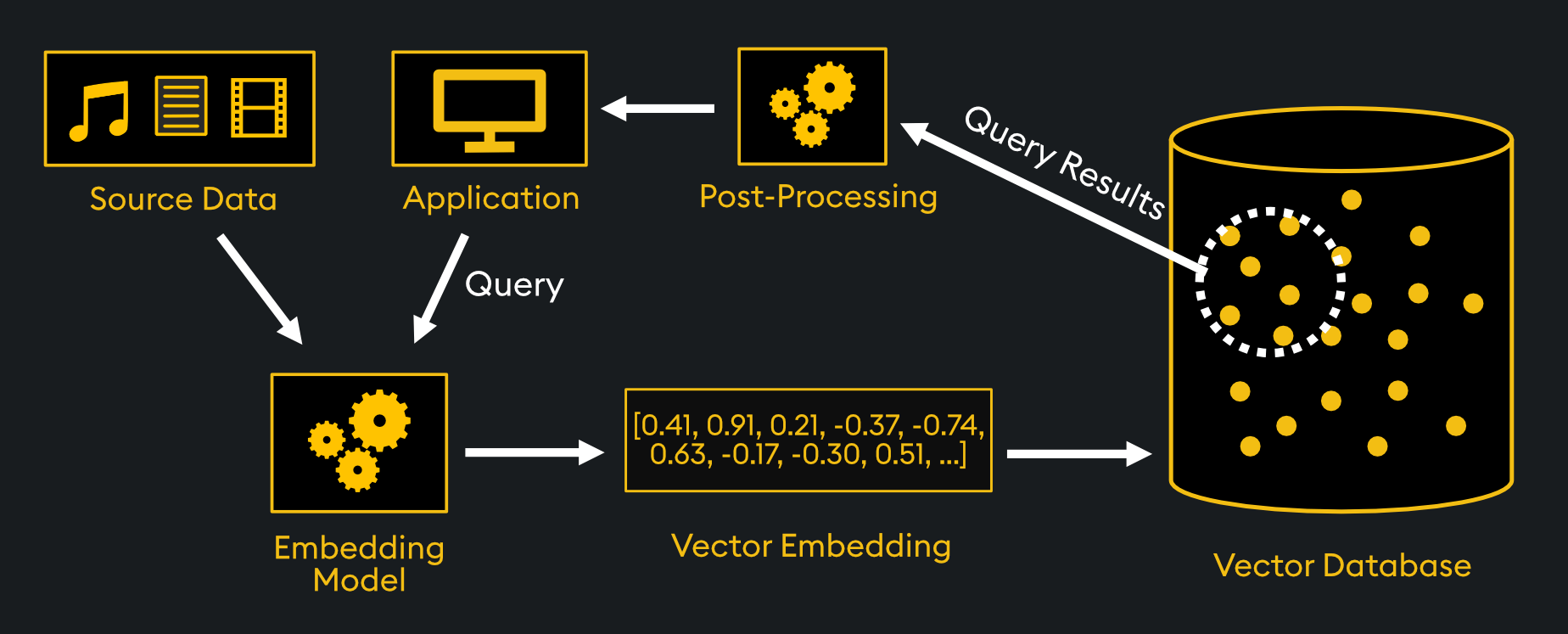
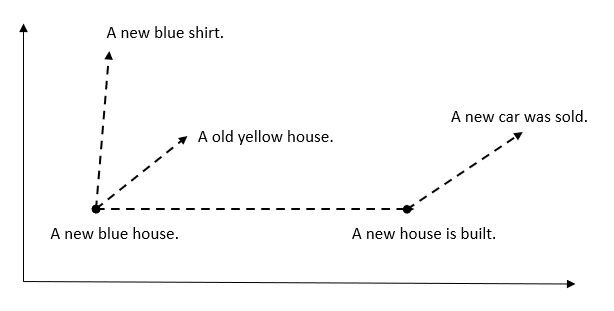
These are a unique type of embedding used in natural language processing which converts words into a series of vectors. It enables words with similar meanings to have similar vector representations, producing a three-dimensional map of data points in the vector space.
Machines traditionally struggle with language because they understand numbers, not words. Vector embeddings bridge this gap by converting words into a numerical format that machines can process. More importantly, the captured relationships between words allow machines to perform NLP tasks like translation and sentiment analysis more effectively.
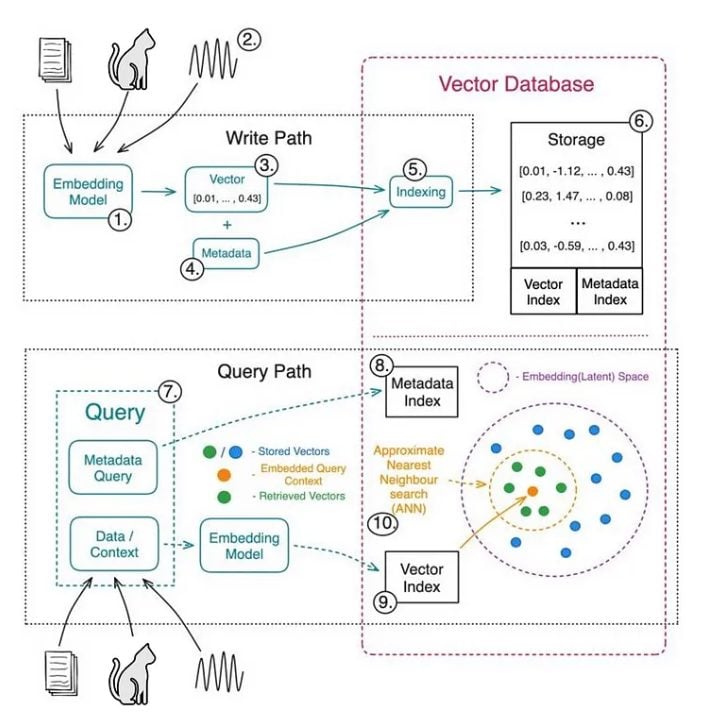
Here’s a video series providing a comprehensive exploration of embeddings and vector databases.
Vector embeddings are like a secret language for machines, enabling them to grasp the nuances of human language. However, when organizations are building their databases, they must carefully consider different factors to choose the right vector embedding model for their data.
However, database characteristics are not the only aspect to consider. Enterprises must also explore the different types of vector databases and their features. It is also a useful tactic to navigate through the top vector databases in the market.
Thus, embeddings and databases work hand-in-hand in enabling transformers to understand and process human language. These developments within the world of LLMs have also given rise to the idea of prompt engineering. Let’s understand this concept and its many facets.
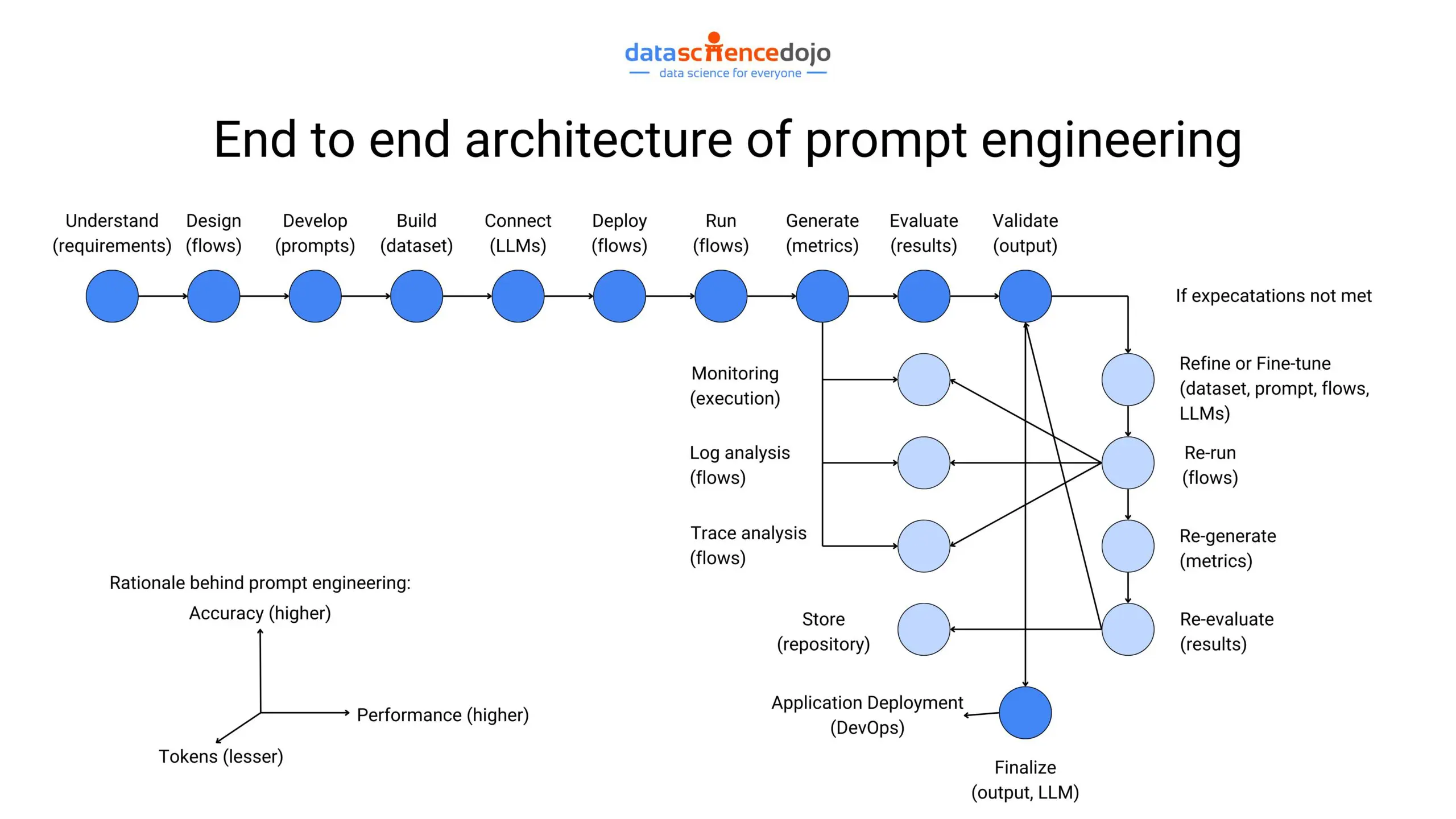
It refers to the art of crafting clear and informative prompts when one interacts with large language models. Well-defined instructions have the power to unlock an LLM’s complete potential, empowering it to generate effective and desired outputs.
Effective prompt engineering is crucial because LLMs, while powerful, can be like complex machines with numerous functionalities. Clear prompts bridge the gap between the user and the LLM. Specifying the task, including relevant context, and structuring the prompt effectively can significantly improve the quality of the LLM’s output.
With the growing dominance of LLMs in today’s digital world, prompt engineering has become a useful skill to hone for individuals. It has led to increased demand for skilled, prompt engineers in the job market, making it a promising career choice for people. While it’s a skill to learn through experimentation, here is a 10-step roadmap to kickstart the journey.
Explaining the workflow for prompt engineering
Now that we have explored the different aspects contributing to the functionality of large language models, it’s time we navigate the processes for optimizing LLM performance.
How to Optimize the Performance of Large Language Models?
As businesses work with the design and use of different LLM applications, it is crucial to ensure the use of their full potential. It requires them to optimize LLM performance, creating enhanced accuracy, efficiency, and relevance of LLM results. Some common terms associated with the idea of optimizing LLMs are listed below:
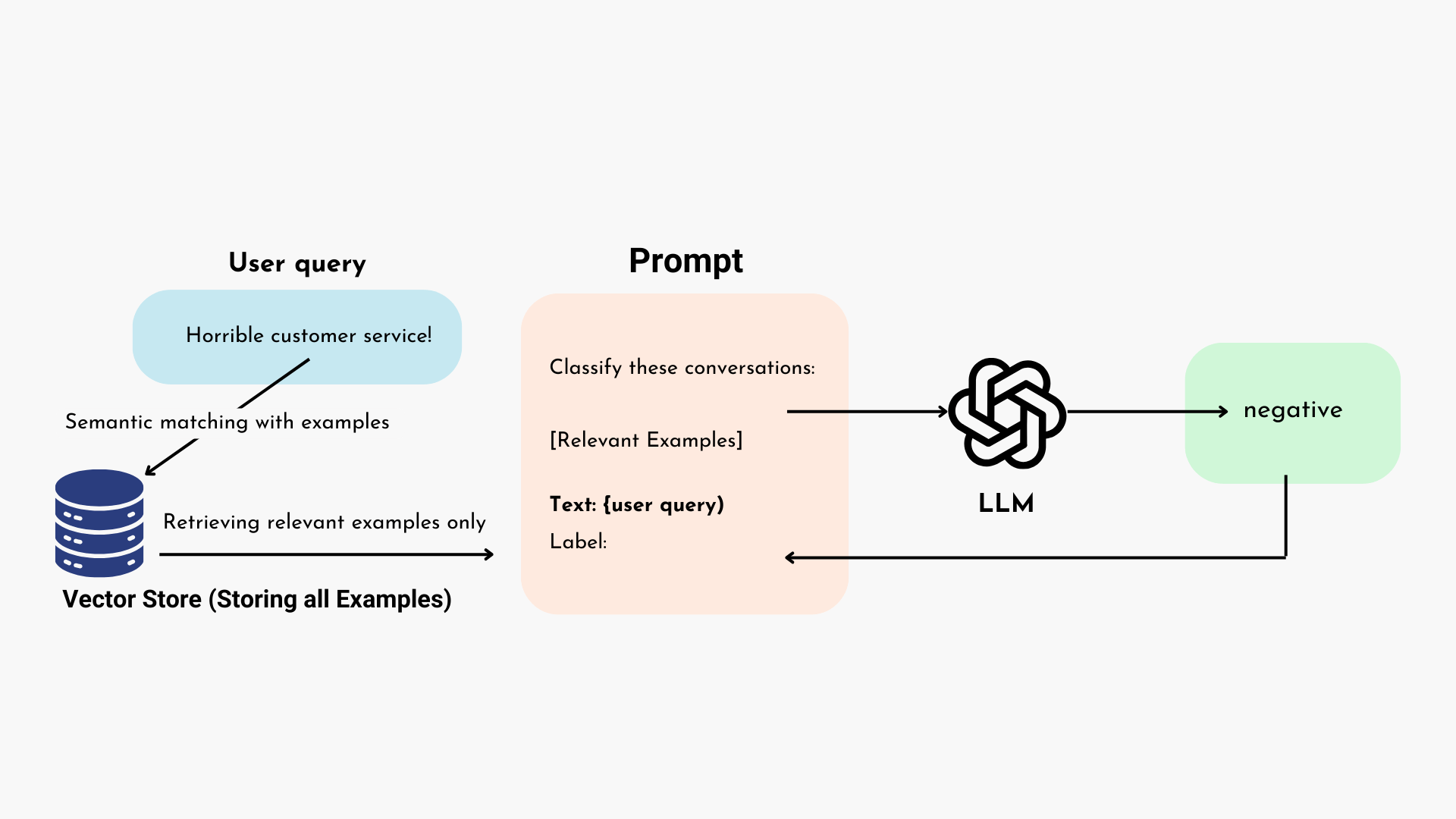
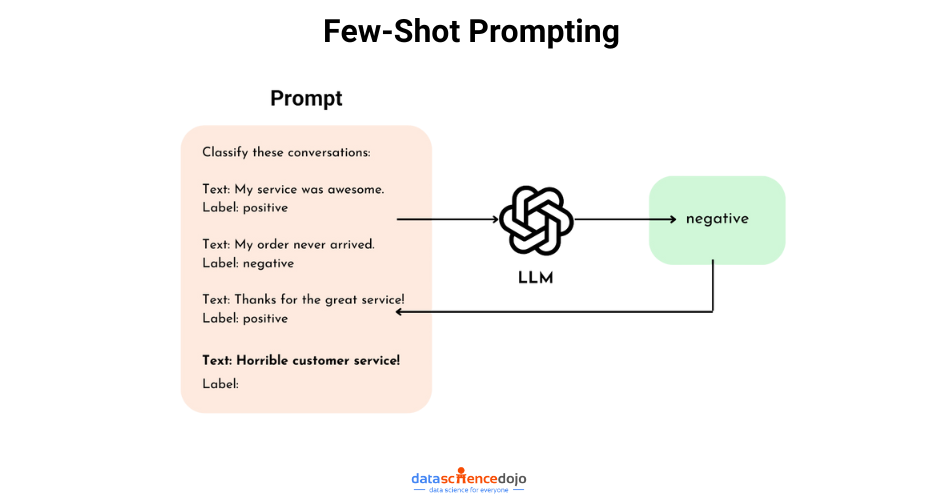
Dynamic Few-Shot Prompting
Beyond the standard few-shot approach, it is an upgrade that selects the most relevant examples based on the user’s specific query. The LLM becomes a resourceful tool, providing contextually relevant responses. Hence, top 10 LLM use cases enhances an LLM’s performance, creating more captivating digital content.
Selective Prediction
It allows LLMs to generate selective outputs based on their certainty about the answer’s accuracy. It enables the applications to avoid results that are misleading or contain incorrect information. Hence, by focusing on high-confidence outputs, selective prediction enhances the reliability of LLMs and fosters trust in their capabilities.
Predictive Analytics
In the AI-powered technological world of today, predictive analytics have become a powerful tool for high-performing applications. The same holds for its role and support in large language models. The analytics can identify patterns and relationships that can be incorporated into improved fine-tuning of LLMs, generating more relevant outputs.
Here’s a crash course to deepen your understanding of predictive analytics!
Chain-Of-Thought Prompting
It refers to a specific type of few-shot prompting that breaks down a problem into sequential steps for the model to follow. It enables LLMs to handle increasingly complex tasks with improved accuracy. Thus, chain-of-thought prompting improves the quality of responses and provides a better understanding of how the model arrived at a particular answer.
Read more about the role of chain-of-thought and zero-shot prompting in LLMs here
Zero-Shot Prompting
Zero-shot prompting unlocks new skills for LLMs without extensive training. By providing clear instructions through prompts, even complex tasks become achievable, boosting LLM versatility and efficiency. This approach not only reduces training costs but also pushes the boundaries of LLM capabilities, allowing us to explore their potential for new applications.
While these terms pop up when we talk about optimizing LLM performance, let’s dig deeper into the process and talk about some key concepts and practices that support enhanced LLM results.
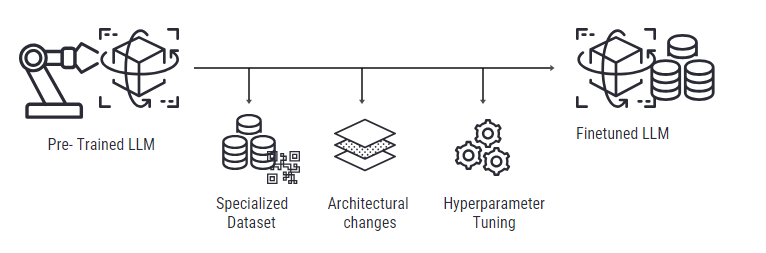
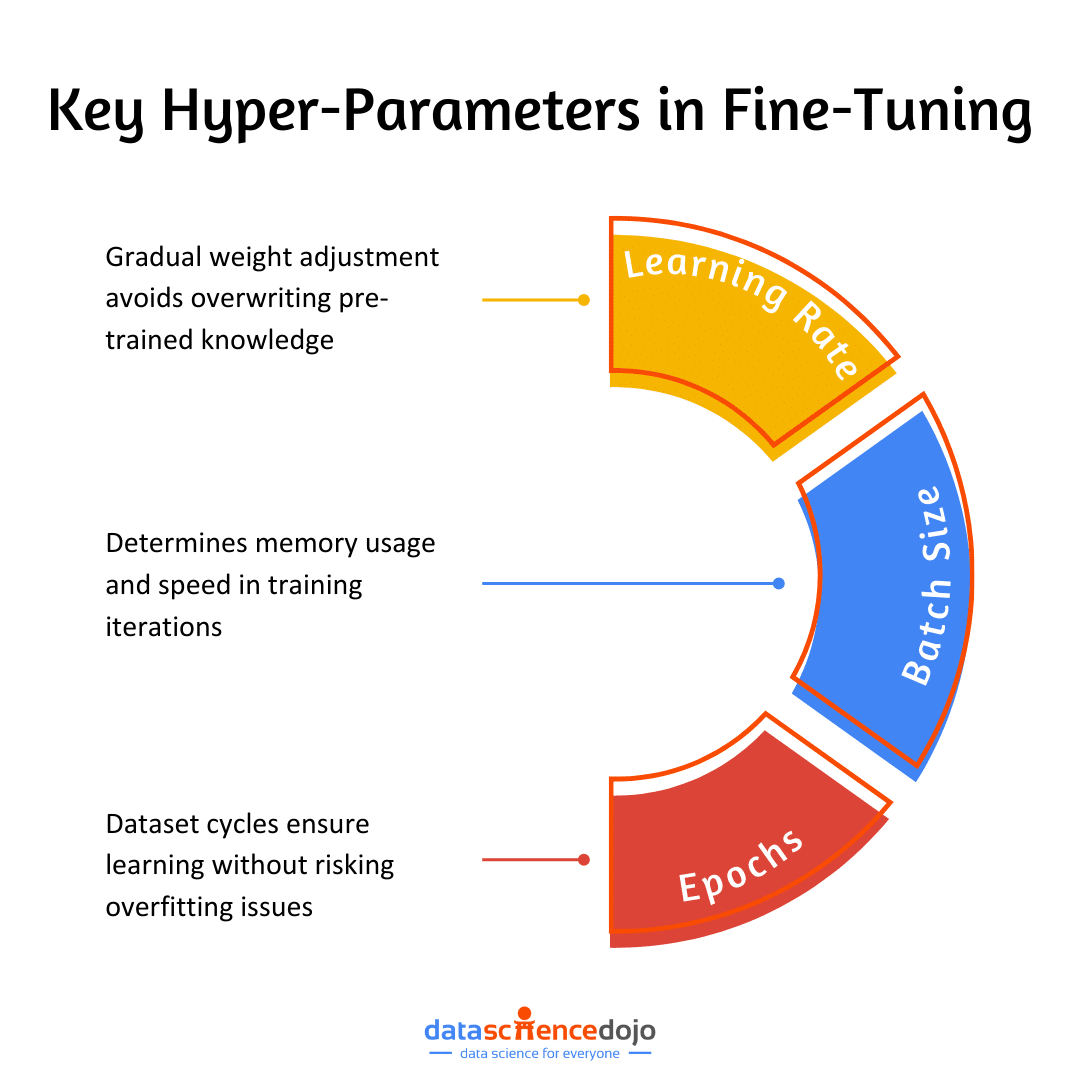
Fine-Tuning LLMs
It is a powerful technique that improves LLM performance on specific tasks. It involves training a pre-trained LLM using a focused dataset for a relevant task, providing the application with domain-specific knowledge. It ensures that the model output is refined for that particular context, making your LLM application an expert in that area.
Here is a detailed guide that explores the role, methods, and impact of fine-tuning LLMs. While this provides insights into ways of fine-tuning an LLM application, another approach includes tuning specific LLM parameters. It is a more targeted approach, including various parameters like the model size, temperature, context window, and much more.
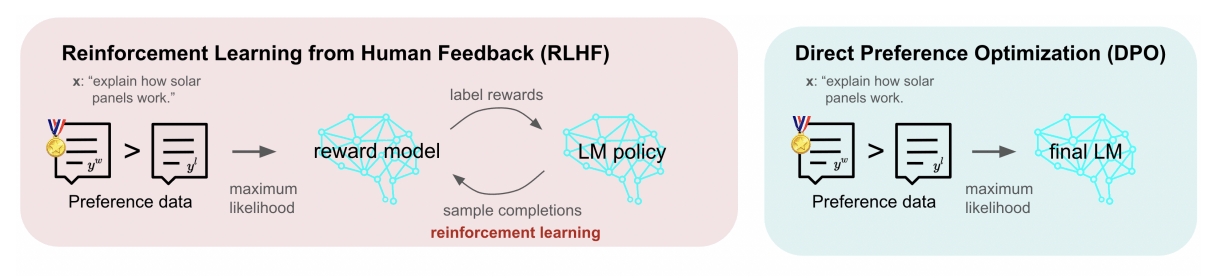
Moreover, among the many techniques of fine-tuning, Direct Preference Optimization (DPO) and Reinforcement Learning from Human Feedback (RLHF) are popular methods of performance enhancement. Here’s a quick glance at comparing the two ways for you to explore.
A comparative analysis of RLHF and DPO – Read more and in detail here
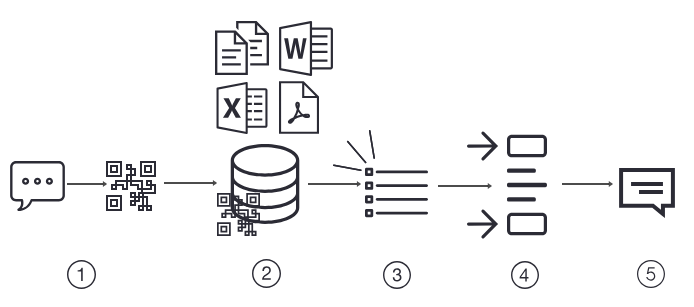
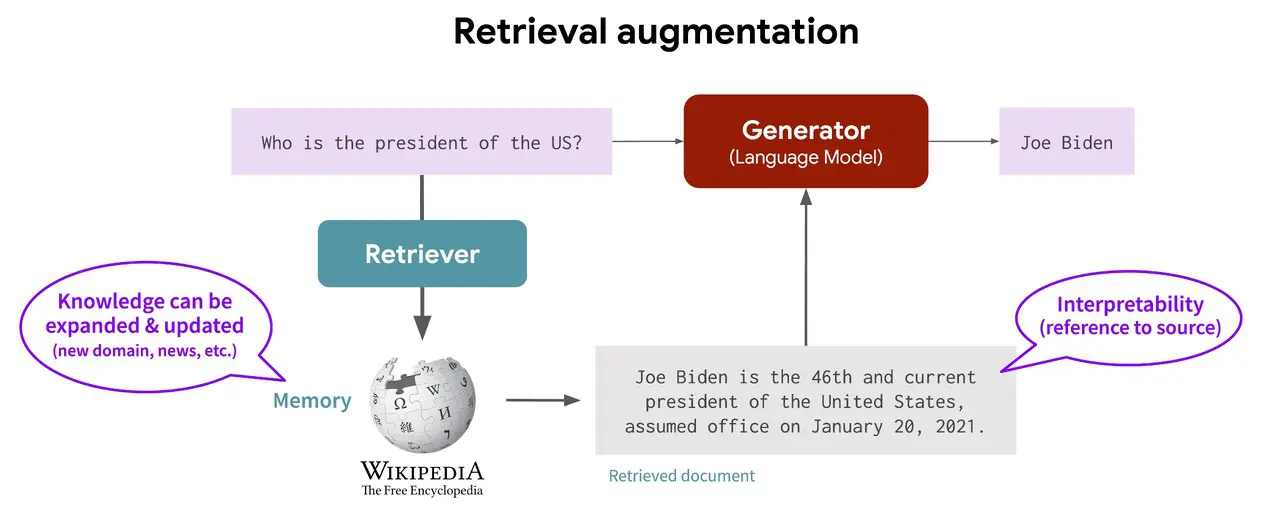
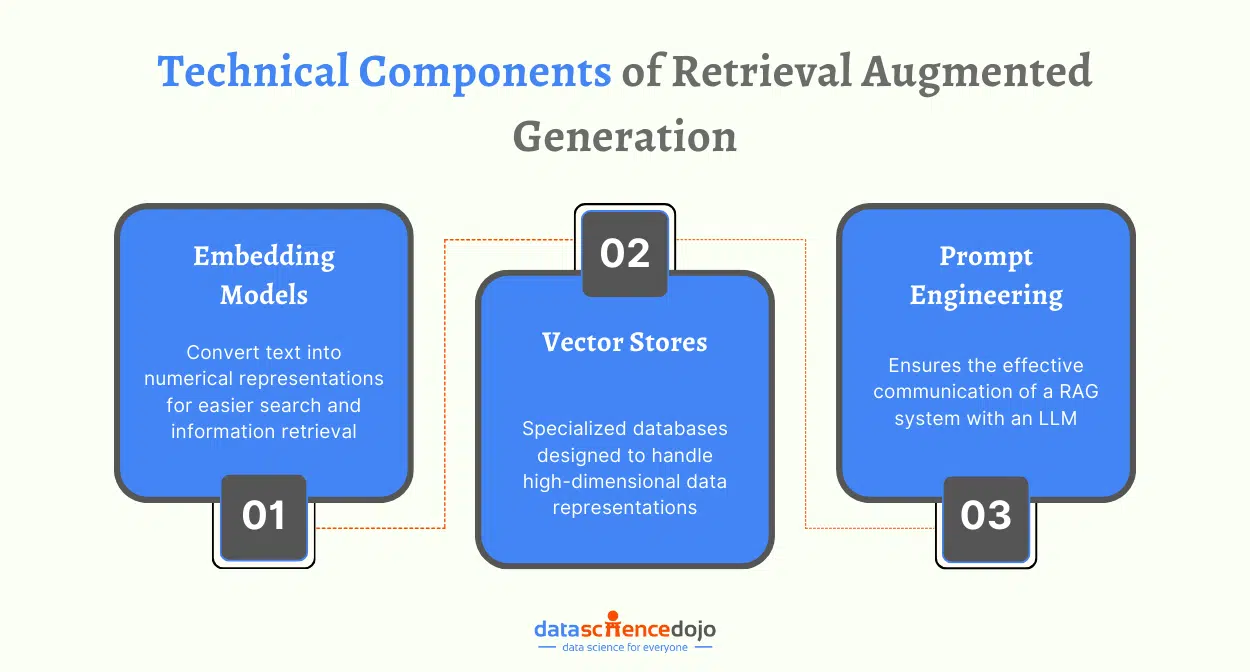
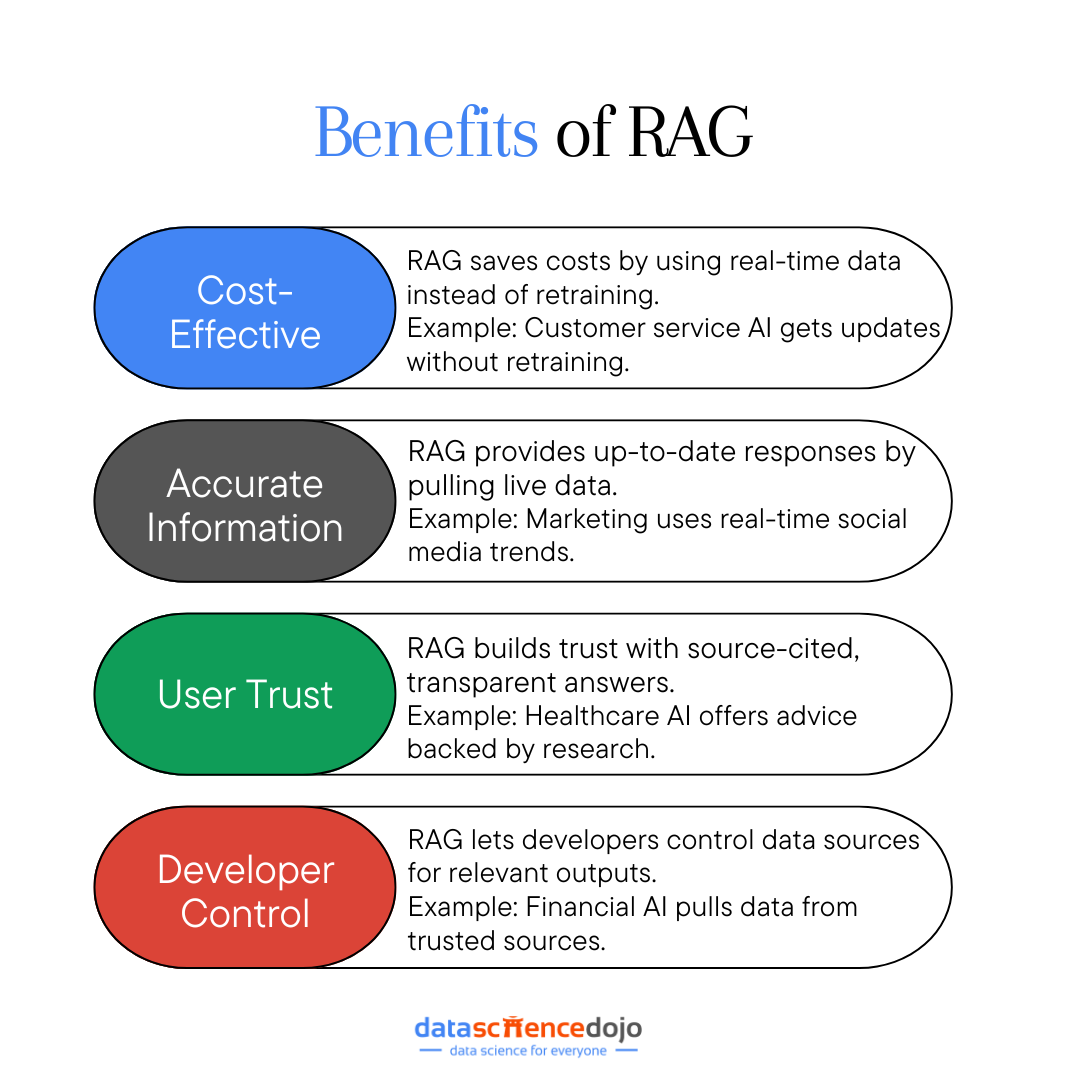
Retrieval Augmented Generation (RAG)
RAG or retrieval augmented generation is a LLM optimization technique that particularly addresses the issue of hallucinations in LLMs. An LLM application can generate hallucinated responses when prompted with information not present in their training set, despite being trained on extensive data.
The solution with RAG creates a bridge over this information gap, offering a more flexible approach to adapting to evolving information. Here’s a guide to assist you in implementing RAG to elevate your LLM experience.
A glance into the advanced RAG to elevate your LLM experience
Hence, with these two crucial approaches to enhance LLM performance, the question comes down to selecting the most appropriate one.
RAG and Fine-Tuning
Let me share two valuable resources that can help you answer the dilemma of choosing the right technique for LLM performance optimization.
The blog provides a detailed and in-depth exploration of the two techniques, explaining the workings of a RAG pipeline and the fine-tuning process. It also focuses on explaining the role of these two methods in advancing the capabilities of LLMs.
Once you are hooked by the importance and impact of both methods, delve into the findings of this article that navigates through the RAG vs fine-tuning dilemma. With a detailed comparison of the techniques, the blog takes it a step ahead and presents a hybrid approach for your consideration as well.
While building and optimizing are crucial steps in the journey of developing LLM applications, evaluating large language models is an equally important aspect.
Evaluating LLMs
Evaluation process to enhance LLM performance
It is the systematic process of assessing an LLM’s performance, reliability, and effectiveness across various tasks. Usually, through a series of tests to gauge its strengths, weaknesses, and suitability for different applications, we can evaluate LLM performance.
It ensures that a large language model application shows the desired functionality while highlighting its areas of strengths and weaknesses. It is an effective way to determine which LLMs are best suited for specific tasks.
Learn more about the simple and easy techniques for evaluating LLMs.
Performance Metrics – It includes accuracy, fluency, and coherence to assess the quality of the LLM’s outputs
Generalization – It explores how well the LLM performs on unseen data, not just the data it was trained on
Robustness – It involves testing the LLM’s resilience against adversarial attacks or output manipulation
Ethical Considerations – It considers potential biases or fairness issues within the LLM’s outputs
Explore the top LLM evaluation methods you can use when testing your LLM applications. A key part of the process also involves understanding the challenges and risks associated with large language models.
Like any other technological tool or development, LLMs also carry certain challenges and risks in their design and implementation. Some common issues associated with LLMs include hallucinations in responses, high toxic probabilities, bias and fairness, data security threats, and lack of accountability.
However, the problems associated with LLMs do not go unaddressed. The answer lies in the best practices you can take on when dealing with LLMs to mitigate the risks, and also in implementing the large language model operations (also known as LLMOps) process that puts special focus on addressing the associated challenges.
Hence, it is safe to say that as you start your LLM journey, you must navigate through various aspects and stages of development and operation to get a customized and efficient LLM application. The key to it all is to take the first step towards your goal – the rest falls into place gradually.
An overview of the 20 key technical terms to make you well-versed in the LLM jargon
A blog introducing you to the top 9 YouTube channels to learn about LLMs
A list of the top 10 YouTube videos to help you kickstart your exploration of LLMs
An article exploring the top 5 generative AI and LLM bootcamps
Bonus Addition!
If you are unsure about bootcamps – here are some insights into their importance. The hands-on approach and real-time learning might be just the push you need to take your LLM journey to the next level! And it’s not too time-consuming, you’d know the most about LLMs in as much as 40 hours!
As we conclude our LLM exploration journey, take the next step and learn to build customized LLM applications with fellow enthusiasts in the field. Check out our in-person large language models BootCamp and explore the pathway to deepen your understanding of LLMs!
Knowledge graphs and LLMs are the building blocks of the most recent advancements happening in the world of artificial intelligence (AI). Combining knowledge graphs (KGs) and LLMs produces a system that has access to a vast network of factual information and can understand complex language.
The system has the potential to use this accessibility to answer questions, generate textual outputs, and engage with other NLP tasks. This blog aims to explore the potential of integrating knowledge graphs and LLMs, navigating through the promise of revolutionizing AI.
Introducing Knowledge Graphs and LLMs
Before we understand the impact and methods of integrating KGs and LLMs, let’s visit the definition of the two concepts.
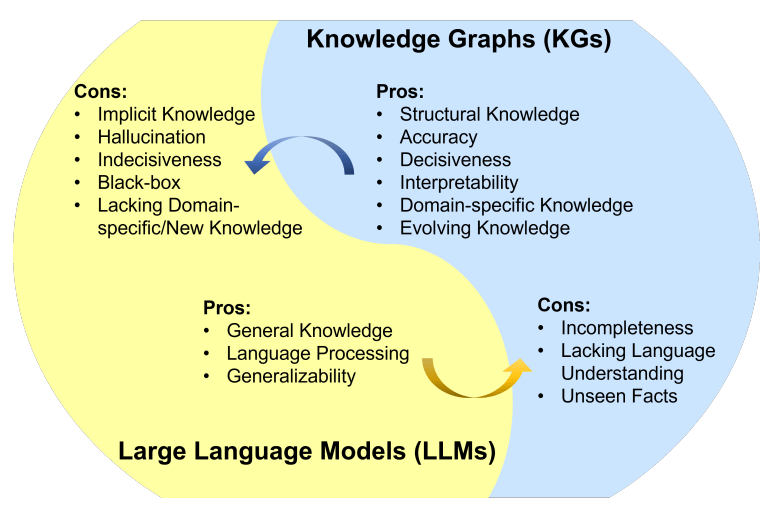
What are Knowledge Graphs (KGs)?
They are a visual web of information that focuses on connecting factual data in a meaningful manner. Each set of data is represented as a node with edges building connections between them. This representational storage of data allows a computer to recognize information and relationships between the data points.
KGs organize data to highlight connections and new relationships in a dataset. Moreover, it enabled improved search results as knowledge graphs integrate the contextual information to provide more relevant results.
What are Large Language Models (LLMs)?
LLMs are a powerful tool within the world of AI using deep learning techniques for general-purpose language generation and other natural language processing (NLP) tasks. They train on massive amounts of textual data to produce human-quality texts.
Large language models have revolutionized human-computer interactions with the potential for further advancements. However, LLMs are limited in the factual grounding of their results. It makes LLMs able to produce high-quality and grammatically accurate results that can be factually inaccurate.
An overview of knowledge graphs and LLMs – Source: arXiv
Combining KGs and LLMs
Within the world of AI and NLP, integrating the concepts of KGs and LLMs has the potential to open up new avenues of exploration. While knowledge graphs cannot understand language, they are good at storing factual data. Unlike KGs, LLMs excel in language understanding but lack factual grounding.
Combining the two entities brings forward a solution that addresses the weaknesses of both. The strengths of KGs and LLMs cover each concept’s limitations, enhancing both data processing and understanding capabilities. It leverages the strengths of LLMs in natural language understanding and the structured, interlinked data representation of knowledge graphs.
Some key impacts of this integration include:
Enhanced Information Retrieval
Integrating LLMs with knowledge graphs can significantly improve information retrieval systems. For instance, Google has been working on enhancing its search engine by combining LLMs like BERT with its extensive knowledge graph. This allows for a better understanding of search queries by considering the relationships and context provided by the knowledge graph, leading to more relevant and accurate search results.
Improved Conversational Agents
LLMs are already being used in virtual assistants like Siri and Alexa for natural language processing. By integrating these models with knowledge graphs, these agents can access structured data to provide more precise and contextually relevant responses.
Advanced Recommendation Systems
LLMs can interpret user preferences and sentiments from unstructured data, while knowledge graphs can map these preferences against a structured network of related items, offering more personalized and context-aware recommendations. It can be particularly useful for companies like Amazon and Netflix.
Scientific Research and Discovery
In fields like drug discovery, integrating LLMs with knowledge graphs can facilitate the exploration of existing research data and the generation of new hypotheses. For instance, IBM’s Watson has been used in healthcare to analyze vast amounts of medical literature. By combining its NLP capabilities with a knowledge graph of medical terms and relationships, researchers can uncover previously unknown connections between diseases and potential treatments.
While we understand the impact of this integration, let’s look at some proposed methods of combining these two key technological aspects.
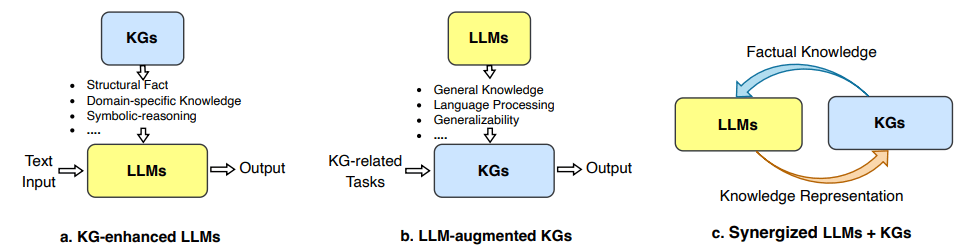
It is one thing to talk about combining knowledge graphs and large language models, implementing the idea requires planning and research. So far, researchers have explored three different frameworks aiming to integrate KGs and LLMs for enhanced outputs.
In this section, we will explore these three frameworks that are published as a paper in IEEE Transactions on Knowledge and Data Engineering.
Frameworks for integrating KGs and LLMs – Source: arXiv
KG-Enhanced LLMs
This framework focuses on using knowledge graphs to train LLMs. The factual knowledge and relationship links in the KGs become accessible to the LLMs in addition to the traditional textual data during the training phase. A LLM can then learn from the information available in KGs.
As a result, LLMs can get a boost in factual accuracy and grounding by incorporating the data from KGs. It will also enable the models to fact-check the outputs and produce more accurate and informative results.
LLM-Augmented KGs
This design shifts the structure of the first framework. Instead of KGs enhancing LLMs, they leverage the reasoning power of large language models to improve knowledge graphs. It makes LLMs smart assistants to improve the output of KGs, curating their information representation.
Moreover, this framework can leverage LLMs to find problems and inconsistencies in information connections of KGs. The high reasoning of LLMs also enables them to infer new relationships in a knowledge graph, enriching its outputs.
This builds a pathway to create more comprehensive and reliable knowledge graphs, benefiting from the reasoning and inference abilities of LLMs.
This framework proposes a mutually beneficial relationship between the two AI components. Each entity works to improve the other through a feedback loop. It is designed in the form of a continuous learning cycle between LLMs and KGs.
It can be viewed as a concept that combines the two above-mentioned frameworks into a single design where knowledge graphs enhance language model outputs and LLMs analyze and improve KGs.
It results in a dynamic cycle where KGs and LLMs constantly improve each other. The iterative design of this integration framework leads to a more powerful and intelligent system overall.
While we have looked at the three different frameworks of integration of KGs and LLMs, the synergized LLMs + KGs is the most advanced approach in this field. It promises to unlock the full potential of both entities, supporting the creation of superior AI systems with enhanced reasoning, knowledge representation, and text generation capabilities.
Future of LLM and KG Integration
The combination of Large Language Models (LLMs) and knowledge graphs is paving the way for an AI landscape that’s smarter and more capable than ever before. By merging the adaptability and creativity of language models with the precision and dependability of structured data, this integration is opening up a world of new possibilities across various sectors.
Imagine real-time decision-making, ethical AI solutions, and highly personalized user experiences—all made possible by this powerful synergy. Whether in healthcare, education, or finance, the applications are not only exciting but also transformative.
As this blend continues to develop, we are on the brink of achieving AI that is not just powerful but also transparent, reliable, and focused on human needs. The future of AI innovation is unfolding right before us, driven by the harmonious collaboration of LLMs and knowledge graphs.
Natural language processing (NLP) and large language models (LLMs) have been revolutionized with the introduction of transformer models. These refer to a type of neural network architecture that excels at tasks involving sequences.
While we have talked about the details of a typical transformer architecture, in this blog we will explore the different types of the models.
How to Categorize Transformer Models?
Transformers ensure the efficiency of LLMs in processing information. Their role is critical to ensure improved accuracy, faster training on data, and wider applicability. Hence, it is important to understand the different model types available to choose the right one for your needs.
However, before we delve into the many types of transformer models, it is important to understand the basis of their classification.
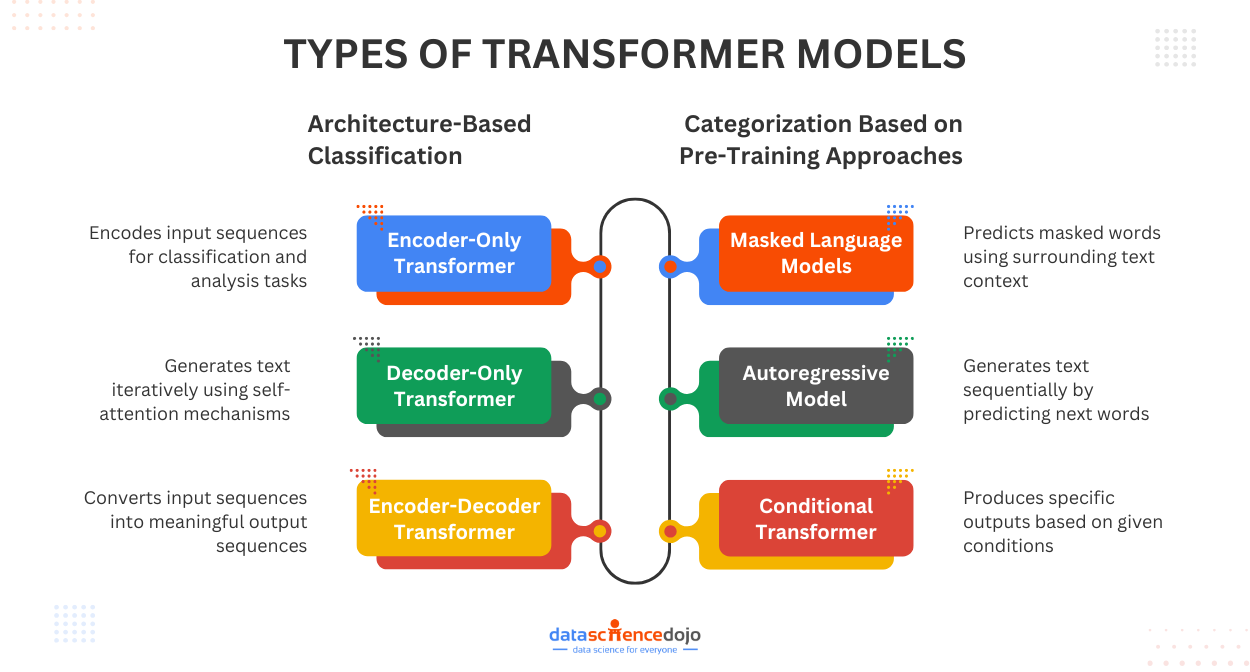
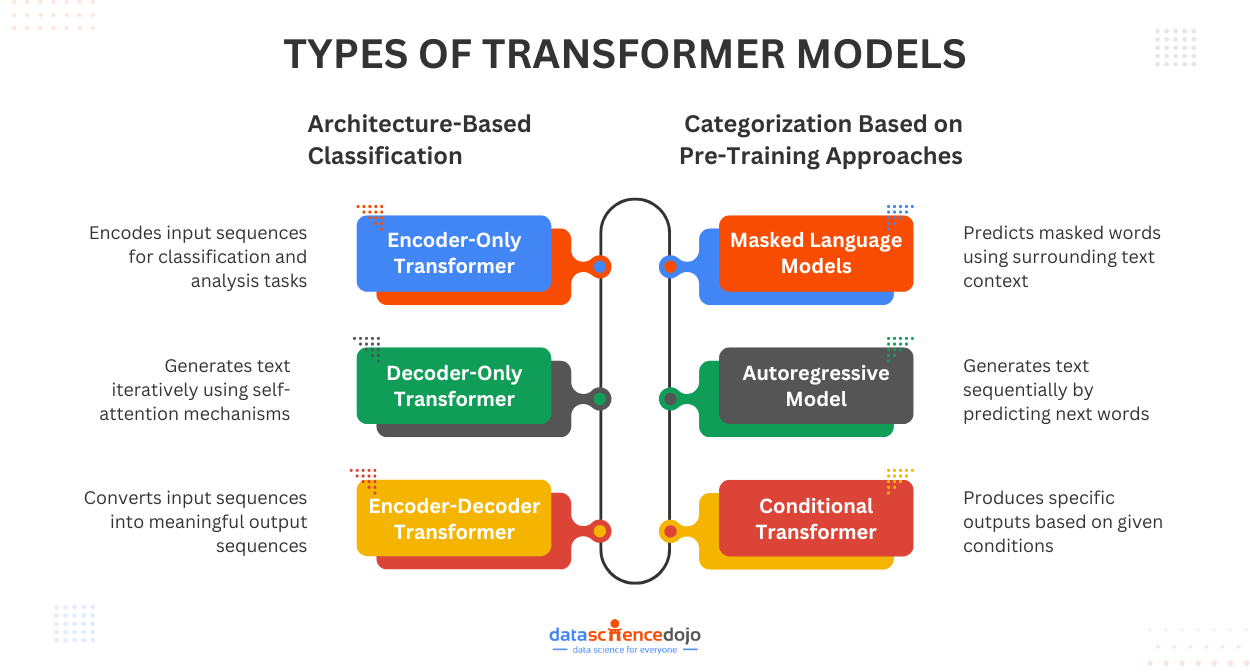
Classification by Transformer Architecture
The most fundamental categorization of transformer models is done based on their architecture. The variations are designed to perform specific tasks or cater to the limitations of the base architecture. The very common model types under this category include:
encoder-only
decoder-only
encoder-decoder transformers
Categorization Based on Pre-Training Approaches
While architecture is a basic component of consideration, the training techniques are equally crucial components for transformers. Pre-training approaches refer to the techniques used to train a transformer on a general dataset before finetuning it to perform specific tasks.
Some common approaches that define classification under this category include:
Masked Language Models (MLMs)
autoregressive models
conditional transformers
This presents a general outlook on classifying transformer models. While we now know the types present under the broader categories, let’s dig deeper into each transformer model type.
As the name suggests, this architectural type uses only the encoder part of the transformer, focusing on encoding the input sequence. For this model type, understanding the input sequence is crucial while generating an output sequence is not required.
Some common applications of an encoder-only transformer include:
Text Classification: It is focused on classifying the input data based on defined parameters. It is often used in email spam filters to categorize incoming emails. The transformer model can also train over the patterns for effective filtration of unwanted messages.
Sentimental Analysis: This feature makes it an appropriate choice for social media companies to analyze customer feedback and their emotion toward a service or product. It provides useful data insights, leading to the creation of effective strategies to enhance customer satisfaction.
Anomaly Detection: It is particularly useful for finance companies. The analysis of financial transactions allows the timely detection of anomalies. Hence, possible fraudulent activities can be addressed promptly.
Other uses of an encoder-only transformer include question-answering, speech recognition, and image captioning.
2. Decoder-Only Transformer
It is a less common type of transformer model that uses only the decoder component to generate text sequences based on input prompts. The self-attention mechanism allows the model to focus on previously generated outputs in the sequence, enabling it to refine the output and create more contextually aware results.
Some common uses of decoder-only transformers include:
Text Summarization: It can iteratively generate textual summaries of the input, focusing on including the important aspects of information.
Text Generation: It builds on a provided prompt to generate relevant textual outputs. The results cover a diverse range of content types, like poems, codes, and snippets. It is capable of iterating the process to create connected and improved responses.
Chatbots: It is useful to handle conversational interactions via chatbots. The decoder can also consider previous conversations to formulate relevant responses.
This is a classic architectural type of transformer, efficiently handling sequence-to-sequence tasks, where you need to transform one type of sequence (like text) into another (like a translation or summary). An encoder processes the input sequence while a decoder is used to generate an output sequence.
Some common uses of an encoder-decoder transformer include:
Machine Translation: Since the sequence is important at both the input and output, it makes this transformer model a useful tool for translation. It also considers contextual references and relationships between words in both languages.
Text Summarization: While this use overlaps with that of a decoder-only transformer, text summarization differs from an encoder-decoder transformer due to its focus on the input sequence. It enables the creation of summaries that focus on relevant aspects of the text highlighted in an input prompt.
Question-Answering: It is important to understand the question before providing a relevant answer. An encoder-decoder transformer allows this focus on both ends of the communication, ensuring each question is understood and answered appropriately.
This concludes our exploration of architecture-based transformer models. Let’s explore the classification from the lens of pre-training approaches.
Categorization Based on Pre-Training Approaches
While the architectural differences provide a basis for transformer types, the models can be further classified based on their techniques of pre-training.
Let’s explore the various transformer models segregated based on pre-training approaches.
1. Masked Language Models (MLMs)
Models with this pre-training approach are usually encoder-only in architecture. They are trained to predict a masked word in a sentence based on the contextual information of the surrounding words. The training enables these model types to become efficient in understanding language relationships.
Some common MLM applications are:
Boosting Downstream NLP Tasks: MLMs train on massive datasets, enabling the models to develop a strong understanding of language context and relationships between words. This knowledge enables MLM models to contribute and excel in diverse NLP applications.
General-Purpose NLP Tool: The enhanced learning, knowledge, and adaptability of MLMs make them a part of multiple NLP applications. Developers leverage this versatility of pre-trained MLMs to build a basis for different NLP tools.
Efficient NLP Development: The pre-trained foundation of MLMs reduces the time and resources needed for the deployment of NLP applications. It promotes innovation, faster development, and efficiency.
2. Autoregressive Models
Typically built using a decoder-only architecture, this pre-training model is used to generate sequences iteratively. It can predict the next word based on the previous one in the text you have written. Some common uses of autoregressive models include:
Text Generation: The iterative prediction from the model enables it to generate different text formats. From codes and poems to musical pieces, it can create all while iteratively refining the output as well.
Chatbots: The model can also be utilized in a conversational environment, creating engaging and contextually relevant responses,
Machine Translation: While encoder-decoder models are commonly used for translation tasks, some languages with complex grammatical structures are supported by autoregressive models.
This transformer model incorporates the additional information of a condition along with the main input sequence. It enables the model to generate highly specific outputs based on particular conditions, ensuring more personalized results.
Some uses of conditional transformers include:
Machine Translation with Adaptation: The conditional aspect enables the model to set the target language as a condition. It ensures better adjustment of the model to the target language’s style and characteristics.
Summarization with Constraints: Additional information allows the model to generate summaries of textual inputs based on particular conditions.
Speech Recognition with Constraints: With the consideration of additional factors like speaker ID or background noise, the recognition process enhances to produce improved results.
Future of Transformer Model Types
While numerous transformer model variations are available, the ongoing research promises their further exploration and growth. Some major points of further development will focus on efficiency, specialization for various tasks, and integration of transformers with other AI techniques.
Transformers can also play a crucial role in the field of human-computer interaction with their enhanced capabilities. The growth of transformers will definitely impact the future of AI. However, it is important to understand the uses of each variation of a transformer model before you choose the one that fits your requirements.
In the dynamic field of artificial intelligence, Large Language Models (LLMs) are groundbreaking innovations shaping how we interact with digital environments. These sophisticated models, trained on vast collections of text, have the extraordinary ability to comprehend and generate text that mirrors human language, powering a variety of applications from virtual assistants to automated content creation.
The essence of LLMs lies not only in their initial training but significantly in fine-tuning, a crucial step to refine these models for specialized tasks and ensure their outputs align with human expectations.
Introduction to Finetuning
Finetuning LLMs involves adjusting pre-trained models to perform specific functions more effectively, enhancing their utility across different applications. This process is essential because, despite the broad knowledge base acquired through initial training, LLMs often require customization to excel in particular domains or tasks.
For instance, a model trained on a general dataset might need fine-tuning to understand the nuances of medical language or legal jargon, making it more relevant and effective in those contexts.
Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO) are two leading methodologies for finetuning LLMs. RLHF utilizes a sophisticated feedback loop, incorporating human evaluations and a reward model to guide the AI’s learning process.
On the other hand, DPO adopts a more straightforward approach, directly applying human preferences to influence the model’s adjustments. Both strategies aim to enhance model performance and ensure the outputs are in tune with user needs, yet they operate on distinct principles and methodologies.
This blog post aims to unfold the layers of RLHF and DPO, drawing a comparative analysis to elucidate their mechanisms, strengths, and optimal use cases.
Understanding these fine-tuning methods paves the path to deploying LLMs that not only boast high performance but also resonate deeply with human intent and preferences, marking a significant step towards achieving more intuitive and effective AI-driven solutions.
Examples of How Finetuning Improves Performance in Practical Applications
Customer Service Chatbots: Fine-tuning an LLM on customer service transcripts can enhance its ability to understand and respond to user queries accurately, improving customer satisfaction.
Legal Document Analysis: By fine-tuning legal texts, LLMs can become adept at navigating complex legal language, aiding in tasks like contract review or legal research.
Medical Diagnosis Support: LLMs fine-tuned with medical data can assist healthcare professionals by providing more accurate information retrieval and patient interaction, thus enhancing diagnostic processes.
Explore Reinforcement Learning from Human Feedback (RLHF)
Explanation of RLHF and its Components
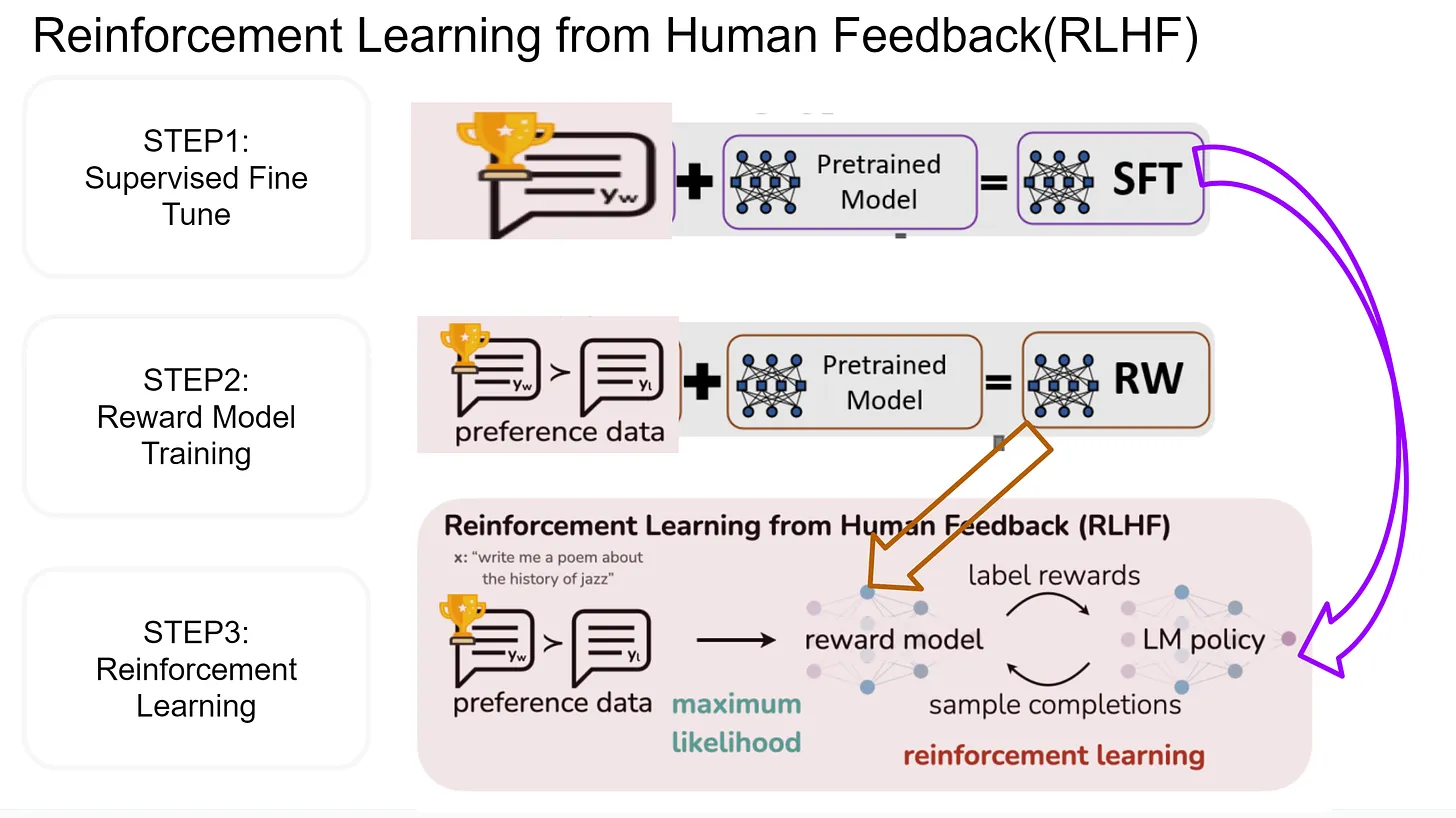
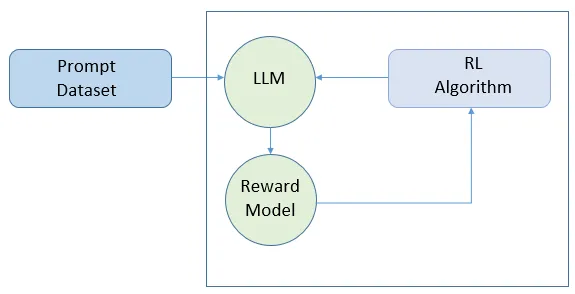
Reinforcement Learning from Human Feedback (RLHF) is a technique used to fine-tune AI models, particularly language models, to enhance their performance based on human feedback.
The core components of RLHF include the fine-tuned language model, the reward model that evaluates the language model’s outputs, and the human feedback that informs the reward model. This process ensures that the language model produces outputs that are more aligned with human preferences.
RLHF is grounded in reinforcement learning, where the model learns from actions rather than from a static dataset.
Unlike supervised learning, where models learn from labeled data, or unsupervised learning, where models identify patterns in data, reinforcement learning models learn from the consequences of their actions, guided by rewards. In RLHF, the “reward” is determined by human feedback, which signifies the model’s success in generating desirable outputs.
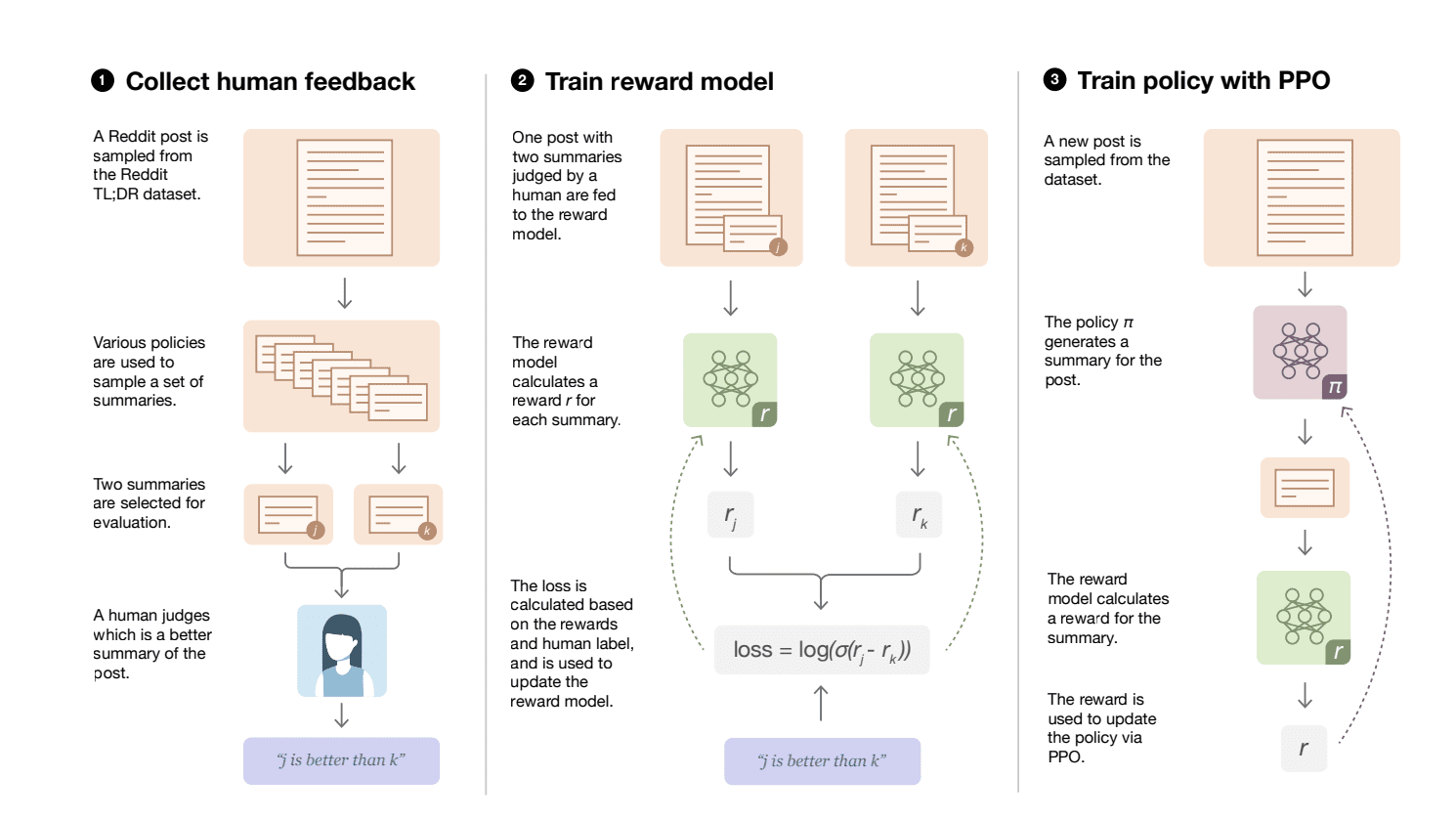
The RLHF process – Source: AI Changes Everything
Four-Step Process of RLHF
1. Pretraining the Language Model with Self-Supervision
Data Gathering: The process begins by collecting a vast and diverse dataset, typically encompassing a wide range of topics, languages, and writing styles. This dataset serves as the initial training ground for the language model.
Self-Supervised Learning: Using this dataset, the model undergoes self-supervised learning. Here, the model is trained to predict parts of the text given other parts. For instance, it might predict the next word in a sentence based on the previous words. This phase helps the model grasp the basics of language, including grammar, syntax, and some level of contextual understanding.
Foundation Building: The outcome of this stage is a foundational model that has a general understanding of language. It can generate text and understand some context but lacks specialization or fine-tuning for specific tasks or preferences.
2. Ranking Model’s Outputs Based on Human Feedback
Generation and Evaluation: Once pretraining is complete, the model starts generating text outputs, which are then evaluated by humans. This could involve tasks like completing sentences, answering questions, or engaging in dialogue.
Scoring System: Human evaluators use a scoring system to rate each output. They consider factors like how relevant, coherent, or engaging the text is. This feedback is crucial as it introduces the model to human preferences and standards.
Adjustment for Bias and Diversity: Care is taken to ensure the diversity of evaluators and mitigate biases in feedback. This helps in creating a balanced and fair assessment criterion for the model’s outputs.
Modeling Human Judgment: The scores and feedback from human evaluators are then used to train a separate model, known as the reward model. This model aims to understand and predict the scores human evaluators would give to any piece of text generated by the language model.
Feedback Loop: The reward model effectively creates a feedback loop. It learns to distinguish between high-quality and low-quality outputs based on human ratings, encapsulating the criteria humans use to judge the text.
Iteration for Improvement: This step might involve several iterations of feedback collection and reward model adjustment to accurately capture human preferences.
4. Finetuning the Language Model Using Feedback from the Reward Model
Integration of Feedback: The insights gained from the reward model are used to fine-tune the language model. This involves adjusting the model’s parameters to increase the likelihood of generating text that aligns with the rewarded behaviors.
Reinforcement Learning Techniques: Techniques such as Proximal Policy Optimization (PPO) are employed to methodically adjust the model. The model is encouraged to “explore” different ways of generating text but is “rewarded” more when it produces outputs that are likely to receive higher scores from the reward model.
Continuous Improvement: This fine-tuning process is iterative and can be repeated with new sets of human feedback and reward model adjustments, continuously improving the language model’s alignment with human preferences.
The iterative process of RLHF allows for continuous improvement of the language model’s outputs. Through repeated cycles of feedback and adjustment, the model refines its approach to generating text, becoming better at producing outputs that meet human standards of quality and relevance.
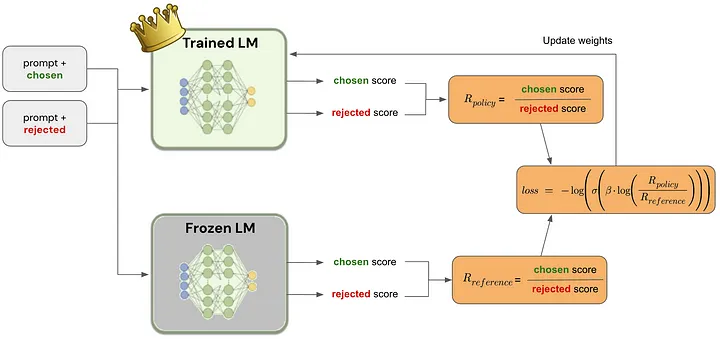
Using a reward model for finetuning LLMs – Source: nownextlater.ai
Exploring Direct Preference Optimization (DPO)
Concept of DPO as a Direct Approach
Direct Preference Optimization (DPO) represents a streamlined method for fine-tuning large language models (LLMs) by directly incorporating human preferences into the training process.
This technique simplifies the adaptation of AI systems to better meet user needs, bypassing the complexities associated with constructing and utilizing reward models.
Theoretical Foundations of DPO
DPO is predicated on the principle that direct human feedback can effectively guide the development of AI behavior.
By directly using human preferences as a training signal, DPO simplifies the alignment process, framing it as a direct learning task. This method proves to be both efficient and effective, offering advantages over traditional reinforcement learning approaches like RLHF.
Finetuning LLMs using DPO – Source: Medium
Steps Involved in the DPO process
1. Training the Language Model through Self-Supervision
Data Preparation: The model starts with self-supervised learning, where it is exposed to a wide array of text data. This could include everything from books and articles to websites, encompassing a variety of topics, styles, and contexts.
Learning Mechanism: During this phase, the model learns to predict text sequences, essentially filling in blanks or predicting subsequent words based on the preceding context. This method helps the model grasp the fundamentals of language structure, syntax, and semantics without explicit task-oriented instructions.
Outcome: The result is a baseline language model capable of understanding and generating coherent text, ready for further specialization based on specific human preferences.
2. Collecting Pairs of Examples and Obtaining Human Ratings
Generation of Comparative Outputs: The model generates pairs of text outputs, which might vary in tone, style, or content focus. These pairs are then presented to human evaluators in a comparative format, asking which of the two better meets certain criteria such as clarity, relevance, or engagement.
Human Interaction: Evaluators provide their preferences, which are recorded as direct feedback. This step is crucial for capturing nuanced human judgments that might not be apparent from purely quantitative data.
Feedback Incorporation: The preferences gathered from this comparison form the foundational data for the next phase of optimization. This approach ensures that the model’s tuning is directly influenced by human evaluations, making it more aligned with actual user expectations and preferences.
3. Training the Model Using a Cross-Entropy-Based Loss Function
Optimization Technique: Armed with pairs of examples and corresponding human preferences, the model undergoes fine-tuning using a binary cross-entropy loss function. This statistical method compares the model’s output against the preferred outcomes, quantifying how well the model’s predictions match the chosen preferences.
Adjustment Process: The model’s parameters are adjusted to minimize the loss function, effectively making the preferred outputs more likely in future generations. This process iteratively improves the model’s alignment with human preferences, refining its ability to generate text that resonates with users.
4. Constraining the Model to Maintain its Generativity
Balancing Act: While the model is being fine-tuned to align closely with human preferences, it’s vital to ensure that it doesn’t lose its generative diversity. The process involves carefully adjusting the model to incorporate feedback without overfitting specific examples or restricting its creative capacity.
Ensuring Flexibility: Techniques and safeguards are put in place to ensure the model remains capable of generating a wide range of responses. This includes regular evaluations of the model’s output diversity and implementing mechanisms to prevent the narrowing of its generative abilities.
Outcome: The final model retains its ability to produce varied and innovative text while being significantly more aligned with human preferences, demonstrating an enhanced capability to engage users in a meaningful way.
DPO eliminates the need for a separate reward model by treating the language model’s adjustment as a direct optimization problem based on human feedback. This simplification reduces the layers of complexity typically involved in model training, making the process more efficient and directly focused on aligning AI outputs with user preferences.
Comparative Analysis: RLHF vs. DPO
After exploring both Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO), we’re now at a point where we can compare these two key methods used to fine-tune Large Language Models (LLMs).
This side-by-side look aims to clarify the differences and help decide which method might be better for certain situations.
Direct Comparison
Training Efficiency
RLHF involves several steps, including pre-training, collecting feedback, training a reward model, and then fine-tuning. This process is detailed and requires a lot of computer power and setup time. On the other hand, DPO is simpler and more straightforward because it optimizes the model directly based on what people prefer, often leading to quicker results.
Data Requirements
RLHF uses a variety of feedback, such as scores or written comments, which means it needs a wide range of input to train well. DPO, however, focuses on comparing pairs of options to see which one people like more, making it easier to collect the needed data.
Model Performance
RLHF is very flexible and can be fine-tuned to perform well in complex situations by understanding detailed feedback. DPO is great for making quick adjustments to align with what users want, although it might not handle varied feedback as well as RLHF.
Scalability
RLHF’s detailed process can make it hard to scale up due to its high computer resource needs. DPO’s simpler approach means it can be scaled more easily, which is particularly beneficial for projects with limited resources.
Pros and Cons
Advantages of RLHF: Its ability to work with many kinds of feedback gives RLHF an edge in tasks that need detailed customization. This makes it well-suited for projects that require a deep understanding and nuanced adjustments.
Disadvantages of RLHF: The main drawback is its complexity and the need for a reward model, which makes it more demanding in terms of computational resources and setup. Also, the quality and variety of feedback can significantly influence how well the fine-tuning works.
Advantages of DPO: DPO’s more straightforward process means faster adjustments and less demand on computational resources. It integrates human preferences directly, leading to a tight alignment with what users expect.
Disadvantages of DPO: The main issue with DPO is that it might not do as well with tasks needing more nuanced feedback, as it relies on binary choices. Also, gathering a large amount of human-annotated data might be challenging.
Comparing the RLHF and DPO – Source: arxiv.org
Scenarios of Application
Ideal Use Cases for RLHF: RLHF excels in scenarios requiring customized outputs, like developing chatbots or systems that need to understand the context deeply. Its ability to process complex feedback makes it highly effective for these uses.
Ideal Use Cases for DPO: When you need quick AI model adjustments and have limited computational resources, DPO is the way to go. It’s especially useful for tasks like adjusting sentiments in text or decisions that boil down to yes/no choices, where its direct approach to optimization can be fully utilized.
Summarizing Key Insights and Applications
As we wrap up our journey through the comparative analysis of Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO) for fine-tuning Large Language Models (LLMs), a few key insights stand out.
Both methods offer unique advantages and cater to different needs in the realm of AI development. Here’s a recap and some guidance on choosing the right approach for your project.
Recap of Fundamental Takeaways
RLHF is a detailed, multi-step process that provides deep customization potential through the use of a reward model. It’s particularly suited for complex tasks where nuanced feedback is crucial.
DPO simplifies the fine-tuning process by directly applying human preferences, offering a quicker and less resource-intensive path to model optimization.
Explore LLM optimization further with the use of vector databases
Choosing the Right Finetuning Method
The decision between RLHF and DPO should be guided by several factors:
Task Complexity: If your project involves complex interactions or requires understanding nuanced human feedback, RLHF might be the better choice. For more straightforward tasks or when quick adjustments are needed, DPO could be more effective.
Available Resources: Consider your computational resources and the availability of human annotators. DPO is generally less demanding in terms of computational power and can be more straightforward in gathering the necessary data.
Desired Control Level: RLHF offers more granular control over the fine-tuning process, while DPO provides a direct route to aligning model outputs with user preferences. Evaluate how much control and precision you need in the fine-tuning process.
The Future of Finetuning LLMs
Looking ahead, the field of LLM fine-tuning is ripe for innovation. We can anticipate advancements that further streamline these processes, reduce computational demands, and enhance the ability to capture and apply complex human feedback.
Additionally, the integration of AI ethics into fine-tuning methods is becoming increasingly important, ensuring that models not only perform well but also operate fairly and without bias. As we continue to push the boundaries of what AI can achieve, the evolution of fine-tuning methods like RLHF and DPO will play a crucial role in making AI more adaptable, efficient, and aligned with human values.
By carefully considering the specific needs of each project and staying informed about advancements in the field, developers can leverage these powerful tools to create AI systems that are not only technologically advanced but also deeply attuned to the complexities of human communication and preferences.
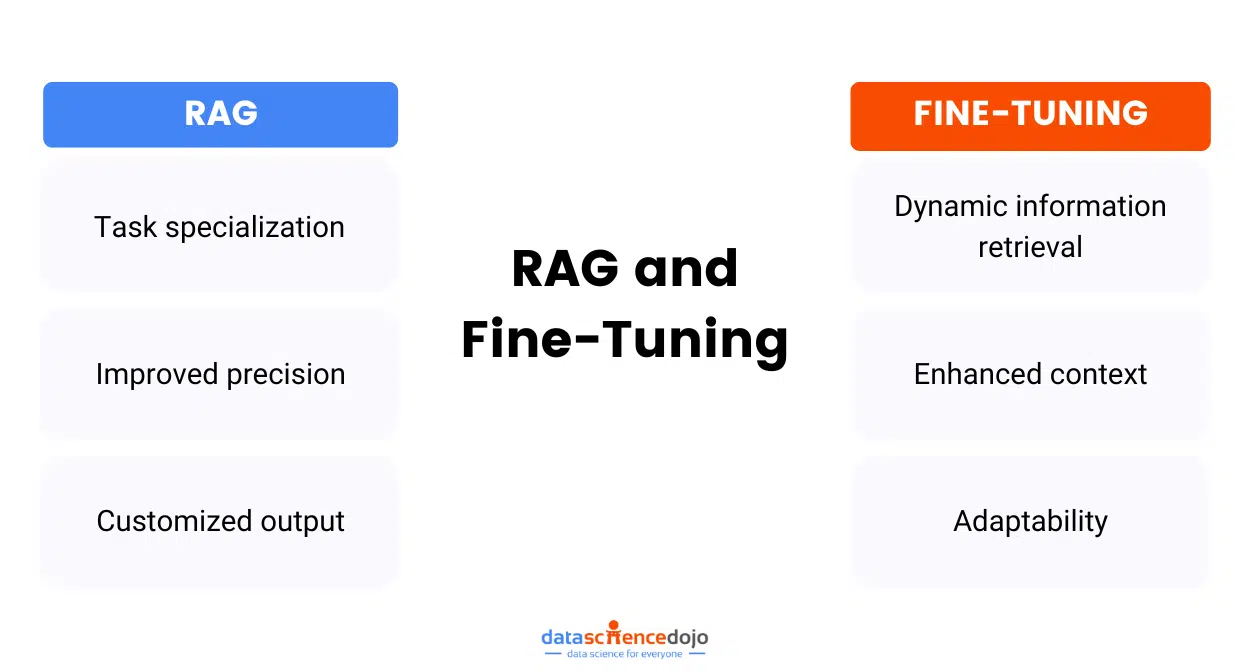
While we provided a detailed guideline on understanding RAG and finetuning, a comparative analysis of the two provides a deeper insight. Let’s explore and address the RAG vs finetuning debate to determine the best tool to optimize LLM performance.
RAG vs Finetuning LLM – A Detailed Comparison
It’s crucial to grasp that these methodologies while targeting the enhancement of large language models (LLMs), operate under distinct paradigms. Recognizing their strengths and limitations is essential for effectively leveraging them in various AI applications.
This understanding allows developers and researchers to make informed decisions about which technique to employ based on the specific needs of their projects. Whether it’s adapting to dynamic information, customizing linguistic styles, managing data requirements, or ensuring domain-specific performance, each approach has its unique advantages.
By comprehensively understanding these differences, you’ll be equipped to choose the most suitable method—or a blend of both—to achieve your objectives in developing sophisticated, responsive, and accurate AI models.
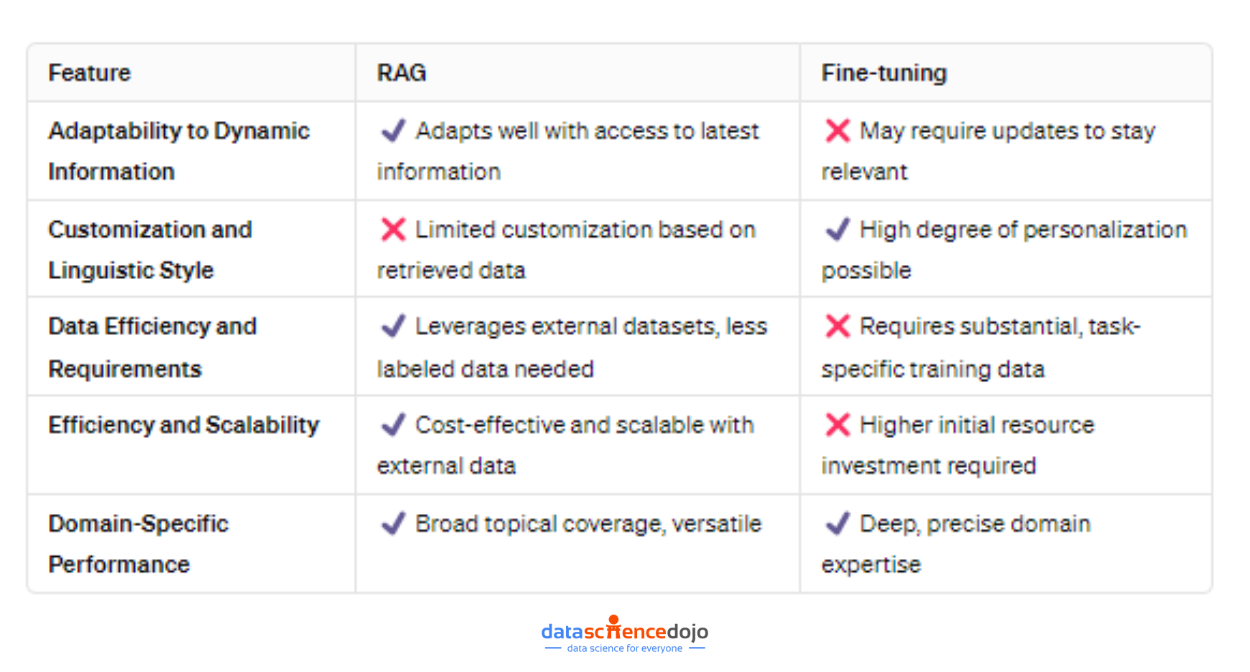
Summarizing the RAG vs finetuning comparison
Team RAG or team Fine-Tuning? Tune in to this podcast now to find out their specific benefits, trade-offs, use cases, enterprise adoption, and more!
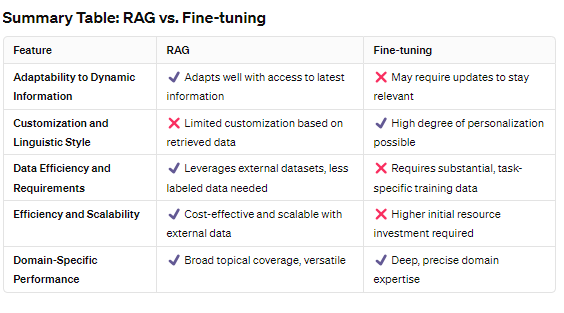
Adaptability to Dynamic Information
RAG shines in environments where information is constantly updated. By design, RAG leverages external data sources to fetch the latest information, making it inherently adaptable to changes.
This quality ensures that responses generated by RAG-powered models remain accurate and relevant, a crucial advantage for applications like real-time news summarization or updating factual content.
Fine-tuning, in contrast, optimizes a model’s performance for specific tasks through targeted training on a curated dataset.
While it significantly enhances the model’s expertise in the chosen domain, its adaptability to new or evolving information is constrained. The model’s knowledge remains as current as its last training session, necessitating regular updates to maintain accuracy in rapidly changing fields.
RAG‘s primary focus is on enriching responses with accurate, up-to-date information retrieved from external databases.
This process, though excellent for fact-based accuracy, means RAG models might not tailor their linguistic style as closely to specific user preferences or nuanced domain-specific terminologies without integrating additional customization techniques.
Fine-tuning excels in personalizing the model to a high degree, allowing it to mimic specific linguistic styles, adhere to unique domain terminologies, and align with particular content tones.
This is achieved by training the model on a dataset meticulously prepared to reflect the desired characteristics, enabling the fine-tuned model to produce outputs that closely match the specified requirements.
Data Efficiency and Requirements
RAG operates by leveraging external datasets for retrieval, thus requiring a sophisticated setup to manage and query these vast data repositories efficiently.
The model’s effectiveness is directly tied to the quality and breadth of its connected databases, demanding rigorous data management but not necessarily a large volume of labeled training data.
Fine-tuning, however, depends on a substantial, well-curated dataset specific to the task at hand.
It requires less external data infrastructure compared to RAG but relies heavily on the availability of high-quality, domain-specific training data. This makes fine-tuning particularly effective in scenarios where detailed, task-specific performance is paramount and suitable training data is accessible.
Efficiency and Scalability
RAG is generally considered cost-effective and efficient for a wide range of applications, particularly because it can dynamically access and utilize information from external sources without the need for continuous retraining.
This efficiency makes RAG a scalable solution for applications requiring access to the latest information or coverage across diverse topics.
Fine-tuning demands a significant investment in time and resources for the initial training phase, especially in preparing the domain-specific dataset and computational costs.
However, once fine-tuned, the model can operate with high efficiency within its specialized domain. The scalability of fine-tuning is more nuanced, as extending the model’s expertise to new domains requires additional rounds of fine-tuning with respective datasets.
RAG demonstrates exceptional versatility in handling queries across a wide range of domains by fetching relevant information from its external databases.
Its performance is notably robust in scenarios where access to wide-ranging or continuously updated information is critical for generating accurate responses.
Fine-tuning is the go-to approach for achieving unparalleled depth and precision within a specific domain.
By intensively training the model on targeted datasets, fine-tuning ensures the model’s outputs are not only accurate but deeply aligned with the domain’s subtleties, making it ideal for specialized applications requiring high expertise.
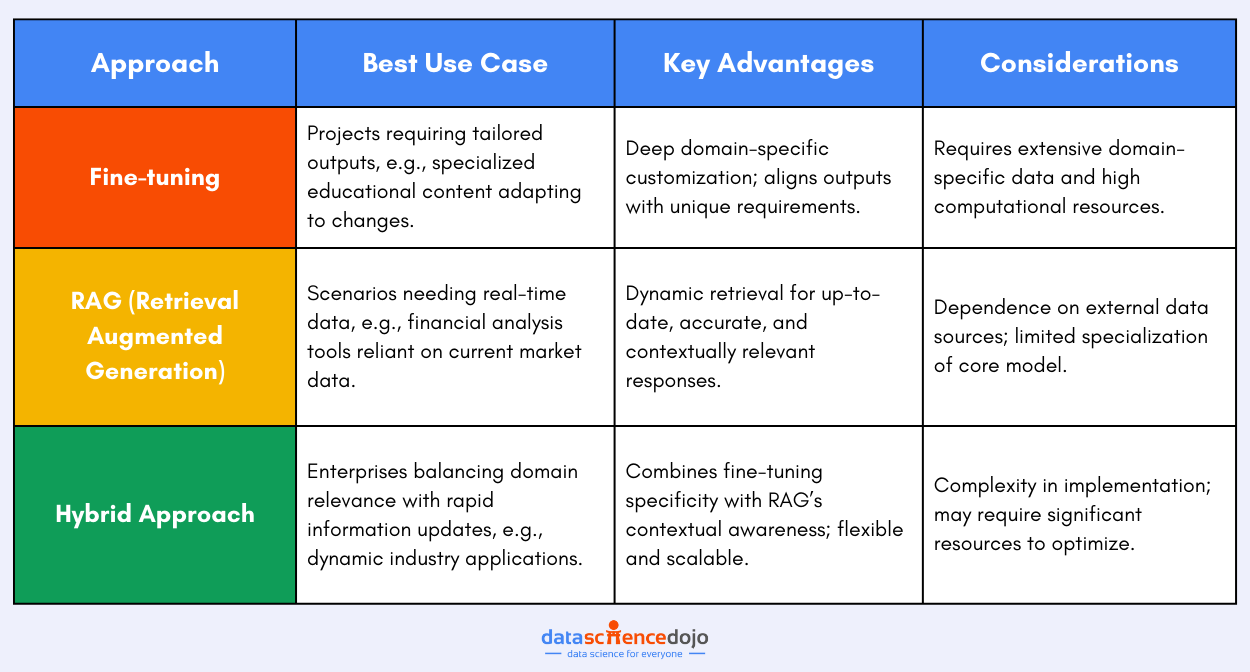
Hybrid Approach: Enhancing LLMs with RAG and Finetuning
The concept of a hybrid model that integrates Retrieval-Augmented Generation (RAG) with fine-tuning presents an interesting advancement. This approach allows for the contextual enrichment of LLM responses with up-to-date information while ensuring that outputs are tailored to the nuanced requirements of specific tasks.
Such a model can operate flexibly, serving as either a versatile, all-encompassing system or as an ensemble of specialized models, each optimized for particular use cases.
In practical applications, this could range from customer service chatbots that pull the latest policy details to enrich responses and then tailor these responses to individual user queries, to medical research assistants that retrieve the latest clinical data for accurate information dissemination, adjusted for layman understanding.
The hybrid model thus promises not only improved accuracy by grounding responses in factual, relevant data but also ensures that these responses are closely aligned with specific domain languages and terminologies.
However, this integration introduces complexities in model management, potentially higher computational demands, and the need for effective data strategies to harness the full benefits of both RAG and fine-tuning.
Despite these challenges, the hybrid approach marks a significant step forward in AI, offering models that combine broad knowledge access with deep domain expertise, paving the way for more sophisticated and adaptable AI solutions.
Choosing the Best Approach: Finetuning, RAG, or Hybrid
Choosing between fine-tuning, Retrieval Augmented Generation (RAG), or a hybrid approach for enhancing a Large Language Model should consider specific project needs, data accessibility, and the desired outcome alongside computational resources and scalability.
Fine-tuning is best when you have extensive domain-specific data and seek to tailor the LLM’s outputs closely to specific requirements, making it a perfect fit for projects like creating specialized educational content that adapts to curriculum changes. RAG, with its dynamic retrieval capability, suits scenarios where responses must be informed by the latest information, ideal for financial analysis tools that rely on current market data.
A hybrid approach merges these advantages, offering the specificity of fine-tuning with the contextual awareness of RAG, suitable for enterprises needing to keep pace with rapid information changes while maintaining deep domain relevance. As technology evolves, a hybrid model might offer the flexibility to adapt, providing a comprehensive solution that encompasses the strengths of both fine-tuning and RAG.
As the landscape of artificial intelligence continues to evolve, so too do the methodologies and technologies at its core. Among these, Retrieval-Augmented Generation (RAG) and fine-tuning are experiencing significant advancements, propelling them toward new horizons of AI capabilities.
Advanced Enhancements in RAG
Enhancing the Retrieval Augmented Generation Pipeline
RAG has undergone significant transformations and advancements in each step of its pipeline. Each research paper on RAG introduces advanced methods to boost accuracy and relevance at every stage.
Let’s use the same query example from the basic RAG explanation: “What’s the latest breakthrough in renewable energy?”, to better understand these advanced techniques.
Pre-Retrieval Optimizations
Before the system begins to search, it optimizes the query for better outcomes. For our example, Query Transformations and Routing might break down the query into sub-queries like “latest renewable energy breakthroughs” and “new technology in renewable energy.”
This ensures the search mechanism is fine-tuned to retrieve the most accurate and relevant information.
Enhanced Retrieval Techniques
During the retrieval phase, Hybrid Search combines keyword and semantic searches, ensuring a comprehensive scan for information related to our query.
Moreover, by Chunking and Vectorization, the system breaks down extensive documents into digestible pieces, which are then vectorized. This means our query doesn’t just pull up general information but seeks out the precise segments of texts discussing recent innovations in renewable energy.
Post-Retrieval Refinements
After retrieval, the Reranking and Filtering processes evaluate the gathered information chunks. Instead of simply using the top ‘k’ matches, these techniques rigorously assess the relevance of each piece of retrieved data.
For our query, this could mean prioritizing a segment discussing a groundbreaking solar panel efficiency breakthrough over a more generic update on solar energy. This step ensures that the information used in generating the response directly answers the query with the most relevant and recent breakthroughs in renewable energy.
Through these advanced RAG enhancements, the system not only finds and utilizes information more effectively but also ensures that the final response to the query about renewable energy breakthroughs is as accurate, relevant, and up-to-date as possible.
Towards Multimodal Integration
RAG, traditionally focused on enhancing text-based language models by incorporating external data, is now also expanding its horizons towards a multimodal future.
Multimodal RAG integrates various types of data, such as images, audio, and video, alongside text, allowing AI models to generate responses that are not only informed by a vast array of textual information but also enriched by visual and auditory contexts.
This evolution signifies a move towards AI systems capable of understanding and interacting with the world more holistically, mimicking human-like comprehension across different sensory inputs.
In parallel, fine-tuning is transforming more parameter-efficient methods. Fine-tuning large language models (LLMs) presents a unique challenge for AI practitioners aiming to adapt these models to specific tasks without the overwhelming computational costs typically involved.
One such innovative technique is Parameter-Efficient Fine-Tuning (PEFT), which offers a cost-effective and efficient method for fine-tuning such a model.
Techniques like Low-Rank Adaptation (LoRA) are at the forefront of this change, enabling fine-tuning to be accomplished with significantly less computational overhead. LoRA and similar approaches adjust only a small subset of the model’s parameters, making fine-tuning not only more accessible but also more sustainable.
Specifically, it introduces a low-dimensional matrix that captures the essence of the downstream task, allowing for fine-tuning with minimal adjustments to the original model’s weights.
This method exemplifies how cutting-edge research is making it feasible to tailor LLMs for specialized applications without the prohibitive computational cost typically associated.
The Emergence of Long-Context LLMs
The evolution toward long context LLMs – Source: Google Blog
As we embrace these advancements in RAG and fine-tuning, the recent introduction of Long Context LLMs, like Gemini 1.5 Pro, poses an intriguing question about the future necessity of these technologies. Gemini 1.5 Pro, for instance, showcases a remarkable capability with its 1 million token context window, setting a new standard for AI’s ability to process and utilize extensive amounts of information in one go.
The big deal here is how this changes the game for technologies like RAG and advanced fine-tuning. RAG was a breakthrough because it helped AI models to look beyond their training, fetching information from outside when needed, to answer questions more accurately.
But now, with Long Context LLMs’ ability to hold so much information in memory, the question arises: Do we still need RAG anymore?
This doesn’t mean RAG and fine-tuning are becoming obsolete. Instead, it hints at an exciting future where AI can be both deeply knowledgeable, thanks to its vast memory, and incredibly adaptable, using technologies like RAG to fill in any gaps with the most current information.
In essence, Long Context LLMs could make AI more powerful by ensuring it has a broad base of knowledge to draw from, while RAG and fine-tuning techniques ensure that the AI remains up-to-date and precise in its answers. So the emergence of Long Context LLMs like Gemini 1.5 Pro does not diminish the value of RAG and fine-tuning but rather complements it.
Concluding Thoughts
The trajectory of AI, through the advancements in RAG, fine-tuning, and the emergence of long-context LLMs, reveals a future rich with potential. As these technologies mature, their combined interaction will make systems more adaptable, efficient, and capable of understanding and interacting with the world in ways that are increasingly nuanced and human-like.
The evolution of AI is not just a testament to technological advancement but a reflection of our continuous quest to create machines that can truly understand, learn from, and respond to the complex landscape of human knowledge and experience.
This is the first blog in the series of RAG and finetuning, focusing on providing a better understanding of the two approaches.
RAG LLM and finetuning: You’ve likely seen these terms tossed around on social media, hailed as the next big leap in artificial intelligence. But what do they really mean, and why are they so crucial in the evolution of AI?
To truly understand their significance, it’s essential to recognize the practical challenges faced by current language models, such as ChatGPT, renowned for their ability to mimic human-like text across essays, dialogues, and even poetry.
Yet, despite these impressive capabilities, their limitations became more apparent when tasked with providing up-to-date information on global events or expert knowledge in specialized fields.
Take, for instance, the FIFA World Cup.
Messi’s winning shot at the Fifa World Cup – Source: Economic Times
If you were to ask ChatGPT, “Who won the FIFA World Cup?” expecting details on the most recent tournament, you might receive an outdated response citing France as the champions despite Argentina’s triumphant victory in Qatar 2022.
ChatGPT’s response to an inquiry about the winner of the FIFA World Cup 2022
Moreover, the limitations of AI models extend beyond current events to specialized knowledge domains. Try asking ChatGPT for treatments in neurodegenerative diseases, a highly specialized medical field. The model might offer generic advice based on its training data but lacks depth or specificity – and, most importantly, accuracy.
Symptoms of Parkinson’s disease – Source: Neuro2go
GPT’s response to inquiry about Parkinson’s disease
These scenarios precisely illustrate the problem: a language model might generate text relevant to a past context or data but falls short when current or specialized knowledge is required.
RAG revolutionizes the way language models access and use information. Incorporating a retrieval step allows these models to pull in data from external sources in real time.
This means that when you ask a RAG-powered model a question, it doesn’t just rely on what it learned during training; instead, it can consult a vast, constantly updated external database to provide an accurate and relevant answer. This would bridge the gap highlighted by the FIFA World Cup example.
On the other hand, fine-tuning offers a way to specialize a general AI model for specific tasks or knowledge domains. Additional training on a focused dataset sharpens the model’s expertise in a particular area, enabling it to perform with greater precision and understanding.
This process transforms a jack-of-all-trades into a master of one, equipping it with the nuanced understanding required for tasks where generic responses just won’t cut it. This would allow it to perform as a seasoned medical specialist dissecting a complex case rather than a chatbot giving general guidelines to follow.
Curious about the LLM context augmentation approaches like RAG and fine-tuning and their benefits, trade-offs and use-cases? Tune in to this podcast with Co-founder and CEO of LlamaIndex now!
This blog will walk you through RAG and finetuning, unraveling how they work, why they matter, and how they’re applied to solve real-world problems. By the end, you’ll not only grasp the technical nuances of these methodologies but also appreciate their potential to transform AI systems, making them more dynamic, accurate, and context-aware.
Understanding the RAG LLM Duo
Let’s take a closer look at the RAG LLM duo and its impact on a language model.
What is RAG?
Retrieval-augmented generation (RAG) significantly enhances how AI language models respond by incorporating a wealth of updated and external information into their answers. It could be considered a model consulting an extensive digital library for information as needed.
Its essence is in the name: Retrieval, Augmentation, and Generation.
Retrieval
The process starts when a user asks a query, and the model needs to find information beyond its training data. It searches through a vast database that is loaded with the latest information, looking for data related to the user’s query.
Augmentation
Next, the information retrieved is combined, or ‘augmented,’ with the original query. This enriched input provides a broader context, helping the model understand the query in greater depth.
Generation
Finally, the language model generates a response based on the augmented prompt. This response is informed by the model’s training and the newly retrieved information, ensuring accuracy and relevance.
Retrieval-augmented generation (RAG) brings an approach to natural language processing that’s both smart and efficient. It solved many problems faced by current LLMs, and that’s why it’s the most talked about technique in the NLP space.
Always Up-To-Date: RAG keeps answers fresh by accessing the latest information. RAG ensures the AI’s responses are current and correct in fields where facts and data change rapidly.
Sticks to the Facts: Unlike other models that might guess or make up details (a ” hallucinations ” problem), RAG checks facts by referencing real data. This makes it reliable, giving you answers based on actual information.
Flexible and Versatile: RAG is adaptable, working well across various settings, from chatbots to educational tools and more. It meets the need for accurate, context-aware responses in a wide range of uses, and that’s why it’s rapidly being adapted in all domains.
To understand RAG further, consider when you interact with an AI model by asking a question like “What’s the latest breakthrough in renewable energy?”. This is when the RAG system springs into action. Let’s walk through the actual process.
A visual representation of an RAG pipeline
Query Initiation and Vectorization
Your query starts as a simple string of text. However, computers, particularly AI models, don’t understand text and its underlying meanings the same way humans do. To bridge this gap, the RAG system converts your question into an embedding, also known as a vector.
Why a vector, you might ask? Well, A vector is essentially a numerical representation of your query, capturing not just the words but the meaning behind them. This allows the system to search for answers based on concepts and ideas, not just matching keywords.
Searching the Vector Database
With your query now in vector form, the RAG system seeks answers in an up-to-date vector database. The system looks for the vectors in this database that are closest to your query’s vector—the semantically similar ones, meaning they share the same underlying concepts or topics.
Vector databases defined: A vector database stores vast amounts of information from diverse sources, such as the latest research papers, news articles, and scientific discoveries. However, it doesn’t store this information in traditional formats (like tables or text documents). Instead, each piece of data is converted into a vector during the ingestion process.
Why vectors?: This conversion to vectors allows the database to represent the data’s meaning and context numerically or into a language the computer can understand and comprehend deeply, beyond surface-level keywords.
Indexing: Once information is vectorized, it’s indexed within the database. Indexing organizes the data for rapid retrieval, much like an index in a textbook, enabling you to find the information you need quickly. This process ensures that the system can efficiently locate the most relevant information vectors when it searches for matches to your query vector.
The key here is that this information is external and not originally part of the language model’s training data, enabling the AI to access and provide answers based on the latest knowledge.
Selecting the Top ‘k’ Responses
From this search, the system selects the top few matches—let’s say the top 5. These matches are essentially pieces of information that best align with the essence of your question.
By concentrating on the top matches, the RAG system ensures that the augmentation enriches your query with the most relevant and informative content, avoiding information overload and maintaining the response’s relevance and clarity.
Augmenting the Query
Next, the information from these top matches is used to augment the original query you asked the LLM. This doesn’t mean the system simply piles on data. Instead, it integrates key insights from these top matches to enrich the context for generating a response. This step is crucial because it ensures the model has a broader, more informed base from which to draw when crafting its answer.
Generating the Response
Now comes the final step: generating a response. With the augmented query, the model is ready to reply. It doesn’t just output the retrieved information verbatim. Instead, it synthesizes the enriched data into a coherent, natural-language answer.
For your renewable energy question, the model might generate a summary highlighting the most recent and impactful breakthrough, perhaps detailing a new solar panel technology that significantly increases power output. This answer is informative, up-to-date, and directly relevant to your query.
Understanding Fine-Tuning
While we now understand RAG better, we must also explore the other key process when optimizing LLMs – fine-tuning. The basic details include:
What is Fine-Tuning?
Fine-tuning could be likened to sculpting, where a model is precisely refined, like shaping marble into a distinct figure. Initially, a model is broadly trained on a diverse dataset to understand general patterns—this is known as pre-training. Think of pre-training as laying a foundation; it equips the model with a wide range of knowledge.
Fine-tuning, then, adjusts this pre-trained model and its weights to excel in a particular task by training it further on a more focused dataset related to that specific task. From training on vast text corpora, pre-trained LLMs, such as GPT or BERT, have a broad understanding of language.
Fine-tuning adjusts these models to excel in targeted applications, from sentiment analysis to specialized conversational agents.
The breadth of knowledge LLMs acquire through initial training is impressive but often lacks the depth or specificity required for certain tasks. Fine-tuning addresses this by adapting the model to the nuances of a specific domain or function, enhancing its performance significantly on that task without the need to train a new model from scratch.
The Fine-Tuning Process
Fine-tuning involves several key steps, each critical to customizing the model effectively. The process aims to methodically train the model, guiding its weights toward the ideal configuration for executing a specific task with precision.
A look at the finetuning process
Selecting a Task
Identify the specific task you wish your model to perform better on. The task could range from classifying emails into spam or not spam to generating medical reports from patient notes.
Choosing the Right Pre-Trained Model
The foundation of fine-tuning begins with selecting an appropriate pre-trained large language model (LLM) such as GPT or BERT. These models have been extensively trained on large, diverse datasets, giving them a broad understanding of language patterns and general knowledge.
The choice of model is critical because its pre-trained knowledge forms the basis for the subsequent fine-tuning process. For tasks requiring specialized knowledge, like medical diagnostics or legal analysis, choose a model known for its depth and breadth of language comprehension.
Preparing the Specialized Dataset
For fine-tuning to be effective, the dataset must be closely aligned with the specific task or domain of interest. This dataset should consist of examples representative of the problem you aim to solve. For a medical LLM, this would mean assembling a dataset comprised of medical journals, patient notes, or other relevant medical texts.
The key here is to provide the model with various examples it can learn from. This data must represent the types of inputs and desired outputs you expect once the model is deployed.
Reprocess the Data
Before your LLM can start learning from this task-specific data, the data must be processed into a format the model understands. This could involve tokenizing the text, converting categorical labels into numerical format, and normalizing or scaling input features.
At this stage, data quality is crucial; thus, you’ll look out for inconsistencies, duplicates, and outliers, which can skew the learning process, and fix them to ensure cleaner, more reliable data.
After preparing this dataset, you divide it into training, validation, and test sets. This strategic division ensures that your model learns from the training set, tweaks its performance based on the validation set, and is ultimately assessed for its ability to generalize from the test set.
Once the pre-trained model and dataset are ready, you must better tailor the model to suit your specific task. An LLM comprises multiple neural network layers, each learning different aspects of the data.
During fine-tuning, not every layer is tweaked—some represent foundational knowledge that applies broadly. In contrast, the top or later layers are more plastic and customized to align with the specific nuances of the task.
The architecture requires two key adjustments:
Layer freezing: To preserve the general knowledge the model has gained during pre-training, freeze most of its layers, especially the lower ones closer to the input. This ensures the model retains its broad understanding while you fine-tune the upper layers to be more adaptable to the new task.
Output layer modification: Replace the model’s original output layer with a new one tailored to the number of categories or outputs your task requires. This involves configuring the output layer to classify various medical conditions accurately for a medical diagnostic task.
Fine-Tuning Hyperparameters
With the model’s architecture now adjusted, we turn your attention to hyperparameters. Hyperparameters are the settings and configurations that are crucial for controlling the training process. They are not learned from the data but are set before training begins and significantly impact model performance.
Key hyperparameters in fine-tuning include:
Learning rate: Perhaps the most critical hyperparameter in fine-tuning. A lower learning rate ensures that the model’s weights are adjusted gradually, preventing it from “forgetting” its pre-trained knowledge.
Batch size: The number of training examples used in one iteration. It affects the model’s learning speed and memory usage.
Epochs: The number of times the entire dataset is passed through the model. Enough epochs are necessary for learning, but too many can lead to overfitting.
With the dataset prepared, the model was adapted, and the hyperparameters were set, so the model is now ready to be fine-tuned.
The training process involves repeatedly passing your specialized dataset through the model, allowing it to learn from the task-specific examples, it involves adjusting the model’s internal parameters, the weights, and biases of those fine-tuned layers so the output predictions get as close to the desired outcomes as possible.
This is done in iterations (epochs), and thanks to the pre-trained nature of the model, it requires fewer epochs than training from scratch.
Here is what happens in each iteration:
Forward pass: The model processes the input data, making predictions based on its current state.
Loss calculation: The difference between the model’s predictions and the actual desired outputs (labels) is calculated using a loss function. This function quantifies how well the model is performing.
Backward pass (Backpropagation): The gradients of the loss for each parameter (weight) in the model are computed. This indicates how the changes being made to the weights are affecting the loss.
Update weights: Apply an optimization algorithm to update the model’s weights, focusing on those in unfrozen layers. This step is where the model learns from the task-specific data, refining its predictions to become more accurate.
A tight feedback loop where you incessantly monitor the model’s validation performance guides you in preventing overfitting and determining when the model has learned enough. It gives you an indication of when to stop the training.
After fine-tuning, assess the model’s performance on a separate validation dataset. This helps gauge how well the model generalizes to new data. You do this by running the model against the test set—data it hadn’t seen during training.
Here, you look at metrics appropriate to the task, like BLEU and ROUGE for translation or summarization, or even qualitative evaluations by human judges, ensuring the model is ready for real-life application and isn’t just regurgitating memorized examples.
If the model’s performance is not up to par, you may need to revisit the hyperparameters, adjust the training data, or further tweak the model’s architecture.
For medical LLM applications, it is this entire process that enables the model to grasp medical terminologies, understand patient queries, and even assist in diagnosing from text descriptions—tasks that require deep domain knowledge.
Hence, this provides a comprehensive introduction to RAG and fine-tuning, highlighting their roles in advancing the capabilities of large language models (LLMs). Some key points to take away from this discussion can be put down as:
LLMs struggle with providing up-to-date information and excelling in specialized domains.
RAG addresses these limitations by incorporating external information retrieval during response generation, ensuring informative and relevant answers.
Fine-tuning refines pre-trained LLMs for specific tasks, enhancing their expertise and performance in those areas.
Do you want to learn more about RAG, fine-tuning, and other relevant concepts and their practical application within the field of LLMs? Register for our LLM bootcamp today and explore the magic of this technological advancement!
AI chatbots are transforming the digital world with increased efficiency, personalized interaction, and useful data insights. While Open AI’s GPT and Google’s Gemini are already transforming modern business interactions, Anthropic AI recently launched its newest addition, Claude 3.
This blog explores the latest developments in the world of AI with the launch of Claude 3 and discusses the relative position of Anthropic’s new AI tool to its competitors in the market.
Let’s begin by exploring the budding realm of Claude 3.
What is Claude 3?
It is the most recent advancement in large language models (LLMs) by Anthropic AI to its claude family of AI models. It is the latest version of the company’s AI chatbot with an enhanced ability to analyze and forecast data. The chatbot can understand complex questions and generate different creative text formats.
Among its many leading capabilities is its feature to understand and respond in multiple languages. Anthropic has emphasized responsible AI development with Claude 3, implementing measures to reduce related issues like bias propagation.
Introducing the Members of the Claude 3 Family
Since the nature of access and usability differs for people, the Claude 3 family comes with various options for the users to choose from. Each choice has its own functionality, varying in data-handling capabilities and performance.
The Claude 3 family consists of a series of three models called Haiku, Sonnet, and Opus.
Members of the Claude 3 family – Source: Anthropic
Let’s take a deeper look into each member and their specialties.
Haiku
It is the fastest and most cost-effective model of the family and is ideal for basic chat interactions. It is designed to provide swift responses and immediate actions to requests, making it a suitable choice for customer interactions, content moderation tasks, and inventory management.
However, while it can handle simple interactions speedily, it is limited in its capacity to handle data complexity. It falls short of generating creative texts or providing complex reasoning.
Sonnet
Sonnet provides the right balance between the speed of Haiku and the intelligence of Opus. It is a middle-ground model among this family of three with an improved capability to handle complex tasks. It is designed to particularly manage enterprise-level tasks.
Hence, it is ideal for data processing, like retrieval augmented generation (RAG) or searching vast amounts of organizational information. It is also useful for sales-related functions like product recommendations, forecasting, and targeted marketing.
Moreover, the Sonnet is a favorable tool for several time-saving tasks. Some common uses in this category include code generation and quality control.
Opus
Opus is the most intelligent member of the Claude 3 family. It is capable of handling complex tasks, open-ended prompts, and sight-unseen scenarios. Its advanced capabilities enable it to engage with complex data analytics and content generation tasks.
Hence, Opus is useful for R&D processes like hypothesis generation. It also supports strategic functions like advanced analysis of charts and graphs, financial documents, and market trends forecasting. The versatility of Opus makes it the most intelligent option among the family, but it comes at a higher cost.
Ultimately, the best choice depends on the specific required chatbot use. While Haiku is the best for a quick response in basic interactions, Sonnet is the way to go for slightly stronger data processing and content generation. However, for highly advanced performance and complex tasks, Opus remains the best choice among the three.
Among the Competitors
While Anthropic’s Claude 3 is a step ahead in the realm of large language models (LLMs), it is not the first AI chatbot to flaunt its many functions. The stage for AI had already been set with ChatGPT and Gemini. Anthropic has, however, created its space among its competitors.
Let’s take a look at Claude 3’s position in the competition.
Positioning Claude 3 among its competitors – Source: Anthropic
Performance Benchmarks
The chatbot performance benchmarks highlight the superiority of Claude 3 in multiple aspects. The Opus of the Claude 3 family has surpassed both GPT-4 and Gemini Ultra in industry benchmark tests. Anthropic’s AI chatbot outperformed its competitors in undergraduate-level knowledge, graduate-level reasoning, and basic mathematics.
Moreover, the Opus raises the benchmarks for coding, knowledge, and presenting a near-human experience. In all the mentioned aspects, Anthropic has taken the lead over its competition.
Comparing across multiple benchmarks – Source: Anthropic
For a deep dive into large language models, context windows, and content augmentation, watch this podcast now!
Data Processing Capacity
In terms of data processing, Claude 3 can consider much larger text at once when formulating a response, unlike the 64,000-word limit on GPT-4. Moreover, Opus from the Anthropic family can summarize up to 150,000 words while ChatGPT’s limit is around 3000 words for the same task.
It also possesses multimodal and multi-language data-handling capacity. When coupled with enhanced fluency and human-like comprehension, Anthropic’s Claude 3 offers better data processing capabilities than its competitors.
Ethical Considerations
The focus on ethics, data privacy, and safety makes Claude 3 stand out as a highly harmless model that goes the extra mile to eliminate bias and misinformation in its performance. It has an improved understanding of prompts and safety guardrails while exhibiting reduced bias in its responses.
Which AI Chatbot to Use?
Your choice relies on the purpose for which you need an AI chatbot. While each tool presents promising results, they outshine each other in different aspects. If you are looking for a factual understanding of language, Gemini is your go-to choice. ChatGPT, on the other hand, excels in creative text generation and diverse content creation.
However, striding in line with modern content generation requirements and privacy, Claude 3 has come forward as a strong choice. Alongside strong reasoning and creative capabilities, it offers multilingual data processing. Moreover, its emphasis on responsible AI development makes it the safest choice for your data.
To Sum It Up
Claude 3 emerges as a powerful LLM, boasting responsible AI, impressive data processing, and strong performance. While each chatbot excels in specific areas, Claude 3 shines with its safety features and multilingual capabilities. While access is limited now, Claude 3 holds promise for tasks requiring both accuracy and ingenuity.
Whether it’s complex data analysis or crafting captivating poems, Claude 3 is a name to remember in the ever-evolving world of AI chatbots.
With the rapidly evolving technological world, businesses are constantly contemplating the debate of traditional vs vector databases. This blog delves into a detailed comparison between the two data management techniques.
In today’s digital world, businesses must make data-driven decisions to manage huge sets of information. Hence, databases are important for strategic data handling and enhanced operational efficiency.
However, before we dig deeper into the types of databases, let’s understand them better.
Understanding Databases
Databases are a structured way to store and organize data effectively. It involves multiple data handling processes, like updating, deleting, or changing information. These are important for efficient data organization, security, and control.
Rules are put in place by databases to ensure data integrity and minimize redundancy. Moreover, organized storage of data facilitates data analysis, enabling retrieval of useful insights and data patterns. It also facilitates integration with different applications to enhance their functionality with organized access to data.
In data science, databases are important for data preprocessing, cleaning, and integration. Data scientists often rely on databases to perform complex queries and visualize data. Moreover, databases allow the storage of training datasets, facilitating model training and validation.
While databases are vital to data management, they have also developed over time. The changing technological world has led to a transition in available databases. Hence, the digital arena has gradually shifted from traditional to vector databases.
Since the shift is still underway, you can access both kinds of databases. However, it is important to understand the uses, limitations, and functions of both databases to understand which is more suitable for your organization. Let’s explore the arguments around the debate of traditional vs vector databases.
Exploring the Traditional vs Vector Databases Debate
In comparing the two categories of databases, we must explore a common set of factors to understand the basic differences between them. Hence, this blog will explore the debate from a few particular aspects, highlighting the characteristics of both traditional and vector databases in the process.
Traditional vs vector databases
Data Models
Traditional Databases:
They use a relational model that consists of a structured tabular form. Data is contained in tables divided into rows and columns. While each column represents a particular field, each row represents a single record within that field. Hence, the data is well-organized and maintains a well-defined relationship between different entities.
This relational data model holds a rigid schema, defining the structure of the data upfront. While it ensures high data integrity, it also makes the model inflexible in handling diverse and evolving data types.
Vector Databases:
Instead of a relational row and column structure, vector databases use a vector-based model consisting of a multidimensional array of numbers. Each data point is stored as a vector in a three-dimensional space, representing different features and properties of data.
Unlike a traditional database, the vector representation is well-suited to store unstructured data. It also allows easier handling of complex data points, making it a versatile data model. Its flexible schema allows better adaptability but at the cost of data integrity.
Suggestion:
Based on the data models of both databases, it can be said that when making a choice, you must find the right balance between maintaining data integrity and flexible data-handling capabilities. Understanding your database requirements between these two properties will help you towards an accurate option.
They rely on Structured Query Language (SQL), designed to navigate through relational databases. It provides a standardized way to interact with data, allowing data manipulation in the form of updating, inserting, deleting, and more.
It presents a highly focused method of addressing queries where data is filtered using exact matches, comparisons, and logical operators. SQL querying has long been present in the industry, hence it comes with a rich ecosystem of support.
Unlike a declarative language like SQL, vector databases execute querying through API calls. These can vary based on the vector database you use. The APIs perform similarity searches and nearest-neighbor operations as part of the querying process.
The process is based on retrieving similar data points to a query from the multidimensional vector space. It leverages indexing and search techniques that are suitable for complex vector databases.
Suggestion:
Hence, query language specifications are highly particular to your choice of a database. You would have to rely on either SQL for traditional databases or work with API calls if you are dealing with vector spaces for data storage.
Indexing Techniques
Traditional Databases:
Different data representation in a Hash and B-Tree Index – Source: IT Tutorial
Indexing techniques for traditional databases include B-trees and hash indexes that are designed for structured data. B-trees is the most common method that organizes data in a hierarchical tree format. It assists in the efficient sorting and retrieval of data.
Hash indexes rely on hash functions to map data to particular locations in an index. On accessing this location, you can retrieve the actual data stored there. They are integral for point queries where exact matches are known.
Vector Databases:
HNSW and IVF are indexing methods that specialize in handling vector databases. These differentiated techniques optimize similarity searches in high-dimensional vector data.
A visual representation of HNSW – Source: Pinecone
HNSW stands for Hierarchical Navigable Small World which facilitates rapid proximity searches. It creates a multi-layer navigation graph to represent the vector space, creating a network of shortcuts to narrow down the search space to a small subset of similar vectors.
IVF or Inverted File Index divides the vector space into clusters and creates an inverted file for each cluster. A file records vectors that belong to each cluster. It enables comparison and detailed data search within clusters.
Both methods aim to enhance the similarity search in vector databases. While HNSW speeds up the process, IVF also increases its efficiency.
Suggestion:
While traditional indexing techniques optimize precise queries and efficient data manipulation in structured data, vector database methods are designed for similarity searches within high-dimensional data, handling complex queries such as nearest neighbor searches in machine learning applications.
These databases manage transactional workloads with a focus on data integrity (ACID compliance) and support complex querying capabilities. However, their performance is limited due to their design of vertical scalability, making it a costly and hardware-dependent process to handle large data volumes.
Vector Databases:
Vector databases provide distinct performance advantages in environments requiring quick insights from large volumes of complex data, enabling efficient search operations. Moreover, its horizontal scalability design promotes the distribution of data management across multiple machines, making it a cost-effective process.
Suggestion:
Performance-based decisions can be made by finding the right balance between data integrity and flexible data handling, similar to the consideration of their data model differences. However, the horizontal and vertical scalability highlights that vector databases are more cost-efficient for large data volumes.
Use Cases
Traditional Databases:
They are ideal for applications that rely on structured data and require transactional safety while managing data records and performing complex queries. Some common use cases include financial systems, E-commerce platforms, customer relationship management (CRM), and human resource (HR) systems.
Vector Databases:
They are useful for complex and multimodal datasets, often associated with complex machine learning (ML) tasks. Some important use cases include natural language processing (NLP), fraud detection, recommendation systems, and real-time personalization.
The differences in use cases highlight the varied strengths of both databases. You cannot undermine one over the other but understand both databases better to make the right choice for your data. Traditional databases remain the backbone for structured data while vector databases are better adapted for modern datasets.
The Final Verdict
Traditional databases are suitable for small or medium-sized datasets where retrieval of specific data is required from well-defined links of information. Vector databases, on the other hand, are better for large unstructured datasets with a focus on similarity searches.
Hence, the clash of databases can be seen as a tradition meeting innovation. Traditional databases excel in structured realms, while vector databases revolutionize with speed in high-dimensional data. The final verdict of making the right choice hinges on your specific use cases.
In the dynamic world of machine learning and natural language processing (NLP), managing complex data efficiently has become crucial. Traditional databases often fall short when handling the high-dimensional data generated by modern AI applications, such as embeddings from text, images, and audio.
This challenge has led to the rise of vector databases, which offer robust solutions for storing and retrieving complex data types with remarkable efficiency. These sophisticated platforms have emerged as indispensable tools, providing a robust infrastructure for managing the intricate data structures generated by large language models (LLMs).
These databases support efficient storage and rapid, accurate similarity searches, making them vital for various applications.
This blog explores the significance of vector databases, examining their unique features and applications in LLM scenarios. We will also present real-world case studies that highlight their impact across different industries. Join us as we uncover the critical role of vector databases in driving AI innovation.
What are Vector Databases?
Vector databases are specialized purpose-built platforms designed to store, manage, and query high-dimensional data represented as vectors. These vectors are mathematical representations that capture the semantic meaning of unstructured data types such as text, images, audio, and more.
These databases enable efficient and accurate similarity searches within these complex data structures, which are beyond the capabilities of traditional databases. By organizing data as vectors, these databases facilitate advanced ML and NLP tasks, such as semantic search, recommendation systems, and real-time personalization.
Hence, vector databases are meticulously designed to address the intricate challenges posed by the storage and retrieval of vector embeddings.
In the landscape of NLP applications, these embeddings serve as the lifeblood, capturing intricate semantic and contextual relationships within vast datasets. Traditional databases, grappling with the high-dimensional nature of these embeddings, falter in comparison to the efficiency and adaptability offered by vector databases.
Visual representation of traditional and vector databases
The uniqueness of vector databases lies in their tailored ability to efficiently manage complex data structures, a critical requirement for handling embeddings generated from large language models and other intricate machine learning models.
These databases serve as the hub, providing an optimized solution for the nuanced demands of NLP tasks. In a landscape where the boundaries of machine learning are continually pushed, vector databases stand as pillars of adaptability, efficiently catering to the specific needs of high-dimensional vector storage and retrieval.
Understanding vector databases
How are Vector Embeddings Linked to Vector Databases?
Vector embeddings are mathematical representations of data in the form of multi-dimensional vectors that algorithms can easily process and analyze. Unlike traditional methods, vector embeddings place data points in a continuous space, allowing for more detailed and meaningful comparisons.
For example, in natural language processing (NLP), embeddings can capture the contextual meaning of words, enabling more sophisticated text analysis and understanding. The dimensions of these vectors represent different data features, and the vector position in space reflects the relationships and similarities between different points.
These vector embeddings are the fundamental data type that vector databases store, manage, and retrieve. The databases rely on the high-dimensional characteristics of these embeddings for quick and efficient searches.
Common types of vector embeddings include:
Word Embeddings: represent words in vector space based on their context
Sentence Embeddings: capture the meaning of entire sentences to aid tasks like semantic search
Image Embeddings: present visual features like shapes and colors as vectors for efficient image search
User Behavior Embeddings: quantify user actions and preferences for enhanced recommendations
The variety of these vector embeddings empowers advanced AI and machine learning applications for deeper insights and more personalized, intelligent systems across various fields.
Machine learning (ML) models transform raw data points into numerical representations in a high-dimensional space as vector embeddings. The models are designed to capture the meaningful features and relationships in the data to encode them as vectors.
Some popular ML models used for the creation of vector embeddings are as follows:
BERT (Bidirectional Encoder Representations from Transformers): BERT is a model that reads text in both directions (left-to-right and right-to-left) to understand the context of each word in a sentence. This helps in capturing the detailed meaning of words based on their surroundings.
GPT (Generative Pre-trained Transformer): GPT is designed to predict the next word in a sequence, which helps in generating text that is coherent and contextually relevant. It also captures the relationships between words effectively.
CNNs (Convolutional Neural Networks): Although CNNs are primarily used for image data, they can also be applied to text. CNNs analyze smaller parts of data, such as phrases or image patches, to create embeddings that capture essential features.
All these ML models rely on high-dimensional space to capture the complex relationships and semantic meanings within data. Each dimension is used to represent a different feature of the data, enabling ML models to understand and analyze various types of data for more accurate results.
For example, words with similar meanings will be placed closer together, while unrelated words will be farther apart. This spatial arrangement helps in understanding and processing data more effectively.
The Problem of High-Dimensional Data Retrieval
Since multi-dimensional vector embeddings capture complex features of data, each vector can have hundreds or thousands of dimensions. With an increase in dimensions, distances between data points become less meaningful making it difficult to navigate data.
Thus, traditional retrieval methods do not work for such complex databases. Hence, data retrieval from vector databases requires specialized algorithms and indexing techniques to find vectors efficiently. Let’s explore some indexing techniques used to navigate high-dimensional data.
Indexing Techniques in Vector Databases
Indexing techniques in vector databases are specialized methods designed to handle high-dimensional data efficiently. These techniques are optimized for performing similarity searches in vector spaces.
Here are some key indexing techniques used in vector databases:
Hierarchical Navigable Small World (HNSW) – a graph-based algorithm that creates a multi-layer navigation graph to represent the vector space, forming a network of shortcuts that narrow down the search space to a small subset of similar vectors.
Inverted File Index (IVF) – divides the vector space into clusters and creates an inverted file for each cluster. Each file records vectors belonging to a specific cluster, enabling comparison and detailed data search within clusters.
Product Quantization (PQ) – compresses vectors into a smaller representation that can be used for efficient search. It reduces the storage space and improves the query performance, making it suitable for large datasets.
Locality-Sensitive Hashing (LSH) – finds similar vectors by hashing them into buckets. Vectors that are close to each other in the vector space are likely to be hashed into the same bucket, facilitating efficient similarity searches.
Indexing in vector databases is essential to achieve a balance between accuracy and speed, especially when dealing with large datasets. It results in trade-offs of retrieval speed, memory usage, and accuracy. Following are the key trade-offs in indexing:
Retrieval Speed vs. Accuracy:
Exact nearest neighbor methods guarantee high accuracy but can be slow, especially with large datasets. However, Approximate nearest neighbor (ANN) techniques offer faster retrieval times by slightly sacrificing accuracy to quickly find vectors that are close enough, making them ideal for large-scale applications.
Memory Usage vs. Speed:
Some indexing techniques, like Product Quantization (PQ), compress vectors to reduce memory usage, which can also speed up searches by making data more manageable. Meanwhile, Locality-Sensitive Hashing (LSH) hashes vectors into buckets, which speeds up the search but might require more memory to maintain the hash tables.
Hence, indexing in vector databases strikes a balance between accuracy and speed, ensuring efficient data management and scalability. By leveraging sophisticated algorithms, these databases handle large datasets while maintaining quick and reliable search performance.
Let’s look at some common search processes that rely on vector databases to produce useful and accurate results.
Vector Search – A Focused Similarity Search for Vector Databases
Similarity search is a data retrieval technique to find items that are most similar to a query input. Unlike traditional keyword searches that rely on exact matches, similarity search focuses on finding items that are alike in terms of their semantic meaning or other complex relationships.
A type of similarity search is vector search that is specifically designed for high-dimensional data represented as vector embeddings. The process relies on vector databases to execute large-scale data retrieval efficiently.
With suitable indexing techniques in these databases, it also executes faster searches. As a result, vector search is used to conduct context-aware or semantic search to user queries. Other applications of vector search include:
Text Search: Phrases or documents search for ones that are semantically similar to a query.
Image Retrieval: Identifying images that are visually similar.
Recommendation Systems: Suggesting products or content based on user preferences.
Fraud Detection: Identifying suspicious activities by comparing them to known patterns.
Exploring Different Types of Vector Databases and Their Features
The vast landscape of vector databases unfolds in diverse types, each armed with unique features meticulously crafted for specific use cases.
Types of vector databases
Weaviate: Graph-Driven Semantic Understanding
Weaviate stands out for seamlessly blending graph database features with powerful vector search capabilities, making it an ideal choice for NLP applications requiring advanced semantic understanding and embedding exploration.
With a user-friendly RESTful API, client libraries, and a WebUI, Weaviate simplifies integration and management for developers. The API ensures standardized interactions, while client libraries abstract complexities, and the WebUI offers an intuitive graphical interface.
Weaviate’s cohesive approach empowers developers to leverage its capabilities effortlessly, making it a standout solution in the evolving landscape of data management for NLP.
DeepLake, an open-source powerhouse, excels in the efficient storage and retrieval of embeddings, prioritizing scalability and speed. With a distributed architecture and built-in support for horizontal scalability, DeepLake emerges as the preferred solution for managing vast NLP datasets.
Its implementation of an Approximate Nearest Neighbor (ANN) algorithm, specifically based on the Product Quantization (PQ) method, not only guarantees rapid search capabilities but also maintains pinpoint accuracy in similarity searches.
DeepLake is meticulously designed to address the challenges of handling large-scale NLP data, offering a robust and high-performance solution for storage and retrieval tasks.
Deep Lake architectural pattern
Faiss by Facebook: High-Performance Similarity Search
Faiss, known for its outstanding performance in similarity searches, offers a diverse range of optimized indexing methods for swift retrieval of nearest neighbors. With support for GPU acceleration and a user-friendly Python interface, Faiss firmly establishes itself in the landscape.
This versatility enables seamless integration with NLP pipelines, enhancing its effectiveness across a wide spectrum of machine learning applications. Faiss stands out as a powerful tool, combining performance, flexibility, and ease of integration for robust similarity search capabilities in diverse use cases.
Milvus: Scaling Heights with Open-Source Flexibility
Milvus, an open-source tool, stands out for its emphasis on scalability and GPU acceleration. Its ability to scale up and work with graphics cards makes it great for managing large NLP datasets. Milvus is designed to be distributed across multiple machines, making it ideal for handling massive amounts of data.
It easily integrates with popular libraries like Faiss, Annoy, and NMSLIB, giving developers more choices for organizing data and improving the accuracy and efficiency of vector searches. The diversity of vector databases ensures that developers have a nuanced selection of tools, each catering to specific requirements and use cases within the expansive landscape of NLP and machine learning.
Efficient Storage and Retrieval of Vector Embeddings for LLM Applications
Efficiently leveraging vector databases for the storage and retrieval of embeddings in the world of large language models (LLMs) involves a meticulous process. This journey is multifaceted, encompassing crucial considerations and strategic steps that collectively pave the way for optimized performance.
Choosing the Right Database
The foundational step in this intricate process is the selection of a vector database that seamlessly aligns with the scalability, speed, and indexing requirements specific to the LLM project at hand.
The decision-making process involves a careful evaluation of the project’s intricacies, understanding the nuances of the data, and forecasting future scalability needs. The chosen vector database becomes the backbone, laying the groundwork for subsequent stages in the embedding storage and retrieval journey.
Integration with NLP Pipelines
Leveraging the provided RESTful APIs and client libraries is the key to ensuring a harmonious integration of the chosen vector database within NLP frameworks and LLM applications.
This stage is characterized by a meticulous orchestration of tools, ensuring that the vector database seamlessly becomes an integral part of the larger ecosystem. The RESTful APIs serve as the conduit, facilitating communication and interaction between the database and the broader NLP infrastructure.
Optimizing Search Performance
The crux of efficient storage and retrieval lies in the optimization of search performance. Here, developers delve into the intricacies of the chosen vector database, exploring and utilizing specific indexing methods and GPU acceleration capabilities.
These nuanced optimizations are tailored to the unique demands of LLM applications, ensuring that vector searches are not only precise but also executed with optimal speed. The performance optimization stage serves as the fine-tuning mechanism, aligning with the intricacies of large language models.
Language-specific Indexing
In scenarios where LLM applications involve multilingual content, the choice of a vector database supporting language-specific indexing and retrieval capabilities becomes paramount. This consideration reflects the diverse linguistic landscape that the LLM is expected to navigate.
Language-specific indexing ensures that the database comprehends and processes linguistic nuances, ultimately leading to accurate search results across different languages.
Incremental Updates
A forward-thinking strategy involves the consideration of vector databases supporting incremental updates. This capability is crucial for LLM applications characterized by dynamically changing embeddings.
The database’s ability to efficiently store and retrieve these dynamic embeddings, adapting in real-time to the evolving nature of the data, becomes a pivotal factor in ensuring the sustained accuracy and relevance of the LLM application.
This multifaceted approach to embedding storage and retrieval for LLM applications ensures that developers navigate the complexities of large language models with precision and efficacy, harnessing the full potential of vector databases.
Case Studies: Real-world Impact of Database Optimization with Vector Databases
The real-world impact of vector databases unfolds through compelling case studies across diverse industries, showcasing their versatility and efficacy in varied applications.
Case Study 1: Semantic Understanding in Chatbots
The implementation of Weaviate‘s vector database in an AI chatbot leveraging large language models exemplifies the real-world impact on semantic understanding. Weaviate facilitates the efficient storage and retrieval of semantic embeddings, enabling the chatbot to interpret user queries within context.
The result is a chatbot that provides accurate and contextually relevant responses, significantly enhancing the user experience.
Case Study 2: Multilingual NLP Applications
VectorStore’s language-specific indexing and retrieval capabilities take center stage in a multilingual NLP platform.
The case study illuminates how VectorStore efficiently manages and retrieves embeddings across different languages, providing contextually relevant results for a global user base. This underscores the adaptability of vector databases in diverse linguistic landscapes.
Understanding multilingual NLP applications
Case Study 3: Image Generation and Similarity Search
In the world of image generation and similarity search, a company harnesses databases to streamline the storage and retrieval of image embeddings. By representing images as high-dimensional vectors, the database enables swift and accurate similarity searches, enhancing tasks such as image categorization, duplicate detection, and recommendation systems.
The real-world impact extends to the world of visual content, underscoring the versatility of vector databases.
Case Study 4: Movie and Product Recommendations
E-commerce and movie streaming platforms optimize their recommendation systems through the power of vector databases. Representing movies or products as high-dimensional vectors based on attributes like genre, cast, and user reviews, the database ensures personalized recommendations.
This personalized touch elevates the user experience, leading to higher conversion rates and improved customer retention. The case study vividly illustrates how vector databases contribute to the dynamic landscape of recommendation systems.
Case Study 5: Sentiment Analysis in Social Media
A social media analytics company transforms sentiment analysis with the efficient use of vector databases. Representing text snippets or social media posts as high-dimensional vectors, the database enables rapid and accurate sentiment analysis.
This real-time analysis of large volumes of text data provides valuable insights, allowing businesses and marketers to track public opinion, detect trends, and identify potential brand reputation issues.
Case Study 6: Fraud Detection in Financial Services
The application of vector databases in a financial services company amplifies fraud detection capabilities. By representing transaction patterns as high-dimensional vectors, the database enables rapid similarity searches to identify suspicious or anomalous behavior.
In the world of financial services, where timely detection is paramount, vector databases provide the efficiency and accuracy needed to safeguard customer accounts. The case study emphasizes the real-world impact of these databases in enhancing security measures.
The Final Word
In conclusion, the complex interplay of efficient storage and retrieval of vector embeddings using vector databases is at the heart of the success of machine learning and NLP applications, particularly in the expansive landscape of large language models.
This journey has unveiled the profound significance of vector databases, explored the diverse types and features they bring to the table, and provided insights into their application in LLM scenarios.
Real-world case studies have served as representations of their tangible impact, showcasing their ability to enhance semantic understanding, multilingual support, image generation, recommendation systems, sentiment analysis, and fraud detection.
By assimilating the insights shared in this exploration, developers embark on a path that brings them closer to harnessing the full potential of vector databases. These databases, with their adaptability, efficiency, and real-world impact, emerge as indispensable allies in the dynamic landscape of machine learning and NLP applications.
Mistral AI is getting a lot of attention with its new model, Mistral Large. It’s quickly becoming a strong competitor to GPT-4, and for good reason. So, what makes Mistral Large stand out? Simply put, it offers amazing performance and flexibility that’s catching the eye of developers and businesses alike.
In this blog, we’ll take a closer look at why Mistral AI’s Large is becoming so popular, how it compares to GPT-4, and what this means for the future of AI. If you’re curious about the next big thing in AI, keep reading!
What is Mistral AI?
Before diving into the comparison between Mistral Large and GPT-4, let’s first understand what Mistral AI is all about and why it’s causing such a buzz in the world of artificial intelligence.
Mistral AI is an innovative AI research company focused on developing cutting-edge LLMs. It aims to challenge the dominance of existing AI models like GPT-4 by introducing unique features that enhance performance and efficiency.
With its breakthroughs in deep learning and natural language processing, Mistral AI is positioned to reshape the AI landscape, offering more accessible and scalable solutions for various industries.
Now, let’s understand why Mistral Large is winning hearts by exploring its key features.
Features of Mistral AI’s Large Model
If you think Mistral Large is just another large language model (LLM) in the market, think again. This model is a game-changer, packed with features that have the potential to challenge GPT-4’s dominance.
From its advanced natural language understanding and multilingual support to its fast-processing speeds and scalable architecture, Mistral Large offers powerful performance tailored to diverse needs.
Let’s dive into the details that make this model stand out and why it’s quickly becoming the go-to choice for businesses and developers alike.
Advanced Natural Language Understanding
Mistral Large excels in natural language understanding, offering deep contextual awareness and accurate interpretations of user inputs. A standout feature is its native support for multiple languages, including English, French, Spanish, German, and Italian.
This broad language proficiency makes it a versatile choice for businesses and developers looking to engage with diverse audiences across the globe. It ensures high-quality, nuanced responses, no matter the language, making it a reliable tool for multilingual applications and global communication.
Model Size and Architecture Comparisons
When it comes to model size and architecture, Mistral Large has been designed with efficiency in mind. While GPT-4 is known for its vast model size, Mistral AI has optimized its architecture to balance performance with resource usage.
This thoughtful design results in a model that delivers powerful results without the hefty computational demands often associated with larger models, making it more accessible for a broader range of users.
Speed and Efficiency Improvements
Speed is another area where Mistral Large makes significant strides. Thanks to its streamlined architecture and optimized processing, it offers faster response times compared to many of its competitors.
This efficiency not only enhances the user experience but also reduces operational costs, making it a practical choice for businesses looking to integrate AI solutions without compromising on performance. The combination of speed and cost savings ensures that Mistral Large stands out as a forward-thinking model in the AI landscape.
Mistral AI vs. GPT-4: A Comparative Look
If you’ve been following the evolution of AI, you know GPT-4 has been the benchmark for excellence. But Mistral Large is stepping into the spotlight, not just as another competitor, but as a serious challenger reshaping the narrative.
With features designed to compete head-on, let’s explore how Mistral AI’s Large Model stacks up against GPT-4.
Cost Efficiency
Mistral Large is designed with cost-effectiveness at its core, offering a budget-friendly alternative to other top-tier AI models. It charges $8 per million input tokens and $24 per million output tokens, making it 20% cheaper than GPT-4 Turbo.
Additionally, its development costs were kept under $22 million, significantly lower than GPT-4’s estimated $100 million. This combination of lower usage fees and efficient training highlights Mistral AI’s commitment to delivering cutting-edge technology without the hefty price tag, making advanced AI more accessible to businesses of all sizes.
Benchmark Performance
In terms of performance, Mistral Large doesn’t just compete—it excels. Ranking just behind GPT-4, it surpasses major players like Google and Meta in key benchmarks. This achievement underscores Mistral AI’s commitment to delivering a model that’s not only cost-effective but also highly capable in real-world applications.
Commercial Strategy
Mistral AI’s approach to commercialization strikes a perfect balance between accessibility and smart monetization. With its usage-based pricing model for the paid API, Mistral AI ensures that both individual developers and large enterprises can access powerful AI tools at a price point that works for them.
This flexible pricing strategy allows users to scale their usage efficiently without compromising on the quality of the AI experience.
Model Variants
Additionally, Mistral AI offers a range of model variants to cater to different user needs. Whether you’re looking for lower latency, full-scale performance, or concise outputs, there’s a model for every use case.
Users can choose from Mistral Small, Mistral Large, or Mistral Next, with each version designed to provide tailored solutions that meet specific requirements. This variety ensures that Mistral AI can support a wide spectrum of applications, from fast-response scenarios to more complex, large-scale AI tasks.
With this strategic flexibility, Mistral AI makes advanced technology accessible and adaptable for a wide range of users.
How to Choose Between Mistral AI and GPT-4
Choosing between Mistral AI and GPT-4 can feel like a big decision, especially with the impressive features both models bring to the table. To make the best choice, it’s important to think about a few key factors that align with your business needs and goals. Let’s break it down in simple terms so you can decide which AI is the right fit for you.
Evaluating Business Needs and Goals
Start by considering what your business needs. If you’re focused on supporting multiple languages, fast response times, or scalable solutions, Mistral Large could be the better fit. Its strong multilingual capabilities and efficient processing handle a wide range of tasks with ease.
On the other hand, if you need an AI with a broad range of applications and top-tier benchmark performance, GPT-4 is known for its versatility and proven results. Consider the complexity of your tasks—Mistral AI offers flexibility, while GPT-4 excels in more demanding scenarios.
Cost is another crucial factor to think about. If you’re working with a tighter budget, Mistral Large offers a more cost-effective solution without sacrificing quality, making it a great option for businesses looking to maximize value.
On the flip side, GPT-4 might be the way to go if you’re willing to invest a bit more for that extra precision and wide-ranging capabilities it’s known for.
Integration Ease and Technical Support
Finally, consider how easy it will be to integrate the AI into your system and the kind of support you’ll need. Mistral AI offers flexible solutions with different model variants to fit various technical needs, while GPT-4 comes with extensive documentation and a large user community, making integration smoother for some teams.
Think about the level of technical support your team might require and choose the model that aligns with your resources.
Final Note
Both Mistral AI and GPT-4 bring unique strengths to the table. Mistral AI offers an affordable, flexible solution with strong multilingual capabilities, making it a great choice for businesses looking to maximize value.
On the other hand, GPT-4 excels in broader applications and performance, making it the go-to for more demanding tasks. The choice between them ultimately depends on your specific business needs and goals.
As AI technology continues to evolve, we can expect both Mistral AI and GPT-4 to push the boundaries of innovation. With more advancements on the horizon, businesses can look forward to even more powerful and cost-effective AI solutions in the future.
If you enjoyed this article, you may also like: Claude vs ChatGPT debate
Are you confused about where to start working on your large language model? It all starts with an understanding of a typical LLM project lifecycle. As part of the generative AI world, LLMs have led to innovation in machine-learning tasks.
Let’s take a look at the steps that make up an LLM project lifecycle and their impact on the process.
Roadmap to Understanding an LLM Project Lifecycle
Within the realm of generative AI, a project involving large language models can be a daunting task. It demands proper coordination and skills to execute a task successfully. In order to create an ease of understanding, we have broken down a typical LLM project lifecycle into multiple steps.
A roadmap of an LLM project lifecycle
In this section, we will delve deeper into the various stages of the process.
Defining the Scope of the Project
It is paramount to begin your LLM project lifecycle by understanding its scope. It begins with a comprehension of the problem you aim to solve. Market research and stakeholder interviews are a good place to start at this stage. You must also review the available technological possibilities.
Discover the Full Details of LLMs: Click Here to Learn More
LLMs are multifunctional but the size and architecture of the model determine its ability, ranging from long-form text generation and text summarization to language translation. Based on your research, you can determine the specifics of your LLM project and hence the scope of it.
The next part of this step is to explore the feasibility of a solution in generative AI. You must use this to set clear and measurable objectives as they would define the roadmap for your LLM project lifecycle.
Data Preprocessing and Relevant Considerations
Now that you have defined your problem, the next step is to look for relevant data. Data collection can encompass various sources, depending on your problem. Once you have the data, you need to clean and preprocess it. The goal is to make the data usable for model training.
Moreover, it is important in your LLM project lifecycle to consider all the ethical and legal considerations when dealing with data. You must have the clearance to use data, including protection laws, anonymization, and user consent. Moreover, you must ensure the prevention of potential biases through the diversity of perspectives in the data.
Selecting a Relevant Model
When it comes to model selection, you have two choices. Either use an existing base model or pre-train your own from scratch. Based on your project demands, you can start by exploring the available models to check if any aligns with your requirements.
Models like GPT-4 and PalM2 are powerful model options. Moreover, you can also explore FLAN-T5 – a hugging face model, offering enhanced Text-to-Text Transfer Transformer features. However, you need to consider license and certification details before choosing an open-source base model.
In case none of the existing models fulfill your demands, you need to pre-train a model from scratch to begin your LLM project lifecycle. It requires machine-learning expertise, computational resources, and time. The large investment in pre-training results in a highly customized model for your project.
What is pre-training? It is a compute-intensive phase of unsupervised learning tasks. In an LLM project lifecycle, the objective primarily focuses on text generation or next-token prediction. During this complex process, the model is trained and the transformer architecture is decided. It results in the creation of Formation Models.
Training the Model
The next step in the LLM project lifecycle is to adapt and train the foundation model. The goal is to refine your LLM model with your project requirements. Let’s look at some common techniques for the model training process.
Prompt engineering: As the name suggests, this method relies on prompt generation. You must structure prompts carefully for your LLM model to get accurate results. It requires you to have a proper understanding of your model and the project goals.
For a typical LLM model, a prompt is provided to the model for it to generate a text. This complete process is called inference. It is the simplest phase in an LLM project lifecycle that aims to refine your model responses and enhance its performance.
Fine-tuning: At this point, you focus on customizing your model to your specific project needs. The fine-tuning process enables you to convert a generic model into a tailored one by using domain-specific data, resulting in its optimized performance for particular tasks. It is a supervised learning task that adds weights to the foundation model, making it more efficient in the process.
Caching: It is one of the less-renowned but important techniques in the training process. It involves the frequent storage of prompts and responses to speed up your model’s performance. Caching high-dimensional vectors results in faster retrieval of information and generation of more efficient results.
Reinforcement Learning
Reinforcement learning happens from human or AI feedback, where the former is called RLHF and the latter is RLAIF. RLHF is aimed at aligning the LLM model with human values, expectations, and standards. The human evaluators review, rate, and provide feedback on the model performance.
A visual representation of reinforcement learning – Source: Medium
It is an iterative process completed using rewards against each successful model output which results in the creation of a rewards model. Then the RLAIF is used to scale human feedback that ensures the model is completely aligned with the human values.
Evaluating the Model
It involves the validation and testing of your LLM model. The model is tested using unseen data (also referred to as test data). The output is evaluated against a set of metrics. Some common LLM evaluation metrics include BLEU (Bilingual Evaluation Understudy), GLUE (General Language Understanding Evaluation), and HELM (Holistic Evaluation of Language Models).
Along with the set metrics, the results are also analyzed for adherence to ethical standards and the absence of biases. This ensures that your model for the LLM project lifecycle is efficient and relevant to your goals.
Model Optimization and Deployment
Model optimization is a prerequisite to the deployment process. You must ensure that the model is efficiently designed for your application environment. The process primarily includes the reduction of model size, enhancement of inference speed, and efficient operation of the model in real-world scenarios. It ensures faster inference using less memory.
Some common optimization techniques include:
Distillation – it teaches a smaller model (called the student model) from a larger model (called the teacher model)
Post-training quantization – it aims to reduce the precision of model weights
Pruning – it focuses on removing the model weights that have negligible impact
This stage of the LLM project lifecycle concludes with seamless integration of workflows, existing systems, and architectures. It ensures smooth accessibility and operation of the model.
Model Monitoring and Building LLM Applications
The LLM project lifecycle does not end at deployment. It is crucial to monitor the model’s performance in real-world situations and ensure its adaptability to evolving requirements. It also focuses on addressing any issues that arise and regularly updating the model parameters.
Finally, your model is ready for building robust LLM applications. These platforms can cater to diverse goals, including automated content creation, advanced predictive analysis, and other solutions to complex problems.
Summarizing the LLM Project Lifecycle
Hence, the roadmap to completing an LLM project lifecycle is a complex trajectory involving multiple stages. Each stage caters to a unique aspect of the model development process. The final goal is to create a customized and efficient machine-learning model to deploy and build innovative LLM applications.
Large Language Models have surged in popularity due to their remarkable ability to understand, generate, and interact with human language with unprecedented accuracy and fluency.
This surge is largely attributed to advancements in machine learning and the vast increase in computational power, enabling these models to process and learn from billions of words and texts on the internet.
OpenAI significantly shaped the landscape of LLMs with the introduction of GPT-3.5, marking a pivotal moment in the field. Unlike its predecessors, GPT-3.5 was not fully open-source, giving rise to closed-source large language models.
This move was driven by considerations around control, quality, and the commercial potential of such powerful models. OpenAI’s approach showcased the potential for proprietary models to deliver cutting-edge AI capabilities while also igniting discussions about accessibility and innovation.
The Introduction of Open-Source LLM
Contrastingly, companies like Meta and Mistral have opted for a different approach by releasing models like LLaMA and Mistral as open-source.
These models not only challenge the dominance of closed-source models like GPT-3.5 but also fuel the ongoing debate over which approach—open-source or closed-source—yields better results. Read more
By making their models openly available, Meta and similar entities encourage widespread innovation, allowing researchers and developers to improve upon these models, which in turn, has seen them topping performance leaderboards.
From an enterprise standpoint, understanding the differences between open-source LLM and closed-source LLM is crucial. The choice between the two can significantly impact an organization’s ability to innovate, control costs, and tailor solutions to specific needs.
Let’s dig in to understand the difference between Open-Source LLM and Closed Source LLM
What Are Open-Source Large Language Models?
Open-source large language models, such as the ones offered by Meta AI, provide a foundational AI technology that can analyze and generate human-like text by learning from vast datasets consisting of various written materials.
As open-source software, these language models have their source code and underlying architecture publicly accessible, allowing developers, researchers, and enterprises to use, modify, and distribute them freely.
Open-source projects allow anyone to contribute, from individual hobbyists to researchers and developers from various industries. This diversity in the contributor base brings a wide array of perspectives, skills, and needs into the project.
Innovation and Problem-Solving:
Different contributors may identify unique problems or have innovative ideas for applications that the original developers hadn’t considered. For example, someone might improve the model’s performance on a specific language or dialect, develop a new method for reducing bias, or create tools that make the model more accessible to non-technical users.
Discover how embeddings enhance open-source LLMs in our detailed guide here
2. Wide Range of Applications
Specialized Use Cases:
Contributors often adapt and extend open-source models for specialized use cases. For instance, a developer might fine-tune a language model on legal documents to create a tool that assists in legal research or on medical literature to support healthcare professionals.
New Features and Enhancements:
Through experimenting with the model, contributors might develop new features, such as more efficient training algorithms, novel ways to interpret the model’s outputs, or integration capabilities with other software tools.
3. Iterative Improvement and Evolution
Feedback Loop:
The open-source model encourages a cycle of continuous improvement. As the community uses and experiments with the model, they can identify shortcomings, bugs, or opportunities for enhancement. Contributions addressing these points can be merged back into the project, making the model more robust and versatile over time.
Collaboration and Knowledge Sharing:
Open-source projects facilitate collaboration and knowledge sharing within the community. Contributions are often documented and discussed publicly, allowing others to learn from them, build upon them, and apply them in new contexts.
Closed-source large language models, such as GPT-3.5 by OpenAI, embody advanced AI technologies capable of analyzing and generating human-like text through learning from extensive datasets.
Unlike their open-source counterparts, the source code and architecture of closed-source language models are proprietary, accessible only under specific terms defined by their creators. This exclusivity allows for controlled development, distribution, and usage.
For a deeper dive into the best large language models, check out our detailed guide here
Features of Closed-Sourced Large Language Models
1. Controlled Quality and Consistency
Centralized development: Closed-source projects are developed, maintained, and updated by a dedicated team, ensuring a consistent quality and direction of the project. This centralized approach facilitates the implementation of high standards and systematic updates.
Reliability and stability: With a focused team of developers, closed-source LLMs often offer greater reliability and stability, making them suitable for enterprise applications where consistency is critical.
2. Commercial Support and Innovation
Vendor support: Closed-source models come with professional support and services from the vendor, offering assistance for integration, troubleshooting, and optimization, which can be particularly valuable for businesses.
Proprietary innovations: The controlled environment of closed-source development enables the introduction of unique, proprietary features and improvements, often driving forward the technology’s frontier in specialized applications.
3. Exclusive Use and Intellectual Property
Competitive advantage: The proprietary nature of closed-source language models allows businesses to leverage advanced AI capabilities as a competitive advantage, without revealing the underlying technology to competitors.
Intellectual property protection: Closed-source licensing protects the intellectual property of the developers, ensuring that their innovations remain exclusive and commercially valuable.
4. Customization and Integration
Tailored solutions: While customization in closed-source models is more restricted than in open-source alternatives, vendors often provide tailored solutions or allow certain levels of configuration to meet specific business needs.
Seamless integration: Closed-source large language models are designed to integrate smoothly with existing systems and software, providing a seamless experience for businesses and end-users.
Open-Source vs Closed-Source LLMs for Enterprise Adoption
In terms of enterprise adoption, comparing open-source and closed-source large language models involves evaluating various factors such as costs, innovation pace, support, customization, and intellectual property rights.
Costs
Open-Source: Generally offers lower initial costs since there are no licensing fees for the software itself. However, enterprises may incur costs related to infrastructure, development, and potentially higher operational costs due to the need for in-house expertise to customize, maintain, and update the models.
Closed-Source: Often involves licensing fees, subscription costs, or usage-based pricing, which can predictably scale with use. While the initial and ongoing costs can be higher, these models frequently come with vendor support, reducing the need for extensive in-house expertise and potentially lowering overall maintenance and operational costs.
Innovation and Updates
Open-Source: The pace of innovation can be rapid, thanks to contributions from a diverse and global community. Enterprises can benefit from the continuous improvements and updates made by contributors. However, the direction of innovation may not always align with specific enterprise needs.
Closed-Source: Innovation is managed by the vendor, which can ensure that updates are consistent and high-quality. While the pace of innovation might be slower compared to the open-source community, it’s often more predictable and aligned with enterprise needs, especially for vendors closely working with their client base.
Discover the top LLM use cases to enhance your understanding here
Support and Reliability
Open-Source: Support primarily comes from the community, forums, and potentially from third-party vendors offering professional services. While there can be a wealth of shared knowledge, response times and the availability of help can vary.
Closed-Source: Typically comes with professional support from the vendor, including customer service, technical support, and even dedicated account management. This can ensure reliability and quick resolution of issues, which is crucial for enterprise applications.
Customization and Flexibility
Open-Source: Offer high levels of customization and flexibility, allowing enterprises to modify the models to fit their specific needs. This can be particularly valuable for niche applications or when integrating the model into complex systems.
Closed-Source: Customization is usually more limited compared to open-source models. While some vendors offer customization options, changes are generally confined to the parameters and options provided by the vendor.
Intellectual Property and Competitive Advantage
Open-Source: Using open-source models can complicate intellectual property (IP) considerations, especially if modifications are shared publicly. However, they allow enterprises to build proprietary solutions on top of open technologies, potentially offering a competitive advantage through innovation.
Closed-Source: The use of closed-source models clearly defines IP rights, with enterprises typically not owning the underlying technology. However, leveraging cutting-edge, proprietary models can provide a different type of competitive advantage through access to exclusive technologies.
Choosing Between Open-Source LLMs and Closed-Source LLMs
The choice between open-source and closed-source language models for enterprise adoption involves weighing these factors in the context of specific business objectives, resources, and strategic directions.
Open-source models can offer cost advantages, customization, and rapid innovation but require significant in-house expertise and management. Closed-source models provide predictability, support, and ease of use at a higher cost, potentially making them a more suitable choice for enterprises looking for ready-to-use, reliable AI solutions.
In the ever-evolving landscape of natural language processing (NLP), embedding techniques have played a pivotal role in enhancing the capabilities of language models.
The birth of Word Embeddings
Before venturing into the large number of embedding techniques that have emerged in the past few years, we must first understand the problem that led to the creation of such techniques.
Word embeddings were created to address the absence of efficient text representations for NLP models. Since NLP techniques operate on textual data, which inherently cannot be directly integrated into machine learning models designed to process numerical inputs, a fundamental question arose: how can we convert text into a format compatible with these models?
Basic approaches like one-hot encoding and Bag-of-Words (BoW) were employed in the initial phases of NLP development. However, these methods were eventually discarded due to their evident shortcomings in capturing the contextual and semantic nuances of language. Each word was treated as an isolated unit, without understanding its relationship with other words or its usage in different contexts.
Popular word embedding techniques
Word2Vec
In 2013, Google presented a new technique to overcome the shortcomings of the previous word embedding techniques, called Word2Vec. It represents words in a continuous vector space, better known as an embedding space, where semantically similar words are located close to each other.
This contrasted with traditional methods, like one-hot encoding, which represents words as sparse, high-dimensional vectors. The dense vector representations generated by Word2Vec had several advantages, including the ability to capture semantic relationships, support vector arithmetic (e.g., “king” – “man” + “woman” = “queen”), and improve the performance of various NLP tasks like language modeling, sentiment analysis, and machine translation.
Transition to GloVe and FastText
The success of Word2Vec paved the way for further innovations in the realm of word embeddings. The Global Vectors for Word Representation (GloVe) model, introduced by Stanford researchers in 2014, aimed to leverage global statistical information about word co-occurrences.
GloVe demonstrated improved performance over Word2Vec in capturing semantic relationships. Unlike Word2Vec, GloVe considers the entire corpus when learning word vectors, leading to a more global understanding of word relationships.
Fast forward to 2016, Facebook’s FastText introduced a significant shift by considering sub-word information. Unlike traditional word embeddings, FastText represented words as bags of character n-grams. This sub-word information allowed FastText to capture morphological and semantic relationships in a more detailed manner, especially for languages with rich morphology and complex word formations. This approach was particularly beneficial for handling out-of-vocabulary words and improving the representation of rare words.
The Rise of Transformer Models
The real game-changer in the evolution of embedding techniques came with the advent of the Transformer architecture. Introduced by researchers at Google in the form of the Attention is All You Need paper in 2017, Transformers demonstrated remarkable efficiency in capturing long-range dependencies in sequences.
The architecture laid the foundation for state-of-the-art models like OpenAI’s GPT (Generative Pre-trained Transformer) series and BERT (Bidirectional Encoder Representations from Transformers). Hence, the traditional understanding of embedding techniques is revamped with new solutions.
Impact of Embedding Techniques on Language Models
The embedding techniques mentioned above have significantly impacted the performance and capabilities of LLMs. Pre-trained models like GPT-3 and BERT leverage these embeddings to understand natural language context, semantics, and syntactic structures. The ability to capture context allows these models to excel in a wide range of NLP tasks, including sentiment analysis, text summarization, and question-answering.
Imagine the sentence: “The movie was not what I expected, but the plot twist at the end made it incredible.”
Traditional models might struggle with the negation of “not what I expected.” Word embeddings could capture some sentiment but might miss the subtle shift in sentiment caused by the positive turn of events in the latter part of the sentence.
In contrast, LLMs with contextualized embeddings can consider the entire sentence and comprehend the nuanced interplay of positive and negative sentiments. They grasp that the initial negativity is later counteracted by the positive twist, resulting in a more accurate sentiment analysis.
Advantages of Embeddings in LLMs
Contextual Understanding: LLMs equipped with embeddings comprehend the context in which words appear, allowing for a more nuanced interpretation of sentiment in complex sentences.
Semantic Relationships: Word embeddings capture semantic relationships between words, enabling the model to understand the subtleties and nuances of language.
Handling Ambiguity: Contextual embeddings help LLMs handle ambiguous language constructs, such as negations or sarcasm, contributing to improved accuracy in sentiment analysis.
Transfer Learning: The pre-training of LLMs with embeddings on vast datasets allows them to generalize well to various downstream tasks, including sentiment analysis, with minimal task-specific data.
How are Enterprises Using Embeddings in their LLM Processes?
In light of recent advancements, enterprises are keen on harnessing the robust capabilities of Large Language Models (LLMs) to construct comprehensive Software as a Service (SAAS) solutions. Nevertheless, LLMs come pre-trained on extensive datasets, and to tailor them to specific use cases, fine-tuning on proprietary data becomes essential.
This process can be laborious. To streamline this intricate task, the widely embraced Retrieval Augmented Generation (RAG) technique comes into play. RAG involves retrieving pertinent information from an external source, transforming it to a format suitable for LLM comprehension, and then inputting it into the LLM to generate textual output.
This innovative approach enables the fine-tuning of LLMs with knowledge beyond their original training scope.In this process, you need an efficient way to store, retrieve, and ingest data into your LLMs to use it accurately for your given use case.
One of the most common ways to store and search over unstructured data is to embed it and store the resulting embedding vectors, and then at query time to embed the unstructured query and retrieve the embedding vectors that are ‘most similar’ to the embedded query. Hence, without embedding techniques, your RAG approach will be impossible.
Understanding the Creation of Embeddings
Much like a machine learning model, an embedding model undergoes training on extensive datasets. Various models available can generate embeddings for you, and each model is distinct. You can find the top embedding models here.
It is unclear what makes an embedding model perform better than others. However, a common way to select one for your use case is to evaluate how many words a model can take in without breaking down. There’s a limit to how many tokens a model can handle at once, so you’ll need to split your data into chunks that fit within the limit. Hence, choosing a suitable model is a good starting point for your use case.
Creating embeddings with Azure OpenAI is a matter of a few lines of code. To create embeddings of a simple sentence like The food was delicious and the waiter…, you can execute the following code blocks:
First, import AzureOpenAI from OpenAI
Load in your environment variables
Create your Azure OpenAI client.
Create your embeddings
And you’re done! It’s really that simple to generate embeddings for your data. If you want to generate embeddings for an entire dataset, you can follow along with the great notebook provided by OpenAI itself here.
To Sum It Up!
The evolution of embeddingtechniques has revolutionized natural language processing, empowering language models with a deeper understanding of context and semantics. From Word2Vec to Transformer models, each advancement has enriched LLM capabilities, enabling them to excel in various NLP tasks.
Enterprises leverage techniques like Retrieval Augmented Generation, facilitated by embeddings, to tailor LLMs for specific use cases. Platforms like Azure OpenAI offer straightforward solutions for generating embeddings, underscoring their importance in NLP development. As we forge ahead, embeddings will remain pivotal in driving innovation and expanding the horizons of language understanding.
Imagine staring at a blank screen, the cursor blinking impatiently. You know you have a story to tell, but the words just won’t flow. You’ve brainstormed, outlined, and even consumed endless cups of coffee, but inspiration remains elusive. This was often the reality for writers, especially in the fast-paced world of blog writing.
In this struggle, enter chatbots as potential saviors, promising to spark ideas with ease. But their responses often felt generic, trapped in a one-size-fits-all format that stifled creativity. It was like trying to create a masterpiece with a paint-by-numbers kit.
Then comes Dynamic Few-Shot Prompting into the scene. This revolutionary technique is a game-changer in the creative realm, empowering language models to craft more accurate, engaging content that resonates with readers.
It addresses the challenges by dynamically selecting a relevant subset of examples for prompts, allowing for a tailored and diverse set of creative responses specific to user needs. Think of it as having access to a versatile team of writers, each specializing in different styles and genres.
Before moving forward, consider exploring our LLM Bootcamp to see how it can help you harness the power of large language models effectively.
Quick Prompting Test For You
To comprehend this exciting technique, let’s first delve into its parent concept: Few-shot prompting.
Few-Shot Prompting
Few-shot prompting is a technique in natural language processing that involves providing a language model with a limited set of task-specific examples, often referred to as “shots,” to guide its responses in a desired way. This means you can “teach” the model how to respond on the fly simply by showing it a few examples of what you want it to do.
In this approach, the user collects examples representing the desired output or behavior. These examples are then integrated into a prompt instructing the Large Language Model (LLM) on how to generate the intended responses.
The prompt, including the task-specific examples, is then fed into the LLM, allowing it to leverage the provided context to produce new and contextually relevant outputs.
Few-shot prompting at a glance
Unlike zero-shot prompting, where the model relies solely on its pre-existing knowledge, few-shot prompting enables the model to benefit from in-context learning by incorporating specific task-related examples within the prompt.
Dynamic Few-Shot Prompting: Taking It to the Next Level
Dynamic Few-Shot Prompting takes this adaptability a step further by dynamically selecting the most relevant examples based on the specific context of a user’s query. This means the model can tailor its responses even more precisely, resulting in more relevant and engaging content.
To choose relevant examples, various methods can be employed. In this blog, we’ll explore the semantic example selector, which retrieves the most relevant examples through semantic matching.
Enhancing adaptability with dynamic few-shot prompting
What Is the Importance of Dynamic Few-Shot Prompting?
The significance of Dynamic Few-Shot Prompting lies in its ability to address critical challenges faced by modern Large Language Models (LLMs). With limited context lengths in LLMs, processing longer prompts becomes challenging, requiring increased computational resources and incurring higher financial costs.
Dynamic Few-Shot Prompting optimizes efficiency by strategically utilizing a subset of training data, effectively managing resources. This adaptability allows the model to dynamically select relevant examples, catering precisely to user queries, resulting in more precise, engaging, and cost-effective responses.
A Closer Look (With Code!)
It’s time to get technical! Let’s delve into the workings of Dynamic Few-Shot Prompting using the LangChain Framework.
Importing necessary modules and libraries.
In the .env file, I have my OpenAI API key and base URL stored for secure access.
This code defines an example prompt template with input variables “user_query” and “blog_format” to be utilized in the FewShotPromptTemplate of LangChain.
user_query_1 = “Write a technical blog on topic [user topic]”
blog_format_1 = “””
**Title:** [Compelling and informative title related to user topic]
**Introduction:**
* Introduce the topic in a clear and concise way.
* State the problem or question that the blog will address.
* Briefly outline the key points that will be covered.
**Body:**
* Break down the topic into well-organized sections with clear headings.
* Use bullet points, numbered lists, and diagrams to enhance readability.
* Provide code examples or screenshots where applicable.
* Explain complex concepts in a simple and approachable manner.
* Use technical terms accurately, but avoid jargon that might alienate readers.
**Conclusion:**
* Summarize the main takeaways of the blog.
* Offer a call to action, such as inviting readers to learn more or try a new technique.
**Additional tips for technical blogs:**
* Use visuals to illustrate concepts and break up text.
* Link to relevant resources for further reading.
* Proofread carefully for accuracy and clarity.
“””
user_query_2 = “Write a humorous blog on topic [user topic]”
blog_format_2 = “””
**Title:** [Witty and attention-grabbing title that makes readers laugh before they even start reading]
**Introduction:**
* Set the tone with a funny anecdote or observation.
* Introduce the topic with a playful twist.
* Tease the hilarious insights to come.
**Body:**
* Use puns, wordplay, exaggeration, and unexpected twists to keep readers entertained.
* Share relatable stories and experiences that poke fun at everyday life.
* Incorporate pop culture references or current events for added relevance.
* Break the fourth wall and address the reader directly to create a sense of connection.
**Conclusion:**
* End on a high note with a punchline or final joke that leaves readers wanting more.
* Encourage readers to share their own funny stories or experiences related to the topic.
**Additional tips for humorous blogs:**
* Keep it light and avoid sensitive topics.
* Use visual humor like memes or GIFs.
* Read your blog aloud to ensure the jokes land.
“””
user_query_3 = “Write an adventure blog about a trip to [location]”
blog_format_3 = “””
**Title:** [Evocative and exciting title that captures the spirit of adventure]
**Introduction:**
* Set the scene with vivid descriptions of the location and its atmosphere.
* Introduce the protagonist (you or a character) and their motivations for the adventure.
* Hint at the challenges and obstacles that await.
**Body:**
* Chronicle the journey in chronological order, using sensory details to bring it to life.
* Describe the sights, sounds, smells, and tastes of the location.
* Share personal anecdotes and reflections on the experience.
* Build suspense with cliffhangers and unexpected twists.
* Capture the emotions of excitement, fear, wonder, and accomplishment.
**Conclusion:**
* Reflect on the lessons learned and the personal growth experienced during the adventure.
* Inspire readers to seek out their own adventures.
**Additional tips for adventure blogs:**
* Use high-quality photos and videos to showcase the location.
* Incorporate maps or interactive elements to enhance the experience.
* Write in a conversational style that draws readers in.
“””
These examples showcase different blog formats, each tailored to a specific genre. The three dummy examples include a technical blog template with a focus on clarity and code, a humorous blog template designed for entertainment with humor elements, and an adventure blog template emphasizing vivid storytelling and immersive details about a location.
While these are just three examples for simplicity, more formats can be added, to cater to diverse writing styles and topics. Instead of examples showcasing formats, original blogs can also be utilized as examples.
Next, we’ll compile a list from the crafted examples. This list will be passed to the example selector to store them in the vector store with vector embeddings. This arrangement enables semantic matching to these examples at a later stage.
Now initialize AzureOpenAIEmbeddings() for creating embeddings used in semantic similarity.
Now comes the example selector that stores the provided examples in a vector store. When a user asks a question, it retrieves the most relevant example based on semantic similarity. In this case, k=1 ensures only one relevant example is retrieved.
This code sets up a FewShotPromptTemplate for dynamic few-shot prompting in LangChain. The ExampleSelector is used to fetch relevant examples based on semantic similarity, and these examples are incorporated into the prompt along with the user query. The resulting template is then ready for generating dynamic and tailored responses.
Output
A sample output
This output gives an understanding of the final prompt that our LLM will use for generating responses. When the user query is “I’m writing a blog on Machine Learning. What topics should I cover?”, the ExampleSelector employs semantic similarity to fetch the most relevant example, specifically a template for a technical blog.
Hence the resulting prompt integrates instructions, the retrieved example, and the user query, offering a customized structure for crafting engaging content related to Machine Learning. With k=1, only one example is retrieved to shape the response.
As our prompt is ready, now we will initialize an Azure ChatGPT model to generate a tailored blog structure response based on a user query using dynamic few-shot prompting.
Output
Generative AI sample output
The LLM efficiently generates a blog structure tailored to the user’s query, adhering to the format of technical blogs, and showcasing how dynamic few-shot prompting can provide relevant and formatted content based on user input.
Conclusion
To conclude, Dynamic Few-Shot Prompting takes the best of two worlds (few-shot prompts and zero-shot prompts) and makes language models even better. It helps them understand your goals using smart examples, focusing only on relevant things according to the user’s query. This saves resources and opens the door for innovative use.
Dynamic Few-Shot Prompting adapts well to the token limitations of Large Language Models (LLMs) giving efficient results. As this technology advances, it will revolutionize the way Large Language Models respond, making them more efficient in various applications.
In a world of large language models (LLMs), deep double descent has created a new shift in understanding data and its position in deep learning models. A traditional LLM uses large amounts of data to train a machine-learning model, believing that bigger datasets lead to greater accuracy of results.
While OpenAI‘s GPT, Anthropic’s Claude, and Google’s Gemini are focused on using large amounts of training data for improved performance, the recent phenomenon of deep double descent presents an alternative picture. It makes you wonder about the significance of data in modern deep learning.
Before moving forward, consider exploring our comprehensive LLM Bootcamp to build hands-on skills and gain deeper insights into large language models.
Let’s dig deeper into understanding this phenomenon and its new perspective on the use of large datasets for model training.
What is Deep Double Descent?
It is a modern phenomenon in deep neural networks that presents its performance as a function of model complexity. Typically, a model improves its performance up to a certain point with an increasing amount of data. Beyond this point, the model output is expected to degrade due to overfitting.
The concept of double descent highlights that the performance of a model increases beyond the dip due to overfitting, and then degrades again. Hence, a neural network’s performance experiences a second descent with increasing data complexity.
Double descent curve – Source: ResearchGate
A typical pattern of deep double descent can be categorized as follows:
Underparametrized region – refers to the early stages of model training when the parameters are small in number. As the dataset increases in complexity, the model performance is enhanced, resulting in a decrease in the test error.
Overparametrized region – as the model training continues, the number of parameters increases. The increase in data complexity leads to model overfitting, resulting in the degradation of its performance.
Double descent region – it relates to the region beyond the overfitting of the training model. A further increase in data complexity increases the parameters for training, causing a second descent in test error that leads to enhancement in model performance.
The name of the phenomenon is rooted in the two descents of test error. The region towards the left of the interpolation point is called the classical regime. In this part, the bias-variance trade-off behaves expectedly. The region towards the right of the interpolation regime. In this region, the model perfectly memorizes the points of training data.
Understanding the Learning Lifecycle of a Model through Double Descent
As explained in an OpenAI article in 2019, the learning lifecycle of a training model can be explained using the double descent phenomenon. It explains how the test error varies during the iterations of a model’s testing and training.
Let’s look at the three main scenarios of the lifecycle and how each one impacts the training model.
Model-Wise Double Descent
A visual representation of model-wise double descent – Source: OpenAI
The scenario describes a phenomenon where the model is underparametrized. The model requires more parameters and complexity for improvement in results. A peak in test error occurs around the interpolation point and the model becomes large enough to fit the train set. It also indicates that changes in data complexity, like optimization algorithm, label noise, and the number of training sets can also impact the interpolation threshold and consequently the test error peak.
Sample-Wise Non-Monotonicity
Graphical view of sample-wise non-monotonicity – Source: OpenAI
It is the region where an increase in dataset and parameters degrades the model performance. The increase in samples requires larger models to fit the training model, moving the interpolation point to the right. It can be visualized with a shrunken area under the curve that also shifts towards the right.
Epoch-Wise Double Descent
It explains the transition of large models from under to over-parametrized regions. During this time, considerably large training models can experience double descent of the test error. As the number of epochs (training time) is increased, the effect of overfitting is reversed.
Hence, the phenomenon highlights how an increase in a dataset can damage model performance before improving it. It raises an important aspect of the deep model learning process, highlighting the importance of data choice for training. Since the optimization of the training process is crucial, it is essential to consider the deep double descent during model training.
Mitigation Strategies: Navigating Deep Double Descent Effectively
When dealing with the complexities of deep double descent, it’s essential to have a few key strategies up your sleeve to ensure your model performs reliably and avoids the pitfalls of overfitting. Here are some practical techniques you can apply:
Regularization: Employ L1 or L2 regularization to add a penalty for large weights, helping to control the model’s complexity and reduce the chances of overfitting.
Early Stopping: Keep an eye on your model’s validation performance and halt training as soon as the validation error starts to rise, which is a clear signal that overfitting might be setting in.
Adjusting Model Complexity: Fine-tune your model by tweaking the number of layers, neurons, or parameters to strike a balance between underfitting and overfitting, ensuring it aligns well with your dataset’s characteristics.
Dataset-Specific Adjustments: Remember, every dataset is different. Take the time to understand its unique properties and make necessary adjustments, such as data augmentation or balancing, to optimize model performance.
By implementing these strategies, you can effectively navigate the deep double descent curve and build models that are not only powerful but also robust and generalizable.
Are Small Language Models a Solution?
Since the double descent phenomenon indicates a degraded performance of training models with an increase in data, it has opened a new area of exploration for researchers. Data scientists need to dig deeper into this concept to understand the reasons for the two dips in test errors with larger datasets.
While the research is ongoing, there must be other solutions to consider. One such alternative can be in the form of small language models (SLMs). As they work with lowered data complexity and fewer parameters, they offer a solution where an increase in test errors and model degradation can be avoided. It can serve as an alternative solution while research continues to understand the recent phenomenon of double descent.
Imagine you’re running a customer support center, and your AI chatbot not only answers queries but does so by pulling the most up-to-date information from a live database. This isn’t science fiction—it’s the magic of Retrieval Augmented Generation (RAG)!
It is an innovative approach that bridges the gap between static knowledge and evolving information, enhancing the capabilities of large language models (LLM) with real-time access to external knowledge sources. This significantly reduces the chances of AI hallucinations and increases the reliability of generated content.
By integrating a powerful retrieval mechanism, RAG empowers AI systems to deliver informed, trustworthy, and up-to-date outputs, making it a game-changer for applications ranging from customer support to complex problem-solving in specialized domains.
What is Retrieval Augmented Generation?
Retrieval Augmented Generation (RAG) is an advanced technique in the field of generative AI that enhances the capabilities of LLMs by integrating a retrieval mechanism to access external knowledge sources in real-time.
Instead of relying solely on static, pre-loaded training data, RAG dynamically fetches the most current and relevant information to generate precise, contextually accurate responses. Hence, integrating RAG’s retrieval-based and generation-based approaches provides a robust database for LLMs.
Using RAG as one of the NLP techniques helps to ensure that the responses are grounded in factual information, reducing the likelihood of generating incorrect or misleading answers (hallucinations). Additionally, it provides the ability to access the latest information without the need for frequent retraining of the model.
Hence, retrieval augmented generation has redefined the standard for information search and navigation with LLMs.
Source: LinkedIn
How Does RAG Work?
A RAG model operates in two main phases: the retrieval phase and the generation phase. These phases work together to enhance the accuracy and relevance of the generated responses.
1. Retrieval Phase
The retrieval phase fetches relevant information from an external knowledge base. This phase is crucial because it provides contextually relevant data to the LLM. Algorithms search for and retrieve snippets of information that are relevant to the user’s query.
These snippets come from various sources like databases, document repositories, and the internet. The retrieved information is then combined with the user’s prompt and passed on to the LLM for further processing.
This leads to the creation of high-performing LLM applications that have access to the latest and most reliable information, minimizing the chances of generating incorrect or misleading responses. Some key components of the retrieval phase include:
Embedding models play a vital role in the retrieval phase by converting user queries and documents into numerical representations, known as vectors. This conversion process is called embedding. The embeddings capture the semantic meaning of the text, allowing for efficient searching within a vector database.
By representing both the query and the documents as vectors, the system can perform mathematical operations to find the closest matches, ensuring that the most relevant information is retrieved.
Vector Database and Knowledge Library
The vector database is specialized to store these embeddings as it can handle high-dimensional data representations. The database can quickly search through these vectors to retrieve the most relevant information.
This fast and accurate retrieval is made possible because the vector database indexes the embeddings in a way that allows for efficient similarity searches. This setup ensures that the system can provide timely and accurate responses based on the most relevant data from the knowledge library.
Unlike traditional keyword searches, semantic search understands the intent behind the user’s query. It uses embeddings to find contextually appropriate information, even if the exact keywords are not present.
This capability ensures that the retrieved information is not just a literal match but is also semantically relevant to the query. By focusing on the meaning and context of the query, semantic search improves the accuracy and relevance of the information retrieved from the knowledge library.
2. Generation Phase
In the generation phase, the retrieved information is combined with the original user query and fed into the LLM. This process ensures that the LLM has access to both the context provided by the user’s query and the additional, relevant data fetched during the retrieval phase.
This integration allows the LLM to generate responses that are more accurate and contextually relevant, as it can draw from the most current and authoritative information available. These responses are generated through the following steps:
Augmented Prompt Construction
To construct an augmented prompt, the retrieved information is combined with the user’s original query. This involves appending the relevant data to the query in a structured format that the LLM can easily interpret.
This augmented prompt provides the LLM with all the necessary context, ensuring that it has a comprehensive understanding of the query and the related information.
Response Generation Using the Augmented Prompt
Once the augmented prompt is prepared, it is fed into the LLM. The language model leverages its pretrained capabilities along with the additional context provided by the retrieved information to better understand the query.
The combination enables the LLM to generate responses that are not only accurate but also contextually enriched, drawing from both its internal knowledge and the external data provided.
Explore how LLM RAG works to make language models enterprise-ready
Hence, the two phases are closely interlinked.
The retrieval phase provides the essential context and factual grounding needed for the generation phase to produce accurate and relevant responses. Without the retrieval phase, the LLM might rely solely on its training data, leading to outdated or less accurate answers.
Meanwhile, the generation phase uses the context provided by the retrieval phase to enhance its outputs, making the entire system more robust and reliable. Hence, the two phases work together to enhance the overall accuracy of LLM responses.
Technical Components in Retrieval Augmented Generation
While we understand how RAG works, let’s take a closer look at the key technical components involved in the process.
Embedding Models
Embedding models are essential in ensuring a high RAG performance with efficient search and retrieval responses. Some popular embedding models in RAG are:
OpenAI’s text-embedding-ada-002: This model generates high-quality text embeddings suitable for various applications.
Jina AI’s jina-embeddings-v2: Offered by Jina AI, this model creates embeddings that capture the semantic meaning of text, aiding in efficient retrieval tasks.
SentenceTransformers’ multi-QA models: These models are part of the SentenceTransformers library and are optimized for producing embeddings effective in question-answering scenarios.
These embedding models help in converting text into numerical representations, making it easier to search and retrieve relevant information in RAG systems.
Vector Stores
Vector stores are specialized databases designed to handle high-dimensional data representations. Here are some common vector stores used in RAG implementations:
Facebook’s FAISS
FAISS is a library for efficient similarity search and clustering of dense vectors. It helps in storing and retrieving large-scale vector data quickly and accurately.
Chroma DB
Chroma DB is another vector store that specializes in handling high-dimensional data representations. It is optimized for quick retrieval of vectors.
Pinecone
Pinecone is a fully managed vector database that allows you to handle high-dimensional vector data efficiently. It supports fast and accurate retrieval based on vector similarity.
Weaviate
Weaviate is an open-source vector search engine that supports various data formats. It allows for efficient vector storage and retrieval, making it suitable for RAG implementations.
Prompt engineering is a crucial component in RAG as it ensures effective communication with an LLM. High-quality prompting skills train your language model to generate high-quality responses that are well-aligned with the user’s needs.
Here’s how prompt engineering can enhance your LLM performance:
Tailoring Functionality
A well-crafted prompt helps in tailoring the LLM’s functionalities to better align with the user’s intent. This ensures that the model understands the query precisely and generates a relevant response.
Contextual Relevance
In Retrieval-Augmented Generation (RAG) systems, the prompt includes the user’s query along with relevant contextual information retrieved from the semantic search layer. This enriched prompt helps the LLM to generate more accurate and contextually relevant responses.
Reducing Hallucinations
Effective prompt engineering can reduce the chances of the LLM generating inaccurate or hallucinated responses. By providing clear and specific instructions, the prompt guides the LLM to focus on the relevant information.
Improving Interaction
A good prompt structure can improve the interaction between the user and the LLM. For example, a prompt that clearly sets the context and intent will enable the LLM to understand and respond correctly, enhancing the overall user experience.
Here’s a 10-step guide for you to become an expert prompt engineer
Bringing these components together ensures an effective implementation of RAG to enhance the overall efficiency of a language model.
Comparing RAG and Fine-Tuning
While RAG LLM integrates real-time external data to improve responses, Fine-Tuning sharpens a model’s capabilities through specialized dataset training. Understanding the strengths and limitations of each method is essential for developers and researchers to fully leverage AI.
Some key points of comparison are listed below.
Adaptability to Dynamic Information
RAG is great at keeping up with the latest information. It pulls data from external sources, making it super responsive to changes—perfect for things like news updates or financial analysis. Since it uses external databases, you get accurate, up-to-date answers without needing to retrain the model constantly.
On the flip side, fine-tuning needs regular updates to stay relevant. Once you fine-tune a model, its knowledge is as current as the last training session. To keep it updated with new info, you have to retrain it with fresh datasets. This makes fine-tuning less flexible, especially in fast-changing fields.
Customization and Linguistic Style
Fine-tuning is great for personalizing models to specific domains or styles. It trains on curated datasets, making it perfect for creating outputs that match unique terminologies and tones.
This is ideal for applications like customer service bots that need to reflect a company’s specific communication style or educational content aligned with a particular curriculum.
Meanwhile, RAG focuses on providing accurate, up-to-date information from external sources. While it excels in factual accuracy, it doesn’t tailor linguistic style as closely to specific user preferences or domain-specific terminologies without extra customization.
Data Efficiency and Requirements
RAG is efficient with data because it pulls information from external datasets, so it doesn’t need a lot of labeled training data. Instead, it relies on the quality and range of its connected databases, making the initial setup easier. However, managing and querying these extensive data repositories can be complex.
Fine-tuning, on the other hand, requires a large amount of well-curated, domain-specific training data. This makes it less data-efficient, especially when high-quality labeled data is hard to come by.
Efficiency and Scalability
RAG is generally considered cost-effective and efficient for many applications. It can access and use up-to-date information from external sources without needing constant retraining, making it scalable across diverse topics. However, it requires sophisticated retrieval mechanisms and might introduce some latency due to real-time data fetching.
Fine-tuning needs a significant initial investment in time and resources to prepare the domain-specific dataset. Once tuned, the model performs efficiently within its specialized area. However, adapting it to new domains requires additional training rounds, which can be resource-intensive.
Domain-Specific Performance
RAG excels in versatility, handling queries across various domains by fetching relevant information from external databases. It’s robust in scenarios needing access to a wide range of continuously updated information.
Fine-tuning is perfect for achieving precise and deep domain-specific expertise. Training on targeted datasets, ensures highly accurate outputs that align with the domain’s nuances, making it ideal for specialized applications.
Hybrid Approach
A hybrid model that blends the benefits of RAG and fine-tuning is an exciting development. This method enriches LLM responses with current information while also tailoring outputs to specific tasks.
It can function as a versatile system or a collection of specialized models, each fine-tuned for particular uses. Although it adds complexity and demands more computational resources, the payoff is in better accuracy and deep domain relevance.
Hence, both RAG and fine-tuning have distinct advantages and limitations, making them suitable for different applications based on specific needs and desired outcomes. Plus, there is always a hybrid approach to explore and master as you work through the wonders of RAG and fine-tuning.
Benefits of RAG
While retrieval augmented generation improves LLM responses, it offers multiple benefits to enhance an enterprise’s experience with generative AI integration. Let’s look at some key advantages of RAG in the process.
Explore RAG and its benefits, trade-offs, use cases, and enterprise adoption, in detail with our podcast!
Cost-Effective Implementation
RAG is a game-changer when it comes to cutting costs. Unlike traditional LLMs that need expensive and time-consuming retraining to stay updated, RAG pulls the latest information from external sources in real time.
By tapping into existing databases and retrieval systems, RAG provides a more affordable and accessible solution for keeping generative AI up-to-date and useful across various applications.
Example
Imagine a customer service department using an LLM to handle inquiries. Traditionally, they would need to retrain the model regularly to keep up with new product updates, which is costly and resource-intensive.
With RAG, the model can instantly pull the latest product information from the company’s database, providing accurate answers without the hefty retraining costs. This not only saves money but also ensures customers always get the most current information.
Providing Current and Accurate Information
RAG shines in delivering up-to-date information by connecting to external data sources. Unlike static LLMs, which rely on potentially outdated training data, RAG continuously pulls relevant info from live databases, APIs, and real-time data streams. This ensures that responses are both accurate and current.
Example
Imagine a marketing team that needs the latest social media trends for their campaigns. Without RAG, they would rely on periodic model updates, which might miss the latest buzz.
However, RAG gives instant access to live social media feeds and trending news, ensuring their strategies are always based on the most current data. It keeps the campaigns relevant and effective by integrating the latest research and statistics.
Enhancing User Trust
RAG boosts user trust by ensuring accurate responses and citing sources. This transparency lets users verify the information, building confidence in the AI’s outputs. It reduces the chances of presenting false information, a common problem with traditional LLMs. This traceability enhances the AI’s credibility and trustworthiness.
Example
Consider a healthcare organization using AI to offer medical advice. Traditionally, the AI might give outdated or inaccurate advice due to old training data. With RAG, the AI can pull the latest medical research and guidelines, citing these sources in its responses.
This ensures patients receive accurate, up-to-date information and can trust the advice given, knowing it’s backed by reliable sources. This transparency and accuracy significantly enhance user trust in the AI system.
Offering More Control for Developers
RAG gives developers more control over the information base and the quality of outputs. They can tailor the data sources accessed by the LLM, ensuring that the information retrieved is relevant and appropriate.
This flexibility allows for better alignment with specific organizational needs and user requirements. Developers can also restrict access to sensitive data, ensuring it is handled properly. This control also extends to troubleshooting and optimizing the retrieval process, enabling refinements for better performance and accuracy.
Example
For instance, developers at a financial services company can use RAG to ensure the AI pulls data only from trusted financial news sources and internal market analysis reports.
They can also restrict access to confidential client data. This tailored approach ensures the AI provides relevant, accurate, and secure investment advice that meets both company standards and client needs.
Thus, RAG brings several benefits that make it a top choice for improving LLMs. As organizations look for more reliable and adaptable AI solutions, RAG efficiently meets these needs.
Frameworks for Retrieval Augmented Generation
A RAG system combines a retrieval model with a generation model. Developers use frameworks and libraries available online to implement the required retrieval system. Let’s take a look at some of the common resources used for it.
Hugging Face Transformers
It is a popular library of pre-trained models for different tasks. It includes retrieval models like Dense Passage Retrieval (DPR) and generation models like GPT. The transformer allows the integration of these systems to generate a unified retrieval augmented generation model.
Facebook AI Similarity Search (FAISS)
FAISS is used for similarity search and clustering dense vectors. It plays a crucial role in building retrieval components of a system. Its use is preferred in models where vector similarity is crucial for the system.
PyTorch and TensorFlow
These are commonly used deep learning frameworks that offer immense flexibility in building RAG models. They enable the developers to create retrieval and generation models separately. Both models can then be integrated into a larger framework to develop a RAG model.
Haystack
It is a Python framework that is built on Elasticsearch. It is suitable to build end-to-end conversational AI systems. The components of the framework are used for storage of information, retrieval models, and generation models.
Applications of Retrieval-Augmented Generation
Building LLM applications has never been more exciting, thanks to the revolutionary approach known as Retrieval Augmented Generation (RAG). By merging the strengths of information retrieval and text generation, RAG is significantly enhancing the capabilities of LLMs.
This innovative technique is transforming various domains, making LLM applications more accurate, reliable, and contextually aware. Let’s explore how RAG is making a profound impact across multiple fields.
Enhancing Customer Service Chatbots
Customer service chatbots are one of the most prominent beneficiaries of RAG. By leveraging RAG, these chatbots can provide more accurate and reliable responses, greatly enhancing user experience.
RAG lets chatbots pull up-to-date information from various sources. For example, a retail chatbot can access the latest inventory and promotions, giving customers precise answers about product availability and discounts.
By using verified external data, RAG ensures chatbots provide accurate information, building user trust. Imagine a financial services chatbot offering real-time market data to give clients reliable investment advice.
It primarily deals with writing articles and blogs. It is one of the most common uses of LLM where the retrieval models are used to generate coherent and relevant content. It can lead to personalized results for users that include real-time trends and relevant contextual information.
Real-Time Commentary
A retriever uses APIs to connect real-time information updates with an LLM. It is used to create a virtual commentator which can be integrated further to create text-to-speech models. IBM used this mechanism during the US Open 2023 for live commentary.
Question Answering System
Source: Medium
The ability of LLMs to generate contextually relevant content enables the retrieval model to function as a question-answering machine. It can retrieve factual information from an extensive knowledge base to create a comprehensive answer.
Language Translation
Translation is a tricky process. A retrieval model can detect the context of phrases and words, enabling the generation of relevant translations. Access to external databases ensures the results are accurate and fluent for the users. The extensive information on available idioms and phrases in multiple languages ensures this use case of the retrieval model.
Implementations in Knowledge Management Systems
Knowledge management systems greatly benefit from the implementation of RAG, as it aids in the efficient organization and retrieval of information.
RAG can be integrated into knowledge management systems to improve the search and retrieval of information. For example, a corporate knowledge base can use RAG to provide employees with quick access to the latest company policies, project documents, and best practices.
The educational arena can also use these RAG-based knowledge management systems to extend their question-answering functionality. This RAG application uses the system for educational queries of users, generating academic content that is more comprehensive and contextually relevant.
As organizations look for reliable and flexible AI solutions, RAG’s uses will keep growing, boosting innovation and efficiency.
Challenges and Solutions in RAG
Let’s explore common issues faced during the implementation of the RAG framework and provide practical solutions and troubleshooting tips to overcome these hurdles.
Common Issues Faced During Implementation
One significant issue is the knowledge gap within organizations since RAG is a relatively new technology, leading to slow adoption rates and potential misalignment with business goals.
Moreover, the high initial investment and ongoing operational costs associated with setting up specialized infrastructure for information retrieval and vector databases make RAG less accessible for smaller enterprises.
Another challenge is the complexity of data modeling for both structured and unstructured data within the knowledge library and vector database. Incorrect data modeling can result in inefficient retrieval and poor performance, reducing the effectiveness of the RAG system.
Furthermore, handling inaccuracies in retrieved information is crucial, as errors can erode trust and user satisfaction. Scalability and performance also pose challenges; as data volume grows, ensuring the system scales without compromising performance can be difficult, leading to potential bottlenecks and slower response times.
You can start by improving the knowledge of RAG at an organizational level through collaboration with experts. A team can be dedicated to pilot RAG projects, allowing them to develop expertise and share knowledge across the organization.
Moreover, RAG proves more cost-effective than frequently retraining LLMs. Focus on the long-term benefits and ROI of a more accurate and reliable system, and consider using cloud-based solutions like Oracle’s OCI Generative AI service for predictable performance and pricing.
You can also develop clear data modeling strategies that integrate both structured and unstructured data, utilizing vector databases like FAISS or Chroma DB for high-dimensional data representations. Regularly review and update data models to align with evolving RAG system needs, and use embedding models for efficient retrieval.
Another aspect is establishing feedback loops to monitor user responses and flag inaccuracies for review and correction.
While implementing RAG can present several challenges, understanding these issues and proactively addressing them can lead to a successful deployment. Organizations must harness the full potential of RAG to deliver accurate, contextually relevant, and up-to-date information.
Future of RAG
RAG is rapidly evolving, and its future looks exciting. Some key aspects include:
RAG incorporates various data types like text, images, audio, and video, making AI responses richer and more human-like.
Enhanced retrieval techniques such as Hybrid Search combine keyword and semantic searches to fetch the most relevant information.
Parameter-efficient fine-tuning methods like Low-Rank Adaptation (LoRA) are making it cheaper and easier for organizations to customize AI models.
Looking ahead, RAG is expected to excel in real-time data integration, making AI responses more current and useful, especially in dynamic fields like finance and healthcare. We’ll see its expansion into new areas such as law, education, and entertainment, providing specialized content tailored to different needs.
Moreover, as RAG technology becomes more powerful, ethical AI development will gain focus, ensuring responsible use and robust data privacy measures. The integration of RAG with other AI methods like reinforcement learning will further enhance AI’s adaptability and intelligence, paving the way for smarter, more accurate systems.
Hence, retrieval augmented generation is an important aspect of large language models within the arena of generative AI. It has improved the overall content processing and promises an improved architecture of LLMs in the future.
The integration of artificial intelligence (AI) with healthcare is revolutionizing precision medicine, offering unprecedented possibilities through the use of vector databases. These databases are designed to handle complex, high-dimensional data, making them an essential tool for personalized healthcare solutions.
By transforming intricate medical data into vectors, they enable advanced analytics and insights, facilitating improved patient outcomes through precision medicine. This blog delves into the technical details of how AI in healthcare empowers patient similarity searches and paves the path for precision medicine.
Explore 10 AI startups revolutionizing healthcare you should know about
What are Vector Databases?
Vector databases are specialized databases designed to store and manage high-dimensional vector data, crucial for handling complex and unstructured data like text, video, and audio. Unlike traditional databases, which focus on precise queries, vector databases excel in similarity searches using advanced indexing techniques such as Hierarchical Navigable Small Worlds (HNSW).
They transform data into numerical arrays, or vector embeddings, which capture essential features and relationships, allowing for efficient retrieval and analysis. These databases are particularly beneficial for AI applications requiring real-time data processing, such as Retrieval Augmented Generation (RAG).
Their ability to manage complex data efficiently makes them a transformative technology in fields like precision medicine and AI, offering enhanced scalability, security, and trust compared to traditional databases
Source: kdb.ai
Limitations of Traditional Databases
Traditional databases, such as relational databases, have significant limitations when applied to precision medicine and other AI-driven healthcare applications. They are primarily designed to manage structured data, which makes them efficient for handling transactions and maintaining records but less suitable for the unstructured and semi-structured data prevalent in healthcare.
Traditional databases struggle with scalability when dealing with large volumes of complex and high-dimensional data, such as genomic sequences or medical imaging, which are crucial for precision medicine. Additionally, their reliance on structured query languages limits their ability to perform the similarity searches required for advanced medical diagnostics and personalized treatments.
Vector Databases in Precision Medicine
Vector databases are revolutionizing healthcare data management. Unlike traditional, table-like structures, they excel at handling the intricate, multi-dimensional nature of patient information. Each patient becomes a unique point in a high-dimensional space, defined by their genetic markers, lab values, and medical history.
This dense representation unlocks powerful capabilities discussed later. Working with vector data is tough because regular databases, which usually handle one piece of information at a time, can’t handle the complexity and large amount of this type of data. This makes it hard to find important information and analyze it quickly.
That’s where vector databases come in handy—they are made on purpose to handle this special kind of data. They give you the speed, ability to grow, and flexibility you need to get the most out of your data.
Patient Similarity Search with Vector Databases
In vector databases, complex data such as medical records, genomic information, and clinical notes are transformed into vectors. These vectors act as numerical representations capturing essential features and relationships of the data.
The similarity between vectors is determined using metrics like Euclidean distance and cosine similarity. These measures help assess how closely two patient profiles are related based on their vector representations.
Vector databases use advanced indexing methods, such as Hierarchical Navigable Small Worlds (HNSW), to efficiently search for similar vectors. This indexing reduces the need to compare every vector, allowing for faster retrieval of similar patient profiles.
Personalized Treatment Plans
By uncovering patients with comparable profiles and treatment outcomes, doctors can tailor interventions with greater confidence and optimize individual care. It also serves as handy for medical researchers to look for efficient cures or preventions for a disease diagnosed over multiple patients by analyzing their data, particularly for a certain period.Here’s how vector databases transform treatment plans:
Precise Targeting: By comparing a patient’s vector to those of others who have responded well to specific treatments, doctors can identify the most promising options with laser-like accuracy. This reduces the guesswork and minimizes the risk of ineffective therapies.
Predictive Insights: Vector databases enable researchers to analyze the trajectories of similar patients, predicting their potential responses to different treatments. This foresight empowers doctors to tailor interventions, preventing complications and optimizing outcomes proactively.
Unlocking Untapped Potential: By uncovering hidden connections between seemingly disparate data points, vector databases can reveal new therapeutic targets and treatment possibilities. This opens doors for personalized medicine breakthroughs that were previously unimaginable.
Dynamic Adaptation: As a patient’s health evolves, their vector map shifts and readjusts accordingly. This allows for real-time monitoring and continuous refinement of treatment plans, ensuring the best possible care at every stage of the journey.
Drug Discovery and Repurposing
Identifying patients similar to those successfully treated with a specific drug can accelerate clinical trials and uncover unexpected connections for existing medications. Vector Databases can accelerate exploration, repurpose potential, and provide personalized insights and predictions.
Accelerated exploration: They transform complex drug and disease data into dense vectors, allowing for rapid similarity searches and the identification of promising drug candidates. Imagine sifting through millions of molecules at a single glance, pinpointing those with properties similar to those of known effective drugs.
Repurposing potential: Vector databases can unearth hidden connections between existing drugs and potential new applications. By comparing drug vectors to disease vectors, they can reveal unexpected repurposing opportunities, offering a faster and cheaper path to new treatments.
Personalization insights: By weaving genetic and patient data into the drug discovery tapestry, vector databases can inform the development of personalized medications tailored to individual needs and responses. This opens the door to a future where treatments are as unique as the patients themselves.
Predictive power: Analyzing the molecular dance within the vector space can unveil potential side effects and predict drug efficacy before entering clinical trials. This helps navigate the treacherous waters of development, saving time and resources while prioritizing promising candidates.
Cohort Analysis in Research
Grouping patients with similar characteristics facilitates targeted research efforts, leading to faster breakthroughs in disease understanding and treatment development. This indicates a strong understanding of exploring disease mechanisms and unveiling hidden patterns.
Exploring Disease Mechanisms: Vector databases facilitate the identification of patient clusters that share similar disease progression patterns. This can shed light on underlying disease mechanisms and guide the development of novel diagnostic markers and therapeutic target
Unveiling Hidden Patterns: Vector databases excel at similarity search, enabling researchers to pinpoint patients with similar clinical trajectories, even if they don’t share the same diagnosis or traditional risk factors. This reveals hidden patterns that might have been overlooked in traditional data analysis methods.
Genomic Data Integration
In precision medicine, vector databases play a crucial role in genomic data integration by storing and analyzing high-dimensional genomic data. These databases can efficiently handle vast amounts of genetic information, enabling researchers to gain genetic insights that pave the way for personalized treatment plans.
By integrating diverse genomic datasets, vector databases facilitate a more comprehensive understanding of genetic variations and their implications on health outcomes. This integration is instrumental in enabling precision medicine, where treatments are tailored to individual genetic profiles, thereby enhancing therapeutic efficacy and minimizing adverse effects.
Predictive Diagnostics
Predictive diagnostics benefit significantly from vector databases through the use of vector embeddings for early disease detection. By transforming complex patient data into numerical vectors, these databases can identify patterns and correlations that might indicate the early stages of diseases such as cancer.
For example, vector databases can be employed to predict cancer progression by analyzing genetic markers and patient history, thereby identifying high-risk patients who may benefit from preventive interventions. This capability allows healthcare providers to take proactive measures, potentially improving patient outcomes through timely interventions and personalized care strategies.
Medical Imaging Analysis
Vector databases enhance medical imaging analysis by vectorizing imaging data such as X-rays and MRIs, facilitating faster and more accurate diagnoses. By converting imaging data into vectors, these databases enable efficient comparison and analysis of patient scans to identify abnormalities.
For instance, by comparing current patient scans against a database of historical images, clinicians can quickly detect deviations or patterns indicative of specific health conditions, speeding up diagnostic processes and improving accuracy.
Semantic Search in Medical Records
Semantic search in medical records is another area where vector databases prove invaluable. By utilizing vector-based semantic search capabilities, healthcare providers can efficiently retrieve relevant patient records and simplify access to complex medical histories.
This approach allows for a more intuitive search experience, enabling medical professionals to quickly locate necessary information based on semantic relevance rather than exact match keywords. As a result, clinicians can gain a comprehensive understanding of a patient’s medical history, leading to more informed decision-making and improved patient care outcomes.
Technicalities of Vector Databases
Using a vector database enables the incorporation of advanced functionalities into our artificial intelligence, such as semantic information retrieval and long-term memory. The diagram provided below enhances our comprehension of the significance of vector databases in such applications.
Initially, we employ the embedding model to generate vector embeddings for the content intended for indexing.
The resulting vector embedding is then placed into the vector database, referencing the original content from which the embedding was derived.
Upon receiving a query from the application, we utilize the same embedding model to create embeddings for the query. These query embeddings are subsequently used to search the database for similar vector embeddings. As previously noted, these analogous embeddings are linked to the initial content from which they were created.
In comparison to the working of a traditional database, where data is stored as common data types like string, integer, date, etc. Users query the data by comparing each row; the result of this query is the rows where the condition of the query is withheld.
In vectordatabases, this process of querying is more optimized and efficient with the use of a similaritymetric for searching the most similarvectorto our query. The search involves a combination of various algorithms, like approximate nearest neighbor optimization, which uses hashing, quantization, and graph-based detection.
Here are a few key components of the discussed process described below:
Feature engineering: Transforming raw clinical data into meaningful numerical representations suitable for vector space. This may involve techniques like natural language processing for medical records or dimensionality reduction for complex biomolecular data.
Distance metrics: Choosing the appropriate distance metric to calculate the similarity between patient vectors. Popular options include Euclidean distance, cosine similarity, and Manhattan distance, each capturing different aspects of the data relationships.
Source: Camelot
Cosine Similarity: Calculates the cosine of the angle between two vectors in a vector space. It varies from -1 to 1, with 1 indicating identical vectors, 0 denoting orthogonal vectors, and -1 representing diametrically opposed vectors.
Euclidean Distance: Measures the straight-line distance between two vectors in a vector space. It ranges from 0 to infinity, where 0 signifies identical vectors and larger values indicate increasing dissimilarity between vectors.
Dot Product: Evaluate the product of the magnitudes of two vectors and the cosine of the angle between them. Its range is from -∞ to ∞, with a positive value indicating vectors pointing in the same direction, 0 representing orthogonal vectors, and a negative value signifying vectors pointing in opposite directions.
Nearest neighbor search algorithms: Efficiently retrieving the closest patient vectors to a given query. Techniques like k-nearest neighbors (kNN) and Annoy trees excel in this area, enabling rapid identification of similar patients.
A general pipeline from storing vectors to querying them is shown in the figure below:
Pipeline for vector database – Source: pinecone.io
Indexing: The vector database utilizes algorithms like PQ, LSH, or HNSW (detailed below) to index vectors. This process involves mapping vectors to a data structure that enhances search speed.
Querying: The vector database examines the indexed query vector against the dataset’s indexed vectors, identifying the nearest neighbors based on a similarity metric employed by that specific index.
Post Processing: In certain instances, the vector database retrieves the ultimate nearest neighbors from the dataset and undergoes post-processing to deliver the final results. This step may involve re-evaluating the nearest neighbors using an alternative similarity measure.
Challenges in Implementing Vector Databases for Precision Medicine
Navigating the landscape of challenges and considerations is crucial for effective decision-making and strategic planning in any endeavor. While vector databases offer immense potential, challenges remain:
Data Privacy and Security
Safeguarding patient data while harnessing its potential for enhanced healthcare outcomes requires the implementation of robust security protocols and careful consideration of ethical standards. This involves establishing comprehensive measures to protect sensitive information, ensuring secure storage, and implementing stringent access controls.
Additionally, ethical considerations play a pivotal role, emphasizing the importance of transparent data handling practices, informed consent procedures, and adherence to privacy regulations. As healthcare organizations leverage the power of data to advance patient care, a meticulous approach to security and ethics becomes paramount to fostering trust and upholding the integrity of the healthcare ecosystem.
Explainability and Interoperability
Gaining insight into the reasons behind patient similarity is essential for informed clinical decision-making. It is crucial to develop transparent models that not only analyze the “why” behind these similarities but also offer insights into the importance of features within the vector space.
This transparency ensures a comprehensive understanding of the factors influencing patient similarities, contributing to more effective and reasoned clinical decisions. Integration with existing infrastructure: Seamless integration with legacy healthcare systems is essential for the practical adoption of vector database technology.
AI in Healthcare – Opening Avenues for Precision Medicine
In summary, the integration of artificial intelligence or vector databases in healthcare is revolutionizing patient care and diagnostics. Overcoming the limitations of traditional systems, these databases enable efficient handling of complex patient data, leading to precise treatment plans, accelerated drug discovery, and enhanced research capabilities.
While the technical aspects showcase the sophistication of these systems, challenges such as data privacy and seamless integration with existing infrastructure need attention. Despite these hurdles, the potential benefits promise a significant impact on personalized medicine and improved healthcare outcomes.
Large language models (LLMs) are a fascinating aspect of machine learning. Selective prediction in large language models refers to the model’s ability to generate specific predictions or responses based on the given input.
This means that the model can focus on certain aspects of the input text to make more relevant or context-specific predictions. For example, if asked a question, the model will selectively predict an answer relevant to that question, ignoring unrelated information.
They function by employing deep learning techniques and analyzing vast datasets of text. Here’s a simple breakdown of how they work:
Architecture: LLMs use a transformer architecture, which is highly effective in handling sequential data like language. This architecture allows the model to consider the context of each word in a sentence, enabling more accurate predictions and the generation of text.
Training: They are trained on enormous amounts of text data. During this process, the model learns patterns, structures, and nuances of human language. This training involves predicting the next word in a sentence or filling in missing words, thereby understanding language syntax and semantics.
Understand the LLM Guide as a beginner resource to top technology
Capabilities: Once trained, LLMs can perform a variety of tasks such as translation, summarization, question answering, and content generation. They can understand and generate text in a way that is remarkably similar to human language.
How Selective Predictions Work in LLMs
Selective prediction in the context of large language models (LLMs) is a technique aimed at enhancing the reliability and accuracy of the model’s outputs. Here’s how it works in detail:
Decision to Predict or Abstain
Selective prediction serves as a vital mechanism in LLMs, enabling the model to decide whether to make a prediction or abstain based on its confidence level. This decision-making process is crucial for ensuring that the model only provides answers when it is reasonably certain of their accuracy.
By implementing this approach, LLMs can significantly reduce the risk of delivering incorrect or irrelevant information, which is especially important in sensitive applications such as healthcare, legal advice, and financial analysis.
This careful consideration not only enhances the reliability of the model but also builds user trust by ensuring that the information provided is both relevant and accurate. Through selective prediction, LLMs can maintain a high standard of output quality, making them more dependable tools in critical decision-making scenarios.
Improving Reliability
The selective prediction mechanism plays a pivotal role in enhancing the reliability of LLMs by allowing them to abstain from making predictions when uncertainty is high. This capability is particularly crucial in fields where the repercussions of incorrect information can be severe.
For instance, in healthcare, an inaccurate diagnosis could lead to inappropriate treatment, potentially endangering patient lives. Similarly, in legal advice, erroneous predictions might result in costly legal missteps, while in financial forecasting, they could lead to significant economic losses.
By choosing to withhold responses in situations where confidence is low, LLMs uphold a higher standard of accuracy and trustworthiness. This not only minimizes the risk of errors but also fosters greater user confidence in the model’s outputs, making it a reliable tool in critical decision-making processes.
Self-Evaluation
Incorporating self-evaluation mechanisms into selective prediction allows LLMs to internally assess the likelihood of their predictions being correct. This self-assessment is vital for refining the model’s output and ensuring higher accuracy.
Models like PaLM-2 and GPT-3 have shown that using self-evaluation scores can significantly enhance the alignment of predictions with correct answers. This process involves the model analyzing its own confidence levels and historical performance, enabling it to make informed decisions about when to predict.
By continuously evaluating its predictions, the model can adjust its strategies, leading to improved performance and reliability over time.
Advanced Techniques like ASPIRE
Google’s ASPIRE framework represents an advanced approach to selective prediction, enhancing LLMs’ ability to make confident predictions. ASPIRE effectively determines when to provide a response and when to abstain by leveraging sophisticated algorithms to evaluate the model’s confidence.
Are Bootcamps worth It for LLM Training? Get Insights Here
This ensures that predictions are made only when there is a high probability of correctness. By implementing such advanced techniques, LLMs can improve their decision-making processes, resulting in more accurate and reliable outputs.
Selective Prediction in Applications
Selective prediction proves particularly beneficial in various applications, such as conformal prediction, multi-choice question answering, and filtering out low-quality predictions. In these contexts, the technique ensures that the model only delivers responses when it has a high degree of confidence.
This approach not only improves the quality of the output but also reduces the risk of disseminating incorrect information. By integrating selective prediction, LLMs can achieve a balance between providing valuable insights and maintaining accuracy, ultimately leading to more reliable and trustworthy AI systems.
This balance is crucial for enhancing the overall user experience and building trust in the model’s capabilities.
Example
How do Selective Predictions Work in LLMs? Imagine using a language model for a task like answering trivia questions. The LLM is prompted with a question: “What is the capital of France?” Normally, the model would generate a response based on its training.
However, with selective prediction, the model first evaluates its confidence in its knowledge about the answer. If it’s highly confident (knowing that Paris is the capital), it proceeds with the response. If not, it may abstain from answering or express uncertainty rather than providing a potentially incorrect answer.
Improvement in Response Quality
Selective predictions in LLM help in the improvement of the response quality. this is done by removing misinformation and ensuring confident answers or solutions from the model. this increases the reliability of the model and builds trust in the outputs.
Reduces Misinformation: By abstaining from answering when uncertain, selective prediction minimizes the risk of spreading incorrect information.
Enhances Reliability: It improves the overall reliability of the model by ensuring that responses are given only when the model has high confidence in their accuracy.
Better User Trust: Users can trust the model more, knowing that it avoids guessing when unsure, leading to higher quality and more dependable interactions.
Selective prediction, therefore, plays a vital role in enhancing the quality and reliability of responses in real-world applications of LLMs.
ASPIRE Framework for Selective Predictions
The ASPIRE framework, particularly in the context of selective prediction for Large Language Models (LLMs), is a sophisticated process designed to enhance the model’s prediction capabilities. It comprises three main stages:
In this initial stage, the LLM is fine-tuned for specific tasks. This means adjusting the model’s parameters and training it on data relevant to the tasks it will perform. This step ensures that the model is well-prepared and specialized for the type of predictions it will make.
Answer Sampling
After tuning, the LLM engages in answer sampling. Here, the model generates multiple potential answers or responses to a given input. This process allows the model to explore a range of possible predictions rather than settle on the first plausible option.
The final stage involves self-evaluation learning. The model evaluates the generated answers from the previous stage, assessing their quality and relevance. It learns to identify which answers are most likely to be correct or useful based on its training and the specific context of the question or task.
Boosting Business Decisions with ASPIRE
Businesses and industries can greatly benefit from adopting selective prediction frameworks in informed decision-making. Frameworks like ASPIRE helps in several ways:
Enhanced Decision Making: By using selective prediction, businesses can make more informed decisions. The framework’s focus on task-specific tuning and self-evaluation allows for more accurate predictions, which is crucial in strategic planning and market analysis.
Risk Management: Selective prediction helps in identifying and mitigating risks. By accurately predicting market trends and customer behavior, businesses can proactively address potential challenges.
Efficiency in Operations: In industries such as manufacturing, selective prediction can optimize supply chain management and production processes. This leads to reduced waste and increased efficiency.
Improved Customer Experience: In service-oriented sectors, predictive frameworks can enhance customer experience by personalizing services and anticipating customer needs more accurately.
Innovation and Competitiveness: Selective prediction aids in fostering innovation by identifying new market opportunities and trends. This helps businesses stay competitive in their respective industries.
Cost Reduction: By making more accurate predictions, businesses can reduce costs associated with trial and error and inefficient processes.
Selective prediction frameworks like ASPIRE offer businesses and industries a strategic advantage by enhancing decision-making, improving operational efficiency, managing risks, fostering innovation, and ultimately leading to cost savings.
Overall, the ASPIRE framework is designed to refine the predictive capabilities of LLMs, making them more accurate and reliable by focusing on task-specific tuning, exploratory answer generation, and self-assessment of generated responses.
In summary, selective prediction in LLMs is about the model’s ability to judge its own certainty and decide when to provide a response. This enhances the trustworthiness and applicability of LLMs in various domains.
Mistral AI, a startup co-founded by individuals with experience at Google’s DeepMind and Meta, made a significant entrance into the world of LLMs with Mistral 7B. This model can be easily accessed and downloaded from GitHub or via a 13.4-gigabyte torrent, emphasizing accessibility.
Mistral 7b, a 7.3 billion parameter model with the sheer size of some of its competitors, Mistral 7b punches well above its weight in terms of capability and efficiency.
What makes Mistral 7b a Great Competitor?
One of the key strengths of Mistral 7b lies in its architecture. Unlike many LLMs relying solely on transformer networks, Mistral 7b incorporates a hybrid approach, leveraging transformers and recurrent neural networks (RNNs). This unique blend allows Mistral 7b to excel at tasks that require both long-term memory and context awareness, such as question answering and code generation.
Furthermore, Mistral 7b utilizes innovative attention mechanisms like group query attention and sliding window attention. These techniques enable the model to focus on relevant parts of the input data more effectively, improving performance and efficiency.
Mistral 7b Architecture
Mistral 7B is an architecture based on transformer architecture and introduces several innovative features and parameters. Here are the architectural details;
1. Sliding Window Attention
Mistral 7B addresses the quadratic complexity of vanilla attention by implementing Sliding Window Attention (SWA).SWA allows each token to attend to a maximum of W tokens from the previous layer (here, W = 3).
Tokens outside the sliding window still influence next-word prediction.Information can propagate forward by up to k × W tokens after k attention layers. Parameters include dim = 4096, n_layers = 32, head_dim = 128, hidden_dim = 14336, n_heads = 32, n_kv_heads = 8, window_size = 4096, context_len = 8192, and vocab_size = 32000.
Source: E2Enetwork
2. Rolling Buffer Cache
This fixed-size cache serves as the “memory” for the sliding window attention. It efficiently stores key-value pairs for recent timesteps, eliminating the need for recomputing that information. A set attention span stays constant, managed by a rolling buffer cache limiting its size.
Within the cache, each time step’s keys and values are stored at a specific location, determined by i mod W, where W is the fixed cache size. When the position i exceeds W, previous values in the cache get replaced.This method slashes cache memory usage by 8 times while maintaining the model’s effectiveness.
Source: E2Enetwork
3. Pre-fill and Chunking
During sequence generation, the cache is pre-filled with the provided prompt to enhance context. For long prompts, chunking divides them into smaller segments, each treated with both cache and current chunk attention, further optimizing the process.
When creating a sequence, tokens are guessed step by step, with each token relying on the ones that came before it. The starting information, known as the prompt, lets us fill the (key, value) cache beforehand with this prompt.
The chunk size can determine the window size, and the attention mask is used across both the cache and the chunk. This ensures the model gets the necessary information while staying efficient.
Source: E2Enetwork
Comparison of Performance: Mistral 7B vs Llama2-13B
The true test of any LLM lies in its performance on real-world tasks. Mistral 7b has been benchmarked against several established models, including Llama 2 (13B parameters) and Llama 1 (34B parameters).
The results are impressive, with Mistral 7b outperforming both models on all tasks tested. It even approaches the performance of CodeLlama 7B (also 7B parameters) on code-related tasks while maintaining strong performance on general language tasks.Performance comparisons were conducted across a wide range of benchmarks, encompassing various aspects.
1. Performance Comparison: Mistral 7B surpasses Llama2-13B across various benchmarks, excelling in common sense reasoning, world knowledge, reading comprehension, and mathematical tasks. Its dominance isn’t marginal; it’s a robust demonstration of its capabilities.
2. Equivalent Model Capacity: In reasoning, comprehension, and STEM tasks, Mistral 7B functions akin to a Llama2 model over three times its size. This not only highlights its efficiency in memory usage but also its enhanced processing speed. Essentially, it offers immense power within an elegantly streamlined design.
3. Knowledge-based Assessments: Mistral 7B demonstrates superiority in most assessments and competes equally with Llama2-13B in knowledge-based benchmarks. This parallel performance in knowledge tasks is especially intriguing, given Mistral 7B’s comparatively restrained parameter count.
Source: MistralAI
Beyond Benchmarks: Practical Applications
The capabilities of Mistral 7B extend far beyond benchmark scores, showcasing a versatility that is not confined to a single skill. This model excels across various tasks, effectively bridging code-related fields and English language tasks. Its performance is particularly notable in coding tasks, where it rivals the capabilities of CodeLlama-7B, underscoring its adaptability and broad-ranging abilities. Below are some of the common applications in different fields:
Natural Language Processing (NLP)
Mistral 7B demonstrates strong proficiency in NLP tasks such as machine translation, where it can convert text between languages with high accuracy. It also excels in text summarization, efficiently condensing lengthy documents into concise summaries while retaining key information.
For question answering, the model provides precise and relevant responses, and in sentiment analysis, it accurately detects and interprets the emotional tone of text.
Code Generation and Analysis
In the realm of code generation, Mistral 7B can produce code snippets from natural language descriptions, streamlining the development process. It also translates natural language instructions into code, facilitating automation and reducing manual coding errors.
Additionally, the model analyzes existing code to identify potential issues, offering suggestions for improvements and debugging.
Creative Writing
The model’s creative prowess is evident in its ability to compose a wide variety of creative texts. It can craft engaging poems, write scripts for plays or films, and produce musical pieces. These capabilities make it an invaluable tool for writers and artists seeking inspiration or assistance in generating new content.
Education and Research
Mistral 7B assists educators and researchers by generating educational materials tailored to specific learning objectives. It can personalize learning experiences by adapting content to the needs of individual students. In research settings, the model aids in automating data analysis and report generation, thereby enhancing productivity and efficiency.
By excelling in these diverse applications, Mistral 7B proves itself to be a versatile and powerful tool across multiple domains.
Source: E2Enetwork
Source: MistralAI
Key Features of Mistral 7b
A Cost-Effective Solution
One of the most compelling aspects of Mistral 7B is its cost-effectiveness. Compared to other models of similar size, Mistral 7B requires significantly less computational resources to operate. This feature makes it an attractive option for both individuals and organizations, particularly those with limited budgets, seeking powerful language model capabilities without incurring high operational costs.
Mistral AI enhances this accessibility by offering flexible deployment options, allowing users to either run the model on their own infrastructure or utilize cloud-based solutions, thereby accommodating diverse operational needs and preferences.
Versatile Deployment and Open Source Flexibility
Mistral 7B is distinctive due to its Apache 2.0 license, which grants broad accessibility for a variety of users, ranging from individuals to major corporations and governmental bodies. This open-source license not only ensures inclusivity but also encourages customization and adaptation to meet specific user requirements.
By allowing users to modify, share, and utilize Mistral 7B for a wide array of applications, it fosters innovation and collaboration within the community, supporting a dynamic ecosystem of development and experimentation.
Decentralization and Transparency Concerns
While Mistral AI emphasizes transparency and open access, there are safety concerns associated with its fully decentralized ‘Mistral-7B-v0.1’ model, which is capable of generating unmoderated responses. Unlike more regulated models such as GPT and LLaMA, it lacks built-in mechanisms to discern appropriate responses, posing potential exploitation risks.
Nonetheless, despite these safety concerns, decentralized Large Language Models (LLMs) offer significant advantages by democratizing AI access and enabling positive applications across various sectors.
Are Large Language Models the Zero Shot Reasoners? Read here
Conclusion
Mistral 7b is a testament to the power of innovation in the LLM domain. Despite its relatively small size, it has established itself as a force to be reckoned with, delivering impressive performance across a wide range of tasks. With its focus on efficiency and cost-effectiveness, Mistral 7b is poised to democratize access to cutting-edge language technology and shape the future of how we interact with machines.