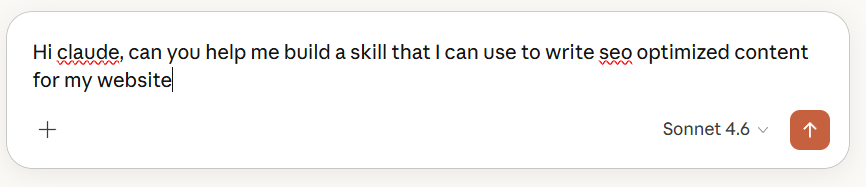
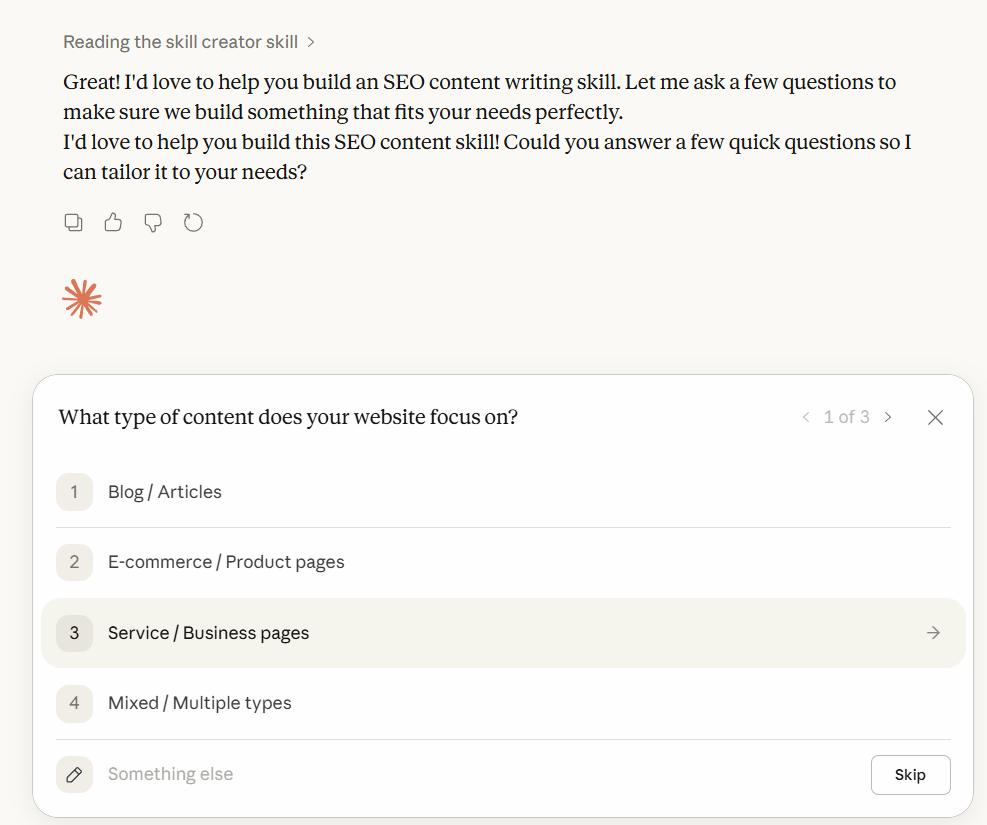
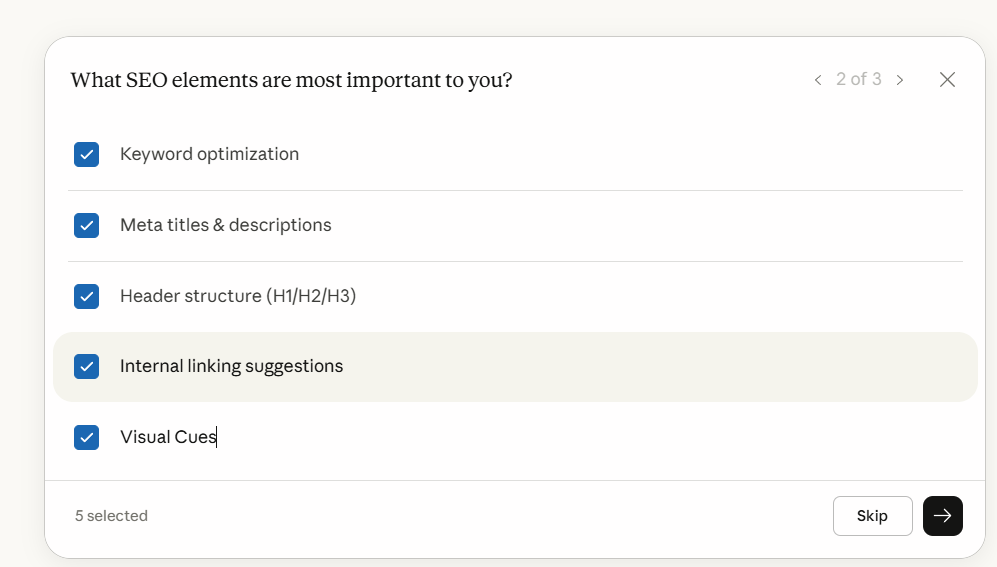
Key Takeaways
- Hermes Agent is an open-source autonomous AI agent by Nous Research that learns and improves the longer you use it
- Its built-in learning loop — persistent memory, autonomous skill creation, and user modeling — is what separates it from every other open-source agent available today
- By the end of this guide you’ll have Hermes installed, WhatsApp connected, and your first AI briefing scheduled — no email setup, no business account
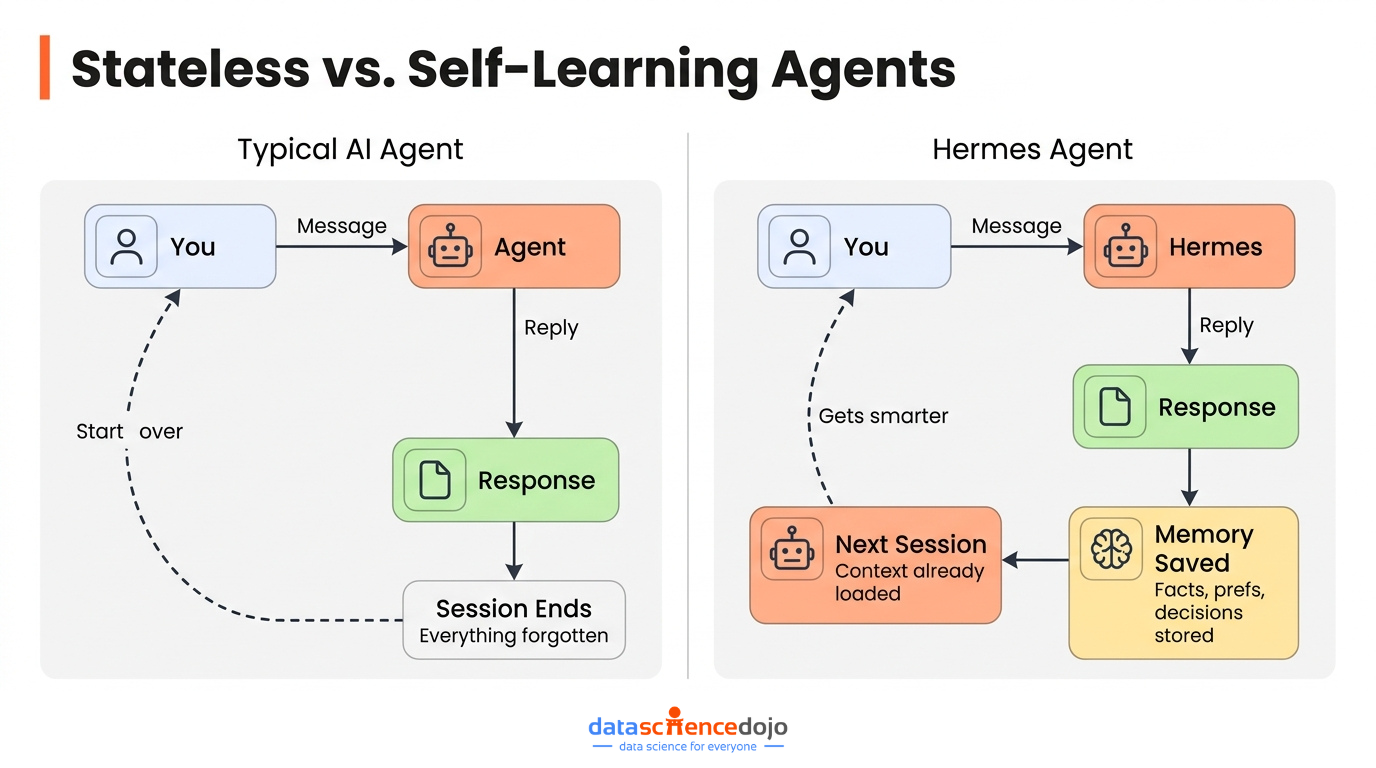
Most AI tools forget everything the moment you close the tab. You come back the next day, open a new session, and you’re explaining yourself from scratch again. Your name, your preferences, the context of what you were working on — gone.
Hermes Agent was built on the premise that this is unacceptable for anything you’d actually call an agent. An agent that forgets is just a chatbot with a fancier UI. Real autonomy requires memory, continuity, and the ability to get better at your specific tasks over time — not just smarter responses within a single session.
Released in February 2026 by Nous Research under the MIT license, Hermes crossed 140,000 GitHub stars in under three months and became the most-used agent on OpenRouter. That’s not explained by novelty. It’s explained by what the framework actually delivers that others don’t.
This guide covers how Hermes works under the hood, how it compares to OpenClaw and the major agent frameworks, and closes with a step-by-step setup guide for getting Hermes running and delivering a daily AI briefing to your WhatsApp using just your personal number.
The Problem Hermes Was Built to Solve
Open a new session with most AI agents, even good ones, and you face the same three problems:
- No memory of previous conversations. Every session starts cold.
- No accumulated skill. The agent approaches your tasks the same way on day 100 as it did on day 1.
- No model of you. It doesn’t know your preferences, your projects, your communication style, or what you’ve already decided.
The frustration compounds fast. Ask an agent to do something complex that spans multiple days and you’ll spend more time re-explaining context than you will on the actual work.
Most frameworks treat memory as an optional plugin — something you wire in if you need it. Hermes treats it as a first-class architectural requirement. The same goes for skill creation and user modeling. These aren’t add-ons. They’re built into how the system works by default, from the first conversation.
Understanding why this matters at a deeper level — why continuity, context, and behavioral reuse are the actual bottlenecks in agentic systems — is something worth reading about separately. The concept of context engineering covers exactly this: why what surrounds a prompt often matters more than the prompt itself, and how production agents are built to manage that surrounding layer intelligently.
If you’re new to autonomous agents and want grounding before diving into a specific tool, it’s worth understanding what agentic AI actually is and what separates it from standard LLM applications before going further.
How Hermes Agent Works: The Learning Loop
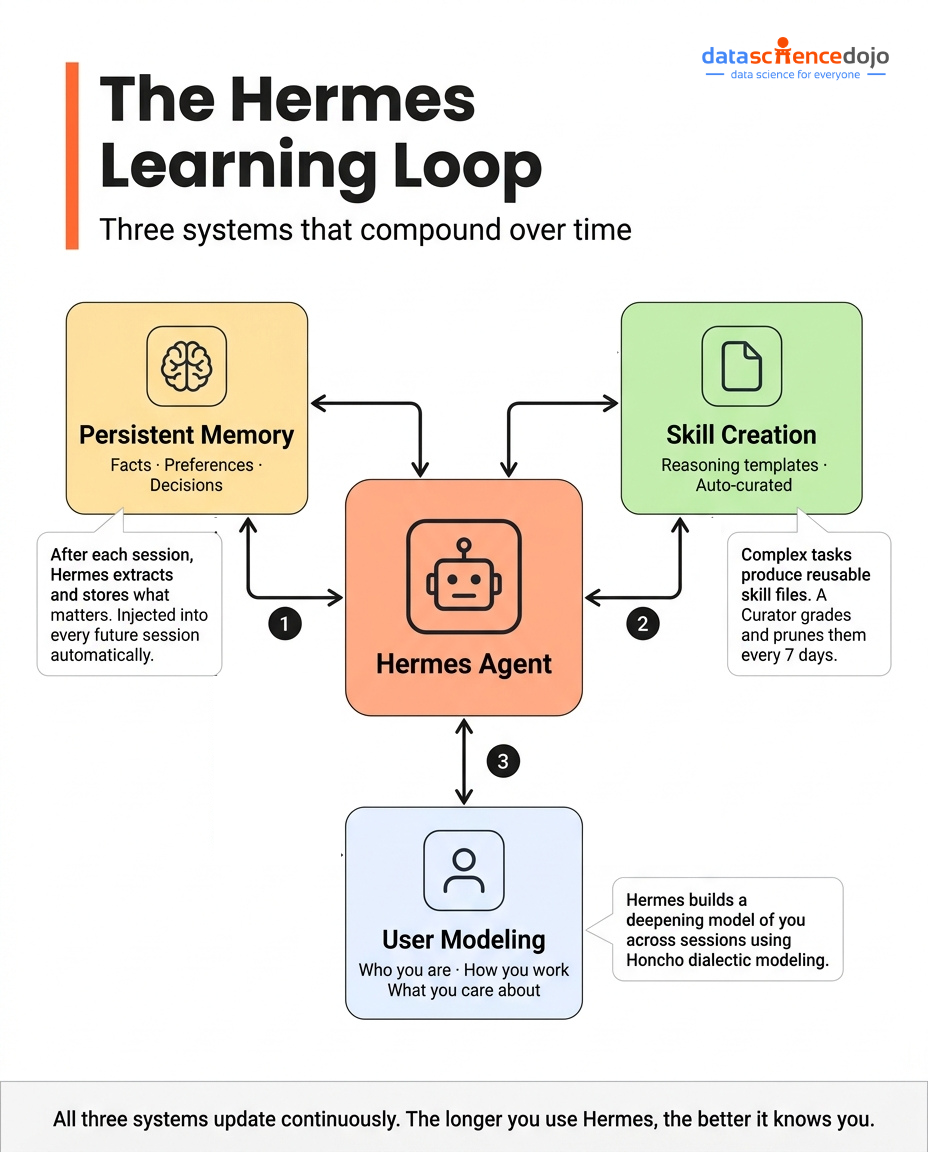
The core of Hermes is what Nous Research calls the learning loop. It has three distinct but interlocking components, and all three have to work together for the system to behave the way it’s designed to.
Persistent Memory
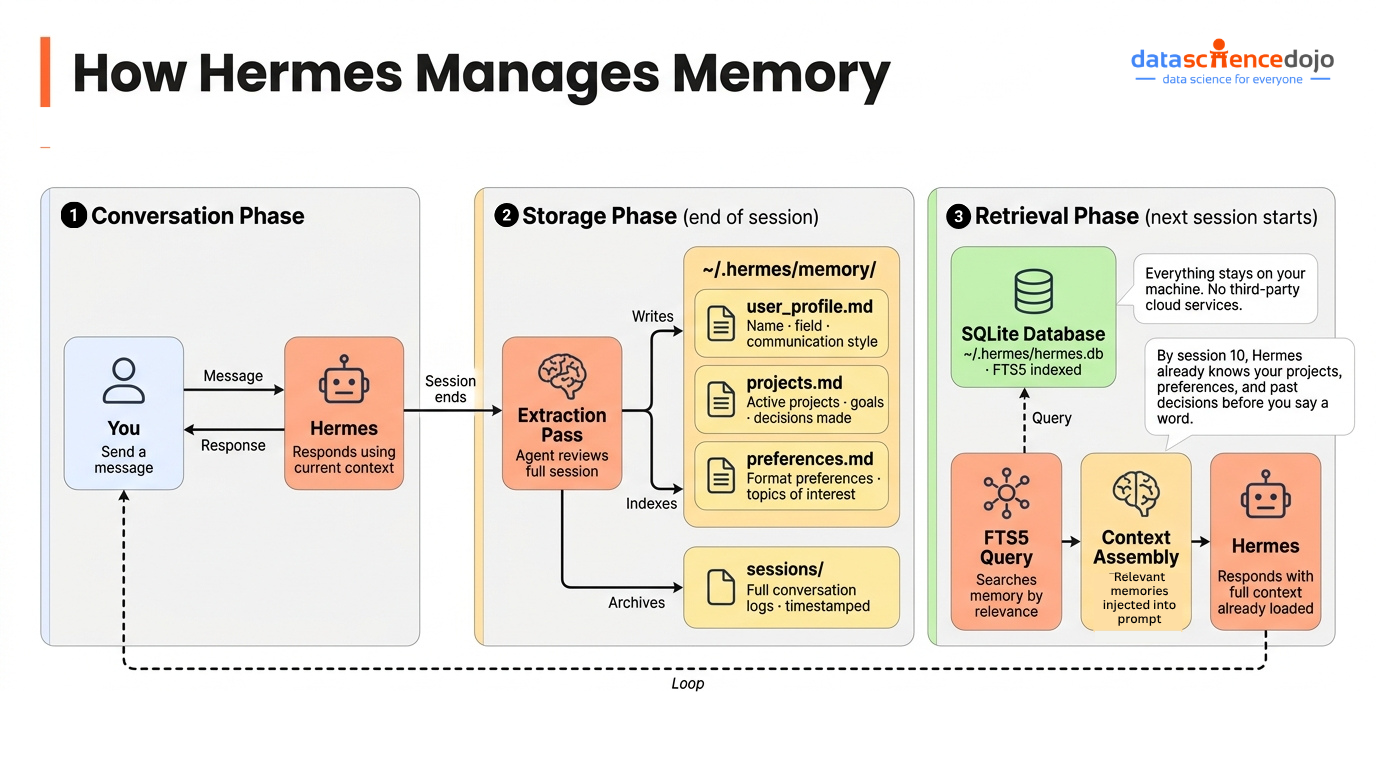
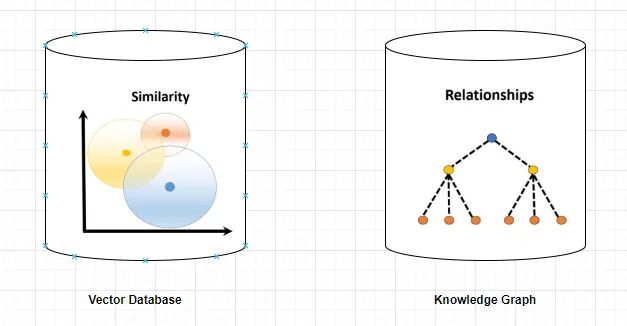
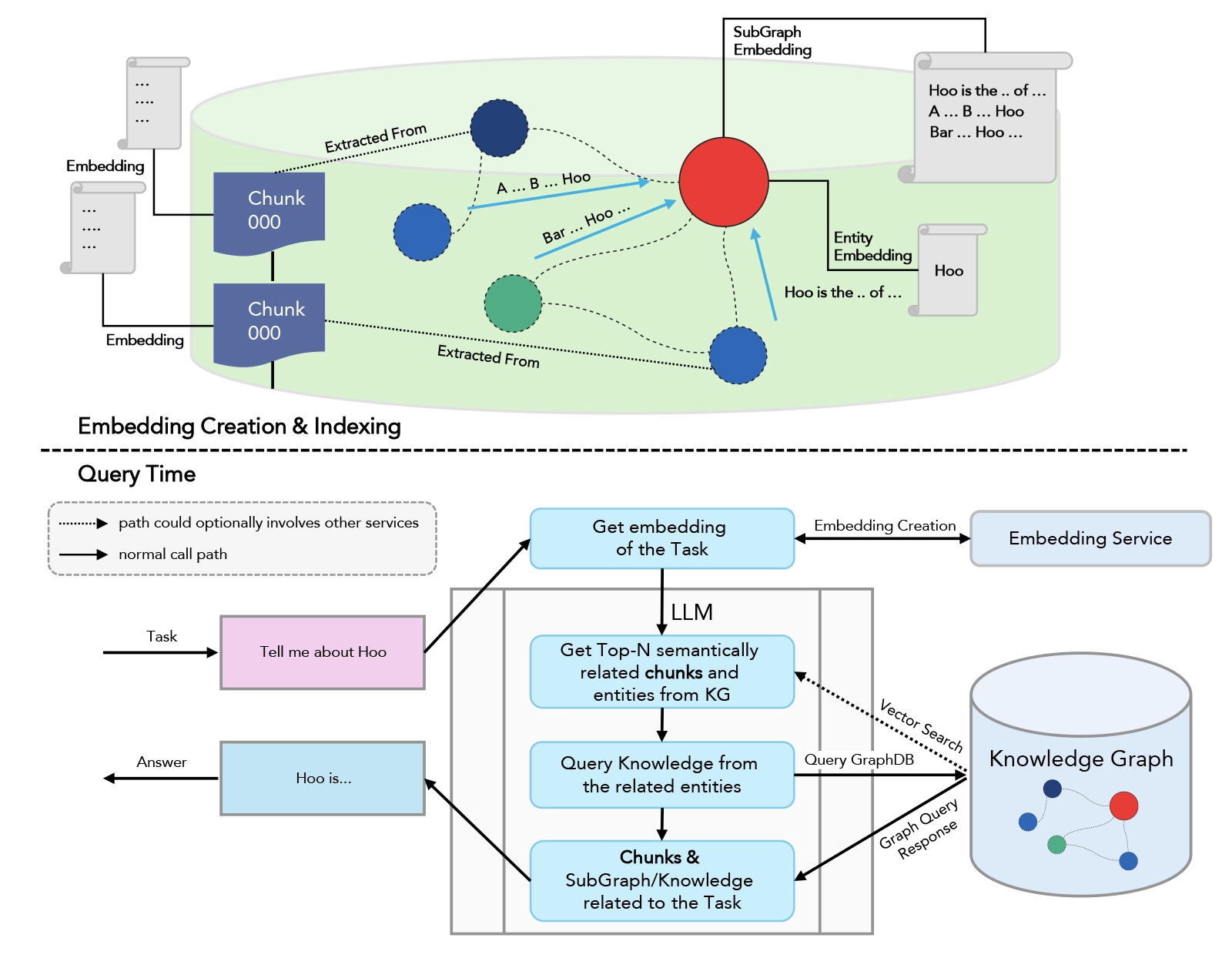
Everything Hermes learns about you and your work lives in a local SQLite database at ~/.hermes/. Nothing passes through third-party cloud infrastructure. Your data stays on your machine.
At the end of each conversation, Hermes runs an extraction pass over the session — pulling out facts, preferences, decisions, and context worth preserving. These get stored and indexed via SQLite FTS5, which gives the system full-text search across all past sessions.
When a new conversation starts, Hermes queries that database and injects relevant memories into context before the model ever sees your first message.
- By the second conversation, Hermes knows your name, your field, and what you’re working on
- By the fifth, it knows how you like things formatted, what topics you care about, and what questions you’ve already answered
- By the tenth, it’s making connections between recent news and your specific projects without being asked
This is the compounding effect that makes persistent memory more than a convenience feature. It changes what the agent is capable of producing over time — not because the model got smarter, but because the context it’s operating in became richer and more personal.
It’s worth noting that this is a solved architectural problem in 2026. There are entire frameworks and memory products dedicated to the long-term memory layer for agents. What makes Hermes distinctive is that it ships with this built in, fully integrated with the scheduler, the skill system, and the user model — not as a separate service you connect to.
Autonomous Skill Creation
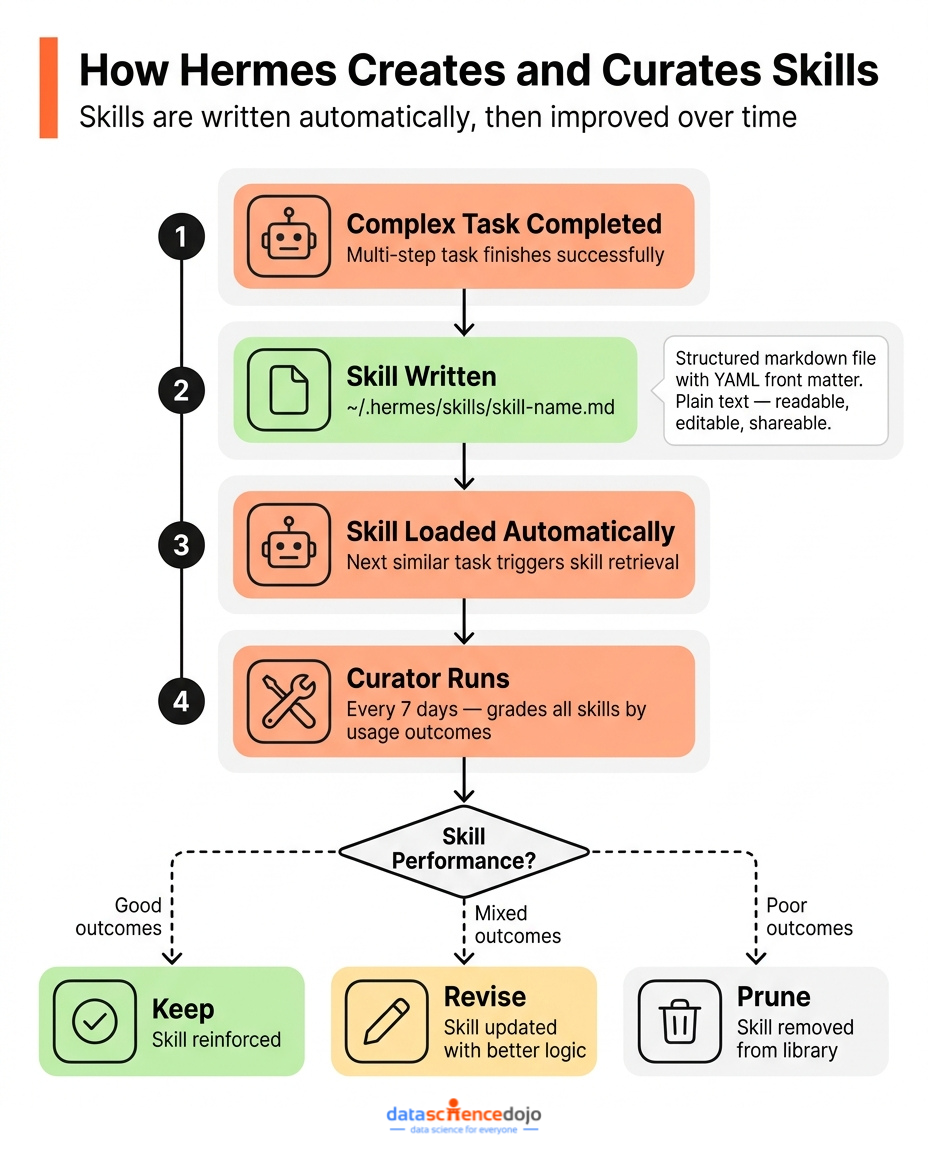
When Hermes completes a complex, multi-step task, it doesn’t just return a result. It also writes a skill — a structured markdown file with YAML front matter that encodes the reasoning template it used.
Skills are stored in ~/.hermes/skills/ and are loaded automatically when relevant tasks come up. The next time you ask Hermes to do something similar, it doesn’t start from scratch. It loads the skill, applies the accumulated logic, and produces better output faster.
Here’s what makes this genuinely useful rather than just an interesting feature:
- Skills are plain text markdown files. You can read them, edit them, version-control them, and share them.
- They’re compatible with the agentskills.io open standard, so you can import skills from the community or publish your own.
- They’re not static. An autonomous Curator process runs on a 7-day cycle, grading skills based on actual usage outcomes, consolidating overlapping ones, and pruning those that consistently underperform.
The Curator is what separates Hermes’s skill system from other platforms like Claude. Skills evolve based on evidence. A skill that worked well three months ago but no longer produces good results gets revised or removed. The library stays lean and current.
There’s a useful conceptual distinction worth understanding here, between tools and skills. Tools give an agent external capabilities — web search, file access, API calls, terminal commands. Skills give it internal behavioral templates — the domain-specific reasoning logic that makes outputs consistent and purposeful. Both matter, but they solve different problems. If you want to go deeper on the difference between agent tools and agent skills and why that distinction matters for building reliable agents, it’s a concept that shows up constantly in production systems.
User Modeling
The third layer is the most distinctive component of Hermes and the one with no real equivalent in competing frameworks.
Hermes uses the Honcho dialectic user modeling system to build a persistent representation of you across sessions. This goes well beyond a preference list. It models:
- How you communicate and what level of detail you prefer
- What projects you’re working on and how they relate to each other
- What decisions you’ve already made and don’t want relitigated
- What topics connect to your work in ways you’d find useful to know about
The user model updates continuously as you interact. It informs not just how Hermes responds, but what it proactively notices and flags. A morning briefing produced for someone building an AI agent project will look meaningfully different from one produced for someone tracking climate policy — even if the underlying news sources and search queries are identical — because the user model shapes what gets surfaced and how it’s framed.
This is the layer that makes Hermes feel like it knows you after a few weeks of use. The technical foundation is solid — it’s not a gimmick — but the experience of it is closer to having an assistant who’s been paying attention than using a tool that retrieved your preferences from a database.
Core Architecture: Under the Hood
The Agent Core
Every Hermes subsystem — the CLI, the messaging gateway, the cron scheduler, the ACP server for IDE integration — runs through a single AIAgent object defined in run_agent.py. This is an important design choice. It means the agent responding to your message in the terminal is architecturally identical to the one handling your scheduled tasks and responding to messages in Discord. Same memory, same skills, same user model, same behavior.
Many frameworks have inconsistencies between their interactive and automated modes — subtle differences in how context is handled, which tools are available, or how memory is accessed. Hermes eliminates that class of problem by having a single agent core that everything else wraps around.
Transport Layer
Model access is abstracted behind a ProviderTransport abstract base class, with concrete implementations for Anthropic, OpenAI-compatible endpoints, AWS Bedrock, and the Responses API. What this means in practice: you can switch models or providers with hermes model and nothing else changes. No code edits, no configuration rewrites, no behavioral differences.
Supported providers include:
- 200+ models via OpenRouter (including free tiers)
- Anthropic (Claude Haiku, Sonnet, Opus)
- OpenAI (GPT-4.1, o3, o4-mini)
- AWS Bedrock
- Local models via Ollama and LM Studio (fully offline, zero API cost)
The model-agnostic architecture also matters for cost management. You can run lightweight free models for routine daily tasks like news briefings and switch to a more capable model only for complex research or coding work — all within the same agent instance.
Sub-Agent Delegation
When tasks get complex, Hermes doesn’t try to handle everything in a single context window. Instead, it spawns sub-agents — isolated, short-lived workers that each get a focused context, a specific toolset, and a single well-defined goal.
The main agent acts as an orchestrator. It breaks the task into parts, delegates each part to a sub-agent, collects results, and synthesizes the final output. Each sub-agent runs in its own session, keeping concerns separated and context windows small.
This architecture has practical benefits beyond just handling larger tasks:
- Smaller context windows work better with local and lightweight models
- Parallel sub-agents can run workstreams simultaneously, not sequentially
- Failures in one sub-agent don’t contaminate the main context
Built-in Scheduler
The cron system is one of Hermes’s most practically valuable features. The gateway runs a background ticker that checks every 60 seconds for due jobs. When a job fires, it spins up a fresh agent session, runs the job’s prompt with full tool access, and delivers the output to whatever messaging platform or destination you specified.
Jobs are created in natural language:
Every weekday at 8am, search for AI news and send me a summary by email
Hermes parses this, generates the correct cron expression, registers the job, and you’re done. No cron syntax to remember, no external scheduler to set up.
A few important nuances about the scheduler worth understanding:
- Each cron job runs in a fresh session with no chat history — by design. This keeps jobs predictable and prevents state bleed between runs. It means your prompts need to be self-contained.
- Jobs can be chained via the context_from parameter. Job B can automatically receive Job A’s output as context. This enables multi-stage pipelines: collect → analyze → deliver.
- You can attach specific skills to a job so it has relevant domain expertise loaded without having to pull in the entire skill library.
- A safety constraint prevents cron-triggered sessions from creating new cron jobs, which stops runaway scheduling loops.
Browser Tooling
Rather than scraping raw HTML, Hermes represents web pages as accessibility trees — structured formats that encode the semantic meaning of page elements, not just their raw markup. This makes the agent significantly more reliable at:
- Understanding page structure and navigation
- Clicking the right buttons on dynamically rendered pages
- Filling forms correctly without misidentifying fields
- Extracting structured information from complex layouts
Browser support includes cloud providers like Browserbase and local Chrome or Chromium instances.
Hermes vs. OpenClaw: A Genuine Architectural Comparison
OpenClaw is the closest open-source comparison to Hermes, and the distinction between them is meaningful. A framing that circulates widely in developer communities captures it accurately: “Hermes packages a gateway around a learning agent. OpenClaw packages an agent around a messaging gateway.”
That’s not a trivial difference. It determines what the system fundamentally optimizes for. OpenClaw is excellent at what it does — a messaging-first agent that’s reliable, extensible, and well-suited to teams that want a capable bot integrated into their communication workflow. Hermes optimizes for the agent getting smarter and more personalized over time.
[IMAGE: Side-by-side comparison diagram of Hermes vs OpenClaw architecture]
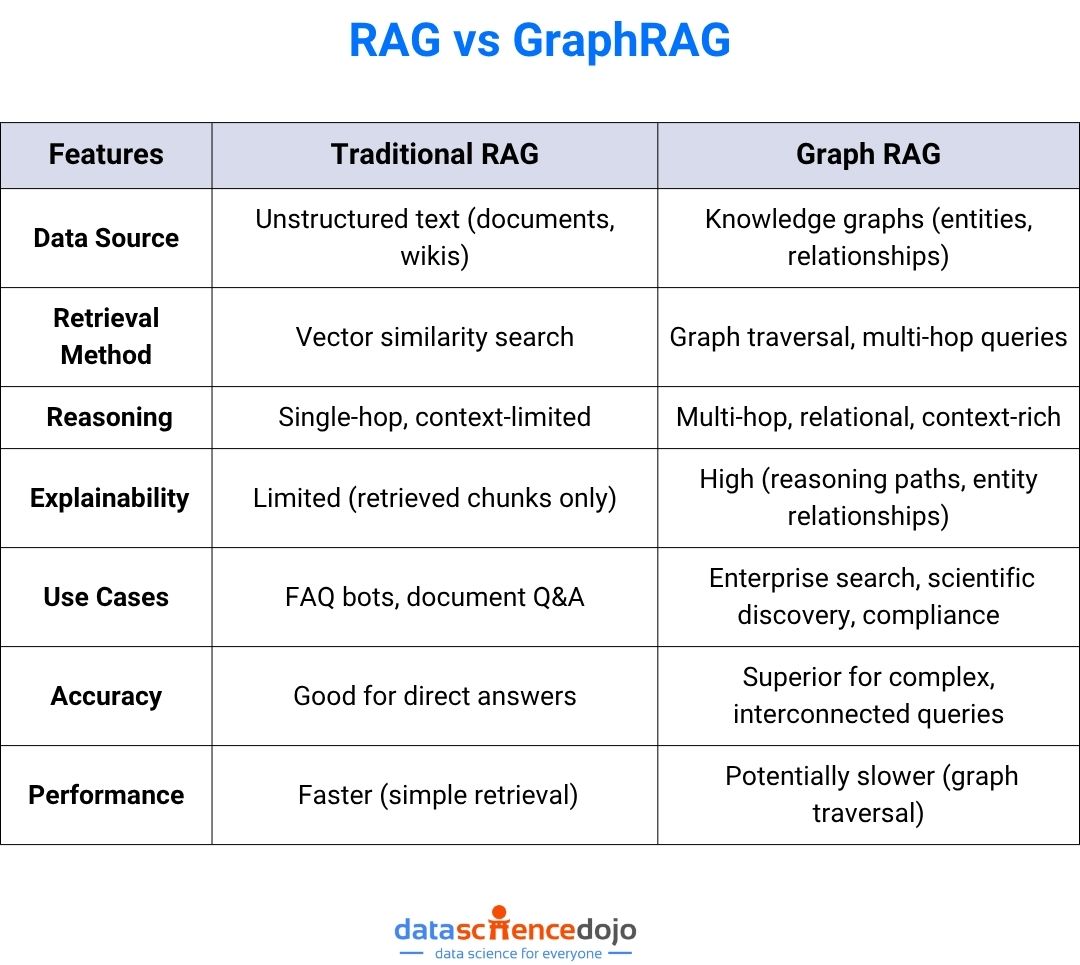
| Feature | Hermes Agent | OpenClaw |
|---|---|---|
| Memory | Persistent, local SQLite, FTS5 search | Session-scoped, resets between runs |
| Skill system | Autonomous creation, self-improving Curator | Manual skill configuration |
| User modeling | Honcho dialectic modeling across sessions | Not built-in |
| Scheduling | Native cron, 60s tick, natural language input | Requires external setup |
| Model support | 200+ via OpenRouter, all major providers | OpenAI-compatible APIs |
| Local model support | Ollama, LM Studio, llama.cpp | Ollama |
| Platform support | 18 messaging platforms natively | Core platforms |
| Self-evolution | GEPA optimizer, autonomous PR generation | Not present |
| License | MIT | MIT |
The practical gap is most visible after a few weeks of consistent use. With OpenClaw, the agent’s capability on day 30 is roughly the same as day 1 — it’s as good as the model and configuration you set up. With Hermes, the skill library has grown, the user model has deepened, and the agent’s outputs are measurably more relevant to your work. Developer comparisons using identical underlying models consistently show stronger results in Hermes for tasks that span multiple days.
How Hermes Compares to LangChain, CrewAI, and AutoGen
Beyond OpenClaw, the broader landscape includes orchestration frameworks like LangChain, CrewAI, and AutoGen. These are fundamentally different kinds of tools.
LangChain, CrewAI, and AutoGen are developer libraries. You write Python to define agent logic, configure which tools are available, wire up a memory backend, set up a scheduler if you want one, and manage the infrastructure to keep it running. They’re powerful and flexible, and they’re the right choice if you want full programmatic control over your agent’s behavior. They require engineering investment to set up and ongoing maintenance to keep running.
Hermes is an end-user product that happens to be open source. The difference in practice:
- Install with a single curl command and you’re talking to it in minutes
- Memory, skill creation, user modeling, and scheduling are all on by default — nothing to configure
- Runs as a persistent background service with an install command that handles the systemd/launchd setup
- Messaging gateway, IDE integration, email delivery, and browser tools are all first-party, not external integrations
The tradeoff is control. If you need to define precisely how an agent orchestrates subtasks, LangChain or LangGraph gives you that. If you want a capable agent running on your machine today with minimal setup, Hermes is the faster path. Neither is universally better — it depends on what you’re building.
For a broader view of how automation and AI agents work together and where these tools fit in a modern workflow, it’s worth reading about building smarter workflows with AI agents. Traditional automation follows fixed rules. Agents apply judgment. Hermes adds a third layer on top of that — it applies judgment, stores the outcome, and adjusts the next run.
The Self-Evolution Subsystem
The hermes-agent-self-evolution companion repository has no direct equivalent in other open-source agents. It implements GEPA — Genetic Evolution of Prompt Architectures — an automated optimizer that works as follows:
- Reads the current set of skill definitions, prompt templates, and tool configurations
- Generates evaluation datasets based on actual usage patterns and execution history
- Produces candidate variants by applying targeted mutations based on failure analysis
- Runs each variant through execution traces and evaluates against constraint gates — tests, size limits, and benchmark thresholds
- Opens a pull request against the main hermes-agent repository with the best-performing variant
The critical distinction from naive prompt optimization is that GEPA doesn’t just measure whether outputs were good or bad — it reads execution traces to understand why things failed. That produces targeted, root-cause-level improvements rather than generic rewrites that might improve one metric while degrading others.
This is a programmatic implementation of what the field now calls harness engineering — the discipline of building structural correction mechanisms around an agent so that specific failure modes become harder to repeat over time. If you want to understand what harness engineering is and why it’s become central to reliable agent systems in 2026, it’s a concept worth spending time on. The self-evolution subsystem is one of the clearest real-world examples of it working at scale.
Full Feature Inventory
Before the tutorial, here’s a complete picture of what Hermes ships with out of the box.
Tools and Capabilities
- 40+ built-in tools: web search, browser automation, file access, code execution, terminal commands, image generation, and more
- ACP server for IDE integration: VS Code, Zed, and JetBrains
- OpenAI-compatible API server exposed at port 8642 — use Hermes as a local LLM endpoint
Messaging and Delivery
- 18 messaging platforms: Telegram, Discord, Slack, WhatsApp, Signal, Feishu/Lark, WeCom, QQBot, Yuanbao, Microsoft Teams (via plugin), and more
- Email delivery via SMTP
- Voice memo transcription and TTS audio responses (Telegram)
Infrastructure
- 7 terminal backends: Local, Docker, SSH, Singularity, Modal, Daytona, Vercel Sandbox
- Native cron scheduler with natural language input, job chaining, and per-job skill injection
- hermes gateway install creates a persistent background service (systemd on Linux, launchd on macOS)
Learning and Customization
- Persistent SQLite memory with FTS5 full-text search
- Autonomous skill creation, Curator-managed skill library, agentskills.io compatibility
- SOUL.md for custom agent personality
- AGENTS.md for project-specific context injection
- Honcho user modeling
Training and Research
- RL training data export: generate tool-calling trajectories for fine-tuning
- Atropos integration for reinforcement learning experiments
- GEPA self-evolution subsystem
Getting Started: Install Hermes and Set Up Your WhatsApp Briefing
Everything covered above runs from a single install. Here’s how to get it running and delivering your daily AI briefing straight to WhatsApp — using your personal number, no Meta business account needed.
Time: ~15 minutes
Difficulty: Beginner
Cost: Free
Platform: Windows (WSL2), Linux, or macOS
Part 1: Install Hermes
WSL2 / Linux / macOS:
Note: For this, you would need wsl installed.
Open your Ubuntu terminal and run:
The installer handles everything — Python 3.11, Node.js 22, ripgrep, ffmpeg, repo clone, and virtualenv. Takes 3–5 minutes. When done, close and reopen the terminal, then verify:
hermes –version
⚠️ On Windows, run this inside the Ubuntu app (WSL2), not PowerShell. Everything from here runs in Ubuntu.
Part 2: Run Setup
hermes setupThe wizard walks you through three choices:
- Provider: Choose OpenRouter. Get a free key at openrouter.ai, no credit card required.
- Model: For this tutorial, we’re using nvidia/nemotron-3-super-120b-a12b. It’s free.
- Terminal backend: Select Local.
When it asks about messaging, select Set up messaging now and choose WhatsApp. It might not complete the setup after this. If that happens you can use hermes whatsapp to set up messaging gateway for Whatsapp.
Part 3: Connect WhatsApp via QR Code
Hermes uses Baileys to connect to WhatsApp — no Meta developer account, no business number. Just your personal WhatsApp and a QR scan.
Start the gateway:
hermes gateway
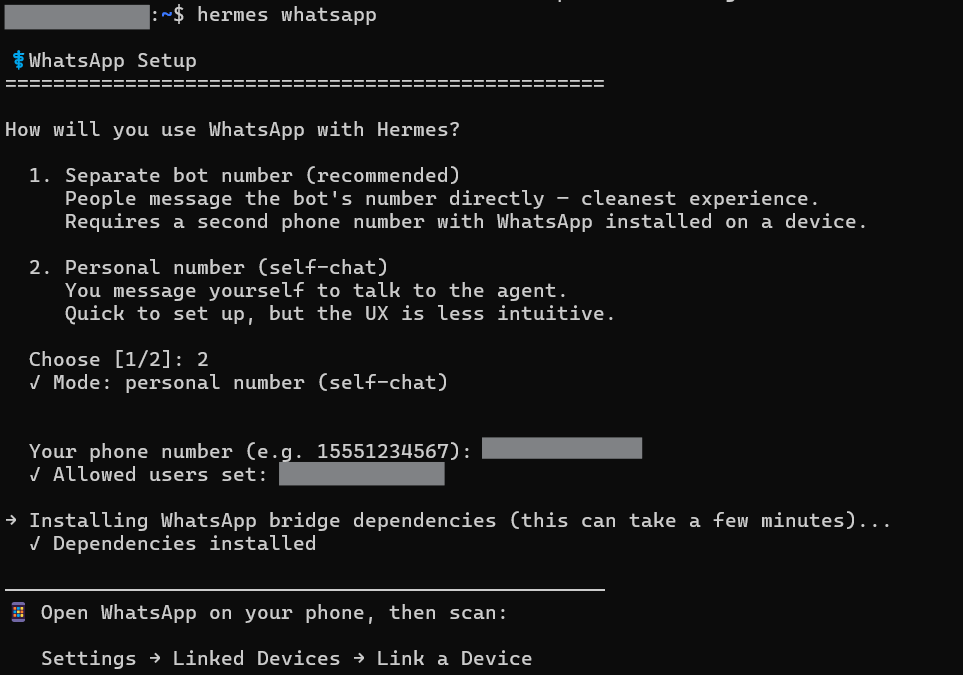
A QR code will appear in the terminal. On your phone:
- Open WhatsApp
- Tap the three dots (Android) or Settings (iOS)
- Tap Linked Devices → Link a Device
- Scan the QR code in your terminal
You’ll see a confirmation:
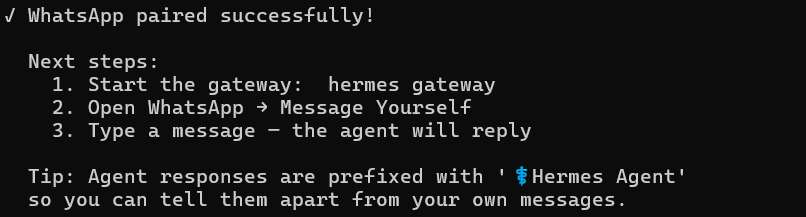
Part 4: Set Your Home Chat and Create the Briefing
Open WhatsApp on your phone and message yourself (use the “Message yourself” feature or send to your own number). Send:
/sethome
Hermes confirms this chat as the delivery destination. Now send your briefing instruction:
Hermes confirms:

It automatically triggered a test run and after a few minutes shares today’s briefing:
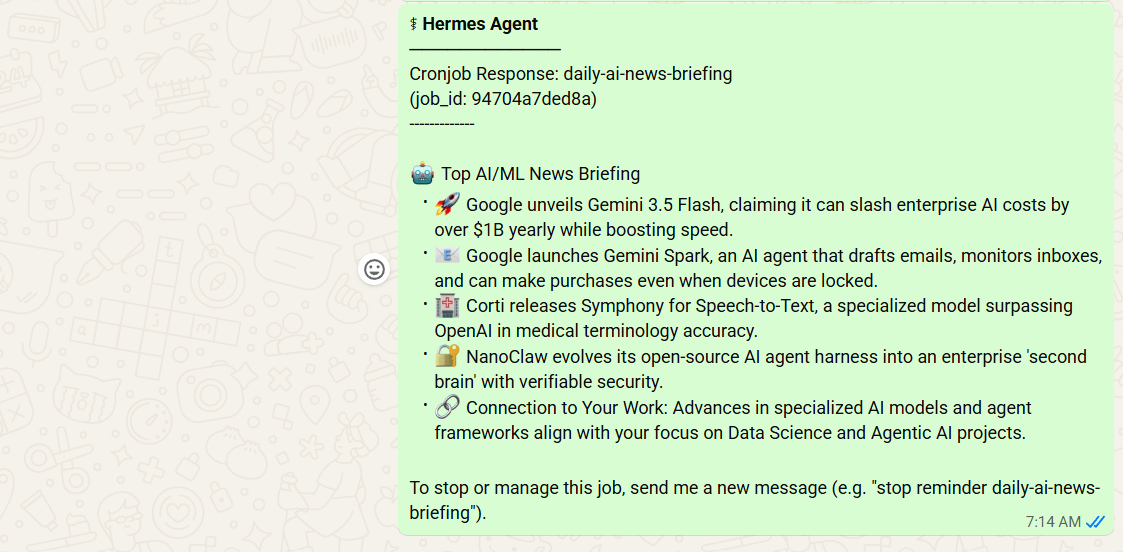
This is just the beginning. You can keep giving it instructions and Hermes will automatically update the News Briefing Skill for you.
Part 5: Keep the Gateway Running
The WhatsApp connection stays alive as long as hermes gateway is running. To make it persistent:
Windows 11 WSL2 (systemd):
- hermes gateway install
- hermes gateway start
Frequently Asked Questions
Does Hermes require a paid API key?
No. It can run on free models via OpenRouter and works fully offline with local models via Ollama or LM Studio — zero API cost either way. The daily morning briefing tutorial in this post costs nothing to run.
How is this different from just scheduling a Python script that calls an API?
A Python script executes a fixed function every time it runs. The output on day 100 is structurally identical to the output on day 1. Hermes runs a language model with persistent memory context, skill injection, and a continuously updated user model. The output on day 100 reflects what the agent has learned about what you actually want — not just what the prompt says.
Does Hermes send my data anywhere?
Memories, skills, session history, and the user model all stay local in ~/.hermes/on your machine. The only outbound data is your LLM API calls, which go directly to whichever provider you configured. Nothing routes through Nous Research infrastructure.
Can I use Hermes without Telegram, Discord, or any messaging platform?
Yes. The CLI (hermes) works completely standalone. Scheduled jobs can deliver to email or save output to local files. A messaging platform makes it more convenient to interact on mobile, but it’s entirely optional.
What happens if a cron job fails mid-run?
Failed jobs are logged in ~/.hermes/logs/ with full error details. They are not automatically retried. For workflows where failure would be a problem, add a fallback instruction directly in the job prompt: “if the web search returns no results, send an email noting that no news was found today.”
Can I share my skills with teammates or the community?
Yes. Skills are plain markdown files in ~/.hermes/skills/. They’re portable, version-controllable with git, and compatible with the agentskills.io open standard for community sharing. If you build a skill that works well for a particular domain, publishing it means others can import it directly.
What’s the difference between the CLI and the gateway?
The CLI (hermes) is for interactive sessions — you type, it responds. The gateway is the background process that handles messaging platforms and runs scheduled cron jobs. Both use the same agent core, so behavior is consistent. You need the gateway running for scheduled tasks to fire.
Wrapping Up
Hermes Agent is worth paying attention to not because it has the most features or the most impressive benchmarks, but because it solves the right problem. Stateless agents are fundamentally limited for any task that spans more than a single session. Hermes is the most complete open-source attempt to fix that.
The combination of persistent local memory, autonomous skill creation, a continuously updated user model, and a built-in scheduler that runs 24/7 produces something that behaves qualitatively differently from any other open-source agent available today. The morning briefing use case in this tutorial demonstrates all of those components working together — and it only gets better with time.
For anyone who wants to go deeper on how agentic systems are designed and deployed in 2026 — covering LangGraph, context engineering, multi-agent coordination, and production deployment patterns — the Agentic AI Bootcamp is the most comprehensive structured program available. If you’re building agents seriously, it’s worth the investment.




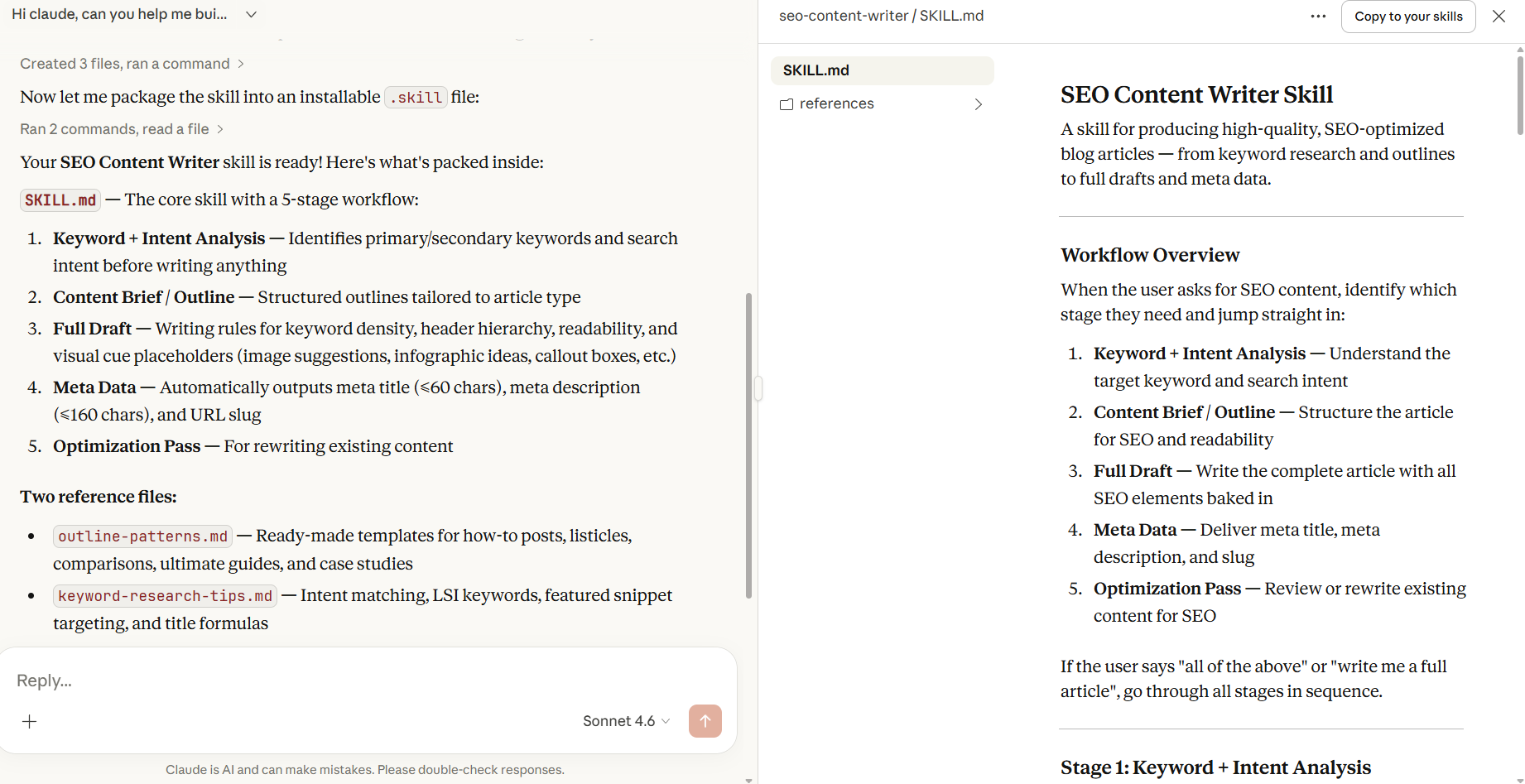
 Reference files only load when Claude decides they're needed. This keeps the context window clean. Claude isn't loading a 500-line document for every message, only when the task actually calls for it.
You can read more on how to create custom skills in this
Reference files only load when Claude decides they're needed. This keeps the context window clean. Claude isn't loading a 500-line document for every message, only when the task actually calls for it.
You can read more on how to create custom skills in this