

Develop an understanding of text analytics, text conforming, and special character cleaning. Learn how to make text machine-readable.
Text analytics for machine learning: Part 2
Last week, in part 1 of our text analytics series, we talked about text processing for machine learning. We wrote about how we must transform text into a numeric table, called a term frequency matrix, so that our machine learning algorithms can apply mathematical computations to the text. However, we found that our textual data requires some data cleaning.
In this blog, we will cover the text conforming and special character cleaning parts of text analytics.
Understand how computers read text
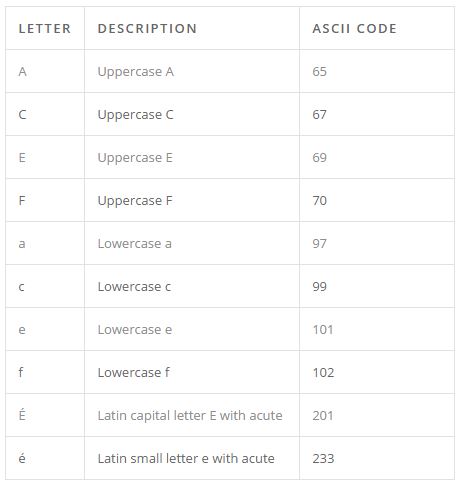
The computer sees text differently from humans. Computers cannot see anything other than numbers. Every character (letter) that we see on a computer is actually a numeric representation to a computer, with the mapping between numbers and characters determined by an “encoding table.” The simplest, but most common, is ASCII encoding in text analytics. A small sample ASCII table is shown to the right.
Any human would know that this is just six different spellings for the same word, but to a computer these are six different words. These would spawn six different columns in our term-frequency matrix. This will bloat our already enormous term-frequency matrix, as well as complicate or even prevent useful analysis.
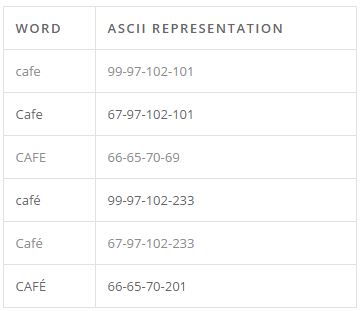
Unify words with the same spelling
To unify the six different “CAFÉ’s”, we can perform two simple global transformations.
Casing: First we must convert all characters to the same casing, uppercase or lowercase. This is a common enough operation. Most programming languages have a built-in function that converts all characters into a string into either lowercase or uppercase. We can choose either global lowercasing or global uppercasing, it does not matter as long as it’s applied globally.
String normalization: Second, we must convert all accented characters to their unaccented variants. This is often called Unicode normalization, since accented and other special characters are usually encoded using the Unicode standard rather than the ASCII standard. Not all programming languages have this feature out of the box, but most have at least one package which will perform this function.
Note that implementations vary, so you should not mix and match Unicode normalization packages. What kind of normalization you do is highly language dependent, as characters which are interchangeable in English may not be in other languages (such as Italian, French, or Vietnamese).
Remove special characters and numbers
The next thing we have to do is remove special characters and numbers. Numbers rarely contain useful meaning. Examples of such irrelevant numbers include footnote numbering and page numbering. Special characters, as discussed in the string normalization section, have a habit of bloating our term-frequency matrix. For instance, representing a quotation mark has been a pain-point since the beginning of computer science.
Unlike a letter, which may only be capital or not capital, quotation marks have many popular representations. A quotation character has three main properties: curly, straight, or angled; left or right; single, double, or triple. Depending on the text analytics encoding used, not all of these may exist.
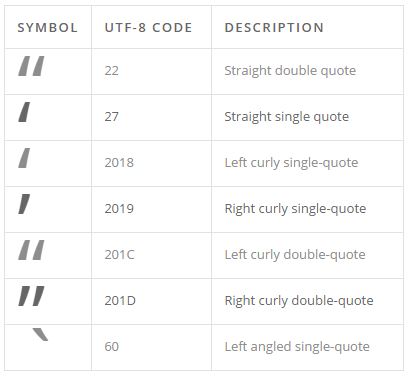
The table below shows how quoting the word “café” in both straight quote and left-right quotes would look in a UTF-8 table in Arial font.

Avoid over-cleaning
The problem is further complicated by each individual font, operating system, and programming language since implementation of the various encoding standards is not always consistent. A common solution is to simply remove all special characters and numeric digits from the text. However, removing all special characters and numbers can have negative consequences.
There is a thing as too much data cleaning when it comes to text analytics. The more we clean and remove the more “lost in translation” the textual message may become. We may inadvertently strip information or meaning from our messages so that by the time our machine learning algorithm sees the textual data, much or all the relevant information has been stripped away.
For each type of cleaning above, there are situations in which you will want to either skip it altogether or selectively apply it. As in all data science situations, experimentation and good domain knowledge are required to achieve the best results.
When do we want to avoid over-cleaning in your text analytics?
Special characters: The advent of email, social media, and text messaging have given rise to text-based emoticons represented by ASCII special characters.
For example, if you were building a sentiment predictor for text, text-based emoticons like “=)” or “>:(” are very indicative of sentiment because they directly reference happy or sad. Stripping our messages of these emoticons by removing special characters will also strip meaning from our message.
Numbers: Consider the infinitely gridlocked freeway in Washington state, “I-405.” In a sentiment predictor model, anytime someone talks about “I-405,” more likely than not the document should be classified as “negative.” However, by removing numbers and special characters, the word now becomes “I”. Our models will be unable to use this information, which, based on domain knowledge, we would expect to be a strong predictor.
Casing: Even cases can carry useful information sometimes. For instance, the word “trump” may carry a different sentiment than “Trump” with a capital T, representing someone’s last name.
One solution to filter out proper nouns that may contain information is through name entity recognition, where we use a combination of predefined dictionaries and scanning of the surrounding syntax (sometimes called “lexical analysis”). Using this, we can identify people, organizations, and locations.
Next, we’ll talk about stemming and Lemmatization as a way to help computers understand that different versions of words can have the same meaning (ex. run, running, runs).
Learn more
Want to learn more about text analytics? Check out the short video on our curriculum page OR