

Word embeddings provide a way to present complex data in a way that is understandable by machines. Hence, acting as a translator, it converts human language into a machine-readable form. Their impact on ML tasks has made them a cornerstone of AI advancements.
Understand Embeddings 101: The Foundation of Large Language Models
These embeddings, when particularly used for natural language processing (NLP) tasks, are also referred to as LLM embeddings. In this blog, we will focus on these embeddings in LLM and explore how they have evolved over time within the world of NLP, each transformation being a result of technological advancement and progress.
This journey of continuous evolution of LLM embeddings is key to the enhancement of large language model performance and its improved understanding of the human language. Before we take a trip through the journey of embeddings from the beginning, let’s revisit the impact of embeddings on LLMs.

Impact of Embeddings on LLMs
It is the introduction of embeddings that has transformed LLMs over time from basic text processors to powerful tools that understand language. They have empowered language models to move beyond tasks of simple text manipulation to generate complex and contextually relevant content.
With a deeper understanding of the human language, LLM embeddings have also facilitated these models to generate outputs with greater accuracy. Hence, in their own journey of evolution through the years, embeddings have transformed LLMs to become more efficient and creative, generating increasingly innovative and coherent responses.
Understand the role of embeddings in generative AI
Let’s take a step back and travel through the journey of LLM embeddings from the start to the present day, understanding their evolution every step of the way.
Growth Stages of Word Embeddings
Embeddings have revolutionized the functionality and efficiency of LLMs. The journey of their evolution has empowered large language models to do much more with the content. Let’s get a glimpse of the journey of LLM embeddings to understand the story behind the enhancement of LLMs.
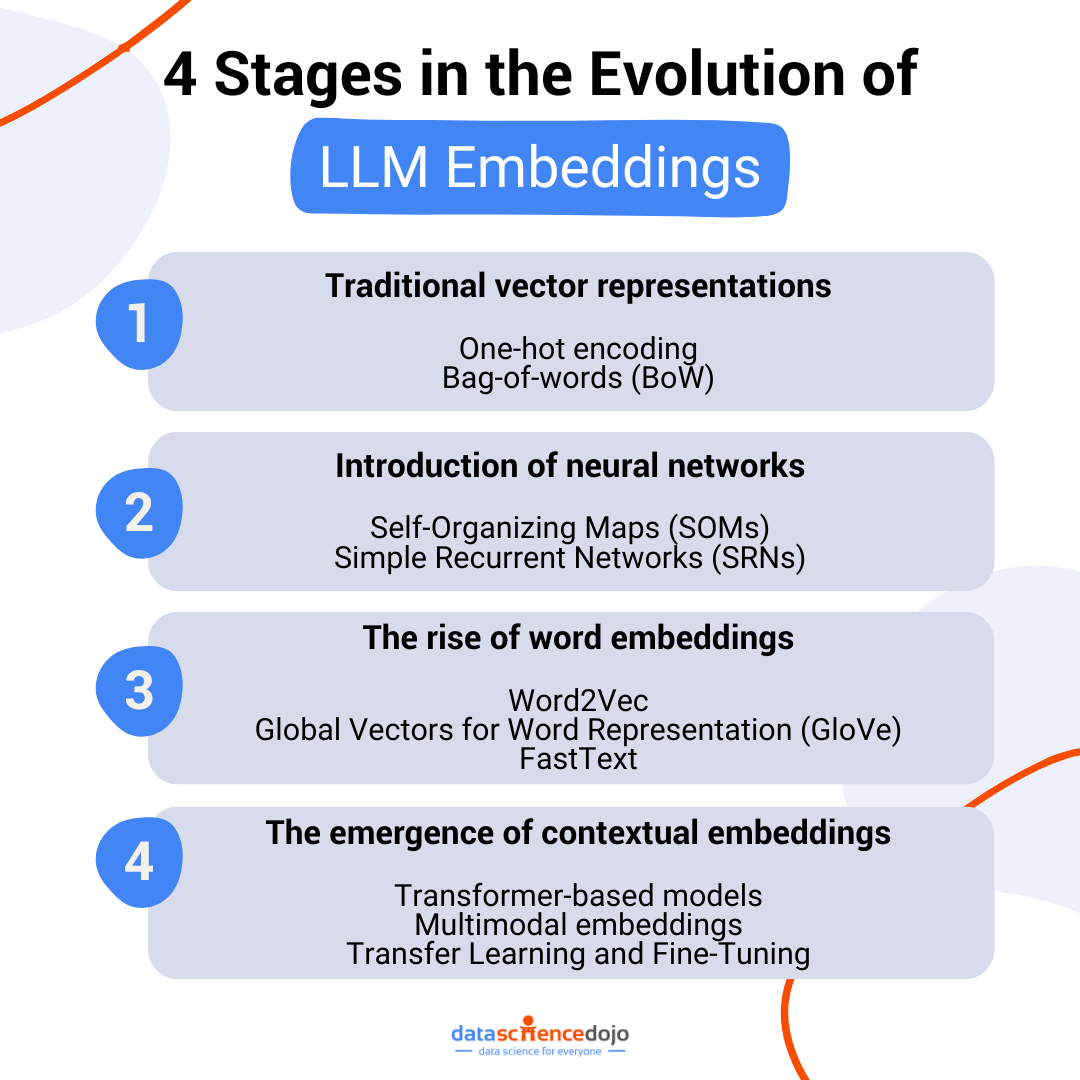
Stage 1: Traditional vector representations
The earliest word representations were in the form of traditional vectors for machines, where words were treated as isolated entities within a text. While it enabled machines to read and understand words, it failed to capture the contextual relationships between words.
Explore the guide to find the difference between Traditional vs Vector databases
Techniques present in this era of language models included:
One-hot encoding
It converts categorical data into a machine-readable format by creating a new binary feature for each category of a data point. It allows ML models to work with data but in a limited manner. Moreover, the technique is more suited to numerical data than textual input.
Bag-of-words (BoW)
This technique focuses on summarizing textual data by creating a simple feature for each word in the input data. BoW does not focus on the order of words in a text. Hence, while it is helpful to develop a basic understanding of a document, it is limited in forming a connection between words to grasp a deeper meaning.
Stage 2: Introduction of neural networks
The next step for LLM embeddings was the introduction of neural networks to capture the contextual information within the data.
Here’s a comprehensive guide to understanding neural networks
New techniques to translate data for machines were used using neural networks, which primarily included:
Self-Organizing Maps (SOMs)
These are useful to explore high-dimensional data, like textual information that has many features. SOMs work to bring down the information into a 2-dimensional map where similar data points form clusters, providing a starting point for advanced embeddings.
Simple Recurrent Networks (SRNs)
The strength of SRNs lies in their ability to handle sequences like text. They function by remembering past inputs to learn more contextual information. However, with long sequences, the networks failed to capture the intricate nuances of language.
Stage 3: The rise of word embeddings
It marks one of the major transitions in the history of LLM embeddings. The idea of word embeddings brought forward the vector representation of words. It also resulted in the formation of more refined word clusters in the three-dimensional space, capturing the semantic relationship between words in a better way.
Some popular word embedding models are listed below.
Word2Vec
It is a word embedding technique that considers the surrounding words in a text and their co-occurrence to determine the complete contextual information.
Using this information, Word2Vec creates a unique vector representation of each word, creating improved clusters for similar words. This allows machines to grasp the nuances of language and perform tasks like machine translation and text summarization more effectively.
Global Vectors for Word Representation (GloVe)
It takes on a statistical approach in determining the contextual information of words and analyzing how effectively words contribute to the overall meaning of a document.
With a broader analysis of co-occurrences, GloVe captures the semantic similarity and any analogies in the data. It creates informative word vectors that enhance tasks like sentiment analysis and text classification.
FastText
This word embedding technique involves handling out-of-vocabulary (OOV) words by incorporating subword information. It functions by breaking down words into smaller units called n-grams. FastText creates representations by analyzing the occurrences of n-grams within words.
Stage 4: The emergence of contextual embeddings
This stage is marked by embeddings and gathering contextual information after the analysis of surrounding words and sentences. It creates a dynamic representation of words based on the specific context in which they appear. The era of contextual embeddings has evolved in the following manner:
Transformer-based models
The use of transformer-based models like BERT has boosted the revolution of embeddings. Using a transformer architecture, a model like BERT generates embeddings that capture both contextual and syntactic information, leading to highly enhanced performance on various NLP tasks.
Navigate transformer models to understand how they will shape the future of NLP
Multimodal embeddings
As data complexity has increased, embeddings are also created to cater to the various forms of information like text, image, audio, and more. Models like OpenAI’s CLIP (Contrastive Language-Image Pretraining) and Vision Transformer (ViT) enable joint representation learning, allowing embeddings to capture cross-modal relationships.
Transfer Learning and Fine-Tuning
Techniques of transfer learning and fine-tuning pre-trained embeddings have also facilitated the growth of embeddings since they eliminate the need for training from scratch. Leveraging these practices results in more specialized LLMs dealing with specific tasks within the realm of NLP.
Hence, the LLM embeddings started off from traditional vector representations and have evolved from simple word embeddings to contextual embeddings over time. While we now understand the different stages of the journey of embeddings in NLP tasks, let’s narrow our lens towards a comparative look at things.
Read more about fine-tuning LLMs
Through a Lens of Comparative Analysis
Embeddings have played a crucial role in NLP tasks to enhance the accuracy of translation from human language to machine-readable form. With context and meaning as major nuances of human language, embeddings have evolved to apply improved techniques to generate the closest meaning of textual data for ML tasks.
A comparative analysis of some important stages of evolution for LLM embeddings presents a clearer understanding of the aspects that have improved and in what ways.
Word embeddings vs contextual embeddings
Word embeddings and contextual embeddings are both techniques used in NLP to represent words or phrases as numerical vectors. They differ in the way they capture information and the context in which they operate.
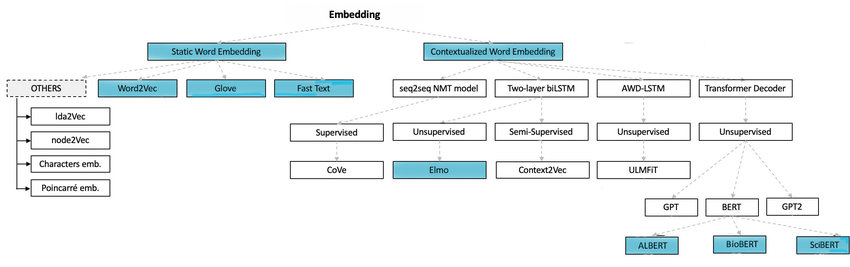
Word embeddings represent words in a fixed-dimensional vector space, giving each unit a unique code that presents its meaning. These codes are based on co-occurrence patterns or global statistics, where each word’s code has a single vector representation regardless of its context.
In this way, word embeddings capture the semantic relationships between words, allowing for tasks like word similarity and analogy detection. They are particularly useful when the meaning of a word remains relatively constant across different contexts.
Popular word embedding techniques include Word2Vec and GloVe.
On the other hand, contextual embeddings consider the surrounding context of a word or phrase, creating a more contextualized vector representation. It enables them to capture the meaning of words based on the specific context in which they appear, allowing for more nuanced and dynamic representations.
Contextual embeddings are trained using deep neural networks. They are particularly useful for tasks like sentiment analysis, machine translation, and question answering, where capturing the nuances of meaning is crucial. Common examples of contextual embeddings include ELMo and BERT.

Hence, it is evident that while word embeddings provide fixed representations in a vector space, contextual embeddings generate more dynamic results based on the surrounding context. The choice between the two depends on the specific NLP task and the level of context sensitivity required.
Unsupervised vs. supervised learning for embeddings
While vector representation and contextual inference remain important factors in the evolution of LLM embeddings, the lens of comparative analysis also highlights another aspect for discussion. It involves the different approaches to train embeddings. The two main approaches of interest for embeddings include unsupervised and supervised learning.
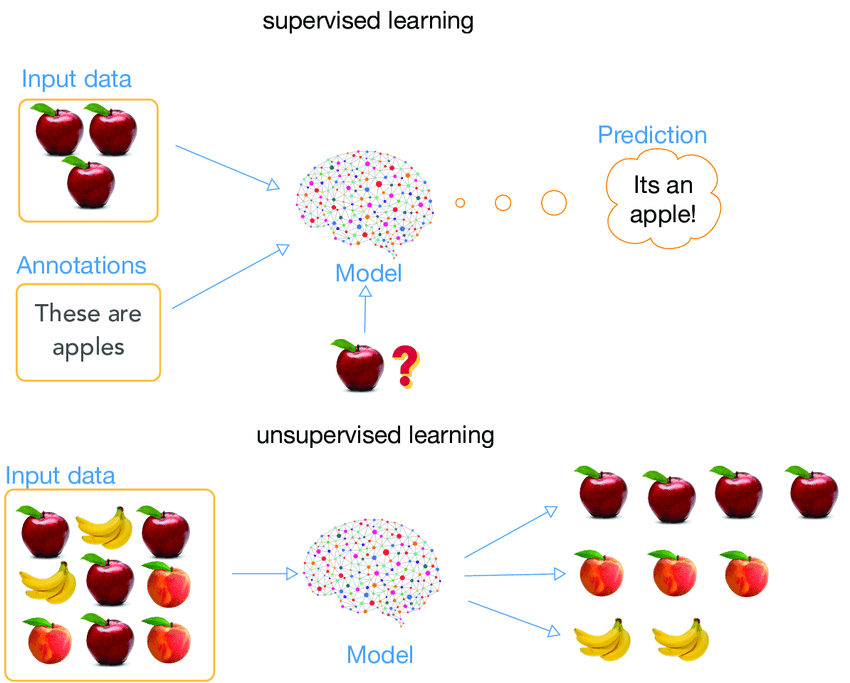
As the name suggests, unsupervised learning is a type of approach that allows the model to learn patterns and analyze massive amounts of text without any labels or guidance. It aims to capture the inherent structure of the data by finding meaningful representations without any specific task in mind.
Word2Vec and GloVe use unsupervised learning, focusing on how often words appear together to capture the general meaning. They use techniques like neural networks to learn word embeddings based on co-occurrence patterns in the data.
Since unsupervised learning does not require labeled data, it is easier to execute and manage. It is suitable for tasks like word similarity, analogy detection, and even discovering new relationships between words. However, it is limited in its accuracy, especially for words with multiple meanings.
On the contrary, supervised learning requires labeled data where each unit has explicit input-output pairs to train the model. These algorithms train embeddings by leveraging labeled data to learn representations that are optimized for a specific task or prediction.
Learn more about embeddings as building blocks for LLMs
BERT and ELMo are techniques that use supervised learning to capture the meaning of words based on their specific context. These algorithms are trained on large datasets and fine-tuned for specialized tasks like sentiment analysis, named entity recognition and question answering. However, labeling data can be an expensive and laborious task.
When it comes to choosing the appropriate approach to train embeddings, it depends on the availability of labeled data. Moreover, it is also linked to your needs, where general understanding can be achieved through unsupervised learning but contextual accuracy requires supervised learning.
Another way out is to combine the two approaches when training your embeddings. It can be done by using unsupervised methods to create a foundation and then fine-tuning them with supervised learning for your specific task. This refers to the concept of pre-training of word embeddings.

The Role of Pre-Training in Embedding Quality
Pre-training refers to the unsupervised learning of a model through massive amounts of textual data before its fine-tuning. By analyzing this data, the model builds a strong understanding of how words co-occur, how sentences work, and how context influences meaning.
It plays a crucial role in embedding quality as it determines a model’s understanding of language fundamentals, impacting the accuracy of an LLM to capture contextual information. It leads to improved performance in tasks like sentiment analysis and machine translation. Hence, with more comprehensive pre-training, you get better results from embeddings.
What is Next in Word Embeddings?
The future of LLM embeddings is brimming with potential. With transformer-based and multimodal embeddings, there is immense room for further advancements.
The future is also about making LLM embeddings more accessible and applicable to real-world problems, from education to chatbots that can navigate complex human interactions and much more. Hence, it is about pushing the boundaries of language understanding and communication in AI.