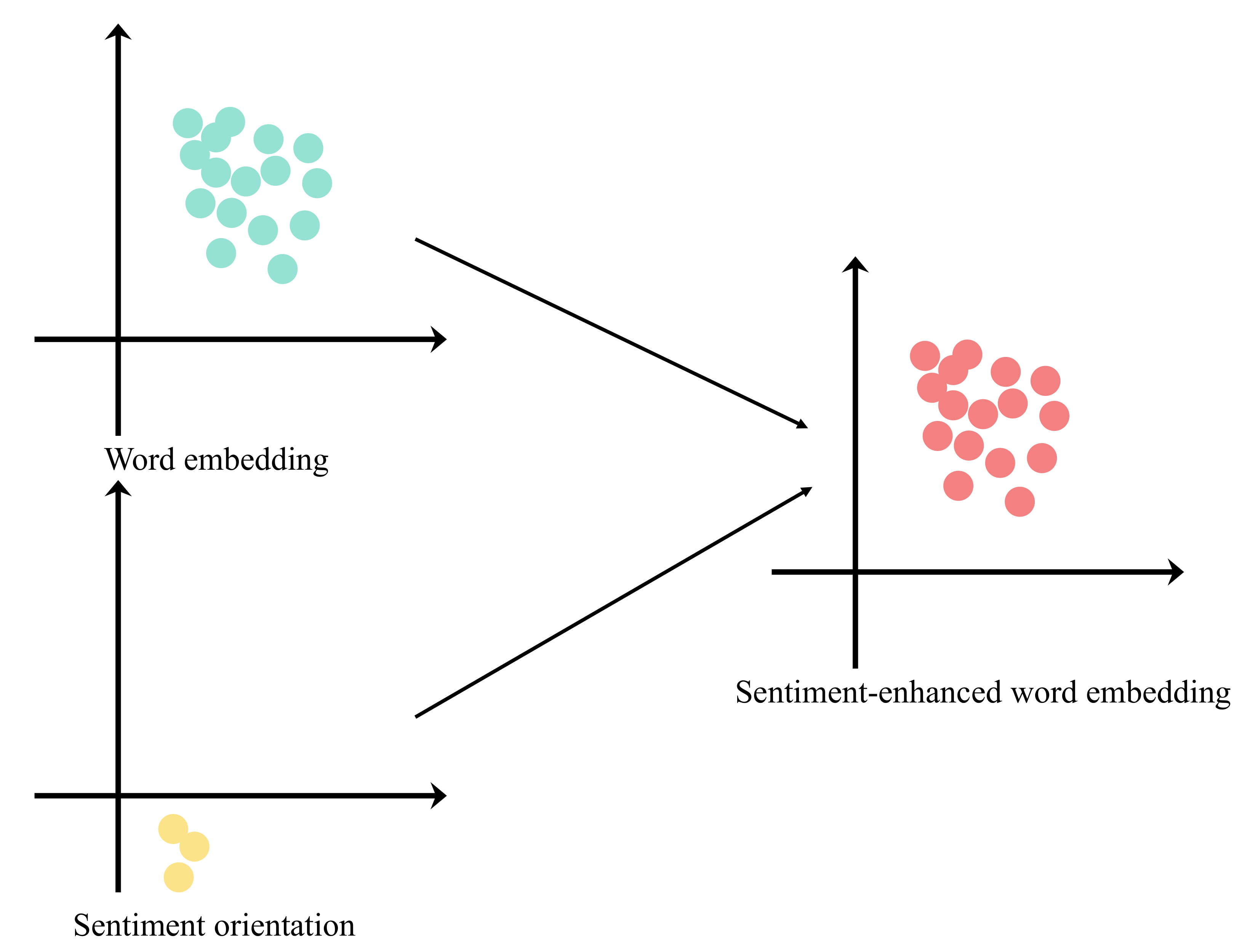
Word embeddings provide a way to present complex data in a way that is understandable by machines. Hence, acting as a translator, it converts human language into a machine-readable form. Their impact on ML tasks has made them a cornerstone of AI advancements.
Understand Embeddings 101: The Foundation of Large Language Models
These embeddings, when particularly used for natural language processing (NLP) tasks, are also referred to as LLM embeddings. In this blog, we will focus on these embeddings in LLM and explore how they have evolved over time within the world of NLP, each transformation being a result of technological advancement and progress.
This journey of continuous evolution of LLM embeddings is key to the enhancement of large language model performance and its improved understanding of the human language. Before we take a trip through the journey of embeddings from the beginning, let’s revisit the impact of embeddings on LLMs.
Impact of Embeddings on LLMs
It is the introduction of embeddings that has transformed LLMs over time from basic text processors to powerful tools that understand language. They have empowered language models to move beyond tasks of simple text manipulation to generate complex and contextually relevant content.
With a deeper understanding of the human language, LLM embeddings have also facilitated these models to generate outputs with greater accuracy. Hence, in their own journey of evolution through the years, embeddings have transformed LLMs to become more efficient and creative, generating increasingly innovative and coherent responses.
Let’s take a step back and travel through the journey of LLM embeddings from the start to the present day, understanding their evolution every step of the way.
Growth Stages of Word Embeddings
Embeddings have revolutionized the functionality and efficiency of LLMs. The journey of their evolution has empowered large language models to do much more with the content. Let’s get a glimpse of the journey of LLM embeddings to understand the story behind the enhancement of LLMs.
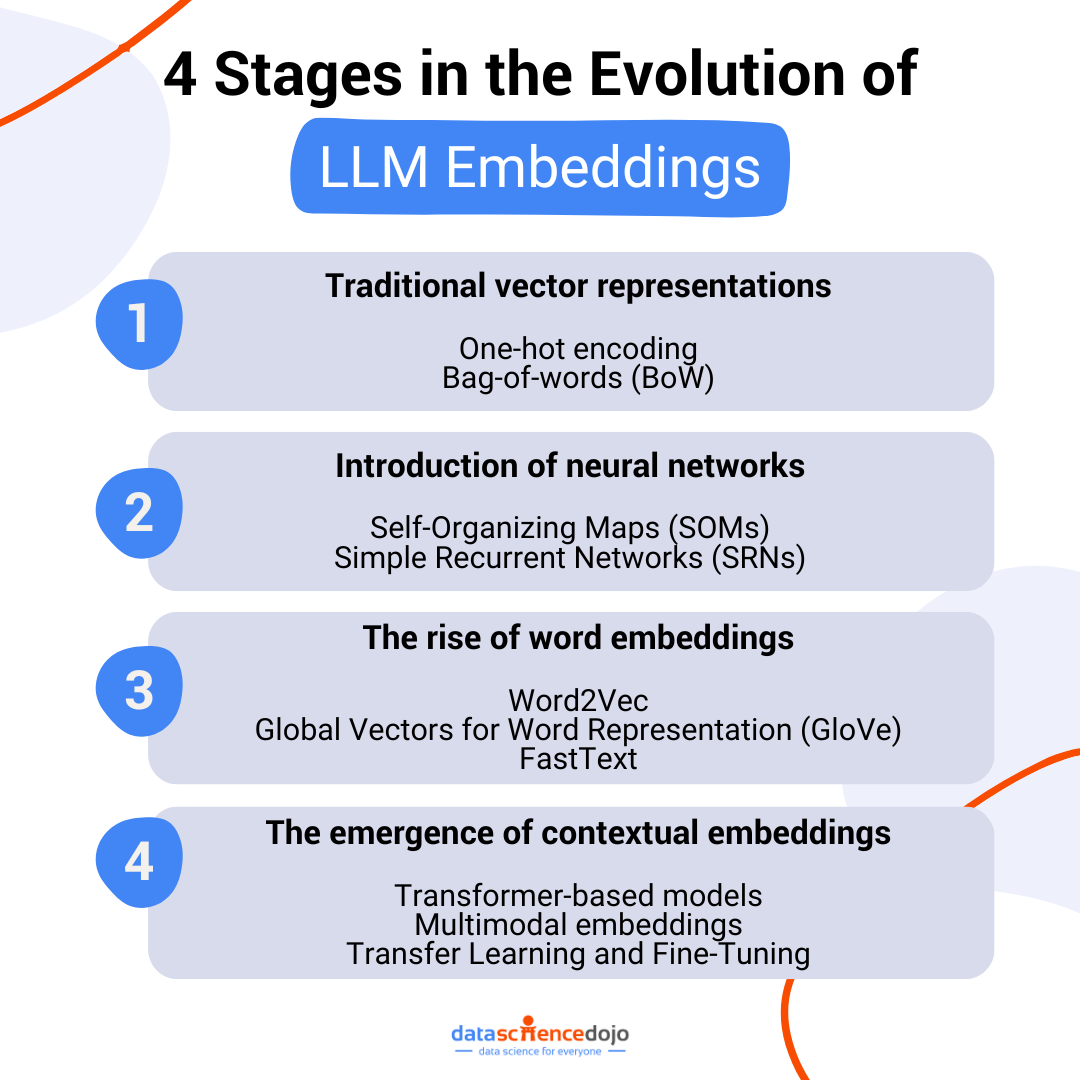
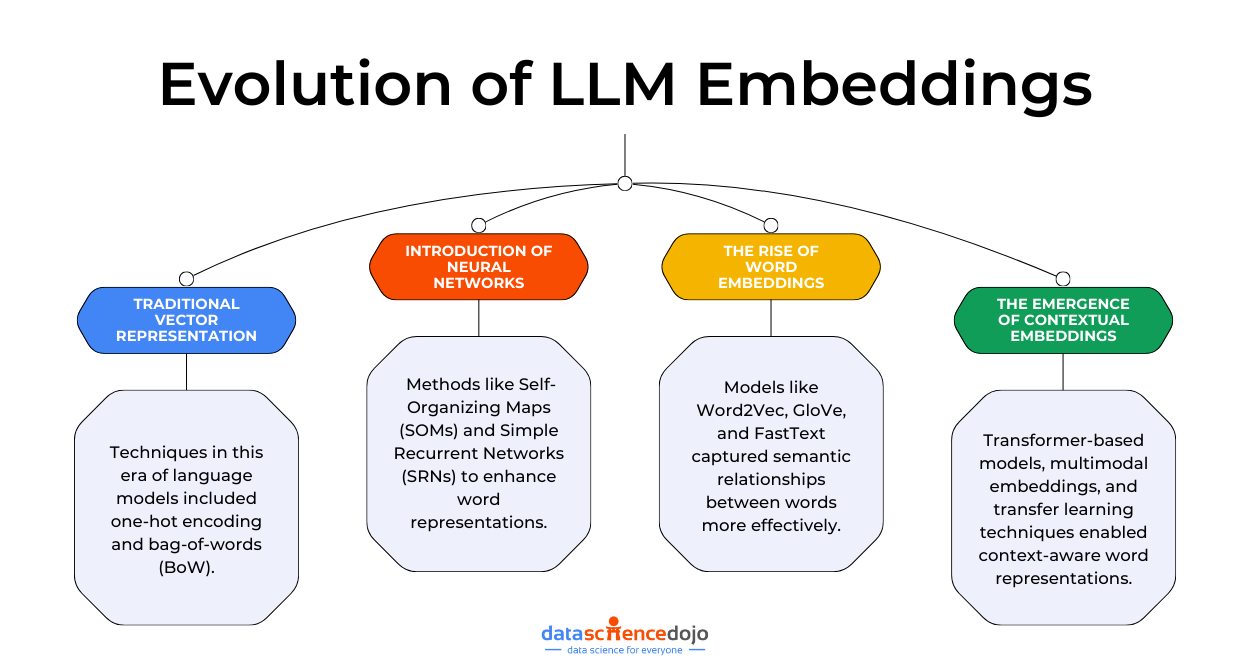
Stage 1: Traditional vector representations
The earliest word representations were in the form of traditional vectors for machines, where words were treated as isolated entities within a text. While it enabled machines to read and understand words, it failed to capture the contextual relationships between words.
Techniques present in this era of language models included:
One-hot encoding
It converts categorical data into a machine-readable format by creating a new binary feature for each category of a data point. It allows ML models to work with data but in a limited manner. Moreover, the technique is more suited to numerical data than textual input.
Bag-of-words (BoW)
This technique focuses on summarizing textual data by creating a simple feature for each word in the input data. BoW does not focus on the order of words in a text. Hence, while it is helpful to develop a basic understanding of a document, it is limited in forming a connection between words to grasp a deeper meaning.
Stage 2: Introduction of neural networks
The next step for LLM embeddings was the introduction of neural networks to capture the contextual information within the data.
New techniques to translate data for machines were used using neural networks, which primarily included:
Self-Organizing Maps (SOMs)
These are useful to explore high-dimensional data, like textual information that has many features. SOMs work to bring down the information into a 2-dimensional map where similar data points form clusters, providing a starting point for advanced embeddings.
Simple Recurrent Networks (SRNs)
The strength of SRNs lies in their ability to handle sequences like text. They function by remembering past inputs to learn more contextual information. However, with long sequences, the networks failed to capture the intricate nuances of language.
Stage 3: The rise of word embeddings
It marks one of the major transitions in the history of LLM embeddings. The idea of word embeddings brought forward the vector representation of words. It also resulted in the formation of more refined word clusters in the three-dimensional space, capturing the semantic relationship between words in a better way.
Some popular word embedding models are listed below.
Word2Vec
It is a word embedding technique that considers the surrounding words in a text and their co-occurrence to determine the complete contextual information.
Using this information, Word2Vec creates a unique vector representation of each word, creating improved clusters for similar words. This allows machines to grasp the nuances of language and perform tasks like machine translation and text summarization more effectively.
Global Vectors for Word Representation (GloVe)
It takes on a statistical approach in determining the contextual information of words and analyzing how effectively words contribute to the overall meaning of a document.
With a broader analysis of co-occurrences, GloVe captures the semantic similarity and any analogies in the data. It creates informative word vectors that enhance tasks like sentiment analysis and text classification.
FastText
This word embedding technique involves handling out-of-vocabulary (OOV) words by incorporating subword information. It functions by breaking down words into smaller units called n-grams. FastText creates representations by analyzing the occurrences of n-grams within words.
Stage 4: The emergence of contextual embeddings
This stage is marked by embeddings and gathering contextual information after the analysis of surrounding words and sentences. It creates a dynamic representation of words based on the specific context in which they appear. The era of contextual embeddings has evolved in the following manner:
Transformer-based models
The use of transformer-based models like BERT has boosted the revolution of embeddings. Using a transformer architecture, a model like BERT generates embeddings that capture both contextual and syntactic information, leading to highly enhanced performance on various NLP tasks.
Navigate transformer models to understand how they will shape the future of NLP
Multimodal embeddings
As data complexity has increased, embeddings are also created to cater to the various forms of information like text, image, audio, and more. Models like OpenAI’s CLIP (Contrastive Language-Image Pretraining) and Vision Transformer (ViT) enable joint representation learning, allowing embeddings to capture cross-modal relationships.
Transfer Learning and Fine-Tuning
Techniques of transfer learning and fine-tuning pre-trained embeddings have also facilitated the growth of embeddings since they eliminate the need for training from scratch. Leveraging these practices results in more specialized LLMs dealing with specific tasks within the realm of NLP.
Hence, the LLM embeddings started off from traditional vector representations and have evolved from simple word embeddings to contextual embeddings over time. While we now understand the different stages of the journey of embeddings in NLP tasks, let’s narrow our lens towards a comparative look at things.
Embeddings have played a crucial role in NLP tasks to enhance the accuracy of translation from human language to machine-readable form. With context and meaning as major nuances of human language, embeddings have evolved to apply improved techniques to generate the closest meaning of textual data for ML tasks.
A comparative analysis of some important stages of evolution for LLM embeddings presents a clearer understanding of the aspects that have improved and in what ways.
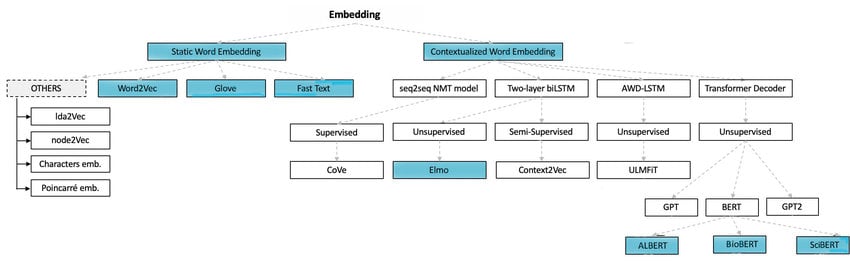
Word embeddings vs contextual embeddings
Word embeddings and contextual embeddings are both techniques used in NLP to represent words or phrases as numerical vectors. They differ in the way they capture information and the context in which they operate.
Comparison of word and contextual embeddings at a glance – Source: ResearchGate
Word embeddings represent words in a fixed-dimensional vector space, giving each unit a unique code that presents its meaning. These codes are based on co-occurrence patterns or global statistics, where each word’s code has a single vector representation regardless of its context.
In this way, word embeddings capture the semantic relationships between words, allowing for tasks like word similarity and analogy detection. They are particularly useful when the meaning of a word remains relatively constant across different contexts.
Popular word embedding techniques include Word2Vec and GloVe.
On the other hand, contextual embeddings consider the surrounding context of a word or phrase, creating a more contextualized vector representation. It enables them to capture the meaning of words based on the specific context in which they appear, allowing for more nuanced and dynamic representations.
Contextual embeddings are trained using deep neural networks. They are particularly useful for tasks like sentiment analysis, machine translation, and question answering, where capturing the nuances of meaning is crucial. Common examples of contextual embeddings include ELMo and BERT.
Hence, it is evident that while word embeddings provide fixed representations in a vector space, contextual embeddings generate more dynamic results based on the surrounding context. The choice between the two depends on the specific NLP task and the level of context sensitivity required.
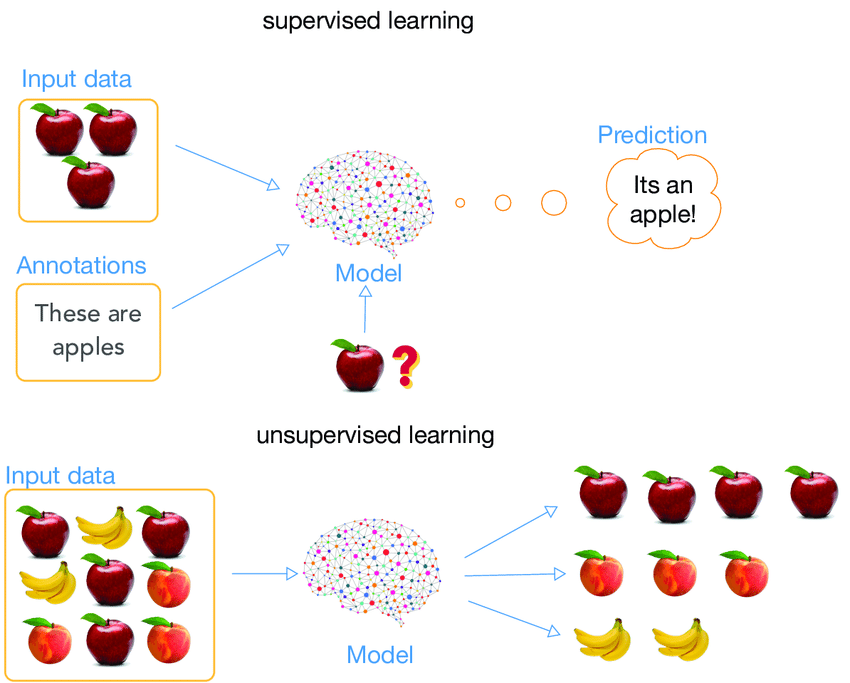
Unsupervised vs. supervised learning for embeddings
While vector representation and contextual inference remain important factors in the evolution of LLM embeddings, the lens of comparative analysis also highlights another aspect for discussion. It involves the different approaches to train embeddings. The two main approaches of interest for embeddings include unsupervised and supervised learning.
Visually representing unsupervised and supervised learning – Source: ResearchGate
As the name suggests, unsupervised learning is a type of approach that allows the model to learn patterns and analyze massive amounts of text without any labels or guidance. It aims to capture the inherent structure of the data by finding meaningful representations without any specific task in mind.
Word2Vec and GloVe use unsupervised learning, focusing on how often words appear together to capture the general meaning. They use techniques like neural networks to learn word embeddings based on co-occurrence patterns in the data.
Since unsupervised learning does not require labeled data, it is easier to execute and manage. It is suitable for tasks like word similarity, analogy detection, and even discovering new relationships between words. However, it is limited in its accuracy, especially for words with multiple meanings.
On the contrary, supervised learning requires labeled data where each unit has explicit input-output pairs to train the model. These algorithms train embeddings by leveraging labeled data to learn representations that are optimized for a specific task or prediction.
Learn more about embeddings as building blocks for LLMs
BERT and ELMo are techniques that use supervised learning to capture the meaning of words based on their specific context. These algorithms are trained on large datasets and fine-tuned for specialized tasks like sentiment analysis, named entity recognition and question answering. However, labeling data can be an expensive and laborious task.
When it comes to choosing the appropriate approach to train embeddings, it depends on the availability of labeled data. Moreover, it is also linked to your needs, where general understanding can be achieved through unsupervised learning but contextual accuracy requires supervised learning.
Another way out is to combine the two approaches when training your embeddings. It can be done by using unsupervised methods to create a foundation and then fine-tuning them with supervised learning for your specific task. This refers to the concept of pre-training of word embeddings.
The Role of Pre-Training in Embedding Quality
Pre-training refers to the unsupervised learning of a model through massive amounts of textual data before its fine-tuning. By analyzing this data, the model builds a strong understanding of how words co-occur, how sentences work, and how context influences meaning.
It plays a crucial role in embedding quality as it determines a model’s understanding of language fundamentals, impacting the accuracy of an LLM to capture contextual information. It leads to improved performance in tasks like sentiment analysis and machine translation. Hence, with more comprehensive pre-training, you get better results from embeddings.
What is Next in Word Embeddings?
The future of LLM embeddings is brimming with potential. With transformer-based and multimodal embeddings, there is immense room for further advancements.
The future is also about making LLM embeddings more accessible and applicable to real-world problems, from education to chatbots that can navigate complex human interactions and much more. Hence, it is about pushing the boundaries of language understanding and communication in AI.
Artificial intelligence (AI) and generative AI may be the most important technology of any lifetime. This insight underscores the transformative power of AI in today’s world.
At the heart of these many AI applications lies the vector embedding model – a tool that translates complex data into meaningful vectors, enabling machines to understand and generate human-like content. Hence, selecting the right vector embedding model isn’t just a technical decision, but pivotal to the success of your AI initiatives.
In this guide, we’ll delve into the essentials of vector embedding models and provide actionable insights to help you make informed choices for your AI applications. Let’s look into the right tools you will need to unleash the true potential of generative AI.
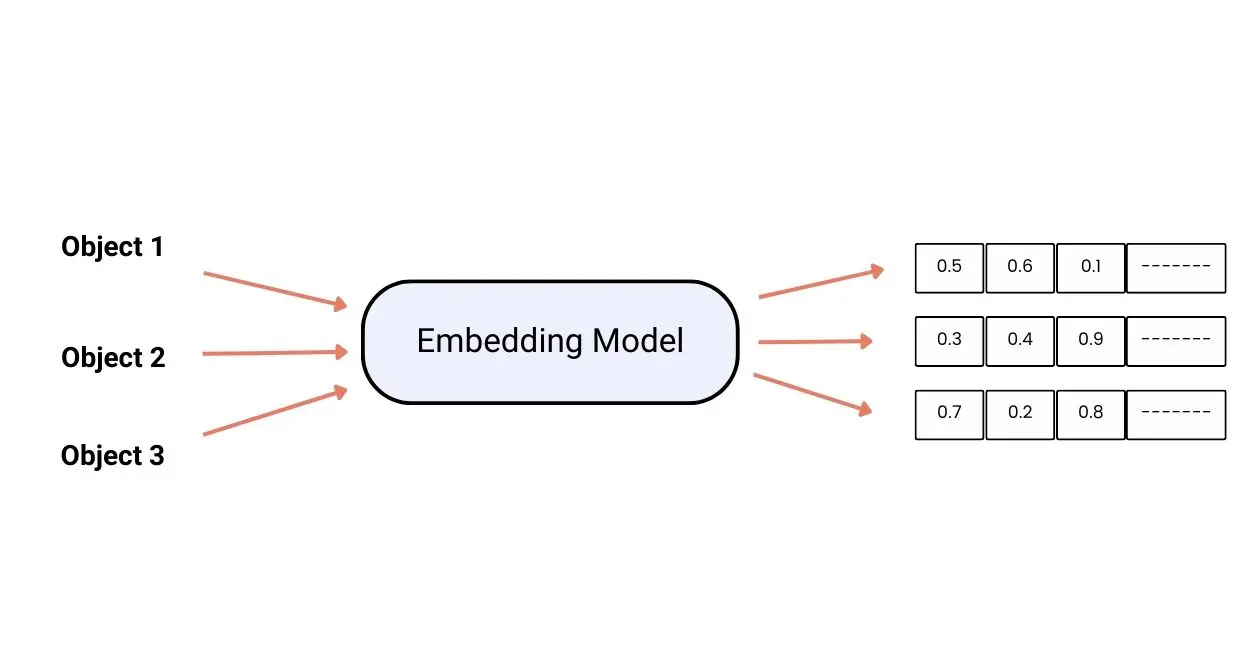
What are Vector Embedding Models?
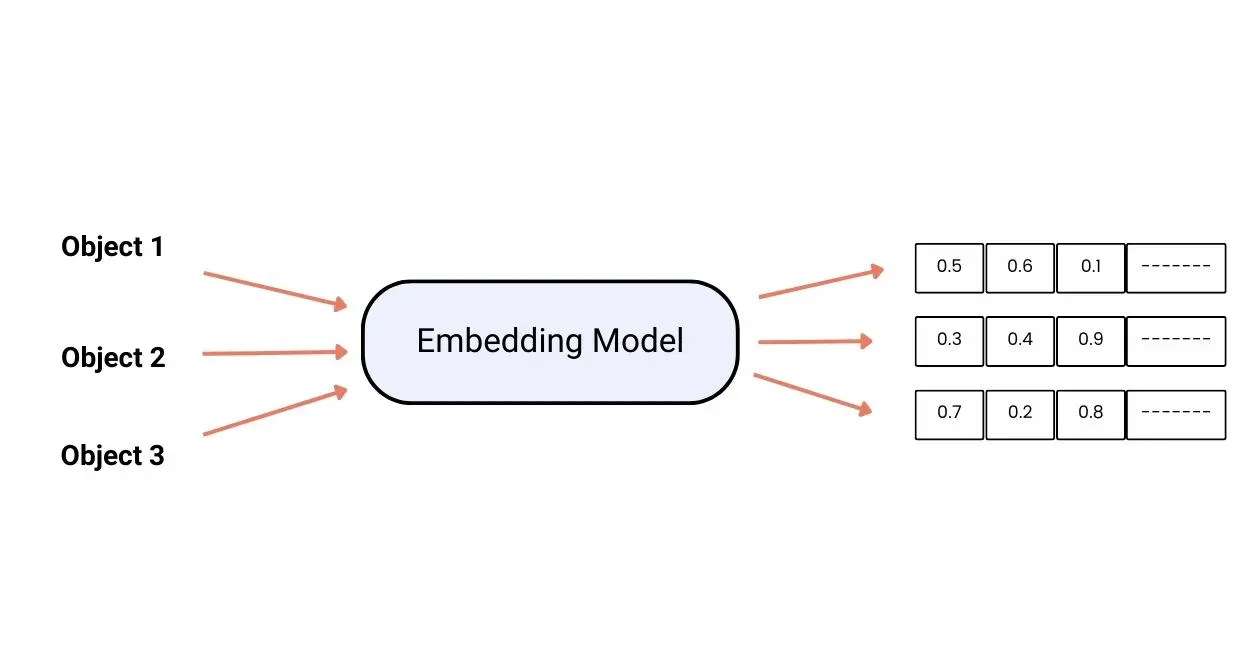
The function of a vector embedding model
These act as data translators that can convert any data into a numerical code, specifically a vector of numbers. The model operates to create vectors that capture the meaning and semantic similarity between data objects. It results in the creation of a map that can be used to study data connections.
Moreover, the embedding models allow better control over the content and style of generated outputs, while dealing with multimodal data. Hence, it can deal with text, images, code, and other forms of data.
While we understand the role and importance of embedding models in the world of vector databases, the selection of the right model is crucial for the success of an AI application. Let’s dig deeper into the details of making the relevant choice.
Since a vector embedding model forms the basis of your generative AI application, your choice is crucial for its success.
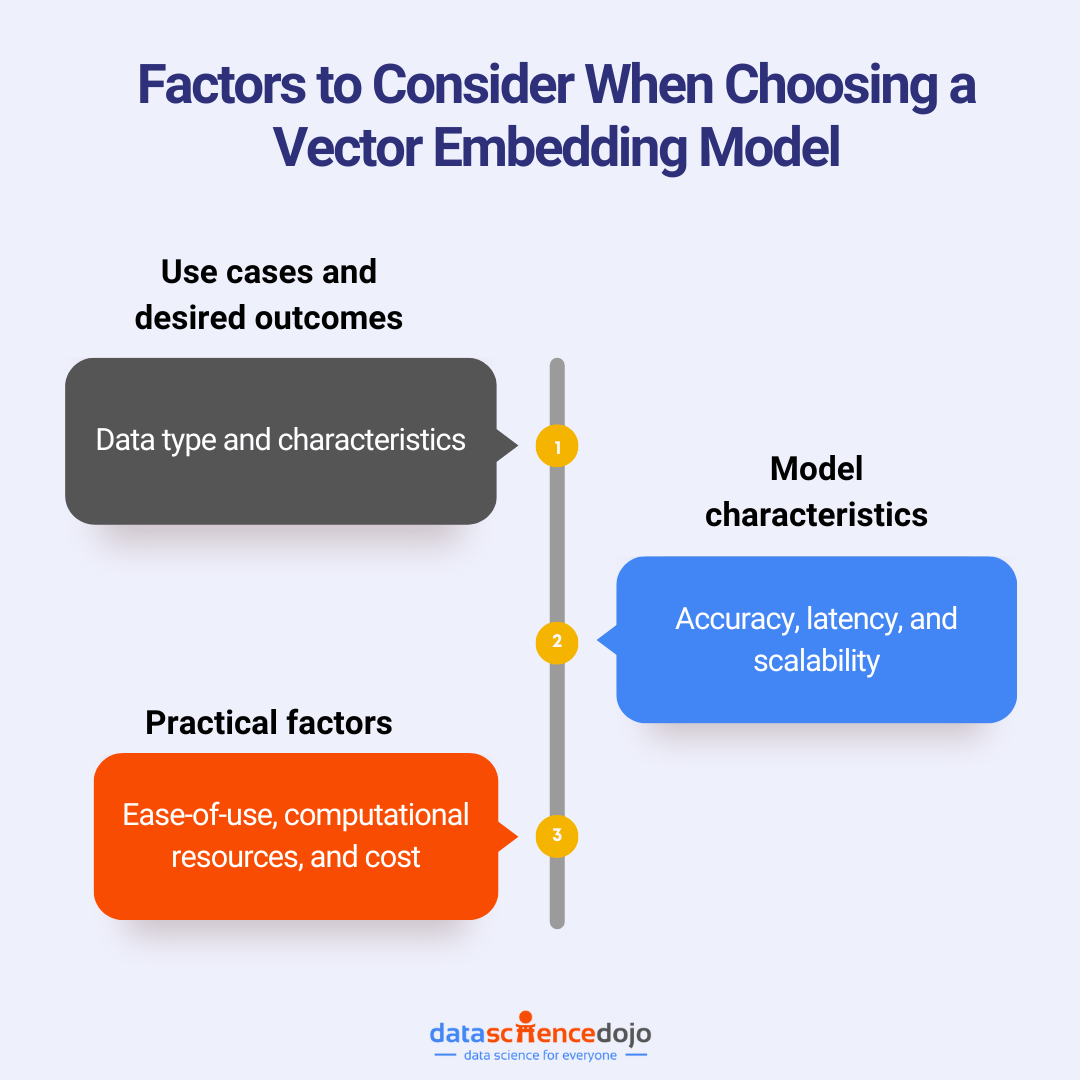
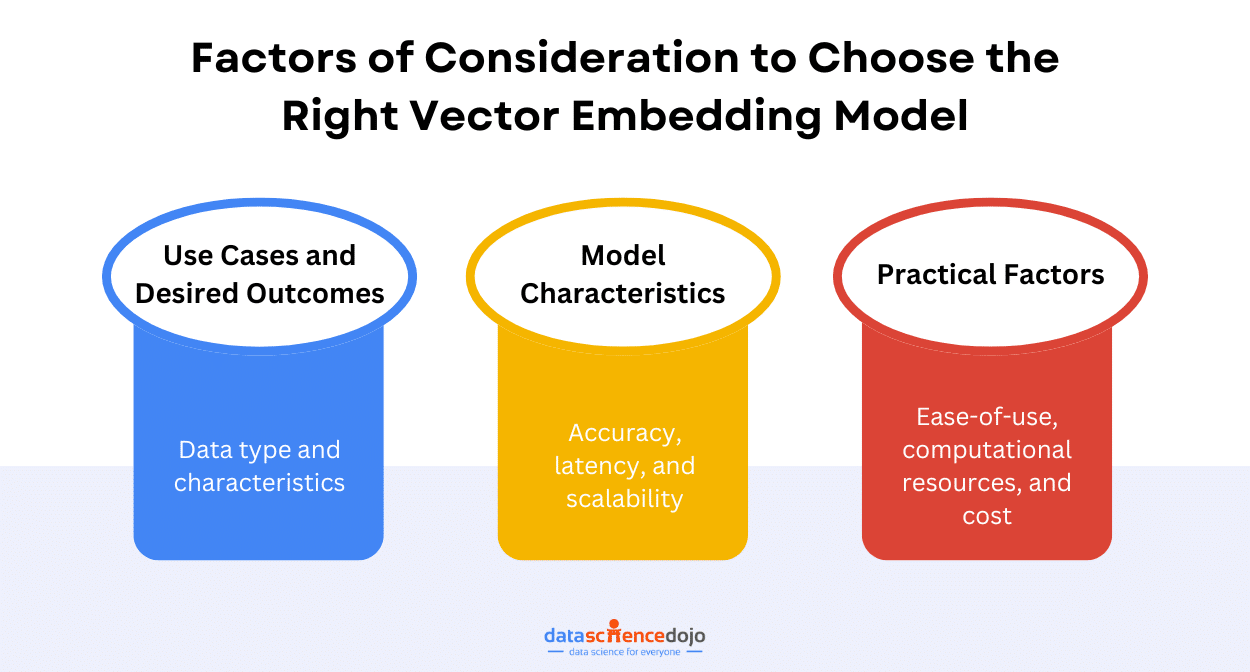
Factors to consider when choosing a vector embedding model
Below are some key factors to consider when exploring your model options.
Use Case and Desired Outcomes
In any choice, your goals and objectives are the most important aspect. The same holds true for your embedding model selection. The use case and outcomes of your generative AI application guide your choice of model.
The type of task you want your app to perform is a crucial factor as different models capture specific aspects of data. The tasks can range from text generation and summarization to code completion and more. You must be clear about your goal before you explore the available options.
Moreover, data characteristics are of equal importance. Your data type – text, code, or image – must be compatible with your data format.
Model Characteristics
The particular model characteristics of consideration include its accuracy, latency, and scalability. Accuracy refers to the ability of the model to correctly capture data relationships, including semantic meaning, word order, and linguistic nuances.
Latency is another important property that caters to real-time interactions of the application, improving the model’s performance with reduced inference time. The size and complexity of data can impact this characteristic of an embedding model.
Moreover, to keep up with the rapidly advancing AI, it is important to choose a model that supports scalability. It also ensures that the model can cater to your growing dataset needs.
Practical Factors
While app requirements and goals are crucial to your model choice, several practical aspects of the decision must also be considered. These primarily include computational resource requirements and the cost of the model. While the former must match your data complexity, the latter should be within your specified budget.
Moreover, the available level of technical expertise also dictates your model choice. Since some vector embedding models require high technical expertise while others are more user-friendly, your strength of technical knowledge will determine your ease of use.
While these considerations address the various aspects of your organization-level goals and application requirements, you must consider some additional benchmarks and evaluation factors. Considering these benchmarks completes the highly important multifaceted approach of model selection.
Curious about the future of LLMs and the role of vector embeddings in it? Tune in to our Future of Data and AI Podcast now!
Benchmarks for Evaluating Vector Embedding Models
Here’s a breakdown of some key benchmarks you can leverage:
Internal Evaluation
These benchmarks focus on the quality of the embeddings for all tasks. Some common metrics of this evaluation include semantic relationships between words, word similarity in the embedding space, and word clustering. All these metrics collectively determine the quality of connections between embeddings.
It keeps track of the performance of embeddings in a specific task. Following is a list of some of the metrics used for external evaluation:
ROUGE Score: It is called the Recall-Oriented Understudy for Gisting Evaluation. It deals with the performance of text summarization tasks, evaluating the overlap between generated and reference summaries.
BLEU Score: The Bilingual Evaluation Understudy, also called human evaluation measures the coherence and quality of outputs. This metric is particularly useful for tracking the quality of dialog generation.
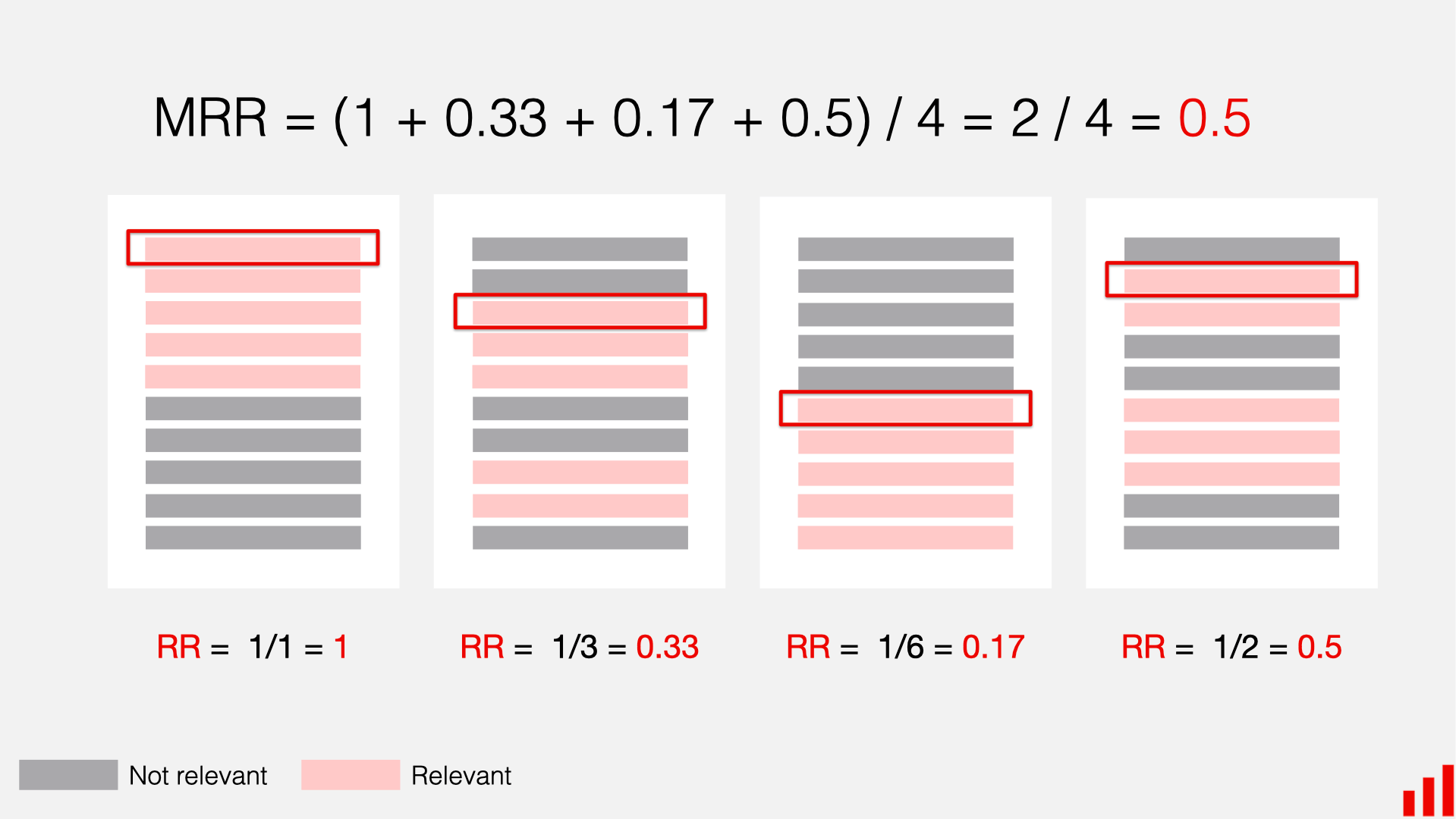
MRR: It stands for Mean Reciprocal Rank. As the name suggests, it ranks the documents in the retrieved results based on their relevance.
You can also read about F1 Score – a metric for LLM evaluation
A visual explanation of MRR – Source: Evidently AI
Benchmark Suites
The benchmark suites work by providing a standardized set of tasks and datasets to assess the models’ performance. It helps in making informed decisions as they highlight the strengths and weaknesses of of each model across a variety of tasks. Some common benchmark suites include:
BEIR (Benchmark for Evaluating Retrieval with BERT)
It focuses on information retrieval tasks by using a reference set that includes diverse information retrieval tasks such as question-answering, fact-checking, and entity retrieval. It provides datasets for retrieving relevant documents or passages based on a query, allowing for a comprehensive evaluation of a model’s capabilities.
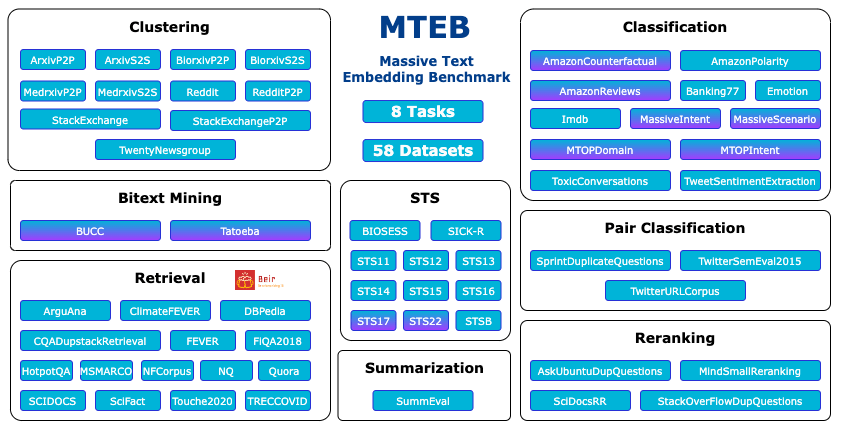
The MTEB leaderboard is available on Hugging Face. It expands on BEIR’s foundation with 58 datasets and covers 112 languages. It enables the evaluation of models against a wide range of linguistic contexts and use cases.
Its metrics and databases are suitable for tasks like text summarization, information retrieval, and semantic textual similarity, allowing you to see model performance on a broad range of tasks.
Hence, the different factors, benchmark suites, evaluation models, and metrics collectively present a multi-faceted approach toward selecting a relevant vector embedding model. However, alongside these quantitative metrics, it is important to incorporate human judgment into the process.
The Final Word
In navigating the performance of your generative AI applications, the journey starts with choosing an appropriate vector embedding model. Since the model forms the basis of your app performance, you must consider all the relevant factors in making a decision.
While you explore the various evaluation metrics and benchmarks, you must also carefully analyze the instances of your application’s poor performance. It will help you understand the embedding model’s weaknesses, enabling you to choose the most appropriate one that ensures high-quality outputs.
In the ever-evolving landscape of natural language processing (NLP), embedding techniques have played a pivotal role in enhancing the capabilities of language models.
The birth of Word Embeddings
Before venturing into the large number of embedding techniques that have emerged in the past few years, we must first understand the problem that led to the creation of such techniques.
Word embeddings were created to address the absence of efficient text representations for NLP models. Since NLP techniques operate on textual data, which inherently cannot be directly integrated into machine learning models designed to process numerical inputs, a fundamental question arose: how can we convert text into a format compatible with these models?
Basic approaches like one-hot encoding and Bag-of-Words (BoW) were employed in the initial phases of NLP development. However, these methods were eventually discarded due to their evident shortcomings in capturing the contextual and semantic nuances of language. Each word was treated as an isolated unit, without understanding its relationship with other words or its usage in different contexts.
Popular word embedding techniques
Word2Vec
In 2013, Google presented a new technique to overcome the shortcomings of the previous word embedding techniques, called Word2Vec. It represents words in a continuous vector space, better known as an embedding space, where semantically similar words are located close to each other.
This contrasted with traditional methods, like one-hot encoding, which represents words as sparse, high-dimensional vectors. The dense vector representations generated by Word2Vec had several advantages, including the ability to capture semantic relationships, support vector arithmetic (e.g., “king” – “man” + “woman” = “queen”), and improve the performance of various NLP tasks like language modeling, sentiment analysis, and machine translation.
Transition to GloVe and FastText
The success of Word2Vec paved the way for further innovations in the realm of word embeddings. The Global Vectors for Word Representation (GloVe) model, introduced by Stanford researchers in 2014, aimed to leverage global statistical information about word co-occurrences.
GloVe demonstrated improved performance over Word2Vec in capturing semantic relationships. Unlike Word2Vec, GloVe considers the entire corpus when learning word vectors, leading to a more global understanding of word relationships.
Fast forward to 2016, Facebook’s FastText introduced a significant shift by considering sub-word information. Unlike traditional word embeddings, FastText represented words as bags of character n-grams. This sub-word information allowed FastText to capture morphological and semantic relationships in a more detailed manner, especially for languages with rich morphology and complex word formations. This approach was particularly beneficial for handling out-of-vocabulary words and improving the representation of rare words.
The Rise of Transformer Models
The real game-changer in the evolution of embedding techniques came with the advent of the Transformer architecture. Introduced by researchers at Google in the form of the Attention is All You Need paper in 2017, Transformers demonstrated remarkable efficiency in capturing long-range dependencies in sequences.
The architecture laid the foundation for state-of-the-art models like OpenAI’s GPT (Generative Pre-trained Transformer) series and BERT (Bidirectional Encoder Representations from Transformers). Hence, the traditional understanding of embedding techniques is revamped with new solutions.
Impact of Embedding Techniques on Language Models
The embedding techniques mentioned above have significantly impacted the performance and capabilities of LLMs. Pre-trained models like GPT-3 and BERT leverage these embeddings to understand natural language context, semantics, and syntactic structures. The ability to capture context allows these models to excel in a wide range of NLP tasks, including sentiment analysis, text summarization, and question-answering.
Imagine the sentence: “The movie was not what I expected, but the plot twist at the end made it incredible.”
Traditional models might struggle with the negation of “not what I expected.” Word embeddings could capture some sentiment but might miss the subtle shift in sentiment caused by the positive turn of events in the latter part of the sentence.
In contrast, LLMs with contextualized embeddings can consider the entire sentence and comprehend the nuanced interplay of positive and negative sentiments. They grasp that the initial negativity is later counteracted by the positive twist, resulting in a more accurate sentiment analysis.
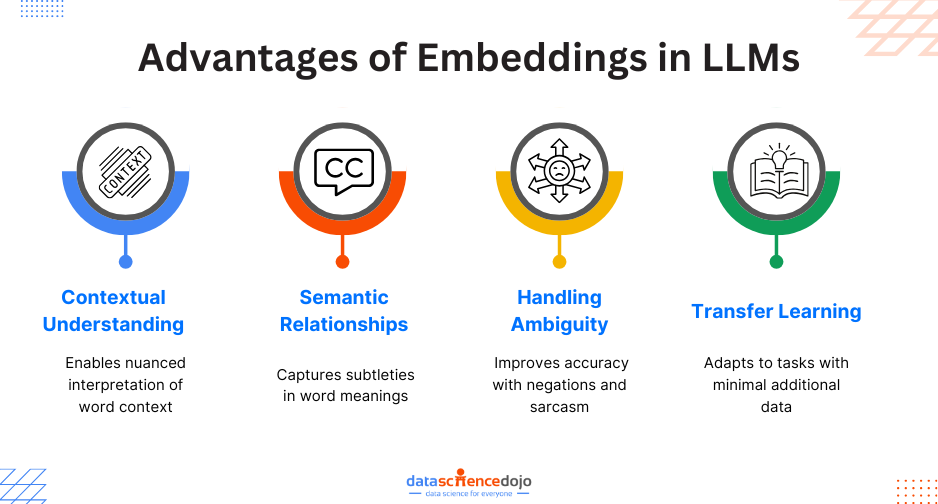
Advantages of Embeddings in LLMs
Contextual Understanding: LLMs equipped with embeddings comprehend the context in which words appear, allowing for a more nuanced interpretation of sentiment in complex sentences.
Semantic Relationships: Word embeddings capture semantic relationships between words, enabling the model to understand the subtleties and nuances of language.
Handling Ambiguity: Contextual embeddings help LLMs handle ambiguous language constructs, such as negations or sarcasm, contributing to improved accuracy in sentiment analysis.
Transfer Learning: The pre-training of LLMs with embeddings on vast datasets allows them to generalize well to various downstream tasks, including sentiment analysis, with minimal task-specific data.
How are Enterprises Using Embeddings in their LLM Processes?
In light of recent advancements, enterprises are keen on harnessing the robust capabilities of Large Language Models (LLMs) to construct comprehensive Software as a Service (SAAS) solutions. Nevertheless, LLMs come pre-trained on extensive datasets, and to tailor them to specific use cases, fine-tuning on proprietary data becomes essential.
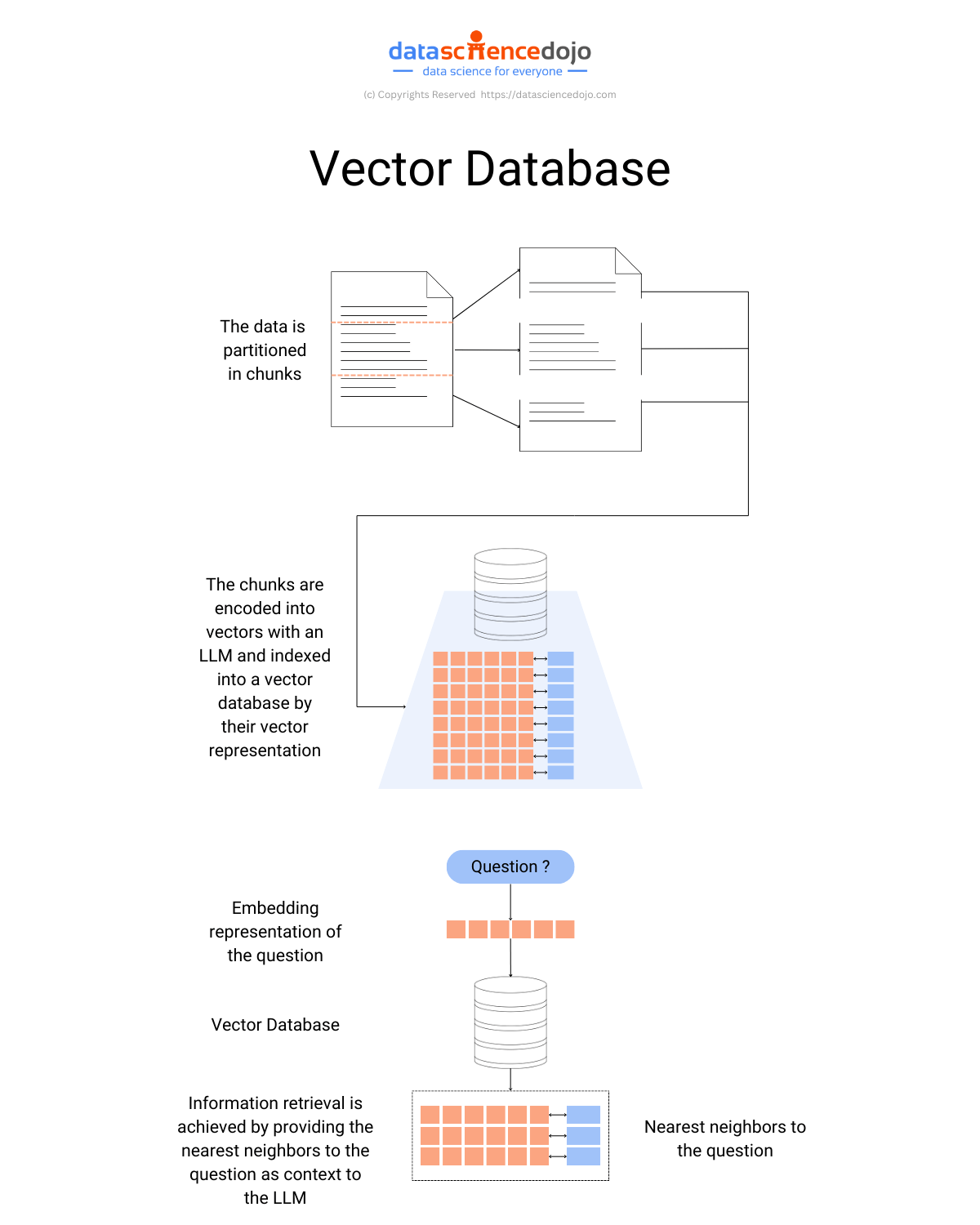
This process can be laborious. To streamline this intricate task, the widely embraced Retrieval Augmented Generation (RAG) technique comes into play. RAG involves retrieving pertinent information from an external source, transforming it to a format suitable for LLM comprehension, and then inputting it into the LLM to generate textual output.
This innovative approach enables the fine-tuning of LLMs with knowledge beyond their original training scope.In this process, you need an efficient way to store, retrieve, and ingest data into your LLMs to use it accurately for your given use case.
One of the most common ways to store and search over unstructured data is to embed it and store the resulting embedding vectors, and then at query time to embed the unstructured query and retrieve the embedding vectors that are ‘most similar’ to the embedded query. Hence, without embedding techniques, your RAG approach will be impossible.
Understanding the Creation of Embeddings
Much like a machine learning model, an embedding model undergoes training on extensive datasets. Various models available can generate embeddings for you, and each model is distinct. You can find the top embedding models here.
It is unclear what makes an embedding model perform better than others. However, a common way to select one for your use case is to evaluate how many words a model can take in without breaking down. There’s a limit to how many tokens a model can handle at once, so you’ll need to split your data into chunks that fit within the limit. Hence, choosing a suitable model is a good starting point for your use case.
Creating embeddings with Azure OpenAI is a matter of a few lines of code. To create embeddings of a simple sentence like The food was delicious and the waiter…, you can execute the following code blocks:
First, import AzureOpenAI from OpenAI
Load in your environment variables
Create your Azure OpenAI client.
Create your embeddings
And you’re done! It’s really that simple to generate embeddings for your data. If you want to generate embeddings for an entire dataset, you can follow along with the great notebook provided by OpenAI itself here.
To Sum It Up!
The evolution of embeddingtechniques has revolutionized natural language processing, empowering language models with a deeper understanding of context and semantics. From Word2Vec to Transformer models, each advancement has enriched LLM capabilities, enabling them to excel in various NLP tasks.
Enterprises leverage techniques like Retrieval Augmented Generation, facilitated by embeddings, to tailor LLMs for specific use cases. Platforms like Azure OpenAI offer straightforward solutions for generating embeddings, underscoring their importance in NLP development. As we forge ahead, embeddings will remain pivotal in driving innovation and expanding the horizons of language understanding.
Vector embeddings refer to numerical representations of data in a continuous vector space. The data points in the three-dimensional space can capture the semantic relationships and contextual information associated with them.
With the advent of generative AI, the complexity of data makes vector embeddings a crucial aspect of modern-day processing and handling of information. They ensure efficient representation of multi-dimensional databases that are easier for AI algorithms to process.
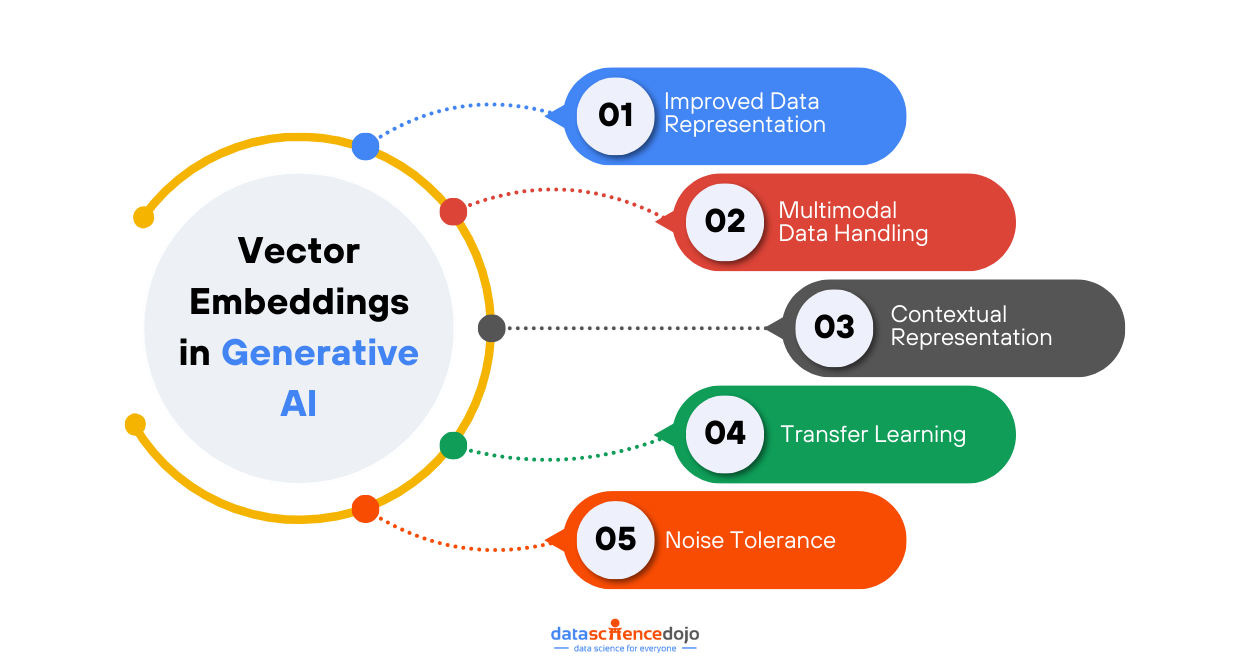
Key Role of Vector Embeddings in Generative AI
Generative AI relies on vector embeddings to understand the structure and semantics of input data. Let’s look at some key roles of embedded vectors in generative AI to ensure their functionality.
Improved Data Representation
Improved data representation through vector embeddings involves transforming complex data into a more meaningful and compact three-dimensional form. These embeddings effectively capture the semantic relationships within the data, allowing similar data items to be represented by similar vectors.
This coherent representation enhances the ability of AI models to process and generate outputs that are contextually relevant and semantically aligned. Additionally, vector embeddings are instrumental in capturing latent representations, which are underlying patterns and features within the input data that may not be immediately apparent.
By utilizing these embeddings, AI systems can achieve more nuanced and sophisticated interpretations of diverse data types, ultimately leading to improved performance and more insightful analysis in various applications.
Multimodal Data Handling
Multimodal data handling refers to the capability of processing and integrating multiple types of data, such as text, images, audio, and time-series data, to create more comprehensive AI models. Vector space allows for multimodal creativity since generative AI is not restricted to a single form of data.
By utilizing vector embeddings that represent different data types, generative AI can effectively generate creative outputs across various forms using these embedded vectors.
This approach enhances the versatility and applicability of AI models, enabling them to understand and produce complex interactions between diverse data modalities, thereby leading to richer and more innovative AI-driven solutions.
Additionally, multimodal data handling allows AI systems to leverage the strengths of each data type, resulting in more accurate and contextually relevant outputs
Contextual Representation
Generative AI uses vector embeddings to control the style and content of outputs. The vector representations in latent spaces are manipulated to produce specific outputs that are representative of the contextual information in the input data.
It ensures the production of more relevant and coherent data output for AI algorithms.
Vector embeddings enable contextual representation of data
Transfer Learning
Transfer Learning is a crucial concept in AI that involves utilizing knowledge gained from one task to enhance the performance of another related task. In the context of vector embeddings, transfer learning allows these embeddings to be initially trained on large datasets, capturing general patterns and features.
These pre-trained embeddings are then transferred and fine-tuned for specific generative tasks, enabling AI algorithms to leverage existing knowledge effectively. This approach not only significantly reduces the amount of required training data for the new task but also accelerates the training process and improves the overall performance of AI models by building upon previously learned information.
Explore 50+ Large Language Models and Generative AI Jokes to fight the Monday blues
By doing so, it enhances the adaptability and efficiency of AI systems across various applications.
Noise Tolerance and Generalizability
Noise tolerance and generalizability in the context of vector embeddings refer to the ability of AI models to handle data imperfections effectively. Data is frequently characterized by noise and missing information, which can pose significant challenges for accurate analysis and prediction.
However, in three-dimensional vector spaces, the continuous representation of data allows for the generation of meaningful outputs despite incomplete information. Vector embeddings, by encoding data into these spaces, are designed to accommodate and manage the noise present in data.
This capability is crucial for building robust models that are resilient to variations and uncertainties inherent in real-world data. It enables generalizability when dealing with uncertain data to generate diverse and meaningful outputs.
Use Cases of Vector Embeddings in Generative AI
There are different applications of vector embeddings in generative AI. While their use encompasses several domains, the following are some important use cases of embedded vectors:
Image generation
It involves Generative Adversarial Networks (GANs) that use embedded vectors to generate realistic images. They can manipulate the style, color, and content of images. Vector embeddings also ensure easy transfer of artistic style from one image to another.
The following are some common image embeddings:
CNNs They are known as Convolutional Neural Networks (CNNs) that extract image embeddings for different tasks like object detection and image classification. The dense vector embeddings are passed through CNN layers to create a hierarchical visual feature from images.
Autoencoders These are trained neural network models that are used to generate vector embeddings. It uses these embeddings to encode and decode images.
Data Augmentation
Vector embeddings integrate different types of data that can generate more robust and contextually relevant AI models. A common use of augmentation is the combination of image and text embeddings. These are primarily used in chatbots and content creation tools as they engage with multimedia content that requires enhanced creativity.
Additionally, this approach enables models to better understand and generate complex interactions between visual and textual information, leading to more sophisticated AI applications.
Music Composition
Musical notes and patterns are represented by vector embeddings that the models can use to create new melodies. The audio embeddings allow the numerical representation of the acoustic features of any instrument for differentiation in the music composition process.
Some commonly used audio embeddings include:
MFCCs It stands for Mel Frequency Cepstral Coefficients. It creates vector embeddings using the calculation of spectral features of an audio. It uses these embeddings to represent the sound content.
CRNNs These are Convolutional Recurrent Neural Networks. As the name suggests, they deal with the convolutional and recurrent layers of neural networks. CRNNs allow the integration of the two layers to focus on spectral features and contextual sequencing of the audio representations produced.
NLP uses vector embeddings in language models to generate coherent and contextual text. The embeddings are also capable of. Detecting the underlying sentiment of words and phrases and ensuring the final output is representative of it.
They can capture the semantic meaning of words and their relationship within a language. The following image shows how NLP integrates word embeddings with sentiment to produce more coherent results.
Word2Vec It represents words as a dense vector representation that trains a neural network to capture the semantic relationship of words. Using the distributional hypothesis enables the network to predict words in a context.
GloVe It stands for Global Vectors for Word Representation. It integrates global and local contextual information to improve NLP tasks. It particularly assists in sentiment analysis and machine translation.
BERT It means Bidirectional Encoder Representations from Transformers. They are used to pre-train transformer models to predict words in sentences. It is used to create context-rich embeddings.
Video Game Development
Another important use of vector embeddings is in video game development. Generative AI uses embeddings to create game environments, characters, and other assets. These embedded vectors also help ensure that the various elements are linked to the game’s theme and context.
Challenges and Considerations in Vector Embeddings for Generative AI
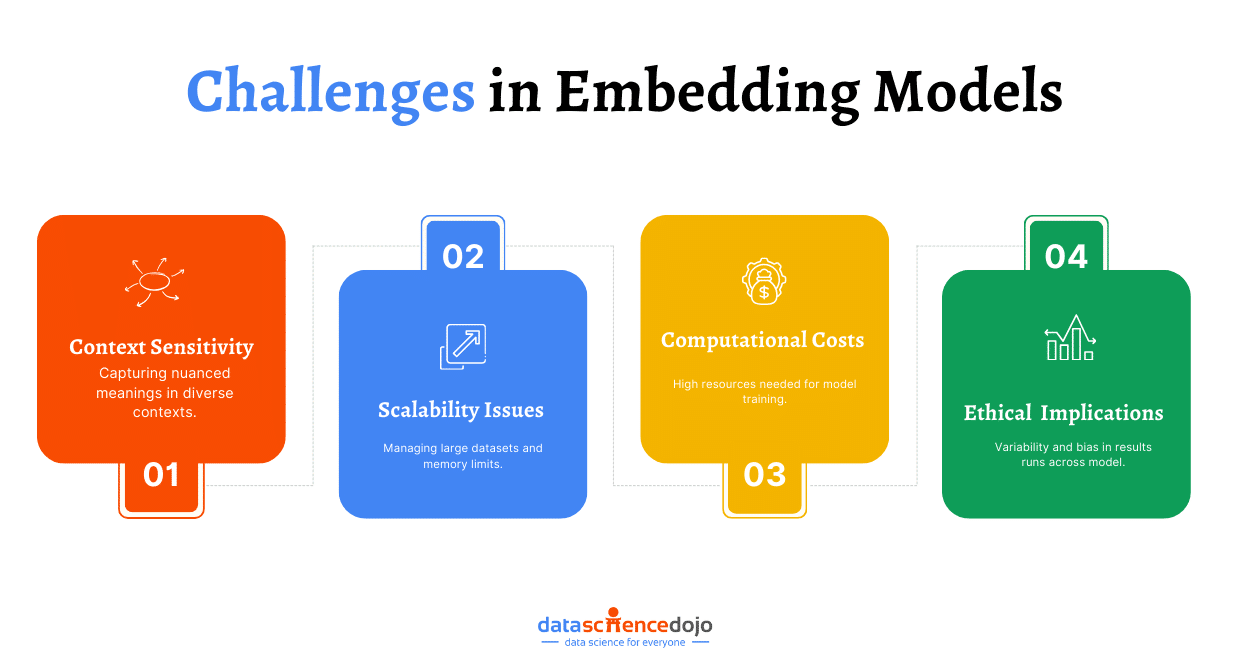
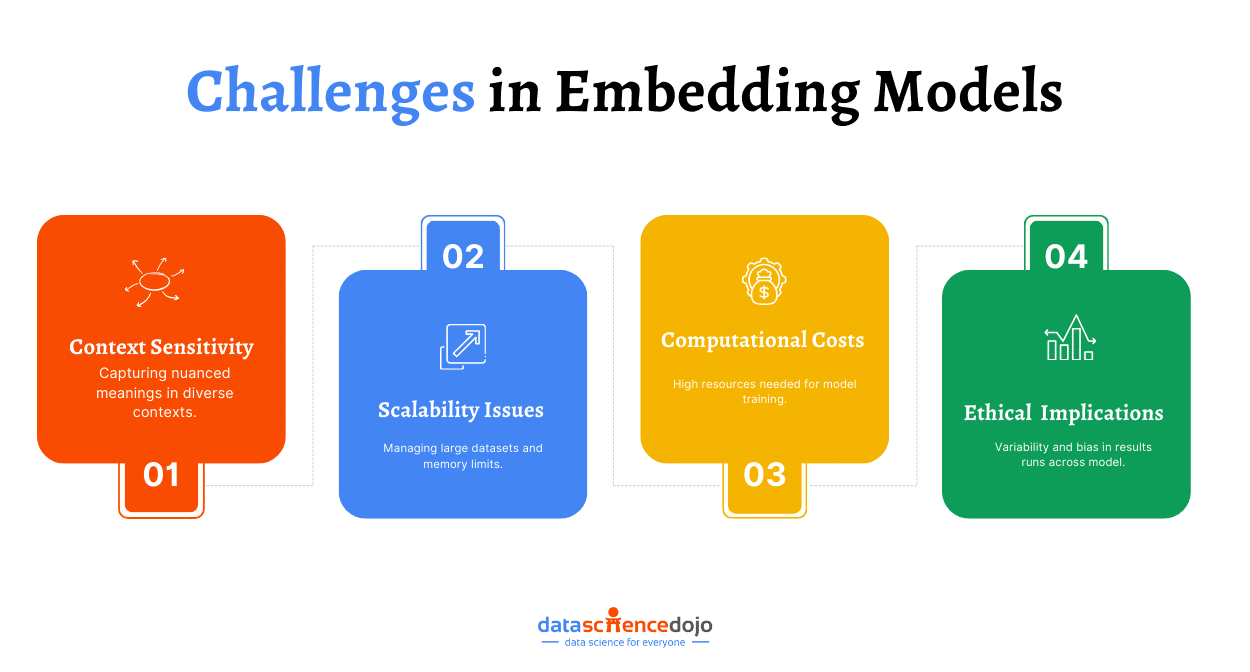
Vector embeddings are crucial in improving the capabilities of generative AI. However, it is important to understand the challenges associated with their use and relevant considerations to minimize the difficulties. Here are some of the major challenges and considerations:
Data Quality and Quantity: The quality and quantity of data used to learn the vector embeddings and train models determine the performance of generative AI. Missing or incomplete data can negatively impact the trained models and final outputs.
It is crucial to carefully preprocess the data for any outliers or missing information to ensure the embedded vectors are learned efficiently. Moreover, the dataset must represent various scenarios to provide comprehensive results.
Ethical Concerns and Data Biases: Since vector embeddings encode the available information, any biases in training data are included and represented in the generative models, producing unfair results that can lead to ethical issues.
It is essential to be careful in data collection and model training processes. The use of fairness-aware embeddings can remove data bias. Regular audits of model outputs can also ensure fair results
Computation-Intensive Processing: Model training with vector embeddings can be a computation-intensive process. The computational demand is particularly high for large or high-dimensional embeddings.
Hence, it is important to consider the available resources and use distributed training techniques for fast processing.
In the coming future, the link between vector embeddings and generative AI is expected to strengthen. The reliance on three-dimensional data representations can cater to the growing complexity of generative AI.
As AI technology progresses, efficient data representations through vector embeddings will also become necessary for smooth operation. Moreover, vector embeddings offer improved interpretability of information by integrating human-readable data with computational algorithms.
The features of these embeddings offer enhanced visualization that ensures a better understanding of complex information and relationships in data, enhancing representation, processing, and analysis.
Hence, the future of generative AI puts vector embeddings at the center of its progress and development.
Large language models (LLMs) are AI models that can generate text, translate languages, write different kinds of creative content, and answer your questions in an informative way. They are trained on massive amounts of text data, and they can learn to understand the nuances of human language.
In this blog, we will take a deep dive into LLMs, including their building blocks, such as embeddings, transformers, and attention. We will also discuss the different applications of LLMs, such as machine translation, question answering, and creative writing.
To test your knowledge of LLM terms, we have included a crossword or quiz at the end of the blog. So, what are you waiting for? Let’s crack the code of large language models!
LLMs are typically built using a transformer architecture. Transformers are a type of neural network that are well-suited for natural language processing tasks. They are able to learn long-range dependencies between words, which is essential for understanding the nuances of human language.
They are typically trained on clusters of computers or even on cloud computing platforms. The training process can take weeks or even months, depending on the size of the dataset and the complexity of the model.
20 Essential LLM Terms for Crafting Applications
1. Large language model (LLM)
Large language models (LLMs) are AI models that can generate text, translate languages, write different kinds of creative content, and answer your questions in an informative way. The building blocks of an LLM are embeddings, transformers, attention, and loss functions.
Embeddings are vectors that represent the meaning of words or phrases. Transformers are a type of neural network that is well-suited for NLP tasks. Attention is a mechanism that allows the LLM to focus on specific parts of the input text. The loss function is used to measure the error between the LLM’s output and the desired output. The LLM is trained to minimize the loss function.
2. OpenAI
OpenAI is a non-profit research company that develops and deploys artificial general intelligence (AGI) in a safe and beneficial way. AGI is a type of artificial intelligence that can understand and reason like a human being. OpenAI has developed a number of LLMs, including GPT-3, Jurassic-1 Jumbo, and DALL-E 2.
GPT-3 is a large language model that can generate text, translate languages, write different kinds of creative content, and answer your questions in an informative way. Jurassic-1 Jumbo is a larger language model that is still under development. It is designed to be more powerful and versatile than GPT-3. DALL-E 2 is a generative AI model that can create realistic images from text descriptions.
3. Generative AI
Generative AI is a type of AI that can create new content, such as text, images, or music. LLMs are a type of generative AI. They are trained on large datasets of text and code, which allows them to learn the patterns of human language. This allows them to generate text that is both coherent and grammatically correct.
Generative AI has a wide range of potential applications. It can be used to create new forms of art and entertainment, to develop new educational tools, and to improve the efficiency of businesses. It is still a relatively new field, but it is rapidly evolving.
4. ChatGPT
ChatGPT is a large language model (LLM) developed by OpenAI. It is designed to be used in chatbots. ChatGPT is trained on a massive dataset of text and code, which allows it to learn the patterns of human conversation. This allows it to hold conversations that are both natural and engaging. ChatGPT is also capable of answering questions, providing summaries of factual topics, and generating different creative text formats.
5. Bard
Bard is a large language model (LLM) developed by Google AI. It is still under development, but it has been shown to be capable of generating text, translating languages, and writing different kinds of creative content. Bard is trained on a massive dataset of text and code, which allows it to learn the patterns of human language. This allows it to generate text that is both coherent and grammatically correct. Bard is also capable of answering your questions in an informative way, even if they are open-ended, challenging, or strange.
6. Foundation models
Foundation models are a family of large language models (LLMs) developed by Google AI. They are designed to be used as a starting point for developing other AI models. Foundation models are trained on massive datasets of text and code, which allows them to learn the patterns of human language. This allows them to be used to develop a wide range of AI applications, such as chatbots, machine translation, and question-answering systems.
7. LangChain
LangChain is a text-to-image diffusion model that can be used to generate images from text descriptions. It is based on the Transformer model and is trained on a massive dataset of text and images. LangChain is still under development, but it has the potential to be a powerful tool for creative expression and problem-solving.
8. Llama Index
Llama Index is a data framework for large language models (LLMs). It provides tools to ingest, structure, and access private or domain-specific data. LlamaIndex can be used to connect LLMs to a variety of data sources, including APIs, PDFs, documents, and SQL databases. It also provides tools to index and query data, so that LLMs can easily access the information they need.
Llama Index is a relatively new project, but it has already been used to build a number of interesting applications. For example, it has been used to create a chatbot that can answer questions about the stock market, and a system that can generate creative text formats, like poems, code, scripts, musical pieces, email, and letters.
9. Redis
Redis is an in-memory data store that can be used to store and retrieve data quickly. It is often used as a cache for web applications, but it can also be used for other purposes, such as storing embeddings. Redis is a popular choice for NLP applications because it is fast and scalable.
10. Streamlit
Streamlit is a framework for creating interactive web apps. It is easy to use and does not require any knowledge of web development. Streamlit is a popular choice for NLP applications because it allows you to quickly and easily build web apps that can be used to visualize and explore data.
11. Cohere
Cohere is a large language model (LLM) developed by Google AI. It is known for its ability to generate human-quality text. Cohere is trained on a massive dataset of text and code, which allows it to learn the patterns of human language. This allows it to generate text that is both coherent and grammatically correct. Cohere is also capable of translating languages, writing different kinds of creative content, and answering your questions in an informative way.
12. Hugging Face
Hugging Face is a company that develops tools and resources for NLP. It offers a number of popular open-source libraries, including Transformer models and datasets. Hugging Face also hosts a number of online communities where NLP practitioners can collaborate and share ideas.
LLM Crossword
13. Midjourney
Midjourney is a LLM developed by Midjourney. It is a text-to-image AI platform that uses a large language model (LLM) to generate images from natural language descriptions. The user provides a prompt to Midjourney, and the platform generates an image that matches the prompt. Midjourney is still under development, but it has the potential to be a powerful tool for creative expression and problem-solving.
14. Prompt Engineering
Prompt engineering is the process of crafting prompts that are used to generate text with LLMs. The prompt is a piece of text that provides the LLM with information about what kind of text to generate.
Prompt engineering is important because it can help to improve the performance of LLMs. By providing the LLM with a well-crafted prompt, you can help the model to generate more accurate and creative text. Prompt engineering can also be used to control the output of the LLM. For example, you can use prompt engineering to generate text that is similar to a particular style of writing, or to generate text that is relevant to a particular topic.
When crafting prompts for LLMs, it is important to be specific, use keywords, provide examples, and be patient. Being specific helps the LLM to generate the desired output, but being too specific can limit creativity.
Using keywords helps the LLM focus on the right topic, and providing examples helps the LLM learn what you are looking for. It may take some trial and error to find the right prompt, so don’t give up if you don’t get the desired output the first time.
Embeddings are a type of vector representation of words or phrases. They are used to represent the meaning of words in a way that can be understood by computers. LLMs use embeddings to learn the relationships between words.
Embeddings are important because they can help LLMs to better understand the meaning of words and phrases, which can lead to more accurate and creative text generation. Embeddings can also be used to improve the performance of other NLP tasks, such as natural language understanding and machine translation.
Fine-tuning is the process of adjusting the parameters of a large language model (LLM) to improve its performance on a specific task. Fine-tuning is typically done by feeding the LLM a dataset of text that is relevant to the task.
For example, if you want to fine-tune an LLM to generate text about cats, you would feed the LLM a dataset of text that contains information about cats. The LLM will then learn to generate text that is more relevant to the task of generating text about cats.
Fine-tuning can be a very effective way to improve the performance of an LLM on a specific task. However, it can also be a time-consuming and computationally expensive process.
17. Vector databases
Vector databases are a type of database that is optimized for storing and querying vector data. Vector data is data that is represented as a vector of numbers. For example, an embedding is a vector that represents the meaning of a word or phrase.
Vector databases are often used to store embeddings because they can efficiently store and retrieve large amounts of vector data. This makes them well-suited for tasks such as natural language processing (NLP), where embeddings are often used to represent words and phrases.
Vector databases can be used to improve the performance of fine-tuning by providing a way to store and retrieve large datasets of text that are relevant to the task. This can help to speed up the fine-tuning process and improve the accuracy of the results.
18. Natural Language Processing (NLP)
Natural Language Processing (NLP) is a field of computer science that deals with the interaction between computers and human (natural) languages. NLP tasks include text analysis, machine translation, and question answering. LLMs are a powerful tool for NLP. NLP is a complex field that covers a wide range of tasks. Some of the most common NLP tasks include:
Text analysis: This involves extracting information from text, such as the sentiment of a piece of text or the entities that are mentioned in the text.
For example, an NLP model could be used to determine whether a piece of text is positive or negative, or to identify the people, places, and things that are mentioned in the text.
Machine translation: This involves translating text from one language to another.
For example, an NLP model could be used to translate a news article from English to Spanish.
Question answering: This involves answering questions about text.
For example, an NLP model could be used to answer questions about the plot of a movie or the meaning of a word.
Speech recognition: This involves converting speech into text.
For example, an NLP model could be used to transcribe a voicemail message.
Text generation: This involves generating text, such as news articles or poems.
For example, an NLP model could be used to generate a creative poem or a news article about a current event.
19. Tokenization
Tokenization is the process of breaking down a piece of text into smaller units, such as words or subwords. Tokenization is a necessary step before LLMs can be used to process text. When text is tokenized, each word or subword is assigned a unique identifier. This allows the LLM to track the relationships between words and phrases.
There are many different ways to tokenize text. The most common way is to use word boundaries. This means that each word is a token. However, some LLMs can also handle subwords, which are smaller units of text that can be combined to form words.
For example, the word “cat” could be tokenized as two subwords: “c” and “at”. This would allow the LLM to better understand the relationships between words, such as the fact that “cat” is related to “dog” and “mouse”.
20. Transformer models
Transformer models are a type of neural network that is well-suited for NLP tasks. They are able to learn long-range dependencies between words, which is essential for understanding the nuances of human language. Transformer models work by first creating a representation of each word in the text. This representation is then used to calculate the relationship between each word and the other words in the text.
The Transformer model is a powerful tool for NLP because it can learn the complex relationships between words and phrases. This allows it to perform NLP tasks with a high degree of accuracy. For example, a Transformer model could be used to translate a sentence from English to Spanish while preserving the meaning of the sentence.
Embeddings transform raw data into meaningful vectors, revolutionizing how AI systems understand and process language,” notes industry expert Frank Liu. These are the cornerstone of large language models (LLM) which are trained on vast datasets, including books, articles, websites, and social media posts.
By learning the intricate statistical relationships between words, phrases, and sentences, LLMs generate text that mirrors the patterns found in their training data.
This comprehensive guide delves into the world of embeddings, explaining their various types, applications, and future advancements. Whether you’re a beginner or an expert, this exploration will provide a deep understanding of how embeddings enhance AI capabilities, making LLMs more efficient and effective in processing natural language data.
Join us as we uncover their essential role in the evolution of AI.
What are Embeddings?
Embeddings are numerical representations of words or phrases in a high-dimensional vector space. These representations map discrete objects (such as words, sentences, or images) into a continuous latent space, capturing their relationship. They are a fundamental component in the field of Natural Language Processing (NLP) and machine learning.
By converting words into vectors, they enable machines to understand and process human language in a more meaningful way. Think of embeddings as a way to organize a library. Instead of arranging books alphabetically, you place similar books close to each other based on their content.
Similarly, embeddings position words into a vector in a high-dimensional latent space so that words with similar meanings are closer together. This helps ML models understand and process text more effectively. For example, the vector for “apple” would be closer to “fruit” than to “car”.
They translate textual data into vectors within a continuous latent space, enabling the measurement of similarities through metrics like cosine similarity and Euclidean distance.
This transformation is crucial because it enables models to perform mathematical operations on text data, thereby facilitating tasks such as clustering, classification, and regression.
It helps to interpret and generate human language with greater accuracy and context-awareness. Techniques such as Azure OpenAI facilitate their creation, empowering language models with enhanced capabilities.
Embeddings are used to represent words as vectors of numbers, which can then be used by machine learning models to understand the meaning of text. These have evolved over time from the simplest one-hot encoding approach to more recent semantic approaches.
When converting data into meaningful numerical representations, different types of embeddings help machines process and interpret information more effectively. Let’s explore the key types of embeddings and how they power various AI applications.
Word Embeddings
Word embeddings represent individual words as vectors of numbers in a high-dimensional space. These vectors capture semantic meanings and relationships between words, making them fundamental in NLP tasks.
By positioning words in such a space, it places similar words closer together, reflecting their semantic relationships. This allows machine learning models to understand and process text more effectively.
Word embeddings help classify texts into categories like spam detection or sentiment analysis by understanding the context of the words used. They enable the generation of concise summaries by capturing the essence of the text.
It allows models to provide accurate answers based on the context of the query and facilitates the translation of text from one language to another by understanding the semantic meaning of words and phrases.
Sentence embeddings represent entire sentences as vectors, capturing the context and meaning of the sentence as a whole. Unlike word embeddings, which only capture individual word meanings, sentence embeddings consider the relationships between words within a sentence, providing a more comprehensive understanding of the text.
These are used to categorize larger text units like sentences or entire documents, making the classification process more accurate. They help generate summaries by understanding the overall context and key points of the document.
Models are also enabled to answer questions based on the context of entire sentences or documents. They improve translation quality by preserving the context and meaning of sentences during translation.
Graph Embeddings
Graph embeddings represent nodes in a graph as vectors, capturing the relationships and structures within the graph. These are particularly useful for tasks that involve network analysis and relational data.
For instance, in a social network graph, it can represent users and their connections, enabling tasks like community detection, link prediction, and recommendation systems.
By transforming the complex relationships in graphs into numerical vectors, ML models can process and analyze graph data efficiently. One of the key advantages is their ability to preserve the structural information of the graph, which is critical for accurately capturing the relationships between nodes.
This capability makes them suitable for a wide range of applications beyond social networks, such as biological network analysis, fraud detection, and knowledge graph completion.
Tools like DeepWalk and Node2Vec have been developed to generate graph embeddings by learning from the graph’s structure, further enhancing the ability to analyze and interpret complex graph data.
Image and Audio Embeddings
Images are represented as vectors by extracting features from them, while audio signals are converted into numerical representations by embeddings. These are crucial for tasks involving visual and auditory data.
Embeddings for images are used in tasks like image classification, object detection, and image retrieval, while those for audio are applied in speech recognition, music genre classification, and audio search.
These are powerful tools in NLP and machine learning, enabling machines to understand and process various forms of data. By transforming text, images, and audio into numerical representations, they enhance the performance of numerous tasks, making them indispensable in the field of artificial intelligence.
Choosing the right embedding type depends on the nature of your data and the task at hand. You can use:
Word embeddings to capture individual word meanings
Sentence and document embeddings for a broader context
Graph embeddings to analyze networks and connections
Image and audio embeddings for tasks like classification and retrieval
Understanding the strengths of each embedding type ensures you select the best approach for optimizing your AI models and improving performance across different applications.
Classic Approaches to Embeddings
In the early days of natural language processing (NLP), embeddings were simply one-hot encoded. Zero vector represents each word with a single one at the index that matches its position in the vocabulary.
1. One-hot Encoding
One-hot encoding is the simplest approach to embedding words. It represents each word as a vector of zeros, with a single one at the index corresponding to the word’s position in the vocabulary. For example, if we have a vocabulary of 10,000 words, then the word “cat” would be represented as a vector of 10,000 zeros, with a single one at index 0.
One-hot encoding is a simple and efficient way to represent words as vectors of numbers. However, it does not take into account the context in which words are used. This can be a limitation for tasks such as text classification and sentiment analysis, where the context of a word can be important for determining its meaning.
For example, the word “cat” can have multiple meanings, such as “a small furry mammal” or “to hit someone with a closed fist.” In one-hot encoding, these two meanings would be represented by the same vector. This can make it difficult for machine learning models to learn the correct meaning of words.
2. TF-IDF
TF-IDF (term frequency-inverse document frequency) is a statistical measure that is used to quantify the importance of process and creates a pre-trained model that can be fine-tuned using a smaller dataset for specific tasks.
This reduces the need for labeled data and training time while achieving good results in natural language processing tasks of a word in a document. It is a widely used technique in NLP for tasks such as text classification, information retrieval, and machine translation.
TF-IDF is calculated by multiplying the term frequency (TF) of a word in a document by its inverse document frequency (IDF). TF measures the number of times a word appears in a document, while IDF measures how rare a word is in a corpus of documents.
The TF-IDF score for a word is high when the word appears frequently in a document and when the word is rare in the corpus. This means that TF-IDF scores can be used to identify words that are important in a document, even if they do not appear very often.
Understanding TF-IDF with an Example
Here is an example of how TF-IDF can be used to create word embeddings. Let’s say we have a corpus of documents about cats. We can calculate the TF-IDF scores for all of the words in the corpus. The words with the highest TF-IDF scores will be the words that are most important in the corpus, such as “cat,” “dog,” “fur,” and “meow.”
We can then create a vector for each word, where each element of the vector represents the TF-IDF score for that word. The TF-IDF vector for the word “cat” would be high, while the TF-IDF vector for the word “dog” would also be high, but not as high as the TF-IDF vector for the word “cat.”
The TF-IDF can then be used by a machine-learning model to classify documents about cats. The model would first create a vector representation of a new document. Then, it would compare the vector representation of the new document to the TF-IDF word embeddings. The document would be classified as a “cat” document if its vector representation is most similar to the TF-IDF word embeddings for “cat.”
Count-based and TF-IDF
To address the limitations of one-hot encoding, count-based and TF-IDF techniques were developed. These techniques take into account the frequency of words in a document or corpus.
Count-based techniques simply count the number of times each word appears in a document. TF-IDF techniques take into account both the frequency of a word and its inverse document frequency.
Count-based and TF-IDF techniques are more effective than one-hot encoding at capturing the context in which words are used. However, they still do not capture the semantic meaning of words.
Capturing Local Context with N-grams
To capture the semantic meaning of words, n-grams can be used. N-grams are sequences of n-words. For example, a 2-gram is a sequence of two words.
N-grams can be used to create a vector representation of a word. The vector representation is based on the frequencies of the n-grams that contain the word.
N-grams are a more effective way to capture the semantic meaning of words than count-based or TF-IDF techniques. However, they still have some limitations. For example, they are not able to capture long-distance dependencies between words.
Semantic Encoding Techniques
Semantic encoding techniques are the most recent approach to embedding words. These techniques use neural networks to learn vector representations of words that capture their semantic meaning.
One of the most popular semantic encoding techniques is Word2Vec. Word2Vec uses a neural network to predict the surrounding words in a sentence. The network learns to associate words that are semantically similar with similar vector representations.
Semantic encoding techniques are the most effective way to capture the semantic meaning of words. They are able to capture long-distance dependencies between words, and they are able to learn the meaning of words even if they have never been seen before. Here are some major semantic encoding techniques;
1. ELMo: Embeddings from Language Models
ELMo is a type of word embedding that incorporates both word-level characteristics and contextual semantics. It is created by taking the outputs of all layers of a deep bidirectional language model (bi-LSTM) and combining them in a weighted fashion. This allows ELMo to capture the meaning of a word in its context, as well as its own inherent properties.
The intuition behind ELMo is that the higher layers of the bi-LSTM capture context, while the lower layers capture syntax. This is supported by empirical results, which show that ELMo outperforms other word embeddings on tasks such as POS tagging and word sense disambiguation.
ELMo is trained to predict the next word in a sequence of words, a task called language modeling. This means that it has a good understanding of the relationships between words. When assigning an embedding to a word, ELMo takes into account the words that surround it in the sentence. This allows it to generate different vectors for the same word depending on its context.
Understanding ELMo with Example
For example, the word “play” can have multiple meanings, such as “to perform” or “a game.” In standard word embeddings, each instance of the word “play” would have the same representation.
However, ELMo can distinguish between these different meanings by taking into account the context in which the word appears. In the sentence “The Broadway play premiered yesterday,” for example, ELMo would assign the word “play” a vector that reflects its meaning as a theater production.
ELMo has been shown to be effective for a variety of natural language processing tasks, including sentiment analysis, question answering, and machine translation. It is a powerful tool that can be used to improve the performance of NLP models.
2. GloVe
GloVe is a statistical method for learning word embeddings from a corpus of text. GloVe is similar to Word2Vec, but it uses a different approach to learning the vector representations of words.
How does GloVe work?
GloVe works by creating a co-occurrence matrix. The co-occurrence matrix is a table that shows how often two words appear together in a corpus of text. For example, the co-occurrence matrix for the words “cat” and “dog” would show how often the words “cat” and “dog” appear together in a corpus of text.
GloVe then uses a machine learning algorithm to learn the vector representations of words from the co-occurrence matrix. The machine learning algorithm learns to associate words that appear together frequently with similar vector representations.
Word2Vec is a semantic encoding technique that is used to learn vector representations of words. Word vectors represent word meaning and can enhance machine learning models for tasks like text classification, sentiment analysis, and machine translation.
Word2Vec works by training a neural network on a corpus of text. The neural network is trained to predict the surrounding words in a sentence. The network learns to associate words that are semantically similar with similar vector representations.
There are two main variants of Word2Vec:
Continuous Bag-of-Words (CBOW): The CBOW model predicts the surrounding words in a sentence based on the current word. For example, the model might be trained to predict the words “the” and “dog” given the word “cat”.
Skip-gram: The skip-gram model predicts the current word based on the surrounding words in a sentence. For example, the model might be trained to predict the word “cat” given the words “the” and “dog”.
Key Application of Word2Vec
Word2Vec has been shown to be effective for a variety of tasks, including;
Text Classification: Word2Vec can be used to train a classifier to classify text into different categories, such as news articles, product reviews, and social media posts.
Sentiment Analysis: Word2Vec can be used to train a classifier to determine the sentiment of text, such as whether it is positive, negative, or neutral.
Machine Translation: Word2Vec can be used to train a machine translation model to translate text from one language to another.
Word2Vec vs Dense Word Embeddings
Word2Vec is a neural network model that learns to represent words as vectors of numbers. Word2Vec is trained on a large corpus of text, and it learns to predict the surrounding words in a sentence.
Word2Vec can be used to create dense word embeddings that are vectors that have a fixed size, regardless of the size of the vocabulary. This makes them easy to use with machine learning models.
These have been shown to be effective in a variety of NLP tasks, such as text classification, sentiment analysis, and machine translation.
Understanding Variations in Text Embeddings
An established process can lead to a text embedding to suggest similar words. This means that every time you input the same text into the model, the same results are produced.
Most traditional embedding models like Word2Vec, GloVe, or fastText operate in this manner leading a text embedding to suggest similar words for similar inputs. However, the results can vary in the following cases:
Random Initialization: Some models might include layers or components with randomly initialized weights that aren’t set to a fixed value or re-used across sessions. This can result in different outputs each time.
Contextual Embeddings: Models like BERT or GPT generate these where the embedding for the same word or phrase can differ based on its surrounding context. If you input the phrase in different contexts, the embeddings will vary.
Non-deterministic Settings: Some neural network configurations or training settings can introduce non-determinism. For example, if dropout (randomly dropping units during training to prevent overfitting) is applied during the embedding generation, it could lead to variations.
Model Updates: If the model itself is updated or retrained, even with the same architecture and training data, slight differences in training dynamics (like changes in batch ordering or hardware differences) can lead to different model parameters and thus different embeddings.
Floating-Point Precision: Differences in floating-point precision, which can vary based on the hardware (like CPU vs. GPU), can also lead to slight variations in the computed vector representations.
So, while many models are deterministic, several factors can lead to differences in the embeddings of the same text under different conditions or configurations.
Real-Life Examples in Action
Vector embeddings have become an integral part of numerous real-world applications, enhancing the accuracy and efficiency of various tasks. Here are some compelling examples showcasing their power:
E-commerce Personalized Recommendations
Platforms use these vector representations to offer personalized product suggestions. By representing products and users as vectors in a high-dimensional space, e-commerce platforms can analyze user behavior, preferences, and purchase history to recommend products that align with individual tastes.
This method enhances the shopping experience by providing relevant suggestions, driving sales, and customer satisfaction. For instance, embeddings help platforms like Amazon and Zalando understand user preferences and deliver tailored product recommendations.
Chatbots and Virtual Assistants
Embeddings enable better understanding and processing of user queries. Modern chatbots and virtual assistants, such as those powered by GPT-3 or other large language models, utilize these to comprehend the context and semantics of user inputs.
This allows them to generate accurate and contextually relevant responses, improving user interaction and satisfaction. For example, chatbots in customer support can efficiently resolve queries by understanding the user’s intent and providing precise answers.
Companies analyze social media posts to gauge public sentiment. By converting text data into vector representations, businesses can perform sentiment analysis to understand public opinion about their products, services, or brand.
This analysis helps in tracking customer satisfaction, identifying trends, and making informed marketing decisions. Tools powered by embeddings can scan vast amounts of social media data to detect positive, negative, or neutral sentiments, providing valuable insights for brands.
Healthcare Applications
Embeddings assist in patient data analysis and diagnosis predictions. In the healthcare sector, these are used to analyze patient records, medical images, and other health data to aid in diagnosing diseases and predicting patient outcomes.
For instance, specialized tools like Google’s Derm Foundation focus on dermatology, enabling accurate analysis of skin conditions by identifying critical features in medical images. These help doctors make informed decisions, improving patient care and treatment outcomes.
These examples illustrate the transformative impact of embeddings across various industries, showcasing their ability to enhance personalization, understanding, and analysis in diverse applications. By leveraging this tool, businesses can unlock deeper insights and deliver more effective solutions to their customers.
LLMs are typically built using a transformer architecture. Transformers are a type of neural network that is well-suited for NLP tasks. They are able to learn long-range dependencies between words, which is essential for understanding the nuances of human language.
LLMs are so large that they cannot be run on a single computer. They are typically trained on clusters of computers or even on cloud computing platforms. The training process can take weeks or even months, depending on the size of the dataset and the complexity of the model.
One of the key technologies that makes LLMs so powerful is vector embeddings. These embeddings allow the model to represent words, sentences, and even entire documents as numerical vectors in a high-dimensional space. By doing so, LLMs can efficiently process meaning, recognize patterns, and retrieve relevant information.
LLMs rely on multiple core components that work together to process and generate human-like text. One of the most fundamental building blocks is vector embeddings. However, embeddings are just one part of a much larger system that enables LLMs to understand, learn, and generate language effectively.
To fully grasp how LLMs function, it is essential to explore the other key components that power them. Below is an explanation of these building blocks of LLMs.
1. Embeddings
These are continuous vector representations of words or tokens that capture their semantic meanings in a high-dimensional space. They allow the model to convert discrete tokens into a format that can be processed by the neural network. LLMs learn embeddings during training to capture relationships between words, like synonyms or analogies.
2. Tokenization
Tokenization is the process of converting a sequence of text into individual words, subwords, or tokens that the model can understand. LLMs use subword algorithms like BPE or wordpiece to split text into smaller units that capture common and uncommon words. This approach helps to limit the model’s vocabulary size while maintaining its ability to represent any text sequence.
3. Attention
Attention mechanisms in LLMs, particularly the self-attention mechanism used in transformers, allow the model to weigh the importance of different words or phrases.
By assigning different weights to the tokens in the input sequence, the model can focus on the most relevant information while ignoring less important details. This ability to selectively focus on specific parts of the input is crucial for capturing long-range dependencies and understanding the nuances of natural language.
4. Pre-training
Pre-training is the process of training an LLM on a large dataset, usually unsupervised or self-supervised, before fine-tuning it for a specific task. During pretraining, the model learns general language patterns, relationships between words, and other foundational knowledge.
The process creates a pre-trained model that can be fine-tuned using a smaller dataset for specific tasks. This reduces the need for labeled data and training time while achieving good results in natural language processing tasks (NLP).
5. Transfer learning
Transfer learning is the technique of leveraging the knowledge gained during pretraining and applying it to a new, related task. In the context of LLMs, transfer learning involves fine-tuning a pre-trained model on a smaller, task-specific dataset to achieve high performance on that task.
The benefit of transfer learning is that it allows the model to benefit from the vast amount of general language knowledge learned during pretraining, reducing the need for large labeled datasets and extensive training for each new task.
While the building blocks of LLMs work together to enable powerful language understanding and generation, they are not without challenges. Since embeddings are the most crucial foundation of these models, let’s explore the key challenges associated with them.
Challenges and Limitations of Embeddings
Vector embeddings, while powerful, come with several inherent challenges and limitations that can impact their effectiveness in various applications. Understanding these challenges is crucial for optimizing their use in real-world scenarios.
Context Sensitivity
Capturing the full context of words or phrases remains challenging, especially when it comes to polysemy (words with multiple meanings) and varying contexts. Enhancing context sensitivity through advanced models like BERT or GPT-3, which consider the surrounding text to better understand the intended meaning, is crucial. Fine-tuning these models on domain-specific data can also help improve context sensitivity.
Scalability Issues
Handling large datasets can be difficult due to the high dimensionality of embeddings, leading to increased storage and retrieval times. Utilizing vector databases like Milvus, Pinecone, and Faiss, which are optimized for storing and querying high-dimensional vector data, can address these challenges.
These databases use techniques like vector compression and approximate nearest neighbor search to manage large datasets efficiently.
Training embeddings is resource-intensive, requiring significant computational power and time, especially for large-scale models. Leveraging pre-trained models and fine-tuning them on specific tasks can reduce computational costs. Using cloud-based services that offer scalable compute resources can also help manage these costs effectively.
Ethical Challenges
Addressing biases and non-deterministic outputs in training data is crucial to ensure fairness, transparency and consistency in AI applications.
Non-deterministic Outputs: Variability in results due to random initialization or training processes can hinder reproducibility. Using deterministic settings and seed initialization can improve consistency.
Bias in Embeddings: Models can inherit biases from training data, impacting fairness. By employing bias detection, mitigation strategies, and regular audits, ethical AI practices can be followed.
Future Advancement
Future advancements in embedding techniques are set to enhance their accuracy and efficiency significantly. New techniques are continually being developed to capture complex semantic relationships and contextual nuances better.
Techniques like ELMo, BERT, and GPT-3 have already made substantial strides in this field by providing deeper contextual understanding and more precise language representations. These advancements aim to improve the overall performance of AI applications, making them more intelligent and capable of understanding human language intricately.
Their integration with generative AI models is poised to revolutionize AI applications further. This combination allows for improved contextual understanding and the generation of more coherent and contextually relevant text.
For instance, models like GPT-3 enable the creation of high-quality text that captures nuanced understanding, enhancing applications in content creation, chatbots, and virtual assistants.
As these technologies continue to evolve, they promise to deliver richer, more sophisticated AI solutions that can handle a variety of data types, including text, images, and audio, ultimately leading to more comprehensive and insightful applications.