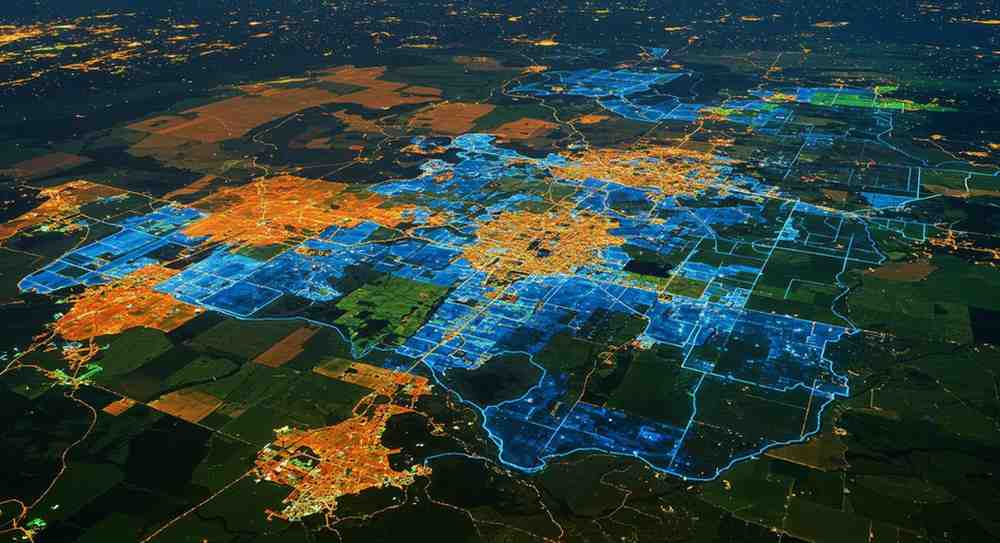
Data Visualization Field Boundaries Detection and Land Cover Classification: How EOSDA Does It? Data Science Dojo Staff
Data Visualization Understanding Data Visualizations: A Beginner’s Guide Syed Muhammad Mubashir Rizvi
Data Visualization The truth behind data storytelling in action: Challenges, successes, and limitations to present data Data Science Dojo Staff