AI is changing the way we communicate, and ChatGPT is leading the charge. From answering questions to generating creative content, this powerful AI tool feels almost human. But how does it actually work? And why is it making such a big impact?
In this blog, we’ll break down AI technology behind ChatGPT in a simple, easy-to-understand way—no technical jargon, just the fascinating tech behind it. Whether you’re curious about AI or want to know how it is shaping the future, you’re in the right place. Let’s dive in!

What is ChatGPT?
ChatGPT was officially launched on 30th November 2022 by OpenAI and quickly amassed a huge following not even in a week. Just to give you an idea it took Facebook around 10 months to gain 1 million followers ChatGPT did it in 5 days. So, the question that might arise in your minds my dear readers is why? Why did it gain so much popularity? What purpose does it serve? How does it work? Well, fret not we are here to answer those questions in this blog.
Let us begin by understanding what ChatGPT is, it is a language model that uses reinforcement learning from human feedback (RLHF) to keep on learning and fine-tuning its responses, it can answer a wide variety of questions within a span of a few minutes, help you in numerous tasks by giving you a curated, targeted response rather than vague links in a human-like manner.
Be it writing a code or searching for something chances are ChatGPT already has the specific thing you are looking for. This brings us to our next question; how does it work? Is there magic behind it? No, it is just the clever use of machine learning and an abundance of use cases and data that OpenAI created something as powerful and elegant as ChatGPT.
ChatGPT Teams for Small Businesses: A Quick Guide
The Architecture of ChatGPT
It is a variant of transformer-based neural network architecture, introduced in a paper by the name “Attention is all you need” in 2017, transformer architecture was specifically designed for NLP (Natural Language Processing) tasks and prevails as one of the most used methods to date.
A quick overview of the architecture involves its usage of self-attention mechanisms which allow the model to focus on specific words and phrases when generating text, rather than processing the entire input as a single unit. It consists of multiple layers, each of which contains a multi-head self-attention mechanism and a fully connected neural network.
Also, it includes a mechanism called positional encoding which lets the model understand the relative position of the words in the input. This architecture has proven to be amazingly effective in natural language processing tasks such as text generation, language translation, and text summarization.
Following are the different layers that are involved in the architecture of ChatGPT
- An embedding layer: This layer is responsible for converting the input words into a dense vector representation that the model can process.
- Multiple layers of self-attention: These layers are responsible for analyzing the input and calculating a set of attention weights, which indicate which parts of the input are most important for the current task.
- Multi-head attention: This layer is responsible for concatenating the outputs of multiple self-attention layers and then linearly transforming the resulting concatenated vectors.
- Multiple layers of fully connected neural networks: These layers are responsible for transforming the output of the attention layers into a final representation that can be used for the task at hand.
- Output layer: This layer is responsible for generating the final output of the model, which can be a probability distribution over the possible next words in a sentence or a classification label for a given input text.
Flow of ChatGPT
After getting a basic understanding of what ChatGPT is and its internal architecture we will now see the flow of ChatGPT from the training phase to answering a user prompt.
1. Data collection:
Around 300 billion words were gathered for the training of ChatGPT, the sources for the data mainly included books, articles, and websites.
2. Pre-Processing:
Once the data was collected it needed to be preprocessed so that it could be used for training. Techniques involved in preprocessing are stopped word removal, removal of duplicate data, lowercasing, removing special characters, tokenization, etc.
3. Training:
The pre-processed data is used to train ChatGPT, which is a variant of the transformer architecture. During training, the model learns the patterns and relationships between words, phrases, and sentences. This process can take several days to several weeks depending on the size of the dataset and the computational resources available.
4. Fine-tuning:
Once the pre-training is done, the model can be fine-tuned on a smaller, task-specific data set to improve its performance on specific natural language processing tasks.
5. Inference:
The trained and fine-tuned model is ready to generate responses to prompts. The input prompt is passed through the model, which uses its pre-trained weights and the patterns it learned during the training phase to generate a response.
6. Output:
The model generates a final output, which is a sequence of words that forms the answer to the prompt.
Strengths of the AI technology of ChatGPT
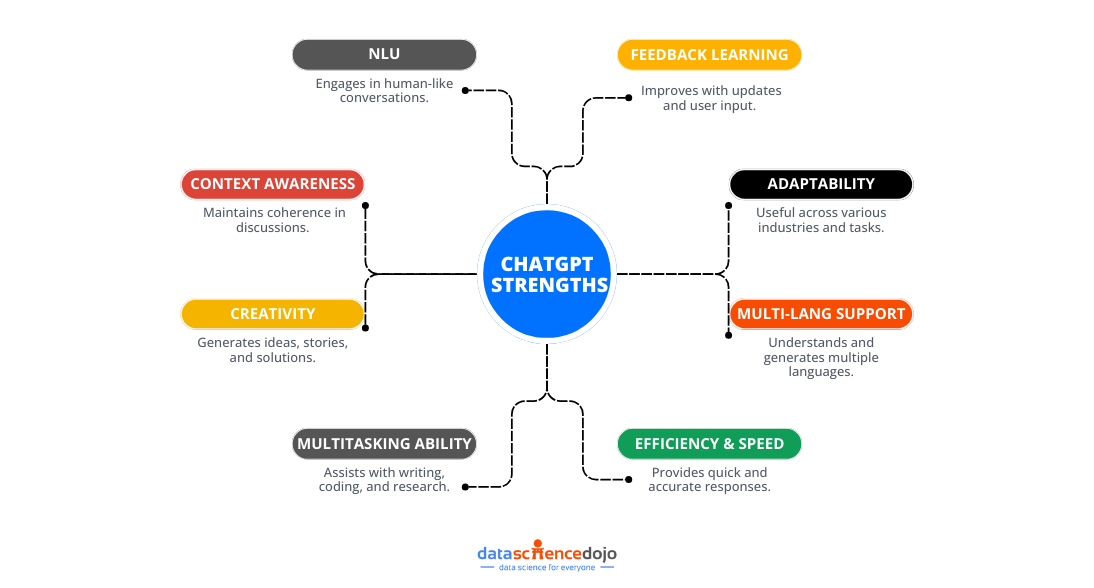
- ChatGPT is a large language model that has been trained on a massive dataset of text data, allowing it to understand and generate human-like text.
- It can perform a wide range of natural language processing tasks such as text completion, question answering, and conversation simulation.
- The transformer-based neural network architecture enables ChatGPT to understand the context of the input and generate a response accordingly.
- It can handle large input sequences and generate coherent and fluent text; this makes it suitable for long-form text generation tasks.
- Chat GPT can be used for multiple languages and can be fine-tuned for different dialects and languages.
- It can be easily integrated with other NLP tasks, such as named entity recognition, sentiment analysis, and text summarization.
- It can also be used in several applications like chatbots, virtual assistants, and language model-based text generation tasks

Weaknesses of ChatGPT
- ChatGPT is limited by the information contained in the training data and does not have access to external knowledge, which may affect its ability to answer certain questions.
- The model can be exposed to biases and stereotypes present in the training data, so the generated text should be used with caution.
- ChatGPT’s performance on languages other than English may be limited.
- Training and running ChatGPT requires significant computational resources and memory.
- ChatGPT is limited to natural language processing tasks and cannot perform tasks such as image or speech recognition.
- Lack of common-sense reasoning ability: ChatGPT is a language model and lacks the ability to understand common-sense reasoning, which can make it difficult to understand some context-based questions.
- Lack of understanding of sarcasm and irony: ChatGPT is trained on text data, which can lack sarcasm and irony, so it might not be able to understand them in the input.
- Privacy and security concerns: ChatGPT and other similar models are trained on large amounts of text data, which may include sensitive information, and the model’s parameters can also be used to infer sensitive information about the training data.
Storming the Internet – What’s Chat GPT-4?
The latest development in artificial intelligence (AI) has taken the internet by storm. OpenAI’s new language model, GPT-4, has everyone talking. GPT-4 is an upgrade from its predecessor, GPT-3, which was already an impressive language model. GPT-4 has improved capabilities, and it is expected to be even more advanced and powerful.
With GPT-4, there is excitement about the potential for advancements in natural language processing, which could lead to breakthroughs in many fields, including medicine, finance, and customer service. GPT-4 could enable computers to understand natural language more effectively and generate more human-like responses.
A Glimpse Into Auto GPT
However, it is not just GPT-4 that is causing a stir. Other AI language models, such as Auto GPT, are also making waves in the tech industry. Auto GPT is a machine learning system that can generate text on its own without any human intervention. It has the potential to automate content creation for businesses, making it a valuable tool for marketers.
Auto chat is particularly useful for businesses that need to engage with customers in real-time, such as customer service departments. By using auto chat, companies can reduce wait times, improve response accuracy and provide a more personalized customer experience.

In a Nutshell
So just to recap, ChatGPT is not a black box of unknown mysteries but rather a carefully crafted state-of-the-art artificial intelligence algorithm that has been rigorously trained with a variety of scenarios in order to cover all the possible use cases. Even though it can do wonders as we have seen already there is still a long way to go as there are still potential problems that need to be inspected and worked on. To get the latest news on astounding technological advancements and other associated fields visit Data Science Dojo to keep yourself posted.
ChatGPT is scary good. We are not far from dangerously strong AI – Elon Musk