

This tutorial will walk you through building a classification model in Azure ML Studio by using the same process as a traditional data mining framework.
Using Azure ML studio (Overview)
We will use the public Titanic dataset for this tutorial. From the dataset, we can build a predictive model that will correctly classify whether you will live or die based upon a passenger’s demographic features and circumstances.
Would you survive the Titanic disaster?
About the data
We use the Titanic dataset in our data science bootcamp, and have found it is one of the few datasets that is good for both beginners and experts because its complexity scales up with feature engineering. There are numerous public resources to obtain the Titanic dataset, however, the most complete (and clean) version of the data can be obtained from Kaggle, specifically their “train” data.
The train Titanic data has 891 rows, each one pertaining to a passenger on the RMS Titanic on the night of its disaster. The dataset also has 12 columns that each record an attribute about each occupant’s circumstances and demographics: user ID, passenger class, age, gender, name, number of siblings and spouses aboard, number of parents and children aboard, fare price, ticket number, cabin number, their port of embarkation, and whether they survived the ordeal or not.
For additional reading, a repository of biographies pertaining to everyone aboard the RMS Titanic can be found here (complete with pictures).
Preprocessing & data exploration
Drop low-value columns
Begin by identifying columns that add little-to-no value for predictive modeling. These columns will be dropped.
The first, most obvious candidate to be dropped is PassengerID. No information was provided to us as to how these keys were derived. Therefore, the keys could have been completely random and may add false correlations or noise to our model.
The second candidate for removal is the passenger Name column. Normally, names can be used to derive missing values of gender, but the gender column holds no empty values. Thus, this column is of no use to us, unless we use it to engineer another name column.
The third candidate for removal will be the Ticket column, which represents the ticket serial ID. Much like PassengerID, information is not readily available as to how these ticket strings were derived. Advanced users may dig into historical documents to investigate how the travel agencies set up their ticket names, perform a clustering analysis, or bin the ticket values. Those techniques are out of the scope of this experiment.
The last candidate to be dropped will be Cabin, which is the cabin number where the passenger stayed. Although this column may hold value when binned, there are 147 missing values in this column (~21% of the data). Advanced users may cluster the cabins by letters, or can dig down into the grit of the actual RMS Titanic ship schematics to derive useful features such as cabin distance from hull breach or average elevation from sea level.
Define categorical variables
We must now define which values are non-continuous by casting them as categorical. Mathematical approaches for continuous and non-continuous values differ greatly. For example, if we graph the “Survived” column now, it will look funny because it would try to account for the range between “0” and “1”. However, being partially alive in this case would be absurd. Categorical values are looked at independently of one another as “choices” or “options” rather than as a numeric range.
For a quick (but not exhaustive) exercise to see if something should be categorical, simply ask, “Would a decimal interval for this value make sense?”
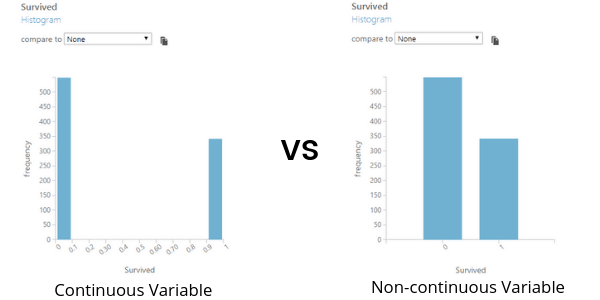
From this exercise, the columns that should be cast as categorical are: Survived, Pclass, Sex, and Embarked. The trickiest of these to determine might have been Pclass because it’s a numerical value that goes from 1 to 3. However, it does not really make sense to have a 2.5 Class between the second class and third class. Also, the relationship or “distance” between each interval of PClass is not explicit.
To cast these columns, drag in the “Edit Metadata” module. Specify the columns to be cast, then change the “Categorical” parameter to “Make categorical”.
Clean missing data in Azure ML
Most algorithms are unable to account for missing values and some treat it inconsistently from others. To address this, we must make sure our dataset contains no missing, “null,” or “NA” values. There are many ways to address missing values. We will cover three: replacement, exclusion, and deletion.
We used exclusion already when we made a conscious decision not to use “Cabin” attributes by dropping the column entirely.
Replacement is the most versatile and preferred method because it allows us to keep our data. It also minimizes collateral damage to other columns as a result of one cell’s bad behavior. In replacement, numerical values can easily be replaced with statistical values such as mean, median, or mode. The median is usually preferred for machine learning because it preserves the distribution of the data and is less affected by outliers. However, the median will skew and overload your frequencies, meaning it’ll mess with your bar graph but not your box plot.
We will cover deletion later in this section.
Now we can hunt for missing values. Drag in a “Summarize Data” module and connect it to your “Edit Metadata” module. Run the experiment and visualize the summary output. You will get a column summarizing the “missing value count” for each attribute. At this point, there are 177 missing values for “Age” and 2 missing values for “Embarked.”
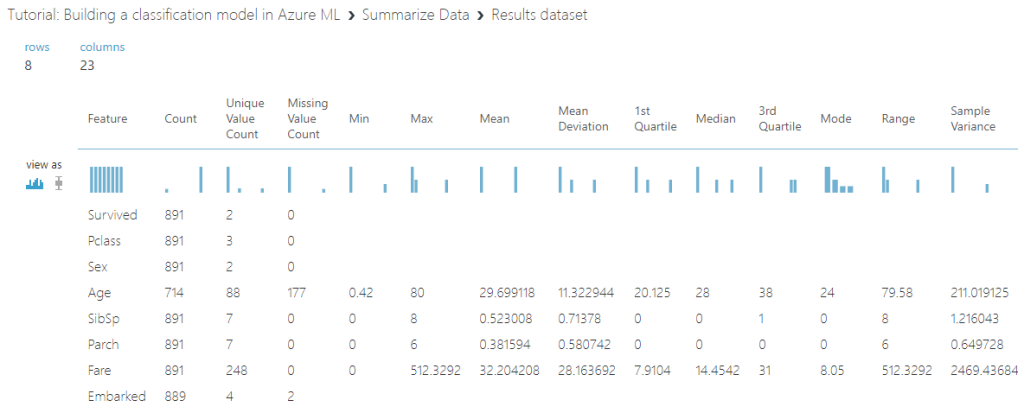
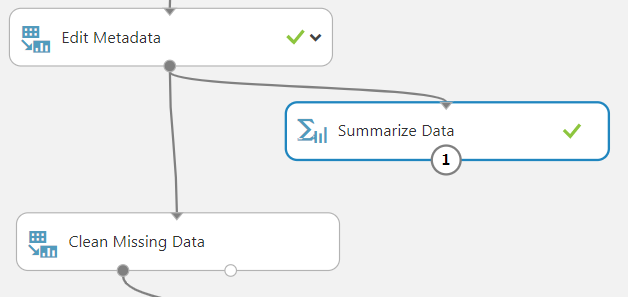
Looking at the metadata of “Age” reveals that it is a “numeric” type. As such, we can easily replace all missing values of age with the median. In this case, each missing value will be replaced with “28.”
Embarked is a bit trickier since it is a categorical string. Usually, the holes in categorical columns can be filled with a placeholder value. In this case, there are only 2 missing values so it would not make much sense to add another categorical value to “Embarked” in the form of S, C, Q, or U (for unknown) just to accommodate 2 rows. We can stand to lose 0.2% of our data by simply dropping these rows. This is an example of deletion.
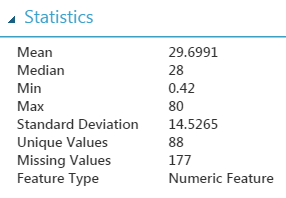
To clean missing values in Azure ML, use the “Clean Missing Data” module. This module will apply a single blanket operation to the selected features. First, we start by having one “Clean Missing Data” module to replace all missing numeric instances with the median. To select all the numeric columns, we select “Column Type” and “Numeric” under “Launch Column Selector” in the Properties of “Clean Missing Data.”
This will target only the “Age” column since it is the only numeric column with missing values. After the data goes through the module, there should only be 2 missing values left in the entire dataset, which is in “Embarked” column. Then, we add another “Clean Missing Data” module, set it to drop the missing rows in order to remove the 2 missing values of “Embarked.”

Specify a response class
We must now directly tell Azure ML which attribute we want our algorithm to train to predict by casting that attribute as a “label.” Do this by dragging in a “Edit Metadata” module. Use the column selector to specify “Survived” and change the “Fields” parameter to “Labels.” A dataset can only have 1 label at a time for this to work. Our model is now ready for machine learning!
Partition and withhold data
It is extremely important to randomly partition your data prior to training an algorithm to test the validity and performance of your model. A predictive model is worthless to us if it can only accurately predict known values. Withhold data represents data that the model never saw when it was training its algorithm. This will allow you to score the performance of your model later to evaluate how well the model can predict future or unknown values.
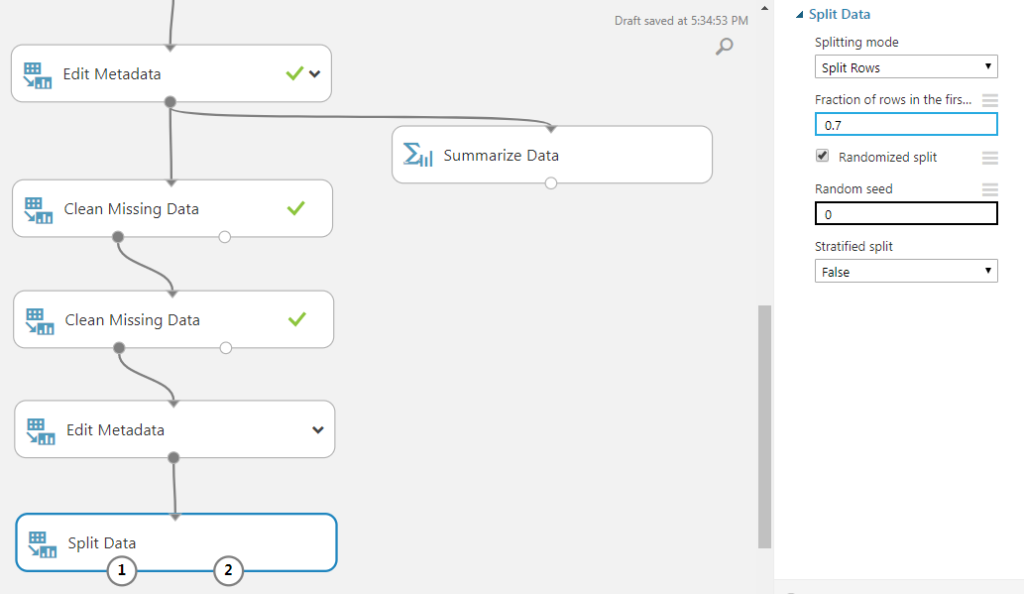
Drag in a “Split Data” module. It is usually industry practice to set a 70/30 split. To do this, set “fraction of rows in the first output dataset” to be 0.7. 70% of the data will be randomly shuffled into the left output node, while the remaining 30% will be shuffled into the right output node.
Select an algorithm
First, we must identify what kind of machine learning problem this is: classification, regression, clustering, etc. Since the response class is a categorical value, or “0” or “1”, for survived or deceased, we can tell that it is a classification problem. Specifically, we can tell that it is a two-class, or binary, classification problem because there are only two possible results: survived or deceased. Luckily, Azure ML ships with many two-class classification algorithms. Without going into algorithm-specific implementations, this problem lends itself well to decision forest and decision tree because the predictor classes are both numeric and categorical. Pick one algorithm (any two-class algorithm will work).
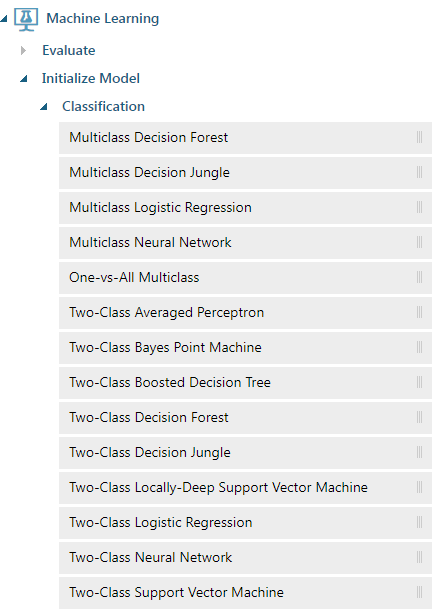
Train your model
Drag in a “Train Model” module and connect your algorithm to it. Connect your training data (the 70%) to the right input of the “Train Model” module. To score the model, drag in a “Score Model” module. Connect the “Train Model” to the left input node of the “Score Model,” and the 30% withhold data to the right input node of the “Score Model.” Finally, to evaluate the performance of model, drag in an “Evaluate Model” module and connect its left input to the output of the “Score Model.”
Run your model
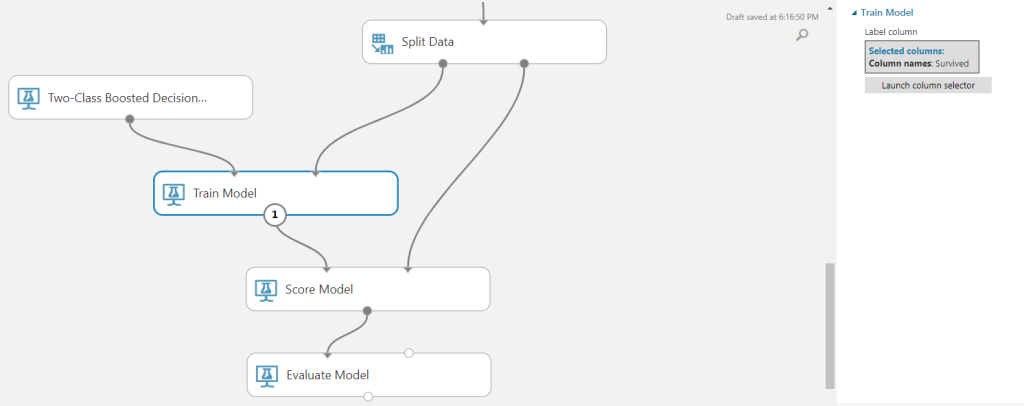
Evaluate your model
If you visualize your “Evaluate Model” module after running your model, you see a staggering number of metrics. Each machine learning problem will have its own unique goals, thus having different priorities when evaluating “good” or “bad” performance. As a result, each problem will also optimize different metrics.
For our experiment, we chose to maximize the RoC AuC because this is a low-risk situation where the outcomes of false negatives or false positives do not have different weights.
RoC AuCs will vary slightly because of the randomized split. The default parameters of our two-class boosted decision tree yielded a RoC AuC of 0.832. This is a fair-performing model. By fine-tuning the parameters, we can further increase the performance of the model.
Which metric to optimize?
- RoC AuC: Overall Performance
- Precision: Relevance
- Recall: Thoroughness
- Accuracy: Correctness
Beginner’s guide to RoC AuC
- o.9~1 = Suspiciously Good
- 0.8~0.9 = Fair
- 0.7~0.8 = Decent Model
- 0.5~0.6 = Worthless Model
Compare your model
How would our model shape up against another algorithm? Let’s find out. Drag in a “Two-Class Decision Forest” module. Copy and paste your “Train Model” module and your “Score Model” module. Reroute the input of the newly-created “Train Model” module to the decision forest. Attach the output of the newly-created “Score Model” module to the right input node of the “Evaluate Model” module. Now we can compare the performance of two machine learning models that were trained separately.
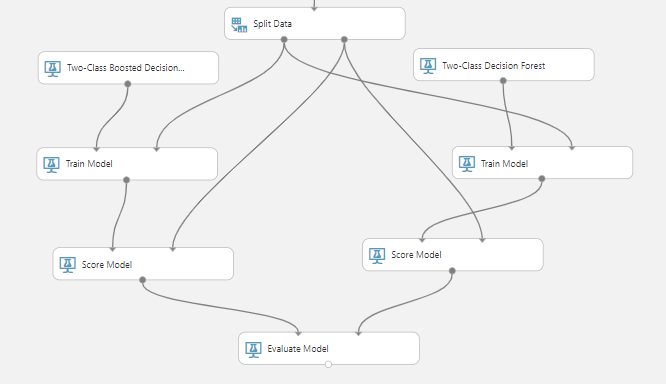
Both models performed fairly (~0.81 RoC AuC each). The boosted decision tree got a slightly higher RoC AuC overall, but the two models were close enough to be considered tied in terms of performance. As a tiebreaker, we can look at other metrics such as accuracy, precision, and recall. Using those metrics, we found that the boosted decision tree had lower accuracy, precision, and recall when compared to the two-class decision forest. If we were to select a winning model right now, it would probably be the two-class decision forest.
Other video tutorials
You can watch this series of videos to dive deeper into Azure Machine Learning:
- What is Azure Machine Learning?
- Subscriptions and Workspaces
- Import and Export Data, Modules, and Experiments
- Data Exploration
- Renaming Columns and Replicating Data
- Joining Datasets
- Dropping and Selecting Columns
- Cleaning and Summarizing Data
- Splitting and Categorical Casting
- Building your Machine Learning Model