Key Takeaways
- Harness engineering is the practice of building the structural layer around an AI agent — the constraints, tools, verification gates, and state management — that makes it behave reliably in production.
- Prompt engineering and context engineering were not enough once agents started running autonomously across real systems. The harness is what fills that gap.
- OpenAI’s Codex team used harness engineering principles to ship over one million lines of production code, written entirely by AI agents, in just five months.
What Is Harness Engineering?
Harness engineering is the discipline of building the structural layer that exists around an AI agent — the environment it operates inside, the boundaries it cannot cross, and the systems that catch it when it goes wrong.
The term was popularized by Mitchell Hashimoto, creator of Terraform and Ghostty, in early 2026. His core idea is straightforward:
“Every time an agent makes a mistake, you don’t just tell it to do better next time. You change the system so that specific mistake becomes structurally harder to repeat.”
This is not about making models smarter or prompts more clever. It’s about building the infrastructure that makes an agent’s intelligence usable in a real system, consistently, across sessions, at scale.
Why Did We Need a New Term?
Prompt engineering and context engineering were genuinely useful, for the tasks they were designed for. The problem is that agents in 2025 and 2026 started operating in environments that neither discipline was built to handle.
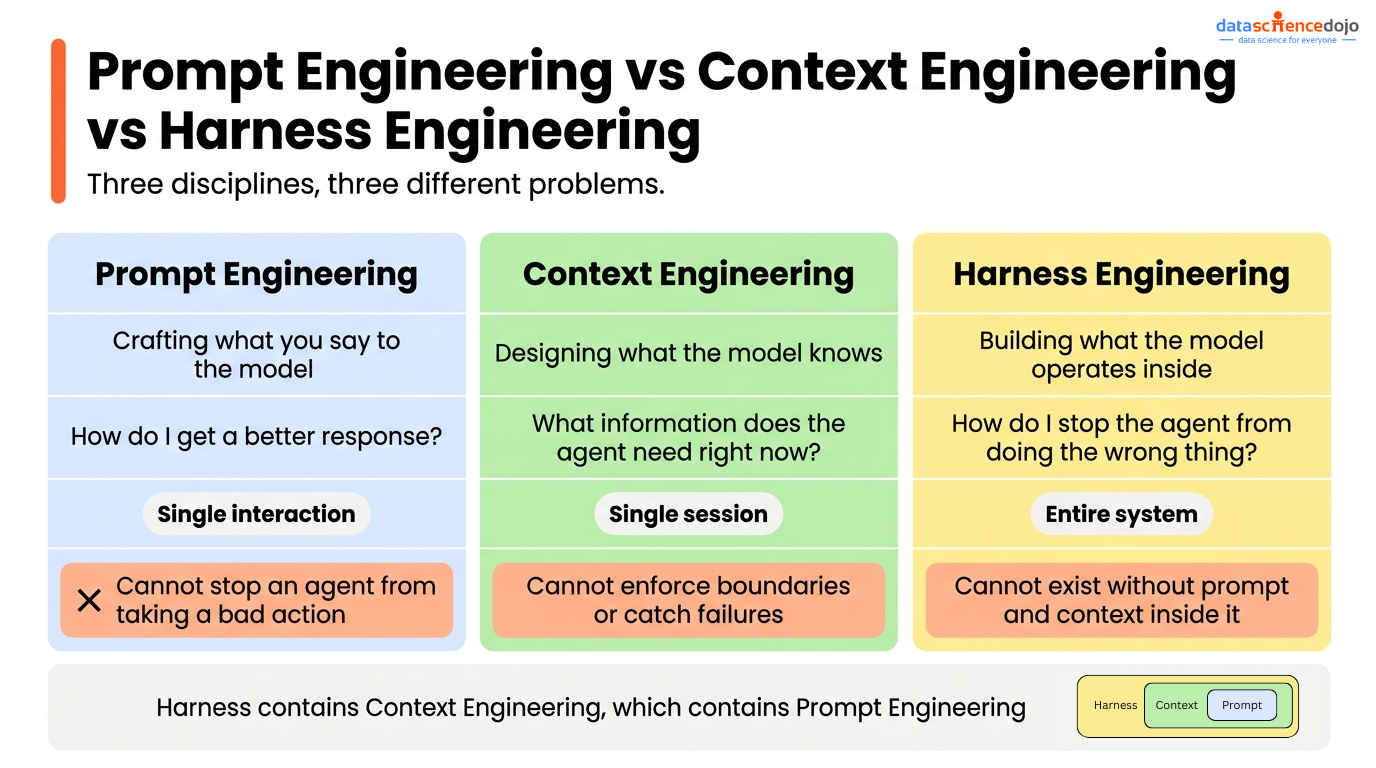
Prompt engineering emerged when models were used for single-turn tasks. You wrote a prompt, got a response, evaluated it. The whole interaction lived in one exchange. Prompt engineering got very good at improving that exchange.
Context engineering emerged as tasks got more complex and multi-turn. The content of what you sent the model started mattering as much as how you phrased it — retrieved documents, memory, session history, structured state. Context engineering addressed what the model knows at inference time.
Both broke down the moment agents started running autonomously for hours, writing real code, making real decisions, and chaining dozens of tool calls across multiple sessions.
The reason is simple: neither prompt engineering nor context engineering has any mechanism to stop an agent from doing something. A well-crafted prompt can influence what an agent tries to do. It cannot prevent the agent from rewriting your entire codebase if there is nothing architecturally stopping it. Retrieved context can give an agent accurate information. It cannot catch a verification failure or break a doom loop. Those are structural problems, and they need structural solutions.
That is what harness engineering is for.
Prompt engineering shapes what the agent tries. Context engineering shapes what the agent knows. Harness engineering shapes what the agent can and cannot do.
What Happens Without a Harness
Picture an agent tasked with fixing a single bug. Without a harness, there are no architectural constraints telling it what it can and cannot touch. There is no verification gate checking whether its fix actually works before it declares success. There is no loop detection to stop it from trying the same broken approach twelve times in a row. There is no progress file, so when the session ends it starts from scratch next time.
The agent edits files across the codebase, marks the task complete because it believes it succeeded, and two days later the fix surfaces in production as a different bug entirely.
This is not a model capability problem. The model was capable enough to attempt the task. It is a harness problem, and it is exactly the kind of failure that became unavoidable as agents moved from controlled demos into real engineering workflows.
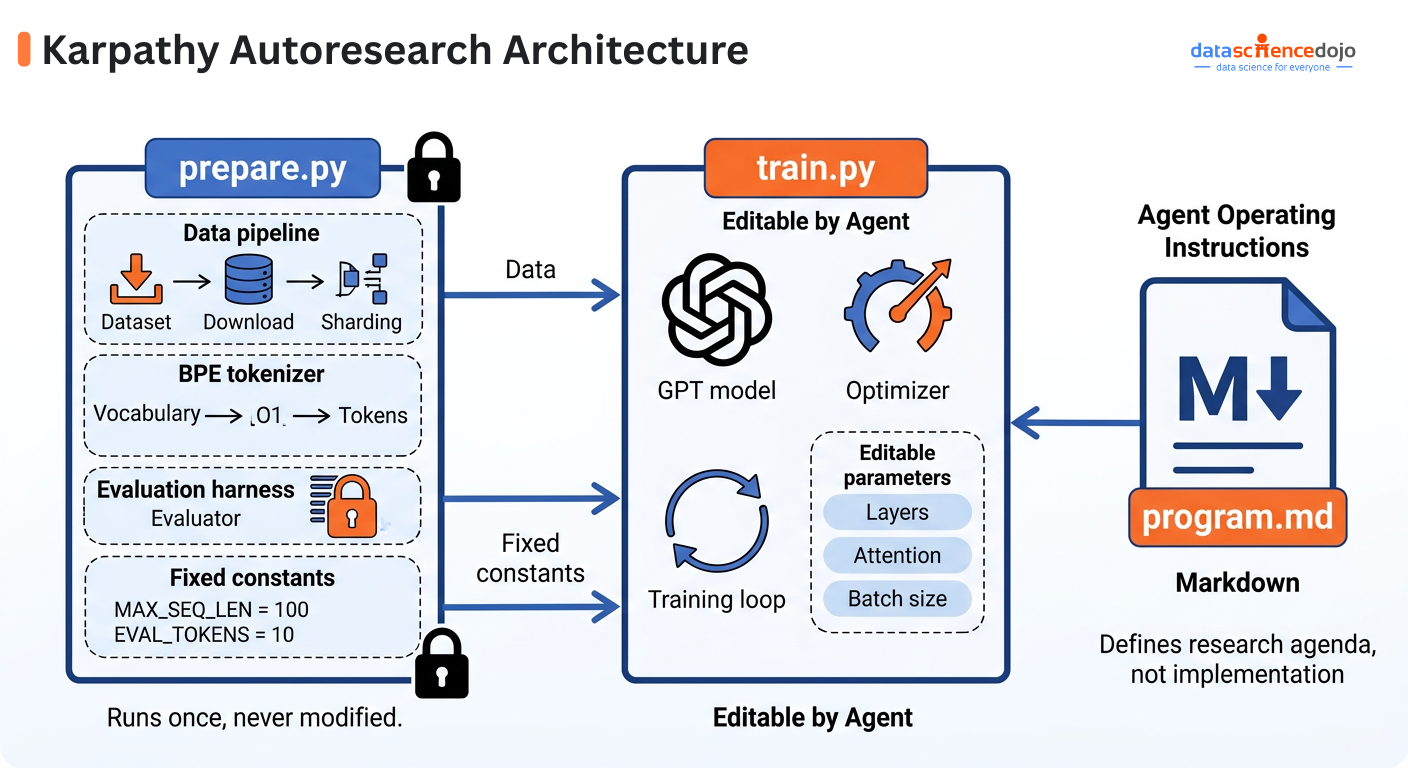
What a Harness Actually Consists Of
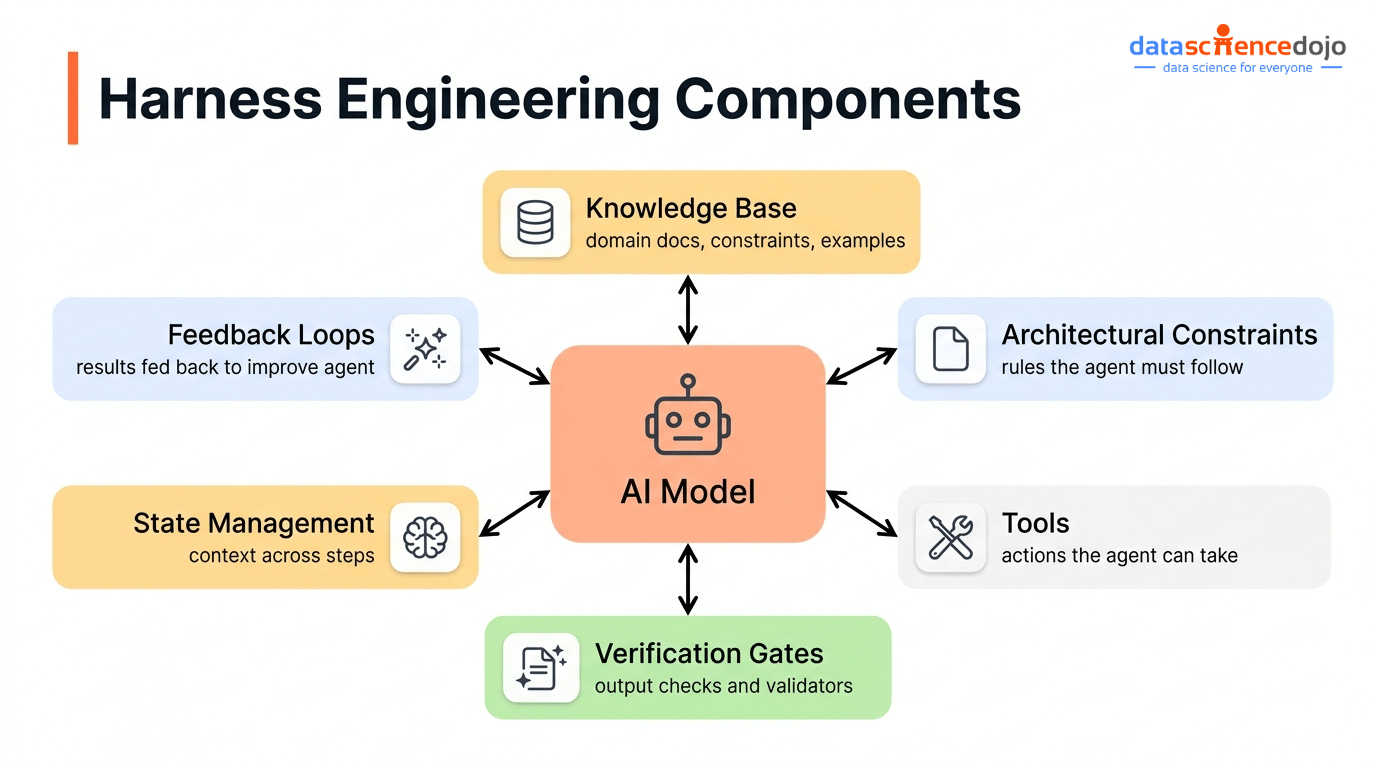
A harness is not a single file you write once. It is a collection of structural components that wrap around the model and govern how i operates. The model provides the intelligence. These components make that intelligence usable.
- Knowledge base: The documentation, architecture decisions, and project context stored in the repository that the agent reads before starting any task. If it is not in the repository, the agent cannot see it.
- Architectural constraints: Rules enforced by linters and structural tests that physically prevent the agent from touching code or systems it should not. These are not suggestions. The agent cannot override them.
- Tools and integrations: The CLI tools, APIs, and MCP servers that give the agent the ability to take real actions. An agent without the right tools is limited to generating text about the task rather than completing it.
- Verification gates: Tests and checks the agent must pass before it can mark a task complete. Without these, “done” means whatever the agent decided it means.
- State management: Progress files and session logs that persist across context windows so the agent never starts a new session with no memory of the previous one.
- Feedback loops: Loop detection and self-correction mechanisms that catch the agent when it repeats a broken approach, and route it back to a working path.
None of these are prompts. None of them are context. They are structural and the agent operates inside them whether it would “choose” to or not.
How Does Harness Engineering Work?
In harness engineering, these components cluster into three operational layers. Each layer addresses a different category of failure that appears when agents run in real-world environments.
1. Context Engineering: Giving the Agent What It Needs to Know
Agents can only work with what is in their context window. Anything stored in a Slack thread, a Google Doc, or someone’s memory is effectively invisible to them.
The context layer of a harness ensures the right information is available at the right moment. In practice this means maintaining a structured knowledge base inside the repository itself, writing progress files and session handoff documents so agents can resume work across context windows, and loading relevant documentation dynamically based on the current task rather than flooding the context upfront.
In their engineering write-up on building effective harnesses for long-running agents, the Anthropic team documented exactly this problem. Each new session began with no memory of prior work. Their solution was structured progress logs, feature tracking files in JSON rather than Markdown — agents were less likely to overwrite structured data — and an init script so a fresh agent could orient itself instantly.
For a deeper look at how context assembly works in modern AI systems, the guide on what context engineering actually is and how it differs from prompt engineering walks through the full architecture, including how RAG fits into the picture.
2. Architectural Constraints: Preventing the Wrong Moves
If the context layer is about what the agent knows, the constraint layer is about what the agent is allowed to do.
Production agents need hard boundaries. Without them, an agent tasked with refactoring a module might rewrite the entire codebase. In their February 2026 write-up on building with Codex agents, OpenAI’s engineering team described enforcing a strict layered architecture where each domain had rigid dependency rules, so code could only import from adjacent layers. This was not documentation guidance. It was enforced by custom linters and structural tests that ran on every pull request, and no agent could bypass them.
The key insight here: Constraints do not limit what an agent can accomplish. They focus it. A well-constrained agent produces better output precisely because it cannot wander into territory that creates downstream problems
3. Feedback Loops and Verification: Catching What Goes Wrong
Even a well-constrained agent with good context makes mistakes. The third layer is the system that catches and corrects those mistakes before they compound.
This includes self-verification prompts that instruct the agent to run tests and check its own output before marking a task complete, garbage collection agents that periodically scan for documentation drift and broken architectural patterns, and loop detection middleware that tracks how many times an agent edits the same file. After a threshold is crossed it injects a prompt nudging the agent to reconsider its approach, breaking the doom loops where agents make small variations on a broken solution ten or more times in a row.
LangChain’s engineering team demonstrated the impact of this layer directly. By improving their harness without changing the underlying model at all, their coding agent jumped from 52.8% to 66.5% on Terminal Bench 2.0, moving from 30th to 5th place overall.
Understanding how AI agent design patterns work, particularly reflection loops and self-correction, is essential groundwork before building these verification layers in your own systems.
Related: What Is Context Engineering? The New Foundation for Reliable AI and RAG Systems
The Real-World Proof: OpenAI’s Million-Line Codebase
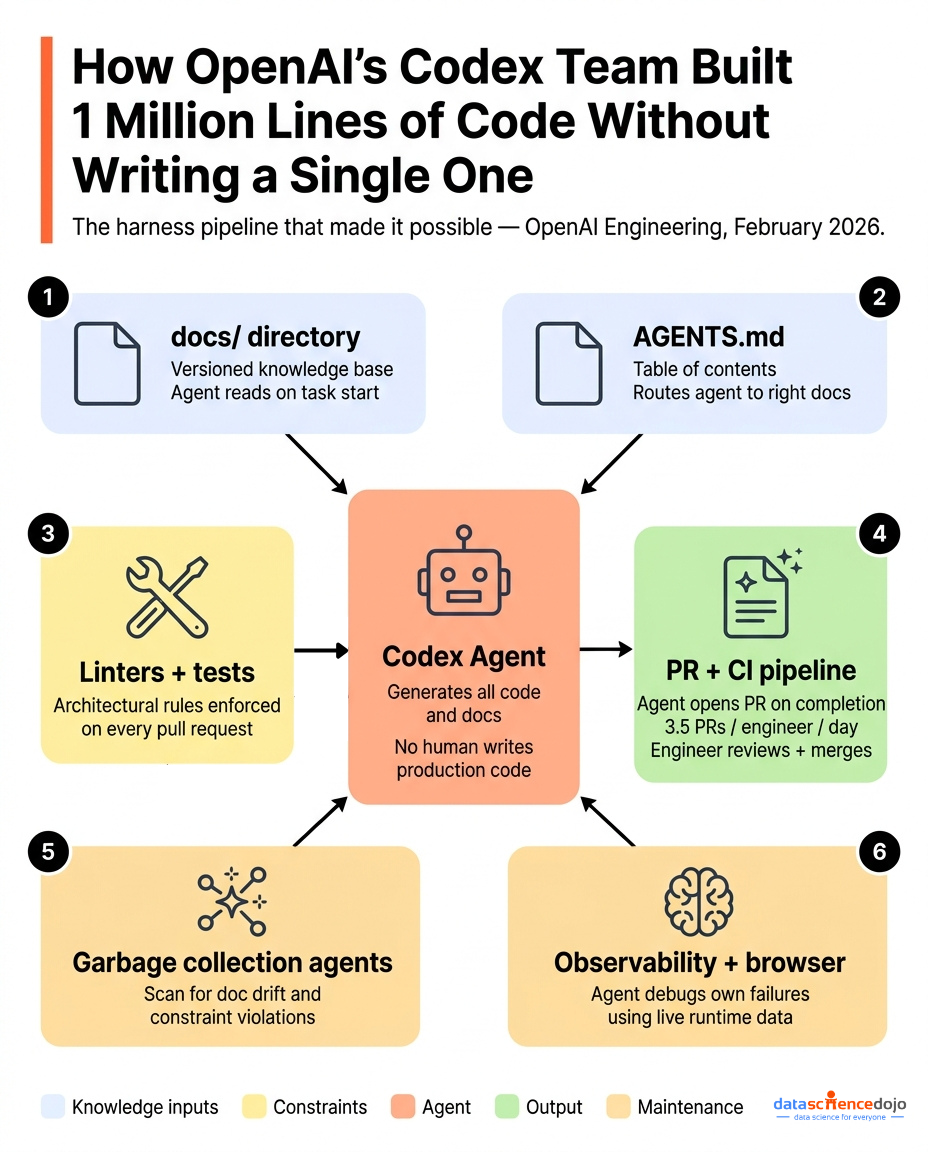
The clearest evidence for harness engineering’s impact comes from OpenAI’s Codex team, who published their findings in February 2026 after building an entire production product without a single human-written line of code.
Their constraint was radical: no human engineer would write a single line of production code. Everything had to be generated by Codex agents. This was not a productivity experiment. It was a forcing function: if the agents could not do the work, the product did not get built.
Five months later, the repository contained roughly one million lines of code across application logic, infrastructure, documentation, and tooling. A team of three engineers, later seven, merged approximately 1,500 pull requests, averaging 3.5 PRs per engineer per day.
The engineers’ job was not coding. It was designing the harness:
- A structured docs/ directory, versioned and indexed, served as the agent’s single source of truth
- A short AGENTS.md file acted as a table of contents, pointing agents to the right documentation for any task
- Custom linters enforced architectural rules that no agent could violate, even by accident
- Periodic garbage-collection agents scanned for documentation drift and constraint violations
- Agents had access to observability data and browser navigation so they could debug failures themselves
The lesson from OpenAI’s experiment is the same one LangChain confirmed with their benchmark results: the underlying model matters less than the system built around it. The model provides the intelligence, but the surrounding architecture determines whether that intelligence is usable consistently.
What Does a Harness Engineer Actually Do?
Harness engineering as a job title is still emerging. As of early 2026, you are more likely to find it listed as “AI infrastructure engineer,” “agent platform engineer,” or “AI systems engineer.” The work, though, is becoming well-defined.
A harness engineer’s core responsibilities are:
- Designing the knowledge base: ensuring all documentation, architecture decisions, and operational context live in the repository where the agent can access them, not in Slack or someone’s head
- Building and maintaining tooling: creating the CLI tools, MCP servers, and integrations that give agents the same capabilities human engineers rely on. The rise of agentic AI communication protocols like MCP and A2A has made this substantially more approachable in 2026
- Enforcing architectural constraints: writing custom linters and structural tests that make it mechanically impossible for agents to violate design rules
- Building verification systems: constructing the feedback loops, test runners, and self-check prompts that catch agent errors before they compound
- Running improvement loops: analyzing agent traces to find recurring failure modes, then fixing the harness so those failures do not repeat
This is distinct from simply building LLM-powered agents. The harness is what keeps those agents working consistently after the demo is over, and across the kind of long-horizon tasks that separate proof-of-concept from production. LangChain’s deep-dive on the anatomy of an agent harness and the academic framing in Pan et al.’s work on natural-language agent harnesses both arrive at the same conclusion: the harness is the primary unit of engineering work in an agent-first world, not the model.
FAQ: Harness Engineering
Q: Is harness engineering only relevant for large teams? No. Even a single developer working with an AI coding assistant benefits from harness engineering: maintaining a structured README, keeping documentation in the repository, and writing tests the agent can run against its own output. The principles scale from solo to enterprise.
Q: Does harness engineering make prompt engineering obsolete? No. Prompts are still the primary interface between a human and a model. Harness engineering operates at the system level. It determines what environment the prompt runs in, what tools are available, and how the output is verified. Good prompts inside a well-designed harness produce the best results.
Q: How does harness engineering relate to AI safety? There is significant overlap. Both are concerned with making AI systems behave predictably. Harness engineering is focused on production reliability (does the agent complete the task correctly?), while AI safety is focused on broader alignment (does the agent pursue the right goals?). Techniques like architectural constraints and verification loops appear in both fields.
Q: What is the difference between a harness and a system prompt? The system prompt is one component of the harness: the instruction layer loaded at the start of a session. The harness also includes tools, file system access, verification systems, architectural constraints, documentation infrastructure, and feedback loops. The system prompt is the tip of the harness iceberg.
Q: How do I start building a harness for my team? Start with the knowledge base. Put all project documentation, architecture decisions, and operational context into your repository in a structured, versioned format. Then add a simple verification step: a test suite the agent must pass before marking a task complete. From there, identify the most common agent failure modes in your traces and address them one at a time. The overview of what agentic AI systems actually require to function is a useful starting point before going deeper into harness engineering.
Q: Will harness engineering become less important as models improve? Probably not, at least not soon. Better models raise the ceiling, but the harness raises the floor. A well-designed harness makes any model more reliable by providing the right information, enforcing correct behavior, and catching errors. These are structural engineering problems that remain valuable regardless of model capability.
Wrapping Up
For a long time, getting better results from AI meant writing better prompts. Then it meant assembling better context. In 2026, the frontier moved again: the teams shipping reliable AI systems at scale are not winning on prompts or context. They are winning on the structural layer that contains both of those things.
That is harness engineering. It is the documentation the agent reads before starting. The rules it cannot override. The tests it must pass before declaring success. The state it carries from one session to the next.
Prompt engineering improved single interactions. Context engineering improved what the model knows. Harness engineering improves how the whole system behaves, and for teams running agents in production, that is the layer where the real leverage is.
If you are building with AI agents today, the harness engineering is where your effort belongs.
Ready to build robust and scalable LLM Applications?
Explore our LLM Bootcamp and Agentic AI Bootcamp for hands-on training in building production-grade retrieval-augmented and agentic AI.