
We have all been using the infamous ChatGPT for quite a while. But the thought of our data being used to train models has made most of us quite uneasy.
People are willing to use on-device AI applications as opposed to cloud-based applications for the obvious reasons of privacy.

Deploying an LLM application on edge devices—such as smartphones, IoT devices, and embedded systems—can provide significant benefits, including reduced latency, enhanced privacy, and offline capabilities.
In this blog, we will explore the process of deploying an LLM application on edge devices, covering everything from model optimization to practical implementation steps.
Understanding Edge Devices
Edge devices are hardware devices that perform data processing at the location where data is generated. Examples include smartphones, IoT devices, and embedded systems.
Edge computing offers several advantages over cloud computing, such as reduced latency, enhanced privacy, and the ability to operate offline.
However, deploying applications on edge devices has challenges, including limited computational resources and power constraints.
Preparing for On-Device AI Deployment
Before deploying an on-device AI application, several considerations must be addressed:
- Application Use Case and Requirements: Understand the specific use case for the LLM application and its performance requirements. This helps in selecting the appropriate model and optimization techniques.
- Data Privacy and Security: Ensure the deployment complies with data privacy and security regulations, particularly when processing sensitive information on edge devices.
Choosing the Right Language Model
Selecting the right language model for edge deployment involves balancing performance and resource constraints. Here are key factors to consider:
- Model Size and Complexity:
Smaller models are generally more suitable for edge devices. These devices have limited computational capacity, so a lighter model ensures smoother operation. Opt for models that strike a balance between size and performance, making them efficient without sacrificing too much accuracy. - Performance Requirements:
Model Optimization Techniques
Optimizing Large Language Models is crucial for efficient edge deployment. Here are several key techniques to achieve this:
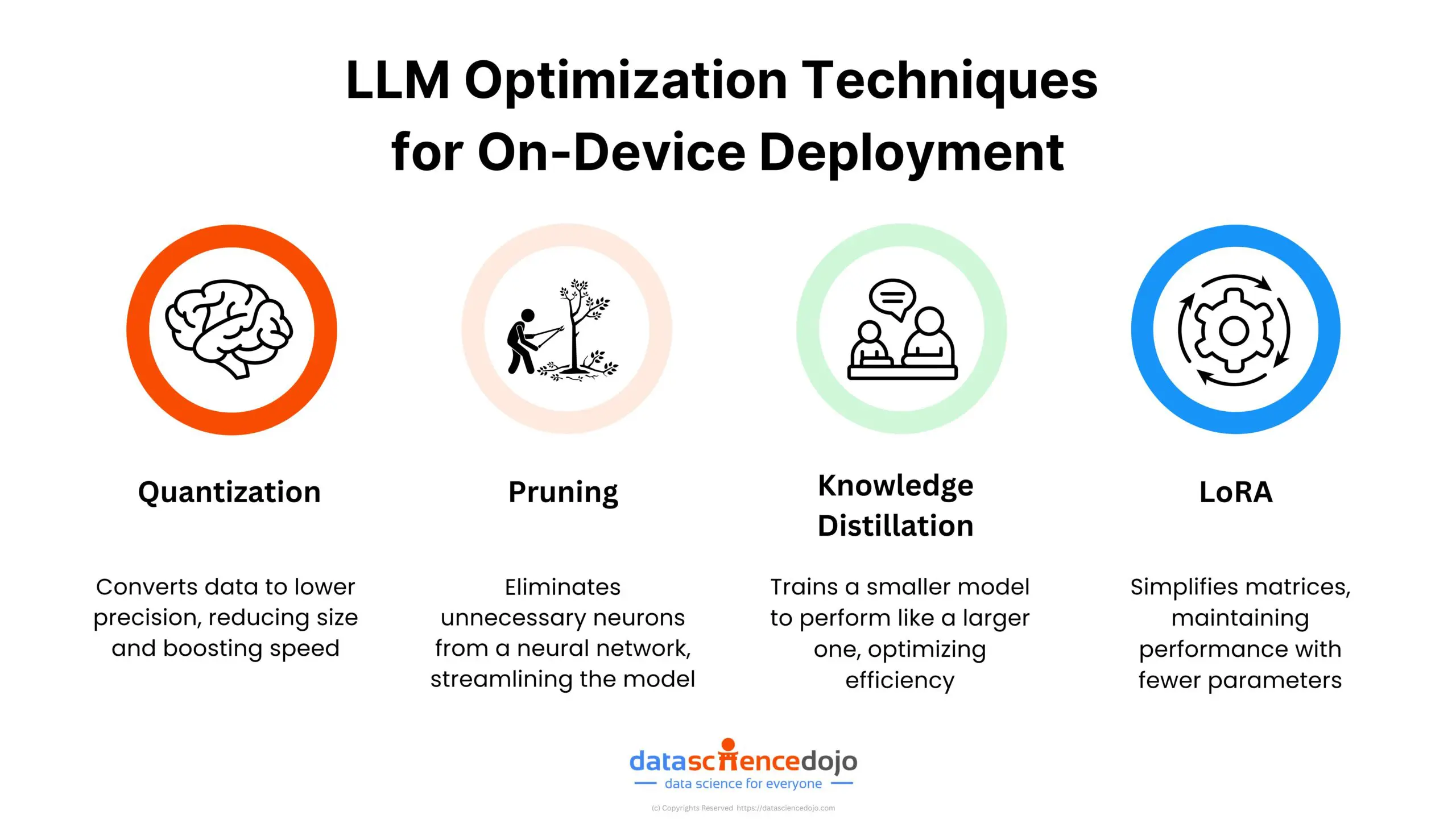
1. Quantization
Quantization reduces the precision of the model’s weights. By using lower precision (e.g., converting 32-bit floats to 8-bit integers), memory usage and computation requirements decrease significantly. This reduction leads to faster inference and lower power consumption, making quantization a popular technique for deploying LLMs on edge devices.
2. Pruning
Pruning involves removing redundant or less important neurons and connections within the model. By eliminating these parts, the model’s size is reduced, leading to faster inference times and lower resource consumption. Pruning helps maintain model performance while making it more efficient and manageable for edge deployment.
3. Knowledge Distillation
Knowledge distillation is a technique where a smaller model (the student) is trained to mimic the behavior of a larger, more complex model (the teacher). The student model learns to reproduce the outputs of the teacher model, retaining much of the original accuracy while being more efficient. This approach allows for deploying a compact, high-performing model on edge devices.
Read more about knowledge distillation
4. Low-Rank Adaptation (LoRA) and QLoRA
Low-Rank Adaptation (LoRA) and its variant QLoRA are techniques designed to adapt and compress models while maintaining performance. LoRA involves factorizing the weight matrices of the model into lower-dimensional matrices, reducing the number of parameters without significantly affecting accuracy. QLoRA further quantizes these lower-dimensional matrices, enhancing efficiency. These methods enable the deployment of robust models on resource-constrained edge devices.
5. Hardware and Software Requirements
Deploying on-device AI necessitates specific hardware and software capabilities to ensure smooth and efficient operation. Here’s what you need to consider:
Hardware Requirements
To run on-device AI applications smoothly, you need to ensure the hardware meets certain criteria:
- Computational Power: The device should have a powerful processor, ideally with multiple cores, to handle the demands of LLM inference. Devices with specialized AI accelerators, such as GPUs or NPUs, are highly beneficial.
- Memory: Adequate RAM is crucial as LLMs require significant memory for loading and processing data. Devices with limited RAM might struggle to run larger models.
- Storage: Sufficient storage capacity is needed to store the model and any related data. Flash storage or SSDs are preferable for faster read/write speeds.
Software Tools and Frameworks
The right software tools and frameworks are essential for deploying on-device AI. These tools facilitate model optimization, deployment, and inference. Key tools and frameworks include:
- TensorFlow Lite: A lightweight version of TensorFlow designed for mobile and edge devices. It optimizes models for size and latency, making them suitable for resource-constrained environments.
- ONNX Runtime: An open-source runtime that allows models trained in various frameworks to be run efficiently on multiple platforms. It supports a wide range of optimizations to enhance performance on edge devices.
- PyTorch Mobile: A version of PyTorch tailored for mobile and embedded devices. It provides tools to optimize and deploy models, ensuring they run efficiently on the edge.
- Edge AI SDKs: Many hardware manufacturers offer specialized SDKs for deploying AI models on their devices. These SDKs are optimized for the hardware and provide additional tools for model deployment and management.
Deployment Strategies for LLM Application
Deploying Large Language Models on edge devices presents unique challenges and opportunities from an AI engineer’s perspective. Effective deployment strategies are critical to ensure optimal performance, resource management, and user experience.
Here, we delve into three primary strategies: On-Device Inference, Hybrid Inference, and Model Partitioning.

On-Device Inference
On-device inference involves running the entire LLM directly on the edge device. This approach offers several significant advantages, particularly in terms of latency, privacy, and offline capability of the LLM application.
Benefits:
- Low Latency: On-device inference minimizes response time by eliminating the need to send data to and from a remote server. This is crucial for real-time applications such as voice assistants and interactive user interfaces.
- Offline Capability: By running the model locally, applications can function without an internet connection. This is vital for use cases in remote areas or where connectivity is unreliable.
- Enhanced Privacy: Keeping data processing on-device reduces the risk of data exposure during transmission. This is particularly important for sensitive applications, such as healthcare or financial services.
Challenges:
- Resource Constraints: Edge devices typically have limited computational power, memory, and storage compared to cloud servers. Engineers must optimize models to fit within these constraints without significantly compromising performance.
- Power Consumption: Intensive computations can drain battery life quickly, especially in portable devices. Balancing performance with energy efficiency is crucial.
Implementation Considerations:
- Model Optimization: Techniques such as quantization, pruning, and knowledge distillation are essential to reduce the model’s size and computational requirements.
- Efficient Inference Engines: Utilizing frameworks like TensorFlow Lite or PyTorch Mobile, which are optimized for mobile and embedded devices, can significantly enhance performance.
Hybrid Inference
Hybrid inference leverages both edge and cloud resources to balance performance and resource constraints. This strategy involves running part of the model on the edge device and part on the cloud server.
Benefits:
- Balanced Load: By offloading resource-intensive computations to the cloud, hybrid inference reduces the burden on the edge device, enabling the deployment of more complex models.
- Scalability: Cloud resources can be scaled dynamically based on demand, providing flexibility and robustness for varying workloads.
- Reduced Latency for Critical Tasks: Immediate, latency-sensitive tasks can be processed locally, while more complex processing can be handled by the cloud.

Challenges:
- Network Dependency: The performance of hybrid inference is contingent on the quality and reliability of the network connection. Network latency or interruptions can impact the user experience.
- Data Privacy: Transmitting data to the cloud poses privacy risks. Ensuring secure data transmission and storage is paramount.
Implementation Considerations:
- Model Segmentation: Engineers need to strategically segment the model, determining which parts should run on the edge and which on the cloud.
- Efficient Data Handling: Minimize the amount of data transferred between the edge and cloud to reduce latency and bandwidth usage. Techniques such as data compression and smart caching can be beneficial.
- Robust Fallbacks: Implement fallback mechanisms to handle network failures gracefully, ensuring the application remains functional even when connectivity is lost.
Model Partitioning
Model partitioning involves splitting the LLM into smaller, manageable segments that can be distributed across multiple devices or environments. This approach can enhance efficiency and scalability.
Benefits:
- Distributed Computation: By distributing the model across different devices, the computational load is balanced, making it feasible to run more complex models on resource-constrained edge devices.
- Flexibility: Different segments of the model can be optimized independently, allowing for tailored optimizations based on the capabilities of each device.
- Scalability: Model partitioning facilitates scalability, enabling the deployment of large models across diverse hardware configurations.
Challenges:
- Complex Implementation: Partitioning a model requires careful planning and engineering to ensure seamless integration and communication between segments.
- Latency Overhead: Communication between different model segments can introduce latency. Engineers must optimize inter-segment communication to minimize this overhead.
- Consistency: Ensuring consistency and synchronization between model segments is critical to maintaining the overall model’s performance and accuracy.
Implementation Considerations:
- Segmentation Strategy: Identify logical points in the model where it can be partitioned without significant loss of performance. This might involve separating different layers or components based on their computational requirements.
- Communication Protocols: Use efficient communication protocols to minimize latency and ensure reliable data transfer between model segments.
- Resource Allocation: Optimize resource allocation for each device based on its capabilities, ensuring that each segment runs efficiently.
Implementation Steps
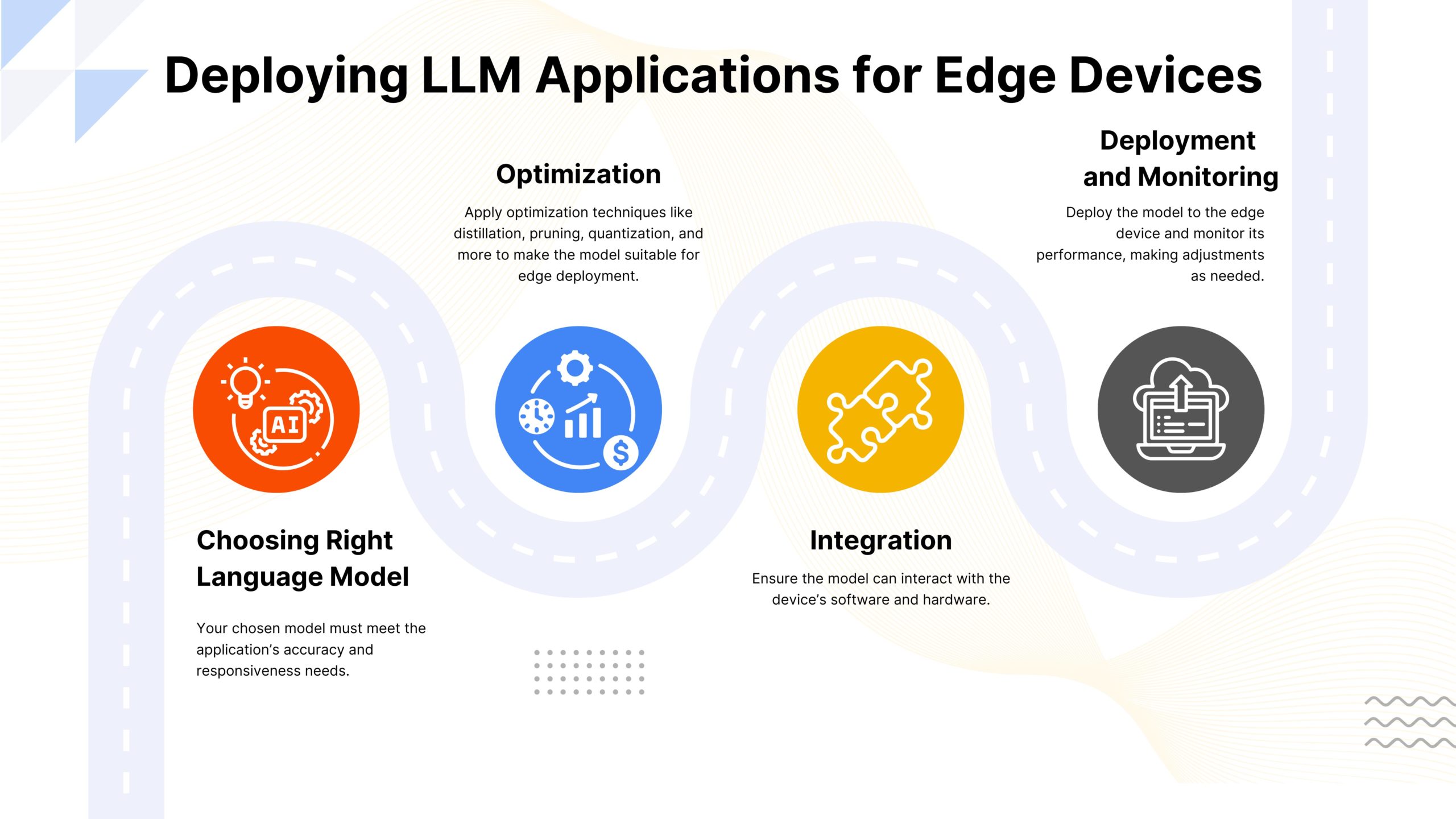
Here’s a step-by-step guide to deploying an on-device AI application:
- Preparing the Development Environment: Set up the necessary tools and frameworks for development.
- Optimizing the Model: Apply optimization techniques to make the model suitable for edge deployment.
- Integrating with Edge Device Software: Ensure the model can interact with the device’s software and hardware.
- Testing and Validation: Thoroughly test the model on the edge device to ensure it meets performance and accuracy requirements.
- Deployment and Monitoring: Deploy the model to the edge device and monitor its performance, making adjustments as needed.
Future of On-Device AI Applications
Deploying on-device AI applications can significantly enhance user experience by providing fast, efficient, and private AI-powered functionalities. By understanding the challenges and leveraging optimization techniques and deployment strategies, developers can successfully implement on-device AI.