

With the increasing role of data in today’s digital world, the multimodality of AI tools has become necessary for modern-day businesses. The multimodal AI market size is expected to experience a 36.2% increase by 2031. Hence, it is an important aspect of the digital world.
In this blog, we will explore multimodality within the world of large language models (LLMs) and how it impacts enterprises. We will also look into some of the leading multimodal LLMs in the market and their role in dealing with versatile data inputs.

Before we explore our list of multimodal LLMs, let’s dig deeper into understanding multimodality.
What is Multimodal AI?
In the context of Artificial Intelligence (AI), a modality refers to a specific type or form of data that can be processed and understood by AI models.

Primary modalities commonly involved in AI include:
- Text: This includes any form of written language, such as articles, books, social media posts, and other textual data.
- Images: This involves visual data, including photographs, drawings, and any kind of visual representation in digital form.
- Audio: This modality encompasses sound data, such as spoken words, music, and environmental sounds.
- Video: This includes sequences of images (frames) combined with audio, such as movies, instructional videos, and surveillance footage.
- Other Modalities: Specialized forms include sensor data, 3D models, and even haptic feedback, which is related to the sense of touch.
Multimodal AI models are designed to integrate information from these various modalities to perform complex tasks that are beyond the capabilities of single-modality models.
Multimodality in AI and Large Language Models (LLMs) is a significant advancement that enables these models to understand, process, and generate multiple types of data, such as text, images, and audio. This capability is crucial for several reasons, including real-world applications, enhanced user interactions, and improved performance.
Explore further the greatness of multimodal AI
The Technological Backbone of Multimodal LLMs
The multimodality of LLMs involves various advanced methodologies and architectures. They are designed to handle data from various modalities, like text, image, audio, and video. Let’s look at the major components and technologies that bring about multimodal LLMs.
How is LLM Development Making Chatbots Smarter
Core Components
Vision Encoder
It is designed to process visual data (images or videos) and convert it into a numerical representation called an embedding. This embedding captures the essential features and patterns of the visual input, making it possible for the model to integrate and interpret visual information alongside other modalities, such as text.
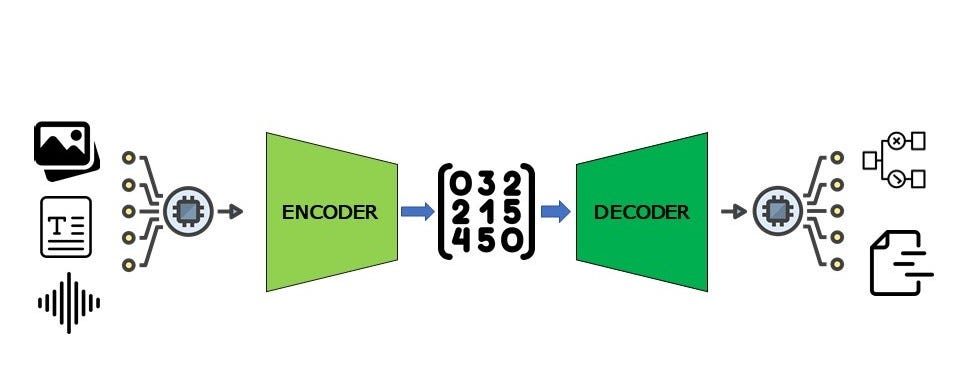
The steps involved in the function of a typical visual encoder can be explained as follows:
- Input Processing:
- The vision encoder takes an image or a video as input and processes it to extract relevant features. This often involves resizing the visual input to a standard resolution to ensure consistency.
- Feature Extraction:
- The vision encoder uses a neural network, typically a convolutional neural network (CNN) or a vision transformer (ViT), to analyze the visual input. These networks are pre-trained on large datasets to recognize various objects, textures, and patterns.
Understand Transformer models
- Embedding Generation:
- The processed visual data is then converted into a high-dimensional vector or embedding. This embedding is a compact numerical representation of the input image or video, capturing its essential features.
- Integration with Text:
- In multimodal LLMs, the vision encoder’s output is integrated with textual data. This is often done by projecting the visual embeddings into a shared embedding space where they can be directly compared and combined with text embeddings.
- Attention Mechanisms:
- Some models use cross-attention layers to allow the language model to focus on relevant parts of the visual embeddings while generating text. For example, Flamingo uses cross-attention blocks to weigh the importance of different parts of the visual and textual embeddings.
Text Encoder
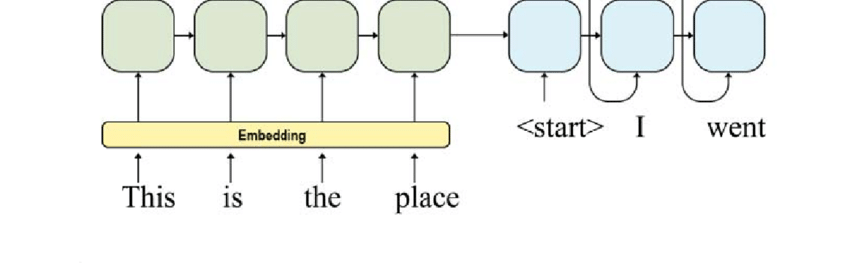
A text encoder works in a similar way to a vision encoder. The only difference is the mode of data it processes. Unlike a vision encoder, a text encoder processes and transforms textual data into numerical representations called embeddings.
Each embedding captures the essential features and semantics of the text, making it compatible for integration with other modalities like images or audio.
Shared Embedding Space
It is a unified numerical representation where data from different modalities—such as text and images—are projected. This space allows for the direct comparison and combination of embeddings from different types of data, facilitating tasks that require understanding and integrating multiple modalities.
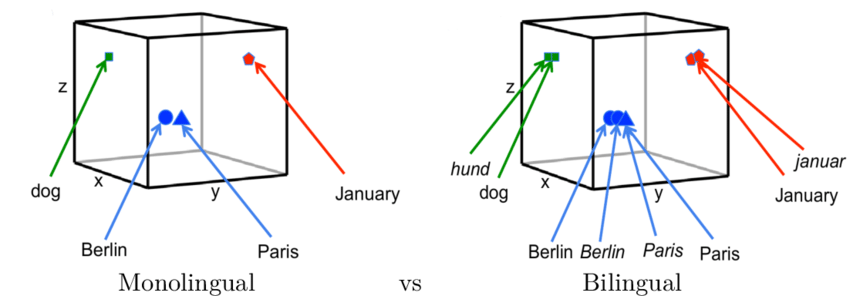
A shared embedding space works in the following manner:
- Individual Modality Encoders:
- Each modality (e.g., text, image) has its own encoder that transforms the input data into embeddings. For example, a vision encoder processes images to generate image embeddings, while a text encoder processes text to generate text embeddings.
- Projection into Shared Space:
- The embeddings generated by the individual encoders are then projected into a shared embedding space. This is typically done using projection matrices that map the modality-specific embeddings into a common space where they can be directly compared.
- Contrastive Learning:
- Contrastive learning techniques are used to align the embeddings in the shared space. It maximizes similarity between matching pairs (e.g., a specific image and its corresponding caption) and minimizes it between non-matching pairs. This helps the model learn meaningful relationships between different modalities.
- Applications:
- Once trained, the shared embedding space allows the model to perform various multimodal tasks. For example, in text-based image retrieval, a text query can be converted into an embedding, and the model can search for the closest image embeddings in the shared space.
Training Methodologies
Contrastive Learning
It is a type of self-supervised learning technique where the model learns to distinguish between similar and dissimilar data points by maximizing the similarity between positive pairs (e.g., matching image-text pairs) and minimizing the similarity between negative pairs (non-matching pairs).
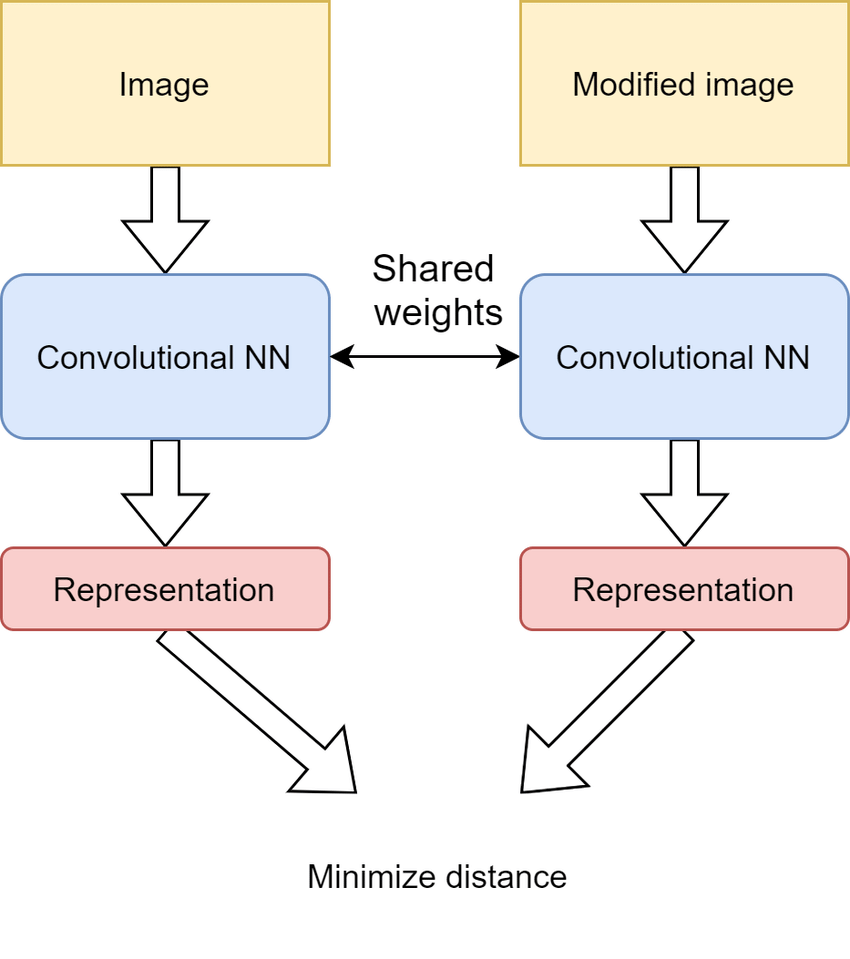
This approach is particularly useful for training models to understand the relationships between different modalities, such as text and images.
How it Works?
- Data Preparation:
- The model is provided with a batch of (N) pairs of data points, typically consisting of positive pairs that are related (e.g., an image and its corresponding caption) and negative pairs that are unrelated.
- Embedding Generation:
- The model generates embeddings for each data point in the batch. For instance, in the case of text and image data, the model would generate text embeddings and image embeddings.
- Similarity Calculation:
- The similarity between each pair of embeddings is computed using a similarity metric like cosine similarity. This results in (N^2) similarity scores for (N) pairs.
- Contrastive Objective:
- The training objective is to maximize the similarity scores of the correct pairings (positive pairs) while minimizing the similarity scores of the incorrect pairings (negative pairs). This is achieved by optimizing a contrastive loss function.
Perceiver Resampler
Perceiver Resampler is a component used in multimodal LLMs to handle variable-sized visual inputs and convert them into a fixed-length format that can be fed into a language model. This component is particularly useful when dealing with images or videos, which can have varying dimensions and feature sizes.
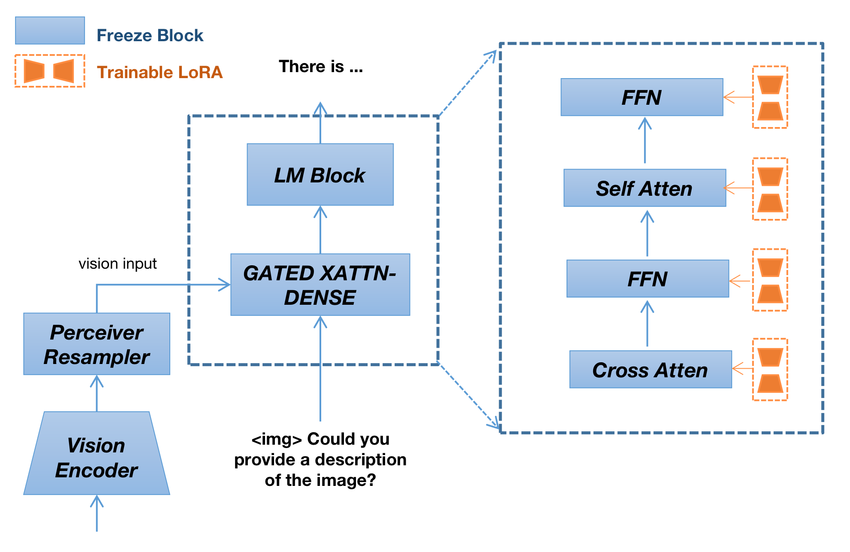
How does it work?
- Variable-Length Input Handling:
- Visual inputs such as images and videos can produce embeddings of varying sizes. For instance, different images might result in different numbers of features based on their dimensions, and videos can vary in length, producing a different number of frames.
- Conversion to Fixed-Length:
- The Perceiver Resampler takes these variable-length embeddings and converts them into a fixed number of visual tokens. This fixed length is necessary for the subsequent processing stages in the language model, ensuring consistency and compatibility with the model’s architecture.
- Training:
- During the training phase, the Perceiver Resampler is trained along with other components of the model. For example, in the Flamingo model, the Perceiver Resampler is trained to convert the variable-length embeddings produced by the vision encoder into a consistent 64 visual outputs.
Cross-Attention Mechanisms
These are specialized attention layers used in neural networks to align and integrate information from different sources or modalities, such as text and images. These mechanisms are crucial in multimodal LLMs for effectively combining visual and textual data to generate coherent and contextually relevant outputs.
How does it work?
- Input Representation:
- Cross-attention mechanisms take two sets of input embeddings: one set from the primary modality (e.g., text) and another set from the secondary modality (e.g., image).
- Query, Key, and Value Matrices:
- In cross-attention, the “query” matrix usually comes from the primary modality (text), while the “key” and “value” matrices come from the secondary modality (image). This setup allows the model to attend to the relevant parts of the secondary modality based on the context provided by the primary modality.
- Attention Calculation:
- The cross-attention mechanism calculates the attention scores between the query and key matrices, which are then used to weight the value matrix. The result is a contextually aware representation of the secondary modality that is aligned with the primary modality.
- Integration:
- The weighted sum of the value matrix is integrated with the primary modality’s embeddings, allowing the model to generate outputs that consider both modalities.
Hence, these core components and training methodologies combine to ensure the effective multimodality of LLMs.
Key Multimodal LLMs and Their Architectures
Let’s take a look at some of the leading multimodal LLMs and their architecture.
GPT-4o
Designed by OpenAI, GPT-4o is a sophisticated multimodal LLM that can handle multiple data types, including text, audio, and images.
Unlike previous models that required multiple models working in sequence (e.g., converting audio to text, processing the text, and then converting it back to audio), GPT-4o can handle all these steps in a unified manner. This integration significantly reduces latency and improves reasoning capabilities.
The model features an audio inference time that is comparable to human response times, clocking in at 320 milliseconds. This makes it highly suitable for real-time applications where quick audio processing is crucial.
GPT-4o is 50% cheaper and faster than GPT-4 Turbo while maintaining the same level of performance on text tasks. This makes it an attractive option for developers and businesses looking to deploy efficient AI solutions.
The Architecture
GPT-4o’s architecture incorporates several innovations to handle multimodal data effectively:
- Improved Tokenization: The model employs advanced tokenization methods to efficiently process and integrate diverse data types, ensuring high accuracy and performance.
- Training and Refinement: The model underwent rigorous training and refinement, including reinforcement learning from human feedback (RLHF), to ensure its outputs are aligned with human preferences and are safe for deployment.
Hence, GPT-4o plays a crucial role in advancing the capabilities of multimodal LLMs by integrating text, audio, and image processing into a single, efficient model. Its design and performance make it a versatile tool for a wide range of applications, from real-time audio processing to visual question answering and image captioning.
CLIP (Contrastive Language-Image Pre-training)
CLIP, developed by OpenAI, is a groundbreaking multimodal model that bridges the gap between text and images by training on large datasets of image-text pairs. It serves as a foundational model for many advanced multimodal systems, including Flamingo and LLaVA, due to its ability to create a shared embedding space for both modalities.
The Architecture
CLIP consists of two main components: an image encoder and a text encoder. The image encoder converts images into embeddings (lists of numbers), and the text encoder does the same for text.
The encoders are trained jointly to ensure that embeddings from matching image-text pairs are close in the embedding space, while embeddings from non-matching pairs are far apart. This is achieved using a contrastive learning objective.
Training Process
CLIP is trained on a large dataset of 400 million image-text pairs, collected from various online sources. The training process involves maximizing the similarity between the embeddings of matched pairs and minimizing the similarity between mismatched pairs using cosine similarity.
This approach allows CLIP to learn a rich, multimodal embedding space where both images and text can be represented and compared directly.
By serving as a foundational model for other advanced multimodal systems, CLIP demonstrates its versatility and significance in advancing AI’s capabilities to understand and generate multimodal content.
Flamingo

This multimodal LLM is designed to integrate and process both visual and textual data. Developed by DeepMind and presented in 2022, Flamingo is notable for its ability to perform various vision-language tasks, such as answering questions about images in a conversational format.
The Architecture
The language model in Flamingo is based on the Chinchilla model, which is pre-trained on next-token prediction. It predicts the next group of characters given a series of previous characters, a process known as autoregressive modeling.
The multimodal LLM uses multiple cross-attention blocks within the language model to weigh the importance of different parts of the vision embedding, given the current text. This mechanism allows the model to focus on relevant visual features when generating text responses.
Training Process
The training process for Flamingo is divided into three stages. The details of each are as follows:
- Pretraining
- The vision encoder is pre-trained using CLIP (Contrastive Language-Image Pre-training), which involves training both a vision encoder and a text encoder on image-text pairs. After this stage, the text encoder is discarded.
- Autoregressive Training
- The language model is pre-trained on next-token prediction tasks, where it learns to predict the subsequent tokens in a sequence of text.
- Final Training
- In the final stage, untrained cross-attention blocks and an untrained Perceiver Resampler are inserted into the model. The model is then trained on a next-token prediction task using inputs that contain interleaved images and text. During this stage, the weights of the vision encoder and the language model are frozen, meaning only the Perceiver Resampler and cross-attention blocks are updated and trained.
Hence, Flamingo stands out as a versatile and powerful multimodal LLM capable of integrating and processing text and visual data. It exemplifies the potential of multimodal LLMs in advancing AI’s ability to understand and generate responses based on diverse data types.
BLIP-2
BLIP-2 was released in early 2023. It represents an advanced approach to integrating vision and language models, enabling the model to perform a variety of tasks that require understanding both text and images.
The Architecture
BLIP-2 utilizes a pre-trained image encoder, which is often a CLIP-pre-trained model. This encoder converts images into embeddings that can be processed by the rest of the architecture. The language model component in BLIP-2 is either the OPT or Flan-T5 model, both of which are pre-trained on extensive text data.
The architecture of BLIP-2 also includes:
- Q-Former:
- The Q-Former is a unique component that acts as a bridge between the image encoder and the LLM. It consists of two main components:
- Visual Component: Receives a set of learnable embeddings and the output from the frozen image encoder. These embeddings are processed through cross-attention layers, allowing the model to weigh the importance of different parts of the visual input.
- Text Component: Processes the text input.
- The Q-Former is a unique component that acts as a bridge between the image encoder and the LLM. It consists of two main components:
- Projection Layer:
- After the Q-Former processes the embeddings, a projection layer transforms these embeddings to be compatible with the LLM. This ensures that the output from the Q-Former can be seamlessly integrated into the language model.
Training Process
The two-stage training process of BLIP-2 can be explained as follows:
- Stage 1: Q-Former Training:
- The Q-Former is trained on three specific objectives:
- Image-Text Contrastive Learning: Similar to CLIP, this objective ensures that the embeddings for corresponding image-text pairs are close in the embedding space.
- Image-Grounded Text Generation: This involves generating captions for images, training the model to produce coherent textual descriptions based on visual input.
- Image-Text Matching: A binary classification task where the model determines if a given image and text pair match (1) or not (0).
- The Q-Former is trained on three specific objectives:
- Stage 2: Full Model Construction and Training:
- In this stage, the full model is constructed by inserting the projection layer between the Q-Former and the LLM. The task now involves describing input images, and during this training stage, only the Q-Former and the projection layer are updated, while the image encoder and LLM remain frozen.
Hence, BLIP-2 represents a significant advancement in the field of multimodal LLMs, combining a pre-trained image encoder and a powerful LLM with the innovative Q-Former component.
While this sums up some of the major multimodal LLMs in the market today, let’s explore some leading applications of such language models.

Applications of Multimodal LLMs
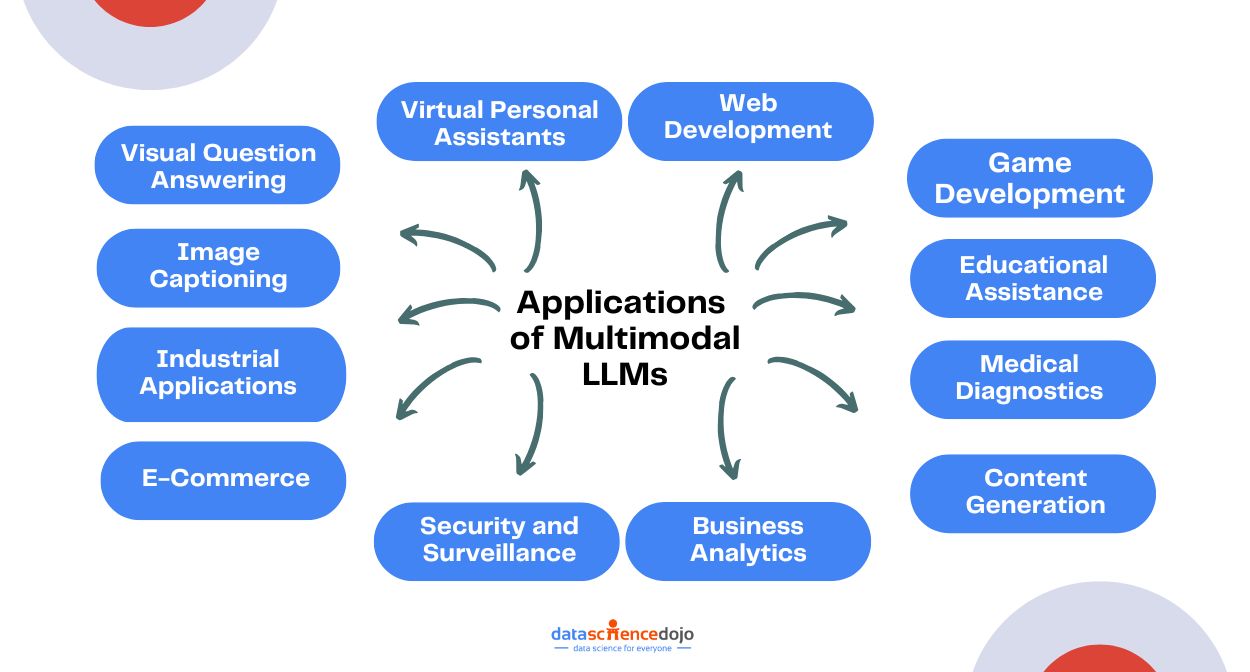
Multimodal LLMs have diverse applications across various domains due to their ability to integrate and process multiple types of data, such as text, images, audio, and video. Some of the key applications include:
1. Visual Question Answering (VQA)
Multimodal LLMs excel in VQA tasks where they analyze an image and respond to natural language questions about it. It is useful in various fields, including medical diagnostics, education, and customer service. For instance, a model can assist healthcare professionals by analyzing medical images and answering specific questions about diagnoses.
2. Image Captioning
These models can automatically generate textual descriptions for images, which is valuable for content management systems, social media platforms, and accessibility tools for visually impaired individuals. The models analyze the visual features of an image and produce coherent and contextually relevant captions.
3. Industrial Applications
Multimodal LLMs have shown significant results in industrial applications such as finance and retail. In the financial sector, they improve the accuracy of identifying fraudulent transactions, while in retail, they enhance personalized services leading to increased sales.
4. E-Commerce
In e-commerce, multimodal LLMs enhance product descriptions by analyzing images of products and generating detailed captions. This improves the user experience by providing engaging and informative product details, potentially increasing sales.
5. Virtual Personal Assistants
Combining image captioning and VQA, virtual personal assistants can offer comprehensive assistance to users, including visually impaired individuals. For example, a user can ask their assistant about the contents of an image, and the assistant can describe the image and answer related questions.
6. Web Development
Multimodal LLMs like GPT-4 Vision can convert design sketches into functional HTML, CSS, and JavaScript code. This streamlines the web development process, making it more accessible and efficient, especially for users with limited coding knowledge.
7. Game Development
These models can be used to develop functional games by interpreting comprehensive overviews provided in visual formats and generating corresponding code. This application showcases the model’s capability to handle complex tasks without prior training in related projects.
8. Educational Assistance
In the educational sector, these models can analyze diagrams, illustrations, and visual aids, transforming them into detailed textual explanations. This helps students and educators understand complex concepts more easily.
9. Medical Diagnostics
In medical diagnostics, multimodal LLMs assist healthcare professionals by analyzing medical images and answering specific questions about diagnoses, treatment options, or patient conditions. This aids radiologists and oncologists in making precise diagnoses and treatment decisions.
10. Content Generation
Multimodal LLMs can be used for generating content across different media types. For example, they can create detailed descriptions for images, generate video scripts based on textual inputs, or even produce audio narrations for visual content.
Here’s a list of the top 8 AI tools for content generation
11. Security and Surveillance
In security applications, these models can analyze surveillance footage and identify specific objects or activities, enhancing the effectiveness of security systems. They can also be integrated with other systems through APIs to expand their application sphere to diverse domains like healthcare diagnostics and entertainment.
12. Business Analytics
By integrating AI models and LLMs in data analytics, businesses can harness advanced capabilities to drive strategic transformation. This includes analyzing multimodal data to gain deeper insights and improve decision-making processes.
Explore 6 marketing analytics features to drive greater revenue
Thus, the multimodality of LLMs makes them a powerful tool. Their applications span across various industries, enhancing capabilities in education, healthcare, e-commerce, content generation, and more. As these models continue to evolve, their potential uses will likely expand, driving further innovation and efficiency in multiple fields.
Challenges and Future Directions
While multimodal AI models face significant challenges in aligning multiple modalities, computational costs, and complexity, ongoing research is making strides in incorporating more data modalities and developing efficient training methods.

Hence, multimodal LLMs have a promising future with advancements in integration techniques, improved model architectures, and the impact of emerging technologies and comprehensive datasets.
As researchers continue to explore and refine these technologies, we can expect more seamless and coherent multimodal models, pushing the boundaries of what LLMs can achieve and bringing us closer to models that can interact with the world similar to human intelligence.