

This is the first blog in the series of RAG and finetuning, focusing on providing a better understanding of the two approaches.
RAG LLM and finetuning: You’ve likely seen these terms tossed around on social media, hailed as the next big leap in artificial intelligence. But what do they really mean, and why are they so crucial in the evolution of AI?
To truly understand their significance, it’s essential to recognize the practical challenges faced by current language models, such as ChatGPT, renowned for their ability to mimic human-like text across essays, dialogues, and even poetry.
Yet, despite these impressive capabilities, their limitations became more apparent when tasked with providing up-to-date information on global events or expert knowledge in specialized fields.
Take, for instance, the FIFA World Cup.

If you were to ask ChatGPT, “Who won the FIFA World Cup?” expecting details on the most recent tournament, you might receive an outdated response citing France as the champions despite Argentina’s triumphant victory in Qatar 2022.
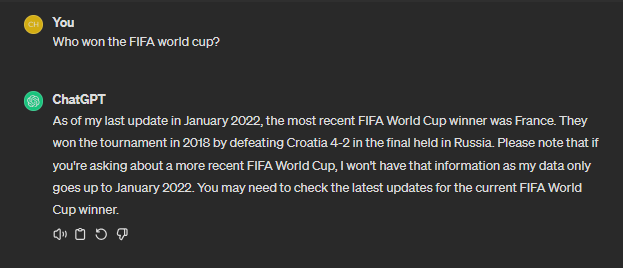
Moreover, the limitations of AI models extend beyond current events to specialized knowledge domains. Try asking ChatGPT for treatments in neurodegenerative diseases, a highly specialized medical field. The model might offer generic advice based on its training data but lacks depth or specificity – and, most importantly, accuracy.


These scenarios precisely illustrate the problem: a language model might generate text relevant to a past context or data but falls short when current or specialized knowledge is required.
Revisit the list of best large language models
Enter RAG and Finetuning
RAG revolutionizes the way language models access and use information. Incorporating a retrieval step allows these models to pull in data from external sources in real time.
This means that when you ask a RAG-powered model a question, it doesn’t just rely on what it learned during training; instead, it can consult a vast, constantly updated external database to provide an accurate and relevant answer. This would bridge the gap highlighted by the FIFA World Cup example.
On the other hand, fine-tuning offers a way to specialize a general AI model for specific tasks or knowledge domains. Additional training on a focused dataset sharpens the model’s expertise in a particular area, enabling it to perform with greater precision and understanding.
This process transforms a jack-of-all-trades into a master of one, equipping it with the nuanced understanding required for tasks where generic responses just won’t cut it. This would allow it to perform as a seasoned medical specialist dissecting a complex case rather than a chatbot giving general guidelines to follow.
Curious about the LLM context augmentation approaches like RAG and fine-tuning and their benefits, trade-offs and use-cases? Tune in to this podcast with Co-founder and CEO of LlamaIndex now!
This blog will walk you through RAG and finetuning, unraveling how they work, why they matter, and how they’re applied to solve real-world problems. By the end, you’ll not only grasp the technical nuances of these methodologies but also appreciate their potential to transform AI systems, making them more dynamic, accurate, and context-aware.

Understanding the RAG LLM Duo
Let’s take a closer look at the RAG LLM duo and its impact on a language model.
What is RAG?
Retrieval-augmented generation (RAG) significantly enhances how AI language models respond by incorporating a wealth of updated and external information into their answers. It could be considered a model consulting an extensive digital library for information as needed.
Its essence is in the name: Retrieval, Augmentation, and Generation.
Retrieval
The process starts when a user asks a query, and the model needs to find information beyond its training data. It searches through a vast database that is loaded with the latest information, looking for data related to the user’s query.
Augmentation
Next, the information retrieved is combined, or ‘augmented,’ with the original query. This enriched input provides a broader context, helping the model understand the query in greater depth.
Generation
Finally, the language model generates a response based on the augmented prompt. This response is informed by the model’s training and the newly retrieved information, ensuring accuracy and relevance.
Read in detail about retrieval augmented generation
Why Use RAG?
Retrieval-augmented generation (RAG) brings an approach to natural language processing that’s both smart and efficient. It solved many problems faced by current LLMs, and that’s why it’s the most talked about technique in the NLP space.
Always Up-To-Date: RAG keeps answers fresh by accessing the latest information. RAG ensures the AI’s responses are current and correct in fields where facts and data change rapidly.
Sticks to the Facts: Unlike other models that might guess or make up details (a ” hallucinations ” problem), RAG checks facts by referencing real data. This makes it reliable, giving you answers based on actual information.
Flexible and Versatile: RAG is adaptable, working well across various settings, from chatbots to educational tools and more. It meets the need for accurate, context-aware responses in a wide range of uses, and that’s why it’s rapidly being adapted in all domains.
Explore the power of the RAG LLM duo for enhanced performance
Exploring the RAG Pipeline
To understand RAG further, consider when you interact with an AI model by asking a question like “What’s the latest breakthrough in renewable energy?”. This is when the RAG system springs into action. Let’s walk through the actual process.
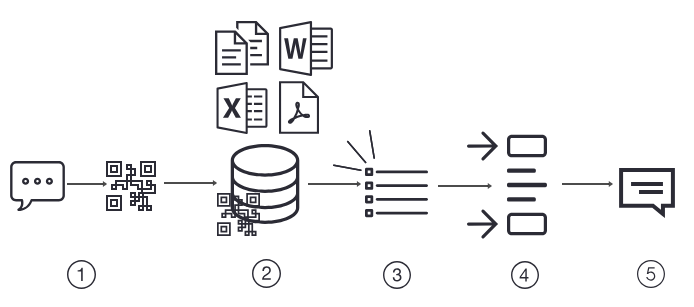
Query Initiation and Vectorization
- Your query starts as a simple string of text. However, computers, particularly AI models, don’t understand text and its underlying meanings the same way humans do. To bridge this gap, the RAG system converts your question into an embedding, also known as a vector.
- Why a vector, you might ask? Well, A vector is essentially a numerical representation of your query, capturing not just the words but the meaning behind them. This allows the system to search for answers based on concepts and ideas, not just matching keywords.
Searching the Vector Database
- With your query now in vector form, the RAG system seeks answers in an up-to-date vector database. The system looks for the vectors in this database that are closest to your query’s vector—the semantically similar ones, meaning they share the same underlying concepts or topics.
Learn all you need to know about vector databases
- But what exactly is a vector database?
- Vector databases defined: A vector database stores vast amounts of information from diverse sources, such as the latest research papers, news articles, and scientific discoveries. However, it doesn’t store this information in traditional formats (like tables or text documents). Instead, each piece of data is converted into a vector during the ingestion process.
- Why vectors?: This conversion to vectors allows the database to represent the data’s meaning and context numerically or into a language the computer can understand and comprehend deeply, beyond surface-level keywords.
- Indexing: Once information is vectorized, it’s indexed within the database. Indexing organizes the data for rapid retrieval, much like an index in a textbook, enabling you to find the information you need quickly. This process ensures that the system can efficiently locate the most relevant information vectors when it searches for matches to your query vector.
Uncover the mystery of indexing and its types in Python
- The key here is that this information is external and not originally part of the language model’s training data, enabling the AI to access and provide answers based on the latest knowledge.
Selecting the Top ‘k’ Responses
- From this search, the system selects the top few matches—let’s say the top 5. These matches are essentially pieces of information that best align with the essence of your question.
- By concentrating on the top matches, the RAG system ensures that the augmentation enriches your query with the most relevant and informative content, avoiding information overload and maintaining the response’s relevance and clarity.
Augmenting the Query
- Next, the information from these top matches is used to augment the original query you asked the LLM. This doesn’t mean the system simply piles on data. Instead, it integrates key insights from these top matches to enrich the context for generating a response. This step is crucial because it ensures the model has a broader, more informed base from which to draw when crafting its answer.
Generating the Response
- Now comes the final step: generating a response. With the augmented query, the model is ready to reply. It doesn’t just output the retrieved information verbatim. Instead, it synthesizes the enriched data into a coherent, natural-language answer.
For your renewable energy question, the model might generate a summary highlighting the most recent and impactful breakthrough, perhaps detailing a new solar panel technology that significantly increases power output. This answer is informative, up-to-date, and directly relevant to your query.

Understanding Fine-Tuning
While we now understand RAG better, we must also explore the other key process when optimizing LLMs – fine-tuning. The basic details include:
What is Fine-Tuning?
Fine-tuning could be likened to sculpting, where a model is precisely refined, like shaping marble into a distinct figure. Initially, a model is broadly trained on a diverse dataset to understand general patterns—this is known as pre-training. Think of pre-training as laying a foundation; it equips the model with a wide range of knowledge.
Fine-tuning, then, adjusts this pre-trained model and its weights to excel in a particular task by training it further on a more focused dataset related to that specific task. From training on vast text corpora, pre-trained LLMs, such as GPT or BERT, have a broad understanding of language.
Fine-tuning adjusts these models to excel in targeted applications, from sentiment analysis to specialized conversational agents.
Compare RLHF and DPO techniques for fine-tuning LLMs
Why Fine-Tune?
The breadth of knowledge LLMs acquire through initial training is impressive but often lacks the depth or specificity required for certain tasks. Fine-tuning addresses this by adapting the model to the nuances of a specific domain or function, enhancing its performance significantly on that task without the need to train a new model from scratch.
The Fine-Tuning Process
Fine-tuning involves several key steps, each critical to customizing the model effectively. The process aims to methodically train the model, guiding its weights toward the ideal configuration for executing a specific task with precision.
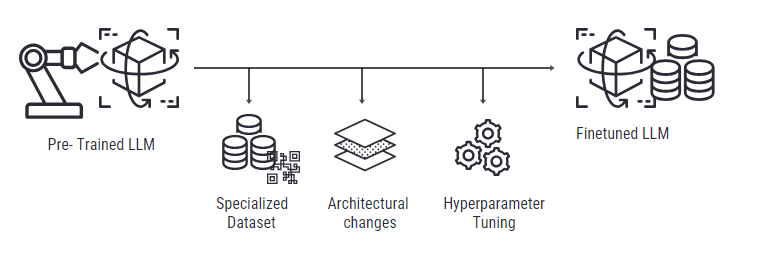
Selecting a Task
Identify the specific task you wish your model to perform better on. The task could range from classifying emails into spam or not spam to generating medical reports from patient notes.
Choosing the Right Pre-Trained Model
The foundation of fine-tuning begins with selecting an appropriate pre-trained large language model (LLM) such as GPT or BERT. These models have been extensively trained on large, diverse datasets, giving them a broad understanding of language patterns and general knowledge.
The choice of model is critical because its pre-trained knowledge forms the basis for the subsequent fine-tuning process. For tasks requiring specialized knowledge, like medical diagnostics or legal analysis, choose a model known for its depth and breadth of language comprehension.
Preparing the Specialized Dataset
For fine-tuning to be effective, the dataset must be closely aligned with the specific task or domain of interest. This dataset should consist of examples representative of the problem you aim to solve. For a medical LLM, this would mean assembling a dataset comprised of medical journals, patient notes, or other relevant medical texts.
The key here is to provide the model with various examples it can learn from. This data must represent the types of inputs and desired outputs you expect once the model is deployed.
Reprocess the Data
Before your LLM can start learning from this task-specific data, the data must be processed into a format the model understands. This could involve tokenizing the text, converting categorical labels into numerical format, and normalizing or scaling input features.
At this stage, data quality is crucial; thus, you’ll look out for inconsistencies, duplicates, and outliers, which can skew the learning process, and fix them to ensure cleaner, more reliable data.
After preparing this dataset, you divide it into training, validation, and test sets. This strategic division ensures that your model learns from the training set, tweaks its performance based on the validation set, and is ultimately assessed for its ability to generalize from the test set.
Read more about Finetuning LLMs
Adapting the Model for a Specific Task
Once the pre-trained model and dataset are ready, you must better tailor the model to suit your specific task. An LLM comprises multiple neural network layers, each learning different aspects of the data.
During fine-tuning, not every layer is tweaked—some represent foundational knowledge that applies broadly. In contrast, the top or later layers are more plastic and customized to align with the specific nuances of the task.
The architecture requires two key adjustments:
Layer freezing: To preserve the general knowledge the model has gained during pre-training, freeze most of its layers, especially the lower ones closer to the input. This ensures the model retains its broad understanding while you fine-tune the upper layers to be more adaptable to the new task.
Output layer modification: Replace the model’s original output layer with a new one tailored to the number of categories or outputs your task requires. This involves configuring the output layer to classify various medical conditions accurately for a medical diagnostic task.
Fine-Tuning Hyperparameters
With the model’s architecture now adjusted, we turn your attention to hyperparameters. Hyperparameters are the settings and configurations that are crucial for controlling the training process. They are not learned from the data but are set before training begins and significantly impact model performance.
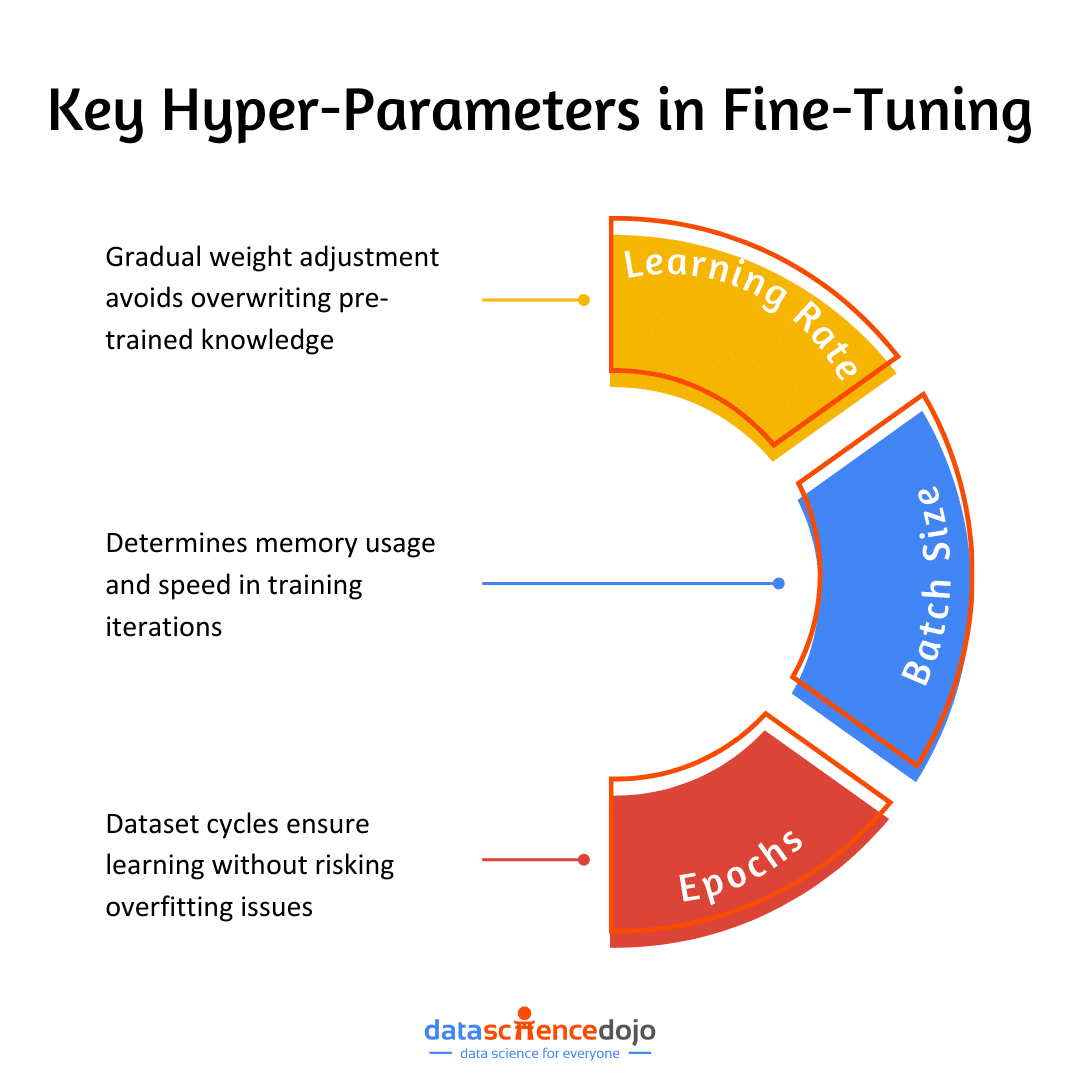
Key hyperparameters in fine-tuning include:
- Learning rate: Perhaps the most critical hyperparameter in fine-tuning. A lower learning rate ensures that the model’s weights are adjusted gradually, preventing it from “forgetting” its pre-trained knowledge.
- Batch size: The number of training examples used in one iteration. It affects the model’s learning speed and memory usage.
- Epochs: The number of times the entire dataset is passed through the model. Enough epochs are necessary for learning, but too many can lead to overfitting.
You can also learn about overparameterization in LLMs
Training Process
With the dataset prepared, the model was adapted, and the hyperparameters were set, so the model is now ready to be fine-tuned.
The training process involves repeatedly passing your specialized dataset through the model, allowing it to learn from the task-specific examples, it involves adjusting the model’s internal parameters, the weights, and biases of those fine-tuned layers so the output predictions get as close to the desired outcomes as possible.
This is done in iterations (epochs), and thanks to the pre-trained nature of the model, it requires fewer epochs than training from scratch.
Here is what happens in each iteration:
- Forward pass: The model processes the input data, making predictions based on its current state.
- Loss calculation: The difference between the model’s predictions and the actual desired outputs (labels) is calculated using a loss function. This function quantifies how well the model is performing.
- Backward pass (Backpropagation): The gradients of the loss for each parameter (weight) in the model are computed. This indicates how the changes being made to the weights are affecting the loss.
- Update weights: Apply an optimization algorithm to update the model’s weights, focusing on those in unfrozen layers. This step is where the model learns from the task-specific data, refining its predictions to become more accurate.
A tight feedback loop where you incessantly monitor the model’s validation performance guides you in preventing overfitting and determining when the model has learned enough. It gives you an indication of when to stop the training.
Read in detail all you must know about LLM evaluation
Evaluation and Iteration

After fine-tuning, assess the model’s performance on a separate validation dataset. This helps gauge how well the model generalizes to new data. You do this by running the model against the test set—data it hadn’t seen during training.
Here, you look at metrics appropriate to the task, like BLEU and ROUGE for translation or summarization, or even qualitative evaluations by human judges, ensuring the model is ready for real-life application and isn’t just regurgitating memorized examples.
If the model’s performance is not up to par, you may need to revisit the hyperparameters, adjust the training data, or further tweak the model’s architecture.
For medical LLM applications, it is this entire process that enables the model to grasp medical terminologies, understand patient queries, and even assist in diagnosing from text descriptions—tasks that require deep domain knowledge.
You can read the second part of the blog series here – RAG vs finetuning: Which is the best tool?
Key Takeaways
Hence, this provides a comprehensive introduction to RAG and fine-tuning, highlighting their roles in advancing the capabilities of large language models (LLMs). Some key points to take away from this discussion can be put down as:
- LLMs struggle with providing up-to-date information and excelling in specialized domains.
- RAG addresses these limitations by incorporating external information retrieval during response generation, ensuring informative and relevant answers.
- Fine-tuning refines pre-trained LLMs for specific tasks, enhancing their expertise and performance in those areas.
Do you want to learn more about RAG, fine-tuning, and other relevant concepts and their practical application within the field of LLMs? Register for our LLM bootcamp today and explore the magic of this technological advancement!