

Pre-trained large language models (LLMs) offer many capabilities but aren’t universal. When faced with a task beyond their abilities, fine-tuning LLMs become an option. This process involves retraining LLMs on new data. While it can be complex and costly, it’s a potent tool for organizations using LLMs. Understanding fine-tuning, even if not doing it yourself, aids in informed decision-making.
Large language models (LLMs) are pre-trained on massive datasets of text and code. This allows them to learn a wide range of tasks, such as text generation, translation, and question-answering. However, LLMs are often not well-suited for specific tasks without fine-tuning.
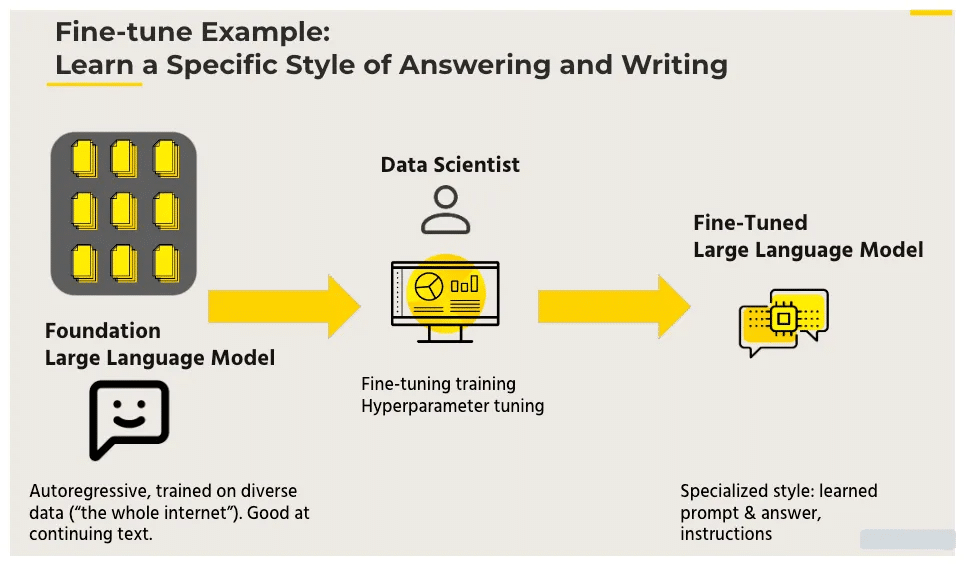
Fine-tuning LLM
Fine-tuning is the process of adjusting the parameters of an LLM to a specific task. This is done by training the model on a dataset of data that is relevant to the task. The amount of fine-tuning required depends on the complexity of the task and the size of the dataset.
There are a number of ways to fine-tune LLMs. One common approach is to use supervised learning. This involves providing the model with a dataset of labeled data, where each data point is a pair of input and output. The model learns to map the input to the output by minimizing a loss function.
Another approach to fine-tuning LLMs is to use reinforcement learning. This involves providing the model with a reward signal for generating outputs that are desired. The model learns to generate desired outputs by maximizing the reward signal.

Fine-Tuning Techniques for LLMs
Fine-tuning is the process of adjusting the parameters of an LLM to a specific task. This is done by training the model on a dataset of data that is relevant to the task. The amount of fine-tuning required depends on the complexity of the task and the size of the dataset. There are two main fine-tuning techniques for LLMs: repurposing and full fine-tuning.
1. Repurposing
Repurposing is a technique where you use an LLM for a task that is different from the task it was originally trained on. For example, you could use an LLM that was trained for text generation for sentiment analysis.
To repurpose an LLM, you first need to identify the features of the input data that are relevant to the task you want to perform. Then, you need to connect the LLM’s embedding layer to a classifier model that can learn to map these features to the desired output.
Repurposing is a less computationally expensive fine-tuning technique than full fine-tuning. However, it is also less likely to achieve the same level of performance.
| Technique | Description |
Computational Cost |
Performance |
|---|---|---|---|
| Repurposing | Use an LLM for a task that is different from the task it was originally trained on. | Less | Less |
| Full Fine-tuning | Train the entire LLM on a dataset of data that is relevant to the task you want to perform. | More | More |
2. Full Fine-Tuning
Full fine-tuning is a technique where you train the entire LLM on a dataset of data that is relevant to the task you want to perform. This is the most computationally expensive fine-tuning technique, but it is also the most likely to achieve the best performance.
To full fine-tune an LLM, you need to create a dataset of data that contains examples of the input and output for the task you want to perform. Then, you need to train the LLM on this dataset using a supervised learning algorithm.
The choice of fine-tuning technique depends on the specific task you want to perform and the resources you have available. If you are short on computational resources, you may want to consider repurposing. However, if you are looking for the best possible performance, you should full fine-tune the LLM.
Unsupervised vs Supervised Fine-Tuning LLMs
Large language models (LLMs) are pre-trained on massive datasets of text and code. This allows them to learn a wide range of tasks, such as text generation, translation, and question-answering. However, LLMs are often not well-suited for specific tasks without fine-tuning.
Fine-tuning is the process of adjusting the parameters of an LLM to a specific task. This is done by training the model on a dataset of data that is relevant to the task. The amount of fine-tuning required depends on the complexity of the task and the size of the dataset.
There are two main types of fine-tuning for LLMs: unsupervised and supervised.

Unsupervised Fine-Tuning
Unsupervised fine-tuning is a technique where you train the LLM on a dataset of data that does not contain any labels. This means that the model does not know what the correct output is for each input. Instead, the model learns to predict the next token in a sequence or to generate text that is similar to the text in the dataset.
Unsupervised fine-tuning is a less computationally expensive fine-tuning technique than supervised fine-tuning. However, it is also less likely to achieve the same level of performance.
Supervised Fine-Tuning
Supervised fine-tuning is a technique where you train the LLM on a dataset of data that contains labels. This means that the model knows what the correct output is for each input. The model learns to map the input to the output by minimizing a loss function.
Supervised fine-tuning is a more computationally expensive fine-tuning technique than unsupervised fine-tuning. However, it is also more likely to achieve the best performance.
The choice of fine-tuning technique depends on the specific task you want to perform and the resources you have available. If you are short on computational resources, you may want to consider unsupervised fine-tuning. However, if you are looking for the best possible performance, you should supervise fine-tuning the LLM.
Here is a table that summarizes the key differences between unsupervised and supervised fine-tuning:
| Technique | Description | Computational Cost | Performance |
|---|---|---|---|
| Unsupervised Fine-tuning | Train the LLM on a dataset of data that does not contain any labels. | Less | Less |
| Supervised Fine-tuning | Train the LLM on a dataset of data that contains labels. | More | More |
Reinforcement Learning from Human Feedback (RLHF) for LLMs
There are two main approaches to fine-tuning LLMs: supervised fine-tuning and reinforcement learning from human feedback (RLHF).
1. Supervised Fine-Tuning
Supervised fine-tuning is a technique where you train the LLM on a dataset of data that contains labels. This means that the model knows what the correct output is for each input. The model learns to map the input to the output by minimizing a loss function.
2. Reinforcement Learning from Human Feedback (RLHF)
RLHF is a technique where you use human feedback to fine-tune the LLM. The basic idea is that you give the LLM a prompt and it generates an output. Then, you ask a human to rate the output. The rating is used as a signal to fine-tune the LLM to generate higher-quality outputs.
RLHF is a more complex and expensive fine-tuning technique than supervised fine-tuning. However, it can be more effective for tasks that are difficult to define or for which there is not enough labeled data.
Revolutionize LLM with Llama 2 fine-tuning
Parameter-Efficient Fine-Tuning (PEFT)
PEFT is a set of techniques that try to reduce the number of parameters that need to be updated during fine-tuning. This can be done by using a smaller dataset, using a simpler model, or using a technique called low-rank adaptation (LoRA).
LoRA is a technique that uses a low-dimensional matrix to represent the space of the downstream task. This matrix is then fine-tuned instead of the entire LLM. This can significantly reduce the amount of computation required for fine-tuning.
PEFT is a promising approach for fine-tuning LLMs. It can make fine-tuning more affordable and efficient, which can make it more accessible to a wider range of users.
When Not to Use LLM Fine-Tuning
Large language models (LLMs) are pre-trained on massive datasets of text and code. This allows them to learn a wide range of tasks, such as text generation, translation, and question answering. However, LLM fine-tuning is not always necessary or desirable.
Here are some cases where you might not want to use LLM fine-tuning:
- The model is not available for fine-tuning. Some LLMs are only available through application programming interfaces (APIs) that do not allow fine-tuning.
- You don’t have enough data to fine-tune the model. Fine-tuning an LLM requires a large dataset of labeled data. If you don’t have enough data, you may not be able to achieve good results with fine-tuning.
- The data is constantly changing. If the data that the LLM is being used on is constantly changing, fine-tuning may not be able to keep up. This is especially true for tasks such as machine translation, where the vocabulary and grammar of the source language can change over time.

- The application is dynamic and context-sensitive. In some cases, the output of an LLM needs to be tailored to the specific context of the user or the situation. For example, a chatbot that is used in a customer service application would need to be able to understand the customer’s intent and respond accordingly. Fine-tuning an LLM for this type of application would be difficult, as it would require a large dataset of labeled data that captures the different contexts in which the chatbot would be used.
In these cases, you may want to consider using a different approach, such as:
- Using a smaller, less complex model. Smaller models are less computationally expensive to train and fine-tune, and they may be sufficient for some tasks.
- Using a transfer learning approach. Transfer learning is a technique where you use a model that has been trained on a different task to initialize a model for a new task. This can be a more efficient way to train a model for a new task, as it can help the model to learn faster.
- Using in-context learning or retrieval augmentation. In-context learning or retrieval augmentation is a technique where you provide the LLM with context during inference time. This can help the LLM to generate more accurate and relevant outputs.
Wrapping Up
In conclusion, fine-tuning LLMs is a powerful tool for tailoring these models to specific tasks. Understanding its nuances and options, including repurposing and full fine-tuning, helps optimize performance. The choice between supervised and unsupervised fine-tuning depends on resources and task complexity. Additionally, reinforcement learning from human feedback (RLHF) and parameter-efficient fine-tuning (PEFT) offer specialized approaches. While fine-tuning enhances LLMs, it’s not always necessary, especially if the model already fits the task. Careful consideration of when to use fine-tuning is essential in maximizing the efficiency and effectiveness of LLMs for specific applications.
