The development of generative AI relies on important machine-learning techniques in today’s technological advancement. It makes machine learning (ML) a critical component of data science where algorithms are statistically trained on data.
An ML model learns iteratively to make accurate predictions and take actions. It enables computer programs to perform tasks without depending on programming. Today’s recommendation engines are one of the most innovative products based on machine learning.
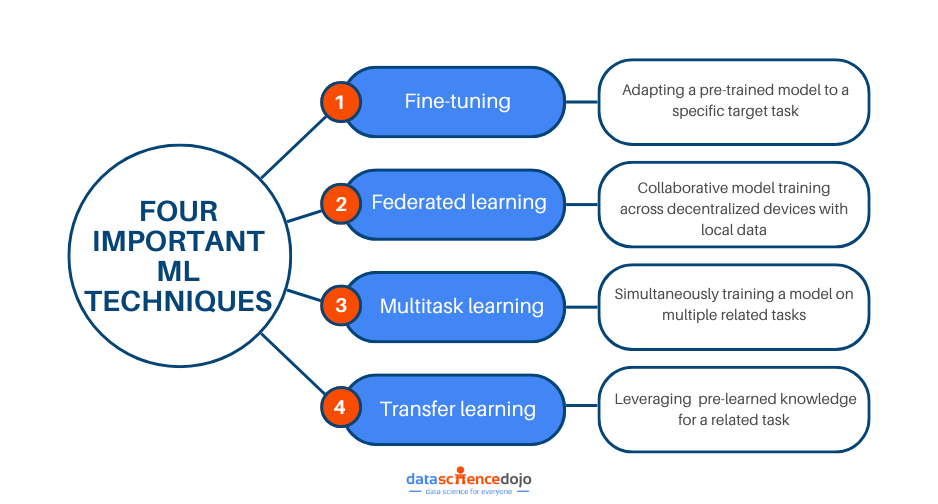
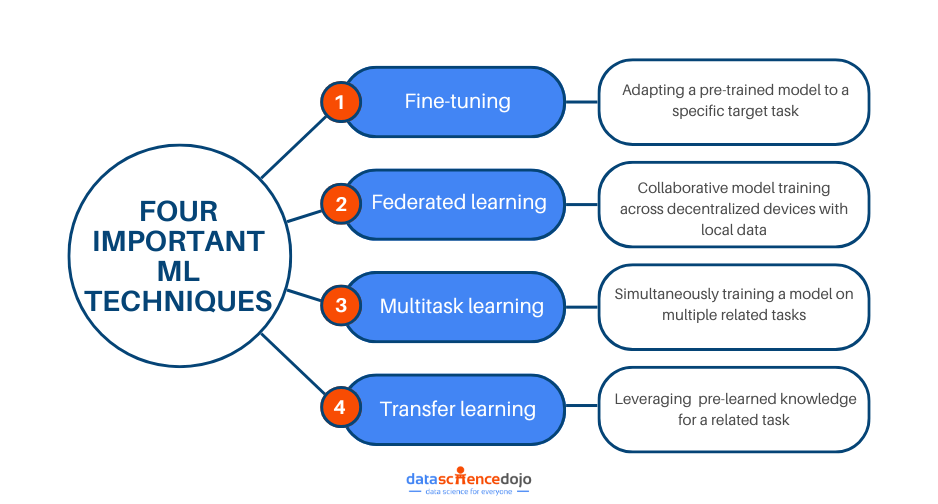
Exploring Important Machine-Learning Techniques
The realm of ML is defined by several learning methods, each aiming to improve the overall performance of a model. Technological advancement has resulted in highly sophisticated algorithms that require enhanced strategies for training models.
Let’s look at some of the critical and cutting-edge machine-learning techniques of today.
Transfer Learning
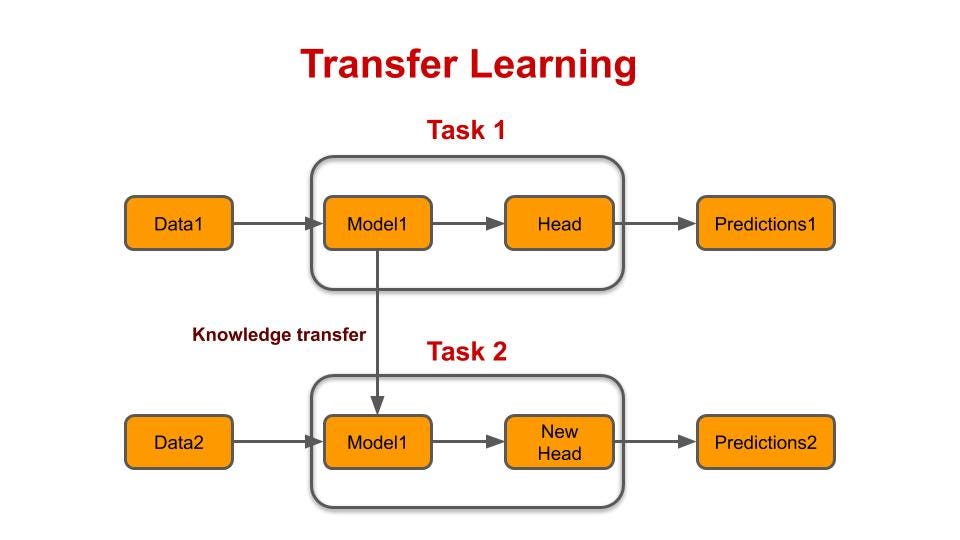
This technique is based on training a neural network on a base model and using the learning to apply the same model to a new task of interest. Here, the base model represents a task similar to that of interest, enabling the model to learn the major data patterns.
A visual understanding of transfer learning – Source: Medium
Why use transfer learning? It leverages knowledge gained from the first (source) task to improve the performance of the second (target) task. As a result, you can avoid training a model from scratch for related tasks. It is also a useful machine-learning technique when data for the task of interest is limited.
Pros: Transfer learning enhances the efficiency of computational resources as the model trains on target tasks with pre-learned patterns. Moreover, it offers improved model performance and allows the reusability of features in similar tasks.
Cons: This machine-learning technique is highly dependent on the similarity of two tasks. Hence, it cannot be used for extremely dissimilar and if applied to such tasks, it risks overfitting the source task during the model training phase.
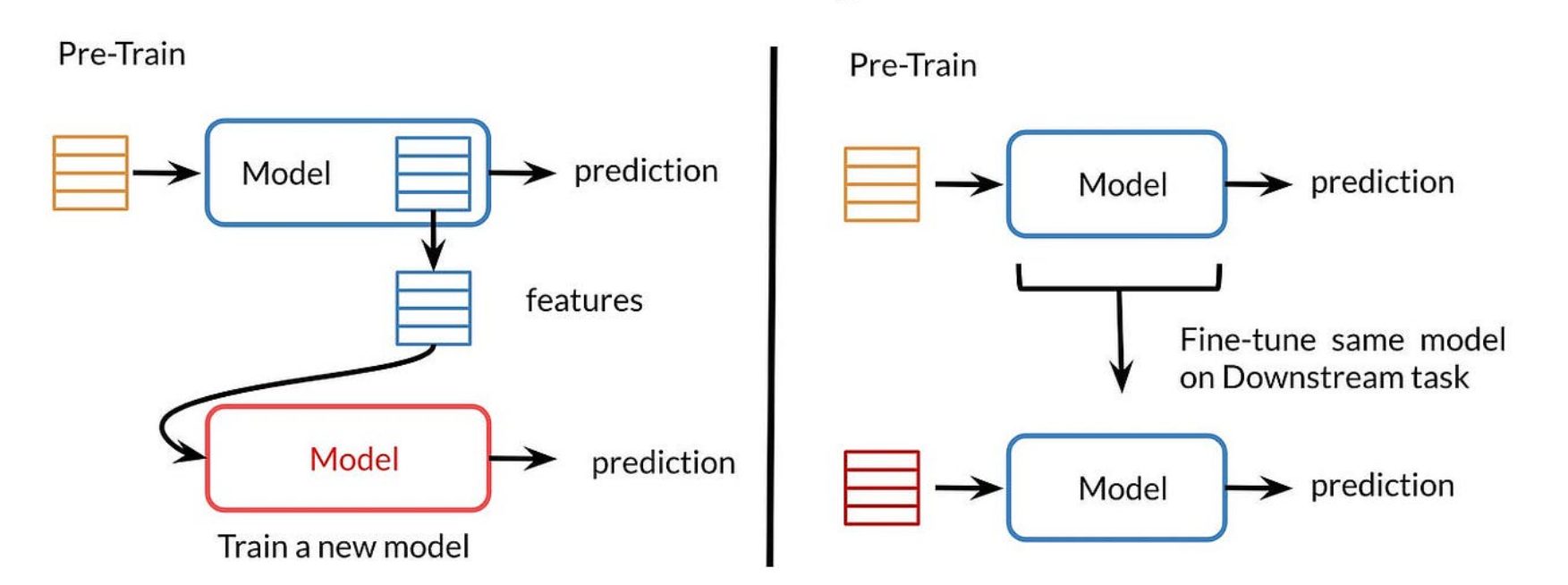
Fine-tuning is a machine-learning technique that aims to support the process of transfer learning. It updates the weights of a model trained on a source task to enhance its adaptability to the new target task. While it looks similar to transfer learning, it does not involve replacing all the layers of a pre-trained network.
Fine-tuning: Improving model performance in transfer learning – Source: Analytics Yogi
Why use fine-tuning? It is useful to enhance the adaptability of a pre-trained model on a new task. It enables the ML model to refine its parameters and learn task-specific patterns needed for improved performance on the target task.
Pros: This machine-learning technique is computationally efficient and offers improved adaptability to an ML model when dealing with transfer learning. The utilization of pre-learned features becomes beneficial when the target task has a limited amount of data.
Cons: Fine-tuning is sensitive to the choice of hyperparameters and you cannot find the optimal settings right away. It requires experimenting with the model training process to ensure optimal results. Moreover, it also has the risk of overfitting and limited adaptation in case of high dissimilarity in source and target tasks.
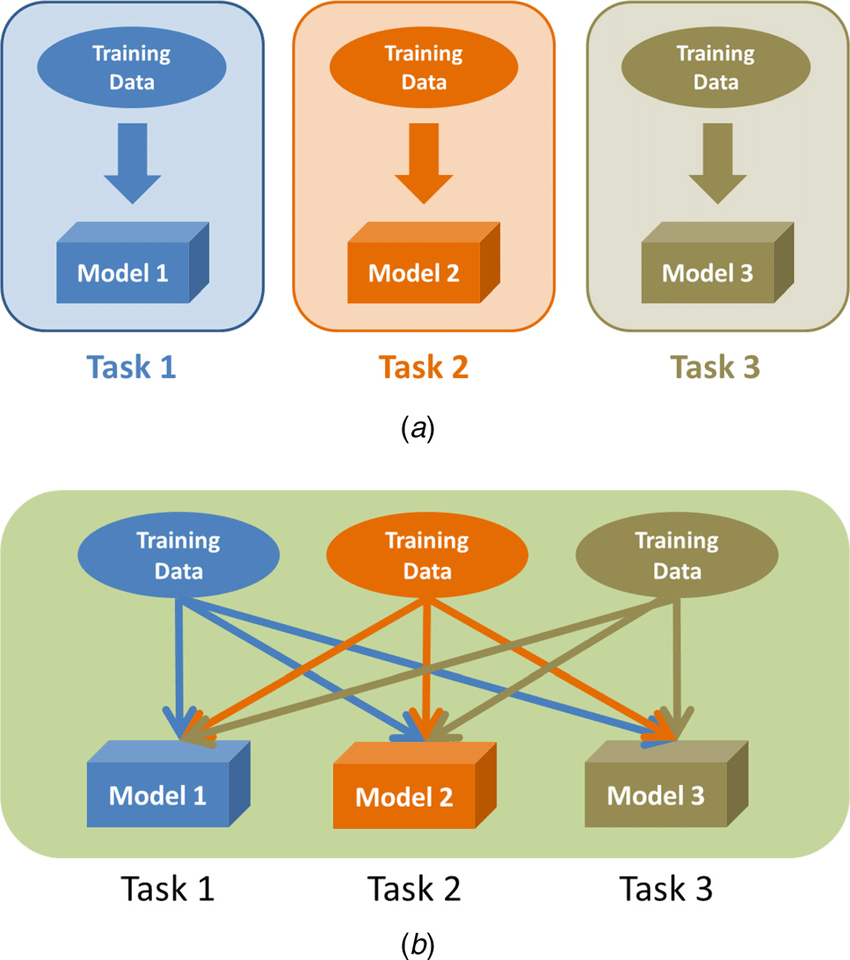
As the name indicates, the multitask machine-learning technique unlocks the power of simultaneity. Here, a model is trained to perform multiple tasks at the same time, sharing the knowledge across these tasks.
Why use multitask learning? It is useful in sharing common representations across multiple tasks, offering improved generalization. You can use it in cases where several related ML tasks can benefit from shared representations.
Pros: The enhanced generalization capability of models ensures the efficient use of data. Leveraging information results in improved model performance and regularization of training. Hence, it results in the creation of more robust training models.
Cons: The increased complexity of this machine-learning technique requires advanced architecture and informed weightage of different tasks. It also depends on the availability of large and diverse datasets for effective results. Moreover, the dissimilarity of tasks can result in unwanted interference in the model performance of other tasks.
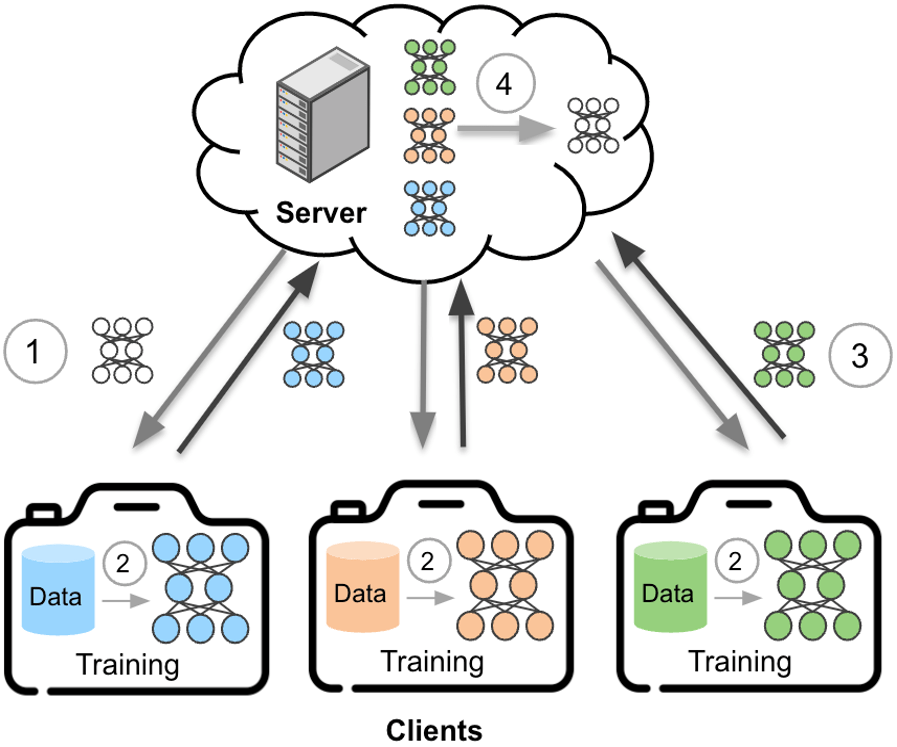
It is one of the most advanced machine-learning techniques that focuses on decentralized model training. As a result, the data remains on the user-end devices, and the model is trained locally. It is a revolutionized ML methodology that enhances collaboration among decentralized devices.
Federated learning: A revolutionary ML technique – Source: Sony AI
Why use federated learning? Federated learning is focused on locally trained models that do not require the sharing of raw data of end-user devices. It enables the sharing of key parameters through ML models while not requiring an exchange of sensitive data.
Pros: This machine-learning technique addresses the privacy concerns in ML training. The decentralized approach enables increased collaborative learning with reduced reliance on central servers for ML processes. Moreover, this method is energy-efficient as models are trained locally.
Cons: It cannot be implemented in resource-constrained environments due to large communication overhead. Moreover, it requires compatibility between local data and the global model at the central server, limiting its ability to handle heterogeneous datasets.
Factors determining the Best Machine-Learning Technique
While there are numerous machine-learning techniques available for model training today, it is crucial to make the right choice for your business. Below is a list of important factors that you must consider when selecting an ML method for your processes.
Context Matters!
Context refers to the type of problem or task at hand. The requirements and constraints of the model-training process is pivotal in choosing an ML technique. For instance, transfer learning and fine-tuning promote knowledge sharing, multitask learning promotes simultaneity, and federated learning supports decentralization.
ML processes require large datasets to develop high-performing models. Hence, the amount and complexity of data determine the choice of method. While transfer learning and multitask learning need large amounts of data, fine-tuning is suitable for a limited dataset. Moreover, data complexity determines knowledge sharing and feature interactions.
Computational Resources
Large neural networks and complex machine-learning techniques require large computational power. The availability of hardware resources and time required for training are important measures of consideration when making your choice of the right ML method.
Data Privacy Considerations
With rapidly advancing technological processes, ML and AI have emerged as major tools that heavily rely on available datasets. It makes data a highly important part of the process, leading to an increase in privacy concerns and protection of critical information. Hence, your choice of machine-learning technique must fulfill your data privacy demands.
In conclusion, it is important to understand the specifications of the four important machine-learning techniques before making a choice. Each method has its requirements and offers unique benefits. It is crucial to understand the dimensions of each technique in the light of key considerations discussed above. Hence, make an informed choice for your ML training processes.
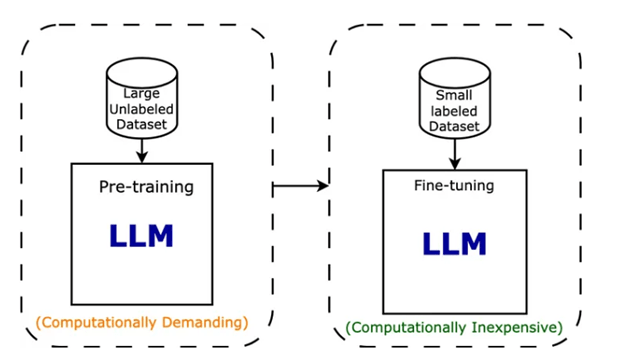
With the introduction of LLaMA v1, we witnessed a surge in customized models like Alpaca, Vicuna, and WizardLM. This surge motivated various businesses to launch their own foundational models, such as OpenLLaMA, Falcon, and XGen, with licenses suitable for commercial purposes. LLaMA 2, the latest release, now combines the strengths of both approaches, offering an efficient foundational model with a more permissive license.
In the first half of 2023, the software landscape underwent a significant transformation with the widespread adoption of APIs like OpenAI API to build infrastructures based on Large Language Models (LLMs). Libraries like LangChain and LlamaIndex played crucial roles in this evolution.
As we move into the latter part of the year, fine-tuning or instruction tuning of these models is becoming standard practice in the LLMOps workflow. This trend is motivated by several factors, including
Potential cost savings
The capacity to handle sensitive data
The opportunity to develop models that can outperform well-known models like ChatGPT and GPT-4 in specific tasks.
Fine-Tuning:
Fine-tuning methods refer to various techniques used to enhance the performance of a pre-trained model by adapting it to a specific task or domain. These methods are valuable for optimizing a model’s weights and parameters to excel in the target task. Here are different fine-tuning methods:
Supervised Fine-Tuning: This method involves further training a pre-trained language model (LLM) on a specific downstream task using labeled data. The model’s parameters are updated to excel in this task, such as text classification, named entity recognition, or sentiment analysis.
Transfer Learning: Transfer learning involves repurposing a pre-trained model’s architecture and weights for a new task or domain. Typically, the model is initially trained on a broad dataset and is then fine-tuned to adapt to specific tasks or domains, making it an efficient approach.
Sequential Fine-tuning: Sequential fine-tuning entails the gradual adaptation of a pre-trained model on multiple related tasks or domains in succession. This sequential learning helps the model capture intricate language patterns across various tasks, leading to improved generalization and performance.
Task-specific Fine-tuning: Task-specific fine-tuning is a method where the pre-trained model undergoes further training on a dedicated dataset for a particular task or domain. While it demands more data and time than transfer learning, it can yield higher performance tailored to the specific task.
Multi-task Learning: Multi-task learning involves fine-tuning the pre-trained model on several tasks simultaneously. This strategy enables the model to learn and leverage common features and representations across different tasks, ultimately enhancing its ability to generalize and perform well.
Adapter Training: Adapter training entails training lightweight modules that are integrated into the pre-trained model. These adapters allow for fine-tuning on specific tasks without interfering with the original model’s performance on other tasks. This approach maintains efficiency while adapting to task-specific requirements.
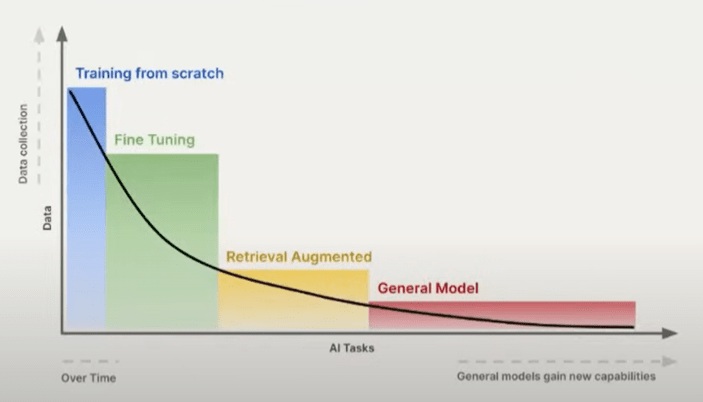
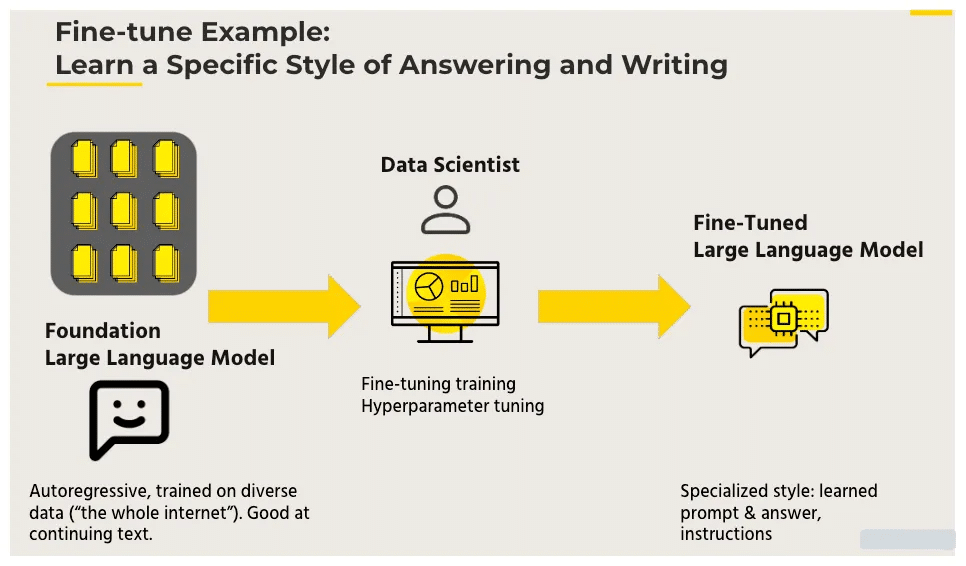
Why Fine-Tune LLM?
Source: DeepLearningAI
The figure discusses the allocation of AI tasks within organizations, taking into account the amount of available data. On the left side of the spectrum, having a substantial amount of data allows organizations to train their own models from scratch, albeit at a high cost.
Alternatively, if an organization possesses a moderate amount of data, it can fine-tune pre-existing models to achieve excellent performance. For those with limited data, the recommended approach is in-context learning, specifically through techniques like retrieval augmented generation using general models.
However, our focus will be on the fine-tuning aspect, as it offers a favorable balance between accuracy, performance, and speed compared to larger, more general models.
Source: Intuitive Tutorials
Why LLaMA 2 Fine Tuning?
Before we dive into the detailed guide, let’s take a quick look at the benefits of Llama 2.
Diverse range: Llama 2 comes in various sizes, from 7 billion to a massive 70 billion parameters. It shares a similar architecture with Llama 1 but boasts improved capabilities.
Extensive training ata: This model has been trained on a massive dataset of 2 trillion tokens, demonstrating its vast exposure to a wide range of information.
Enhanced context: With an extended context length of 4,000 tokens, the model can better understand and generate extensive content.
Grouped query attention (GQA): GQA has been introduced to enhance inference scalability, making attention calculations faster by storing previous token pair information.
Performance excellence: Llama 2 models consistently outperform their predecessors, particularly the Llama 2 70B version. They excel in various benchmarks, competing strongly with models like Llama 1 65B and even Falcon models.
Open source vs. closed source LLMs: When compared to models like GPT-3.5 or PaLM (540B), Llama 2 70B demonstrates impressive performance. While there may be a slight gap in certain benchmarks when compared to GPT-4 and PaLM-2, the model’s potential is evident.
Parameter Efficient Fine-Tuning (PEFT)
Parameter Efficient Fine-Tuning involves adapting pre-trained models to new tasks while making minimal changes to the model’s parameters. This is especially important for large neural network models like BERT, GPT, and similar ones. Let’s delve into why PEFT is so significant:
Reduced overfitting: Limited datasets can be problematic. Making too many parameter adjustments can lead to model overfitting. PEFT allows us to strike a balance between the model’s flexibility and tailoring it to new tasks.
Faster training: Making fewer parameter changes results in fewer computations, which in turn leads to faster training sessions.
Resource efficiency: Training deep neural networks requires substantial computational resources. PEFT minimizes the computational and memory demands, making it more practical to deploy in resource-constrained environments.
Knowledge preservation: Extensive pretraining on diverse datasets equips models with valuable general knowledge. PEFT ensures that this wealth of knowledge is retained when adapting the model to new tasks.
PEFT Technique
The most popular PEFT technique is LoRA. Let’s see what it offers:
LoRA
LoRA, or Low-Rank Adaptation, represents a groundbreaking advancement in the realm of large language models. At the beginning of the year, these models seemed accessible only to wealthy companies. However, LoRA has changed the landscape.
LoRA has made the use of large language models accessible to a wider audience. Its low-rank adaptation approach has significantly reduced the number of trainable parameters by up to 10,000 times. This results in:
A threefold reduction in GPU requirements, which is typically a major bottleneck.
Comparable, if not superior, performance even without fine-tuning the entire model.
In traditional fine-tuning, we modify the existing weights of a pre-trained model using new examples. Conventionally, this required a matrix of the same size. However, by employing creative methods and the concept of rank factorization, a matrix can be split into two smaller matrices. When multiplied together, they approximate the original matrix.
To illustrate, imagine a 1000×1000 matrix with 1,000,000 parameters. Through rank factorization, if the rank is, for instance, five, we could have two matrices, each sized 1000×5. When combined, they represent just 10,000 parameters, resulting in a significant reduction.
In recent days, researchers have introduced an extension of LoRA known as QLoRA.
QLoRA
QLoRA is an extension of LoRA that further introduces quantization to enhance parameter efficiency during fine-tuning. It builds on the principles of LoRA while introducing 4-bit NormalFloat (NF4) quantization and Double Quantization techniques.
Environment Setup
About Dataset
The dataset has undergone special processing to ensure a seamless match with Llama 2’s prompt format, making it ready for training without the need for additional modifications.
Since the data has already been adapted to Llama 2’s prompt format, it can be directly employed to tune the model for particular applications.
Configuring the Model and Tokenizer
We start by specifying the pre-trained Llama 2 model and prepare for an improved version called “llama-2-7b-enhanced”. We load the tokenizer and make slight adjustments to ensure compatibility with half-precision floating-point numbers (fp16) operations. Working with fp16 can offer various advantages, including reduced memory usage and faster model training. However, it’s important to note that not all operations work seamlessly with this lower precision format, and tokenization, a crucial step in preparing text data for model training, is one of them.
Next, we load the pre-trained Llama 2 model with our quantization configurations. We then deactivate caching and configure a pretraining temperature parameter.
In order to shrink the model’s size and boost inference speed, we employ 4-bit quantization provided by the BitsAndBytesConfig. Quantization involves representing the model’s weights in a way that consumes less memory.
The configuration mentioned here uses the ‘nf4’ type for quantization. You can experiment with different quantization types to explore potential performance variations.
Quantization Configuration
In the context of training a machine learning model using Low-Rank Adaptation (LoRA), several parameters play a significant role. Here’s a simplified explanation of each:
Parameters Specific to LoRA:
Dropout Rate (lora_dropout): This parameter represents the probability that the output of each neuron is set to zero during training. It is used to prevent overfitting, which occurs when the model becomes too tailored to the training data.
Rank (r): Rank measures how the original weight matrices are decomposed into simpler, smaller matrices. This decomposition reduces computational demands and memory usage. Lower ranks can make the model faster but may impact its performance. The original LoRA paper suggests starting with a rank of 8, but for QLoRA, a rank of 64 is recommended.
Lora_alpha: This parameter controls the scaling of the low-rank approximation. It’s like finding the right balance between the original model and the low-rank approximation. Higher values can make the approximation more influential during the fine-tuning process, which can affect both performance and computational cost.
By adjusting these parameters, particularly lora_alpha and r, you can observe how the model’s performance and resource utilization change. This allows you to fine-tune the model for your specific task and find the optimal configuration.
Fine-tuning LLaMA 2 unlocks its full potential, making it more efficient and adaptable for specific tasks. By leveraging techniques like Full Fine-Tuning, QLoRA, and PEFT, users can optimize model performance while balancing computational costs. Whether you’re enhancing language models for research, business applications, or AI-driven solutions, choosing the right fine-tuning approach is crucial.
As AI continues to evolve, efficient model customization will play a key role in advancing NLP capabilities. By understanding and implementing these fine-tuning techniques, data scientists and AI practitioners can harness the true power of LLaMA 2 for a wide range of real-world applications.
Revolutionize LLM with Llama 2 Fine-Tuning
With the introduction of LLaMA v1, we witnessed a surge in customized models like Alpaca, Vicuna, and WizardLM. This surge motivated various businesses to launch their own foundational models, such as OpenLLaMA, Falcon, and XGen, with licenses suitable for commercial purposes. LLaMA 2, the latest release, now combines the strengths of both approaches, offering an efficient foundational model with a more permissive license.
In the first half of 2023, the software landscape underwent a significant transformation with the widespread adoption of APIs like OpenAI API to build infrastructures based on Large Language Models (LLMs). Libraries like LangChain and LlamaIndex played crucial roles in this evolution.
As we move into the latter part of the year, fine-tuning or instruction tuning of these models is becoming a standard practice in the LLMOps workflow. This trend is motivated by several factors, including
Potential cost savings
The capacity to handle sensitive data
The opportunity to develop models that can outperform well-known models like ChatGPT and GPT-4 in specific tasks.
Fine-Tuning:
Fine-tuning methods refer to various techniques used to enhance the performance of a pre-trained model by adapting it to a specific task or domain. These methods are valuable for optimizing a model’s weights and parameters to excel in the target task. Here are different fine-tuning methods:
Supervised Fine-Tuning: This method involves further training a pre-trained language model (LLM) on a specific downstream task using labeled data. The model’s parameters are updated to excel in this task, such as text classification, named entity recognition, or sentiment analysis.
Transfer Learning: Transfer learning involves repurposing a pre-trained model’s architecture and weights for a new task or domain. Typically, the model is initially trained on a broad dataset and is then fine-tuned to adapt to specific tasks or domains, making it an efficient approach.
Sequential Fine-tuning: Sequential fine-tuning entails the gradual adaptation of a pre-trained model on multiple related tasks or domains in succession. This sequential learning helps the model capture intricate language patterns across various tasks, leading to improved generalization and performance.
Task-specific Fine-tuning: Task-specific fine-tuning is a method where the pre-trained model undergoes further training on a dedicated dataset for a particular task or domain. While it demands more data and time than transfer learning, it can yield higher performance tailored to the specific task.
Multi-task Learning: Multi-task learning involves fine-tuning the pre-trained model on several tasks simultaneously. This strategy enables the model to learn and leverage common features and representations across different tasks, ultimately enhancing its ability to generalize and perform well.
Adapter Training: Adapter training entails training lightweight modules that are integrated into the pre-trained model. These adapters allow for fine-tuning on specific tasks without interfering with the original model’s performance on other tasks. This approach maintains efficiency while adapting to task-specific requirements.
The figure discusses the allocation of AI tasks within organizations, taking into account the amount of available data. On the left side of the spectrum, having a substantial amount of data allows organizations to train their own models from scratch, albeit at a high cost. Alternatively, if an organization possesses a moderate amount of data, it can fine-tune pre-existing models to achieve excellent performance. For those with limited data, the recommended approach is in-context learning, specifically through techniques like retrieval augmented generation using general models. However, our focus will be on the fine-tuning aspect, as it offers a favorable balance between accuracy, performance, and speed compared to larger, more general models.
Before we dive into the detailed guide, let’s take a quick look at the benefits of Llama 2.
Diverse Range: Llama 2 comes in various sizes, from 7 billion to a massive 70 billion parameters. It shares a similar architecture with Llama 1 but boasts improved capabilities.
Extensive Training Data: This model has been trained on a massive dataset of 2 trillion tokens, demonstrating its vast exposure to a wide range of information.
Enhanced Context: With an extended context length of 4,000 tokens, the model can better understand and generate extensive content.
Grouped Query Attention (GQA): GQA has been introduced to enhance inference scalability, making attention calculations faster by storing previous token pair information.
Performance Excellence: Llama 2 models consistently outperform their predecessors, particularly the Llama 2 70B version. They excel in various benchmarks, competing strongly with models like Llama 1 65B and even Falcon models.
Open Source vs. Closed Source LLMs: When compared to models like GPT-3.5 or PaLM (540B), Llama 2 70B demonstrates impressive performance. While there may be a slight gap in certain benchmarks when compared to GPT-4 and PaLM-2, the model’s potential is evident.
Parameter Efficient Fine-Tuning (PEFT)
Parameter Efficient Fine-Tuning involves adapting pre-trained models to new tasks while making minimal changes to the model’s parameters. This is especially important for large neural network models like BERT, GPT, and similar ones. Let’s delve into why PEFT is so significant:
Reduced Overfitting: Limited datasets can be problematic. Making too many parameter adjustments can lead to the model overfitting. PEFT allows us to strike a balance between the model’s flexibility and tailoring it to new tasks.
Faster Training: Making fewer parameter changes results in fewer computations, which in turn leads to faster training sessions.
Resource Efficiency: Training deep neural networks requires substantial computational resources. PEFT minimizes the computational and memory demands, making it more practical to deploy in resource-constrained environments.
Knowledge Preservation: Extensive pretraining on diverse datasets equips models with valuable general knowledge. PEFT ensures that this wealth of knowledge is retained when adapting the model to new tasks.
PEFT Technique
The most popular PEFT technique is LoRA. Let’s see what it offers:
LoRA
LoRA, or Low Rank Adaptation, represents a groundbreaking advancement in the realm of large language models. At the beginning of the year, these models seemed accessible only to wealthy companies. However, LoRA has changed the landscape.
LoRA has made the use of large language models accessible to a wider audience. Its low-rank adaptation approach has significantly reduced the number of trainable parameters by up to 10,000 times. This results in:
A threefold reduction in GPU requirements, which is typically a major bottleneck.
Comparable, if not superior, performance even without fine-tuning the entire model.
In traditional fine-tuning, we modify the existing weights of a pre-trained model using new examples. Conventionally, this required a matrix of the same size. However, by employing creative methods and the concept of rank factorization, a matrix can be split into two smaller matrices. When multiplied together, they approximate the original matrix.
To illustrate, imagine a 1000×1000 matrix with 1,000,000 parameters. Through rank factorization, if the rank is, for instance, five, we could have two matrices, each sized 1000×5. When combined, they represent just 10,000 parameters, resulting in a significant reduction.
In recent days, researchers have introduced an extension of LoRA known as QLoRA.
QLoRA
QLoRA is an extension of LoRA that further introduces quantization to enhance parameter efficiency during fine-tuning. It builds on the principles of LoRA while introducing 4-bit NormalFloat (NF4) quantization and Double Quantization techniques.
The dataset has undergone special processing to ensure a seamless match with Llama 2’s prompt format, making it ready for training without the need for additional modifications.
Since the data has already been adapted to Llama 2’s prompt format, it can be directly employed to tune the model for particular applications.
# Dataset
data_name = “m0hammadjaan/Dummy-NED-Positions”# Your dataset here
We start by specifying the pre-trained Llama 2 model and prepare for an improved version called “llama-2-7b-enhanced“. We load the tokenizer and make slight adjustments to ensure compatibility with half-precision floating-point numbers (fp16) operations. Working with fp16 can offer various advantages, including reduced memory usage and faster model training. However, it’s important to note that not all operations work seamlessly with this lower precision format, and tokenization, a crucial step in preparing text data for model training, is one of them.
Next, we load the pre-trained Llama 2 model with our quantization configurations. We then deactivate caching and configure a pretraining temperature parameter.
In order to shrink the model’s size and boost inference speed, we employ 4-bit quantization provided by the BitsAndBytesConfig. Quantization involves representing the model’s weights in a way that consumes less memory.
The configuration mentioned here uses the ‘nf4‘ type for quantization. You can experiment with different quantization types to explore potential performance variations.
In the context of training a machine learning model using Low-Rank Adaptation (LoRA), several parameters play a significant role. Here’s a simplified explanation of each:
Parameters Specific to LoRA:
Dropout Rate (lora_dropout): This parameter represents the probability that the output of each neuron is set to zero during training. It is used to prevent overfitting, which occurs when the model becomes too tailored to the training data.
Rank (r): Rank measures how the original weight matrices are decomposed into simpler, smaller matrices. This decomposition reduces computational demands and memory usage. Lower ranks can make the model faster but may impact its performance. The original LoRA paper suggests starting with a rank of 8, but for QLoRA, a rank of 64 is recommended.
Lora_alpha: This parameter controls the scaling of the low-rank approximation. It’s like finding the right balance between the original model and the low-rank approximation. Higher values can make the approximation more influential during the fine-tuning process, which can affect both performance and computational cost.
By adjusting these parameters, particularly lora_alpha and r, you can observe how the model’s performance and resource utilization change. This allows you to fine-tune the model for your specific task and find the optimal configuration.
# Recommended if you are using free google cloab GPU else you’ll get CUDA out of memory
os.environ[“PYTORCH_CUDA_ALLOC_CONF”] = “400”
# LoRA Config
peft_parameters = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=8,
bias=“none”,
task_type=“CAUSAL_LM”
)
# Training Params
train_params = TrainingArguments(
output_dir=“./results_modified”, # Output directory for saving model checkpoints and logs
num_train_epochs=1, # Number of training epochs
per_device_train_batch_size=4, # Batch size per device during training
gradient_accumulation_steps=1, # Number of gradient accumulation steps
I asked both the fine-tuned and unfine-tuned models of LLaMA 2 about a university, and the fine-tuned model provided the correct result. The unfine-tuned model does not know about the query therefore it hallucinated the response.
Unfine-tuned
Fine-tuned
Revolutionize LLM with Llama 2 Fine-Tuning
With the introduction of LLaMA v1, we witnessed a surge in customized models like Alpaca, Vicuna, and WizardLM. This surge motivated various businesses to launch their own foundational models, such as OpenLLaMA, Falcon, and XGen, with licenses suitable for commercial purposes. LLaMA 2, the latest release, now combines the strengths of both approaches, offering an efficient foundational model with a more permissive license.
In the first half of 2023, the software landscape underwent a significant transformation with the widespread adoption of APIs like OpenAI API to build infrastructures based on Large Language Models (LLMs). Libraries like LangChain and LlamaIndex played crucial roles in this evolution.
As we move into the latter part of the year, fine-tuning or instruction tuning of these models is becoming a standard practice in the LLMOps workflow. This trend is motivated by several factors, including
Potential cost savings
The capacity to handle sensitive data
The opportunity to develop models that can outperform well-known models like ChatGPT and GPT-4 in specific tasks.
Fine-Tuning:
Fine-tuning methods refer to various techniques used to enhance the performance of a pre-trained model by adapting it to a specific task or domain. These methods are valuable for optimizing a model’s weights and parameters to excel in the target task. Here are different fine-tuning methods:
Supervised Fine-Tuning: This method involves further training a pre-trained language model (LLM) on a specific downstream task using labeled data. The model’s parameters are updated to excel in this task, such as text classification, named entity recognition, or sentiment analysis.
Transfer Learning: Transfer learning involves repurposing a pre-trained model’s architecture and weights for a new task or domain. Typically, the model is initially trained on a broad dataset and is then fine-tuned to adapt to specific tasks or domains, making it an efficient approach.
Sequential Fine-tuning: Sequential fine-tuning entails the gradual adaptation of a pre-trained model on multiple related tasks or domains in succession. This sequential learning helps the model capture intricate language patterns across various tasks, leading to improved generalization and performance.
Task-specific Fine-tuning: Task-specific fine-tuning is a method where the pre-trained model undergoes further training on a dedicated dataset for a particular task or domain. While it demands more data and time than transfer learning, it can yield higher performance tailored to the specific task.
Multi-task Learning: Multi-task learning involves fine-tuning the pre-trained model on several tasks simultaneously. This strategy enables the model to learn and leverage common features and representations across different tasks, ultimately enhancing its ability to generalize and perform well.
Adapter Training: Adapter training entails training lightweight modules that are integrated into the pre-trained model. These adapters allow for fine-tuning on specific tasks without interfering with the original model’s performance on other tasks. This approach maintains efficiency while adapting to task-specific requirements.
The figure discusses the allocation of AI tasks within organizations, taking into account the amount of available data. On the left side of the spectrum, having a substantial amount of data allows organizations to train their own models from scratch, albeit at a high cost. Alternatively, if an organization possesses a moderate amount of data, it can fine-tune pre-existing models to achieve excellent performance. For those with limited data, the recommended approach is in-context learning, specifically through techniques like retrieval augmented generation using general models. However, our focus will be on the fine-tuning aspect, as it offers a favorable balance between accuracy, performance, and speed compared to larger, more general models.
Before we dive into the detailed guide, let’s take a quick look at the benefits of Llama 2.
Diverse Range: Llama 2 comes in various sizes, from 7 billion to a massive 70 billion parameters. It shares a similar architecture with Llama 1 but boasts improved capabilities.
Extensive Training Data: This model has been trained on a massive dataset of 2 trillion tokens, demonstrating its vast exposure to a wide range of information.
Enhanced Context: With an extended context length of 4,000 tokens, the model can better understand and generate extensive content.
Grouped Query Attention (GQA): GQA has been introduced to enhance inference scalability, making attention calculations faster by storing previous token pair information.
Performance Excellence: Llama 2 models consistently outperform their predecessors, particularly the Llama 2 70B version. They excel in various benchmarks, competing strongly with models like Llama 1 65B and even Falcon models.
Open Source vs. Closed Source LLMs: When compared to models like GPT-3.5 or PaLM (540B), Llama 2 70B demonstrates impressive performance. While there may be a slight gap in certain benchmarks when compared to GPT-4 and PaLM-2, the model’s potential is evident.
Parameter Efficient Fine-Tuning (PEFT)
Parameter Efficient Fine-Tuning involves adapting pre-trained models to new tasks while making minimal changes to the model’s parameters. This is especially important for large neural network models like BERT, GPT, and similar ones. Let’s delve into why PEFT is so significant:
Reduced Overfitting: Limited datasets can be problematic. Making too many parameter adjustments can lead to the model overfitting. PEFT allows us to strike a balance between the model’s flexibility and tailoring it to new tasks.
Faster Training: Making fewer parameter changes results in fewer computations, which in turn leads to faster training sessions.
Resource Efficiency: Training deep neural networks requires substantial computational resources. PEFT minimizes the computational and memory demands, making it more practical to deploy in resource-constrained environments.
Knowledge Preservation: Extensive pretraining on diverse datasets equips models with valuable general knowledge. PEFT ensures that this wealth of knowledge is retained when adapting the model to new tasks.
PEFT Technique
The most popular PEFT technique is LoRA. Let’s see what it offers:
LoRA
LoRA, or Low Rank Adaptation, represents a groundbreaking advancement in the realm of large language models. At the beginning of the year, these models seemed accessible only to wealthy companies. However, LoRA has changed the landscape.
LoRA has made the use of large language models accessible to a wider audience. Its low-rank adaptation approach has significantly reduced the number of trainable parameters by up to 10,000 times. This results in:
A threefold reduction in GPU requirements, which is typically a major bottleneck.
Comparable, if not superior, performance even without fine-tuning the entire model.
In traditional fine-tuning, we modify the existing weights of a pre-trained model using new examples. Conventionally, this required a matrix of the same size. However, by employing creative methods and the concept of rank factorization, a matrix can be split into two smaller matrices. When multiplied together, they approximate the original matrix.
To illustrate, imagine a 1000×1000 matrix with 1,000,000 parameters. Through rank factorization, if the rank is, for instance, five, we could have two matrices, each sized 1000×5. When combined, they represent just 10,000 parameters, resulting in a significant reduction.
In recent days, researchers have introduced an extension of LoRA known as QLoRA.
QLoRA
QLoRA is an extension of LoRA that further introduces quantization to enhance parameter efficiency during fine-tuning. It builds on the principles of LoRA while introducing 4-bit NormalFloat (NF4) quantization and Double Quantization techniques.
The dataset has undergone special processing to ensure a seamless match with Llama 2’s prompt format, making it ready for training without the need for additional modifications.
Since the data has already been adapted to Llama 2’s prompt format, it can be directly employed to tune the model for particular applications.
# Dataset
data_name = “m0hammadjaan/Dummy-NED-Positions”# Your dataset here
We start by specifying the pre-trained Llama 2 model and prepare for an improved version called “llama-2-7b-enhanced“. We load the tokenizer and make slight adjustments to ensure compatibility with half-precision floating-point numbers (fp16) operations. Working with fp16 can offer various advantages, including reduced memory usage and faster model training. However, it’s important to note that not all operations work seamlessly with this lower precision format, and tokenization, a crucial step in preparing text data for model training, is one of them.
Next, we load the pre-trained Llama 2 model with our quantization configurations. We then deactivate caching and configure a pretraining temperature parameter.
In order to shrink the model’s size and boost inference speed, we employ 4-bit quantization provided by the BitsAndBytesConfig. Quantization involves representing the model’s weights in a way that consumes less memory.
The configuration mentioned here uses the ‘nf4‘ type for quantization. You can experiment with different quantization types to explore potential performance variations.
In the context of training a machine learning model using Low-Rank Adaptation (LoRA), several parameters play a significant role. Here’s a simplified explanation of each:
Parameters Specific to LoRA:
Dropout Rate (lora_dropout): This parameter represents the probability that the output of each neuron is set to zero during training. It is used to prevent overfitting, which occurs when the model becomes too tailored to the training data.
Rank (r): Rank measures how the original weight matrices are decomposed into simpler, smaller matrices. This decomposition reduces computational demands and memory usage. Lower ranks can make the model faster but may impact its performance. The original LoRA paper suggests starting with a rank of 8, but for QLoRA, a rank of 64 is recommended.
Lora_alpha: This parameter controls the scaling of the low-rank approximation. It’s like finding the right balance between the original model and the low-rank approximation. Higher values can make the approximation more influential during the fine-tuning process, which can affect both performance and computational cost.
By adjusting these parameters, particularly lora_alpha and r, you can observe how the model’s performance and resource utilization change. This allows you to fine-tune the model for your specific task and find the optimal configuration.
# Recommended if you are using free google cloab GPU else you’ll get CUDA out of memory
os.environ[“PYTORCH_CUDA_ALLOC_CONF”] = “400”
# LoRA Config
peft_parameters = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=8,
bias=“none”,
task_type=“CAUSAL_LM”
)
# Training Params
train_params = TrainingArguments(
output_dir=“./results_modified”, # Output directory for saving model checkpoints and logs
num_train_epochs=1, # Number of training epochs
per_device_train_batch_size=4, # Batch size per device during training
gradient_accumulation_steps=1, # Number of gradient accumulation steps
I asked both the fine-tuned and unfine-tuned models of LLaMA 2 about a university, and the fine-tuned model provided the correct result. The unfine-tuned model does not know about the query therefore it hallucinated the response.
Unfine-tuned
Fine-tuned
Revolutionize LLM with Llama 2 Fine-Tuning
With the introduction of LLaMA v1, we witnessed a surge in customized models like Alpaca, Vicuna, and WizardLM. This surge motivated various businesses to launch their own foundational models, such as OpenLLaMA, Falcon, and XGen, with licenses suitable for commercial purposes. LLaMA 2, the latest release, now combines the strengths of both approaches, offering an efficient foundational model with a more permissive license.
In the first half of 2023, the software landscape underwent a significant transformation with the widespread adoption of APIs like OpenAI API to build infrastructures based on Large Language Models (LLMs). Libraries like LangChain and LlamaIndex played crucial roles in this evolution.
As we move into the latter part of the year, fine-tuning or instruction tuning of these models is becoming a standard practice in the LLMOps workflow. This trend is motivated by several factors, including
Potential cost savings
The capacity to handle sensitive data
The opportunity to develop models that can outperform well-known models like ChatGPT and GPT-4 in specific tasks.
Fine-Tuning:
Fine-tuning methods refer to various techniques used to enhance the performance of a pre-trained model by adapting it to a specific task or domain. These methods are valuable for optimizing a model’s weights and parameters to excel in the target task. Here are different fine-tuning methods:
Supervised Fine-Tuning: This method involves further training a pre-trained language model (LLM) on a specific downstream task using labeled data. The model’s parameters are updated to excel in this task, such as text classification, named entity recognition, or sentiment analysis.
Transfer Learning: Transfer learning involves repurposing a pre-trained model’s architecture and weights for a new task or domain. Typically, the model is initially trained on a broad dataset and is then fine-tuned to adapt to specific tasks or domains, making it an efficient approach.
Sequential Fine-tuning: Sequential fine-tuning entails the gradual adaptation of a pre-trained model on multiple related tasks or domains in succession. This sequential learning helps the model capture intricate language patterns across various tasks, leading to improved generalization and performance.
Task-specific Fine-tuning: Task-specific fine-tuning is a method where the pre-trained model undergoes further training on a dedicated dataset for a particular task or domain. While it demands more data and time than transfer learning, it can yield higher performance tailored to the specific task.
Multi-task Learning: Multi-task learning involves fine-tuning the pre-trained model on several tasks simultaneously. This strategy enables the model to learn and leverage common features and representations across different tasks, ultimately enhancing its ability to generalize and perform well.
Adapter Training: Adapter training entails training lightweight modules that are integrated into the pre-trained model. These adapters allow for fine-tuning on specific tasks without interfering with the original model’s performance on other tasks. This approach maintains efficiency while adapting to task-specific requirements.
The figure discusses the allocation of AI tasks within organizations, taking into account the amount of available data. On the left side of the spectrum, having a substantial amount of data allows organizations to train their own models from scratch, albeit at a high cost. Alternatively, if an organization possesses a moderate amount of data, it can fine-tune pre-existing models to achieve excellent performance. For those with limited data, the recommended approach is in-context learning, specifically through techniques like retrieval augmented generation using general models. However, our focus will be on the fine-tuning aspect, as it offers a favorable balance between accuracy, performance, and speed compared to larger, more general models.
Before we dive into the detailed guide, let’s take a quick look at the benefits of Llama 2.
Diverse Range: Llama 2 comes in various sizes, from 7 billion to a massive 70 billion parameters. It shares a similar architecture with Llama 1 but boasts improved capabilities.
Extensive Training Data: This model has been trained on a massive dataset of 2 trillion tokens, demonstrating its vast exposure to a wide range of information.
Enhanced Context: With an extended context length of 4,000 tokens, the model can better understand and generate extensive content.
Grouped Query Attention (GQA): GQA has been introduced to enhance inference scalability, making attention calculations faster by storing previous token pair information.
Performance Excellence: Llama 2 models consistently outperform their predecessors, particularly the Llama 2 70B version. They excel in various benchmarks, competing strongly with models like Llama 1 65B and even Falcon models.
Open Source vs. Closed Source LLMs: When compared to models like GPT-3.5 or PaLM (540B), Llama 2 70B demonstrates impressive performance. While there may be a slight gap in certain benchmarks when compared to GPT-4 and PaLM-2, the model’s potential is evident.
Parameter Efficient Fine-Tuning (PEFT)
Parameter Efficient Fine-Tuning involves adapting pre-trained models to new tasks while making minimal changes to the model’s parameters. This is especially important for large neural network models like BERT, GPT, and similar ones. Let’s delve into why PEFT is so significant:
Reduced Overfitting: Limited datasets can be problematic. Making too many parameter adjustments can lead to the model overfitting. PEFT allows us to strike a balance between the model’s flexibility and tailoring it to new tasks.
Faster Training: Making fewer parameter changes results in fewer computations, which in turn leads to faster training sessions.
Resource Efficiency: Training deep neural networks requires substantial computational resources. PEFT minimizes the computational and memory demands, making it more practical to deploy in resource-constrained environments.
Knowledge Preservation: Extensive pretraining on diverse datasets equips models with valuable general knowledge. PEFT ensures that this wealth of knowledge is retained when adapting the model to new tasks.
PEFT Technique
The most popular PEFT technique is LoRA. Let’s see what it offers:
LoRA
LoRA, or Low Rank Adaptation, represents a groundbreaking advancement in the realm of large language models. At the beginning of the year, these models seemed accessible only to wealthy companies. However, LoRA has changed the landscape.
LoRA has made the use of large language models accessible to a wider audience. Its low-rank adaptation approach has significantly reduced the number of trainable parameters by up to 10,000 times. This results in:
A threefold reduction in GPU requirements, which is typically a major bottleneck.
Comparable, if not superior, performance even without fine-tuning the entire model.
In traditional fine-tuning, we modify the existing weights of a pre-trained model using new examples. Conventionally, this required a matrix of the same size. However, by employing creative methods and the concept of rank factorization, a matrix can be split into two smaller matrices. When multiplied together, they approximate the original matrix.
To illustrate, imagine a 1000×1000 matrix with 1,000,000 parameters. Through rank factorization, if the rank is, for instance, five, we could have two matrices, each sized 1000×5. When combined, they represent just 10,000 parameters, resulting in a significant reduction.
In recent days, researchers have introduced an extension of LoRA known as QLoRA.
QLoRA
QLoRA is an extension of LoRA that further introduces quantization to enhance parameter efficiency during fine-tuning. It builds on the principles of LoRA while introducing 4-bit NormalFloat (NF4) quantization and Double Quantization techniques.
The dataset has undergone special processing to ensure a seamless match with Llama 2’s prompt format, making it ready for training without the need for additional modifications.
Since the data has already been adapted to Llama 2’s prompt format, it can be directly employed to tune the model for particular applications.
# Dataset
data_name = “m0hammadjaan/Dummy-NED-Positions”# Your dataset here
We start by specifying the pre-trained Llama 2 model and prepare for an improved version called “llama-2-7b-enhanced“. We load the tokenizer and make slight adjustments to ensure compatibility with half-precision floating-point numbers (fp16) operations. Working with fp16 can offer various advantages, including reduced memory usage and faster model training. However, it’s important to note that not all operations work seamlessly with this lower precision format, and tokenization, a crucial step in preparing text data for model training, is one of them.
Next, we load the pre-trained Llama 2 model with our quantization configurations. We then deactivate caching and configure a pretraining temperature parameter.
In order to shrink the model’s size and boost inference speed, we employ 4-bit quantization provided by the BitsAndBytesConfig. Quantization involves representing the model’s weights in a way that consumes less memory.
The configuration mentioned here uses the ‘nf4‘ type for quantization. You can experiment with different quantization types to explore potential performance variations.
In the context of training a machine learning model using Low-Rank Adaptation (LoRA), several parameters play a significant role. Here’s a simplified explanation of each:
Parameters Specific to LoRA:
Dropout Rate (lora_dropout): This parameter represents the probability that the output of each neuron is set to zero during training. It is used to prevent overfitting, which occurs when the model becomes too tailored to the training data.
Rank (r): Rank measures how the original weight matrices are decomposed into simpler, smaller matrices. This decomposition reduces computational demands and memory usage. Lower ranks can make the model faster but may impact its performance. The original LoRA paper suggests starting with a rank of 8, but for QLoRA, a rank of 64 is recommended.
Lora_alpha: This parameter controls the scaling of the low-rank approximation. It’s like finding the right balance between the original model and the low-rank approximation. Higher values can make the approximation more influential during the fine-tuning process, which can affect both performance and computational cost.
By adjusting these parameters, particularly lora_alpha and r, you can observe how the model’s performance and resource utilization change. This allows you to fine-tune the model for your specific task and find the optimal configuration.
# Recommended if you are using free google cloab GPU else you’ll get CUDA out of memory
os.environ[“PYTORCH_CUDA_ALLOC_CONF”] = “400”
# LoRA Config
peft_parameters = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=8,
bias=“none”,
task_type=“CAUSAL_LM”
)
# Training Params
train_params = TrainingArguments(
output_dir=“./results_modified”, # Output directory for saving model checkpoints and logs
num_train_epochs=1, # Number of training epochs
per_device_train_batch_size=4, # Batch size per device during training
gradient_accumulation_steps=1, # Number of gradient accumulation steps
I asked both the fine-tuned and unfine-tuned models of LLaMA 2 about a university, and the fine-tuned model provided the correct result. The unfine-tuned model does not know about the query therefore it hallucinated the response.
Unfine-tuned
Fine-tuned
Revolutionize LLM with Llama 2 Fine-Tuning
With the introduction of LLaMA v1, we witnessed a surge in customized models like Alpaca, Vicuna, and WizardLM. This surge motivated various businesses to launch their own foundational models, such as OpenLLaMA, Falcon, and XGen, with licenses suitable for commercial purposes. LLaMA 2, the latest release, now combines the strengths of both approaches, offering an efficient foundational model with a more permissive license.
In the first half of 2023, the software landscape underwent a significant transformation with the widespread adoption of APIs like OpenAI API to build infrastructures based on Large Language Models (LLMs). Libraries like LangChain and LlamaIndex played crucial roles in this evolution.
As we move into the latter part of the year, fine-tuning or instruction tuning of these models is becoming a standard practice in the LLMOps workflow. This trend is motivated by several factors, including
Potential cost savings
The capacity to handle sensitive data
The opportunity to develop models that can outperform well-known models like ChatGPT and GPT-4 in specific tasks.
Fine-Tuning:
Fine-tuning methods refer to various techniques used to enhance the performance of a pre-trained model by adapting it to a specific task or domain. These methods are valuable for optimizing a model’s weights and parameters to excel in the target task. Here are different fine-tuning methods:
Supervised Fine-Tuning: This method involves further training a pre-trained language model (LLM) on a specific downstream task using labeled data. The model’s parameters are updated to excel in this task, such as text classification, named entity recognition, or sentiment analysis.
Transfer Learning: Transfer learning involves repurposing a pre-trained model’s architecture and weights for a new task or domain. Typically, the model is initially trained on a broad dataset and is then fine-tuned to adapt to specific tasks or domains, making it an efficient approach.
Sequential Fine-tuning: Sequential fine-tuning entails the gradual adaptation of a pre-trained model on multiple related tasks or domains in succession. This sequential learning helps the model capture intricate language patterns across various tasks, leading to improved generalization and performance.
Task-specific Fine-tuning: Task-specific fine-tuning is a method where the pre-trained model undergoes further training on a dedicated dataset for a particular task or domain. While it demands more data and time than transfer learning, it can yield higher performance tailored to the specific task.
Multi-task Learning: Multi-task learning involves fine-tuning the pre-trained model on several tasks simultaneously. This strategy enables the model to learn and leverage common features and representations across different tasks, ultimately enhancing its ability to generalize and perform well.
Adapter Training: Adapter training entails training lightweight modules that are integrated into the pre-trained model. These adapters allow for fine-tuning on specific tasks without interfering with the original model’s performance on other tasks. This approach maintains efficiency while adapting to task-specific requirements.
The figure discusses the allocation of AI tasks within organizations, taking into account the amount of available data. On the left side of the spectrum, having a substantial amount of data allows organizations to train their own models from scratch, albeit at a high cost. Alternatively, if an organization possesses a moderate amount of data, it can fine-tune pre-existing models to achieve excellent performance. For those with limited data, the recommended approach is in-context learning, specifically through techniques like retrieval augmented generation using general models. However, our focus will be on the fine-tuning aspect, as it offers a favorable balance between accuracy, performance, and speed compared to larger, more general models.
Before we dive into the detailed guide, let’s take a quick look at the benefits of Llama 2.
Diverse Range: Llama 2 comes in various sizes, from 7 billion to a massive 70 billion parameters. It shares a similar architecture with Llama 1 but boasts improved capabilities.
Extensive Training Data: This model has been trained on a massive dataset of 2 trillion tokens, demonstrating its vast exposure to a wide range of information.
Enhanced Context: With an extended context length of 4,000 tokens, the model can better understand and generate extensive content.
Grouped Query Attention (GQA): GQA has been introduced to enhance inference scalability, making attention calculations faster by storing previous token pair information.
Performance Excellence: Llama 2 models consistently outperform their predecessors, particularly the Llama 2 70B version. They excel in various benchmarks, competing strongly with models like Llama 1 65B and even Falcon models.
Open Source vs. Closed Source LLMs: When compared to models like GPT-3.5 or PaLM (540B), Llama 2 70B demonstrates impressive performance. While there may be a slight gap in certain benchmarks when compared to GPT-4 and PaLM-2, the model’s potential is evident.
Parameter Efficient Fine-Tuning (PEFT)
Parameter Efficient Fine-Tuning involves adapting pre-trained models to new tasks while making minimal changes to the model’s parameters. This is especially important for large neural network models like BERT, GPT, and similar ones. Let’s delve into why PEFT is so significant:
Reduced Overfitting: Limited datasets can be problematic. Making too many parameter adjustments can lead to the model overfitting. PEFT allows us to strike a balance between the model’s flexibility and tailoring it to new tasks.
Faster Training: Making fewer parameter changes results in fewer computations, which in turn leads to faster training sessions.
Resource Efficiency: Training deep neural networks requires substantial computational resources. PEFT minimizes the computational and memory demands, making it more practical to deploy in resource-constrained environments.
Knowledge Preservation: Extensive pretraining on diverse datasets equips models with valuable general knowledge. PEFT ensures that this wealth of knowledge is retained when adapting the model to new tasks.
PEFT Technique
The most popular PEFT technique is LoRA. Let’s see what it offers:
LoRA
LoRA, or Low Rank Adaptation, represents a groundbreaking advancement in the realm of large language models. At the beginning of the year, these models seemed accessible only to wealthy companies. However, LoRA has changed the landscape.
LoRA has made the use of large language models accessible to a wider audience. Its low-rank adaptation approach has significantly reduced the number of trainable parameters by up to 10,000 times. This results in:
A threefold reduction in GPU requirements, which is typically a major bottleneck.
Comparable, if not superior, performance even without fine-tuning the entire model.
In traditional fine-tuning, we modify the existing weights of a pre-trained model using new examples. Conventionally, this required a matrix of the same size. However, by employing creative methods and the concept of rank factorization, a matrix can be split into two smaller matrices. When multiplied together, they approximate the original matrix.
To illustrate, imagine a 1000×1000 matrix with 1,000,000 parameters. Through rank factorization, if the rank is, for instance, five, we could have two matrices, each sized 1000×5. When combined, they represent just 10,000 parameters, resulting in a significant reduction.
In recent days, researchers have introduced an extension of LoRA known as QLoRA.
QLoRA
QLoRA is an extension of LoRA that further introduces quantization to enhance parameter efficiency during fine-tuning. It builds on the principles of LoRA while introducing 4-bit NormalFloat (NF4) quantization and Double Quantization techniques.
The dataset has undergone special processing to ensure a seamless match with Llama 2’s prompt format, making it ready for training without the need for additional modifications.
Since the data has already been adapted to Llama 2’s prompt format, it can be directly employed to tune the model for particular applications.
# Dataset
data_name = “m0hammadjaan/Dummy-NED-Positions”# Your dataset here
We start by specifying the pre-trained Llama 2 model and prepare for an improved version called “llama-2-7b-enhanced“. We load the tokenizer and make slight adjustments to ensure compatibility with half-precision floating-point numbers (fp16) operations. Working with fp16 can offer various advantages, including reduced memory usage and faster model training. However, it’s important to note that not all operations work seamlessly with this lower precision format, and tokenization, a crucial step in preparing text data for model training, is one of them.
Next, we load the pre-trained Llama 2 model with our quantization configurations. We then deactivate caching and configure a pretraining temperature parameter.
In order to shrink the model’s size and boost inference speed, we employ 4-bit quantization provided by the BitsAndBytesConfig. Quantization involves representing the model’s weights in a way that consumes less memory.
The configuration mentioned here uses the ‘nf4‘ type for quantization. You can experiment with different quantization types to explore potential performance variations.
In the context of training a machine learning model using Low-Rank Adaptation (LoRA), several parameters play a significant role. Here’s a simplified explanation of each:
Parameters Specific to LoRA:
Dropout Rate (lora_dropout): This parameter represents the probability that the output of each neuron is set to zero during training. It is used to prevent overfitting, which occurs when the model becomes too tailored to the training data.
Rank (r): Rank measures how the original weight matrices are decomposed into simpler, smaller matrices. This decomposition reduces computational demands and memory usage. Lower ranks can make the model faster but may impact its performance. The original LoRA paper suggests starting with a rank of 8, but for QLoRA, a rank of 64 is recommended.
Lora_alpha: This parameter controls the scaling of the low-rank approximation. It’s like finding the right balance between the original model and the low-rank approximation. Higher values can make the approximation more influential during the fine-tuning process, which can affect both performance and computational cost.
By adjusting these parameters, particularly lora_alpha and r, you can observe how the model’s performance and resource utilization change. This allows you to fine-tune the model for your specific task and find the optimal configuration.
# Recommended if you are using free google cloab GPU else you’ll get CUDA out of memory
os.environ[“PYTORCH_CUDA_ALLOC_CONF”] = “400”
# LoRA Config
peft_parameters = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=8,
bias=“none”,
task_type=“CAUSAL_LM”
)
# Training Params
train_params = TrainingArguments(
output_dir=“./results_modified”, # Output directory for saving model checkpoints and logs
num_train_epochs=1, # Number of training epochs
per_device_train_batch_size=4, # Batch size per device during training
gradient_accumulation_steps=1, # Number of gradient accumulation steps
I asked both the fine-tuned and unfine-tuned models of LLaMA 2 about a university, and the fine-tuned model provided the correct result. The unfine-tuned model does not know about the query therefore it hallucinated the response.
Unfine-tuned
Fine-tuned
Revolutionize LLM with Llama 2 Fine-Tuning
With the introduction of LLaMA v1, we witnessed a surge in customized models like Alpaca, Vicuna, and WizardLM. This surge motivated various businesses to launch their own foundational models, such as OpenLLaMA, Falcon, and XGen, with licenses suitable for commercial purposes. LLaMA 2, the latest release, now combines the strengths of both approaches, offering an efficient foundational model with a more permissive license.
In the first half of 2023, the software landscape underwent a significant transformation with the widespread adoption of APIs like OpenAI API to build infrastructures based on Large Language Models (LLMs). Libraries like LangChain and LlamaIndex played crucial roles in this evolution.
As we move into the latter part of the year, fine-tuning or instruction tuning of these models is becoming a standard practice in the LLMOps workflow. This trend is motivated by several factors, including
Potential cost savings
The capacity to handle sensitive data
The opportunity to develop models that can outperform well-known models like ChatGPT and GPT-4 in specific tasks.
Fine-Tuning:
Fine-tuning methods refer to various techniques used to enhance the performance of a pre-trained model by adapting it to a specific task or domain. These methods are valuable for optimizing a model’s weights and parameters to excel in the target task. Here are different fine-tuning methods:
Supervised Fine-Tuning: This method involves further training a pre-trained language model (LLM) on a specific downstream task using labeled data. The model’s parameters are updated to excel in this task, such as text classification, named entity recognition, or sentiment analysis.
Transfer Learning: Transfer learning involves repurposing a pre-trained model’s architecture and weights for a new task or domain. Typically, the model is initially trained on a broad dataset and is then fine-tuned to adapt to specific tasks or domains, making it an efficient approach.
Sequential Fine-tuning: Sequential fine-tuning entails the gradual adaptation of a pre-trained model on multiple related tasks or domains in succession. This sequential learning helps the model capture intricate language patterns across various tasks, leading to improved generalization and performance.
Task-specific Fine-tuning: Task-specific fine-tuning is a method where the pre-trained model undergoes further training on a dedicated dataset for a particular task or domain. While it demands more data and time than transfer learning, it can yield higher performance tailored to the specific task.
Multi-task Learning: Multi-task learning involves fine-tuning the pre-trained model on several tasks simultaneously. This strategy enables the model to learn and leverage common features and representations across different tasks, ultimately enhancing its ability to generalize and perform well.
Adapter Training: Adapter training entails training lightweight modules that are integrated into the pre-trained model. These adapters allow for fine-tuning on specific tasks without interfering with the original model’s performance on other tasks. This approach maintains efficiency while adapting to task-specific requirements.
The figure discusses the allocation of AI tasks within organizations, taking into account the amount of available data. On the left side of the spectrum, having a substantial amount of data allows organizations to train their own models from scratch, albeit at a high cost. Alternatively, if an organization possesses a moderate amount of data, it can fine-tune pre-existing models to achieve excellent performance. For those with limited data, the recommended approach is in-context learning, specifically through techniques like retrieval augmented generation using general models. However, our focus will be on the fine-tuning aspect, as it offers a favorable balance between accuracy, performance, and speed compared to larger, more general models.
Before we dive into the detailed guide, let’s take a quick look at the benefits of Llama 2.
Diverse Range: Llama 2 comes in various sizes, from 7 billion to a massive 70 billion parameters. It shares a similar architecture with Llama 1 but boasts improved capabilities.
Extensive Training Data: This model has been trained on a massive dataset of 2 trillion tokens, demonstrating its vast exposure to a wide range of information.
Enhanced Context: With an extended context length of 4,000 tokens, the model can better understand and generate extensive content.
Grouped Query Attention (GQA): GQA has been introduced to enhance inference scalability, making attention calculations faster by storing previous token pair information.
Performance Excellence: Llama 2 models consistently outperform their predecessors, particularly the Llama 2 70B version. They excel in various benchmarks, competing strongly with models like Llama 1 65B and even Falcon models.
Open Source vs. Closed Source LLMs: When compared to models like GPT-3.5 or PaLM (540B), Llama 2 70B demonstrates impressive performance. While there may be a slight gap in certain benchmarks when compared to GPT-4 and PaLM-2, the model’s potential is evident.
Parameter Efficient Fine-Tuning (PEFT)
Parameter Efficient Fine-Tuning involves adapting pre-trained models to new tasks while making minimal changes to the model’s parameters. This is especially important for large neural network models like BERT, GPT, and similar ones. Let’s delve into why PEFT is so significant:
Reduced Overfitting: Limited datasets can be problematic. Making too many parameter adjustments can lead to the model overfitting. PEFT allows us to strike a balance between the model’s flexibility and tailoring it to new tasks.
Faster Training: Making fewer parameter changes results in fewer computations, which in turn leads to faster training sessions.
Resource Efficiency: Training deep neural networks requires substantial computational resources. PEFT minimizes the computational and memory demands, making it more practical to deploy in resource-constrained environments.
Knowledge Preservation: Extensive pretraining on diverse datasets equips models with valuable general knowledge. PEFT ensures that this wealth of knowledge is retained when adapting the model to new tasks.
PEFT Technique
The most popular PEFT technique is LoRA. Let’s see what it offers:
LoRA
LoRA, or Low Rank Adaptation, represents a groundbreaking advancement in the realm of large language models. At the beginning of the year, these models seemed accessible only to wealthy companies. However, LoRA has changed the landscape.
LoRA has made the use of large language models accessible to a wider audience. Its low-rank adaptation approach has significantly reduced the number of trainable parameters by up to 10,000 times. This results in:
A threefold reduction in GPU requirements, which is typically a major bottleneck.
Comparable, if not superior, performance even without fine-tuning the entire model.
In traditional fine-tuning, we modify the existing weights of a pre-trained model using new examples. Conventionally, this required a matrix of the same size. However, by employing creative methods and the concept of rank factorization, a matrix can be split into two smaller matrices. When multiplied together, they approximate the original matrix.
To illustrate, imagine a 1000×1000 matrix with 1,000,000 parameters. Through rank factorization, if the rank is, for instance, five, we could have two matrices, each sized 1000×5. When combined, they represent just 10,000 parameters, resulting in a significant reduction.
In recent days, researchers have introduced an extension of LoRA known as QLoRA.
QLoRA
QLoRA is an extension of LoRA that further introduces quantization to enhance parameter efficiency during fine-tuning. It builds on the principles of LoRA while introducing 4-bit NormalFloat (NF4) quantization and Double Quantization techniques.
The dataset has undergone special processing to ensure a seamless match with Llama 2’s prompt format, making it ready for training without the need for additional modifications.
Since the data has already been adapted to Llama 2’s prompt format, it can be directly employed to tune the model for particular applications.
# Dataset
data_name = “m0hammadjaan/Dummy-NED-Positions”# Your dataset here
We start by specifying the pre-trained Llama 2 model and prepare for an improved version called “llama-2-7b-enhanced“. We load the tokenizer and make slight adjustments to ensure compatibility with half-precision floating-point numbers (fp16) operations. Working with fp16 can offer various advantages, including reduced memory usage and faster model training. However, it’s important to note that not all operations work seamlessly with this lower precision format, and tokenization, a crucial step in preparing text data for model training, is one of them.
Next, we load the pre-trained Llama 2 model with our quantization configurations. We then deactivate caching and configure a pretraining temperature parameter.
In order to shrink the model’s size and boost inference speed, we employ 4-bit quantization provided by the BitsAndBytesConfig. Quantization involves representing the model’s weights in a way that consumes less memory.
The configuration mentioned here uses the ‘nf4‘ type for quantization. You can experiment with different quantization types to explore potential performance variations.
In the context of training a machine learning model using Low-Rank Adaptation (LoRA), several parameters play a significant role. Here’s a simplified explanation of each:
Parameters Specific to LoRA:
Dropout Rate (lora_dropout): This parameter represents the probability that the output of each neuron is set to zero during training. It is used to prevent overfitting, which occurs when the model becomes too tailored to the training data.
Rank (r): Rank measures how the original weight matrices are decomposed into simpler, smaller matrices. This decomposition reduces computational demands and memory usage. Lower ranks can make the model faster but may impact its performance. The original LoRA paper suggests starting with a rank of 8, but for QLoRA, a rank of 64 is recommended.
Lora_alpha: This parameter controls the scaling of the low-rank approximation. It’s like finding the right balance between the original model and the low-rank approximation. Higher values can make the approximation more influential during the fine-tuning process, which can affect both performance and computational cost.
By adjusting these parameters, particularly lora_alpha and r, you can observe how the model’s performance and resource utilization change. This allows you to fine-tune the model for your specific task and find the optimal configuration.
# Recommended if you are using free google cloab GPU else you’ll get CUDA out of memory
os.environ[“PYTORCH_CUDA_ALLOC_CONF”] = “400”
# LoRA Config
peft_parameters = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=8,
bias=“none”,
task_type=“CAUSAL_LM”
)
# Training Params
train_params = TrainingArguments(
output_dir=“./results_modified”, # Output directory for saving model checkpoints and logs
num_train_epochs=1, # Number of training epochs
per_device_train_batch_size=4, # Batch size per device during training
gradient_accumulation_steps=1, # Number of gradient accumulation steps
I asked both the fine-tuned and unfine-tuned models of LLaMA 2 about a university, and the fine-tuned model provided the correct result. The unfine-tuned model does not know about the query therefore it hallucinated the response.
Unfine-tuned
Fine-tuned
Revolutionize LLM with Llama 2 Fine-Tuning
With the introduction of LLaMA v1, we witnessed a surge in customized models like Alpaca, Vicuna, and WizardLM. This surge motivated various businesses to launch their own foundational models, such as OpenLLaMA, Falcon, and XGen, with licenses suitable for commercial purposes. LLaMA 2, the latest release, now combines the strengths of both approaches, offering an efficient foundational model with a more permissive license.
In the first half of 2023, the software landscape underwent a significant transformation with the widespread adoption of APIs like OpenAI API to build infrastructures based on Large Language Models (LLMs). Libraries like LangChain and LlamaIndex played crucial roles in this evolution.
As we move into the latter part of the year, fine-tuning or instruction tuning of these models is becoming a standard practice in the LLMOps workflow. This trend is motivated by several factors, including
Potential cost savings
The capacity to handle sensitive data
The opportunity to develop models that can outperform well-known models like ChatGPT and GPT-4 in specific tasks.
Fine-Tuning:
Fine-tuning methods refer to various techniques used to enhance the performance of a pre-trained model by adapting it to a specific task or domain. These methods are valuable for optimizing a model’s weights and parameters to excel in the target task. Here are different fine-tuning methods:
Supervised Fine-Tuning: This method involves further training a pre-trained language model (LLM) on a specific downstream task using labeled data. The model’s parameters are updated to excel in this task, such as text classification, named entity recognition, or sentiment analysis.
Transfer Learning: Transfer learning involves repurposing a pre-trained model’s architecture and weights for a new task or domain. Typically, the model is initially trained on a broad dataset and is then fine-tuned to adapt to specific tasks or domains, making it an efficient approach.
Sequential Fine-tuning: Sequential fine-tuning entails the gradual adaptation of a pre-trained model on multiple related tasks or domains in succession. This sequential learning helps the model capture intricate language patterns across various tasks, leading to improved generalization and performance.
Task-specific Fine-tuning: Task-specific fine-tuning is a method where the pre-trained model undergoes further training on a dedicated dataset for a particular task or domain. While it demands more data and time than transfer learning, it can yield higher performance tailored to the specific task.
Multi-task Learning: Multi-task learning involves fine-tuning the pre-trained model on several tasks simultaneously. This strategy enables the model to learn and leverage common features and representations across different tasks, ultimately enhancing its ability to generalize and perform well.
Adapter Training: Adapter training entails training lightweight modules that are integrated into the pre-trained model. These adapters allow for fine-tuning on specific tasks without interfering with the original model’s performance on other tasks. This approach maintains efficiency while adapting to task-specific requirements.
The figure discusses the allocation of AI tasks within organizations, taking into account the amount of available data. On the left side of the spectrum, having a substantial amount of data allows organizations to train their own models from scratch, albeit at a high cost. Alternatively, if an organization possesses a moderate amount of data, it can fine-tune pre-existing models to achieve excellent performance. For those with limited data, the recommended approach is in-context learning, specifically through techniques like retrieval augmented generation using general models. However, our focus will be on the fine-tuning aspect, as it offers a favorable balance between accuracy, performance, and speed compared to larger, more general models.
Before we dive into the detailed guide, let’s take a quick look at the benefits of Llama 2.
Diverse Range: Llama 2 comes in various sizes, from 7 billion to a massive 70 billion parameters. It shares a similar architecture with Llama 1 but boasts improved capabilities.
Extensive Training Data: This model has been trained on a massive dataset of 2 trillion tokens, demonstrating its vast exposure to a wide range of information.
Enhanced Context: With an extended context length of 4,000 tokens, the model can better understand and generate extensive content.
Grouped Query Attention (GQA): GQA has been introduced to enhance inference scalability, making attention calculations faster by storing previous token pair information.
Performance Excellence: Llama 2 models consistently outperform their predecessors, particularly the Llama 2 70B version. They excel in various benchmarks, competing strongly with models like Llama 1 65B and even Falcon models.
Open Source vs. Closed Source LLMs: When compared to models like GPT-3.5 or PaLM (540B), Llama 2 70B demonstrates impressive performance. While there may be a slight gap in certain benchmarks when compared to GPT-4 and PaLM-2, the model’s potential is evident.
Parameter Efficient Fine-Tuning (PEFT)
Parameter Efficient Fine-Tuning involves adapting pre-trained models to new tasks while making minimal changes to the model’s parameters. This is especially important for large neural network models like BERT, GPT, and similar ones. Let’s delve into why PEFT is so significant:
Reduced Overfitting: Limited datasets can be problematic. Making too many parameter adjustments can lead to the model overfitting. PEFT allows us to strike a balance between the model’s flexibility and tailoring it to new tasks.
Faster Training: Making fewer parameter changes results in fewer computations, which in turn leads to faster training sessions.
Resource Efficiency: Training deep neural networks requires substantial computational resources. PEFT minimizes the computational and memory demands, making it more practical to deploy in resource-constrained environments.
Knowledge Preservation: Extensive pretraining on diverse datasets equips models with valuable general knowledge. PEFT ensures that this wealth of knowledge is retained when adapting the model to new tasks.
PEFT Technique
The most popular PEFT technique is LoRA. Let’s see what it offers:
LoRA
LoRA, or Low Rank Adaptation, represents a groundbreaking advancement in the realm of large language models. At the beginning of the year, these models seemed accessible only to wealthy companies. However, LoRA has changed the landscape.
LoRA has made the use of large language models accessible to a wider audience. Its low-rank adaptation approach has significantly reduced the number of trainable parameters by up to 10,000 times. This results in:
A threefold reduction in GPU requirements, which is typically a major bottleneck.
Comparable, if not superior, performance even without fine-tuning the entire model.
In traditional fine-tuning, we modify the existing weights of a pre-trained model using new examples. Conventionally, this required a matrix of the same size. However, by employing creative methods and the concept of rank factorization, a matrix can be split into two smaller matrices. When multiplied together, they approximate the original matrix.
To illustrate, imagine a 1000×1000 matrix with 1,000,000 parameters. Through rank factorization, if the rank is, for instance, five, we could have two matrices, each sized 1000×5. When combined, they represent just 10,000 parameters, resulting in a significant reduction.
In recent days, researchers have introduced an extension of LoRA known as QLoRA.
QLoRA
QLoRA is an extension of LoRA that further introduces quantization to enhance parameter efficiency during fine-tuning. It builds on the principles of LoRA while introducing 4-bit NormalFloat (NF4) quantization and Double Quantization techniques.
The dataset has undergone special processing to ensure a seamless match with Llama 2’s prompt format, making it ready for training without the need for additional modifications.
Since the data has already been adapted to Llama 2’s prompt format, it can be directly employed to tune the model for particular applications.
# Dataset
data_name = “m0hammadjaan/Dummy-NED-Positions”# Your dataset here
We start by specifying the pre-trained Llama 2 model and prepare for an improved version called “llama-2-7b-enhanced“. We load the tokenizer and make slight adjustments to ensure compatibility with half-precision floating-point numbers (fp16) operations. Working with fp16 can offer various advantages, including reduced memory usage and faster model training. However, it’s important to note that not all operations work seamlessly with this lower precision format, and tokenization, a crucial step in preparing text data for model training, is one of them.
Next, we load the pre-trained Llama 2 model with our quantization configurations. We then deactivate caching and configure a pretraining temperature parameter.
In order to shrink the model’s size and boost inference speed, we employ 4-bit quantization provided by the BitsAndBytesConfig. Quantization involves representing the model’s weights in a way that consumes less memory.
The configuration mentioned here uses the ‘nf4‘ type for quantization. You can experiment with different quantization types to explore potential performance variations.
In the context of training a machine learning model using Low-Rank Adaptation (LoRA), several parameters play a significant role. Here’s a simplified explanation of each:
Parameters Specific to LoRA:
Dropout Rate (lora_dropout): This parameter represents the probability that the output of each neuron is set to zero during training. It is used to prevent overfitting, which occurs when the model becomes too tailored to the training data.
Rank (r): Rank measures how the original weight matrices are decomposed into simpler, smaller matrices. This decomposition reduces computational demands and memory usage. Lower ranks can make the model faster but may impact its performance. The original LoRA paper suggests starting with a rank of 8, but for QLoRA, a rank of 64 is recommended.
Lora_alpha: This parameter controls the scaling of the low-rank approximation. It’s like finding the right balance between the original model and the low-rank approximation. Higher values can make the approximation more influential during the fine-tuning process, which can affect both performance and computational cost.
By adjusting these parameters, particularly lora_alpha and r, you can observe how the model’s performance and resource utilization change. This allows you to fine-tune the model for your specific task and find the optimal configuration.
# Recommended if you are using free google cloab GPU else you’ll get CUDA out of memory
os.environ[“PYTORCH_CUDA_ALLOC_CONF”] = “400”
# LoRA Config
peft_parameters = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=8,
bias=“none”,
task_type=“CAUSAL_LM”
)
# Training Params
train_params = TrainingArguments(
output_dir=“./results_modified”, # Output directory for saving model checkpoints and logs
num_train_epochs=1, # Number of training epochs
per_device_train_batch_size=4, # Batch size per device during training
gradient_accumulation_steps=1, # Number of gradient accumulation steps
I asked both the fine-tuned and unfine-tuned models of LLaMA 2 about a university, and the fine-tuned model provided the correct result. The unfine-tuned model does not know about the query therefore it hallucinated the response.
Pre-trained large language models (LLMs) offer many capabilities but aren’t universal. When faced with a task beyond their abilities, fine-tuning LLMs become an option. This process involves retraining LLMs on new data. While it can be complex and costly, it’s a potent tool for organizations using LLMs. Understanding fine-tuning, even if not doing it yourself, aids in informed decision-making.
Large language models (LLMs) are pre-trained on massive datasets of text and code. This allows them to learn a wide range of tasks, such as text generation, translation, and question-answering. However, LLMs are often not well-suited for specific tasks without fine-tuning.
source: gettectonic.com
Fine-tuning LLM
Fine-tuning is the process of adjusting the parameters of an LLM to a specific task. This is done by training the model on a dataset of data that is relevant to the task. The amount of fine-tuning required depends on the complexity of the task and the size of the dataset.
By exposing the model to domain-specific data, fine-tuning allows it to adapt its responses, improve accuracy, and generate more contextually appropriate outputs.
The extent of fine-tuning LLMs required depends on multiple factors:
Task Complexity: More intricate tasks, such as medical diagnosis or legal document analysis, require deeper fine-tuning compared to general tasks like sentiment analysis.
Dataset Size & Quality: A well-structured and extensive dataset ensures better adaptation, while a limited or noisy dataset may yield suboptimal results.
Model Architecture: Larger models may require more computational resources and training time, whereas smaller models might fine-tune faster but with reduced capabilities.
Fine-tuning enhances the model’s ability to understand industry-specific terminology, follow structured formats, and generate responses aligned with the desired use case. This makes it a valuable approach for businesses and researchers looking to tailor LLMs for specialized applications.
There are a number of ways to fine-tune LLMs. One common approach is to use supervised learning. This involves providing the model with a dataset of labeled data, where each data point is a pair of input and output. The model learns to map the input to the output by minimizing a loss function.
Another approach to fine-tuning LLMs is to use reinforcement learning. This involves providing the model with a reward signal for generating outputs that are desired. The model learns to generate desired outputs by maximizing the reward signal.
Fine-Tuning Techniques for LLMs
Fine-tuning is the process of adjusting the parameters of an LLM to a specific task. This is done by training the model on a dataset of data that is relevant to the task. The amount of fine-tuning required depends on the complexity of the task and the size of the dataset. There are two main fine-tuning techniques for LLMs: repurposing and full fine-tuning.
1. Repurposing
Repurposing is a technique where you use an LLM for a task that is different from the task it was originally trained on. For example, you could use an LLM that was trained for text generation for sentiment analysis.
To repurpose an LLM, you first need to identify the features of the input data that are relevant to the task you want to perform. Then, you need to connect the LLM’s embedding layer to a classifier model that can learn to map these features to the desired output.
Repurposing is a less computationally expensive fine-tuning technique than full fine-tuning. However, it is also less likely to achieve the same level of performance.
Technique
Description
Computational Cost
Performance
Repurposing
Use an LLM for a task that is different from the task it was originally trained on.
Less
Less
Full Fine-tuning
Train the entire LLM on a dataset of data that is relevant to the task you want to perform.
More
More
2. Full Fine-Tuning
Full fine-tuning is a technique where you train the entire LLM on a dataset of data that is relevant to the task you want to perform. This is the most computationally expensive fine-tuning technique, but it is also the most likely to achieve the best performance.
To full fine-tune an LLM, you need to create a dataset of data that contains examples of the input and output for the task you want to perform. Then, you need to train the LLM on this dataset using a supervised learning algorithm.
The choice of fine-tuning technique depends on the specific task you want to perform and the resources you have available. If you are short on computational resources, you may want to consider repurposing. However, if you are looking for the best possible performance, you should full fine-tune the LLM.
Large language models (LLMs) are pre-trained on massive datasets of text and code. This allows them to learn a wide range of tasks, such as text generation, translation, and question-answering. However, LLMs are often not well-suited for specific tasks without fine-tuning.
Fine-tuning is the process of adjusting the parameters of an LLM to a specific task. This is done by training the model on a dataset of data that is relevant to the task. The amount of fine-tuning required depends on the complexity of the task and the size of the dataset.
There are two main types of fine-tuning for LLMs: unsupervised and supervised.
Unsupervised Fine-Tuning
Unsupervised fine-tuning is a technique where you train the LLM on a dataset of data that does not contain any labels. This means that the model does not know what the correct output is for each input. Instead, the model learns to predict the next token in a sequence or to generate text that is similar to the text in the dataset.
Unsupervised fine-tuning is a less computationally expensive fine-tuning technique than supervised fine-tuning. However, it is also less likely to achieve the same level of performance.
Supervised Fine-Tuning
Supervised fine-tuning is a technique where you train the LLM on a dataset of data that contains labels. This means that the model knows what the correct output is for each input. The model learns to map the input to the output by minimizing a loss function.
Supervised fine-tuning is a more computationally expensive fine-tuning technique than unsupervised fine-tuning. However, it is also more likely to achieve the best performance.
The choice of fine-tuning technique depends on the specific task you want to perform and the resources you have available. If you are short on computational resources, you may want to consider unsupervised fine-tuning. However, if you are looking for the best possible performance, you should supervise fine-tuning the LLM.
Here is a table that summarizes the key differences between unsupervised and supervised fine-tuning:
Technique
Description
Computational Cost
Performance
Unsupervised Fine-tuning
Train the LLM on a dataset of data that does not contain any labels.
Less
Less
Supervised Fine-tuning
Train the LLM on a dataset of data that contains labels.
More
More
Reinforcement Learning from Human Feedback (RLHF) for LLMs
There are two main approaches to fine-tuning LLMs: supervised fine-tuning and reinforcement learning from human feedback (RLHF).
1. Supervised Fine-Tuning
Supervised fine-tuning is a technique where you train the LLM on a dataset of data that contains labels. This means that the model knows what the correct output is for each input. The model learns to map the input to the output by minimizing a loss function.
2. Reinforcement Learning from Human Feedback (RLHF)
RLHF is a technique where you use human feedback to fine-tune the LLM. The basic idea is that you give the LLM a prompt and it generates an output. Then, you ask a human to rate the output. The rating is used as a signal to fine-tune the LLM to generate higher-quality outputs.
RLHF is a more complex and expensive fine-tuning technique than supervised fine-tuning. However, it can be more effective for tasks that are difficult to define or for which there is not enough labeled data.
PEFT is a set of techniques that try to reduce the number of parameters that need to be updated during fine-tuning. This can be done by using a smaller dataset, using a simpler model, or using a technique called low-rank adaptation (LoRA).
LoRA is a technique that uses a low-dimensional matrix to represent the space of the downstream task. This matrix is then fine-tuned instead of the entire LLM. This can significantly reduce the amount of computation required for fine-tuning.
PEFT is a promising approach for fine-tuning LLMs. It can make fine-tuning more affordable and efficient, which can make it more accessible to a wider range of users.
When Not to Use LLM Fine-Tuning
Large language models (LLMs) are pre-trained on massive datasets of text and code. This allows them to learn a wide range of tasks, such as text generation, translation, and question answering. However, LLM fine-tuning is not always necessary or desirable.
Here are some cases where you might not want to use LLM fine-tuning:
The model is not available for fine-tuning. Some LLMs are only available through application programming interfaces (APIs) that do not allow fine-tuning.
You don’t have enough data to fine-tune the model. Fine-tuning an LLM requires a large dataset of labeled data. If you don’t have enough data, you may not be able to achieve good results with fine-tuning.
The data is constantly changing. If the data that the LLM is being used on is constantly changing, fine-tuning may not be able to keep up. This is especially true for tasks such as machine translation, where the vocabulary and grammar of the source language can change over time.
The application is dynamic and context-sensitive. In some cases, the output of an LLM needs to be tailored to the specific context of the user or the situation. For example, a chatbot that is used in a customer service application would need to be able to understand the customer’s intent and respond accordingly. Fine-tuning an LLM for this type of application would be difficult, as it would require a large dataset of labeled data that captures the different contexts in which the chatbot would be used.
In these cases, you may want to consider using a different approach, such as:
Using a smaller, less complex model. Smaller models are less computationally expensive to train and fine-tune, and they may be sufficient for some tasks.
Using a transfer learning approach. Transfer learning is a technique where you use a model that has been trained on a different task to initialize a model for a new task. This can be a more efficient way to train a model for a new task, as it can help the model to learn faster.
Using in-context learning or retrieval augmentation. In-context learning or retrieval augmentation is a technique where you provide the LLM with context during inference time. This can help the LLM to generate more accurate and relevant outputs.
Wrapping Up
In conclusion, fine-tuning LLMs is a powerful tool for tailoring these models to specific tasks. Understanding its nuances and options, including repurposing and full fine-tuning, helps optimize performance. The choice between supervised and unsupervised fine-tuning depends on resources and task complexity. Additionally, reinforcement learning from human feedback (RLHF) and parameter-efficient fine-tuning (PEFT) offer specialized approaches. While fine-tuning enhances LLMs, it’s not always necessary, especially if the model already fits the task. Careful consideration of when to use fine-tuning is essential in maximizing the efficiency and effectiveness of LLMs for specific applications.