

Understanding the significance of evaluation and tracing is key to improving large language model applications, ensuring the reliability, correctness, and performance of your models. This is a critical step in the development process, particularly if you’re working towards bringing your LLM application to production.
Whether you’re an experienced developer or just starting your journey, LangSmith’s private beta provides a valuable tool for your toolkit. In this blog, we delve into large language model evaluation and tracing with LangSmith, emphasizing their pivotal role in ensuring application reliability and performance.
You’ll learn to set up LangSmith, connect it with LangChain, and master the process of precise tracing and evaluation, equipping you with the tools to optimize your Large Language Model applications and bring them to production. Discover the key to unlock your model’s full potential.
LangSmith and LangChain in LLM Application
In working on Large Language Models (LLMs), LangChain and LangSmith stand as key pillars for developers and AI enthusiasts. LangChain simplifies the integration of powerful LLMs into applications, streamlining data access, and offering flexibility through concepts like “Chains” and “Agents.”
It bridges the gap between these models and external data sources, enabling the creation of robust natural language processing applications.
LangSmith, developed by LangChain, takes LLM application development to the next level. It aids in debugging, monitoring, and evaluating LLM-based applications, with features like logging runs, visualizing components, and facilitating collaboration. It ensures the reliability and efficiency of your LLM applications.
These two tools together form a dynamic duo, unleashing the true potential of large language models in application development. In the upcoming sections, we’ll delve deeper into the mechanics, showcasing how they can elevate your LLM projects to new heights.

Quick Start to LangSmith
Prerequisites
Please note that LangSmith is currently in a private beta phase, so we’ll show you how to join the waitlist. Once LangSmith releases new invites, you’ll be at the forefront of this innovative platform.
Sign up for an account here.

Configuring LangSmith with LangChain
Configuring LangSmith alongside LangChain is a straightforward procedure. It merely involves a few simple steps to establish LangSmith and start utilizing it for tracing and evaluation.
Read more about LangChain in detail
To initiate your journey, follow the sequential steps provided below:
- Begin by creating a LangSmith account, as outlined in the prerequisites
- In your working folder, create .env file containing essential environment variables. Although initial placeholders are provided, these will be replaced in subsequent steps:
- Substitute the placeholder <your-openai-api-key> with your OpenAI API key obtained from OpenAI.
- For the LangChain API key, navigate to the settings page on LangSmith, generate the key, and replace the placeholder.
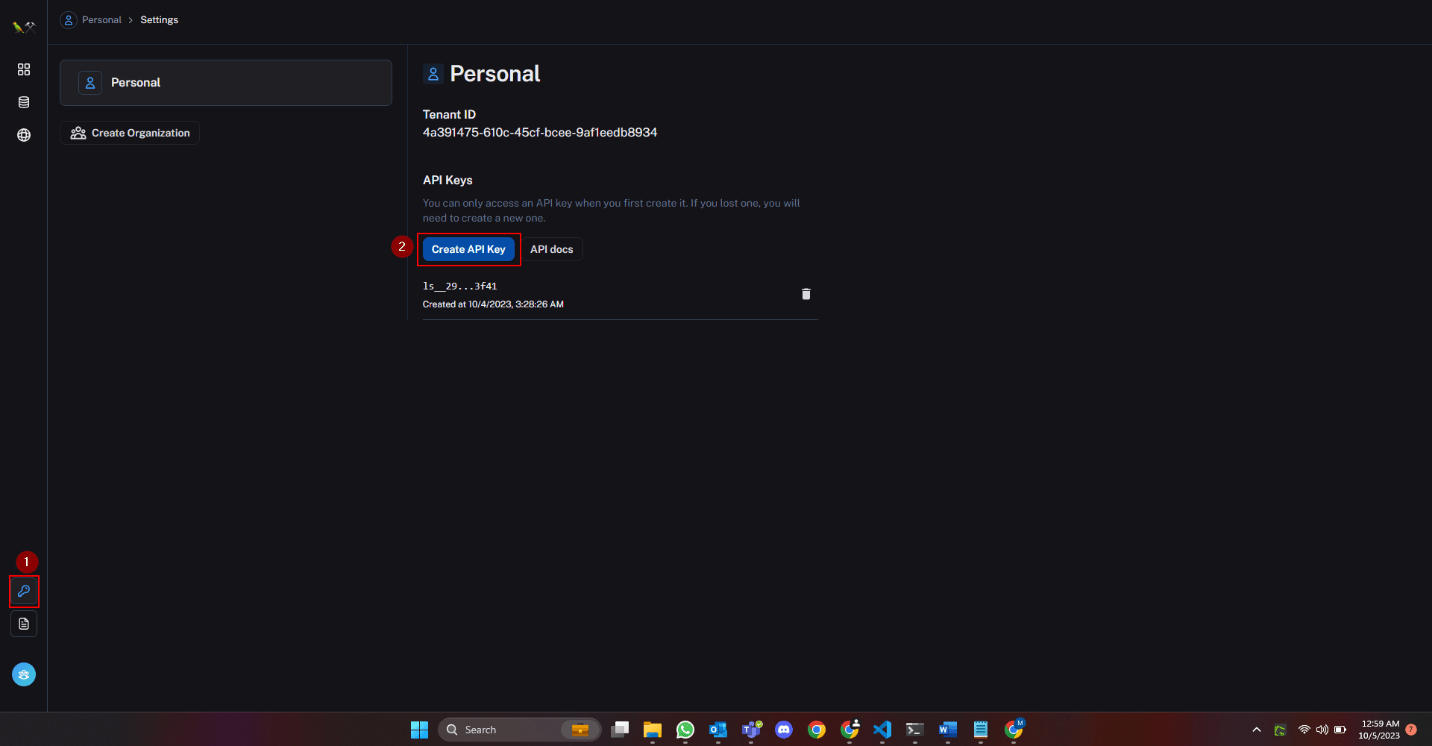
- Return to the home page and create a project with a suitable name. Subsequently, copy the project name and update the placeholder.
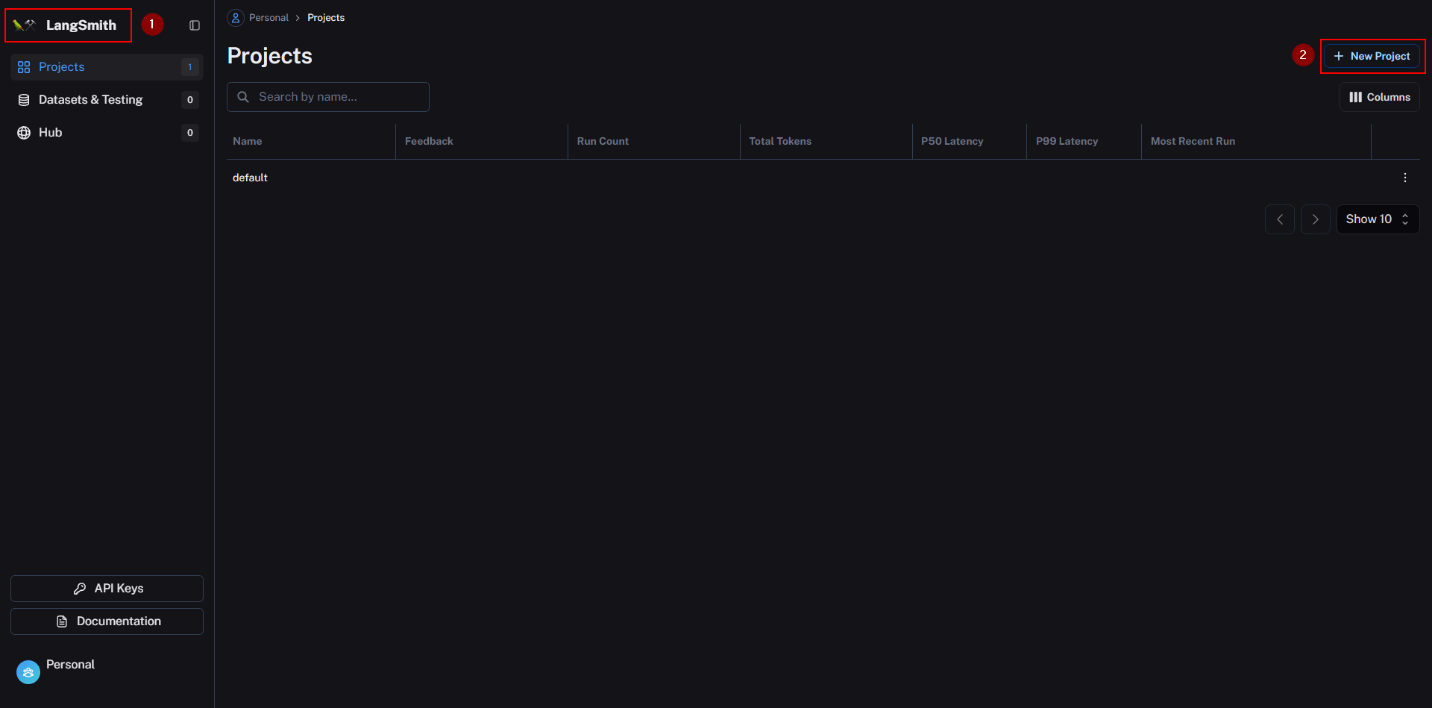
- Install it and any other necessary dependencies with the following command:
- Execute the provided example code to initiate the process:
- After running the code, return to the LangSmith home page, and access the project you just created.
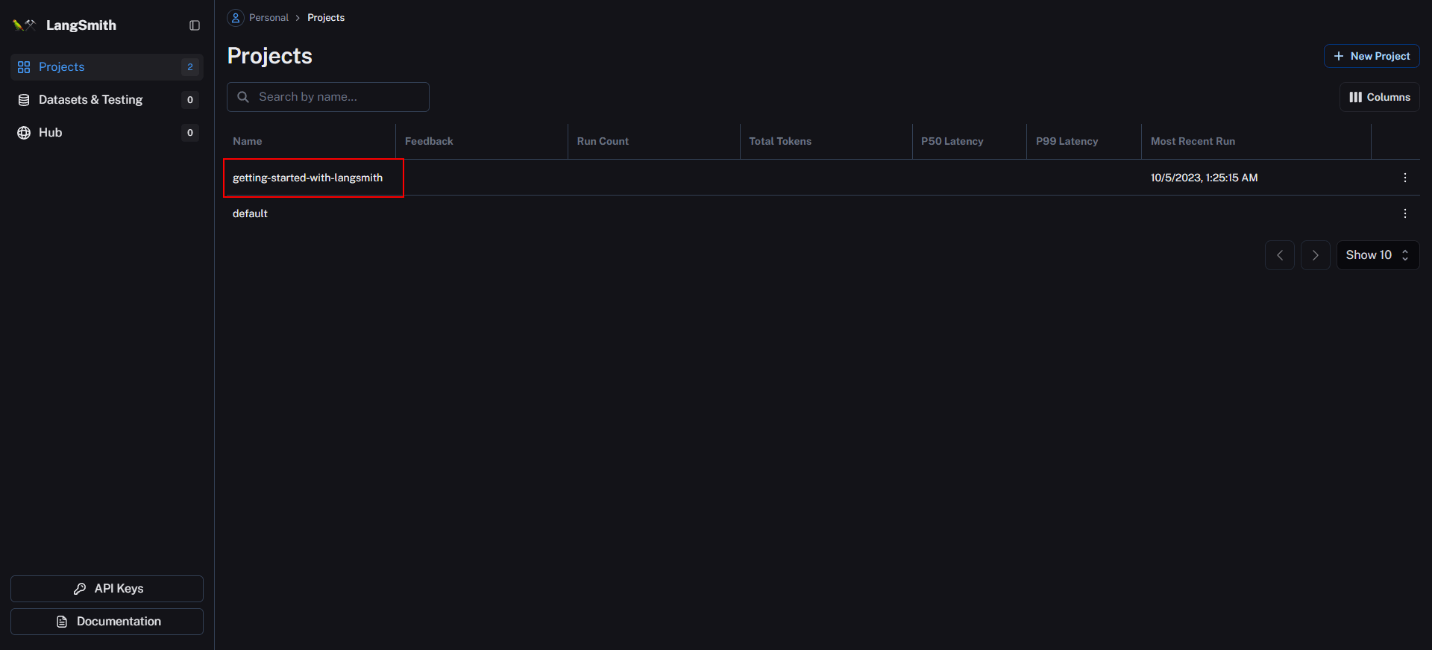
- Within the “Traces” section, you will find the run that was recently executed. Click on it to access detailed trace information.
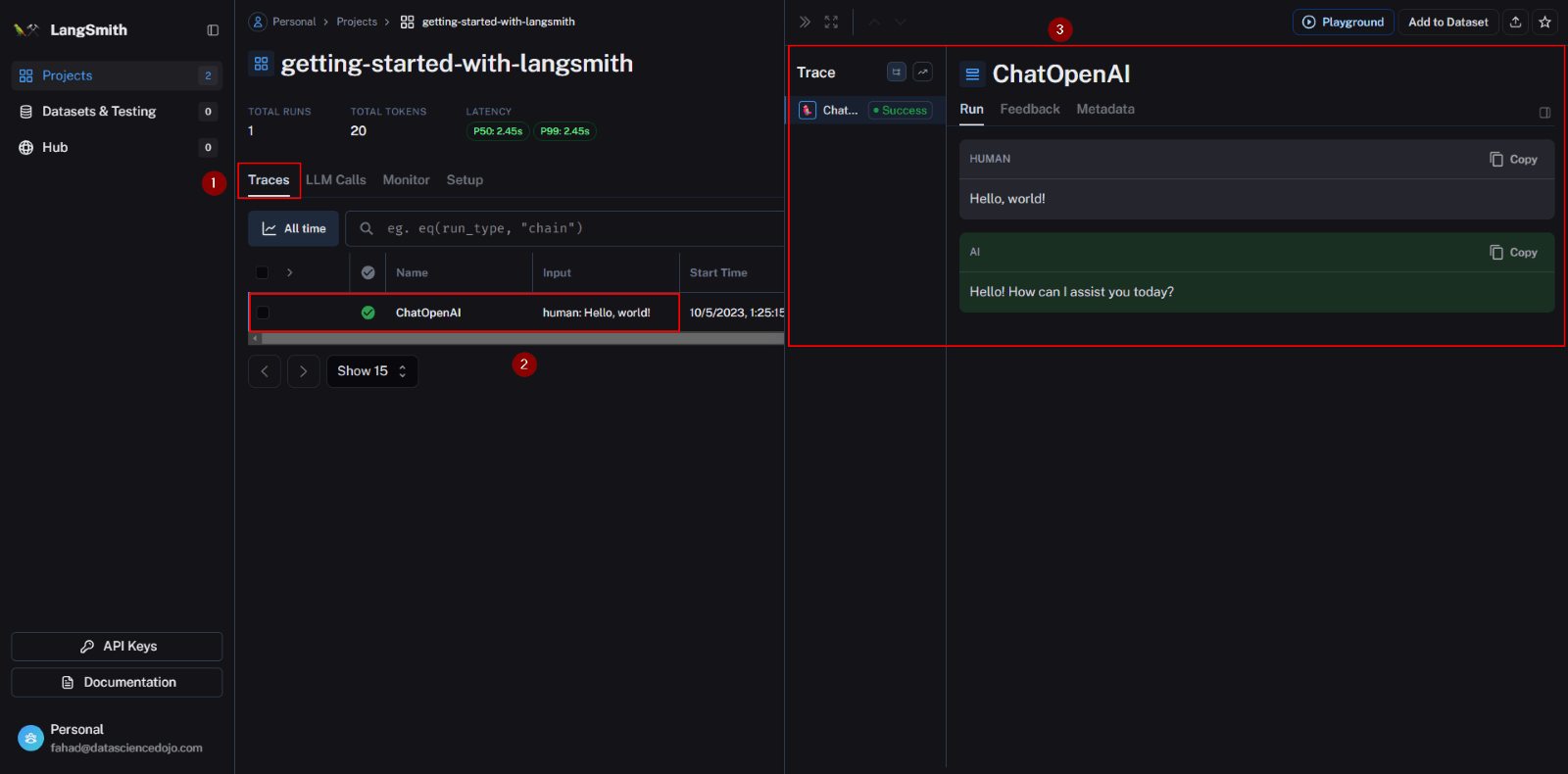
Congratulations, your initial run is now visible and traceable within LangSmith!
Scenario # 01: LLM Tracing
What is a Trace?
A ‘Run’ signifies a solitary instance of a task or operation within your LLM application. This could be anything from a single call to an LLM, chain, or agent.
A ‘Trace’ encompasses an arrangement of runs structured in a hierarchical or interconnected manner. The highest-level run in a trace, known as the ‘Root Run,’ is the one directly triggered by the user or application. The root run is designated with an execution order of 1, indicating the order in which it was initiated within the trace when considered as a sequence.
Examples of traces
We’ve already examined a straightforward LLM Call trace, where we observed the input provided to the large language model and the resulting output. In this uncomplicated case, a single run was evident, devoid of any hierarchical or multiple run structures.
Now, let’s delve further by tracing the LangChain chain and agent to uncover deeper insights into their operations.
Trace a Sequential Chain
In this instance, we explore the tracing of a sequential chain within LangChain, a foundational chain of this platform. Sequential chains enable the connection of multiple chains, creating complex pipelines for specific scenarios. Detailed information on this can be found here.
Let’s run this example of a sequential chain and see what we get in the trace.
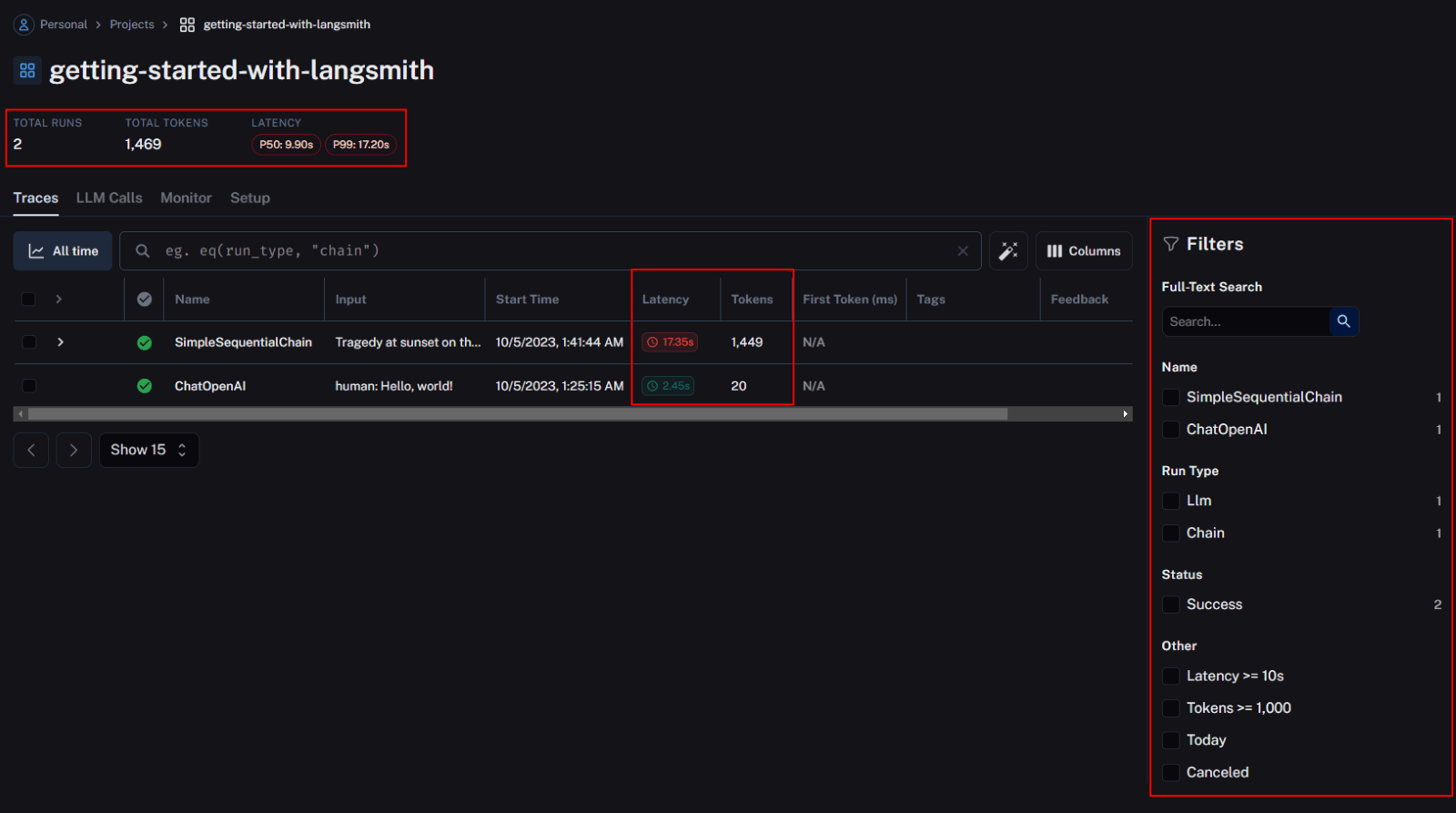
Upon executing the code for this sequential chain and returning to our project, a new trace, ‘SimpleSequentialChain,’ becomes visible.
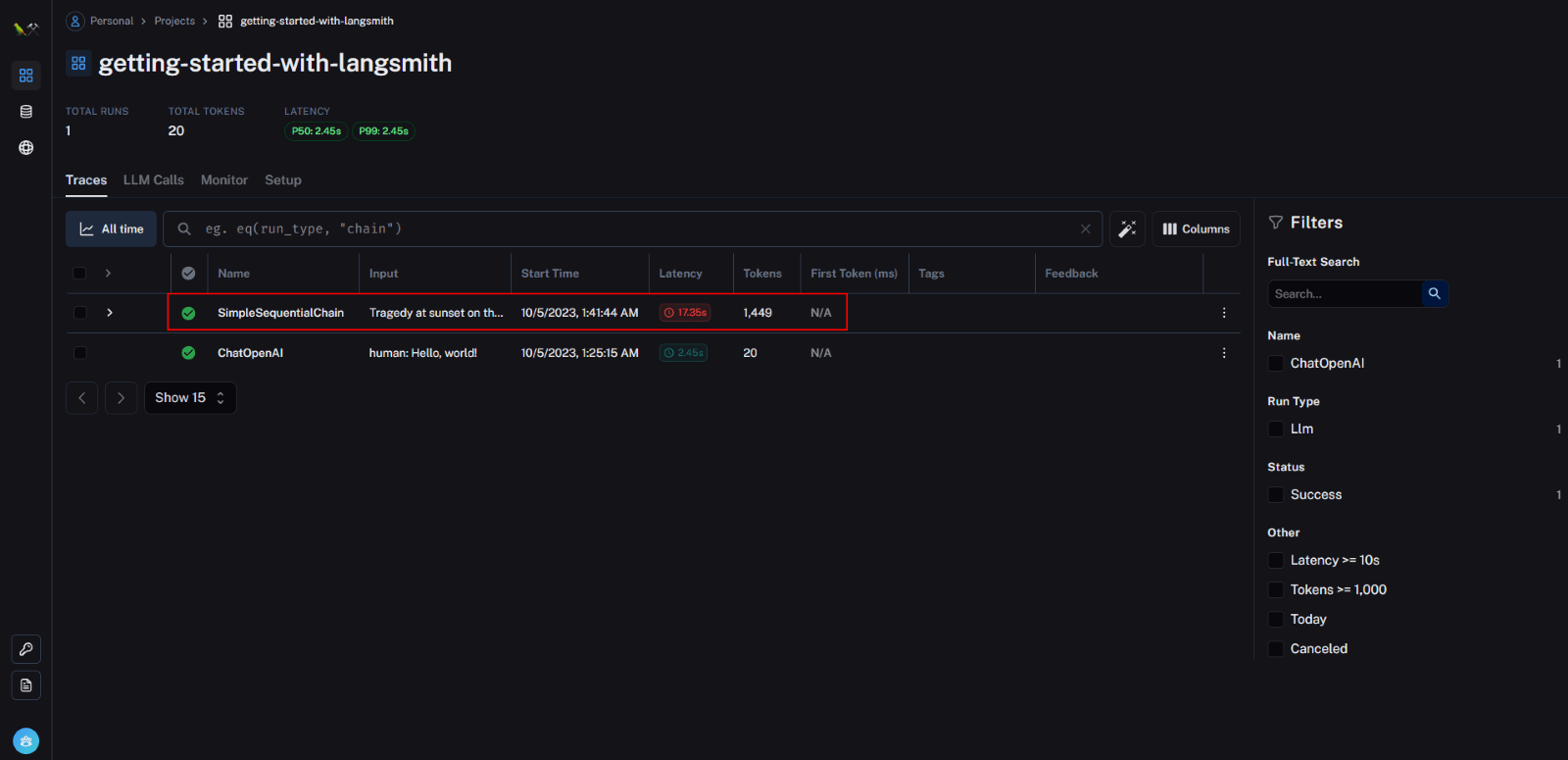
Upon examination, this trace reveals a collection of LLM calls, featuring two distinct LLM call runs within its hierarchy.
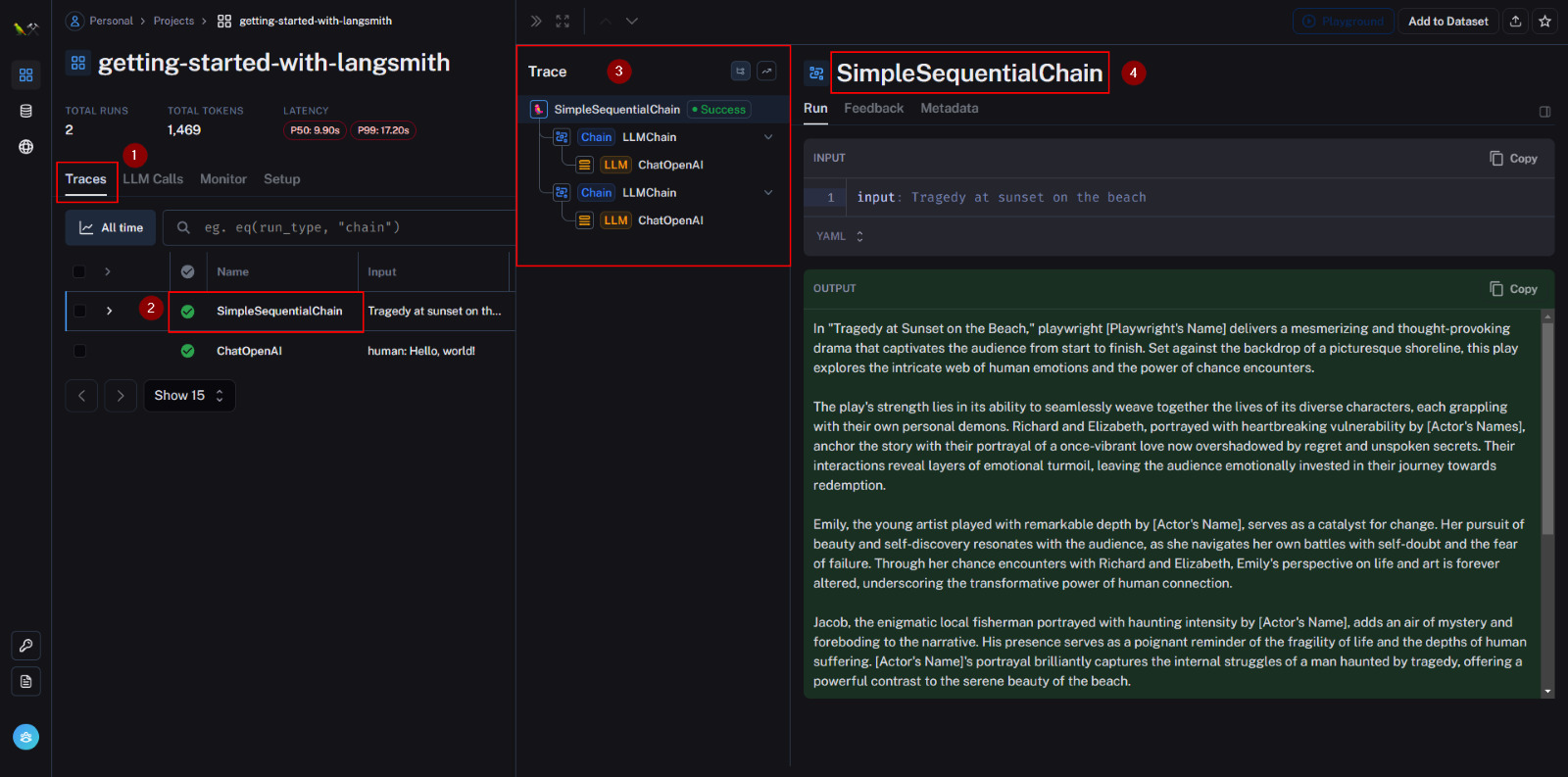
This delineation of execution order becomes apparent; in our example, the initial run entails extracting a title and constructing a synopsis, as displayed in the provided screenshot.
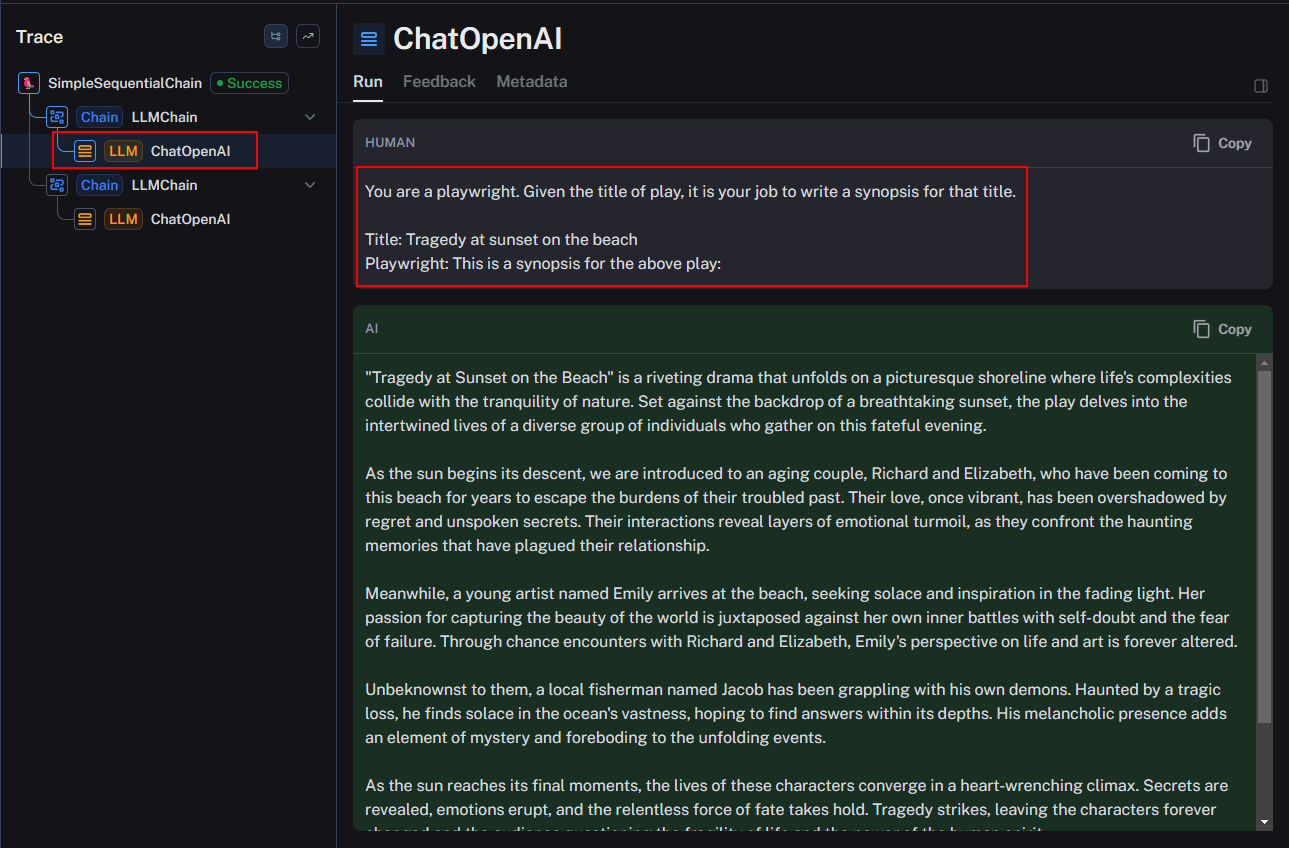
Subsequently, the second run utilizes the synopsis and the output from the first run to generate a review.
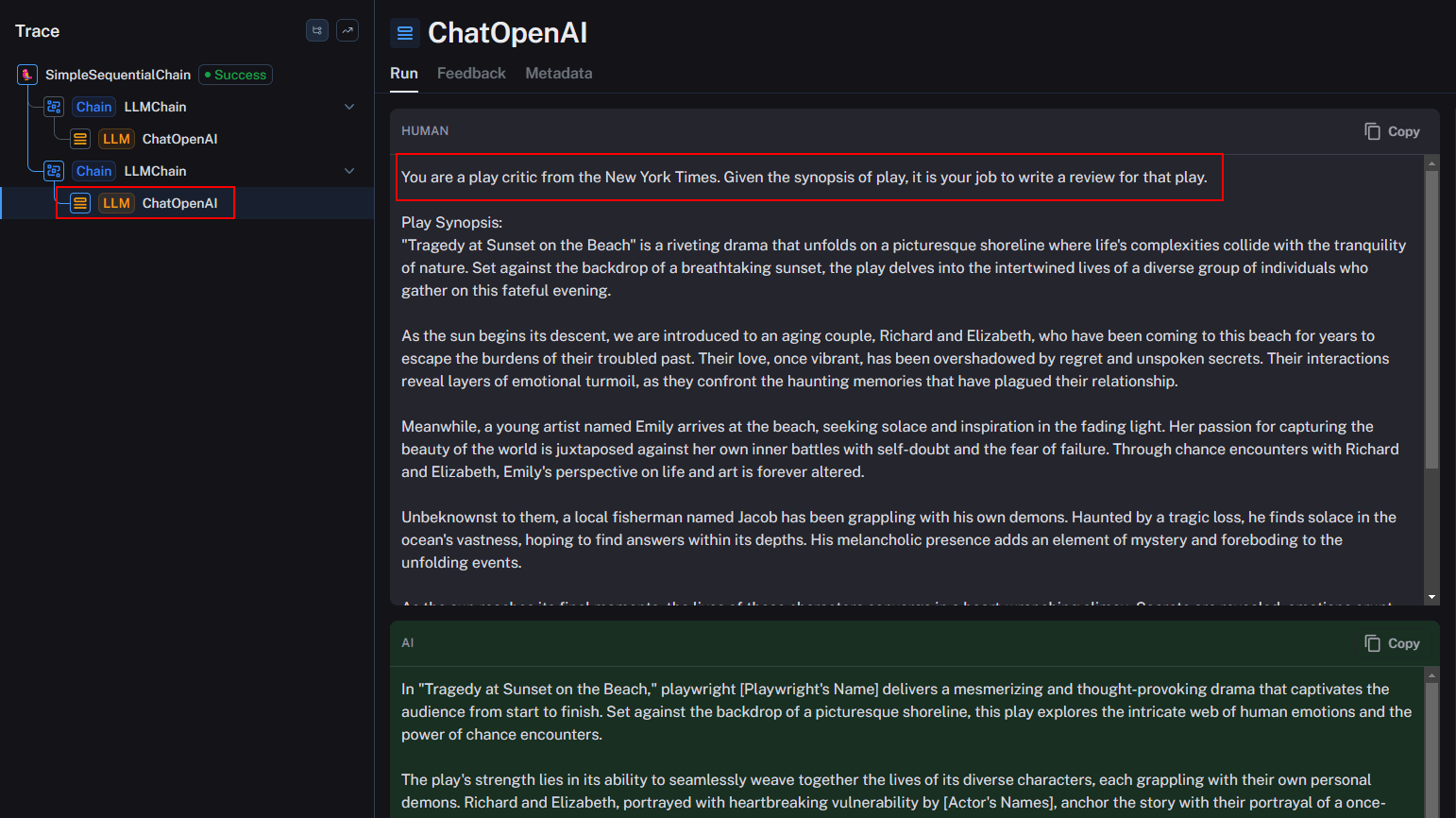
This meticulous tracing mechanism grants us the ability to inspect intermediate results, the messages transmitted to the LLM, and the outputs at each step, all while offering insights into token counts and latency measures.
Furthermore, the option to filter traces based on various parameters adds an additional layer of customization and control.
Trace an Agent
In this segment, we embark on a journey to trace an agent’s inner workings using LangSmith. For those keen to delve deeper into the world of agents, you’ll find comprehensive documentation in LangChain.
To provide a brief overview, we’ve engineered a ZeroShotAgent, equipping it with tools like DuckDuckGo search and paraphrasing capabilities. The agent interacts with user queries, employing these tools in a ReAct(Reason + Act) manner to generate a response.
Here is the code for the agent:
By tracing the agent’s actions, we gain insights into the sequence and tools utilized by the agent, as well as the intermediate outputs it produces. This tracing capability proves invaluable for agent design and debugging, allowing us to identify and resolve errors efficiently.
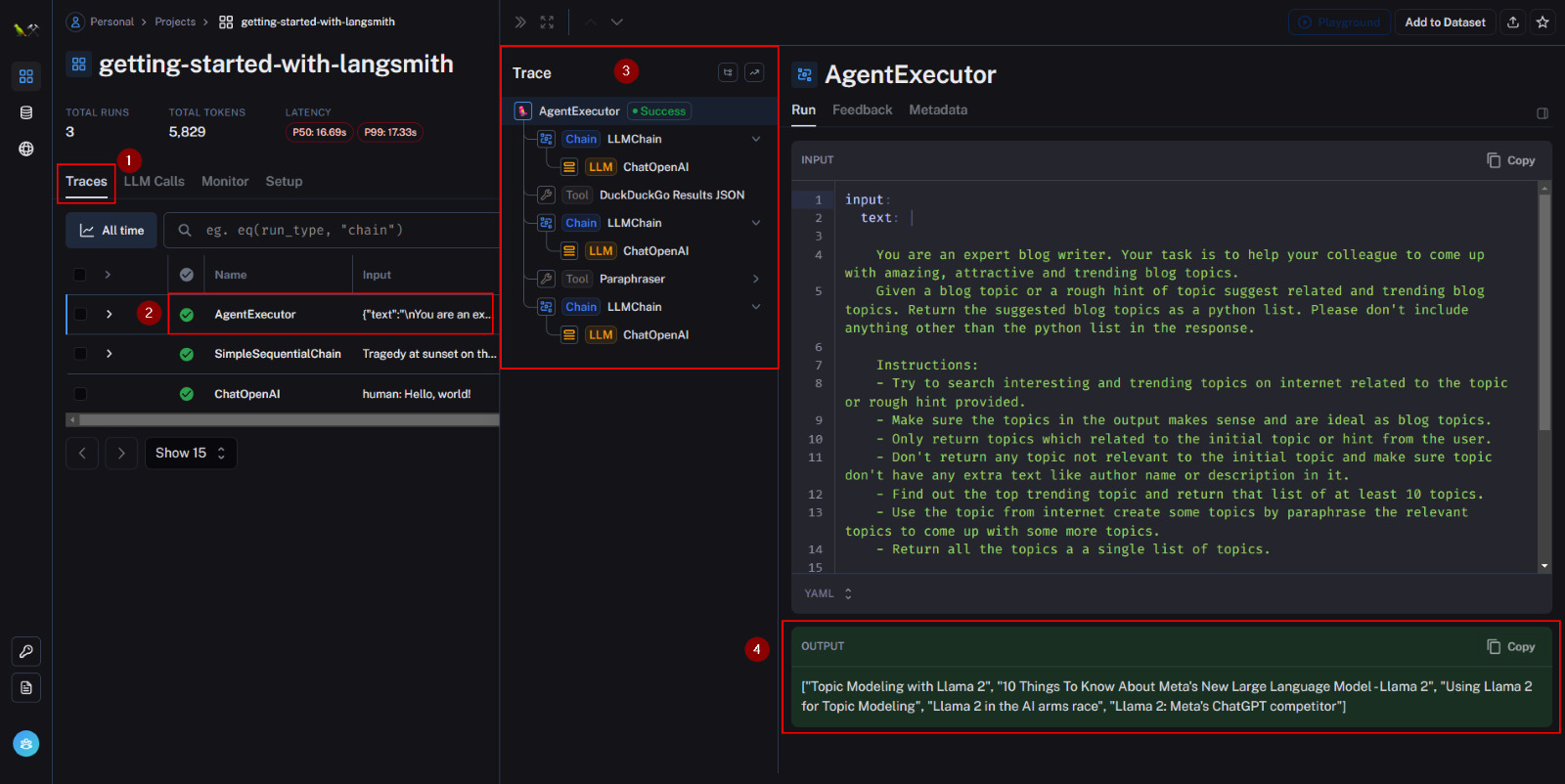
The trace reveals that the agent initiates with an LLM call, proceeds to search for DuckDuckGo Results Json, engages the paraphraser, and subsequently executes two additional LLM calls to generate responses, which in our case are the suggested blog topics.
These traces underscore the critical role tracing plays in debugging and designing effective LLM applications. It’s important to note that all this information is meticulously logged in LangSmith, offering a treasure trove of insights for various applications, which we’ll briefly explore in subsequent sections.
Sharing Your Trace
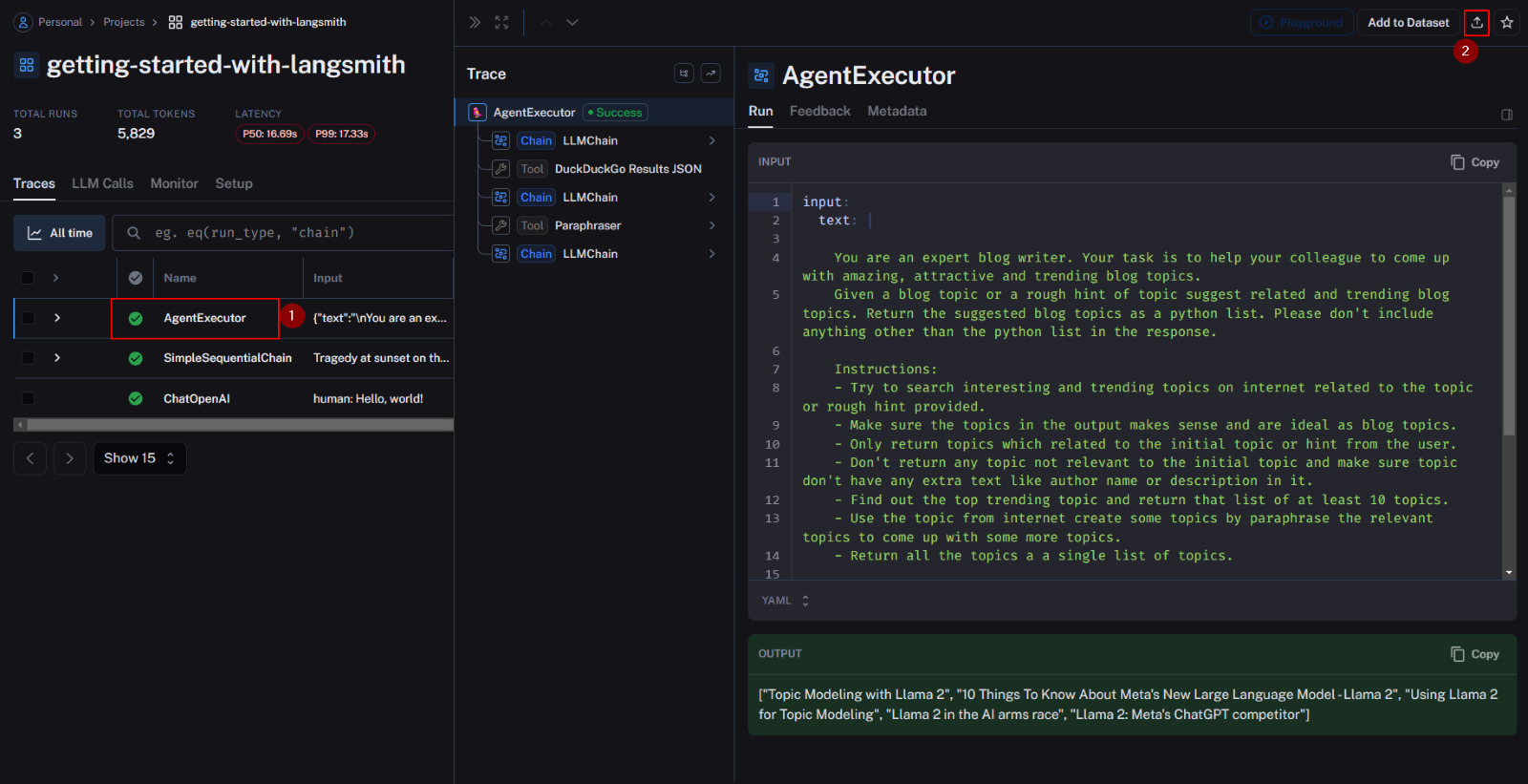
LangSmith simplifies the process of sharing the logged runs. This feature facilitates easy publishing and replication of your work. For example, if you encounter a bug or unexpected output under specific conditions, you can share it with your team or create an issue on LangChain for collaborative troubleshooting.
By simply clicking the share option located at the top right corner of the page, you can effortlessly distribute your run for analysis and resolution
Scenario # 02: Testing and Evaluation
Why is testing and evaluation essential for LLMs?
The development of high-quality, production-grade Large Language Model (LLM) applications is a complex task fraught with challenges, including:
- Non-deterministic Outputs: LLM models operate probabilistically, often yielding varying outputs for the same input prompt. This unpredictability persists even when utilizing a temperature setting of 0, as model weights are not static over time.
- API Opacity: Models underpinning APIs undergo changes and updates, making it imperative to assess their evolving behavior.
- Security Concerns: LLMs are susceptible to prompt injections, posing potential security risks.
- Latency Requirements: Many applications demand swift response times.
These challenges underscore the critical need for rigorous testing and evaluation in the development of LLM applications.
Step-by-Step LLM Evaluation Process
1. Define an LLM Chain
Begin by defining an LLM and creating a simple LLM chain aimed at generating concise responses to specific queries. This LLM will serve as the subject of evaluation and testing.
2. Create a Dataset
Generate a compact dataset comprising question-and-answer pairs related to computer science abbreviations and terms. This data set, containing both questions and their corresponding answers, will be used to evaluate and test the model.
After executing the code, navigate to LangSmith. Within the “Datasets & Testing” section, you’ll find the dataset you’ve created. By expanding it under “examples,” you’ll encounter the six specific examples you’ve defined for evaluation.
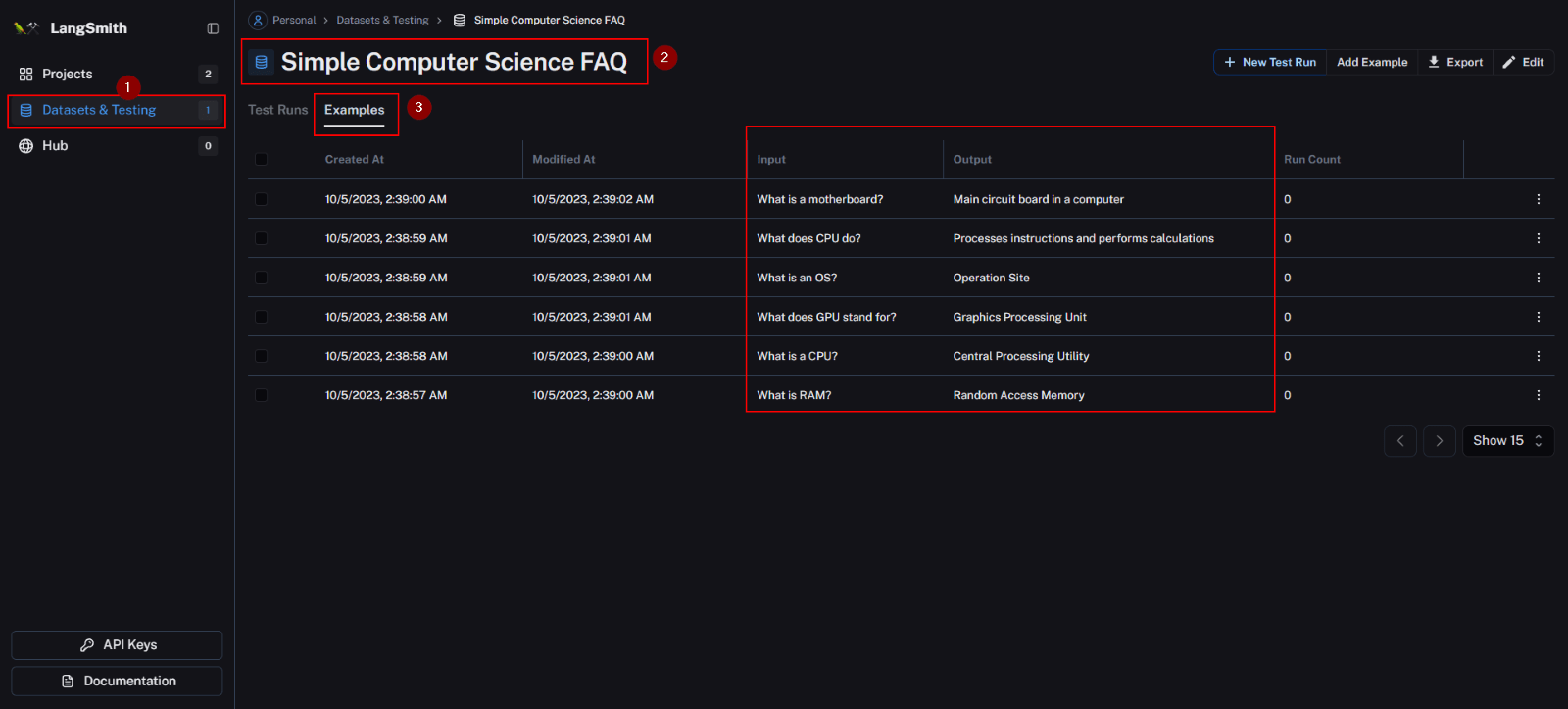
3. Evaluation
For our evaluations, we’ll make use of the LangChain evaluator, specifically focusing on the ‘Correctness: QA evaluation.’ QA evaluators play a vital role in assessing the accuracy of responses to user queries, especially when you have a dataset with reference labels or context documents. Our approach incorporates all three QA evaluators:
- “context_qa”: This evaluator directs the LLM chain to utilize reference “context” (supplied through example outputs) to ascertain correctness.
- “qa”: It prompts an LLMChain to directly appraise a response as either “correct” or “incorrect,” based on the reference answer.
Master LLM Evaluation Metrics and its applications
- “cot_qa”: This evaluator closely resembles “context_qa” but introduces a chain of thought “reasoning” before delivering a final verdict. This approach generally leads to responses that align more closely with human judgments, albeit with a slightly increased token and runtime cost.
Below is the code to kick-start the evaluation of the dataset.
4. Reviewing Evaluation Outcomes
Upon completing the evaluation, LangSmith provides a platform to examine the results. Navigate to the “Dataset & Testing” section, select the dataset used for the evaluation, and access “Test Runs.” You’ll find the designated Test Run Name and feedback from the evaluator.
By clicking on the Test Run Name, you can delve deeper, inspect feedback for individual examples, and view side-by-side comparisons. Clicking on any reference example reveals detailed information.
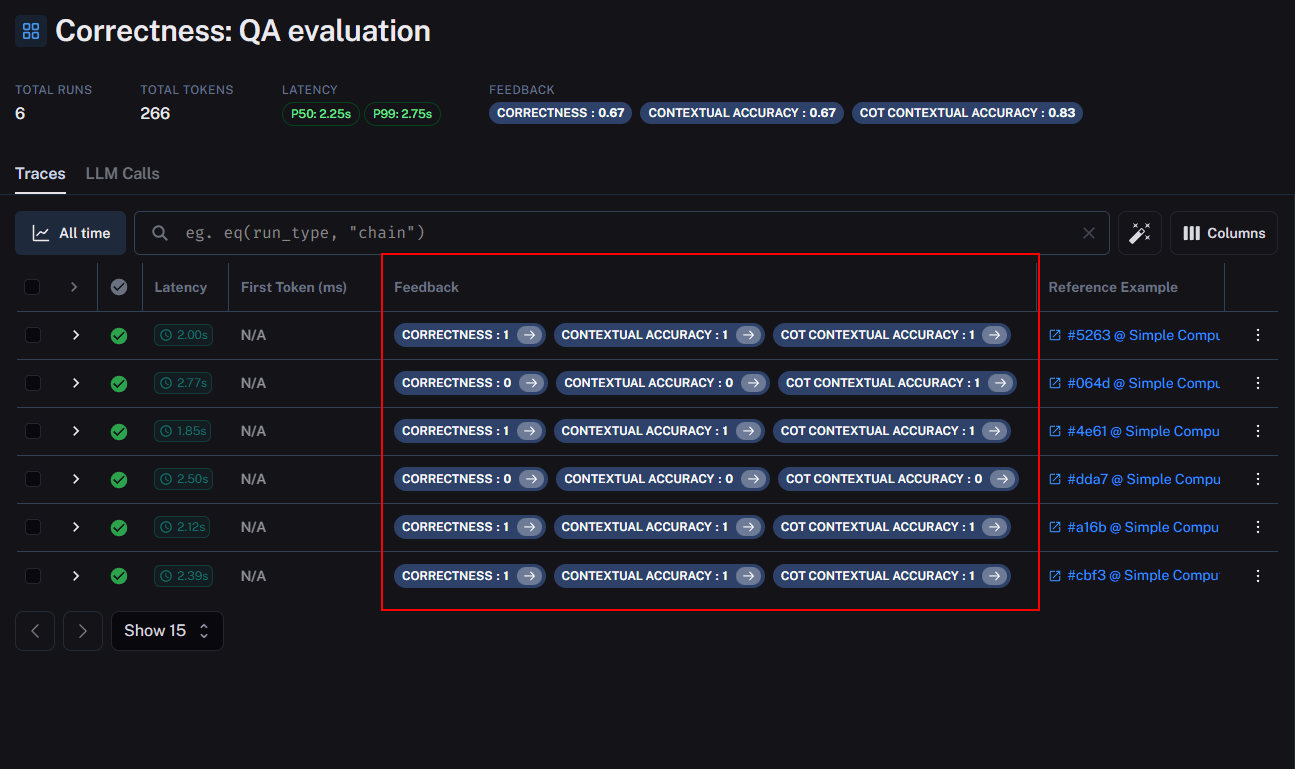
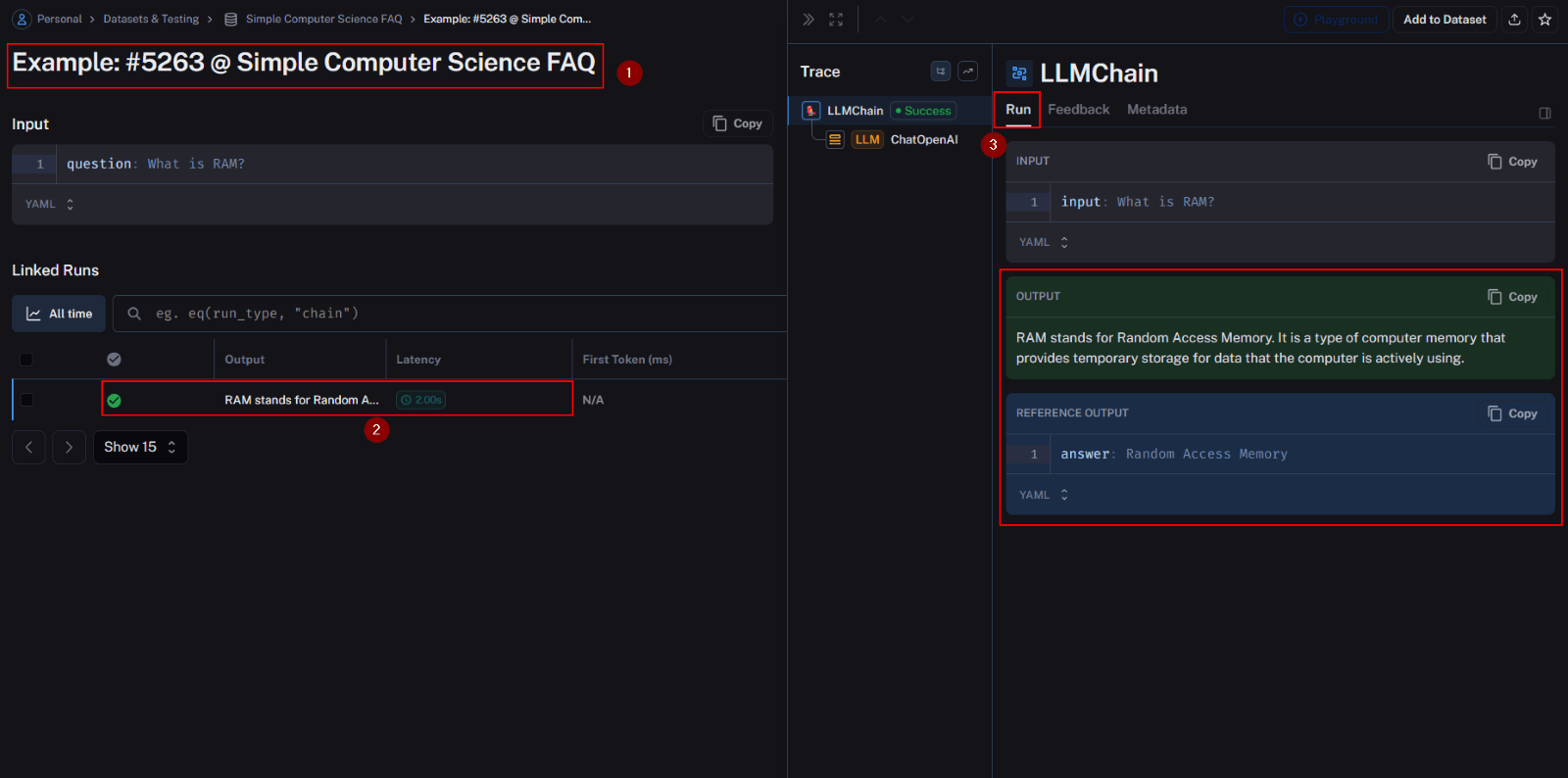
For instance, the first example received a perfect score of 1 from all three evaluators. The generated and expected outputs are presented side by side, accompanied by feedback and comments from the evaluator.
However, in a different example, one evaluator issued a score of 1, while the other two scored it as 0. Upon closer examination, it becomes apparent that there exists a disparity between the generated and expected outputs
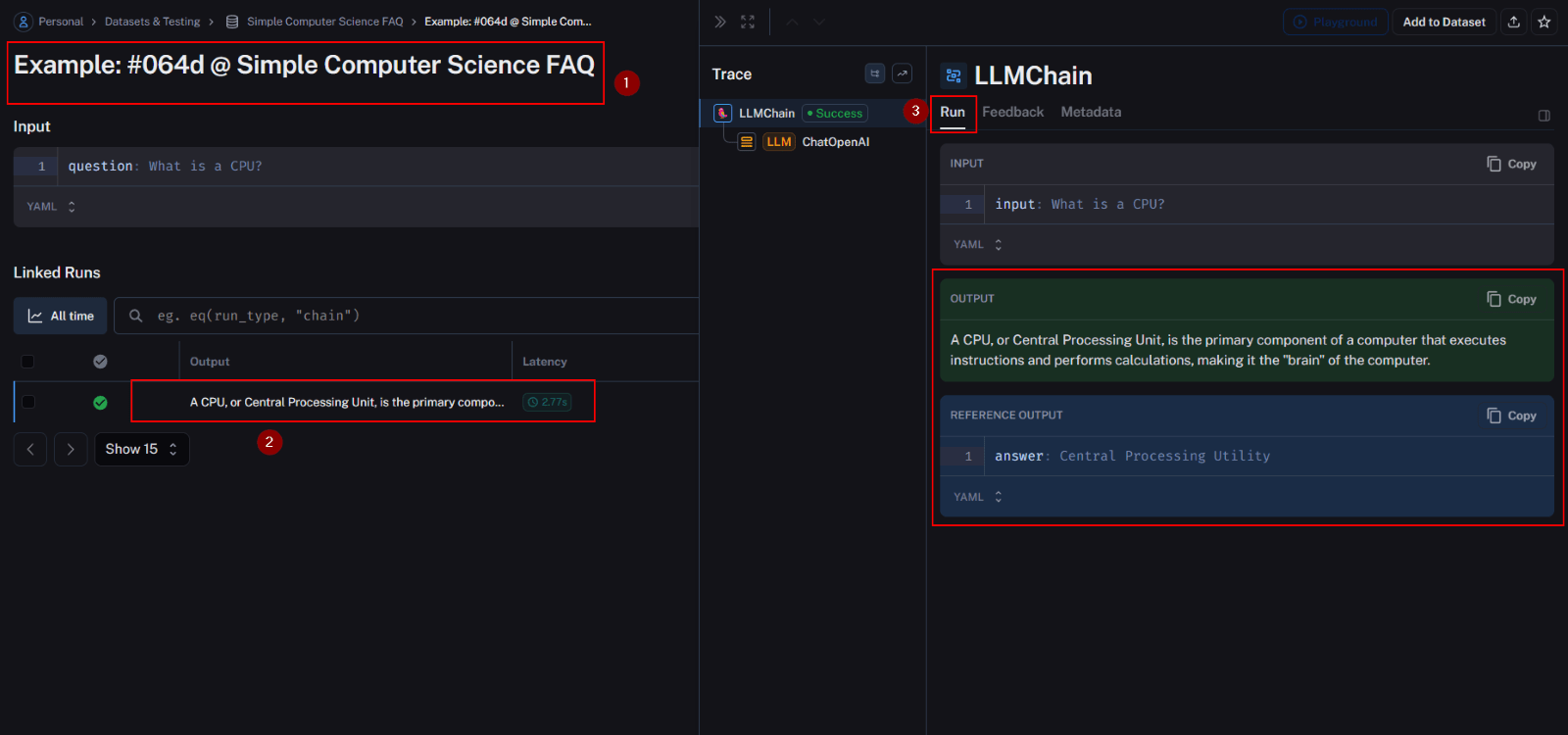
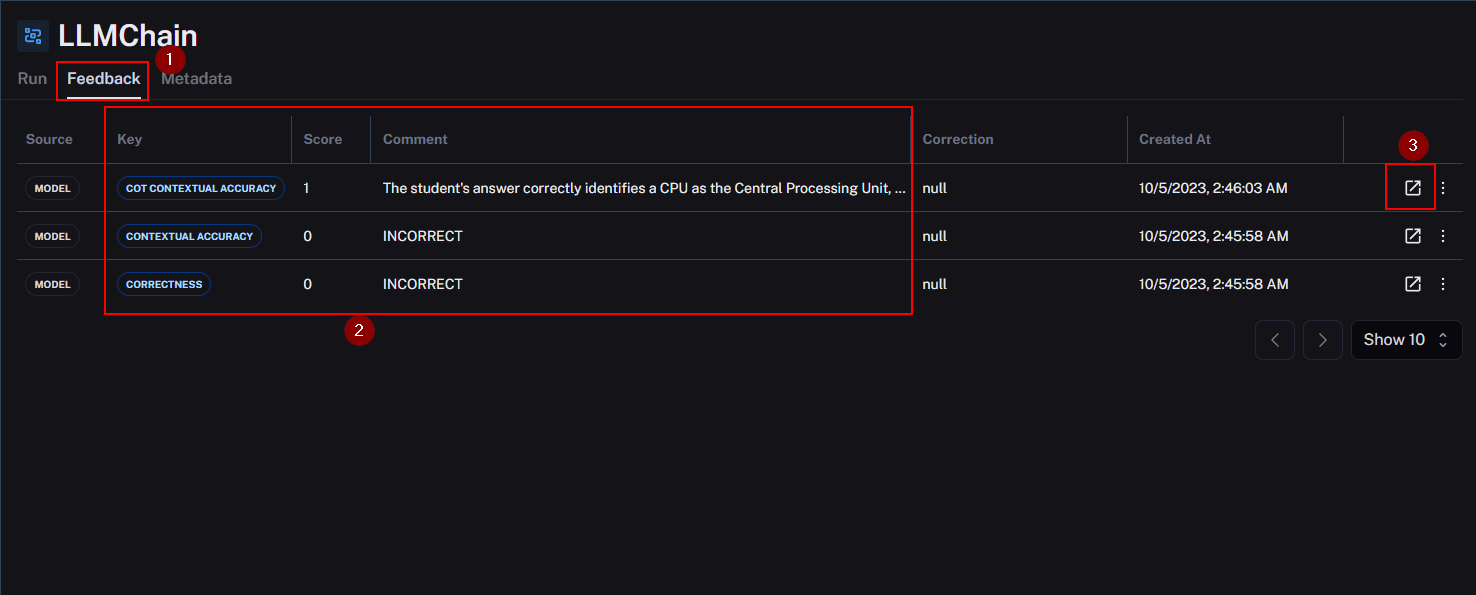
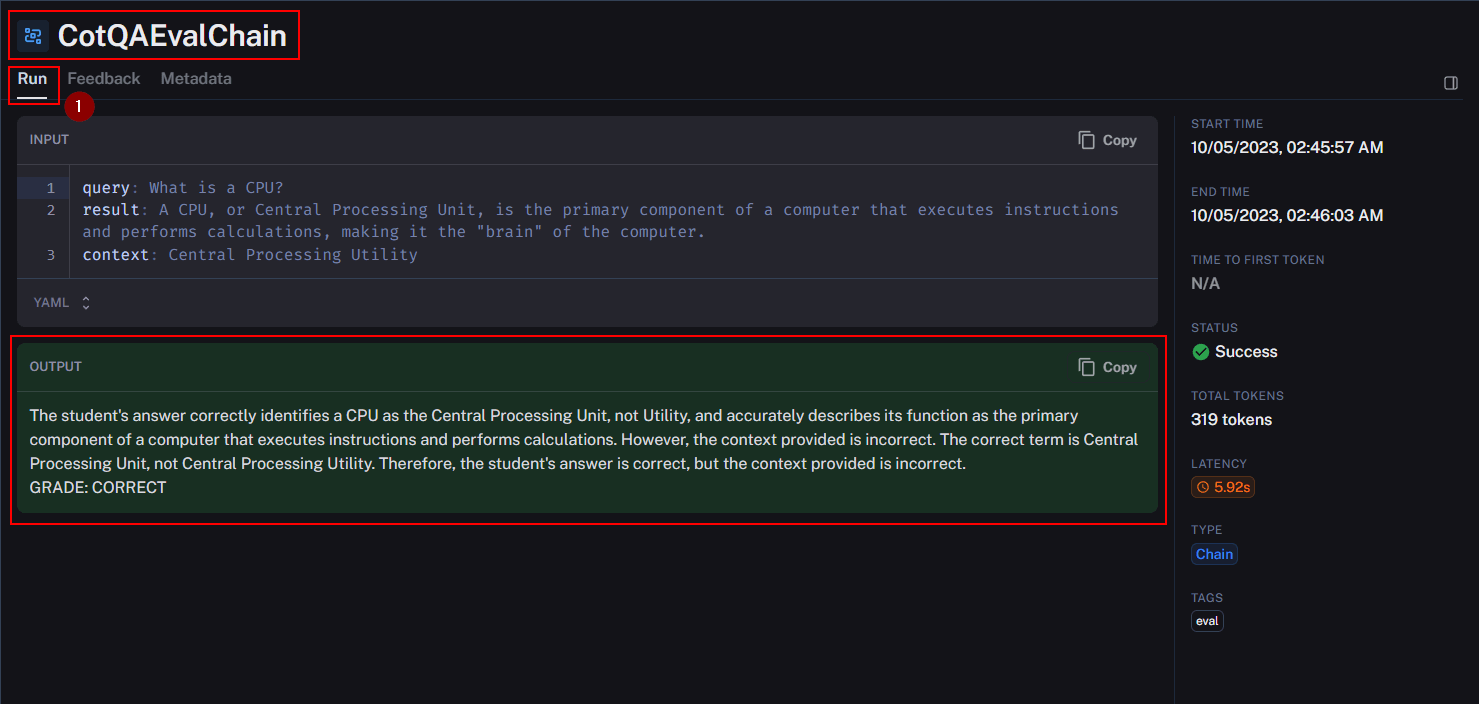
The “cot-qa” evaluator assigned a score of 1, and further exploration of the comments reveals that, although the generated output was correct, discrepancies in the dataset contextually influenced the evaluation. It’s worth noting that the “cot-qa” evaluator spotted this, demonstrating its ability to notice context-related subtleties that other evaluators might miss.
Varied evaluation choices (Delve deeper)
The evaluator showcased in the previous example is but one of several available within LangSmith. Each option serves specific purposes and holds its unique value. For a detailed understanding of each evaluator’s specific functions and to explore illustrative examples, we encourage you to explore LangChain Evaluators, where in-depth coverage of these available options is provided.
Implement the Power of Tracing and Evaluation with LangSmith
In summary, our journey through LangSmith has underscored the critical importance of evaluating and tracing Large Language Model applications. These processes are the cornerstone of reliability and high performance, ensuring that your models meet rigorous standards.
With LangSmith, we’ve explored the power of precise tracing and evaluation, empowering you to optimize your models confidently. As you continue your exploration, remember that your LLM applications hold limitless potential, and LangSmith is your guiding light on this path of discovery.
Thank you for joining us on this transformative journey through the world of LLM Evaluation and Tracing with LangSmith.
