In the dynamic world of artificial intelligence, where advancements shape the future of technology, few innovations stand out as game-changers. Llama 2, Meta’s open-source large language model, is one such remarkable development.
As an accessible tool for both research and commercial applications, it has captured the attention of developers, researchers, and AI enthusiasts worldwide. With its impressive range of pre-trained and fine-tuned generative models, spanning from 7 billion to an astounding 70 billion parameters, it paves the way for groundbreaking applications in AI.
Explore PaLM 2 vs. Llama 2
In this blog, we will be getting started with the this incredible open-source large language model. We will guide you through various methods of accessing it, ensuring that by the end, you will be well-equipped to unlock the power of this remarkable language model for your projects.
Whether you are a developer, researcher, or simply curious about its capabilities, this blog will equip you with the knowledge and tools you need to get started.
Understanding Llama 2
In the ever-evolving landscape of artificial intelligence, language models have emerged as pivotal tools for developers, researchers, and enthusiasts alike. One such remarkable addition to the world of language models is Llama 2. While it may not be the absolute marvel of language models, it stands out as an open-source gem.
Learn about AI and ML from the Top 10 trending AI podcasts
This open-source large language model, opens its doors for both research and commercial use, breaking down barriers to innovation and creativity. It comprises a range of pre-trained and fine-tuned generative text models, varying in scale from 7 billion to a staggering 70 billion parameters.
Among these, the Llama-2-Chat models, optimized for dialogue, shine as they outperform open-source chat models across various benchmarks. In fact, their helpfulness and safety evaluations rival some popular closed-source models like ChatGPT and PaLM.
In this blog, we will explore its training process, improvements over its predecessor, and ways to harness its potential. If you want to use it in your projects, this guide will get you started. So, let us embark on this journey together as we unveil the world of Llama 2 and discover how it can elevate your AI (Artificial Intelligence) endeavors.
Llama 2: The Evolution and Enhanced Features
It represents a significant leap forward from its predecessor, Llama 1, which garnered immense attention and demand from researchers worldwide. With over 100,000 requests for access, the research community demonstrated its appetite for powerful language models.
Compare the Llama Models: Llama 3 vs Llama 3.1 vs Llama 3.2
Building upon this foundation, Llama 2 emerges as the next-generation offering from Meta, succeeding its predecessor, Llama 1. Unlike Llama 1, which was released under a non-commercial license for research purposes, it takes a giant stride by making itself available freely for both research and commercial applications.

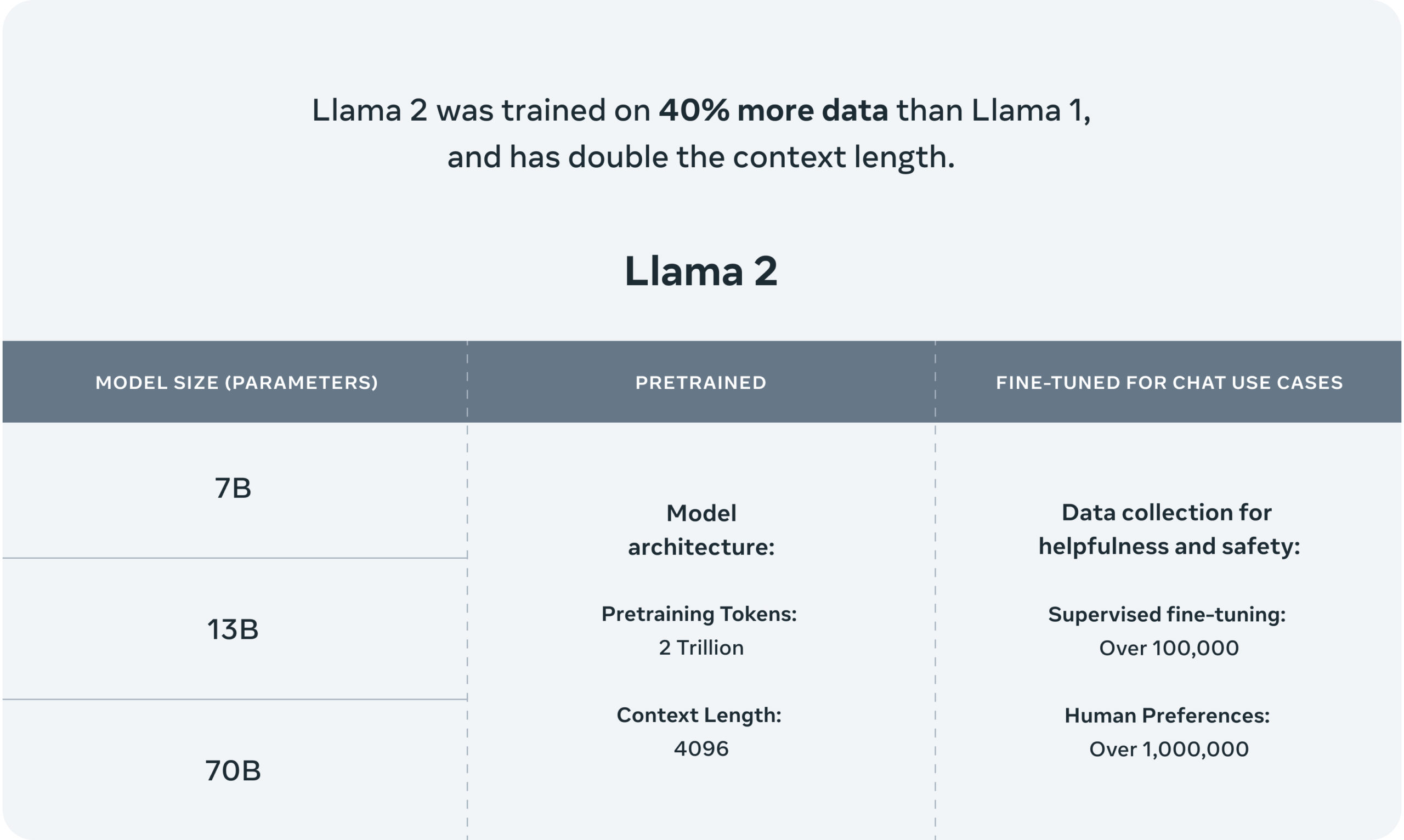
This second-generation model comes with notable enhancements, including pre-trained versions with parameter sizes of 7 billion, 13 billion, and a staggering 70 billion. The training data has been expanded, encompassing 40% more information, all while boasting double the context length compared to Llama 1, with a context length of 4,096 tokens.
Notably, the chat models, tailored for dialogue applications, have been fine-tuned with the assistance of over 1 million new human annotations. As we delve deeper, we will explore the capabilities and the numerous ways to access this remarkable language model.
Exploring your Path to Llama 2: Six Access Methods You Must Learn
Accessing the power of it is easier than you might think, thanks to its open-source nature. Whether you are a researcher, developer, or simply curious, here are six ways to get your hands on the Llama-2 model right now:

Download Llama 2 Model
Since this large language model is open-source, you can freely install it on your desktop and start using it. For this, you will need to complete a few simple steps.
Explore Best 5 No-Code AI Tools to Assist Software Developers
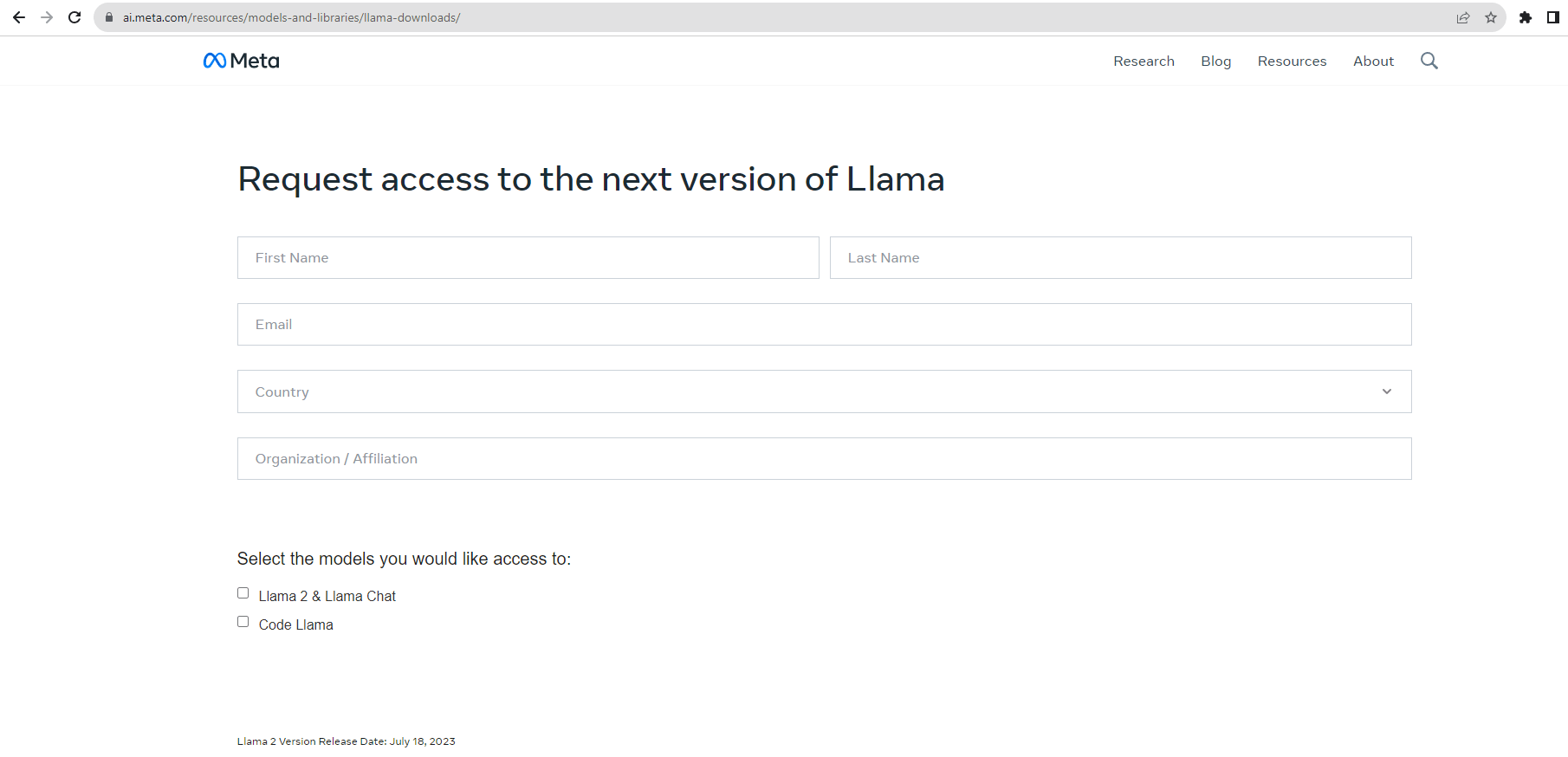
- First, head to Meta AI’s official Llama 2 download webpage and fill in the requested information. Make sure you select the right model you plan on utilizing.
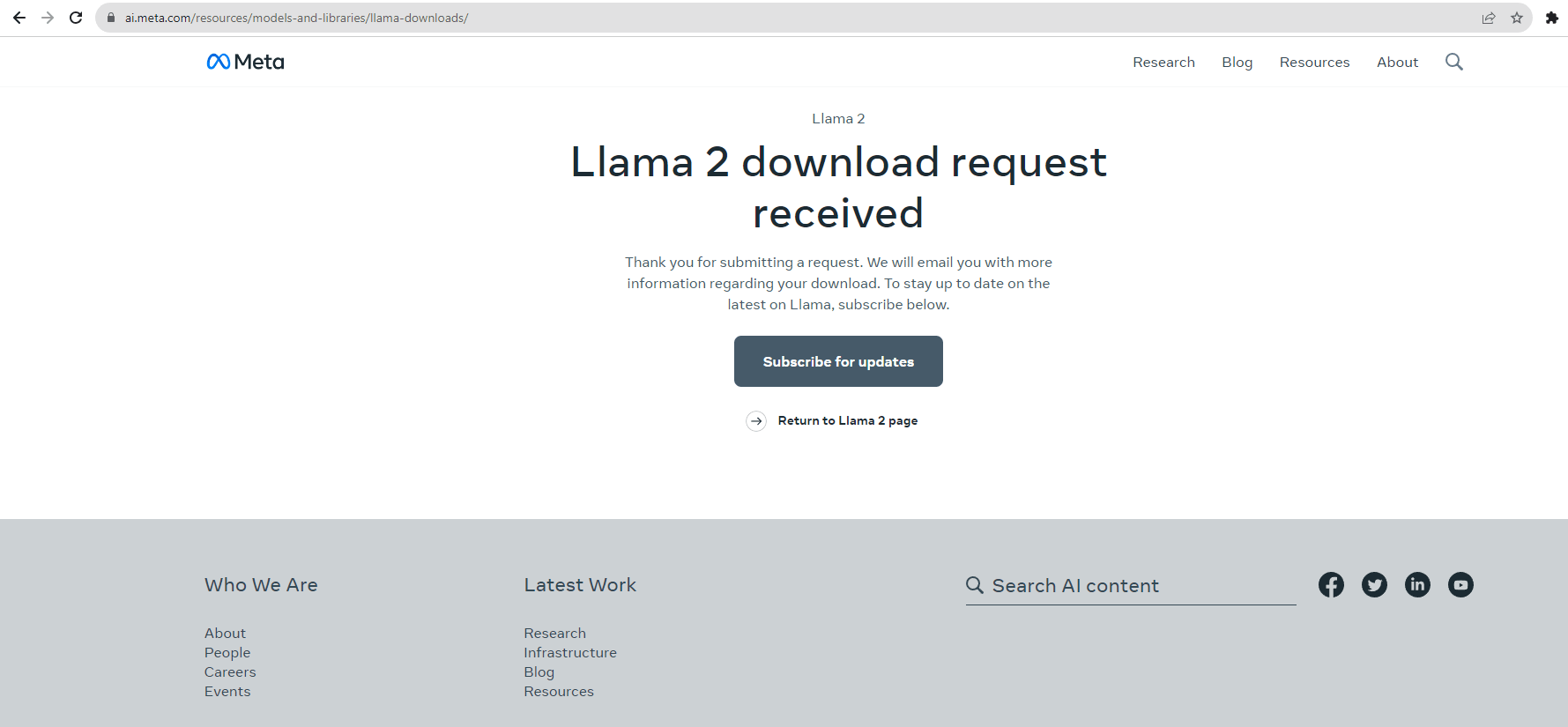
- Upon submitting your download request, you can expect to encounter the following page. You will receive an installation email from Meta with more information regarding the download.
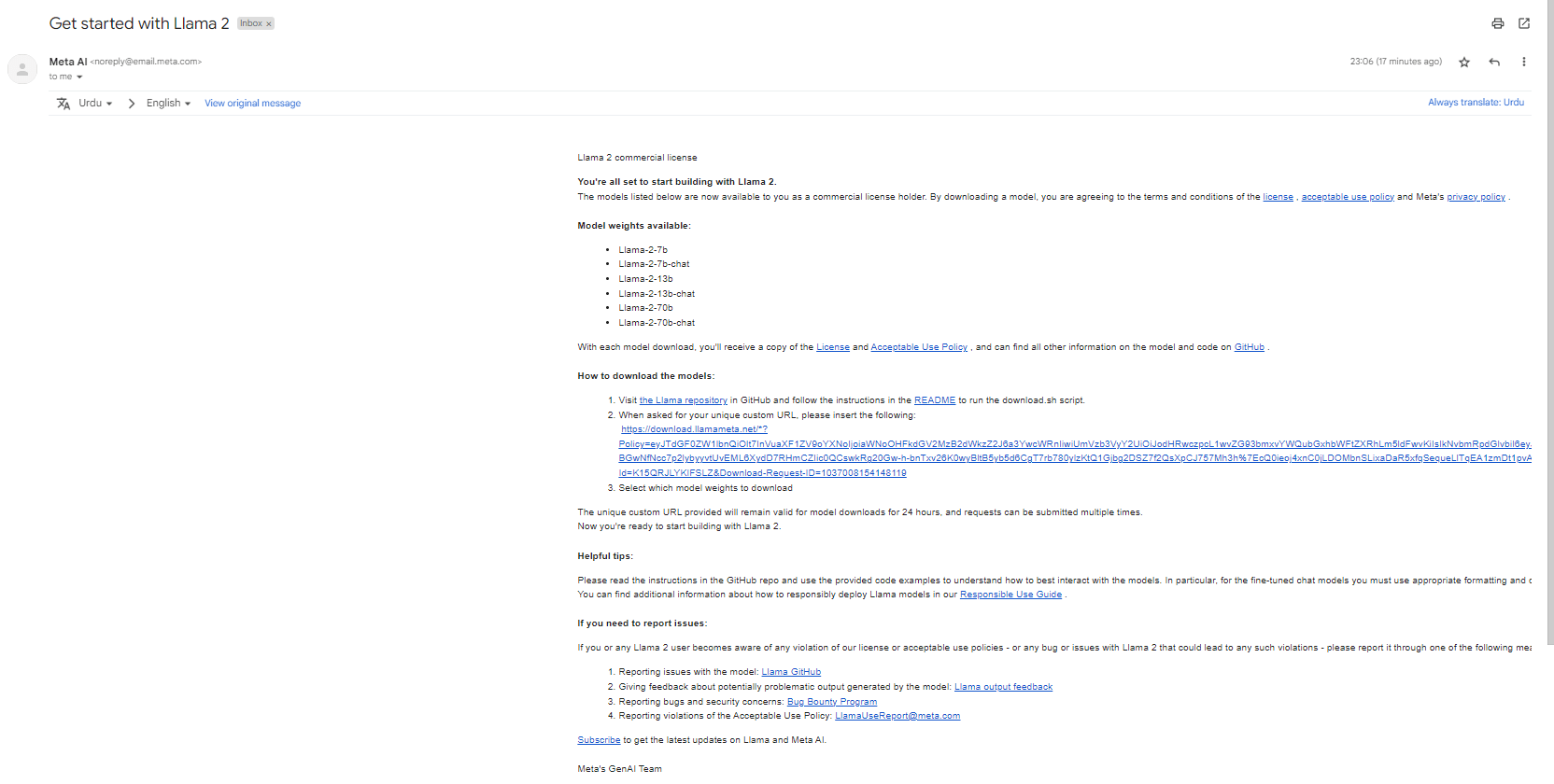
- Once the email has been received, you can proceed with the installation by adhering to the instructions detailed within the email. To begin, the initial step entails accessing the Llama repository on GitHub.
- Download the code and extract the ZIP file to your desktop. Subsequently, proceed by adhering to the instructions outlined in the “Readme” document to start using all available models.
Its models are also available in the Hugging Face organization of Llama-2 from Meta. All the available models are accessible there as well. To use these models from Hugging Face, we still need to submit a download request to Meta, and additionally, we need to fill out a form to enable the use of Llama 2 in Hugging Face.

To access its models on Hugging Face, follow these steps:
- Navigate to the Hugging Face organization of Llama 2 from Meta.
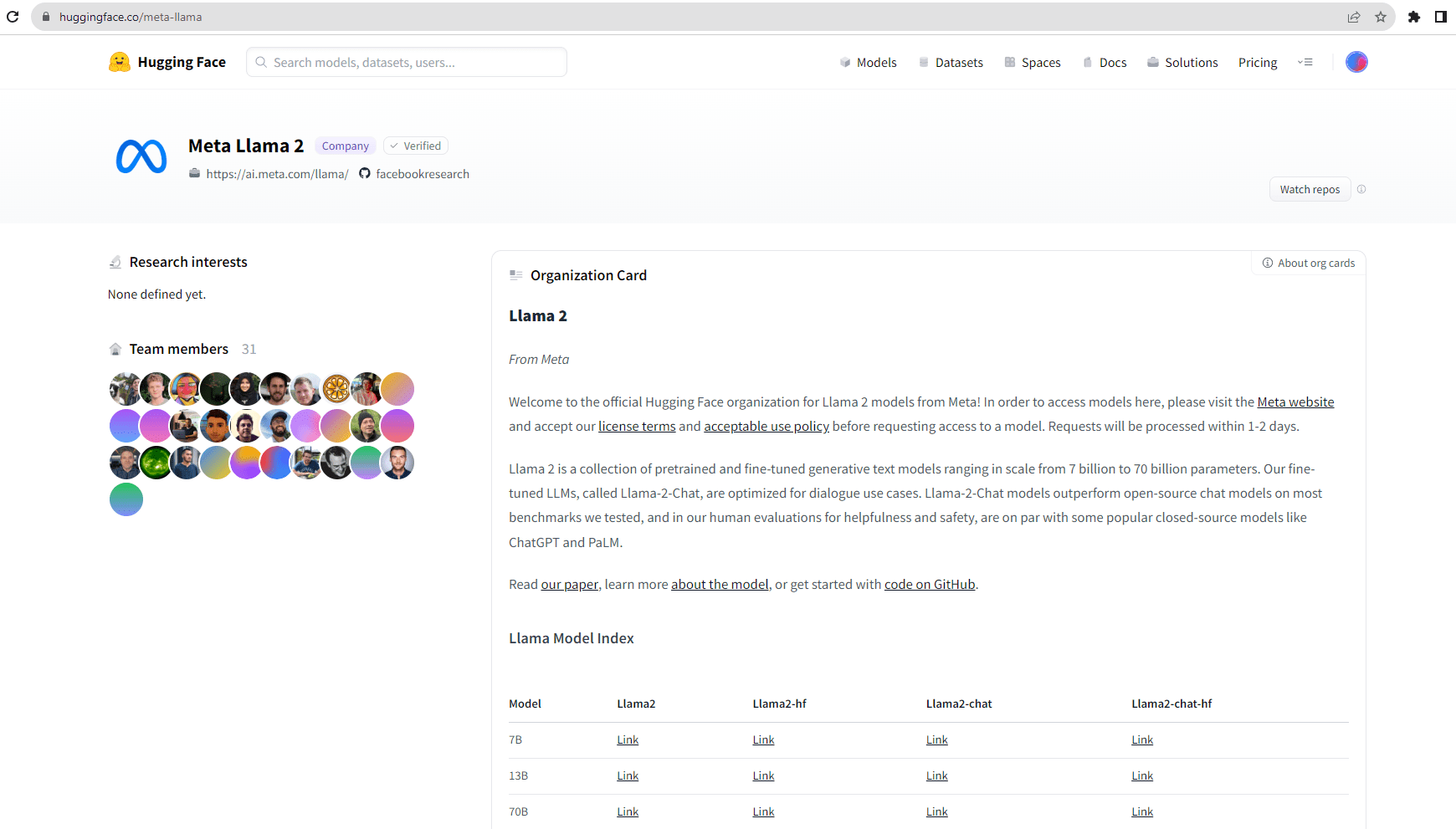
- You can see a “Models” tab on the page which lists all the available models.
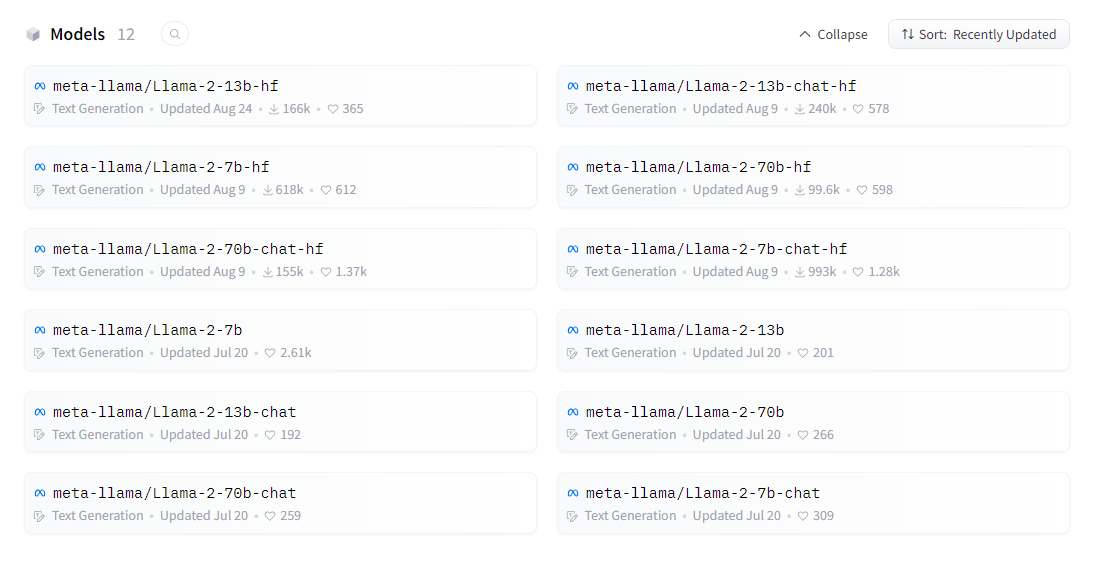
- Click on the model you want to utilize, in our case, meta-llama/Llama-2-7b-hf.
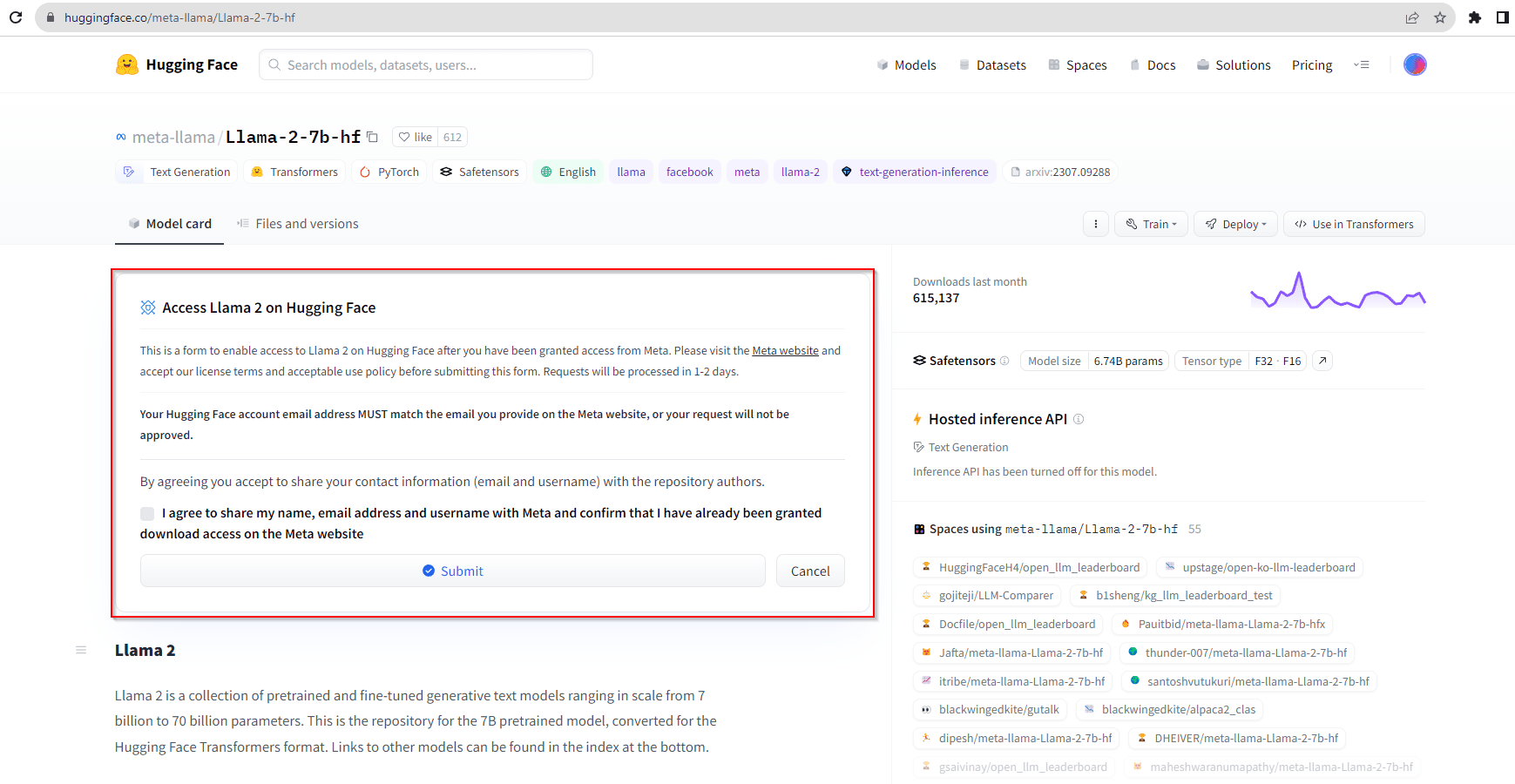
- In the Access Llama 2 on Hugging Face card enter the email you used to send out the download request.
Note: Please ensure that the email you use on Hugging Face matches the one you used to request Llama 2 download permission from Meta.
Utilize the Quantized Model from Hugging Face
In addition to the models from the official Meta Llama 2 organization, there are some quantized models also available on Hugging Face.
If you search for Llama in the Hugging Face search bar. You will see a list of models available in Hugging Face. You can see that models from meta-llama the official organization are available but there are other models also available.

These models are the quantized version of the same Llama-2 models. Like the model, TheBloke/Llama-2-7b-Chat-GGUF contains GGUF format model files for Meta Llama 2’s Llama 2 7B Chat.
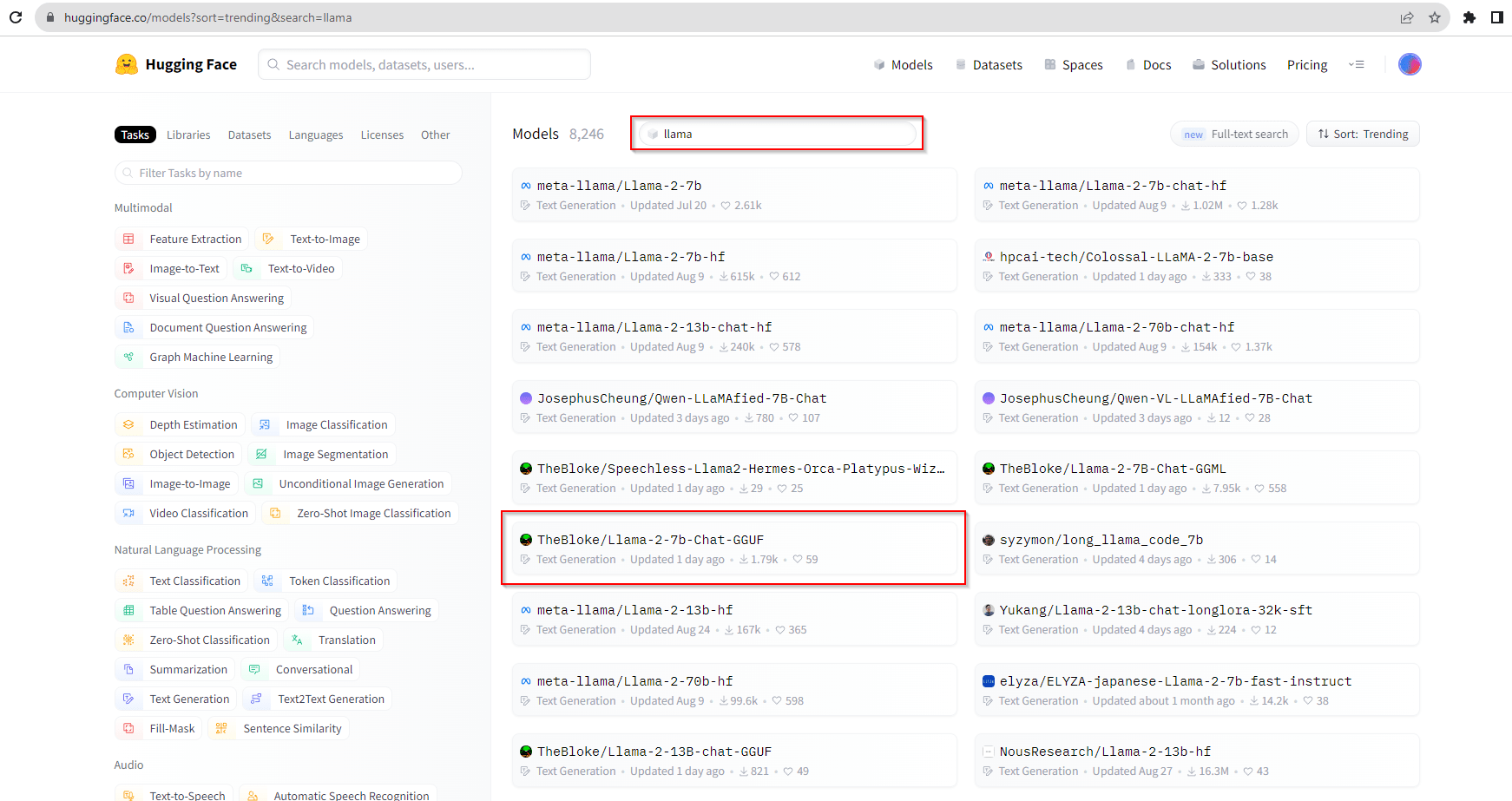
The key advantage of these compressed models lies in their accessibility. They are open-source and do not necessitate users to request downloads from either Meta or Hugging Face. Although they are not the complete, original models, these quantized versions allow users to harness the capabilities of the model with reduced computational requirements.
Deploy Llama 2 on Microsoft Azure
Microsoft and Meta have strengthened their partnership, designating Microsoft as the preferred partner for Llama 2. This collaboration brings Llama 2 into the Azure AI model catalog, granting developers using Microsoft Azure the capability to seamlessly integrate and utilize this powerful language model.
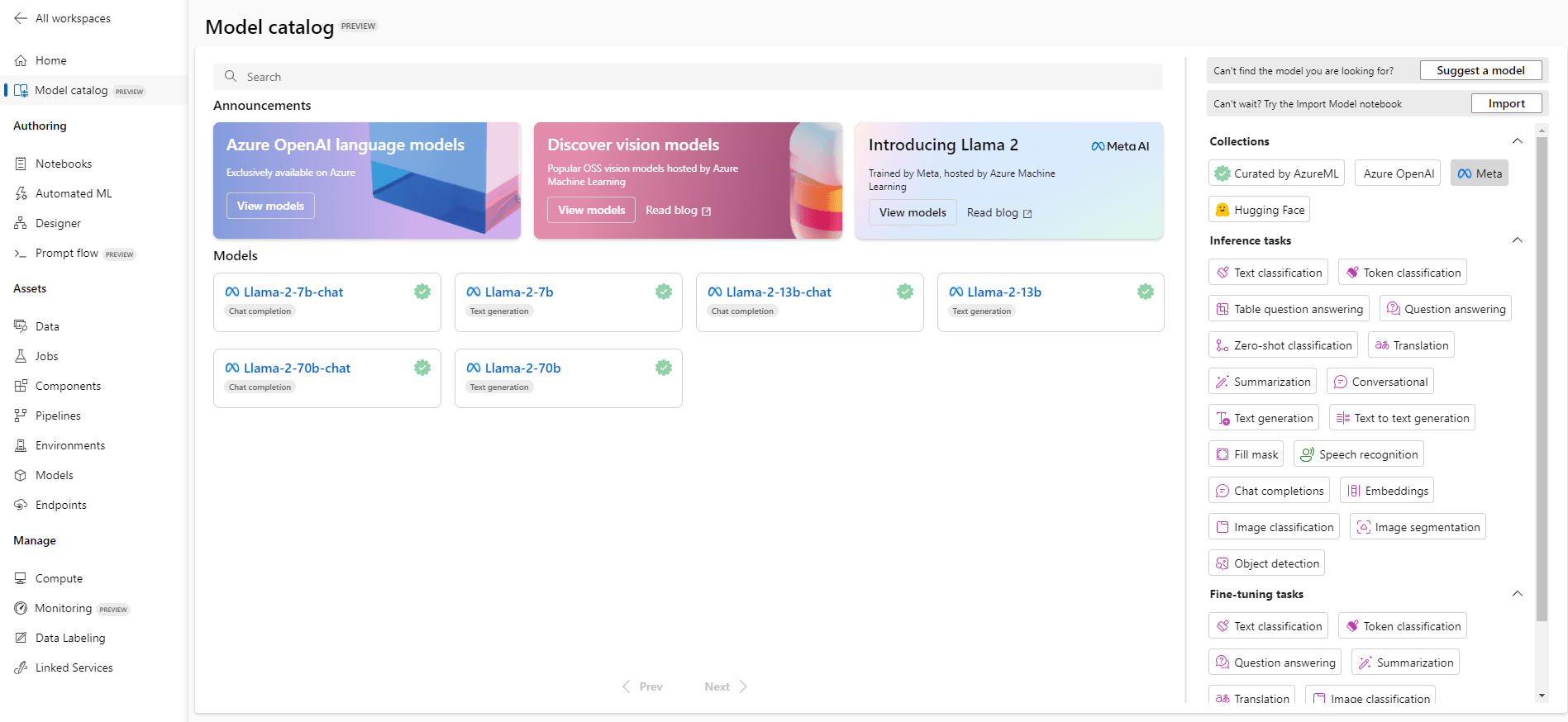
Within the Azure model catalog, you can effortlessly locate the Llama 2 model developed by Meta. Microsoft Azure simplifies the fine-tuning of Llama 2, offering both UI-based and code-based methods to customize the model according to your requirements. Furthermore, you can assess the model’s performance with your test data to ascertain its suitability for your unique use case.
Harness Llama 2 as a cloud-based API
Another avenue to tap into the capabilities of the Llama 2 model is through the deployment of Llama 2 models on platforms such as Hugging Face and Replicate, transforming it into a cloud API. By leveraging the Hugging Face Inference Endpoint, you can establish an accessible endpoint for your Llama 2 model hosted on Hugging Face, facilitating its utilization.
Additionally, it is conveniently accessible through Replicate, presenting a streamlined method for deploying and employing the model via API. This approach alleviates worries about the availability of GPU computing power, whether in the context of development or testing.
It enables the fine-tuning and operation of models in a cloud environment, eliminating the need for dedicated GPU setups. Serving as a cloud API, it simplifies the integration process for applications developed on a wide range of technologies.
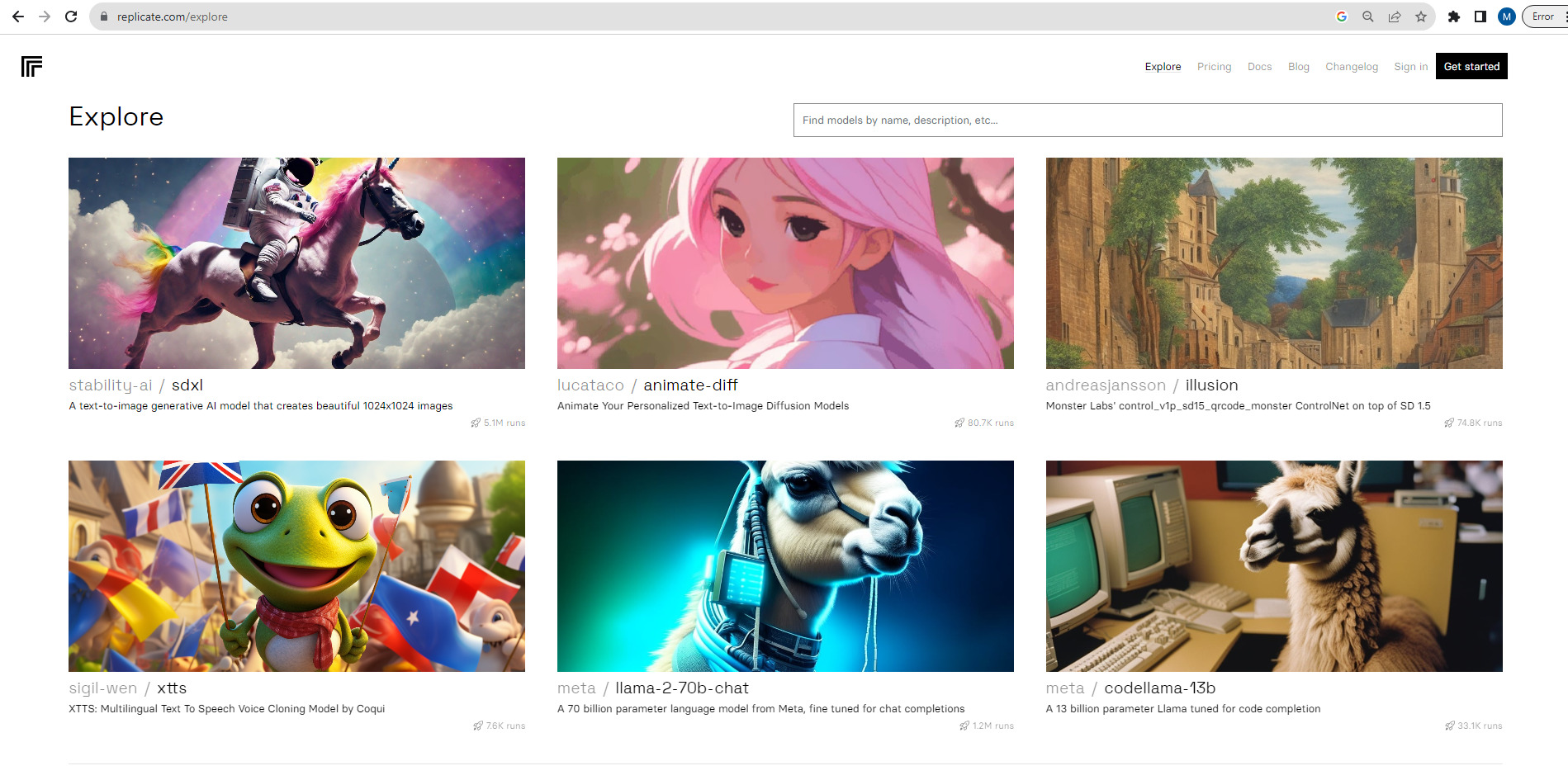
Online Interactions with Llama 2
Experience its capabilities online through platforms like llama2.ai where you can freely engage with different models. Customize your interactions by adjusting parameters such as system prompt, max token, and randomness, offering a user-friendly gateway to explore the model’s creative AI potential.
This demo provides a non-technical audience with the opportunity to submit queries and toggle between chat modes, simplifying the experience of interacting with Llama 2’s generative abilities.
Offline Llama 2 Interaction with LM Studio
With LM Studio, you have the power to run LLMs (Large Language Models) offline on your laptop, employ models through an intuitive in-app Chat UI or compatible local servers, access model files from Hugging Face repositories, and discover exciting new LLMs right from the app’s homepage.
LM_Studio_Llama2
LM Studio empowers you to engage with Llama 2 models offline. Here is how it works:
- First, download LM Studio from https://lmstudio.ai/.
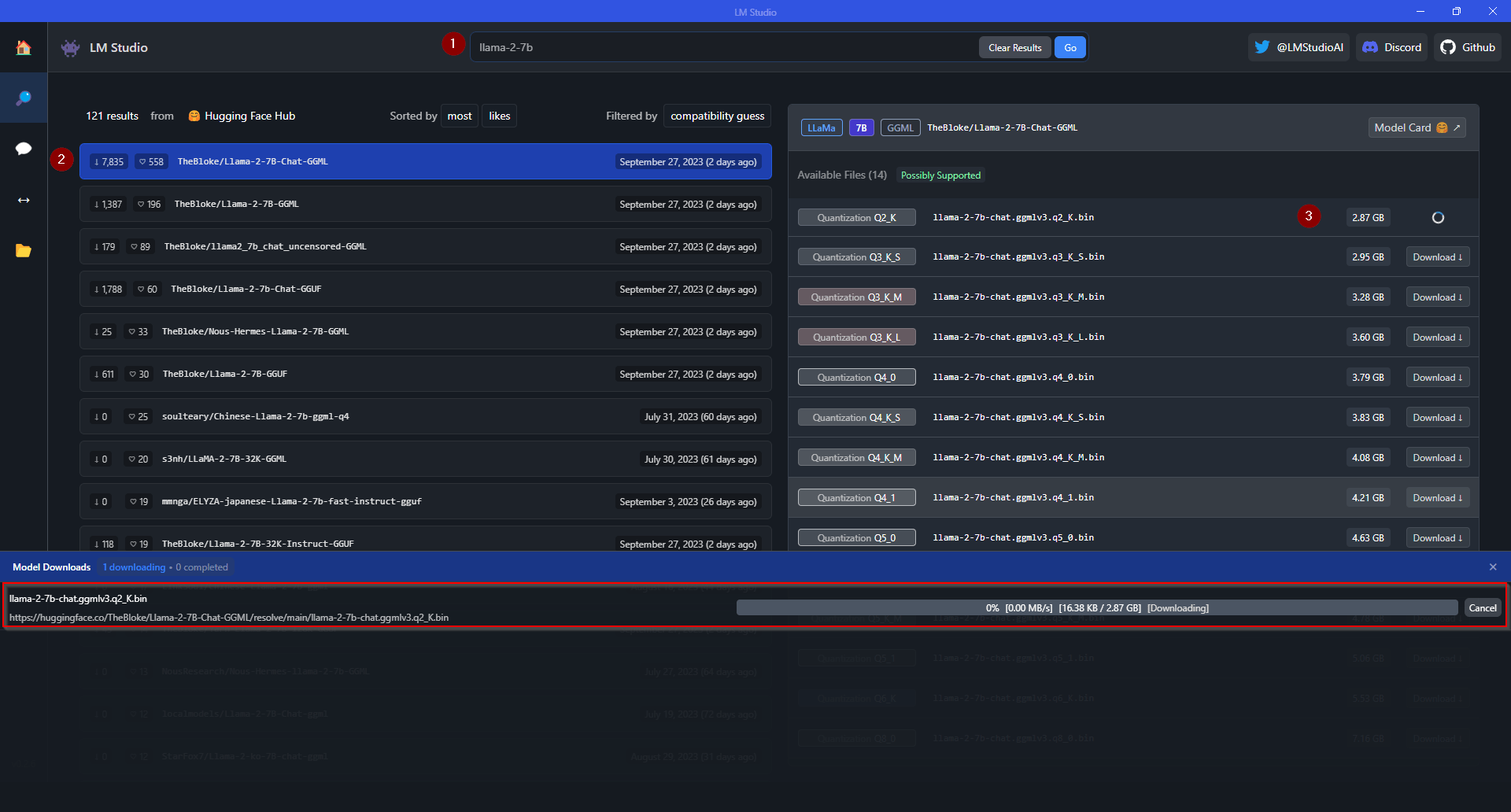
- Once installed, search for your desired Llama 2 model, such as Llama 2 7b. You will find a comprehensive list of repositories and quantized models on Hugging Face. Select your preferred repository and initiate the model download by clicking the link on the right. Monitor the download progress at the bottom of the screen.
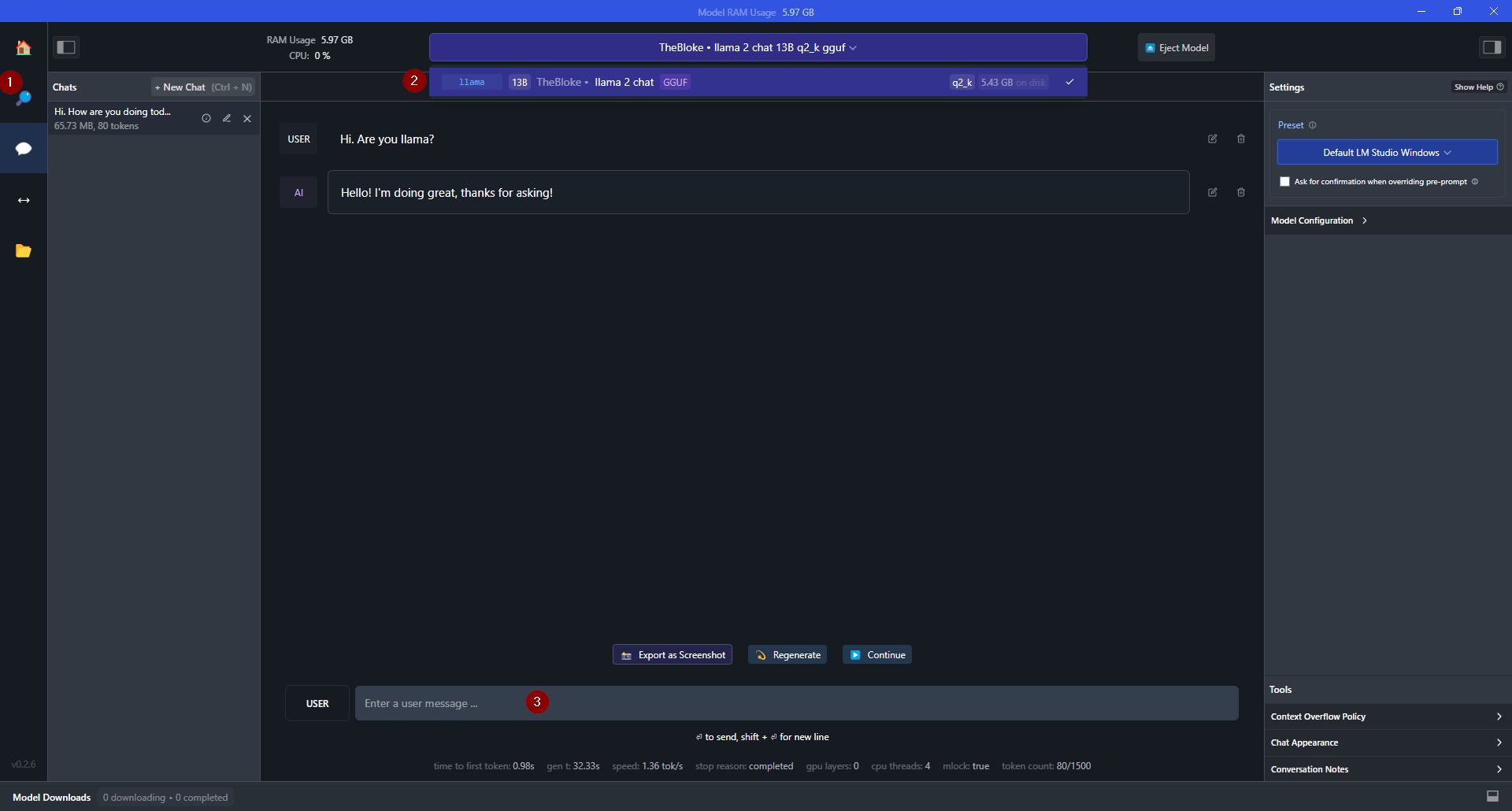
- After the model is downloaded, click the AI Chat icon, select your model, and start a conversation with it. LM Studio offers a seamless offline experience, enabling you to explore the potential of Llama 2 models with ease.
In summary, this blog has guided you on an exploration of an open-source language model. We analyzed its development, pointed out its unique features, and gave a detailed overview of six methods to use it.
These methods are suitable for developers, researchers, and anyone interested in their potential. Armed with this understanding, you are now well-equipped to unlock the capabilities of Llama 2 for your individual AI initiatives and pursuits.