

Artificial intelligence (AI) and generative AI may be the most important technology of any lifetime. This insight underscores the transformative power of AI in today’s world.
At the heart of these many AI applications lies the vector embedding model – a tool that translates complex data into meaningful vectors, enabling machines to understand and generate human-like content. Hence, selecting the right vector embedding model isn’t just a technical decision, but pivotal to the success of your AI initiatives.
In this guide, we’ll delve into the essentials of vector embedding models and provide actionable insights to help you make informed choices for your AI applications. Let’s look into the right tools you will need to unleash the true potential of generative AI.
What are Vector Embedding Models?
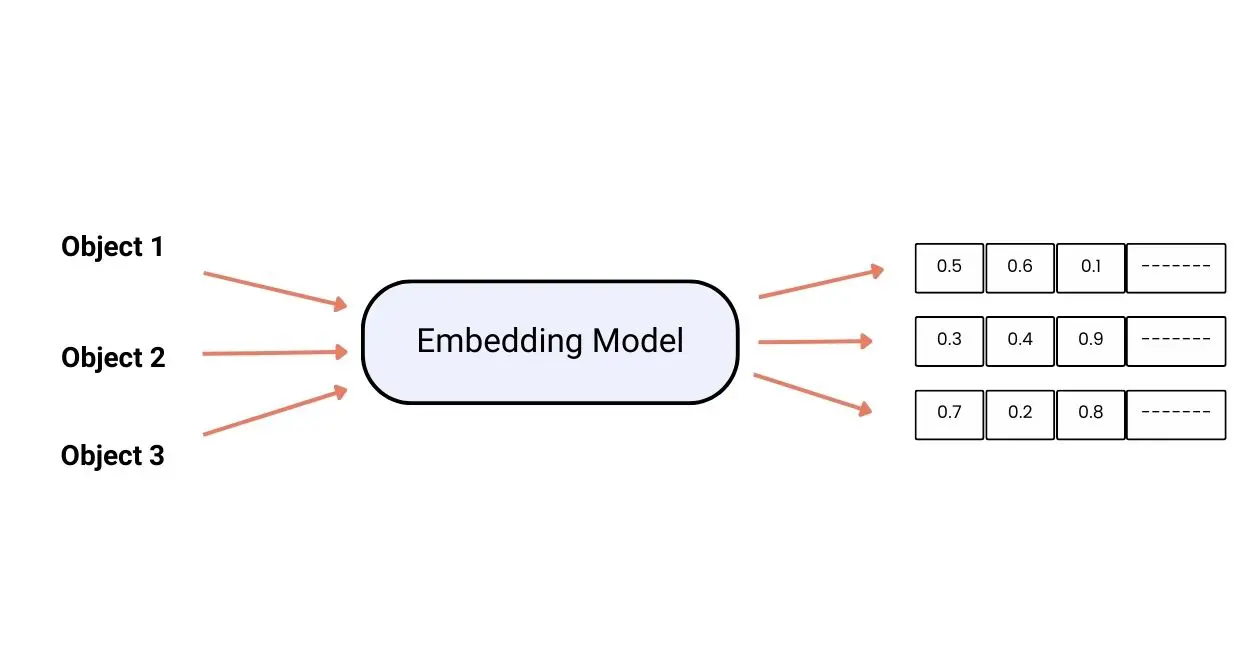
These act as data translators that can convert any data into a numerical code, specifically a vector of numbers. The model operates to create vectors that capture the meaning and semantic similarity between data objects. It results in the creation of a map that can be used to study data connections.
Moreover, the embedding models allow better control over the content and style of generated outputs, while dealing with multimodal data. Hence, it can deal with text, images, code, and other forms of data.
While we understand the role and importance of embedding models in the world of vector databases, the selection of the right model is crucial for the success of an AI application. Let’s dig deeper into the details of making the relevant choice.
Read more about embeddings as a building block for LLMs
Factors of Consideration to Make the Right Choice
Since a vector embedding model forms the basis of your generative AI application, your choice is crucial for its success.
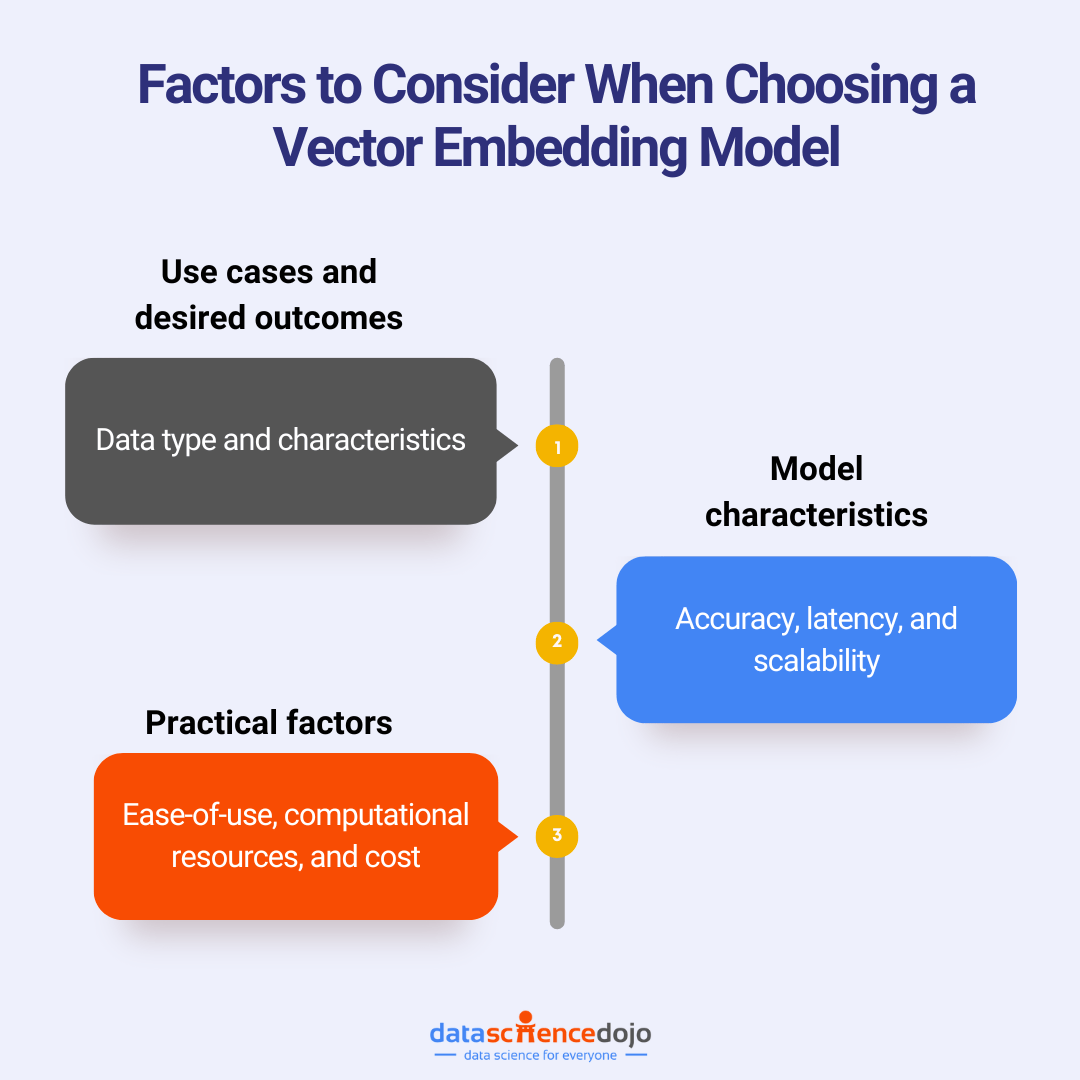
Below are some key factors to consider when exploring your model options.
Use Case and Desired Outcomes
In any choice, your goals and objectives are the most important aspect. The same holds true for your embedding model selection. The use case and outcomes of your generative AI application guide your choice of model.
The type of task you want your app to perform is a crucial factor as different models capture specific aspects of data. The tasks can range from text generation and summarization to code completion and more. You must be clear about your goal before you explore the available options.
Moreover, data characteristics are of equal importance. Your data type – text, code, or image – must be compatible with your data format.
Model Characteristics
The particular model characteristics of consideration include its accuracy, latency, and scalability. Accuracy refers to the ability of the model to correctly capture data relationships, including semantic meaning, word order, and linguistic nuances.
Latency is another important property that caters to real-time interactions of the application, improving the model’s performance with reduced inference time. The size and complexity of data can impact this characteristic of an embedding model.
Moreover, to keep up with the rapidly advancing AI, it is important to choose a model that supports scalability. It also ensures that the model can cater to your growing dataset needs.

Practical Factors
While app requirements and goals are crucial to your model choice, several practical aspects of the decision must also be considered. These primarily include computational resource requirements and the cost of the model. While the former must match your data complexity, the latter should be within your specified budget.
Moreover, the available level of technical expertise also dictates your model choice. Since some vector embedding models require high technical expertise while others are more user-friendly, your strength of technical knowledge will determine your ease of use.
Here’s your guide to top vector databases in the market
While these considerations address the various aspects of your organization-level goals and application requirements, you must consider some additional benchmarks and evaluation factors. Considering these benchmarks completes the highly important multifaceted approach of model selection.
Curious about the future of LLMs and the role of vector embeddings in it? Tune in to our Future of Data and AI Podcast now!
Benchmarks for Evaluating Vector Embedding Models
Here’s a breakdown of some key benchmarks you can leverage:
Internal Evaluation
These benchmarks focus on the quality of the embeddings for all tasks. Some common metrics of this evaluation include semantic relationships between words, word similarity in the embedding space, and word clustering. All these metrics collectively determine the quality of connections between embeddings.
Learn more about LLM evaluation and its key aspects
External Evaluation
It keeps track of the performance of embeddings in a specific task. Following is a list of some of the metrics used for external evaluation:
ROUGE Score: It is called the Recall-Oriented Understudy for Gisting Evaluation. It deals with the performance of text summarization tasks, evaluating the overlap between generated and reference summaries.
BLEU Score: The Bilingual Evaluation Understudy, also called human evaluation measures the coherence and quality of outputs. This metric is particularly useful for tracking the quality of dialog generation.
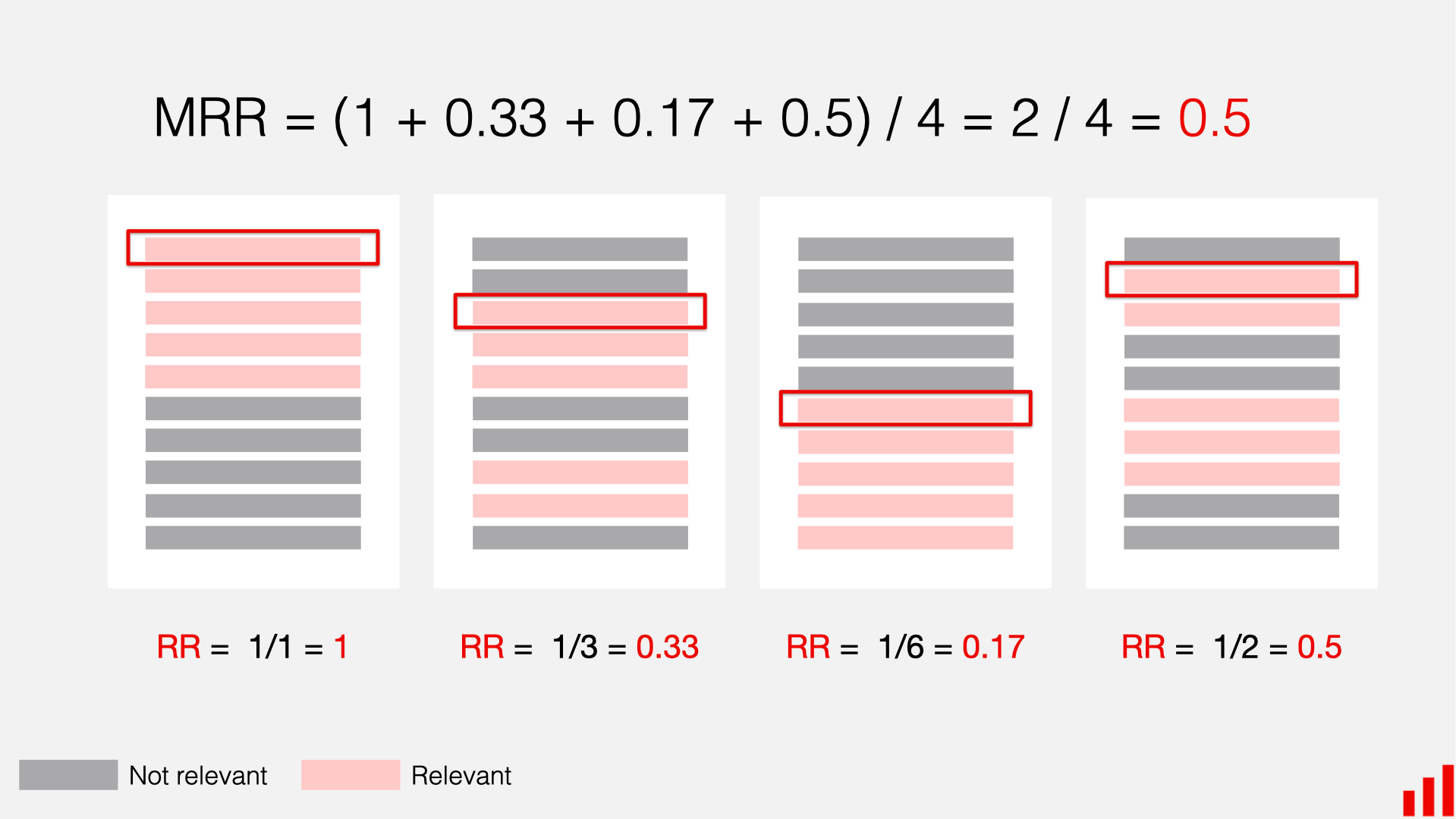
MRR: It stands for Mean Reciprocal Rank. As the name suggests, it ranks the documents in the retrieved results based on their relevance.
You can also read about F1 Score – a metric for LLM evaluation
Benchmark Suites
The benchmark suites work by providing a standardized set of tasks and datasets to assess the models’ performance. It helps in making informed decisions as they highlight the strengths and weaknesses of of each model across a variety of tasks. Some common benchmark suites include:
BEIR (Benchmark for Evaluating Retrieval with BERT)
It focuses on information retrieval tasks by using a reference set that includes diverse information retrieval tasks such as question-answering, fact-checking, and entity retrieval. It provides datasets for retrieving relevant documents or passages based on a query, allowing for a comprehensive evaluation of a model’s capabilities.
MTEB (Massive Text Embedding Benchmark)
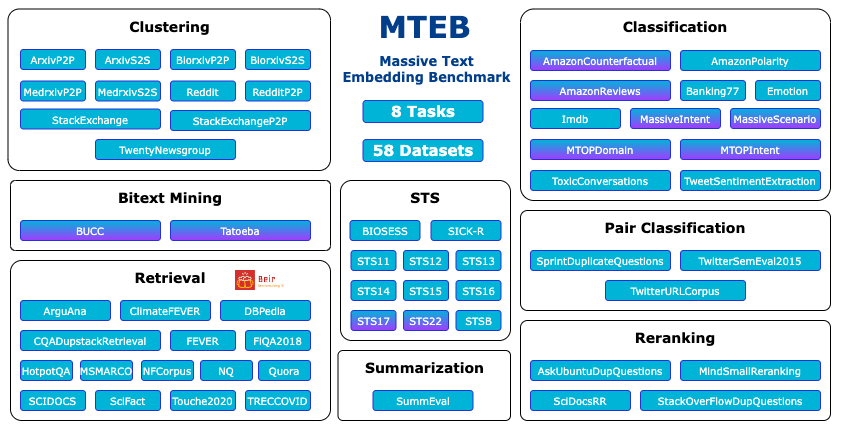
The MTEB leaderboard is available on Hugging Face. It expands on BEIR’s foundation with 58 datasets and covers 112 languages. It enables the evaluation of models against a wide range of linguistic contexts and use cases.
Its metrics and databases are suitable for tasks like text summarization, information retrieval, and semantic textual similarity, allowing you to see model performance on a broad range of tasks.

Hence, the different factors, benchmark suites, evaluation models, and metrics collectively present a multi-faceted approach toward selecting a relevant vector embedding model. However, alongside these quantitative metrics, it is important to incorporate human judgment into the process.
The Final Word
In navigating the performance of your generative AI applications, the journey starts with choosing an appropriate vector embedding model. Since the model forms the basis of your app performance, you must consider all the relevant factors in making a decision.
While you explore the various evaluation metrics and benchmarks, you must also carefully analyze the instances of your application’s poor performance. It will help you understand the embedding model’s weaknesses, enabling you to choose the most appropriate one that ensures high-quality outputs.