

Embeddings transform raw data into meaningful vectors, revolutionizing how AI systems understand and process language,” notes industry expert Frank Liu. These are the cornerstone of large language models (LLM) which are trained on vast datasets, including books, articles, websites, and social media posts.
By learning the intricate statistical relationships between words, phrases, and sentences, LLMs generate text that mirrors the patterns found in their training data.
This comprehensive guide delves into the world of embeddings, explaining their various types, applications, and future advancements. Whether you’re a beginner or an expert, this exploration will provide a deep understanding of how embeddings enhance AI capabilities, making LLMs more efficient and effective in processing natural language data.
Join us as we uncover their essential role in the evolution of AI.

What are Embeddings?
Embeddings are numerical representations of words or phrases in a high-dimensional vector space. These representations map discrete objects (such as words, sentences, or images) into a continuous latent space, capturing their relationship. They are a fundamental component in the field of Natural Language Processing (NLP) and machine learning.
By converting words into vectors, they enable machines to understand and process human language in a more meaningful way. Think of embeddings as a way to organize a library. Instead of arranging books alphabetically, you place similar books close to each other based on their content.
Similarly, embeddings position words into a vector in a high-dimensional latent space so that words with similar meanings are closer together. This helps ML models understand and process text more effectively. For example, the vector for “apple” would be closer to “fruit” than to “car”.
Watch this Webinar to Unlock the Power of Embeddings with Vector Search
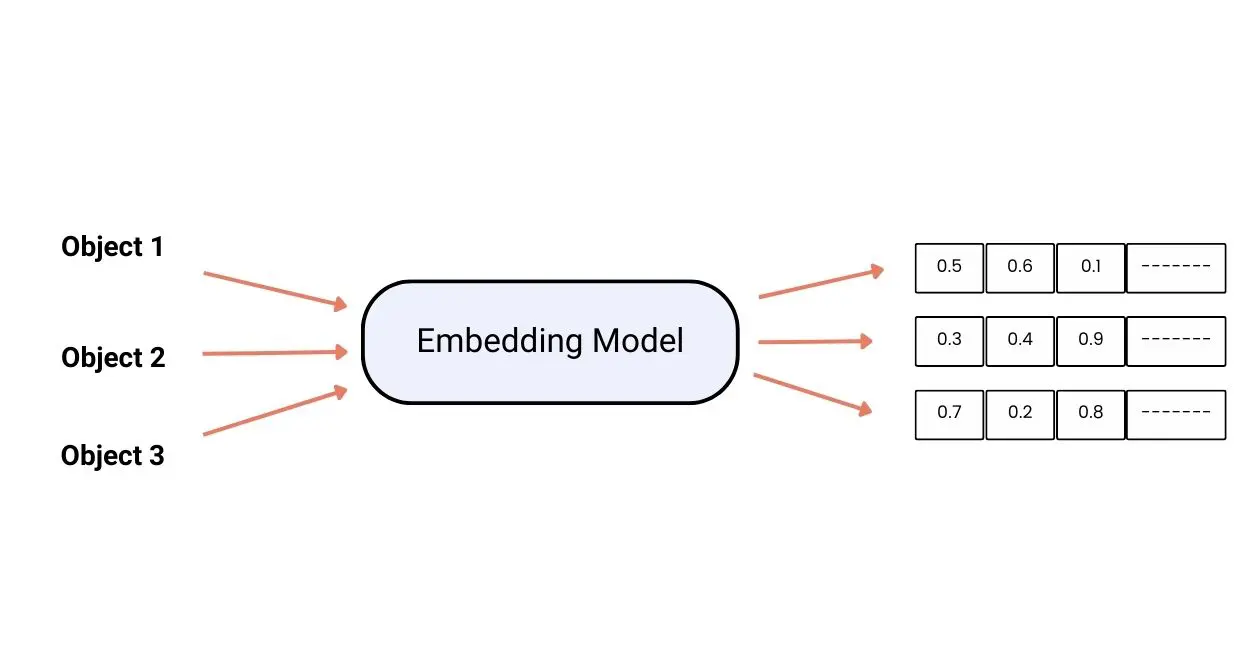
How do Embeddings Work?
They translate textual data into vectors within a continuous latent space, enabling the measurement of similarities through metrics like cosine similarity and Euclidean distance.
This transformation is crucial because it enables models to perform mathematical operations on text data, thereby facilitating tasks such as clustering, classification, and regression.
It helps to interpret and generate human language with greater accuracy and context-awareness. Techniques such as Azure OpenAI facilitate their creation, empowering language models with enhanced capabilities.
Embeddings are used to represent words as vectors of numbers, which can then be used by machine learning models to understand the meaning of text. These have evolved over time from the simplest one-hot encoding approach to more recent semantic approaches.
Here’s a step-by-step guide to deploying ML in your business
Exploring the Key Types of Embeddings
When converting data into meaningful numerical representations, different types of embeddings help machines process and interpret information more effectively. Let’s explore the key types of embeddings and how they power various AI applications.
Word Embeddings
Word embeddings represent individual words as vectors of numbers in a high-dimensional space. These vectors capture semantic meanings and relationships between words, making them fundamental in NLP tasks.
By positioning words in such a space, it places similar words closer together, reflecting their semantic relationships. This allows machine learning models to understand and process text more effectively.
Word embeddings help classify texts into categories like spam detection or sentiment analysis by understanding the context of the words used. They enable the generation of concise summaries by capturing the essence of the text.
It allows models to provide accurate answers based on the context of the query and facilitates the translation of text from one language to another by understanding the semantic meaning of words and phrases.
Learn more about the evolution of word embeddings
Sentence and Document Embeddings
Sentence embeddings represent entire sentences as vectors, capturing the context and meaning of the sentence as a whole. Unlike word embeddings, which only capture individual word meanings, sentence embeddings consider the relationships between words within a sentence, providing a more comprehensive understanding of the text.
These are used to categorize larger text units like sentences or entire documents, making the classification process more accurate. They help generate summaries by understanding the overall context and key points of the document.
Models are also enabled to answer questions based on the context of entire sentences or documents. They improve translation quality by preserving the context and meaning of sentences during translation.
Graph Embeddings
Graph embeddings represent nodes in a graph as vectors, capturing the relationships and structures within the graph. These are particularly useful for tasks that involve network analysis and relational data.
For instance, in a social network graph, it can represent users and their connections, enabling tasks like community detection, link prediction, and recommendation systems.
By transforming the complex relationships in graphs into numerical vectors, ML models can process and analyze graph data efficiently. One of the key advantages is their ability to preserve the structural information of the graph, which is critical for accurately capturing the relationships between nodes.
This capability makes them suitable for a wide range of applications beyond social networks, such as biological network analysis, fraud detection, and knowledge graph completion.
Tools like DeepWalk and Node2Vec have been developed to generate graph embeddings by learning from the graph’s structure, further enhancing the ability to analyze and interpret complex graph data.
Image and Audio Embeddings
Images are represented as vectors by extracting features from them, while audio signals are converted into numerical representations by embeddings. These are crucial for tasks involving visual and auditory data.
Embeddings for images are used in tasks like image classification, object detection, and image retrieval, while those for audio are applied in speech recognition, music genre classification, and audio search.
These are powerful tools in NLP and machine learning, enabling machines to understand and process various forms of data. By transforming text, images, and audio into numerical representations, they enhance the performance of numerous tasks, making them indispensable in the field of artificial intelligence.

Choosing the right embedding type depends on the nature of your data and the task at hand. You can use:
- Word embeddings to capture individual word meanings
- Sentence and document embeddings for a broader context
- Graph embeddings to analyze networks and connections
- Image and audio embeddings for tasks like classification and retrieval
Understanding the strengths of each embedding type ensures you select the best approach for optimizing your AI models and improving performance across different applications.
Classic Approaches to Embeddings
In the early days of natural language processing (NLP), embeddings were simply one-hot encoded. Zero vector represents each word with a single one at the index that matches its position in the vocabulary.
1. One-hot Encoding
One-hot encoding is the simplest approach to embedding words. It represents each word as a vector of zeros, with a single one at the index corresponding to the word’s position in the vocabulary. For example, if we have a vocabulary of 10,000 words, then the word “cat” would be represented as a vector of 10,000 zeros, with a single one at index 0.
One-hot encoding is a simple and efficient way to represent words as vectors of numbers. However, it does not take into account the context in which words are used. This can be a limitation for tasks such as text classification and sentiment analysis, where the context of a word can be important for determining its meaning.
For example, the word “cat” can have multiple meanings, such as “a small furry mammal” or “to hit someone with a closed fist.” In one-hot encoding, these two meanings would be represented by the same vector. This can make it difficult for machine learning models to learn the correct meaning of words.
2. TF-IDF
TF-IDF (term frequency-inverse document frequency) is a statistical measure that is used to quantify the importance of process and creates a pre-trained model that can be fine-tuned using a smaller dataset for specific tasks.
This reduces the need for labeled data and training time while achieving good results in natural language processing tasks of a word in a document. It is a widely used technique in NLP for tasks such as text classification, information retrieval, and machine translation.
TF-IDF is calculated by multiplying the term frequency (TF) of a word in a document by its inverse document frequency (IDF). TF measures the number of times a word appears in a document, while IDF measures how rare a word is in a corpus of documents.
Explore Vector Embeddings for Semantic Search
The TF-IDF score for a word is high when the word appears frequently in a document and when the word is rare in the corpus. This means that TF-IDF scores can be used to identify words that are important in a document, even if they do not appear very often.
Understanding TF-IDF with an Example
Here is an example of how TF-IDF can be used to create word embeddings. Let’s say we have a corpus of documents about cats. We can calculate the TF-IDF scores for all of the words in the corpus. The words with the highest TF-IDF scores will be the words that are most important in the corpus, such as “cat,” “dog,” “fur,” and “meow.”
We can then create a vector for each word, where each element of the vector represents the TF-IDF score for that word. The TF-IDF vector for the word “cat” would be high, while the TF-IDF vector for the word “dog” would also be high, but not as high as the TF-IDF vector for the word “cat.”
The TF-IDF can then be used by a machine-learning model to classify documents about cats. The model would first create a vector representation of a new document. Then, it would compare the vector representation of the new document to the TF-IDF word embeddings. The document would be classified as a “cat” document if its vector representation is most similar to the TF-IDF word embeddings for “cat.”
Count-based and TF-IDF
To address the limitations of one-hot encoding, count-based and TF-IDF techniques were developed. These techniques take into account the frequency of words in a document or corpus.
Count-based techniques simply count the number of times each word appears in a document. TF-IDF techniques take into account both the frequency of a word and its inverse document frequency.
Count-based and TF-IDF techniques are more effective than one-hot encoding at capturing the context in which words are used. However, they still do not capture the semantic meaning of words.
Capturing Local Context with N-grams
To capture the semantic meaning of words, n-grams can be used. N-grams are sequences of n-words. For example, a 2-gram is a sequence of two words.
N-grams can be used to create a vector representation of a word. The vector representation is based on the frequencies of the n-grams that contain the word.
N-grams are a more effective way to capture the semantic meaning of words than count-based or TF-IDF techniques. However, they still have some limitations. For example, they are not able to capture long-distance dependencies between words.
Semantic Encoding Techniques
Semantic encoding techniques are the most recent approach to embedding words. These techniques use neural networks to learn vector representations of words that capture their semantic meaning.
One of the most popular semantic encoding techniques is Word2Vec. Word2Vec uses a neural network to predict the surrounding words in a sentence. The network learns to associate words that are semantically similar with similar vector representations.
Learn the role of embeddings and semantic search in Retrieval Augmented Generation
Semantic encoding techniques are the most effective way to capture the semantic meaning of words. They are able to capture long-distance dependencies between words, and they are able to learn the meaning of words even if they have never been seen before. Here are some major semantic encoding techniques;
1. ELMo: Embeddings from Language Models
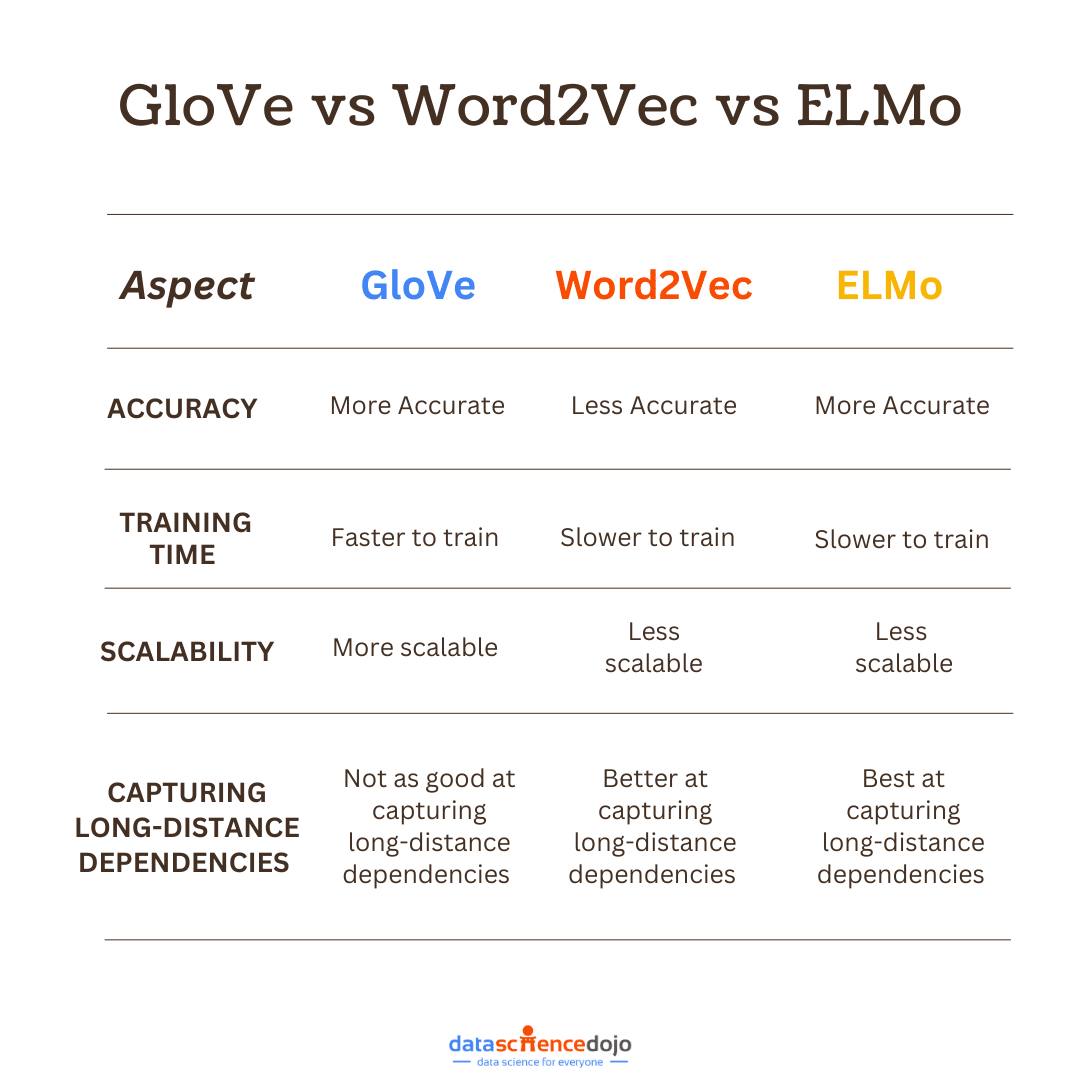
ELMo is a type of word embedding that incorporates both word-level characteristics and contextual semantics. It is created by taking the outputs of all layers of a deep bidirectional language model (bi-LSTM) and combining them in a weighted fashion. This allows ELMo to capture the meaning of a word in its context, as well as its own inherent properties.
The intuition behind ELMo is that the higher layers of the bi-LSTM capture context, while the lower layers capture syntax. This is supported by empirical results, which show that ELMo outperforms other word embeddings on tasks such as POS tagging and word sense disambiguation.
ELMo is trained to predict the next word in a sequence of words, a task called language modeling. This means that it has a good understanding of the relationships between words. When assigning an embedding to a word, ELMo takes into account the words that surround it in the sentence. This allows it to generate different vectors for the same word depending on its context.
Understanding ELMo with Example
For example, the word “play” can have multiple meanings, such as “to perform” or “a game.” In standard word embeddings, each instance of the word “play” would have the same representation.
However, ELMo can distinguish between these different meanings by taking into account the context in which the word appears. In the sentence “The Broadway play premiered yesterday,” for example, ELMo would assign the word “play” a vector that reflects its meaning as a theater production.
ELMo has been shown to be effective for a variety of natural language processing tasks, including sentiment analysis, question answering, and machine translation. It is a powerful tool that can be used to improve the performance of NLP models.
2. GloVe
GloVe is a statistical method for learning word embeddings from a corpus of text. GloVe is similar to Word2Vec, but it uses a different approach to learning the vector representations of words.
How does GloVe work?
GloVe works by creating a co-occurrence matrix. The co-occurrence matrix is a table that shows how often two words appear together in a corpus of text. For example, the co-occurrence matrix for the words “cat” and “dog” would show how often the words “cat” and “dog” appear together in a corpus of text.
GloVe then uses a machine learning algorithm to learn the vector representations of words from the co-occurrence matrix. The machine learning algorithm learns to associate words that appear together frequently with similar vector representations.
Explore Roadmap for Machine Learning
3. Word2Vec
Word2Vec is a semantic encoding technique that is used to learn vector representations of words. Word vectors represent word meaning and can enhance machine learning models for tasks like text classification, sentiment analysis, and machine translation.
Word2Vec works by training a neural network on a corpus of text. The neural network is trained to predict the surrounding words in a sentence. The network learns to associate words that are semantically similar with similar vector representations.
There are two main variants of Word2Vec:
- Continuous Bag-of-Words (CBOW): The CBOW model predicts the surrounding words in a sentence based on the current word. For example, the model might be trained to predict the words “the” and “dog” given the word “cat”.
- Skip-gram: The skip-gram model predicts the current word based on the surrounding words in a sentence. For example, the model might be trained to predict the word “cat” given the words “the” and “dog”.
Key Application of Word2Vec
Word2Vec has been shown to be effective for a variety of tasks, including;
- Text Classification: Word2Vec can be used to train a classifier to classify text into different categories, such as news articles, product reviews, and social media posts.
- Sentiment Analysis: Word2Vec can be used to train a classifier to determine the sentiment of text, such as whether it is positive, negative, or neutral.
- Machine Translation: Word2Vec can be used to train a machine translation model to translate text from one language to another.
Word2Vec vs Dense Word Embeddings
Word2Vec is a neural network model that learns to represent words as vectors of numbers. Word2Vec is trained on a large corpus of text, and it learns to predict the surrounding words in a sentence.
Word2Vec can be used to create dense word embeddings that are vectors that have a fixed size, regardless of the size of the vocabulary. This makes them easy to use with machine learning models.
These have been shown to be effective in a variety of NLP tasks, such as text classification, sentiment analysis, and machine translation.
Understanding Variations in Text Embeddings
An established process can lead to a text embedding to suggest similar words. This means that every time you input the same text into the model, the same results are produced.
Explore Embedding Techniques
Most traditional embedding models like Word2Vec, GloVe, or fastText operate in this manner leading a text embedding to suggest similar words for similar inputs. However, the results can vary in the following cases:
- Random Initialization: Some models might include layers or components with randomly initialized weights that aren’t set to a fixed value or re-used across sessions. This can result in different outputs each time.
- Contextual Embeddings: Models like BERT or GPT generate these where the embedding for the same word or phrase can differ based on its surrounding context. If you input the phrase in different contexts, the embeddings will vary.

- Non-deterministic Settings: Some neural network configurations or training settings can introduce non-determinism. For example, if dropout (randomly dropping units during training to prevent overfitting) is applied during the embedding generation, it could lead to variations.
- Model Updates: If the model itself is updated or retrained, even with the same architecture and training data, slight differences in training dynamics (like changes in batch ordering or hardware differences) can lead to different model parameters and thus different embeddings.
- Floating-Point Precision: Differences in floating-point precision, which can vary based on the hardware (like CPU vs. GPU), can also lead to slight variations in the computed vector representations.
So, while many models are deterministic, several factors can lead to differences in the embeddings of the same text under different conditions or configurations.
Real-Life Examples in Action
Vector embeddings have become an integral part of numerous real-world applications, enhancing the accuracy and efficiency of various tasks. Here are some compelling examples showcasing their power:
E-commerce Personalized Recommendations
Platforms use these vector representations to offer personalized product suggestions. By representing products and users as vectors in a high-dimensional space, e-commerce platforms can analyze user behavior, preferences, and purchase history to recommend products that align with individual tastes.
This method enhances the shopping experience by providing relevant suggestions, driving sales, and customer satisfaction. For instance, embeddings help platforms like Amazon and Zalando understand user preferences and deliver tailored product recommendations.
Chatbots and Virtual Assistants
Embeddings enable better understanding and processing of user queries. Modern chatbots and virtual assistants, such as those powered by GPT-3 or other large language models, utilize these to comprehend the context and semantics of user inputs.
This allows them to generate accurate and contextually relevant responses, improving user interaction and satisfaction. For example, chatbots in customer support can efficiently resolve queries by understanding the user’s intent and providing precise answers.
Learn about AI-based chatbots in Python
Social Media Sentiment Analysis
Companies analyze social media posts to gauge public sentiment. By converting text data into vector representations, businesses can perform sentiment analysis to understand public opinion about their products, services, or brand.
This analysis helps in tracking customer satisfaction, identifying trends, and making informed marketing decisions. Tools powered by embeddings can scan vast amounts of social media data to detect positive, negative, or neutral sentiments, providing valuable insights for brands.
Healthcare Applications
Embeddings assist in patient data analysis and diagnosis predictions. In the healthcare sector, these are used to analyze patient records, medical images, and other health data to aid in diagnosing diseases and predicting patient outcomes.
For instance, specialized tools like Google’s Derm Foundation focus on dermatology, enabling accurate analysis of skin conditions by identifying critical features in medical images. These help doctors make informed decisions, improving patient care and treatment outcomes.
These examples illustrate the transformative impact of embeddings across various industries, showcasing their ability to enhance personalization, understanding, and analysis in diverse applications. By leveraging this tool, businesses can unlock deeper insights and deliver more effective solutions to their customers.
Learn more about AI in healthcare, which has improved patient care
How is a Large Language Model Built?
LLMs are typically built using a transformer architecture. Transformers are a type of neural network that is well-suited for NLP tasks. They are able to learn long-range dependencies between words, which is essential for understanding the nuances of human language.
LLMs are so large that they cannot be run on a single computer. They are typically trained on clusters of computers or even on cloud computing platforms. The training process can take weeks or even months, depending on the size of the dataset and the complexity of the model.
One of the key technologies that makes LLMs so powerful is vector embeddings. These embeddings allow the model to represent words, sentences, and even entire documents as numerical vectors in a high-dimensional space. By doing so, LLMs can efficiently process meaning, recognize patterns, and retrieve relevant information.
Here’s your one-stop guide to learn all about Large Language Models
Key Building Blocks of Large Language Models
LLMs rely on multiple core components that work together to process and generate human-like text. One of the most fundamental building blocks is vector embeddings. However, embeddings are just one part of a much larger system that enables LLMs to understand, learn, and generate language effectively.
To fully grasp how LLMs function, it is essential to explore the other key components that power them. Below is an explanation of these building blocks of LLMs.
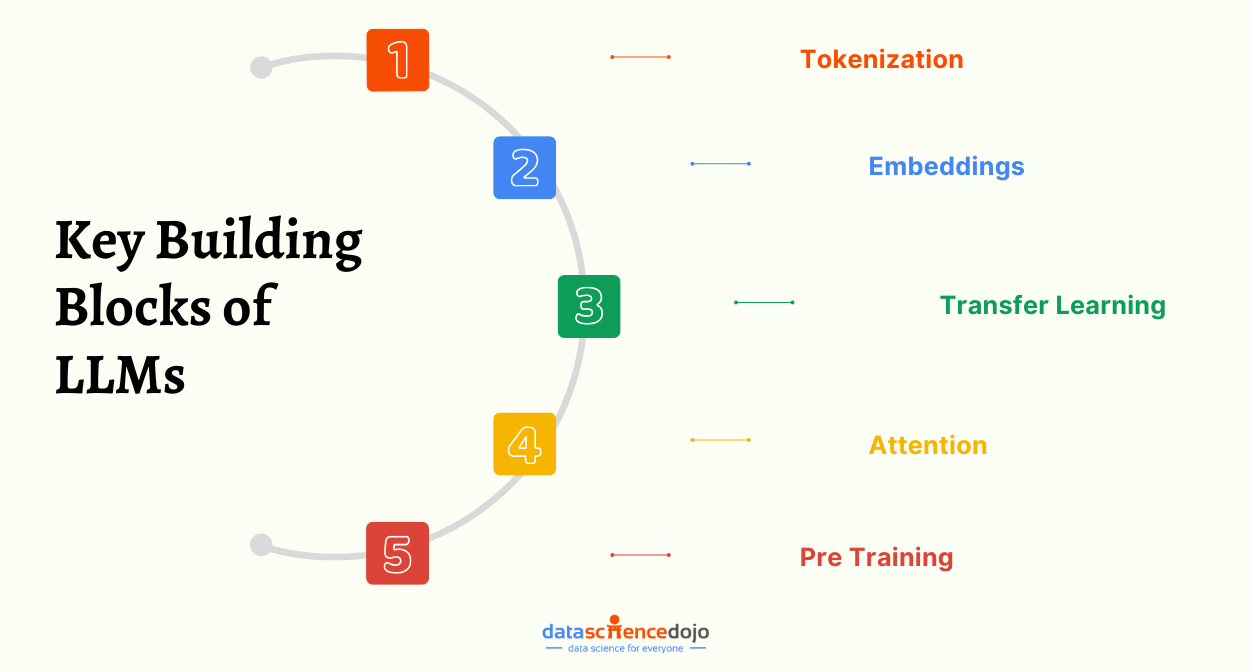
1. Embeddings
These are continuous vector representations of words or tokens that capture their semantic meanings in a high-dimensional space. They allow the model to convert discrete tokens into a format that can be processed by the neural network. LLMs learn embeddings during training to capture relationships between words, like synonyms or analogies.
2. Tokenization
Tokenization is the process of converting a sequence of text into individual words, subwords, or tokens that the model can understand. LLMs use subword algorithms like BPE or wordpiece to split text into smaller units that capture common and uncommon words. This approach helps to limit the model’s vocabulary size while maintaining its ability to represent any text sequence.
3. Attention
Attention mechanisms in LLMs, particularly the self-attention mechanism used in transformers, allow the model to weigh the importance of different words or phrases.
Explore Attention Mechanism in NLP: A Guide to Decoding Transformers
By assigning different weights to the tokens in the input sequence, the model can focus on the most relevant information while ignoring less important details. This ability to selectively focus on specific parts of the input is crucial for capturing long-range dependencies and understanding the nuances of natural language.
4. Pre-training
Pre-training is the process of training an LLM on a large dataset, usually unsupervised or self-supervised, before fine-tuning it for a specific task. During pretraining, the model learns general language patterns, relationships between words, and other foundational knowledge.
The process creates a pre-trained model that can be fine-tuned using a smaller dataset for specific tasks. This reduces the need for labeled data and training time while achieving good results in natural language processing tasks (NLP).
5. Transfer learning
Transfer learning is the technique of leveraging the knowledge gained during pretraining and applying it to a new, related task. In the context of LLMs, transfer learning involves fine-tuning a pre-trained model on a smaller, task-specific dataset to achieve high performance on that task.
The benefit of transfer learning is that it allows the model to benefit from the vast amount of general language knowledge learned during pretraining, reducing the need for large labeled datasets and extensive training for each new task.
While the building blocks of LLMs work together to enable powerful language understanding and generation, they are not without challenges. Since embeddings are the most crucial foundation of these models, let’s explore the key challenges associated with them.
Challenges and Limitations of Embeddings
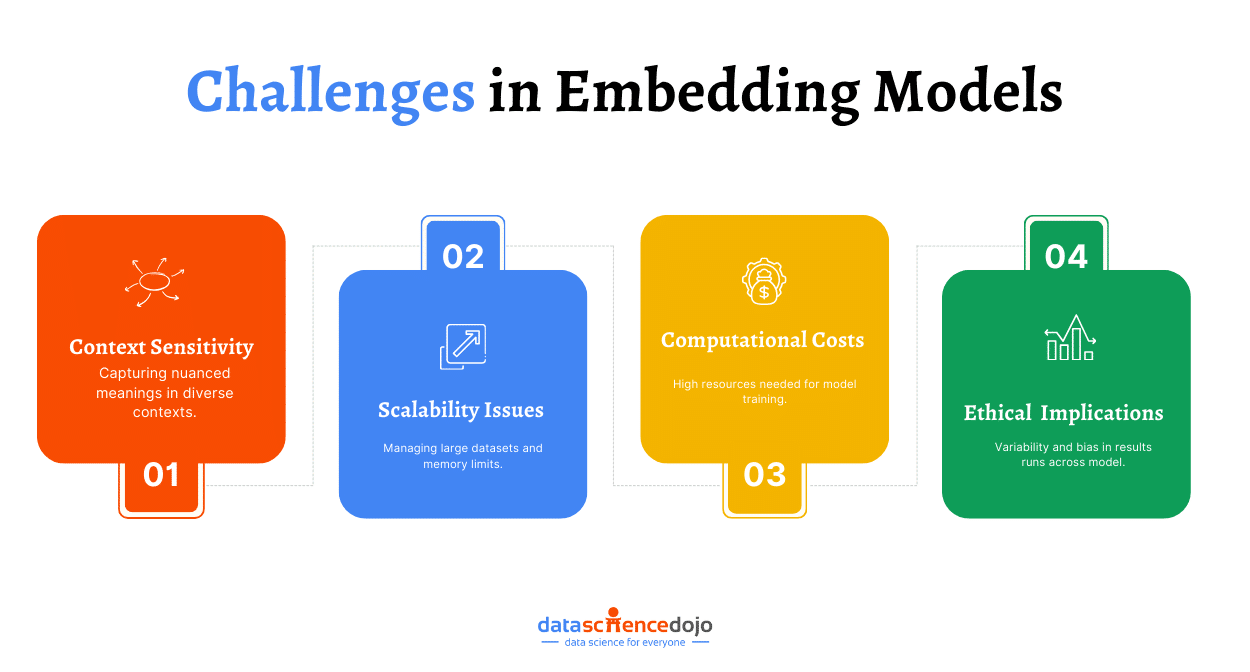
Vector embeddings, while powerful, come with several inherent challenges and limitations that can impact their effectiveness in various applications. Understanding these challenges is crucial for optimizing their use in real-world scenarios.
Context Sensitivity
Capturing the full context of words or phrases remains challenging, especially when it comes to polysemy (words with multiple meanings) and varying contexts. Enhancing context sensitivity through advanced models like BERT or GPT-3, which consider the surrounding text to better understand the intended meaning, is crucial. Fine-tuning these models on domain-specific data can also help improve context sensitivity.
Scalability Issues
Handling large datasets can be difficult due to the high dimensionality of embeddings, leading to increased storage and retrieval times. Utilizing vector databases like Milvus, Pinecone, and Faiss, which are optimized for storing and querying high-dimensional vector data, can address these challenges.
These databases use techniques like vector compression and approximate nearest neighbor search to manage large datasets efficiently.
Explore Vector Database in Healthcare
Computational Costs
Training embeddings is resource-intensive, requiring significant computational power and time, especially for large-scale models. Leveraging pre-trained models and fine-tuning them on specific tasks can reduce computational costs. Using cloud-based services that offer scalable compute resources can also help manage these costs effectively.
Ethical Challenges
Addressing biases and non-deterministic outputs in training data is crucial to ensure fairness, transparency and consistency in AI applications.
Non-deterministic Outputs: Variability in results due to random initialization or training processes can hinder reproducibility. Using deterministic settings and seed initialization can improve consistency.
Bias in Embeddings: Models can inherit biases from training data, impacting fairness. By employing bias detection, mitigation strategies, and regular audits, ethical AI practices can be followed.
Future Advancement
Future advancements in embedding techniques are set to enhance their accuracy and efficiency significantly. New techniques are continually being developed to capture complex semantic relationships and contextual nuances better.
Techniques like ELMo, BERT, and GPT-3 have already made substantial strides in this field by providing deeper contextual understanding and more precise language representations. These advancements aim to improve the overall performance of AI applications, making them more intelligent and capable of understanding human language intricately.
Their integration with generative AI models is poised to revolutionize AI applications further. This combination allows for improved contextual understanding and the generation of more coherent and contextually relevant text.
For instance, models like GPT-3 enable the creation of high-quality text that captures nuanced understanding, enhancing applications in content creation, chatbots, and virtual assistants.

As these technologies continue to evolve, they promise to deliver richer, more sophisticated AI solutions that can handle a variety of data types, including text, images, and audio, ultimately leading to more comprehensive and insightful applications.