

Language is the basis for human interaction and communication. Speaking and listening are the direct by-products of human reliance on language. While humans can use language to understand each other, in today’s digital world, they must also interact with machines.
The answer lies in large language models (LLMs) – machine-learning models that empower machines to learn, understand, and interact using human language. Hence, they open a gateway to enhanced and high-quality human-computer interaction.
Let’s understand large language models further.
What are Large Language Models?
Imagine a computer program that’s a whiz with words, capable of understanding and using language in fascinating ways. That’s essentially what an LLM is! Large language models are powerful AI-powered language tools trained on massive amounts of text data, like books, articles, and even code.
By analyzing this data, LLMs become experts at recognizing patterns and relationships between words. This allows them to perform a variety of impressive tasks, like:
Creative Text Generation
LLMs can generate different creative text formats, crafting poems, scripts, musical pieces, emails, and even letters in various styles. From a catchy social media post to a unique story idea, these language models can pull you out of any writer’s block. Some LLMs, like LaMDA by Google AI, can help you brainstorm ideas and even write different creative text formats based on your initial input.
Speak Many Languages
Since language is the area of expertise for LLMs, the models are trained to work with multiple languages. It enables them to understand and translate languages with impressive accuracy. For instance, Microsoft’s Translator powered by LLMs can help you communicate and access information from all corners of the globe.

Information Powerhouse
With extensive training datasets and a diversity of information, LLMs become information powerhouses with quick answers to all your queries. They are highly advanced search engines that can provide accurate and contextually relevant information to your prompts.
Like Megatron-Turing NLG from NVIDIA can analyze vast amounts of information and summarize it in a clear and concise manner. This can help you gain insights and complete tasks more efficiently.
As you kickstart your journey of understanding LLMs, don’t forget to tune in to our Future of Data and AI podcast!
LLMs are constantly evolving, with researchers developing new techniques to unlock their full potential. These powerful language tools hold immense promise for various applications, from revolutionizing communication and content creation to transforming the way we access and understand information.
As LLMs continue to learn and grow, they’re poised to be a game-changer in the world of language and artificial intelligence.
While this is a basic concept of LLMs, they are a very vast concept in the world of generative AI and beyond. This blog aims to provide in-depth guidance in your journey to understand large language models. Let’s take a look at all you need to know about LLMs.
A Roadmap to Building LLM Applications
Before we dig deeper into the structural basis and architecture of large language models, let’s look at their practical applications and understand the basic roadmap to building them.
Explore the outline of a roadmap that will guide you in learning about building and deploying LLMs. Read more about it here.
LLM applications are important for every enterprise that aims to thrive in today’s digital world. From reshaping software development to transforming the finance industry, large language models have redefined human-computer interaction in all industrial fields.
However, the application of LLM is not just limited to technical and financial aspects of business. The assistance of large language models has upscaled the legal career of lawyers with ease of documentation and contract management.
Here’s your guide to creating personalized Q&A chatbots
While the industrial impact of LLMs is paramount, the most prominent impact of large language models across all fields has been through chatbots. Every profession and business has reaped the benefits of enhanced customer engagement, operational efficiency, and much more through LLM chatbots.
Here’s a guide to the building techniques and real-life applications of chatbots using large language models: Guide to LLM chatbots
LLMs have improved the traditional chatbot design, offering enhanced conversational ability and better personalization. With the advent of OpenAI’s GPT-4, Google AI’s Gemini, and Meta AI’s LLaMA, LLMs have transformed chatbots to become smarter and a more useful tool for modern-day businesses.
Hence, LLMs have emerged as a useful tool for enterprises, offering advanced data processing and communication for businesses with their machine-learning models. If you are looking for a suitable large language model for your organization, the first step is to explore the available options in the market.
Top Large Language Models to Choose From
The modern market is swamped with different LLMs for you to choose from. With continuous advancements and model updates, the landscape is constantly evolving to introduce improved choices for businesses. Hence, you must carefully explore the different LLMs in the market before deploying an application for your business.
Learn to build and deploy custom LLM applications for your business
Below is a list of LLMs you can find in the market today.
ChatGPT
The list must start with the very famous ChatGPT. Developed by OpenAI, it is a general-purpose LLM that is trained on a large dataset, consisting of text and code. Its instant popularity sparked a widespread interest in LLMs and their potential applications.
While people explored cheat sheets to master ChatGPT usage, it also initiated a debate on the ethical impacts of such a tool in different fields, particularly education. However, despite the concerns, ChatGPT set new records by reaching 100 million monthly active users in just two months.
This tool also offers plugins as supplementary features that enhance the functionality of ChatGPT. We have created a list of the best ChatGPT plugins that are well-suited for data scientists. Explore these to get an idea of the computational capabilities that ChatGPT can offer.
Here’s a guide to the best practices you can follow when using ChatGPT.
Mistral 7b
It is a 7.3 billion parameter model developed by Mistral AI. It incorporates a hybrid approach of transformers and recurrent neural networks (RNNs), offering long-term memory and context awareness for tasks. Mistral 7b is a testament to the power of innovation in the LLM domain.
Here’s an article that explains the architecture and performance of Mistral 7b in detail. You can explore its practical applications to get a better understanding of this large language model.
Phi-2
Designed by Microsoft, Phi-2 has a transformer-based architecture that is trained on 1.4 trillion tokens. It excels in language understanding and reasoning, making it suitable for research and development. With only 2.7 billion parameters, it is a relatively smaller LLM, making it useful for research and development.
You can read more about the different aspects of Phi-2 here.
Llama 2
It is an open-source large language model that varies in scale, ranging from 7 billion to a staggering 70 billion parameters. Meta developed this LLM by training it on a vast dataset, making it suitable for developers, researchers, and anyone interested in their potential.
Llama 2 is adaptable for tasks like question answering, text summarization, machine translation, and code generation. Its capabilities and various model sizes open up the potential for diverse applications, focusing on efficient content generation and automating tasks.
Read about the 6 different methods to access Llama 2
Now that you have an understanding of the different LLM applications and their power in the field of content generation and human-computer communication, let’s explore the architectural basis of LLMs.
Emerging Frameworks for Large Language Model Applications
LLMs have revolutionized the world of natural language processing (NLP), empowering the ability of machines to understand and generate human-quality text. The wide range of applications of these large language models is made accessible through different user-friendly frameworks.
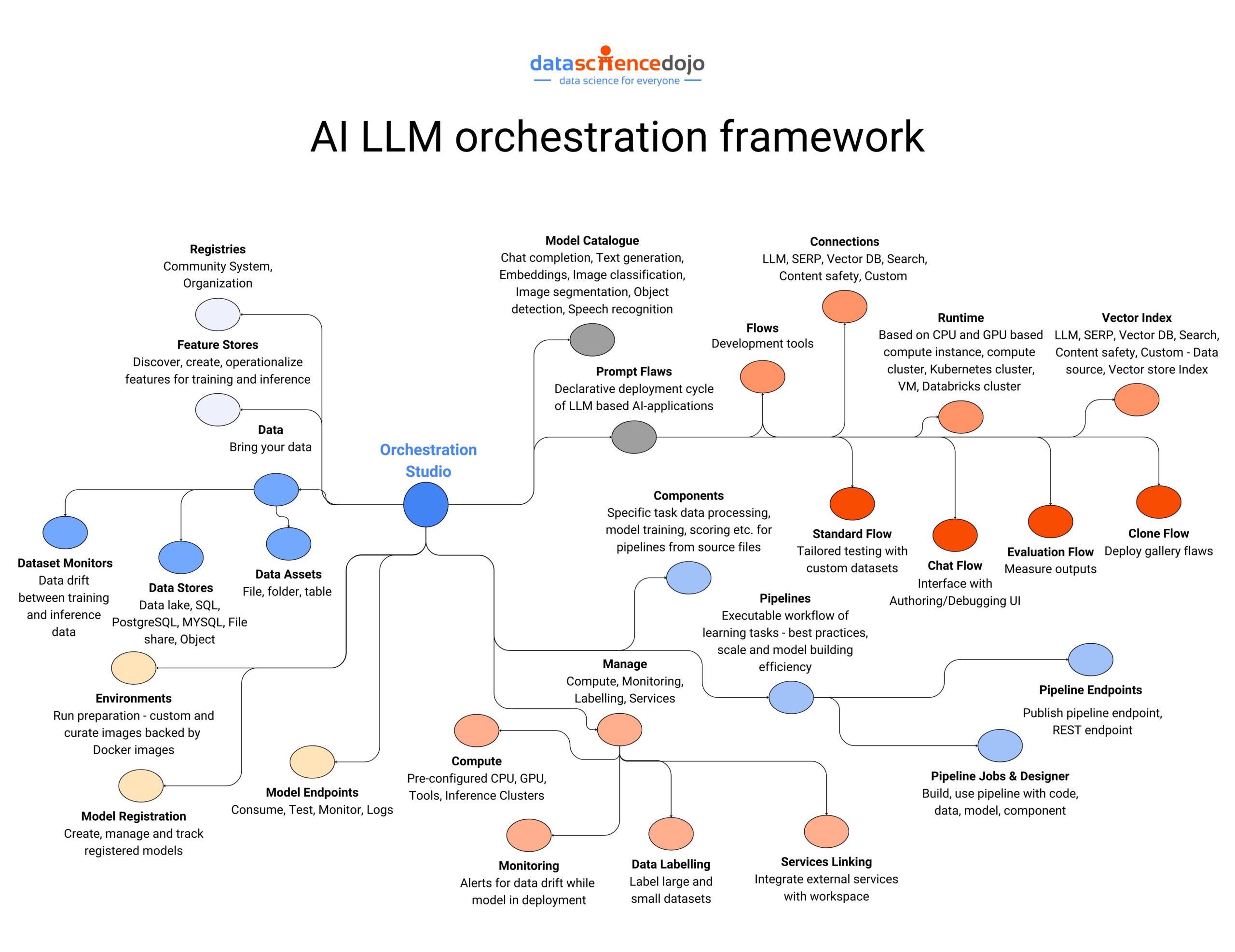
Let’s look at some prominent frameworks for LLM applications.
LangChain for LLM Application Development
LangChain is a useful framework that simplifies the LLM application development process. It offers pre-built components and a user-friendly interface, enabling developers to focus on the core functionalities of their applications.
LangChain breaks down LLM interactions into manageable building blocks called components and chains. Thus, allowing you to create applications without needing to be an LLM expert. Its major benefits include a simplified development process, flexibility in data integration, and the ability to combine different components for a powerful LLM.
With features like chains, libraries, and templates, the development of large language models is accelerated and code maintainability is promoted. Thus, making it a valuable tool to build innovative LLM applications. Here’s a guide exploring the power of LangChain to build custom chatbots.
You can also explore the dynamics of the working of agents in LangChain.
Here’s a complete guide to learn all about LangChain
LlamaIndex for LLM Application Development
It is a special framework designed to build knowledge-aware LLM applications. It emphasizes on integrating user-provided data with LLMs, leveraging specific knowledge bases to generate more informed responses. Thus, LlamaIndex produces results that are more informed and tailored to a particular domain or task.
With its focus on data indexing, it enhances the LLM’s ability to search and retrieve information from large datasets. With its security and caching features, LlamaIndex is designed to uncover deeper insights in text exploration. It also focuses on ensuring efficiency and data protection for developers working with large language models.
Tune in to this podcast featuring LlamaIndex’s Co-founder and CEO Jerry Liu, and learn all about LLMs, RAG, LlamaIndex and more!
Moreover, its advanced query interfaces make it a unique orchestration framework for LLM application development. Hence, it is a valuable tool for researchers, data analysts, and anyone who wants to unlock the knowledge hidden within vast amounts of textual data using LLMs.
Hence, LangChain and LlamaIndex are two useful orchestration frameworks to assist you in the LLM application development process. Here’s a guide explaining the role of these frameworks in simplifying the LLM apps.
Here’s a webinar introducing you to the architectures for LLM applications, including LangChain and LlamaIndex:
Understand the key differences between LangChain and LlamaIndex
The Architecture of Large Language Model Applications
While we have explored the realm of LLM applications and frameworks that support their development, it’s time to take our understanding of large language models a step ahead.
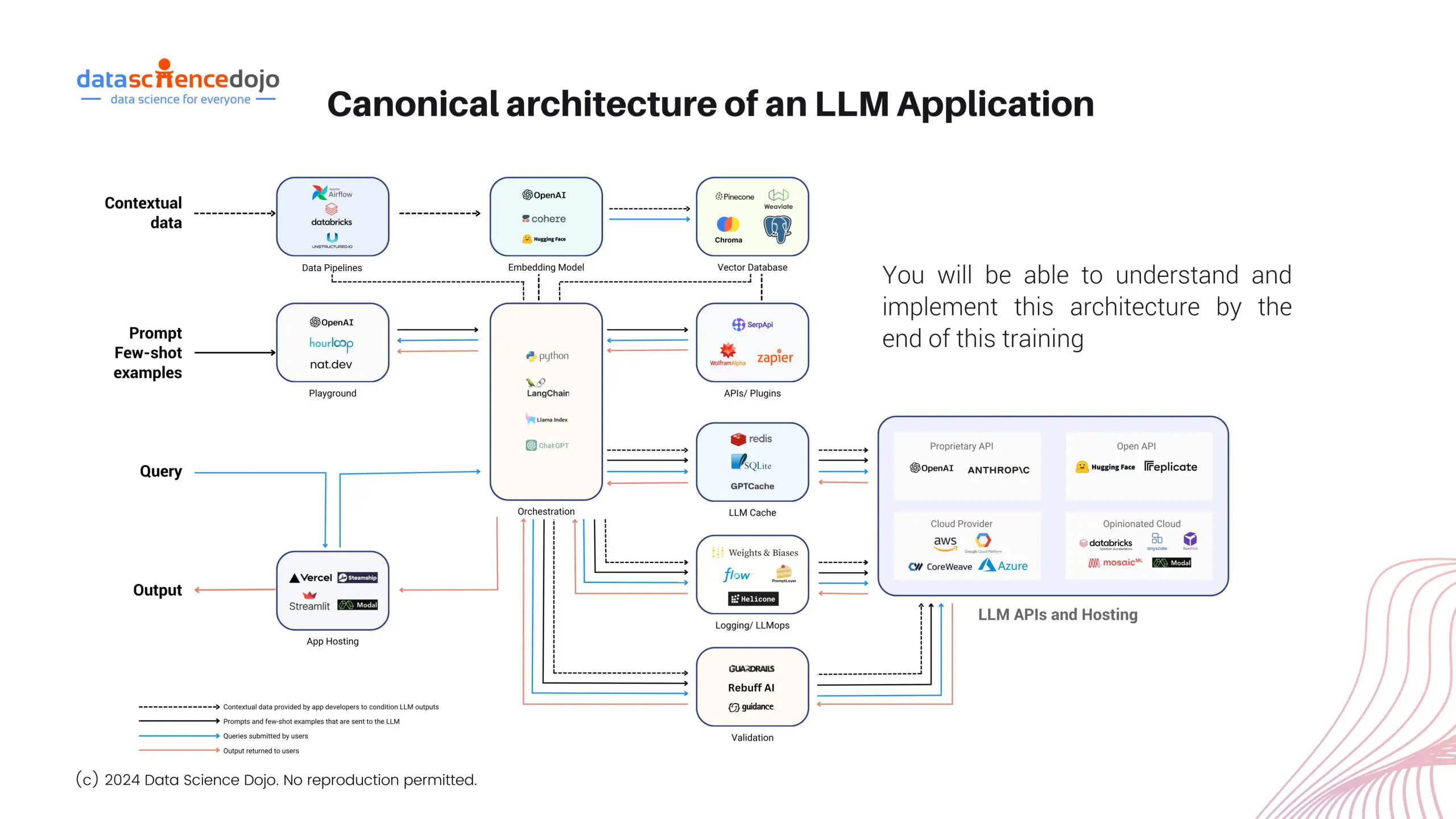
Let’s dig deeper into the key aspects and concepts that contribute to the development of an effective LLM application.
Transformers and Attention Mechanisms
The concept of transformers in neural networks has roots stretching back to the early 1990s with Jürgen Schmidhuber’s “fast weight controller” model. However, researchers have constantly worked towards the advancement of the concept, leading to the rise of transformers as the dominant force in natural language processing
It has paved the way for their continued development and remarkable impact on the field. Transformer models have revolutionized NLP with their ability to grasp long-range connections between words because understanding the relationship between words across the entire sentence is crucial in such applications.
Read along to understand different transformer architectures and their uses
While you understand the role of transformer models in the development of NLP applications, here’s a guide to decoding the transformers further by exploring their underlying functionality using an attention mechanism. It empowers models to produce faster and more efficient results for their users.
Embeddings
While transformer models form the powerful machine architecture to process language, they cannot directly work with words. Transformers rely on embeddings to create a bridge between human language and its numerical representation for the machine model.
Hence, embeddings take on the role of a translator, making words comprehendible for ML models. It empowers machines to handle large amounts of textual data while capturing the semantic relationships in them and understanding their underlying meaning.
Thus, these embeddings lead to the building of databases that transformers use to generate useful outputs in NLP applications. Today, embeddings have also developed to present new ways of data representation with vector embeddings, leading organizations to choose between traditional and vector databases.
While here’s an article that delves deep into the comparison of traditional and vector databases, let’s also explore the concept of vector embeddings.
Learn more about embeddings and their role in LLMs
A Glimpse into the Realm of Vector Embeddings
These are a unique type of embedding used in natural language processing which converts words into a series of vectors. It enables words with similar meanings to have similar vector representations, producing a three-dimensional map of data points in the vector space.
Explore the role of vector embeddings in generative AI
Machines traditionally struggle with language because they understand numbers, not words. Vector embeddings bridge this gap by converting words into a numerical format that machines can process. More importantly, the captured relationships between words allow machines to perform NLP tasks like translation and sentiment analysis more effectively.
Here’s a video series providing a comprehensive exploration of embeddings and vector databases.
Vector embeddings are like a secret language for machines, enabling them to grasp the nuances of human language. However, when organizations are building their databases, they must carefully consider different factors to choose the right vector embedding model for their data.
However, database characteristics are not the only aspect to consider. Enterprises must also explore the different types of vector databases and their features. It is also a useful tactic to navigate through the top vector databases in the market.
Thus, embeddings and databases work hand-in-hand in enabling transformers to understand and process human language. These developments within the world of LLMs have also given rise to the idea of prompt engineering. Let’s understand this concept and its many facets.
Explore the top 10 LLM use cases
Prompt Engineering
It refers to the art of crafting clear and informative prompts when one interacts with large language models. Well-defined instructions have the power to unlock an LLM’s complete potential, empowering it to generate effective and desired outputs.
Effective prompt engineering is crucial because LLMs, while powerful, can be like complex machines with numerous functionalities. Clear prompts bridge the gap between the user and the LLM. Specifying the task, including relevant context, and structuring the prompt effectively can significantly improve the quality of the LLM’s output.
With the growing dominance of LLMs in today’s digital world, prompt engineering has become a useful skill to hone for individuals. It has led to increased demand for skilled, prompt engineers in the job market, making it a promising career choice for people. While it’s a skill to learn through experimentation, here is a 10-step roadmap to kickstart the journey.
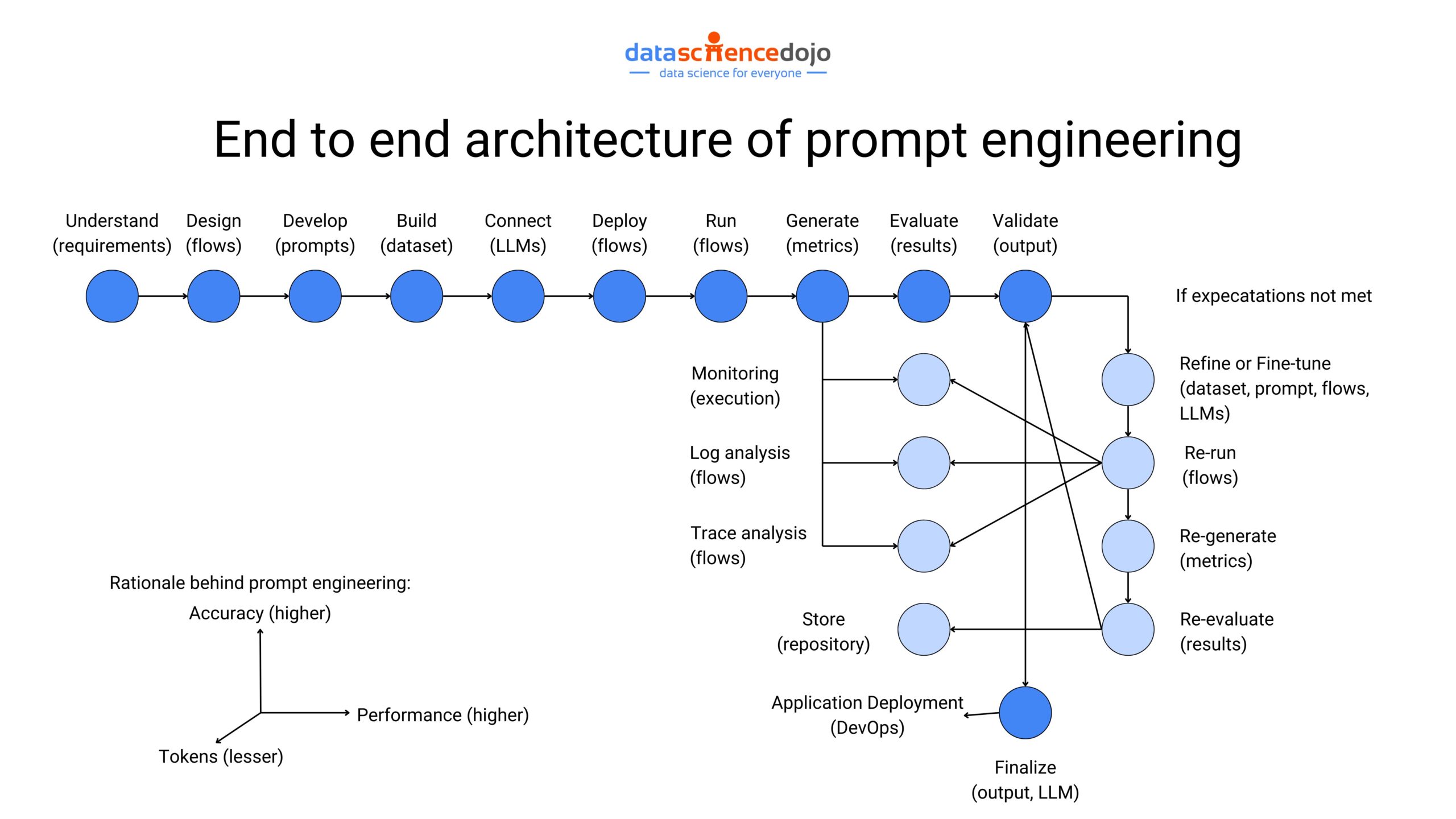
Now that we have explored the different aspects contributing to the functionality of large language models, it’s time we navigate the processes for optimizing LLM performance.
How to Optimize the Performance of Large Language Models?
As businesses work with the design and use of different LLM applications, it is crucial to ensure the use of their full potential. It requires them to optimize LLM performance, creating enhanced accuracy, efficiency, and relevance of LLM results. Some common terms associated with the idea of optimizing LLMs are listed below:
Dynamic Few-Shot Prompting
Beyond the standard few-shot approach, it is an upgrade that selects the most relevant examples based on the user’s specific query. The LLM becomes a resourceful tool, providing contextually relevant responses. Hence, top 10 LLM use cases enhances an LLM’s performance, creating more captivating digital content.

Selective Prediction
It allows LLMs to generate selective outputs based on their certainty about the answer’s accuracy. It enables the applications to avoid results that are misleading or contain incorrect information. Hence, by focusing on high-confidence outputs, selective prediction enhances the reliability of LLMs and fosters trust in their capabilities.
Predictive Analytics
In the AI-powered technological world of today, predictive analytics have become a powerful tool for high-performing applications. The same holds for its role and support in large language models. The analytics can identify patterns and relationships that can be incorporated into improved fine-tuning of LLMs, generating more relevant outputs.
Here’s a crash course to deepen your understanding of predictive analytics!
Chain-Of-Thought Prompting
It refers to a specific type of few-shot prompting that breaks down a problem into sequential steps for the model to follow. It enables LLMs to handle increasingly complex tasks with improved accuracy. Thus, chain-of-thought prompting improves the quality of responses and provides a better understanding of how the model arrived at a particular answer.
Read more about the role of chain-of-thought and zero-shot prompting in LLMs here
Zero-Shot Prompting
Zero-shot prompting unlocks new skills for LLMs without extensive training. By providing clear instructions through prompts, even complex tasks become achievable, boosting LLM versatility and efficiency. This approach not only reduces training costs but also pushes the boundaries of LLM capabilities, allowing us to explore their potential for new applications.
While these terms pop up when we talk about optimizing LLM performance, let’s dig deeper into the process and talk about some key concepts and practices that support enhanced LLM results.
Fine-Tuning LLMs
It is a powerful technique that improves LLM performance on specific tasks. It involves training a pre-trained LLM using a focused dataset for a relevant task, providing the application with domain-specific knowledge. It ensures that the model output is refined for that particular context, making your LLM application an expert in that area.
Here is a detailed guide that explores the role, methods, and impact of fine-tuning LLMs. While this provides insights into ways of fine-tuning an LLM application, another approach includes tuning specific LLM parameters. It is a more targeted approach, including various parameters like the model size, temperature, context window, and much more.
Read about Deep Double Descent and its impact on LLM performance
Moreover, among the many techniques of fine-tuning, Direct Preference Optimization (DPO) and Reinforcement Learning from Human Feedback (RLHF) are popular methods of performance enhancement. Here’s a quick glance at comparing the two ways for you to explore.

Retrieval Augmented Generation (RAG)
RAG or retrieval augmented generation is a LLM optimization technique that particularly addresses the issue of hallucinations in LLMs. An LLM application can generate hallucinated responses when prompted with information not present in their training set, despite being trained on extensive data.
Learn all you need to know about Retrieval Augmented Generation
The solution with RAG creates a bridge over this information gap, offering a more flexible approach to adapting to evolving information. Here’s a guide to assist you in implementing RAG to elevate your LLM experience.
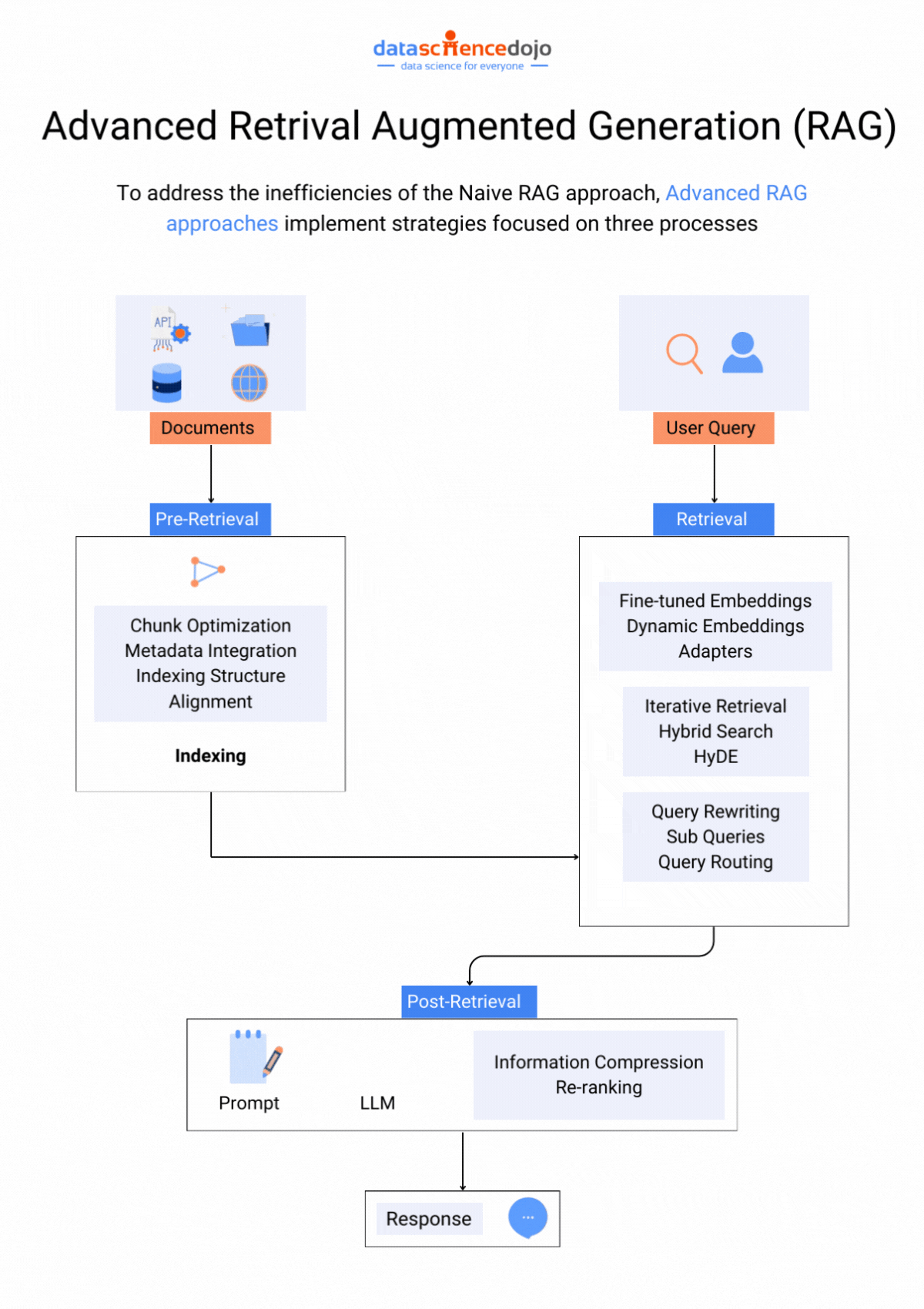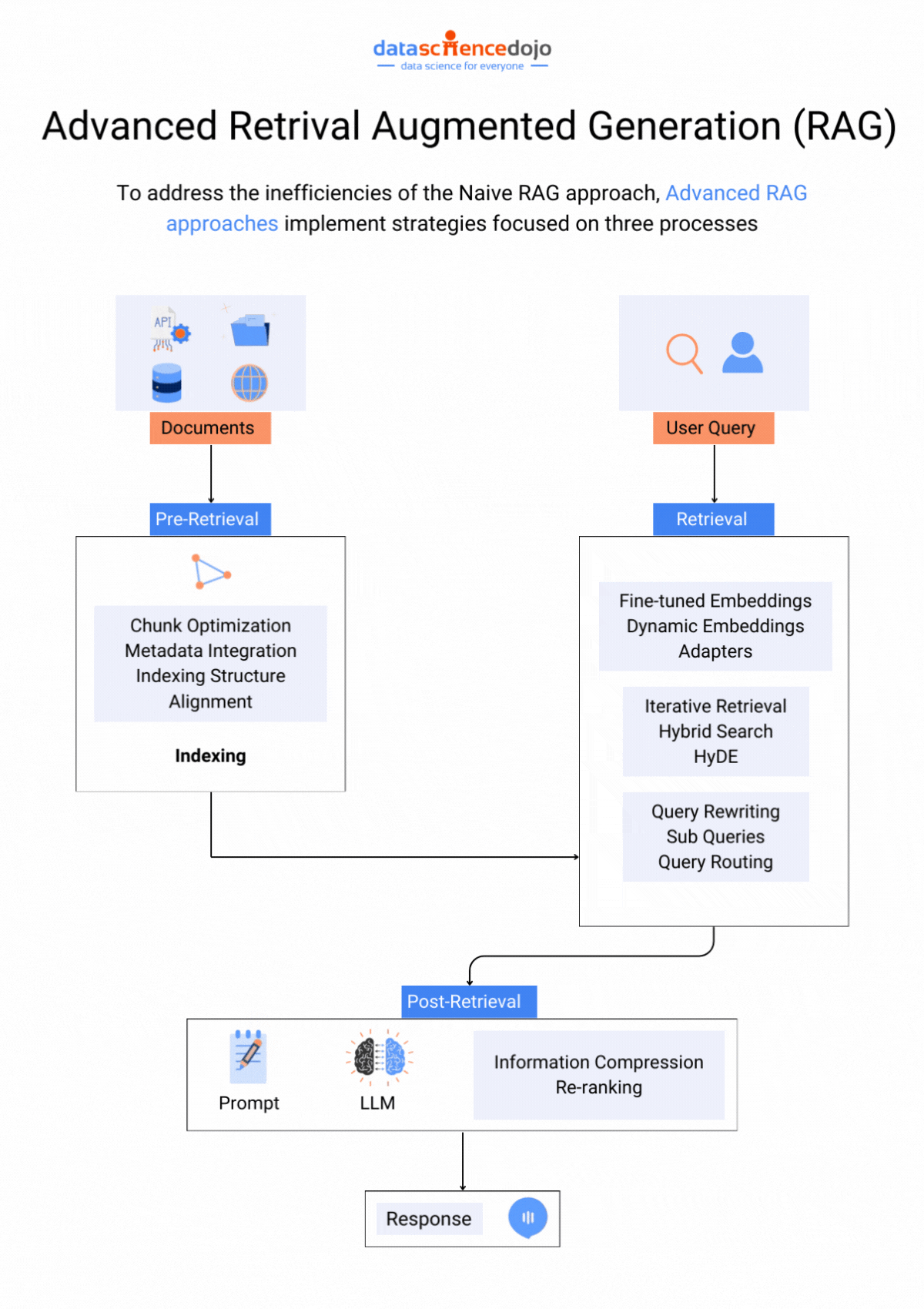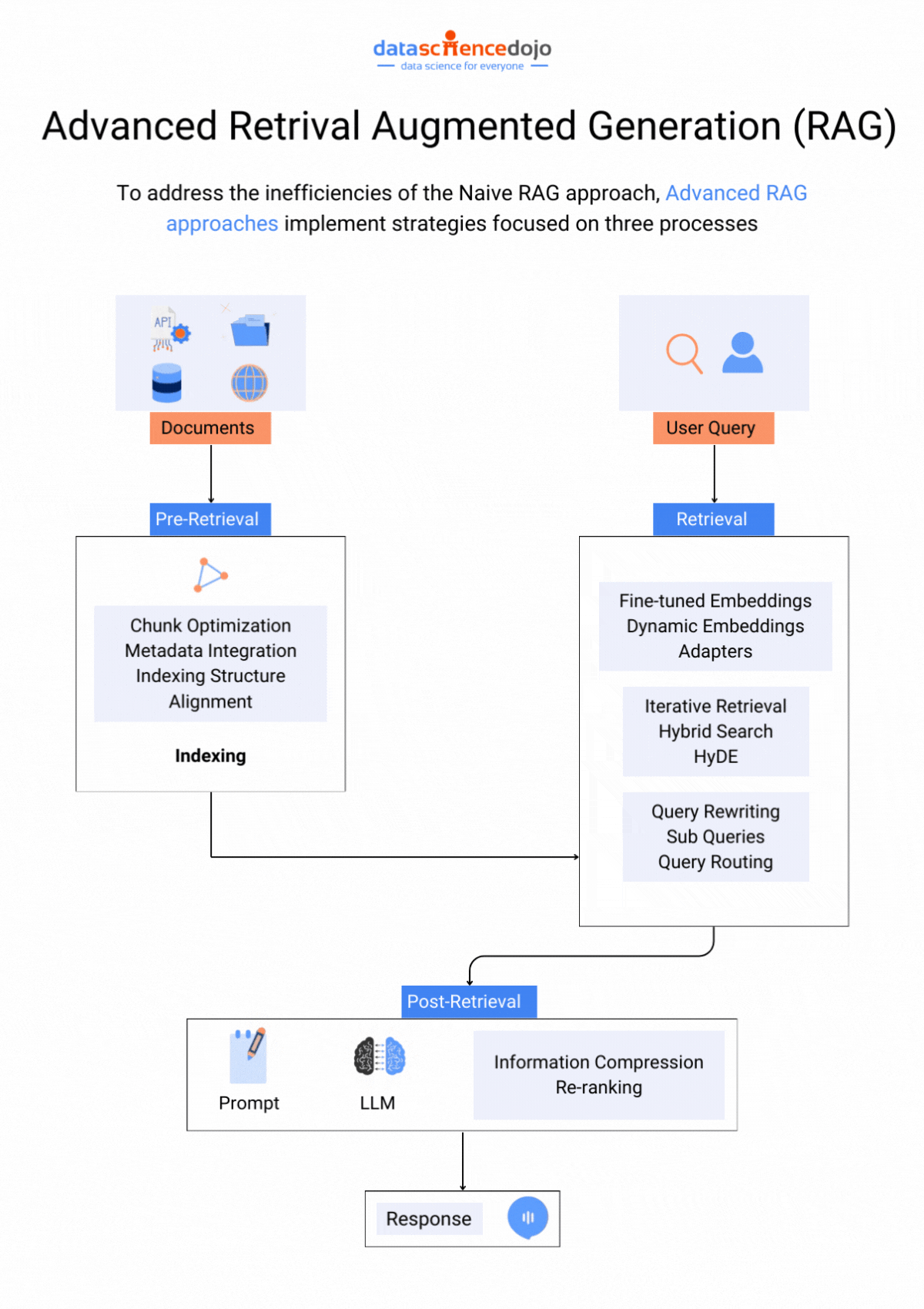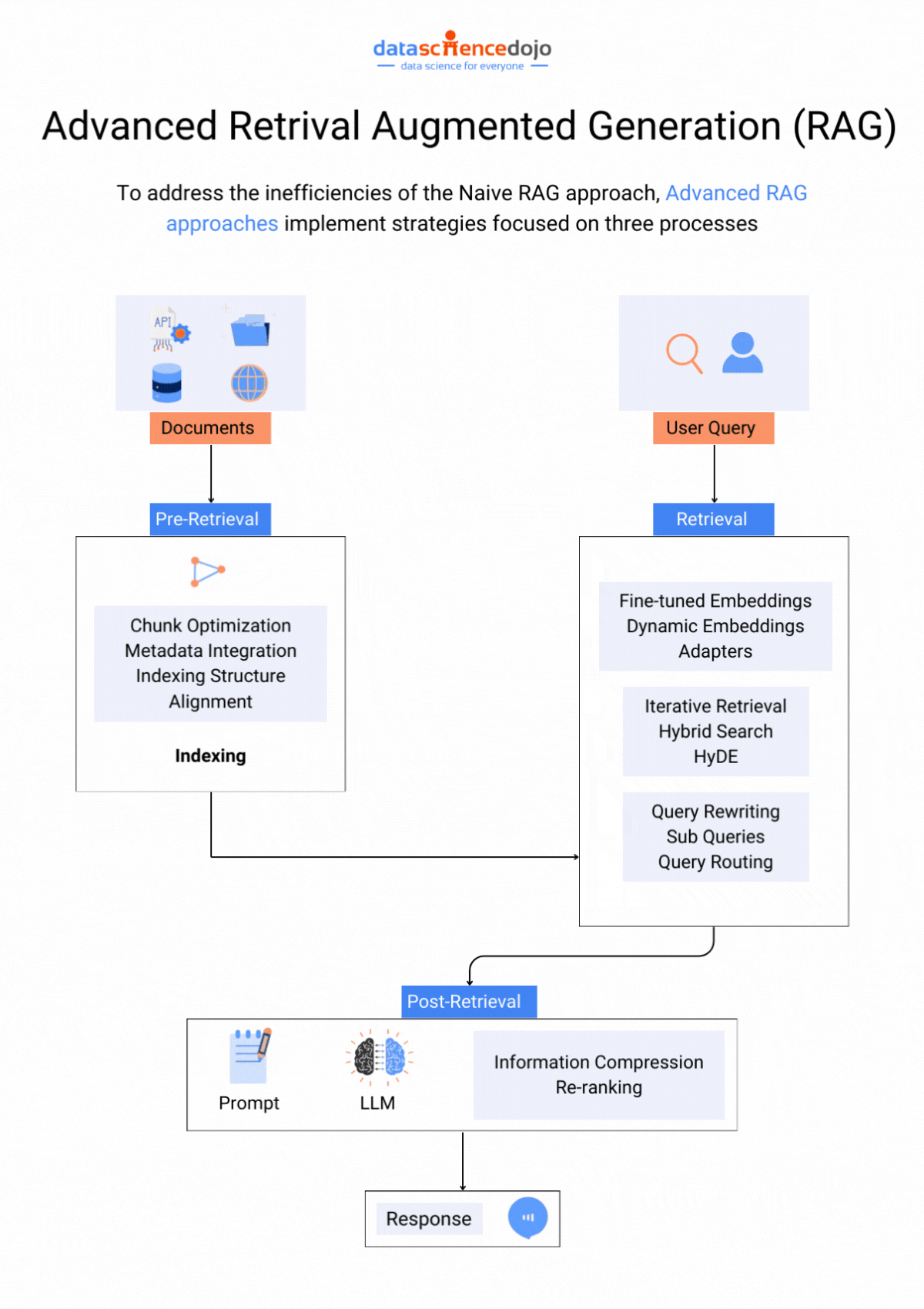
Hence, with these two crucial approaches to enhance LLM performance, the question comes down to selecting the most appropriate one.
RAG and Fine-Tuning
Let me share two valuable resources that can help you answer the dilemma of choosing the right technique for LLM performance optimization.
RAG and Fine-Tuning
The blog provides a detailed and in-depth exploration of the two techniques, explaining the workings of a RAG pipeline and the fine-tuning process. It also focuses on explaining the role of these two methods in advancing the capabilities of LLMs.
RAG vs Fine-Tuning
Once you are hooked by the importance and impact of both methods, delve into the findings of this article that navigates through the RAG vs fine-tuning dilemma. With a detailed comparison of the techniques, the blog takes it a step ahead and presents a hybrid approach for your consideration as well.

While building and optimizing are crucial steps in the journey of developing LLM applications, evaluating large language models is an equally important aspect.
Evaluating LLMs
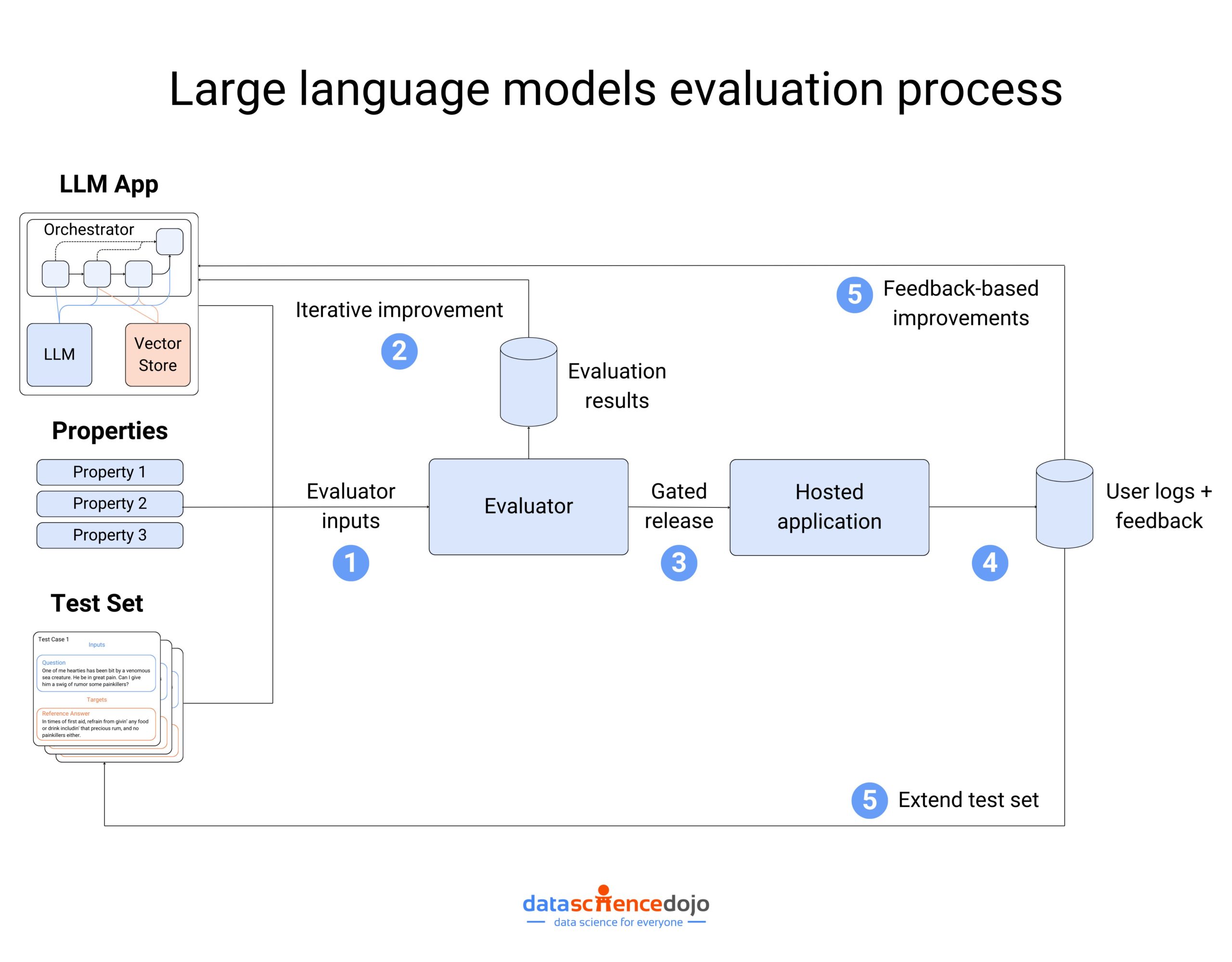
It is the systematic process of assessing an LLM’s performance, reliability, and effectiveness across various tasks. Usually, through a series of tests to gauge its strengths, weaknesses, and suitability for different applications, we can evaluate LLM performance.
It ensures that a large language model application shows the desired functionality while highlighting its areas of strengths and weaknesses. It is an effective way to determine which LLMs are best suited for specific tasks.
Learn more about the simple and easy techniques for evaluating LLMs.
Among the transforming trends of evaluating LLMs, some common aspects to consider during the evaluation process include:
- Performance Metrics – It includes accuracy, fluency, and coherence to assess the quality of the LLM’s outputs
- Generalization – It explores how well the LLM performs on unseen data, not just the data it was trained on
- Robustness – It involves testing the LLM’s resilience against adversarial attacks or output manipulation
- Ethical Considerations – It considers potential biases or fairness issues within the LLM’s outputs
Explore the top LLM evaluation methods you can use when testing your LLM applications. A key part of the process also involves understanding the challenges and risks associated with large language models.
Read in-depth about LLM evaluation benchmarks, metrics, and more
Challenges and Risks of Large Language Models
Like any other technological tool or development, LLMs also carry certain challenges and risks in their design and implementation. Some common issues associated with LLMs include hallucinations in responses, high toxic probabilities, bias and fairness, data security threats, and lack of accountability.
However, the problems associated with LLMs do not go unaddressed. The answer lies in the best practices you can take on when dealing with LLMs to mitigate the risks, and also in implementing the large language model operations (also known as LLMOps) process that puts special focus on addressing the associated challenges.
Hence, it is safe to say that as you start your LLM journey, you must navigate through various aspects and stages of development and operation to get a customized and efficient LLM application. The key to it all is to take the first step towards your goal – the rest falls into place gradually.
Explore the top 5 LLM leaderboards used for evaluation
Some Resources to Explore
To sum it up – here’s a list of some useful resources to help you kickstart your LLM journey!
- A list of best large language models in 2024
- An overview of the 20 key technical terms to make you well-versed in the LLM jargon
- A blog introducing you to the top 9 YouTube channels to learn about LLMs
- A list of the top 10 YouTube videos to help you kickstart your exploration of LLMs
- An article exploring the top 5 generative AI and LLM bootcamps
Bonus Addition!
If you are unsure about bootcamps – here are some insights into their importance. The hands-on approach and real-time learning might be just the push you need to take your LLM journey to the next level! And it’s not too time-consuming, you’d know the most about LLMs in as much as 40 hours!