

Mistral AI, a startup co-founded by individuals with experience at Google’s DeepMind and Meta, made a significant entrance into the world of LLMs with Mistral 7B. This model can be easily accessed and downloaded from GitHub or via a 13.4-gigabyte torrent, emphasizing accessibility.
Mistral 7b, a 7.3 billion parameter model with the sheer size of some of its competitors, Mistral 7b punches well above its weight in terms of capability and efficiency.
What makes Mistral 7b a Great Competitor?
One of the key strengths of Mistral 7b lies in its architecture. Unlike many LLMs relying solely on transformer networks, Mistral 7b incorporates a hybrid approach, leveraging transformers and recurrent neural networks (RNNs). This unique blend allows Mistral 7b to excel at tasks that require both long-term memory and context awareness, such as question answering and code generation.
Learn in detail about the LLM Evaluation Method
Furthermore, Mistral 7b utilizes innovative attention mechanisms like group query attention and sliding window attention. These techniques enable the model to focus on relevant parts of the input data more effectively, improving performance and efficiency.
Mistral 7b Architecture
Mistral 7B is an architecture based on transformer architecture and introduces several innovative features and parameters. Here are the architectural details;
1. Sliding Window Attention
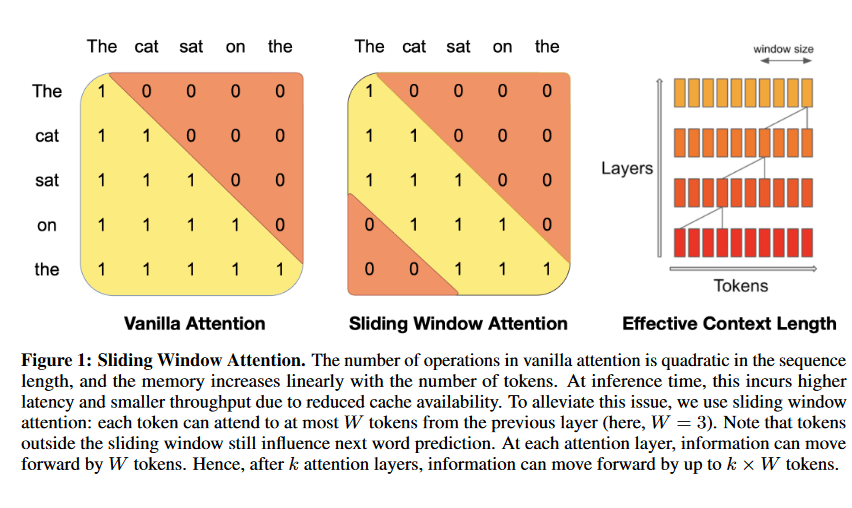
Mistral 7B addresses the quadratic complexity of vanilla attention by implementing Sliding Window Attention (SWA). SWA allows each token to attend to a maximum of W tokens from the previous layer (here, W = 3).
Tokens outside the sliding window still influence next-word prediction. Information can propagate forward by up to k × W tokens after k attention layers. Parameters include dim = 4096, n_layers = 32, head_dim = 128, hidden_dim = 14336, n_heads = 32, n_kv_heads = 8, window_size = 4096, context_len = 8192, and vocab_size = 32000.
2. Rolling Buffer Cache
This fixed-size cache serves as the “memory” for the sliding window attention. It efficiently stores key-value pairs for recent timesteps, eliminating the need for recomputing that information. A set attention span stays constant, managed by a rolling buffer cache limiting its size.
Within the cache, each time step’s keys and values are stored at a specific location, determined by i mod W, where W is the fixed cache size. When the position i exceeds W, previous values in the cache get replaced. This method slashes cache memory usage by 8 times while maintaining the model’s effectiveness.
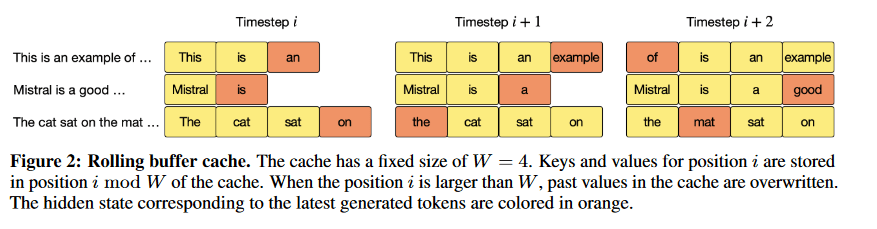
3. Pre-fill and Chunking
During sequence generation, the cache is pre-filled with the provided prompt to enhance context. For long prompts, chunking divides them into smaller segments, each treated with both cache and current chunk attention, further optimizing the process.
When creating a sequence, tokens are guessed step by step, with each token relying on the ones that came before it. The starting information, known as the prompt, lets us fill the (key, value) cache beforehand with this prompt.
The chunk size can determine the window size, and the attention mask is used across both the cache and the chunk. This ensures the model gets the necessary information while staying efficient.

Comparison of Performance: Mistral 7B vs Llama2-13B
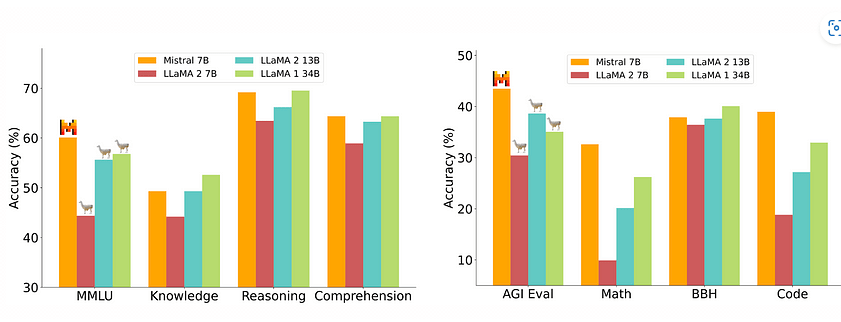
The true test of any LLM lies in its performance on real-world tasks. Mistral 7b has been benchmarked against several established models, including Llama 2 (13B parameters) and Llama 1 (34B parameters).
The results are impressive, with Mistral 7b outperforming both models on all tasks tested. It even approaches the performance of CodeLlama 7B (also 7B parameters) on code-related tasks while maintaining strong performance on general language tasks. Performance comparisons were conducted across a wide range of benchmarks, encompassing various aspects.
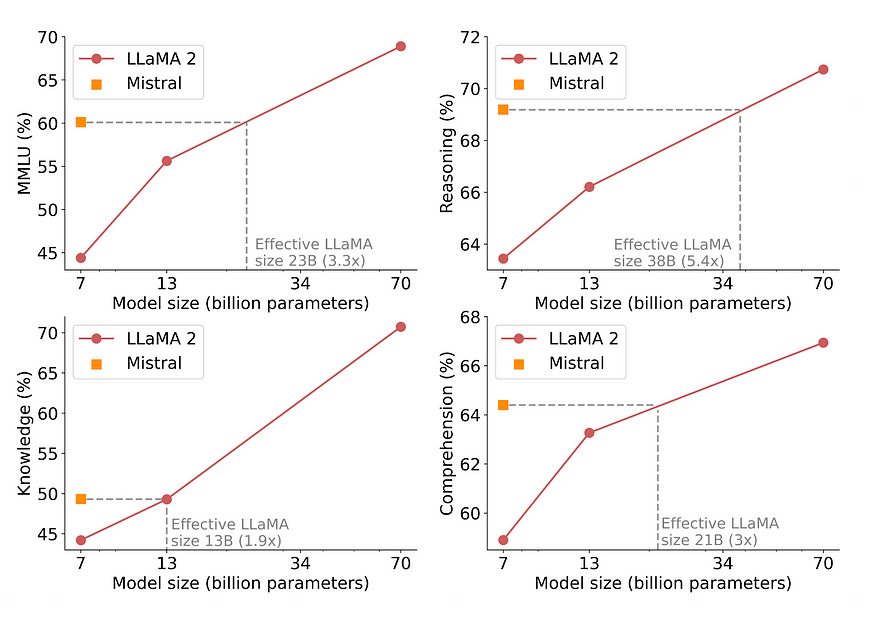
1. Performance Comparison: Mistral 7B surpasses Llama2-13B across various benchmarks, excelling in common sense reasoning, world knowledge, reading comprehension, and mathematical tasks. Its dominance isn’t marginal; it’s a robust demonstration of its capabilities.

2. Equivalent Model Capacity: In reasoning, comprehension, and STEM tasks, Mistral 7B functions akin to a Llama2 model over three times its size. This not only highlights its efficiency in memory usage but also its enhanced processing speed. Essentially, it offers immense power within an elegantly streamlined design.
Explore 7B showdown of LLMs: Mistral 7B vs Llama-2 7B
3. Knowledge-based Assessments: Mistral 7B demonstrates superiority in most assessments and competes equally with Llama2-13B in knowledge-based benchmarks. This parallel performance in knowledge tasks is especially intriguing, given Mistral 7B’s comparatively restrained parameter count.

Beyond Benchmarks: Practical Applications
The capabilities of Mistral 7B extend far beyond benchmark scores, showcasing a versatility that is not confined to a single skill. This model excels across various tasks, effectively bridging code-related fields and English language tasks. Its performance is particularly notable in coding tasks, where it rivals the capabilities of CodeLlama-7B, underscoring its adaptability and broad-ranging abilities. Below are some of the common applications in different fields:
Natural Language Processing (NLP)
Mistral 7B demonstrates strong proficiency in NLP tasks such as machine translation, where it can convert text between languages with high accuracy. It also excels in text summarization, efficiently condensing lengthy documents into concise summaries while retaining key information.
Learn more about Natural Language Processing and its Applications
For question answering, the model provides precise and relevant responses, and in sentiment analysis, it accurately detects and interprets the emotional tone of text.
Code Generation and Analysis
In the realm of code generation, Mistral 7B can produce code snippets from natural language descriptions, streamlining the development process. It also translates natural language instructions into code, facilitating automation and reducing manual coding errors.
Additionally, the model analyzes existing code to identify potential issues, offering suggestions for improvements and debugging.
Creative Writing

Education and Research
By excelling in these diverse applications, Mistral 7B proves itself to be a versatile and powerful tool across multiple domains.
Key Features of Mistral 7b

A Cost-Effective Solution
One of the most compelling aspects of Mistral 7B is its cost-effectiveness. Compared to other models of similar size, Mistral 7B requires significantly less computational resources to operate. This feature makes it an attractive option for both individuals and organizations, particularly those with limited budgets, seeking powerful language model capabilities without incurring high operational costs.
Learn more about the 7B showdown of LLMs: Mistral 7B vs Llama-2 7B
Mistral AI enhances this accessibility by offering flexible deployment options, allowing users to either run the model on their own infrastructure or utilize cloud-based solutions, thereby accommodating diverse operational needs and preferences.
Versatile Deployment and Open Source Flexibility
Mistral 7B is distinctive due to its Apache 2.0 license, which grants broad accessibility for a variety of users, ranging from individuals to major corporations and governmental bodies. This open-source license not only ensures inclusivity but also encourages customization and adaptation to meet specific user requirements.
Understand Genius of Mixtral of Experts by Mistral AI
By allowing users to modify, share, and utilize Mistral 7B for a wide array of applications, it fosters innovation and collaboration within the community, supporting a dynamic ecosystem of development and experimentation.
Decentralization and Transparency Concerns
While Mistral AI emphasizes transparency and open access, there are safety concerns associated with its fully decentralized ‘Mistral-7B-v0.1’ model, which is capable of generating unmoderated responses. Unlike more regulated models such as GPT and LLaMA, it lacks built-in mechanisms to discern appropriate responses, posing potential exploitation risks.
Nonetheless, despite these safety concerns, decentralized Large Language Models (LLMs) offer significant advantages by democratizing AI access and enabling positive applications across various sectors.
Are Large Language Models the Zero Shot Reasoners? Read here
Conclusion
Mistral 7b is a testament to the power of innovation in the LLM domain. Despite its relatively small size, it has established itself as a force to be reckoned with, delivering impressive performance across a wide range of tasks. With its focus on efficiency and cost-effectiveness, Mistral 7b is poised to democratize access to cutting-edge language technology and shape the future of how we interact with machines.