

Large Language Models (LLMs) like GPT-3 and BERT have revolutionized the field of natural language processing. However, large language models evaluation is as crucial as their development. This blog delves into the methods used to assess LLMs, ensuring they perform effectively and ethically.
Evaluation Metrics and Methods

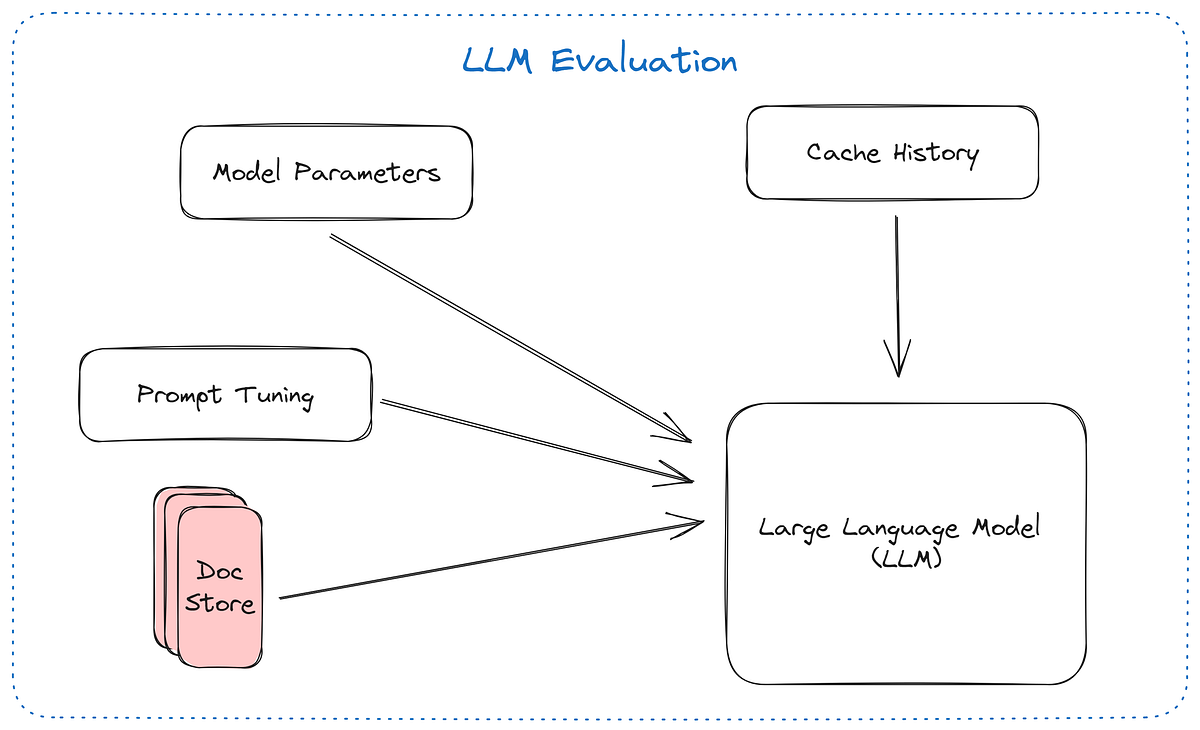
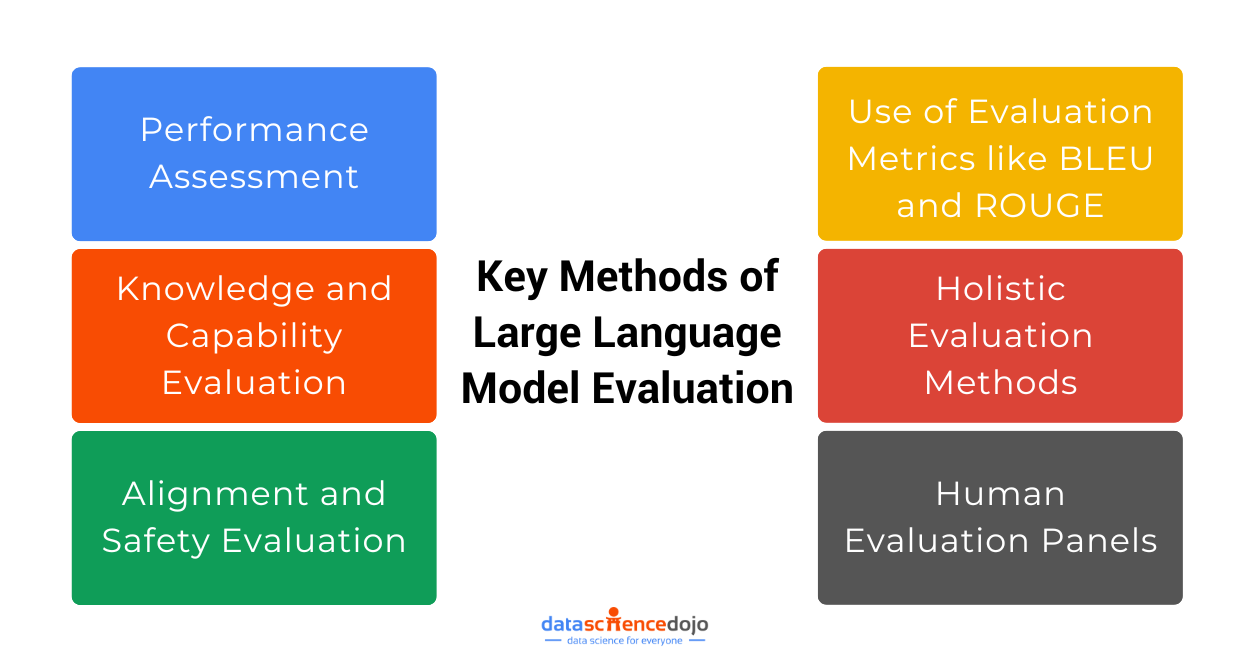
Evaluating large language models (LLMs) is a comprehensive and intricate process that ensures models perform effectively, reliably, and ethically across a wide range of applications. Here’s a look at the key aspects;
Understand 7 Best Large Language Models (LLMs)
Perplexity: Perplexity measures how well a model predicts a text sample. A lower perplexity indicates better performance, as the model is less ‘perplexed’ by the data.
Accuracy, safety, and fairness: Beyond mere performance, assessing an LLM involves evaluating its accuracy in understanding and generating language, safety in avoiding harmful outputs, and fairness in treating all groups equitably.
Embedding-based methods: Methods like BERTScore use embeddings (vector representations of text) to evaluate the semantic similarity between the model’s output and reference texts.
Human evaluation panels: Panels of human evaluators can judge the model’s output for aspects like coherence, relevance, and fluency, offering insights that automated metrics might miss.
Benchmarks like MMLU and HellaSwag: These benchmarks test an LLM’s ability to handle complex language tasks and scenarios, gauging its generalizability and robustness.
Learn about the Top 10 LLM Benchmarks for Comprehensive Model Evaluation
Holistic evaluation: Frameworks like the Holistic Evaluation of Language Models (HELM) assess models across multiple metrics, including accuracy and calibration, to provide a comprehensive view of their capabilities.
Bias detection and interpretability methods: These methods evaluate how biased a model’s outputs are and how interpretable its decision-making process is, addressing ethical considerations.
Explore Algorithmic Biases and Challenges to achieve Fairness in AI
Explore LLM Guide: A Beginner’s Resource to the Decade’s Top Technology