
In the dynamic landscape of artificial intelligence, the emergence of Large Language Models (LLMs) has propelled the field of natural language processing into uncharted territories. As these models, exemplified by giants like GPT-3 and BERT, continue to evolve and scale in complexity, the need for robust evaluation methods becomes increasingly paramount.
This blog embarks on a journey through the transformative trends that have shaped the landscape of evaluating large language models. From the early benchmarks to the multifaceted metrics of today, we explore the nuanced evolution of evaluation methodologies.
Introduction to Large Language Models (LLMs)
The advent of Large Language Models (LLMs) marks a transformative era in natural language processing, redefining the landscape of artificial intelligence. LLMs are sophisticated neural network-based models designed to understand and generate human-like text at an unprecedented scale.
Among the notable LLMs, OpenAI’s GPT (Generative Pre-trained Transformer) series and Google’s BERT (Bidirectional Encoder Representations from Transformers) have gained immense prominence.
Fueled by massive datasets and computational power, these models showcase an ability to grasp the context, generate coherent text, and even perform language-related tasks, from translation to question-answering.
The significance of LLMs lies not only in their impressive linguistic capabilities but also in their potential applications across various domains, such as content creation, conversational agents, and information retrieval. As we delve into the evolving trends in evaluating LLMs, understanding their fundamental role in reshaping how machines comprehend and generate language becomes crucial.
Here’s a list of the best LLMs you must know about
Early Evaluation Benchmarks
In the nascent stages of evaluating Large Language Models (LLMs), early benchmarks predominantly relied on simplistic metrics such as perplexity and accuracy. This was because LLMs were initially developed for specific tasks, such as machine translation and question answering.
As a result, accuracy was seen as a crucial measure of their performance – these rudimentary assessments aimed to gauge a model’s language generation capabilities and overall accuracy in processing information.
The following are some of the metrics that were used in the early evaluation of LLMs.
1. Word Error Rate (WER)
One of the earliest metrics used to evaluate LLMs was the Word Error Rate (WER). WER measures the percentage of errors in a machine-generated text compared to a reference text. It was initially used for machine translation evaluation, where the goal was to minimize the number of errors in the translated text.
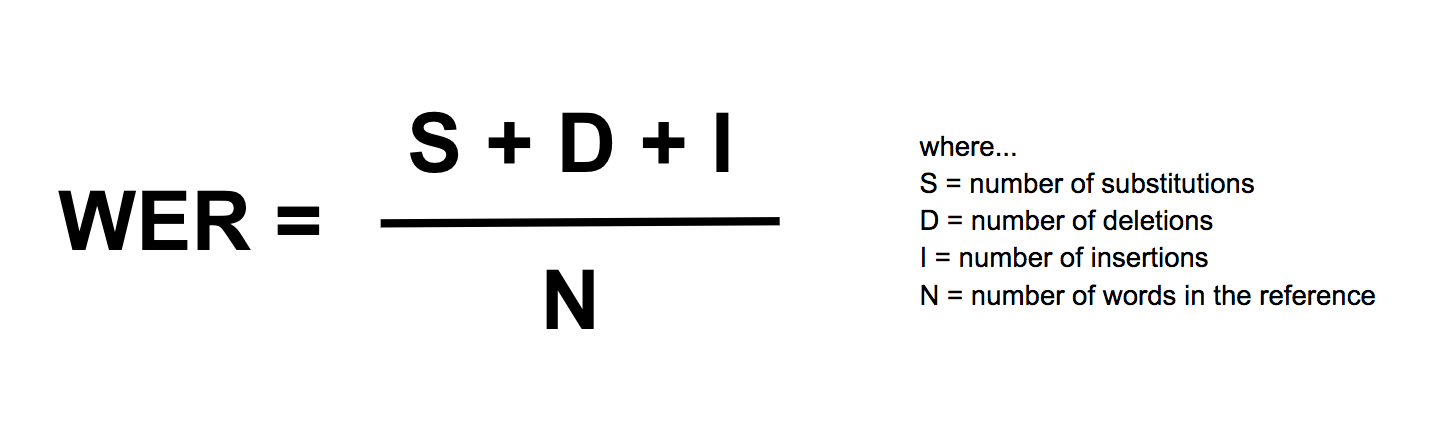
WER is calculated by dividing the total number of errors by the total number of words in the reference text. Errors can include substitutions (replacing one word with another), insertions (adding words that are not in the reference text), and deletions (removing words that are in the reference text).
WER is a simple and intuitive metric that is easy to understand and calculate. However, it has some limitations. For example, it does not consider the severity of the errors. A single substitution of a common word may not be as serious as the deletion of an important word.
2. Perplexity
Another early metric used to evaluate LLMs was perplexity. Perplexity measures the likelihood of a machine-generated text given a language model. It was widely used for evaluating the fluency and coherence of generated text.
Perplexity is calculated by exponentiating the negative average log probability of the words in the text. A lower perplexity score indicates that the language model can better predict the next word in the sequence. It is a more sophisticated metric than WER, as it considers the probability of all the words in the text. However, it is still a measure of accuracy, and it does not capture all of the nuances of human language.
3. BLEU Score
One of the most widely used metrics for evaluating machine translation is the BLEU score. BLEU (Bilingual Evaluation Understudy) is a precision-based metric that compares a machine-generated translation to one or more human-generated references.
The BLEU score is calculated by finding the n-gram precision of the machine-generated translation. N-grams are sequences of n words, and precision is the proportion of n-grams that are correct in the machine-generated translation.
The BLEU score has been criticized for some of its limitations, such as its sensitivity to word order and its inability to capture the nuances of meaning. However, it remains a widely used metric for evaluating machine translation.

These early metrics played a crucial role in the development of LLMs, providing a way to measure their progress and identify areas for improvement. However, as the complexity of LLMs burgeoned, it became apparent that these early benchmarks offered a limited perspective on the models’ true potential.
The evolving nature of language tasks demanded a shift towards more holistic evaluation metrics. The transition from these initial benchmarks marked a pivotal moment in the evaluation landscape, urging researchers to explore more nuanced methodologies that could capture the diverse capabilities of LLMs across various language tasks and domains.
This shift laid the foundation for a more comprehensive understanding of the models’ linguistic prowess and set the stage for transformative trends in the evaluation of Large Language Models.
Holistic Evaluation
As large language models (LLMs) have evolved from simple text generators to sophisticated tools capable of understanding and responding to complex tasks, the need for a more holistic approach to evaluation has become increasingly apparent. Moving beyond the limitations of accuracy-focused metrics, holistic evaluation aims to capture the diverse capabilities of LLMs and provide a comprehensive assessment of their performance.
While accuracy remains a crucial aspect of LLM evaluation, it alone cannot capture the nuances of their performance. LLMs are not just about producing grammatically correct text; they are also expected to generate fluent, coherent, creative, and fair text. Accuracy-focused metrics often fail to capture these broader aspects, leading to an incomplete understanding of LLM capabilities.
Holistic Evaluation Framework
Holistic evaluation encompasses a range of metrics that assess various aspects of LLM performance, including:
- Fluency: to generate text that is grammatically correct, natural-sounding, and easy to read.
- Coherence: to generate text that is organized, well-structured, and easy to understand.
- Creativity: to generate original, imaginative, and unconventional text formats.
- Relevance: to produce text that is pertinent to the given context, task, or topic.
- Fairness: to avoid biases and stereotypes in its outputs, ensuring that it is free from prejudice and discrimination.
- Interpretability: to explain its reasoning process, make its decisions transparent, and provide insights into its internal workings.

Holistic Evaluation Metrics
Several metrics have been developed to assess these holistic aspects of LLM performance. Some examples include:
1. METEOR
METEOR is a metric for evaluating machine translation (MT). It combines precision and recall to assess the fluency and adequacy of machine-generated translations. METEOR considers factors such as matching words, matching stems, chunk matches, synonymy matches, and ordering.
METEOR has been shown to correlate well with human judgments of translation quality. It is a versatile metric that can be used to evaluate translations of various lengths and genres.
2. GEANT
GEANT is a human-based evaluation scheme for assessing the overall quality of machine translation. It considers aspects like fluency, adequacy, and relevance. GEANT involves a panel of human evaluators who rate machine-generated translations on a scale of 1 to 4.
GEANT is a more subjective metric than METEOR, but it is considered to be a more reliable measure of overall translation quality.
3. ROUGE
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) is a recall-based metric for evaluating machine-generated summaries. It focuses on the recall of important words and phrases in the summaries. ROUGE considers the following factors:
- N-gram recall: The number of matching n-grams (sequences of n words) between the machine-generated summary and a reference summary.
- Skip-gram recall: The number of matching skip-grams (sequences of words that may not be adjacent) between the machine-generated summary and a reference summary.
ROUGE has been shown to correlate well with human judgments of summary quality. It is a versatile metric that can be used to evaluate summaries of various lengths and genres.

Multifaceted Evaluation Metrics
As LLMs like GPT-3 and BERT took center stage, the demand for more nuanced evaluation metrics surged. Researchers and practitioners recognized the need to evaluate models across a spectrum of language tasks and domains.
Enter the era of multifaceted evaluation, where benchmarks expanded to include sentiment analysis, question answering, summarization, and translation. This shift allowed for a more comprehensive understanding of a model’s versatility and adaptability.
Several metrics have been developed to assess these multifaceted aspects of LLM performance. Some examples include:
Semantic Similarity: Metrics like word embeddings and sentence embeddings measure the similarity between machine-generated text and human-written text, capturing nuances of meaning and context.
Human Evaluation Panels: Subjective assessments by trained human evaluators provide in-depth feedback on the quality of LLM outputs, considering aspects like fluency, coherence, creativity, relevance, and fairness.
Interpretability Methods: Techniques like LIME (Local Interpretable Model-agnostic Explanations) and SHAP (Shapley Additive explanations) enable us to understand the reasoning process behind LLM outputs, addressing concerns about interpretability.
Bias Detection and Mitigation: Metrics and techniques to identify and address potential biases in LLM training data and outputs, ensuring fairness and non-discrimination.
Multidimensional Evaluation Frameworks: Comprehensive frameworks like the FLUE (Few-shot Learning Evaluation) benchmark and the PaLM benchmark encompass a wide range of tasks and evaluation criteria, providing a holistic assessment of LLM capabilities.
LLMs Evaluating LLMs
LLMs Evaluating LLMs is an emerging approach to assessing the performance of large language models (LLMs) by leveraging the capabilities of LLMs themselves. This approach aims to overcome the limitations of traditional evaluation metrics, which often fail to capture the nuances and complexities of LLM performance.
Benefits of LLM-Based Evaluation
Large language models offer several advantages over traditional evaluation methods:
- Comprehensiveness: It can capture a broader range of aspects than traditional metrics, providing a more holistic assessment of LLM performance.
- Context-awareness: It has an ability to adapt to specific tasks and domains, generating reference text and evaluating outputs within relevant contexts.
- Nuanced feedback: LLMs can identify subtle nuances and provide detailed feedback on fluency, coherence, creativity, relevance, and fairness, enabling more precise evaluation.
- Adaptability: Language models can evolve alongside the development of new LLM models, continuously adapting their evaluation methods to assess the latest advancements.
Mechanism of LLM-Based Evaluation
LLMs can be utilized in various ways to evaluate other LLMs:
Generating Reference Text: Large language models can be used to generate reference text against which the outputs of other LLMs can be compared. This reference text can be tailored to specific tasks or domains, providing a more relevant and context-aware evaluation.
Assessing fluency and coherence: They can be employed to assess the fluency and coherence of text generated by other LLMs. They can identify grammatical errors, inconsistencies, and lack of clarity in the generated text, providing valuable feedback for improvement.
Evaluating creativity and originality: It also evaluates the creativity and originality of text generated by other LLMs. They can identify novel ideas, unconventional expressions, and the ability to break away from established patterns, providing insights into the creative potential of different models.
Assessing relevance and fairness: LLMs can be used to assess the relevance and fairness of text generated by other LLMs. They can identify text that is not pertinent to the given context or task, as well as text that contains biases or stereotypes, promoting responsible and ethical development of LLMs.
Also learn more about multimodality in LLMs
GPT-Eval
GPTEval is a framework for evaluating the quality of natural language generation (NLG) outputs using large language models (LLMs). GPTEval was popularized by a paper released on May 2023 called “G-EVAL: NLG Evaluation using GPT-4 with Better Human Alignment”.
It utilizes a chain-of-thoughts (CoT) approach and a form-filling paradigm to assess the coherence, fluency, and informativeness of generated text. The framework has been shown to correlate highly with human judgments in text summarization and dialogue generation tasks.
GPTEval addresses the limitations of traditional reference-based metrics, such as BLEU and ROUGE, which often fail to capture the nuances and creativity of human-generated text. By employing LLMs, GPTEval provides a more comprehensive and human-aligned evaluation of NLG outputs.
Key Features of GPTEval
Below are some key features of GPTEval to know:
- Chain-of-thoughts (CoT) approach: GPTEval breaks down the evaluation process into a sequence of reasoning steps, mirroring the thought process of a human evaluator.
- Form-filling paradigm: It utilizes a form-filling interface to guide the LLM in providing comprehensive and informative evaluations.
- Human-aligned evaluation: It demonstrates a strong correlation with human judgments, indicating its ability to capture the quality of NLG outputs from a human perspective.
GPTEval represents a significant advancement in NLG evaluation, offering a more accurate and human-centric approach to assessing the quality of the generated text. Its potential applications span a wide range of domains, including machine translation, dialogue systems, and creative text generation.
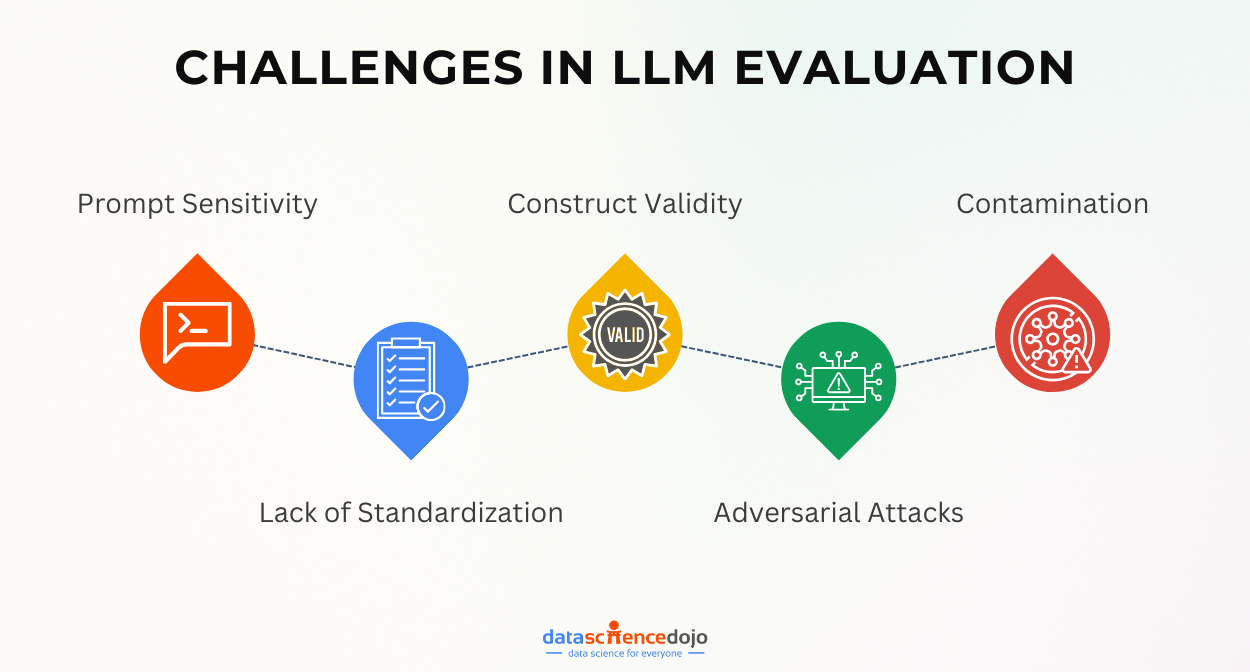
Challenges in LLM Evaluations
The evaluation of Large Language Models (LLMs) is a complex and evolving field, and there are several challenges that researchers face while evaluating LLMs. Some of the current challenges in evaluating LLMs are:
- Prompt sensitivity: Determining if an evaluation metric accurately measures the unique qualities of a model or is influenced by the specific prompt.
- Construct validity: Defining what constitutes a satisfactory answer for diverse use cases proves challenging due to the wide range of tasks that LLMs are employed for.
- Contamination: The presence of bias in LLMs introduces risk, and discerning whether the model harbors a liberal or conservative bias is a complex task.
- Lack of standardization: The absence of standardized evaluation practices leads to researchers employing diverse benchmarks and rankings to assess LLM performance, contributing to a lack of consistency in evaluations.
- Adversarial attacks: LLMs are susceptible to adversarial attacks, posing a challenge in evaluating their resilience and robustness against such intentional manipulations.
Future Horizons for Evaluating Large Language Models
The core objective in evaluating Large Language Models (LLMs) is to align them with human values, fostering models that embody helpfulness, harmlessness, and honesty. Recognizing current evaluation limitations as LLM capabilities advance, there’s a call for a dynamic process.
Some possible future directions would include:
Evaluating Risks: Current risk evaluations, often tied to question answering, may miss nuanced behaviors in LLMs with RLHF. Recognizing QA limitations, there’s a call for in-depth risk assessments, delving into why and how behaviors manifest to prevent catastrophic outcomes.
Efficient Evaluation: Efficient LLM evaluation depends on specific environments. Existing agent research focuses on capabilities, prompting a need to diversify operating environments to understand potential risks and enhance environmental diversity.
Rethinking benchmarks: Static benchmarks present challenges, including data leakage and limitations in assessing dynamic knowledge. Dynamic evaluation emerges as a promising alternative. Through continuous data updates and varied question formats, this aligns with LLMs’ evolving nature. The goal is to ensure benchmarks remain relevant and challenging as LLMs progress toward human-level performance.
Read in detail about benchmarks for LLM evaluation
In conclusion, the evaluation of Large Language Models (LLMs) has undergone a transformative journey, adapting to the dynamic capabilities of these sophisticated language generation systems. These transformative trends not only shape the evaluation of LLMs but also contribute to their development aligned with human values.
The future of LLM evaluation is about balance, pushing the limits of what LLMs can do while making sure they stay helpful and trustworthy. Want to dive deeper into AI evaluation and its impact? Check out the LLM Bootcamp by Data Science Dojo here and take your knowledge to the next level!