

7B refers to a specific model size for large language models (LLMs) consisting of seven billion parameters. With the growing importance of LLMs, there are several options in the market. Each option has a particular model size, providing a wide range of choices to users.
However, in this blog we will explore two LLMs of 7B – Mistral 7B and Llama-2 7B, navigating the differences and similarities between the two options. Before we dig deeper into the showdown of the two 7B LLMs, let’s do a quick recap of the language models.

Understanding Mistral 7B and Llama-2 7B
Mistral 7B is an LLM powerhouse created by Mistral AI. The model focuses on providing enhanced performance and increased efficiency with reduced computing resource utilization. Thus, it is a useful option for conditions where computational power is limited.
Moreover, the Mistral LLM is a versatile language model, excelling at tasks like reasoning, comprehension, tackling STEM problems, and even coding.
Read more and gain deeper insight into Mistral 7B
On the other hand, Llama-2 7B is produced by Meta AI to specifically target the art of conversation. The researchers have fine-tuned the model, making it a master of dialog applications, and empowering it to generate interactive responses while understanding the basics of human language.
The Llama model is available on platforms like Hugging Face, allowing you to experiment with it as you navigate the conversational abilities of the LLM. Hence, these are the two LLMs with the same model size that we can now compare across multiple aspects.
Battle of the 7Bs: Mistral vs Llama

Now, we can take a closer look at comparing the two language models to understand the aspects of their differences.
Performance
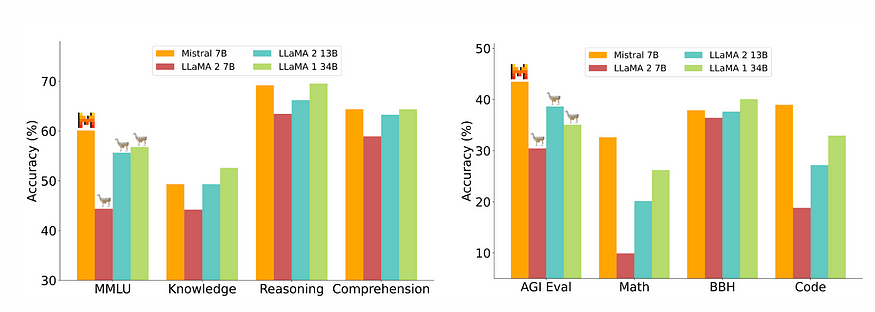
When it comes to performance, Mistral AI’s model excels in its ability to handle different tasks. It has successfully reached the benchmark scores with every standardized test for various challenges in reasoning, comprehension, problem-solving, and much more.
Also learn about Mistral AI’s Large model
On the contrary, Meta AI‘s production takes on a specialized approach. In this case, the art of conversation. While it will not score outstanding results and produce benchmark scores for a variety of tasks, its strength lies in its ability to understand and respond fluently within a dialogue.
Efficiency
Mistral 7B operates with remarkable efficiency due to the adoption of a technique called Group-Query Attention (GQA). It allows the language model to group similar queries for faster inference and results.
GQA is the middle ground between the quality of Multi-Head Attention (MHA) and the speed of Multi-Query Attention (MQA) approaches. Hence, allowing the model to strike a balance between performance and efficiency.
Also learn how to revolutionize LLM with Llama 2 fine-tuning
However, scarce knowledge of the training data of Llama-2 7B limits the understanding of its efficiency. We can still say that a broader and more diverse dataset can enhance the model’s efficiency in producing more contextually relevant responses.
Accessibility
When it comes to accessibility of the two models, both are open-source resources that are open for use and experimentation. It can be noted though, that the Llama-2 model offers easier access through platforms like Hugging Face.
Meanwhile, the Mistral language model requires some deeper navigation and understanding of the resources provided by Mistral AI. It demands some research, unlike its competitor for information access.
Hence, these are some notable differences between the two language models. While these aspects might determine the usability and access of the models, each one has the potential to contribute to the development of LLM applications significantly.

Choosing the Right Model
Since we understand the basic differences, the debate comes down to selecting the right model for use. Based on the highlighted factors of comparison here, we can say that Mistral is an appropriate choice for applications that require overall efficiency and high performance in a diverse range of tasks.
Meanwhile, Llama-2 is more suited for applications that are designed to attain conversational prowess and dialog expertise. While this distinction of use makes it easier to pick the right model, some key factors to consider also include:
- Future Development – Since both models are new, you must stay in touch with their ongoing research and updates. These advancements can bring new information to light, impacting your model selection.
- Community Support – It is a crucial factor for any open-source tool. Investigate communities for both models to get a better understanding of the models’ power. A more active and thriving community will provide you with valuable insights and assistance, making your choice easier.
Another interesting read: Mixtral of Experts
Future Prospects for Language Models
As the digital world continues to evolve, it is accurate to expect the language models to update into more powerful resources in the future. Among some potential routes for Mistral 7B is the improvement of GQA for better efficiency and the ability to run on even less powerful devices.
Moreover, Mistral AI can make the model more readily available by providing access to it through different platforms like Hugging Face. It will also allow a diverse developer community to form around it, opening doors for more experimentation with the model.

As for Llama-2 7B, future prospects can include advancements in dialog modeling. Researchers can work to empower the model to understand and process emotions in a conversation. It can also target multimodal data handling, going beyond textual inputs to handle audio or visual inputs as well.
Thus, we can speculate several trajectories for the development of these two language models. In this discussion, it can be said that no matter in what direction, an advancement of the models is guaranteed in the future. It will continue to open doors for improved research avenues and LLM applications.