Mistral AI is getting a lot of attention with its new model, Mistral Large. It’s quickly becoming a strong competitor to GPT-4, and for good reason. So, what makes Mistral Large stand out? Simply put, it offers amazing performance and flexibility that’s catching the eye of developers and businesses alike.
In this blog, we’ll take a closer look at why Mistral AI’s Large is becoming so popular, how it compares to GPT-4, and what this means for the future of AI. If you’re curious about the next big thing in AI, keep reading!

What is Mistral AI?
Before diving into the comparison between Mistral Large and GPT-4, let’s first understand what Mistral AI is all about and why it’s causing such a buzz in the world of artificial intelligence.
Mistral AI is an innovative AI research company focused on developing cutting-edge LLMs. It aims to challenge the dominance of existing AI models like GPT-4 by introducing unique features that enhance performance and efficiency.
With its breakthroughs in deep learning and natural language processing, Mistral AI is positioned to reshape the AI landscape, offering more accessible and scalable solutions for various industries.
Now, let’s understand why Mistral Large is winning hearts by exploring its key features.
Features of Mistral AI’s Large Model
If you think Mistral Large is just another large language model (LLM) in the market, think again. This model is a game-changer, packed with features that have the potential to challenge GPT-4’s dominance.
From its advanced natural language understanding and multilingual support to its fast-processing speeds and scalable architecture, Mistral Large offers powerful performance tailored to diverse needs.
Let’s dive into the details that make this model stand out and why it’s quickly becoming the go-to choice for businesses and developers alike.

Advanced Natural Language Understanding
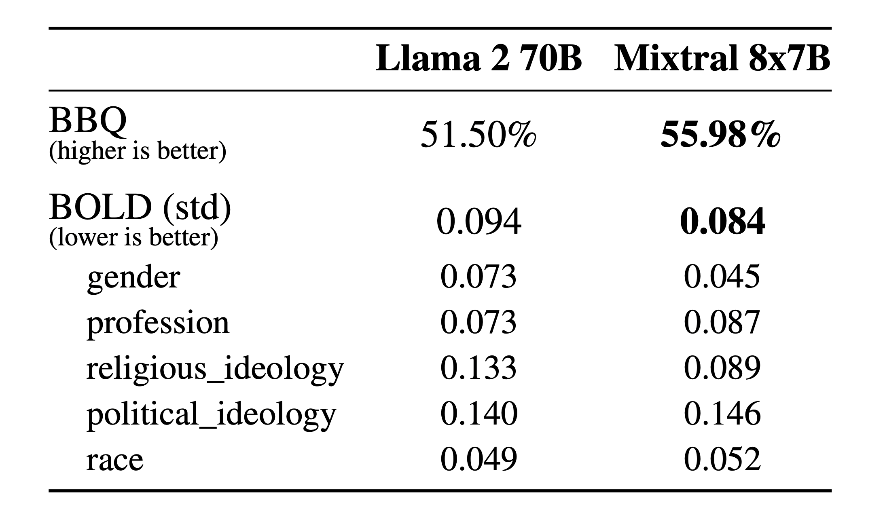
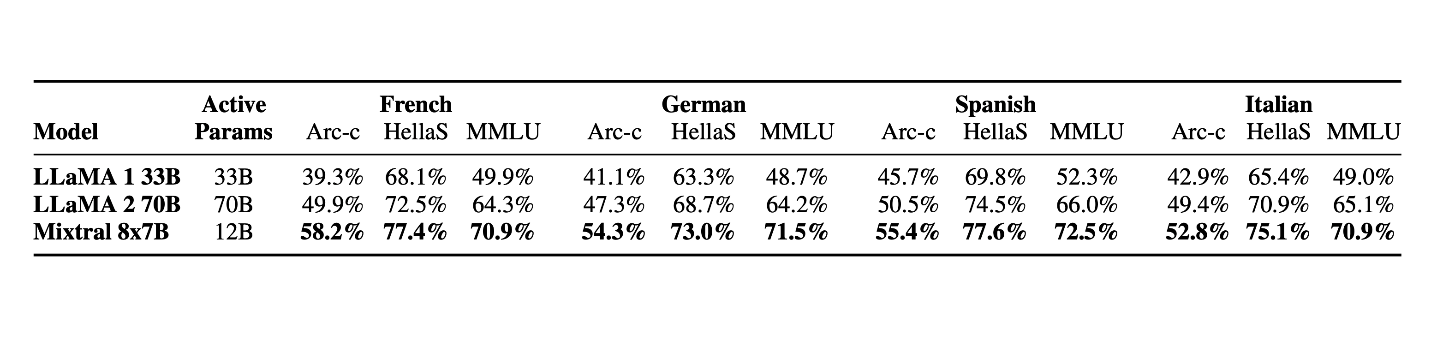
Mistral Large excels in natural language understanding, offering deep contextual awareness and accurate interpretations of user inputs. A standout feature is its native support for multiple languages, including English, French, Spanish, German, and Italian.
This broad language proficiency makes it a versatile choice for businesses and developers looking to engage with diverse audiences across the globe. It ensures high-quality, nuanced responses, no matter the language, making it a reliable tool for multilingual applications and global communication.
Model Size and Architecture Comparisons
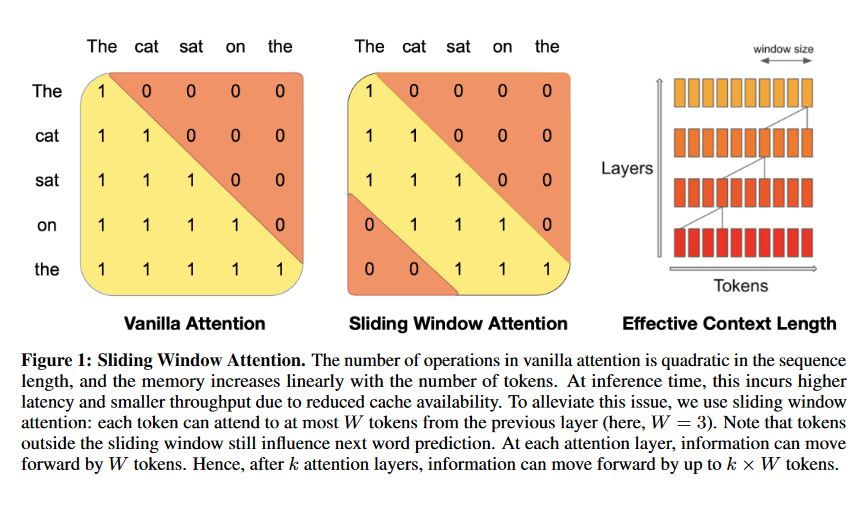
When it comes to model size and architecture, Mistral Large has been designed with efficiency in mind. While GPT-4 is known for its vast model size, Mistral AI has optimized its architecture to balance performance with resource usage.
This thoughtful design results in a model that delivers powerful results without the hefty computational demands often associated with larger models, making it more accessible for a broader range of users.
Speed and Efficiency Improvements
Speed is another area where Mistral Large makes significant strides. Thanks to its streamlined architecture and optimized processing, it offers faster response times compared to many of its competitors.
This efficiency not only enhances the user experience but also reduces operational costs, making it a practical choice for businesses looking to integrate AI solutions without compromising on performance. The combination of speed and cost savings ensures that Mistral Large stands out as a forward-thinking model in the AI landscape.
Mistral AI vs. GPT-4: A Comparative Look
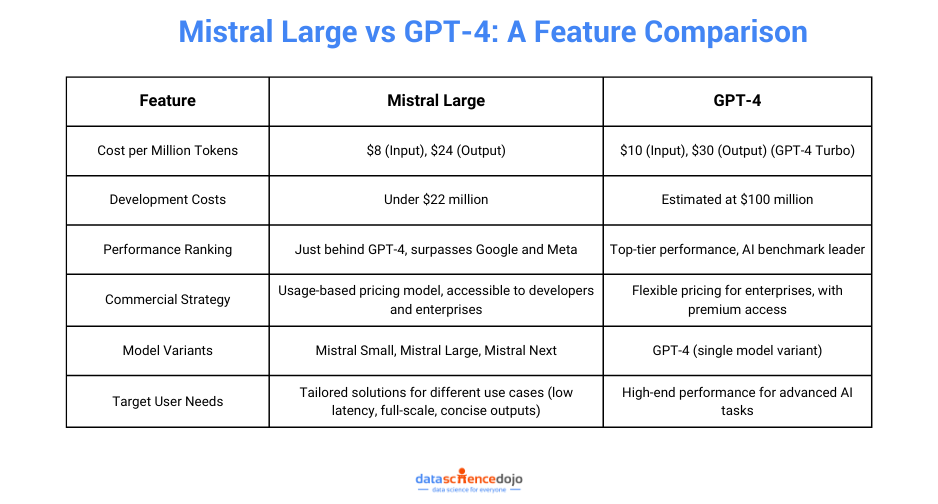
If you’ve been following the evolution of AI, you know GPT-4 has been the benchmark for excellence. But Mistral Large is stepping into the spotlight, not just as another competitor, but as a serious challenger reshaping the narrative.
With features designed to compete head-on, let’s explore how Mistral AI’s Large Model stacks up against GPT-4.
Cost Efficiency
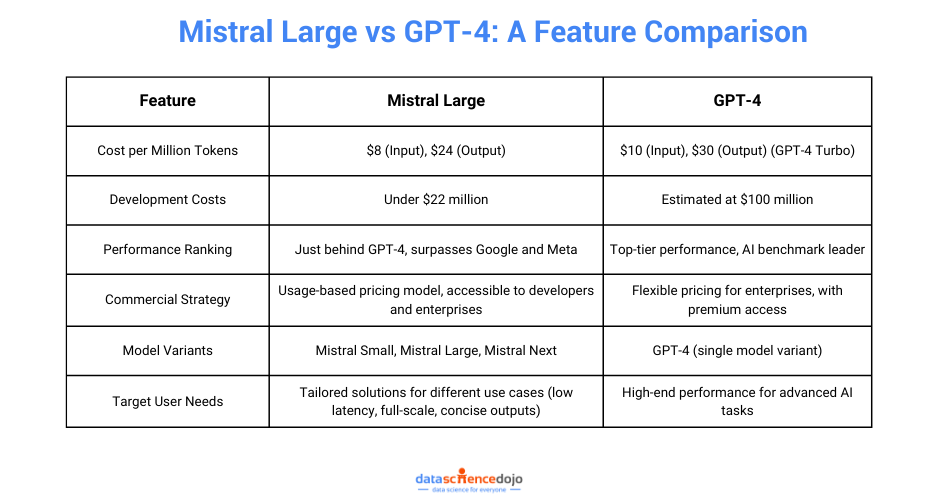
Mistral Large is designed with cost-effectiveness at its core, offering a budget-friendly alternative to other top-tier AI models. It charges $8 per million input tokens and $24 per million output tokens, making it 20% cheaper than GPT-4 Turbo.
Additionally, its development costs were kept under $22 million, significantly lower than GPT-4’s estimated $100 million. This combination of lower usage fees and efficient training highlights Mistral AI’s commitment to delivering cutting-edge technology without the hefty price tag, making advanced AI more accessible to businesses of all sizes.
Benchmark Performance
In terms of performance, Mistral Large doesn’t just compete—it excels. Ranking just behind GPT-4, it surpasses major players like Google and Meta in key benchmarks. This achievement underscores Mistral AI’s commitment to delivering a model that’s not only cost-effective but also highly capable in real-world applications.
Commercial Strategy
Mistral AI’s approach to commercialization strikes a perfect balance between accessibility and smart monetization. With its usage-based pricing model for the paid API, Mistral AI ensures that both individual developers and large enterprises can access powerful AI tools at a price point that works for them.
This flexible pricing strategy allows users to scale their usage efficiently without compromising on the quality of the AI experience.
Model Variants
Additionally, Mistral AI offers a range of model variants to cater to different user needs. Whether you’re looking for lower latency, full-scale performance, or concise outputs, there’s a model for every use case.
Users can choose from Mistral Small, Mistral Large, or Mistral Next, with each version designed to provide tailored solutions that meet specific requirements. This variety ensures that Mistral AI can support a wide spectrum of applications, from fast-response scenarios to more complex, large-scale AI tasks.
With this strategic flexibility, Mistral AI makes advanced technology accessible and adaptable for a wide range of users.

How to Choose Between Mistral AI and GPT-4
Choosing between Mistral AI and GPT-4 can feel like a big decision, especially with the impressive features both models bring to the table. To make the best choice, it’s important to think about a few key factors that align with your business needs and goals. Let’s break it down in simple terms so you can decide which AI is the right fit for you.
Evaluating Business Needs and Goals
Start by considering what your business needs. If you’re focused on supporting multiple languages, fast response times, or scalable solutions, Mistral Large could be the better fit. Its strong multilingual capabilities and efficient processing handle a wide range of tasks with ease.
On the other hand, if you need an AI with a broad range of applications and top-tier benchmark performance, GPT-4 is known for its versatility and proven results. Consider the complexity of your tasks—Mistral AI offers flexibility, while GPT-4 excels in more demanding scenarios.
You might also want to know about GPT-4o
Budget Considerations
Cost is another crucial factor to think about. If you’re working with a tighter budget, Mistral Large offers a more cost-effective solution without sacrificing quality, making it a great option for businesses looking to maximize value.
On the flip side, GPT-4 might be the way to go if you’re willing to invest a bit more for that extra precision and wide-ranging capabilities it’s known for.
Integration Ease and Technical Support
Finally, consider how easy it will be to integrate the AI into your system and the kind of support you’ll need. Mistral AI offers flexible solutions with different model variants to fit various technical needs, while GPT-4 comes with extensive documentation and a large user community, making integration smoother for some teams.
Think about the level of technical support your team might require and choose the model that aligns with your resources.

Final Note
Both Mistral AI and GPT-4 bring unique strengths to the table. Mistral AI offers an affordable, flexible solution with strong multilingual capabilities, making it a great choice for businesses looking to maximize value.
On the other hand, GPT-4 excels in broader applications and performance, making it the go-to for more demanding tasks. The choice between them ultimately depends on your specific business needs and goals.
As AI technology continues to evolve, we can expect both Mistral AI and GPT-4 to push the boundaries of innovation. With more advancements on the horizon, businesses can look forward to even more powerful and cost-effective AI solutions in the future.
If you enjoyed this article, you may also like: Claude vs ChatGPT debate