The integration of artificial intelligence (AI) with healthcare is revolutionizing precision medicine, offering unprecedented possibilities through the use of vector databases. These databases are designed to handle complex, high-dimensional data, making them an essential tool for personalized healthcare solutions.
By transforming intricate medical data into vectors, they enable advanced analytics and insights, facilitating improved patient outcomes through precision medicine. This blog delves into the technical details of how AI in healthcare empowers patient similarity searches and paves the path for precision medicine.
Explore 10 AI startups revolutionizing healthcare you should know about
What are Vector Databases?
Vector databases are specialized databases designed to store and manage high-dimensional vector data, crucial for handling complex and unstructured data like text, video, and audio. Unlike traditional databases, which focus on precise queries, vector databases excel in similarity searches using advanced indexing techniques such as Hierarchical Navigable Small Worlds (HNSW).
Learn more about Top vector databases in market
They transform data into numerical arrays, or vector embeddings, which capture essential features and relationships, allowing for efficient retrieval and analysis. These databases are particularly beneficial for AI applications requiring real-time data processing, such as Retrieval Augmented Generation (RAG).
Their ability to manage complex data efficiently makes them a transformative technology in fields like precision medicine and AI, offering enhanced scalability, security, and trust compared to traditional databases
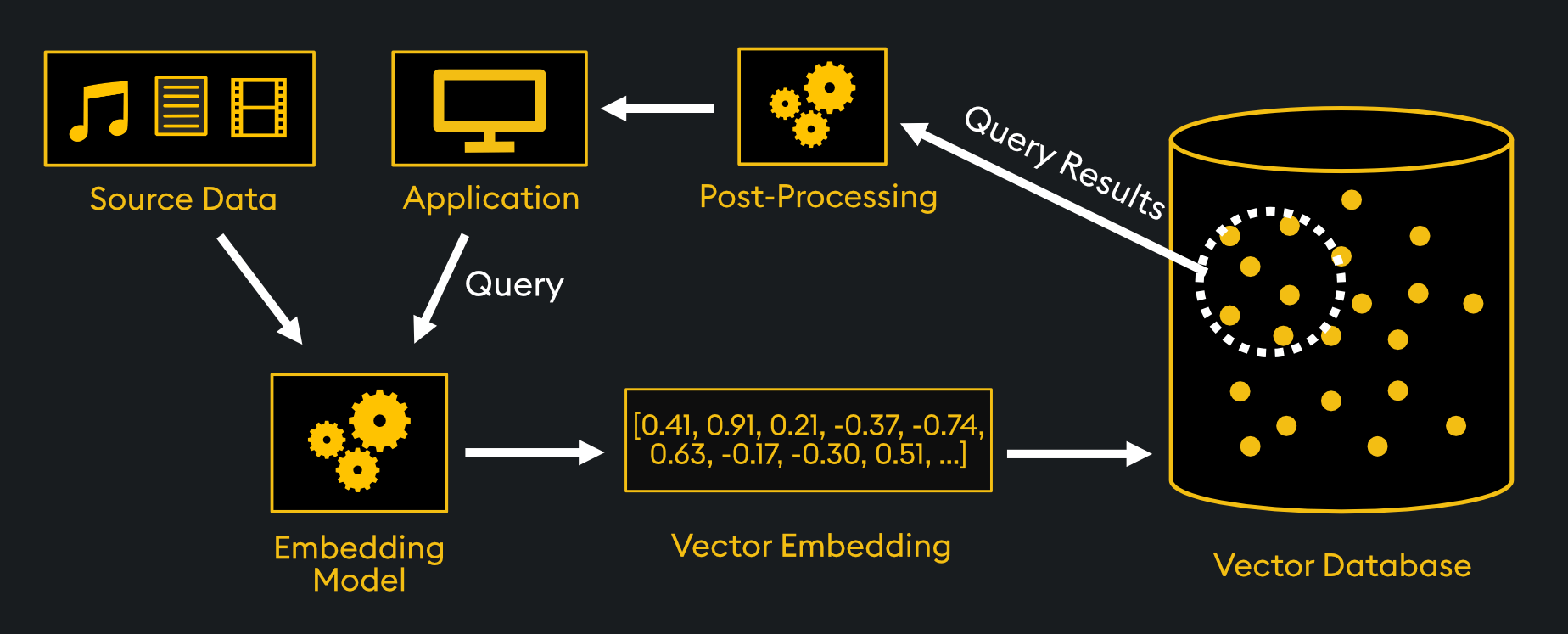
Limitations of Traditional Databases
Traditional databases, such as relational databases, have significant limitations when applied to precision medicine and other AI-driven healthcare applications. They are primarily designed to manage structured data, which makes them efficient for handling transactions and maintaining records but less suitable for the unstructured and semi-structured data prevalent in healthcare.
Understand the difference between Traditional and Vector databases
Traditional databases struggle with scalability when dealing with large volumes of complex and high-dimensional data, such as genomic sequences or medical imaging, which are crucial for precision medicine. Additionally, their reliance on structured query languages limits their ability to perform the similarity searches required for advanced medical diagnostics and personalized treatments.
Vector Databases in Precision Medicine

Vector databases are revolutionizing healthcare data management. Unlike traditional, table-like structures, they excel at handling the intricate, multi-dimensional nature of patient information. Each patient becomes a unique point in a high-dimensional space, defined by their genetic markers, lab values, and medical history.
This dense representation unlocks powerful capabilities discussed later. Working with vector data is tough because regular databases, which usually handle one piece of information at a time, can’t handle the complexity and large amount of this type of data. This makes it hard to find important information and analyze it quickly.
That’s where vector databases come in handy—they are made on purpose to handle this special kind of data. They give you the speed, ability to grow, and flexibility you need to get the most out of your data.

Patient Similarity Search with Vector Databases
In vector databases, complex data such as medical records, genomic information, and clinical notes are transformed into vectors. These vectors act as numerical representations capturing essential features and relationships of the data.
The similarity between vectors is determined using metrics like Euclidean distance and cosine similarity. These measures help assess how closely two patient profiles are related based on their vector representations.
Vector databases use advanced indexing methods, such as Hierarchical Navigable Small Worlds (HNSW), to efficiently search for similar vectors. This indexing reduces the need to compare every vector, allowing for faster retrieval of similar patient profiles.
Personalized Treatment Plans
By uncovering patients with comparable profiles and treatment outcomes, doctors can tailor interventions with greater confidence and optimize individual care. It also serves as handy for medical researchers to look for efficient cures or preventions for a disease diagnosed over multiple patients by analyzing their data, particularly for a certain period. Here’s how vector databases transform treatment plans:
- Precise Targeting: By comparing a patient’s vector to those of others who have responded well to specific treatments, doctors can identify the most promising options with laser-like accuracy. This reduces the guesswork and minimizes the risk of ineffective therapies.
- Predictive Insights: Vector databases enable researchers to analyze the trajectories of similar patients, predicting their potential responses to different treatments. This foresight empowers doctors to tailor interventions, preventing complications and optimizing outcomes proactively.
- Unlocking Untapped Potential: By uncovering hidden connections between seemingly disparate data points, vector databases can reveal new therapeutic targets and treatment possibilities. This opens doors for personalized medicine breakthroughs that were previously unimaginable.
- Dynamic Adaptation: As a patient’s health evolves, their vector map shifts and readjusts accordingly. This allows for real-time monitoring and continuous refinement of treatment plans, ensuring the best possible care at every stage of the journey.
Drug Discovery and Repurposing
Identifying patients similar to those successfully treated with a specific drug can accelerate clinical trials and uncover unexpected connections for existing medications. Vector Databases can accelerate exploration, repurpose potential, and provide personalized insights and predictions.
- Accelerated exploration: They transform complex drug and disease data into dense vectors, allowing for rapid similarity searches and the identification of promising drug candidates. Imagine sifting through millions of molecules at a single glance, pinpointing those with properties similar to those of known effective drugs.
- Repurposing potential: Vector databases can unearth hidden connections between existing drugs and potential new applications. By comparing drug vectors to disease vectors, they can reveal unexpected repurposing opportunities, offering a faster and cheaper path to new treatments.
Explore the role of vector embeddings in generative AI
- Personalization insights: By weaving genetic and patient data into the drug discovery tapestry, vector databases can inform the development of personalized medications tailored to individual needs and responses. This opens the door to a future where treatments are as unique as the patients themselves.
- Predictive power: Analyzing the molecular dance within the vector space can unveil potential side effects and predict drug efficacy before entering clinical trials. This helps navigate the treacherous waters of development, saving time and resources while prioritizing promising candidates.
Cohort Analysis in Research
Grouping patients with similar characteristics facilitates targeted research efforts, leading to faster breakthroughs in disease understanding and treatment development. This indicates a strong understanding of exploring disease mechanisms and unveiling hidden patterns.
Understand Generative AI in healthcare
- Exploring Disease Mechanisms: Vector databases facilitate the identification of patient clusters that share similar disease progression patterns. This can shed light on underlying disease mechanisms and guide the development of novel diagnostic markers and therapeutic target
- Unveiling Hidden Patterns: Vector databases excel at similarity search, enabling researchers to pinpoint patients with similar clinical trajectories, even if they don’t share the same diagnosis or traditional risk factors. This reveals hidden patterns that might have been overlooked in traditional data analysis methods.
Genomic Data Integration
In precision medicine, vector databases play a crucial role in genomic data integration by storing and analyzing high-dimensional genomic data. These databases can efficiently handle vast amounts of genetic information, enabling researchers to gain genetic insights that pave the way for personalized treatment plans.
Learn more about Google’s 2 specialized vector embedding tools to boost healthcare research
By integrating diverse genomic datasets, vector databases facilitate a more comprehensive understanding of genetic variations and their implications on health outcomes. This integration is instrumental in enabling precision medicine, where treatments are tailored to individual genetic profiles, thereby enhancing therapeutic efficacy and minimizing adverse effects.
Predictive Diagnostics
Predictive diagnostics benefit significantly from vector databases through the use of vector embeddings for early disease detection. By transforming complex patient data into numerical vectors, these databases can identify patterns and correlations that might indicate the early stages of diseases such as cancer.
Learn the difference between Predictive analytics and AI
For example, vector databases can be employed to predict cancer progression by analyzing genetic markers and patient history, thereby identifying high-risk patients who may benefit from preventive interventions. This capability allows healthcare providers to take proactive measures, potentially improving patient outcomes through timely interventions and personalized care strategies.
Medical Imaging Analysis
Vector databases enhance medical imaging analysis by vectorizing imaging data such as X-rays and MRIs, facilitating faster and more accurate diagnoses. By converting imaging data into vectors, these databases enable efficient comparison and analysis of patient scans to identify abnormalities.
For instance, by comparing current patient scans against a database of historical images, clinicians can quickly detect deviations or patterns indicative of specific health conditions, speeding up diagnostic processes and improving accuracy.
Semantic Search in Medical Records
Semantic search in medical records is another area where vector databases prove invaluable. By utilizing vector-based semantic search capabilities, healthcare providers can efficiently retrieve relevant patient records and simplify access to complex medical histories.
This approach allows for a more intuitive search experience, enabling medical professionals to quickly locate necessary information based on semantic relevance rather than exact match keywords. As a result, clinicians can gain a comprehensive understanding of a patient’s medical history, leading to more informed decision-making and improved patient care outcomes.
Technicalities of Vector Databases
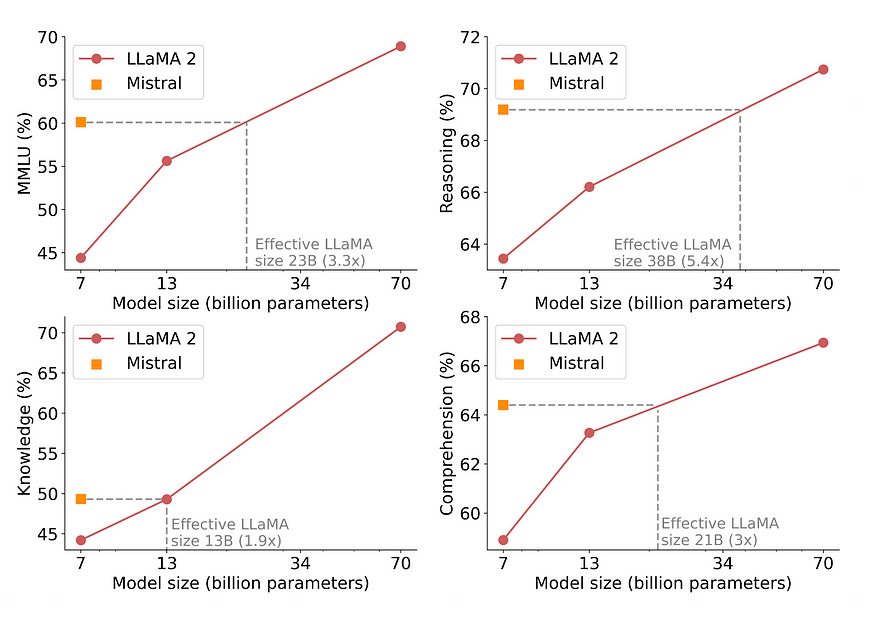
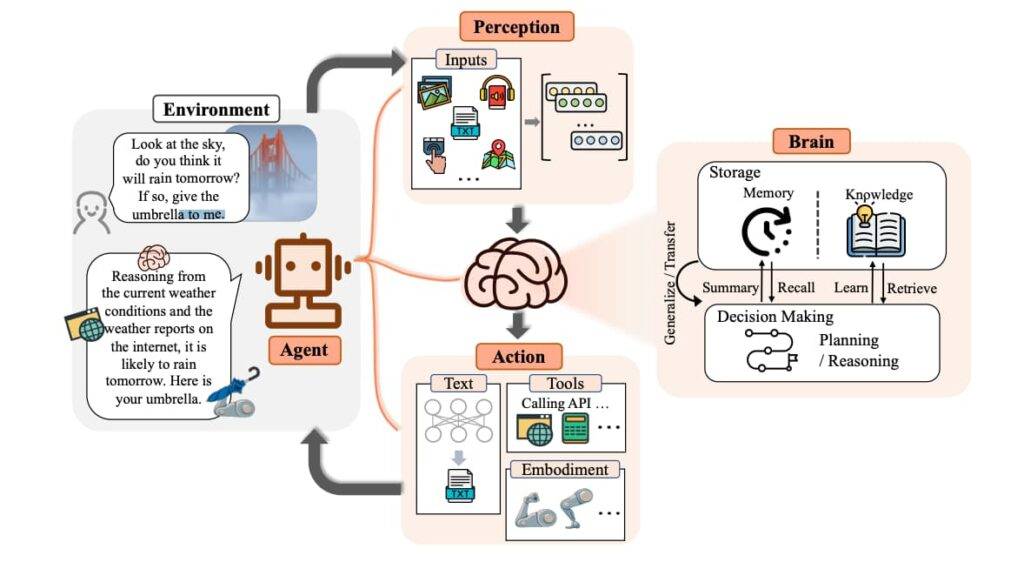
Using a vector database enables the incorporation of advanced functionalities into our artificial intelligence, such as semantic information retrieval and long-term memory. The diagram provided below enhances our comprehension of the significance of vector databases in such applications.
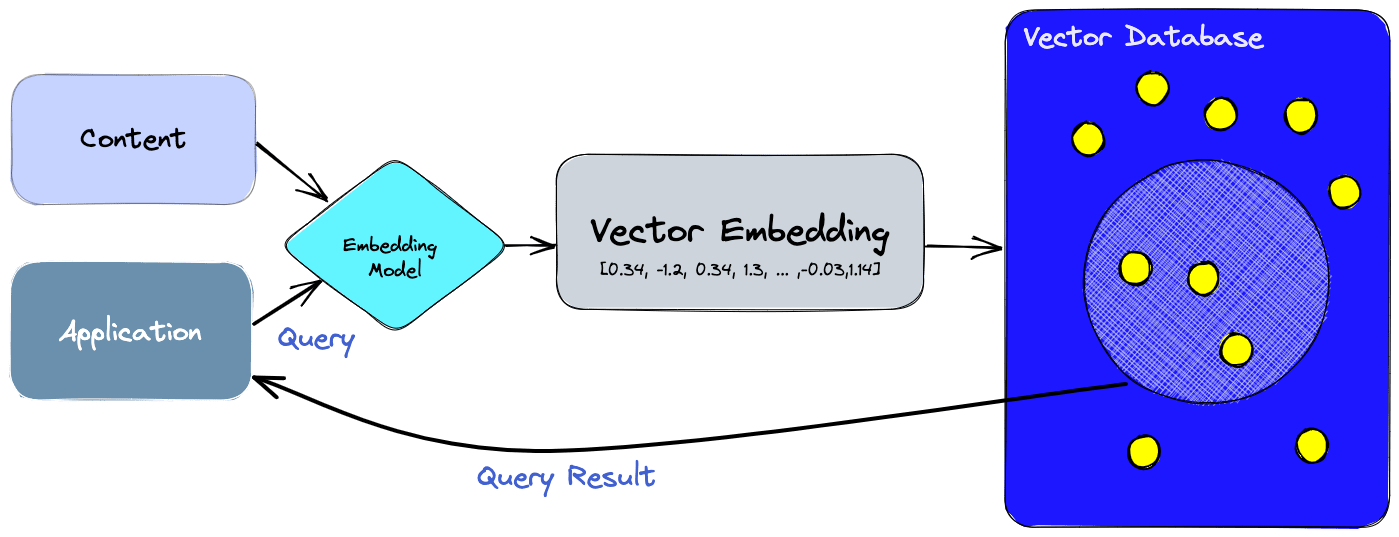
Let’s break down the illustrated process:
- Initially, we employ the embedding model to generate vector embeddings for the content intended for indexing.
- The resulting vector embedding is then placed into the vector database, referencing the original content from which the embedding was derived.
- Upon receiving a query from the application, we utilize the same embedding model to create embeddings for the query. These query embeddings are subsequently used to search the database for similar vector embeddings. As previously noted, these analogous embeddings are linked to the initial content from which they were created.
In comparison to the working of a traditional database, where data is stored as common data types like string, integer, date, etc. Users query the data by comparing each row; the result of this query is the rows where the condition of the query is withheld.
In vector databases, this process of querying is more optimized and efficient with the use of a similarity metric for searching the most similar vector to our query. The search involves a combination of various algorithms, like approximate nearest neighbor optimization, which uses hashing, quantization, and graph-based detection.
Here are a few key components of the discussed process described below:
Feature engineering: Transforming raw clinical data into meaningful numerical representations suitable for vector space. This may involve techniques like natural language processing for medical records or dimensionality reduction for complex biomolecular data.
Distance metrics: Choosing the appropriate distance metric to calculate the similarity between patient vectors. Popular options include Euclidean distance, cosine similarity, and Manhattan distance, each capturing different aspects of the data relationships.
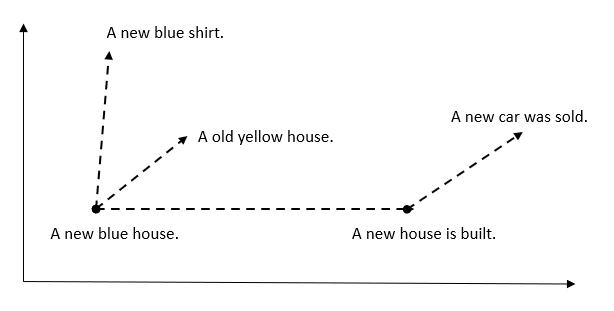
- Cosine Similarity: Calculates the cosine of the angle between two vectors in a vector space. It varies from -1 to 1, with 1 indicating identical vectors, 0 denoting orthogonal vectors, and -1 representing diametrically opposed vectors.
- Euclidean Distance: Measures the straight-line distance between two vectors in a vector space. It ranges from 0 to infinity, where 0 signifies identical vectors and larger values indicate increasing dissimilarity between vectors.
- Dot Product: Evaluate the product of the magnitudes of two vectors and the cosine of the angle between them. Its range is from -∞ to ∞, with a positive value indicating vectors pointing in the same direction, 0 representing orthogonal vectors, and a negative value signifying vectors pointing in opposite directions.
Nearest neighbor search algorithms: Efficiently retrieving the closest patient vectors to a given query. Techniques like k-nearest neighbors (kNN) and Annoy trees excel in this area, enabling rapid identification of similar patients.
A general pipeline from storing vectors to querying them is shown in the figure below:

- Indexing: The vector database utilizes algorithms like PQ, LSH, or HNSW (detailed below) to index vectors. This process involves mapping vectors to a data structure that enhances search speed.
- Querying: The vector database examines the indexed query vector against the dataset’s indexed vectors, identifying the nearest neighbors based on a similarity metric employed by that specific index.
- Post Processing: In certain instances, the vector database retrieves the ultimate nearest neighbors from the dataset and undergoes post-processing to deliver the final results. This step may involve re-evaluating the nearest neighbors using an alternative similarity measure.

Navigating the landscape of challenges and considerations is crucial for effective decision-making and strategic planning in any endeavor. While vector databases offer immense potential, challenges remain:
Data Privacy and Security
Safeguarding patient data while harnessing its potential for enhanced healthcare outcomes requires the implementation of robust security protocols and careful consideration of ethical standards. This involves establishing comprehensive measures to protect sensitive information, ensuring secure storage, and implementing stringent access controls.
Know more about the Risks of Generative AI in healthcare and how to mitigate them
Additionally, ethical considerations play a pivotal role, emphasizing the importance of transparent data handling practices, informed consent procedures, and adherence to privacy regulations. As healthcare organizations leverage the power of data to advance patient care, a meticulous approach to security and ethics becomes paramount to fostering trust and upholding the integrity of the healthcare ecosystem.
Explainability and Interoperability
Gaining insight into the reasons behind patient similarity is essential for informed clinical decision-making. It is crucial to develop transparent models that not only analyze the “why” behind these similarities but also offer insights into the importance of features within the vector space.
This transparency ensures a comprehensive understanding of the factors influencing patient similarities, contributing to more effective and reasoned clinical decisions. Integration with existing infrastructure: Seamless integration with legacy healthcare systems is essential for the practical adoption of vector database technology.
AI in Healthcare – Opening Avenues for Precision Medicine
In summary, the integration of artificial intelligence or vector databases in healthcare is revolutionizing patient care and diagnostics. Overcoming the limitations of traditional systems, these databases enable efficient handling of complex patient data, leading to precise treatment plans, accelerated drug discovery, and enhanced research capabilities.

While the technical aspects showcase the sophistication of these systems, challenges such as data privacy and seamless integration with existing infrastructure need attention. Despite these hurdles, the potential benefits promise a significant impact on personalized medicine and improved healthcare outcomes.