

Large Language Model Ops also known as LLMOps isn’t just a buzzword; it’s the cornerstone of unleashing LLM potential. From data management to model fine-tuning, LLMOps ensures efficiency, scalability, and risk mitigation. As LLMs redefine AI capabilities, mastering LLMOps becomes your compass in this dynamic landscape.

What is LLMOps?
LLMOps, which stands for Large Language Model Ops, encompasses the set of practices, techniques, and tools employed for the operational management of large language models within production environments.
Consequently, there is a growing need to establish best practices for effectively integrating these models into operational workflows. LLMOps facilitates the streamlined deployment, continuous monitoring, and ongoing maintenance of large language models. Similar to traditional Machine Learning Ops (MLOps), LLMOps necessitates a collaborative effort involving data scientists, DevOps engineers, and IT professionals. To acquire insights into building your own LLM, refer to our resources.
Development to production workflow LLMs
Large Language Models (LLMs) represent a novel category of Natural Language Processing (NLP) models that have significantly surpassed previous benchmarks across a wide spectrum of tasks, including open question-answering, summarization, and the execution of nearly arbitrary instructions. While the operational requirements of MLOps largely apply to LLMOps, training and deploying LLMs present unique challenges that call for a distinct approach to LLMOps.
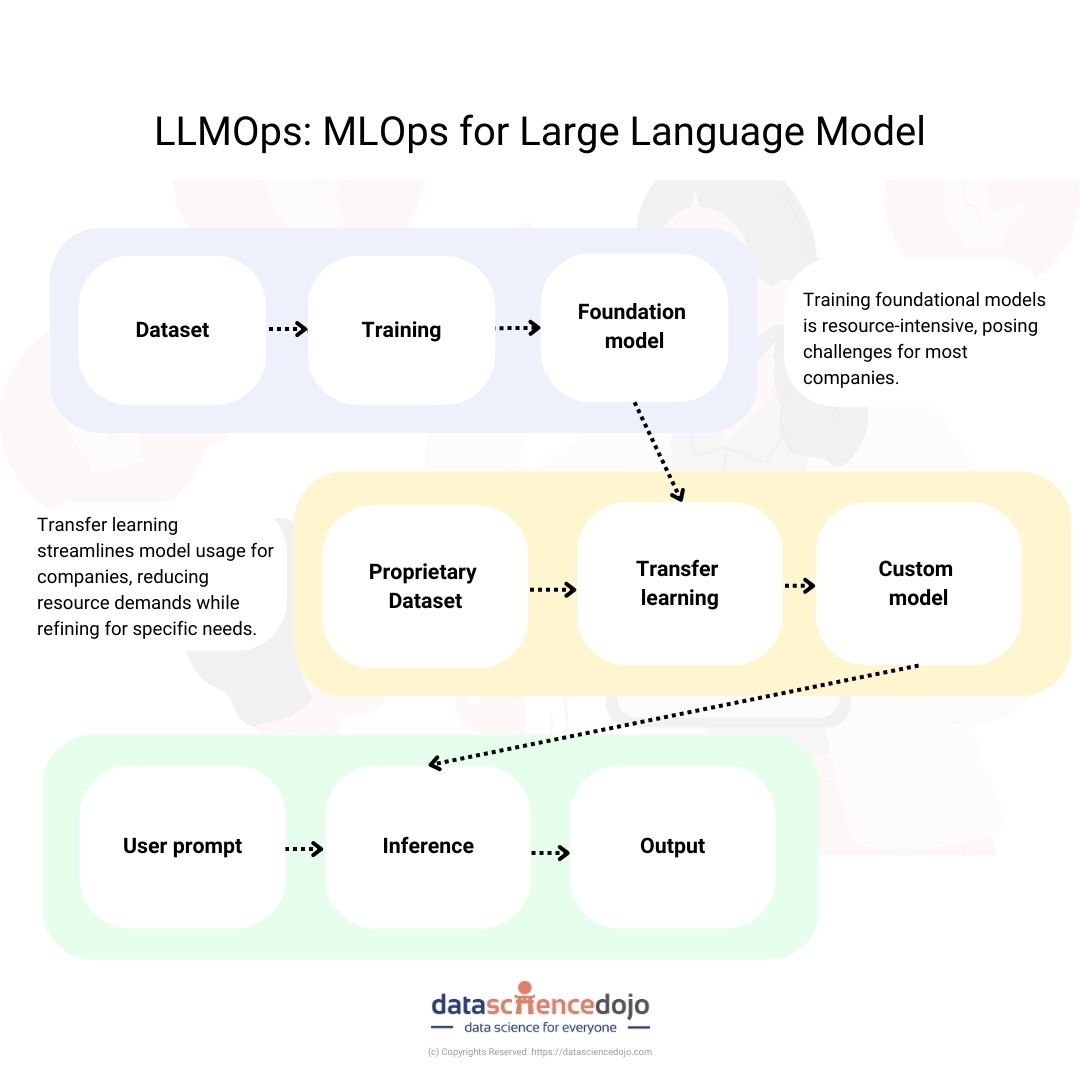
What are the components of LLMOps?
The scope of LLMOps within machine learning projects can vary widely, tailored to the specific needs of each project. Some projects may necessitate a comprehensive LLMOps approach, spanning tasks from data preparation to pipeline production.
1. Exploratory Data Analysis (EDA)
- Data collection: The first step in LLMOps is to collect the data that will be used to train the LLM. This data can be collected from a variety of sources, such as text corpora, code repositories, and social media.
- Data cleaning: Once the data is collected, it needs to be cleaned and prepared for training. This includes removing errors, correcting inconsistencies, and removing duplicate data.
- Data exploration: The next step is to explore the data to better understand its characteristics. This includes looking at the distribution of the data, identifying outliers, and finding patterns.
2. Data prep and prompt engineering
- Data preparation: The data that is used to train an LLM needs to be prepared in a specific way. This includes tokenizing the data, removing stop words, and normalizing the text.
- Prompt engineering: Prompt engineering is the process of creating prompts that are used to generate text with the LLM. The prompts need to be carefully crafted to ensure that the LLM generates the desired output.
3. Model fine-tuning
- Model training: Once the data is prepared, the LLM is trained. This is done by using a machine learning algorithm to learn the patterns in the data.
- Model evaluation: Once the LLM is trained, it needs to be evaluated to see how well it performs. This is done by using a test set of data that was not used to train the LLM.
- Model fine-tuning: If the LLM does not perform well, it can be fine-tuned. This involves adjusting the LLM’s parameters to improve its performance.
4. Model review and governance
- Model review: Once the LLM is fine-tuned, it needs to be reviewed to ensure that it is safe and reliable. This includes checking for bias, safety, and security risks.
- Model governance: Model governance is the process of managing the LLM throughout its lifecycle. This includes tracking its performance, making changes to it as needed, and retiring it when it is no longer needed.
5. Model inference and serving
- Model inference: Once the LLM is reviewed and approved, it can be deployed into production. This means that it can be used to generate text or answer questions.
- Model serving: Model serving is the process of making the LLM available to users. This can be done through a variety of ways, such as a REST API or a web application.
6. Model monitoring with human feedback
- Model monitoring: Once the LLM is deployed, it needs to be monitored to ensure that it is performing as expected. This includes tracking its performance, identifying any problems, and making changes as needed.
- Human feedback: Human feedback can be used to improve the performance of the LLM. This can be done by providing feedback on the text that the LLM generates, or by identifying any problems with the LLM’s performance.
LLMOps vs MLOps
|
Feature
|
LLMOps | MLOps |
|---|---|---|
| Computational resources | Requires more specialized hardware and compute resources | Can be run on a variety of hardware and compute resources |
| Transfer learning | Often uses a foundation model and fine-tunes it with new data | Can be trained from scratch |
| Human feedback | Often uses human feedback to evaluate performance | Can use automated metrics to evaluate performance |
| Hyperparameter tuning | Tuning is important for reducing the cost and computational power requirements of training and inference | Tuning is important for improving accuracy or other metrics |
| Performance metrics | Uses a different set of standard metrics and scoring | Uses well-defined performance metrics, such as accuracy, AUC, F1 score, etc. |
| Prompt engineering | Critical for getting accurate, reliable responses from LLMs | Not as critical, as traditional ML models do not take prompts |
| Building LLM chains or pipelines | Often focuses on building these pipelines, rather than building new LLMs | Can focus on either building new models or building pipelines |
Best practices for LLMOps implementation
LLMOps covers a broad spectrum of tasks, ranging from data preparation to pipeline production. Here are seven key steps to ensure a successful adoption of LLMOps:
1. Data Management and Security
Data is a critical component in LLM training, making robust data management and stringent security practices essential. Consider the following:
- Data Storage: Employ suitable software solutions to handle large data volumes, ensuring efficient data retrieval across the entire LLM lifecycle.
- Data Versioning: Maintain a record of data changes and monitor development through comprehensive data versioning practices.
- Data Encryption and Access Controls: Safeguard data with transit encryption and enforce access controls, such as role-based access, to ensure secure data handling.
- Exploratory Data Analysis (EDA): Continuously prepare and explore data for the machine learning lifecycle, creating shareable visualizations and reproducible datasets.
- Prompt Engineering: Develop reliable prompts to generate accurate queries from LLMs, facilitating effective communication.
Read more –> Learn how to become a prompt engineer in 10 steps
2. Model Management
In LLMOps, efficient training, evaluation, and management of LLM models are paramount. Here are some recommended practices:
- Selection of Foundation Model: Choose an appropriate pre-trained model as the starting point for customization, taking into account factors like performance, size, and compatibility.
- Few-Shot Prompting: Leverage few-shot learning to expedite model fine-tuning for specialized tasks without extensive training data, providing a versatile and efficient approach to utilizing large language models.
- Model Fine-Tuning: Optimize model performance using established libraries and techniques for fine-tuning, enhancing the model’s capabilities in specific domains.
- Model Inference and Serving: Manage the model refresh cycle and ensure efficient inference request times while addressing production-related considerations during testing and quality assurance stages.
- Model Monitoring with Human Feedback: Develop robust data and model monitoring pipelines that incorporate alerts for detecting model drift and identifying potential malicious user behavior.
- Model Evaluation and Benchmarking: Establish comprehensive data and model monitoring pipelines, including alerts to identify model drift and potentially malicious user behavior. This proactive approach enhances model reliability and security.
3. Deployment
Achieve seamless integration into the desired environment while optimizing model performance and accessibility with these tips:
- Cloud-Based and On-Premises Deployment: Choose the appropriate deployment strategy based on considerations such as budget, security, and infrastructure requirements.
- Adapting Existing Models for Specific Tasks: Tailor pre-trained models for specific tasks, as this approach is cost-effective. It also applies to customizing other machine learning models like natural language processing (NLP) or deep learning models.
4. Monitoring and Maintenance
LLMOps ensures sustained performance and adaptability over time:
- Improving Model Performance: Establish tracking mechanisms for model and pipeline lineage and versions, enabling efficient management of artifacts and transitions throughout their lifecycle.
By implementing these best practices, organizations can enhance their LLMOps adoption and maximize the benefits of large language models in their operational workflows.
Why is LLMOps Essential?
Large language models (LLMs) are a type of artificial intelligence (AI) that are trained on massive datasets of text and code. They can be used for a variety of tasks, such as text generation, translation, and question answering. However, LLMs are also complex and challenging to deploy and manage. This is where LLMOps comes in.
LLMOps is the set of practices and tools that are used to deploy, manage, and monitor LLMs. It encompasses the entire LLM development lifecycle, from experimentation and iteration to deployment and continuous improvement.
LLMOps is essential for a number of reasons. First, it helps to ensure that LLMs are deployed and managed in a consistent and reliable way. This is important because LLMs are often used in critical applications, such as customer service chatbots and medical diagnosis systems.
Second, LLMOps helps to improve the performance of LLMs. By monitoring the performance of LLMs, LLMOps can identify areas where they can be improved. This can be done by tuning the LLM’s parameters, or by providing it with more training data.
Third, LLMOps helps to mitigate the risks associated with LLMs. LLMs are trained on massive datasets of text and code, and this data can sometimes contain harmful or biased information. LLMOps can help to identify and remove this information from the LLM’s training data.
What are the benefits of LLMOps?
The primary benefits of LLMOps are efficiency, scalability, and risk mitigation.
- Efficiency: LLMOps can help to improve the efficiency of LLM development and deployment. This is done by automating many of the tasks involved in LLMOps, such as data preparation and model training.
- Scalability: LLMOps can help to scale LLM development and deployment. This is done by making it easier to manage and deploy multiple LLMs.
- Risk mitigation: LLMOps can help to mitigate the risks associated with LLMs. This is done by identifying and removing harmful or biased information from the LLM’s training data, and by monitoring the performance of the LLM to identify any potential problems.
In summary, LLMOps is essential for managing the complexities of integrating LLMs into commercial products. It offers significant advantages in terms of efficiency, scalability, and risk mitigation. Here are some specific examples of how LLMOps can be used to improve the efficiency, scalability, and risk mitigation of LLM development and deployment:
- Efficiency: LLMOps can automate many of the tasks involved in LLM development and deployment, such as data preparation and model training. This can free up data scientists and engineers to focus on more creative and strategic tasks.
- Scalability: LLMOps can help to scale LLM development and deployment by making it easier to manage and deploy multiple LLMs. This is important for organizations that need to deploy LLMs in a variety of applications and environments.
- Risk mitigation: LLMOps can help to mitigate the risks associated with LLMs by identifying and removing harmful or biased information from the LLM’s training data. It can also help to monitor the performance of the LLM to identify any potential problems.
In a nutshell
In conclusion, LLMOps is a critical discipline for organizations that want to successfully deploy and manage large language models. By implementing the best practices outlined in this blog, organizations can ensure that their LLMs are deployed and managed in a consistent and reliable way and that they are able to maximize the benefits of these powerful models.
