
In a world of large language models (LLMs), deep double descent has created a new shift in understanding data and its position in deep learning models. A traditional LLM uses large amounts of data to train a machine-learning model, believing that bigger datasets lead to greater accuracy of results.
While OpenAI‘s GPT, Anthropic’s Claude, and Google’s Gemini are focused on using large amounts of training data for improved performance, the recent phenomenon of deep double descent presents an alternative picture. It makes you wonder about the significance of data in modern deep learning.
Before moving forward, consider exploring our comprehensive LLM Bootcamp to build hands-on skills and gain deeper insights into large language models.

Let’s dig deeper into understanding this phenomenon and its new perspective on the use of large datasets for model training.
What is Deep Double Descent?
It is a modern phenomenon in deep neural networks that presents its performance as a function of model complexity. Typically, a model improves its performance up to a certain point with an increasing amount of data. Beyond this point, the model output is expected to degrade due to overfitting.
The concept of double descent highlights that the performance of a model increases beyond the dip due to overfitting, and then degrades again. Hence, a neural network’s performance experiences a second descent with increasing data complexity.
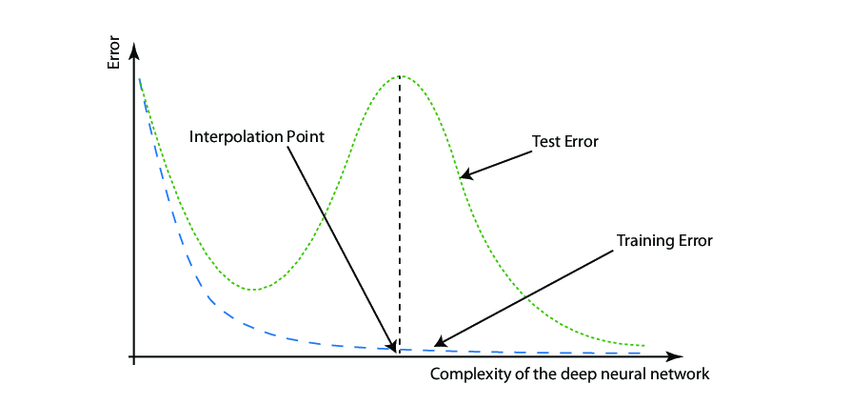
A typical pattern of deep double descent can be categorized as follows:
- Underparametrized region – refers to the early stages of model training when the parameters are small in number. As the dataset increases in complexity, the model performance is enhanced, resulting in a decrease in the test error.
- Overparametrized region – as the model training continues, the number of parameters increases. The increase in data complexity leads to model overfitting, resulting in the degradation of its performance.
- Double descent region – it relates to the region beyond the overfitting of the training model. A further increase in data complexity increases the parameters for training, causing a second descent in test error that leads to enhancement in model performance.
The name of the phenomenon is rooted in the two descents of test error. The region towards the left of the interpolation point is called the classical regime. In this part, the bias-variance trade-off behaves expectedly. The region towards the right of the interpolation regime. In this region, the model perfectly memorizes the points of training data.

Understanding the Learning Lifecycle of a Model through Double Descent
As explained in an OpenAI article in 2019, the learning lifecycle of a training model can be explained using the double descent phenomenon. It explains how the test error varies during the iterations of a model’s testing and training.
Let’s look at the three main scenarios of the lifecycle and how each one impacts the training model.
Model-Wise Double Descent

The scenario describes a phenomenon where the model is underparametrized. The model requires more parameters and complexity for improvement in results. A peak in test error occurs around the interpolation point and the model becomes large enough to fit the train set. It also indicates that changes in data complexity, like optimization algorithm, label noise, and the number of training sets can also impact the interpolation threshold and consequently the test error peak.
Sample-Wise Non-Monotonicity

It is the region where an increase in dataset and parameters degrades the model performance. The increase in samples requires larger models to fit the training model, moving the interpolation point to the right. It can be visualized with a shrunken area under the curve that also shifts towards the right.
Epoch-Wise Double Descent
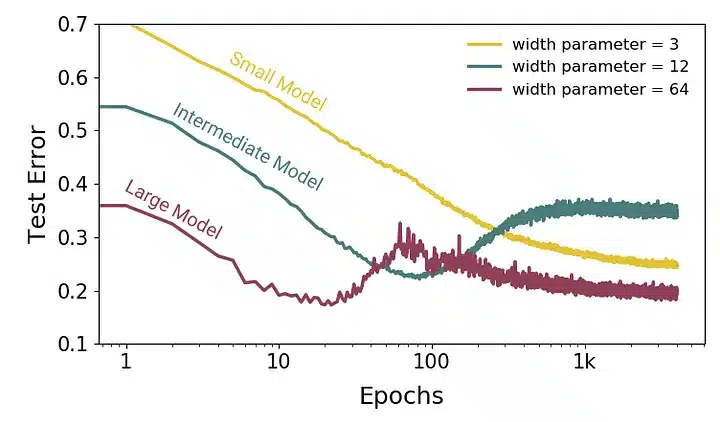
It explains the transition of large models from under to over-parametrized regions. During this time, considerably large training models can experience double descent of the test error. As the number of epochs (training time) is increased, the effect of overfitting is reversed.
Hence, the phenomenon highlights how an increase in a dataset can damage model performance before improving it. It raises an important aspect of the deep model learning process, highlighting the importance of data choice for training. Since the optimization of the training process is crucial, it is essential to consider the deep double descent during model training.

Mitigation Strategies: Navigating Deep Double Descent Effectively
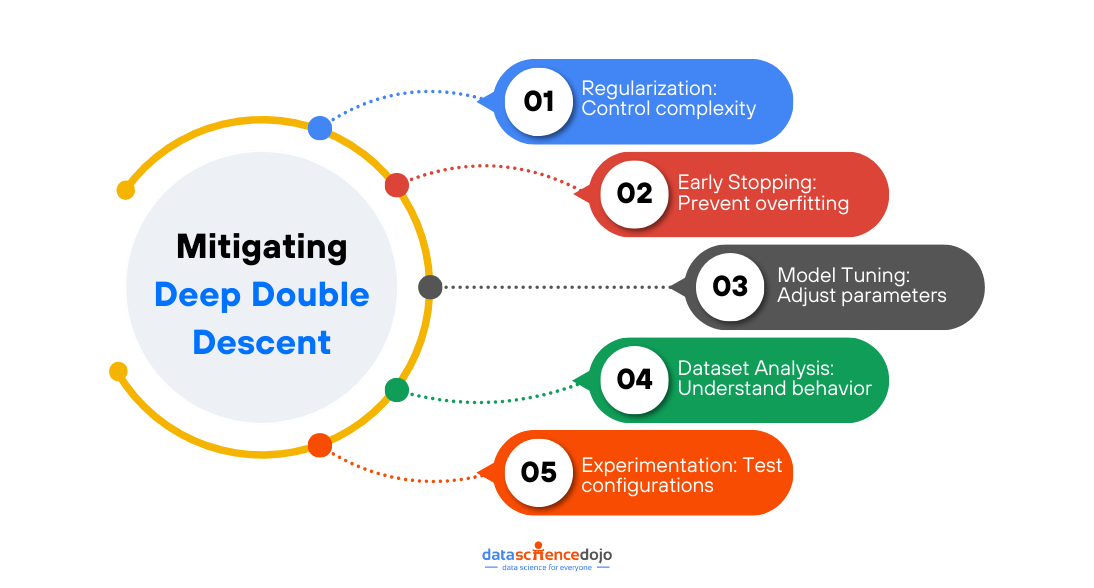
When dealing with the complexities of deep double descent, it’s essential to have a few key strategies up your sleeve to ensure your model performs reliably and avoids the pitfalls of overfitting. Here are some practical techniques you can apply:
- Regularization: Employ L1 or L2 regularization to add a penalty for large weights, helping to control the model’s complexity and reduce the chances of overfitting.
- Early Stopping: Keep an eye on your model’s validation performance and halt training as soon as the validation error starts to rise, which is a clear signal that overfitting might be setting in.
- Adjusting Model Complexity: Fine-tune your model by tweaking the number of layers, neurons, or parameters to strike a balance between underfitting and overfitting, ensuring it aligns well with your dataset’s characteristics.
- Dataset-Specific Adjustments: Remember, every dataset is different. Take the time to understand its unique properties and make necessary adjustments, such as data augmentation or balancing, to optimize model performance.
By implementing these strategies, you can effectively navigate the deep double descent curve and build models that are not only powerful but also robust and generalizable.
Are Small Language Models a Solution?
Since the double descent phenomenon indicates a degraded performance of training models with an increase in data, it has opened a new area of exploration for researchers. Data scientists need to dig deeper into this concept to understand the reasons for the two dips in test errors with larger datasets.
While the research is ongoing, there must be other solutions to consider. One such alternative can be in the form of small language models (SLMs). As they work with lowered data complexity and fewer parameters, they offer a solution where an increase in test errors and model degradation can be avoided. It can serve as an alternative solution while research continues to understand the recent phenomenon of double descent.