While today’s world is increasingly driven by artificial intelligence (AI) and large language models (LLMs), understanding the magic behind them is crucial for your success. To get you started, Data Science Dojo and Weaviate have teamed up to bring you an exciting webinar series: Master Vector Embeddings with Weaviate.
We have carefully curated the series to empower AI enthusiasts, data scientists, and industry professionals with a deep understanding of vector embeddings. These numerical representations promise the building of smarter search systems and the powering of seamless functionality of cutting-edge LLMs.
Since vector embeddings are the foundation of so much of the digital world we rely on today, we aim to make advanced AI concepts accessible, actionable, and scalable. Whether you’re just starting or looking to refine your expertise, this webinar series is your gateway to the true potential of vector embeddings.

Let’s take a closer look at each part of the series and what they contain.
Part 1: Introduction to Vector Embeddings
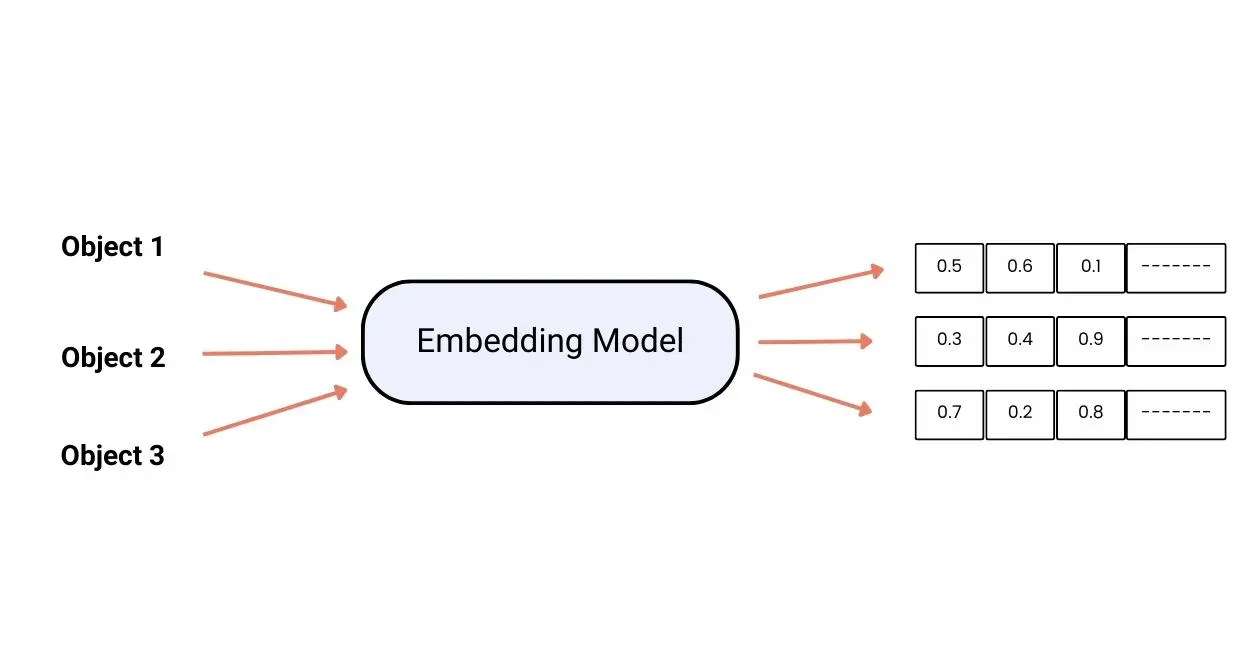
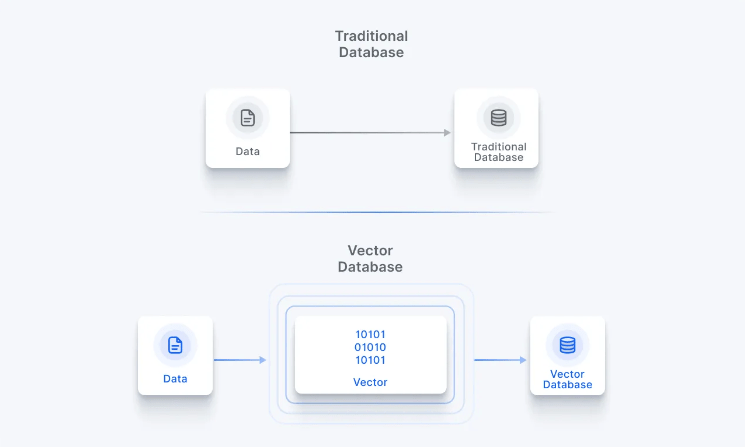
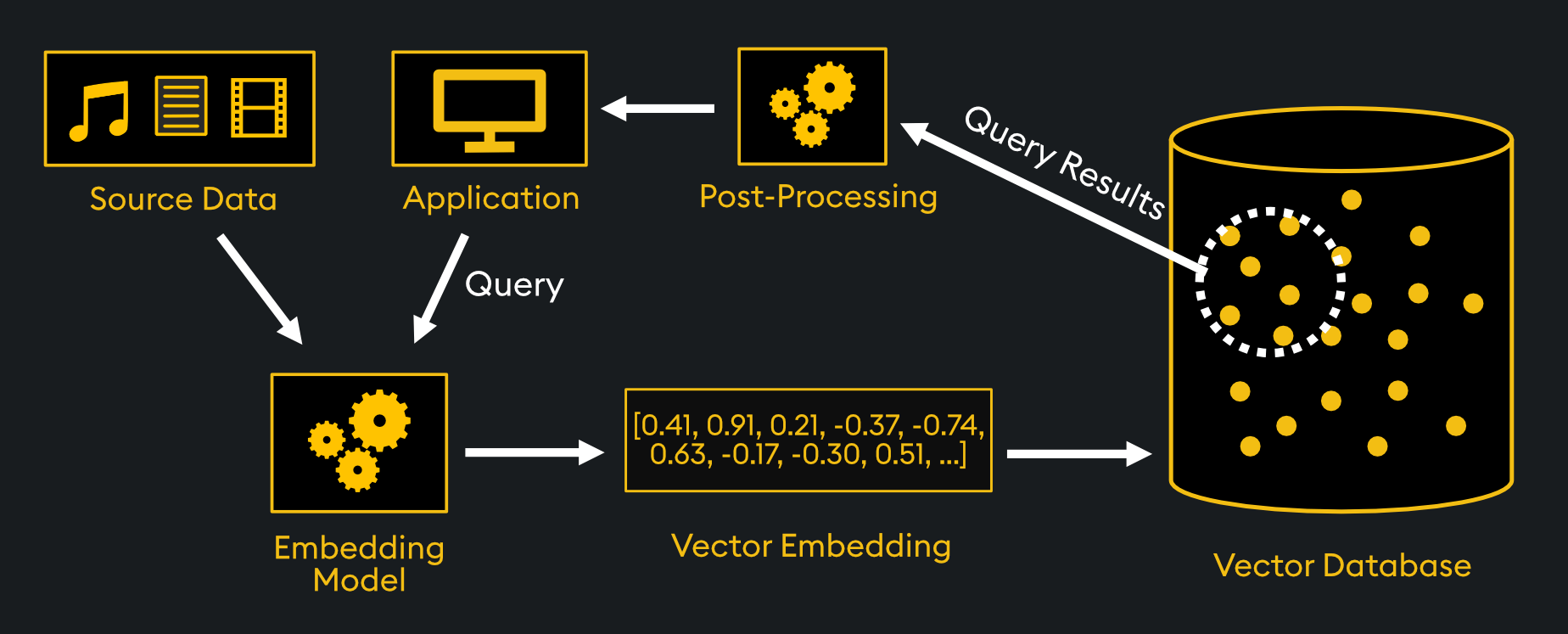
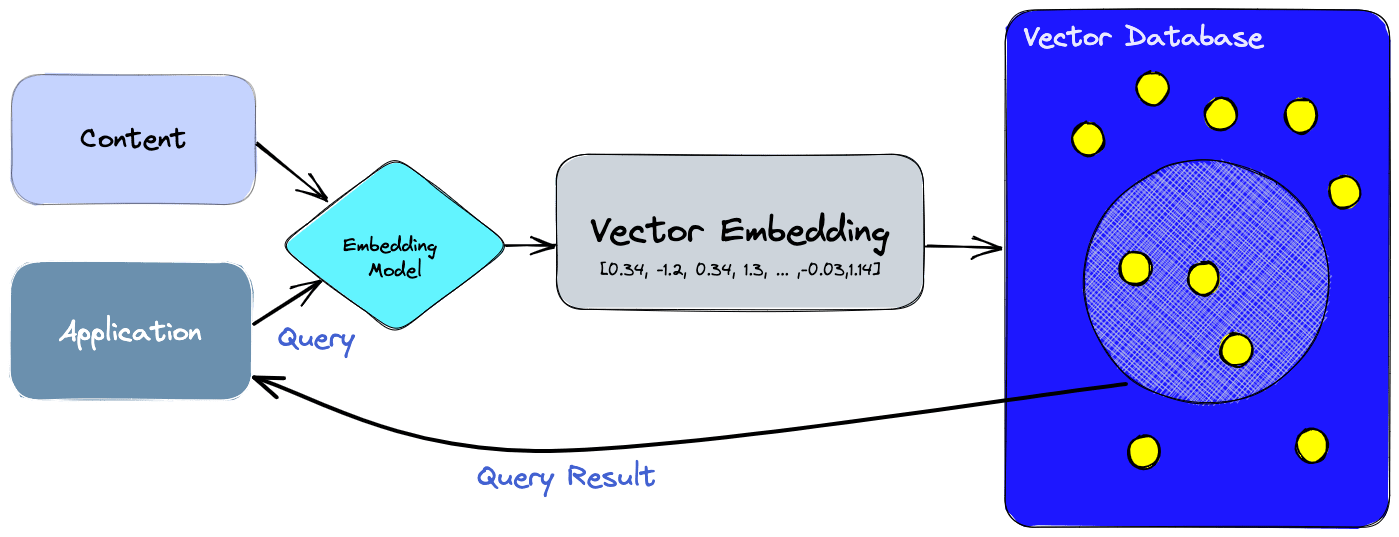
We will kickstart this series with a basic understanding of vector embeddings – the process of converting data into numerical vectors that represent its meaning. These help machines understand complex data like text, images, or audio. Imagine these numbers as points in a space, where similar data points are closer together.
Neural networks trained on large datasets create these embeddings, making it easier for machines to find patterns and relationships in the data. This part digs deeper into these number sequences and their role in representing complex data in a readable format for your machines.
Read more about the role of vector embeddings in generative AI
Role of Vector Embeddings in LLMs
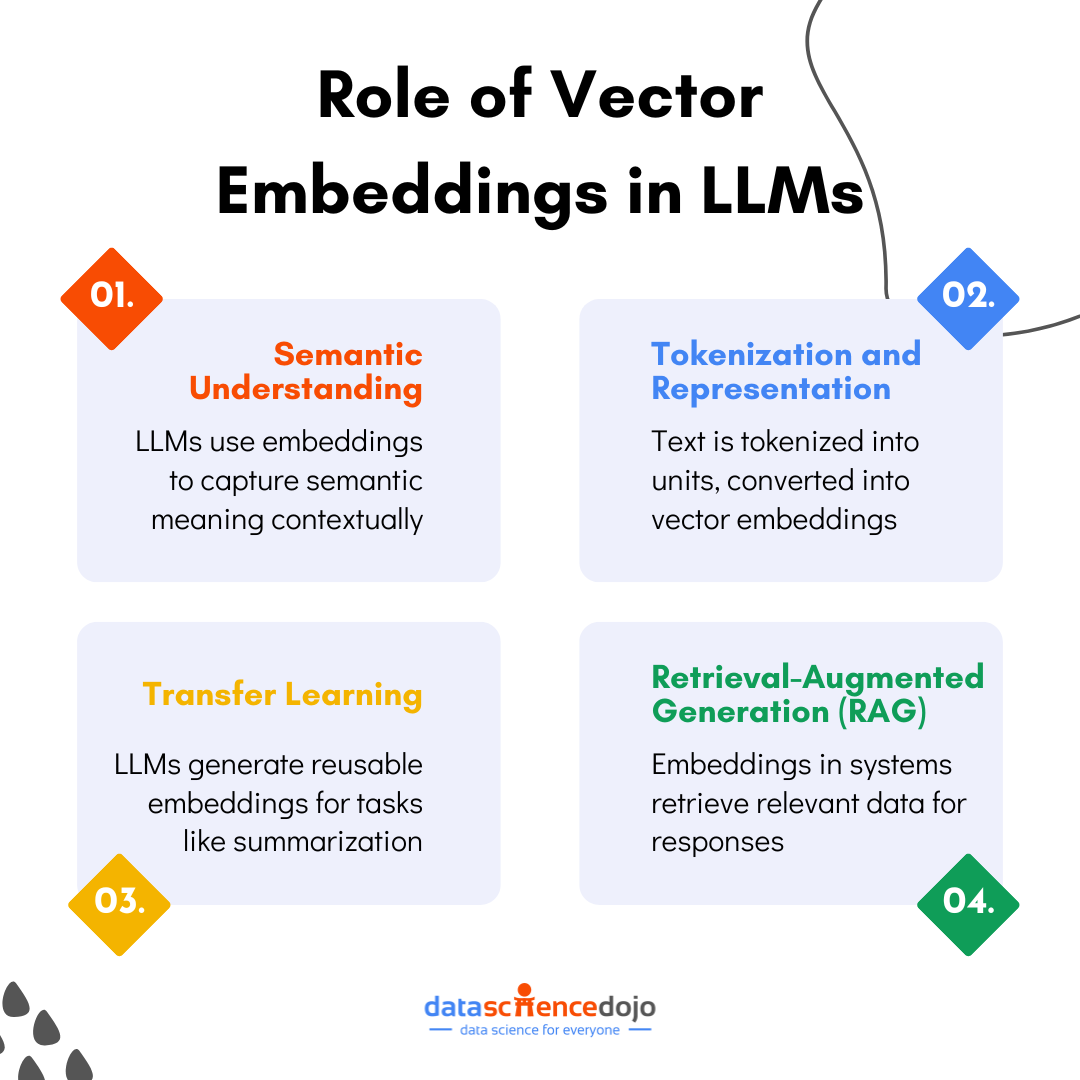
Large Language Models (LLMs) like GPT, BERT, and their variants heavily rely on vector embeddings to process and generate human-like text.
Here’s how embeddings power these advanced systems:
Semantic Understanding
LLMs use embeddings to represent words, sentences, and entire documents in a way that captures their semantic meaning. This allows the models to understand the context and relationships between words, leading to more accurate and relevant outputs.
Tokenization and Representation
Before feeding text into an LLM, it is broken down into smaller units called tokens. Each token is then converted into a vector embedding. These embeddings provide the model with the context it needs to generate coherent and contextually appropriate responses.
Transfer Learning
LLMs trained on large datasets generate embeddings that can be reused for various tasks, such as summarization, sentiment analysis, or question answering. This adaptability is one of the reasons embeddings are so valuable in AI.
Retrieval-Augmented Generation (RAG)
In advanced systems, embeddings are used to retrieve relevant information from external datasets during the text generation process. For example, when a chatbot answers questions, it uses embeddings to fetch the most relevant context or data before formulating its response.
Learn all you need to know about RAG here
Hence, vector embeddings are the first building blocks in the process that enables a machine to comprehend human language. The first part of our webinar series with Weaviate will be focused on uncovering all the essential knowledge you must have about embeddings.
We will start the series by diving into the historical background of embeddings that began from the 2013 Word2Vec paper. You will also gain a high-level understanding of how embedding models work and their wide-ranging applications.
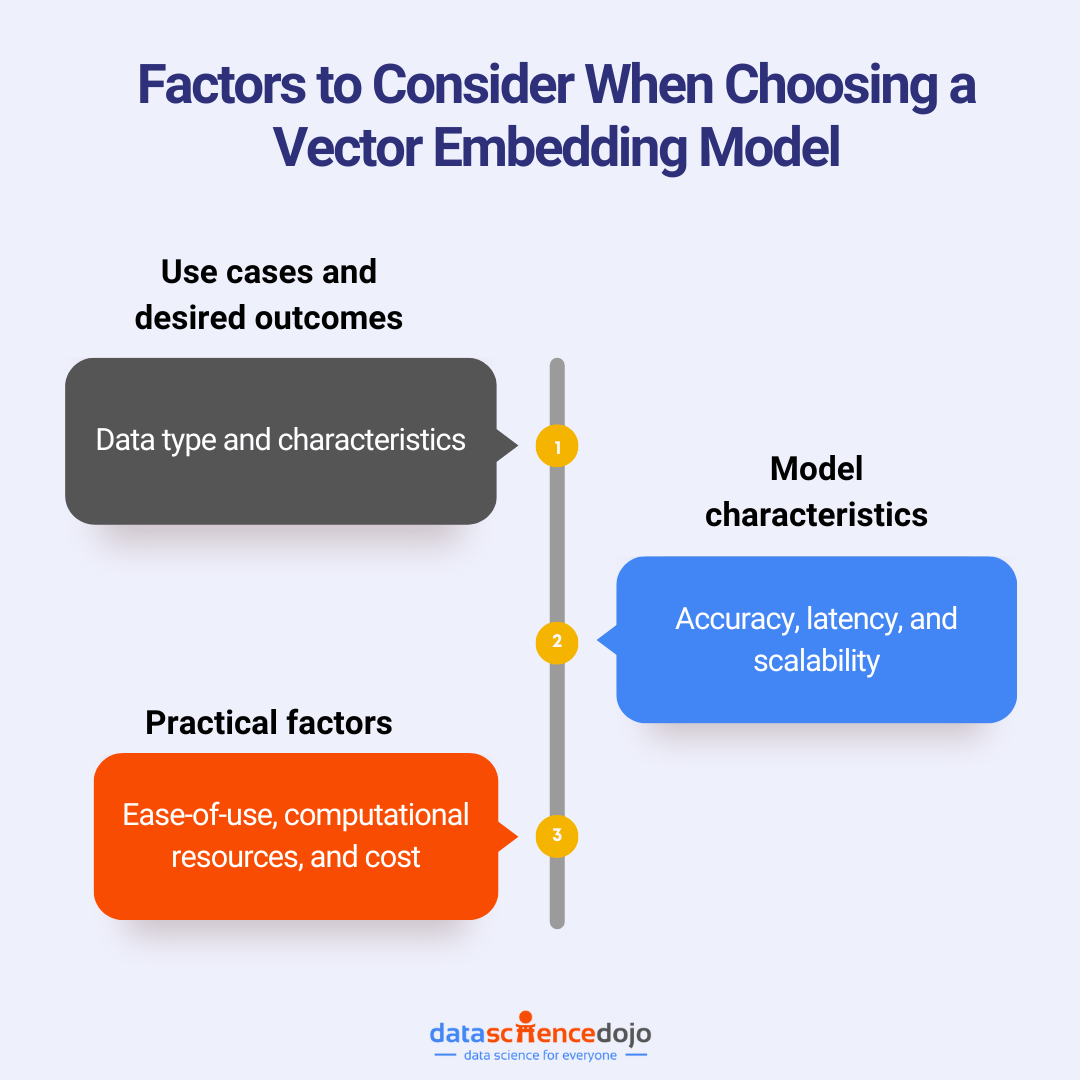
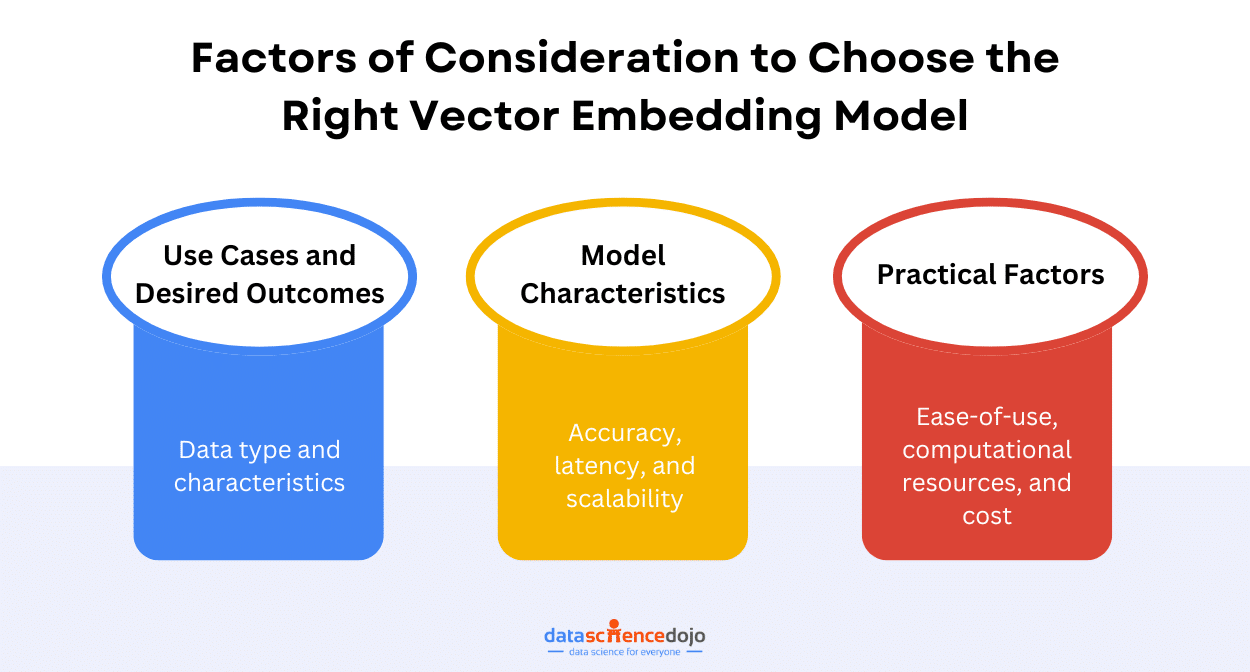
We will explore the practical side of embeddings by creating them in Weaviate using services like OpenAI’s API and open-source models through Huggingface. You will also gain insights into the process of selecting the right embedding model, factoring in considerations like model size, industry relevance, and application type.
Read about Google’s specialized vector embedding tools for healthcare
By the end of this session, you will have a solid understanding of vector embeddings, why they are critical for modern AI systems, and how to implement them effectively.
By mastering the basics of vector embeddings, you’re laying the groundwork for a deeper dive into the advanced AI techniques that shape our digital world. Whether you’re building the next breakthrough in AI or just curious about how it all works, understanding vector embeddings is a critical first step in becoming an expert in the field.
Part 2: Introduction to Vector Search in Vector Embeddings
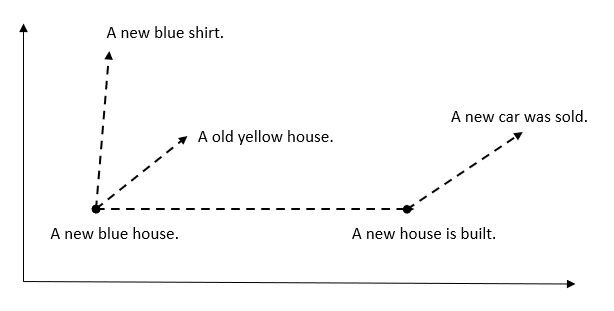
In this next part, we will take a deeper dive into the world of vector embeddings by introducing you to vector search. It refers to a technique that uses mathematical similarity to retrieve related data. Hence, it is a smart way to find information by looking at the meaning behind data instead of exact keywords.
For example, if you search for “affordable smartphones with great cameras,” vector search can understand the intent and show results with similar meanings, even if the exact words don’t match. This works because data is turned into embeddings that capture their meaning.
Vector search involves the comparison of these embeddings by using distance metrics like cosine similarity. The system identifies closely related matches, making vector search especially powerful for unstructured data.

Role of Vector Search in LLMs
The role of vector search extends into the process of semantic understanding and RAG functions of LLMs. Additional functionalities of this process for language models include:
Content Summarization and Question Answering
LLMs depend on vector search for tasks like summarization and question answering. The process enables the models to find the most relevant sections of a document or dataset, improving the accuracy and relevance of their outputs.
Learn about the role and importance of multimodality in LLMs
Multimodal AI Applications
In systems that combine text, images, or audio, vector search helps link related data types. For example, it can match a caption to an image by comparing its embeddings in a shared vector space.
Fine-Tuning and Training
During fine-tuning, LLMs use vector search to align their understanding of concepts with domain-specific data. This makes them more effective for specialized tasks like legal document analysis or scientific research.
Here’s a guide to choosing the right vector embedding model
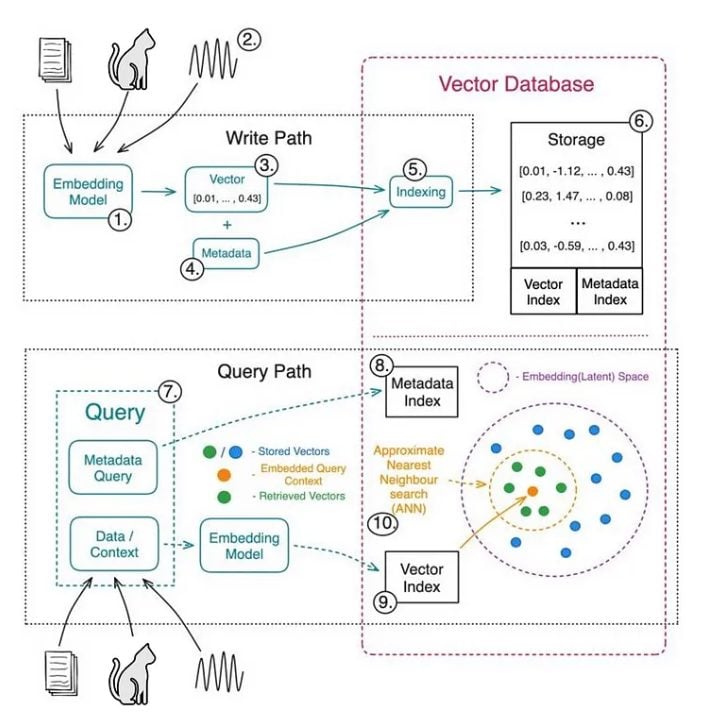
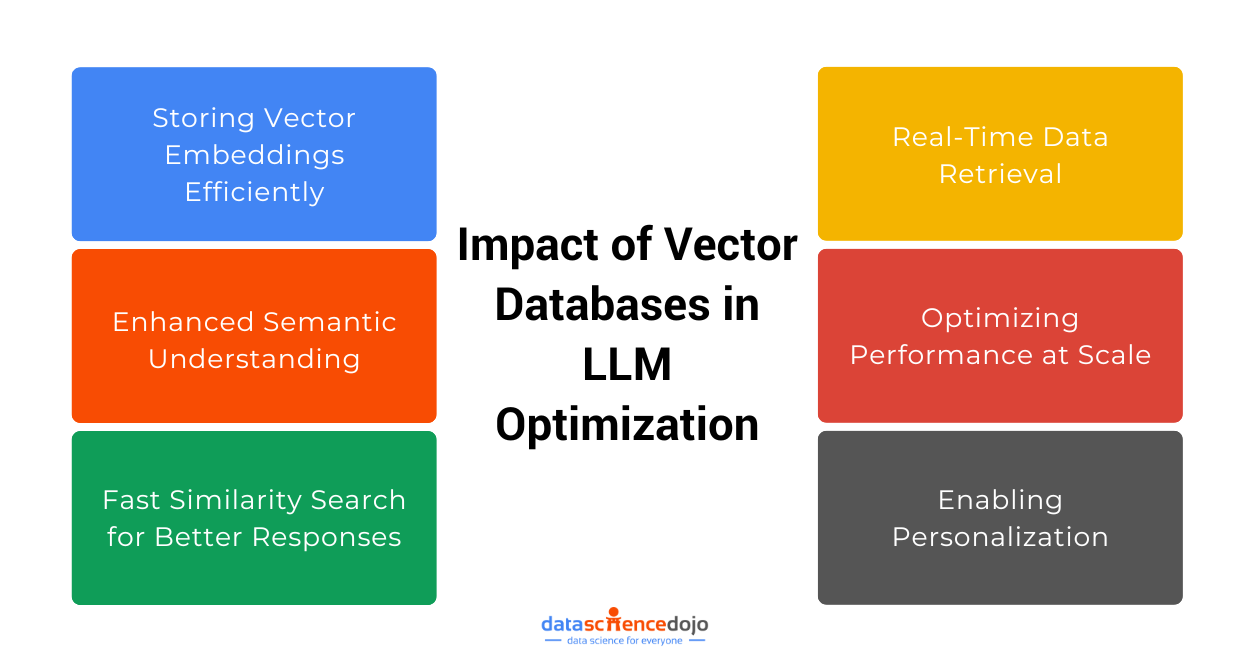
Importance of Vector Databases in Vector Search
Vector databases are the backbone of efficient and scalable vector search. They are specifically designed to store, manage, and query high-dimensional vectors, enabling systems to find similarities between data points quickly and accurately.
Here’s why they are essential:
Efficient Storage and Retrieval
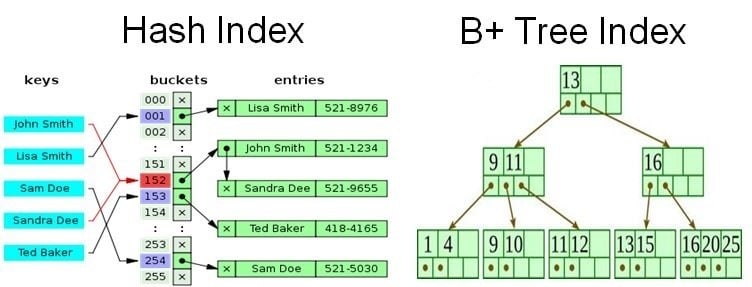
Vector databases optimize the storage of high-dimensional data, making it possible to handle millions or even billions of vectors. They use specialized indexing techniques, like Approximate Nearest Neighbor (ANN) algorithms, to speed up searches without compromising accuracy.
Scalability
As datasets grow larger, traditional databases struggle to handle the complexity of vector searches. Vector databases, on the other hand, are built to scale seamlessly, accommodating massive datasets without significant performance drops.
Real-Time Search Capabilities
Many applications, like recommendation systems or personalized search engines, require instant results. Vector databases deliver real-time performance, ensuring users get quick and relevant results even with complex queries.
Here’s a guide to reverse image search
Integration of Advanced Features
Modern vector databases, like Weaviate, provide features beyond basic vector storage. These include CRUD operations, hybrid search (combining vector and keyword search), and support for embedding generation using APIs or external models. This versatility simplifies the development of AI applications.
Support for Unstructured Data
Vector databases handle unstructured data like images, audio, and text by converting them into embeddings. They allow seamless retrieval of similar items, enabling applications like visual search, recommendation engines, and content moderation.
Improved User Experience
By enabling semantic search and personalized recommendations, vector databases enhance user experiences across platforms. They ensure that users find exactly what they’re looking for, even when queries are vague or lack specific keywords.
Thus, vector search relies on vector databases to enable LLMs to generate accurate and relevant results. While the former is a process, the latter provides the infrastructure to store, manage, and query data effectively. In part 2 of our series, we will explore these topics in detail, making it suitable for beginners and people who aim to deepen their knowledge.
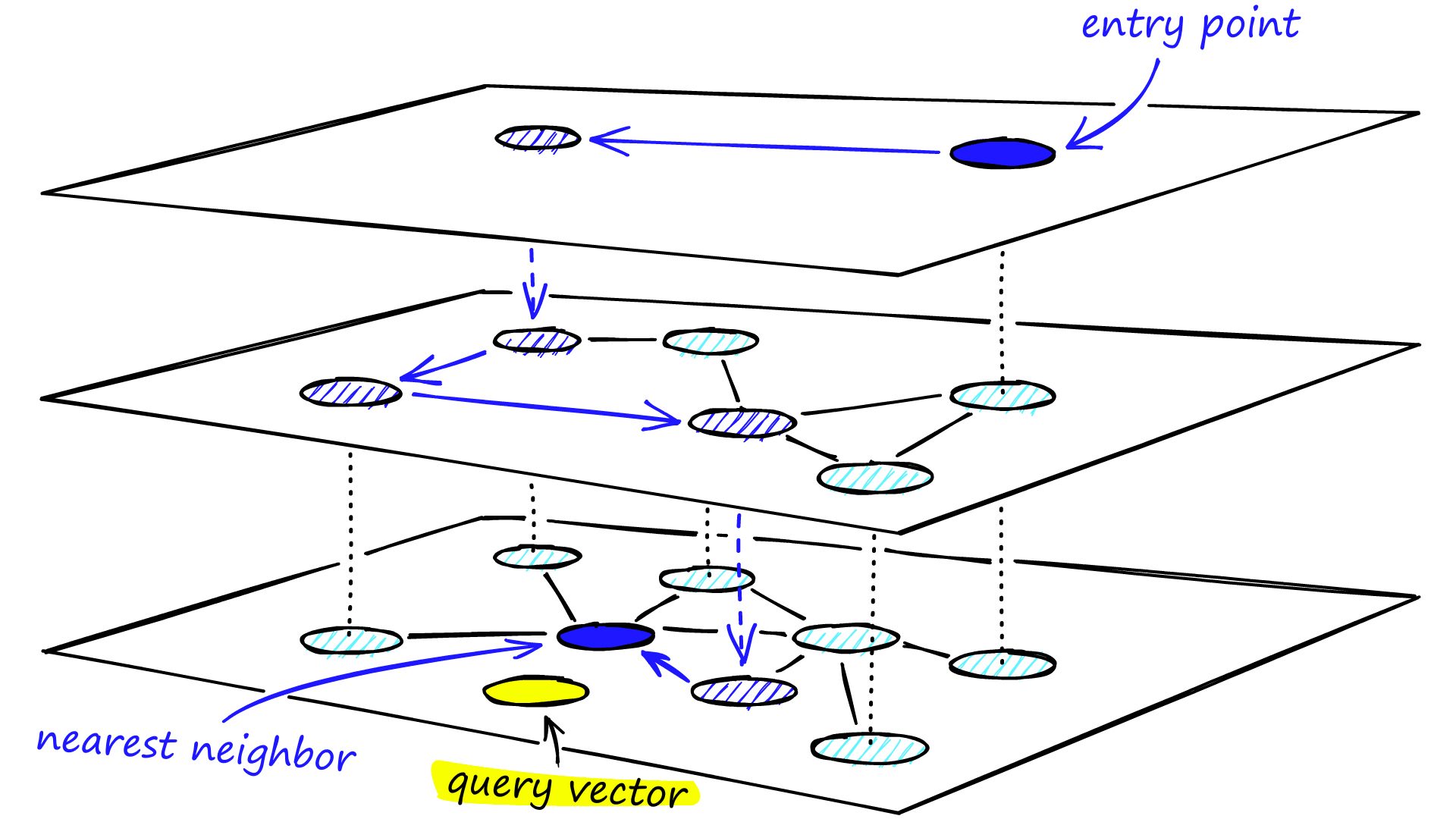
We will break down the major concepts of vector search, explore its limitations, and discuss how it scales with advanced technologies like vector databases. Moreover, you will also learn how modern vector databases, like Weaviate, tackle scalability challenges and optimize search performance with algorithms like Approximate Nearest Neighbor (ANN) and Hierarchical Navigable Small World (HNSW).
This second part of the webinar series will also provide an understanding of how similarity is calculated and explore the limitations of traditional search. You will also see a hands-on demo of implementing vector search over the complete Wikipedia dataset using Weaviate.
Part 3: Challenges of Industry ML/AI Applications at Scale with Vector Embeddings
Scaling AI and ML systems in the modern technological world presents unique and complex challenges. In this last part of the webinar, we will explore the intricacies of building industry-grade ML/AI solutions with hands-on demonstrations using Weaviate.
This session will dive into the details of how to scale AI effectively while maintaining performance and reliability. We will begin with a recap of the foundational concepts from Parts 1 and 2, connecting them to advanced applications like Retrieval Augmented Generation (RAG).
You will also learn how Weaviate simplifies the creation of these systems with its robust architecture. With practical demos and expert insights, this session will provide the tools to tackle the real-world challenges of deploying scalable AI systems.
To conclude this final session of the 3-part webinar series, we will explore the future of AI, including cutting-edge trends like AI agents and Generative Feedback Loops (GFL). The goal will be to showcase their transformative potential for scaling AI applications.
About the Instructor
All the sessions of this webinar series will be led by Victoria Slocum, a machine learning engineer at Weaviate. She specializes in community engagement and education. Her love for creating demo projects, tutorials, and resources enables her to connect with and enable the developer community.
She is highly passionate about making coding accessible. Hence, Victoria focuses on bridging the gap between technical concepts and real-world use cases.

Does this look exciting to you?! If yes, then you should also check out and register for our LLM bootcamp for a deep dive into the world of language models and their increasing impact in today’s digital world.
Meanwhile, you can also access the complete playlist of the 3-part series here: