

Most Data Science enthusiasts know how to write queries and fetch data from SQL but find they may find the concept of indexing to be intimidating.
This blog will aim to clear concepts of how this additional tool can help you efficiently access data, especially when there are clear patterns involved. Having a good understanding of indexing techniques will help you with making better design decisions and performance optimizations for your system.

Understanding Indexing
To understand the concept, take the example of a textbook. Your teacher has just assigned you to open “Chapter 15: Atoms and Ions”. In this case, you will have three possible ways to access this chapter:
- You may turn over each page, until you find the starting page of “Chapter 15”.
- You may open the “Table of Contents”, simply go to the entry of “Chapter 15”, where you will find the page number, where “Chapter 15” starts.
- You may also open the “Index” if words, at the end of the textbooks, where all keywords and their page numbers are mentioned. From there you can find out all the pages where the word “Atoms” is present, accessing each of those pages, you will find the page where “Chapter 15” starts.
In the given example try to figure out which of the paths would be most efficient… You may have already guessed it, the second path, using the “Table of Contents”. You figured this out since you understood the problem and the underlying structure of these access paths. Indexes built on large datasets are very similar to this. Let us move on to a bit more practical example.
It is probable you may have already looked at data with an index built on it, but simply overlooked that detail. Using the “Top Spotify songs from 2010-2019” dataset on Kaggle (https://www.kaggle.com/datasets/leonardopena/top-spotify-songs-from-20102019-by-year), we read it into a Python – Pandas Data Frame.
Notice the left most column, where there is no column name present. This is a default index created by python for this dataset, while considering the first column present in the csv file as an “unnamed” column.
Similarly, we can set index columns according to our requirements. For example, if we wanted to set “nrgy” column as an index, we can do it like this:
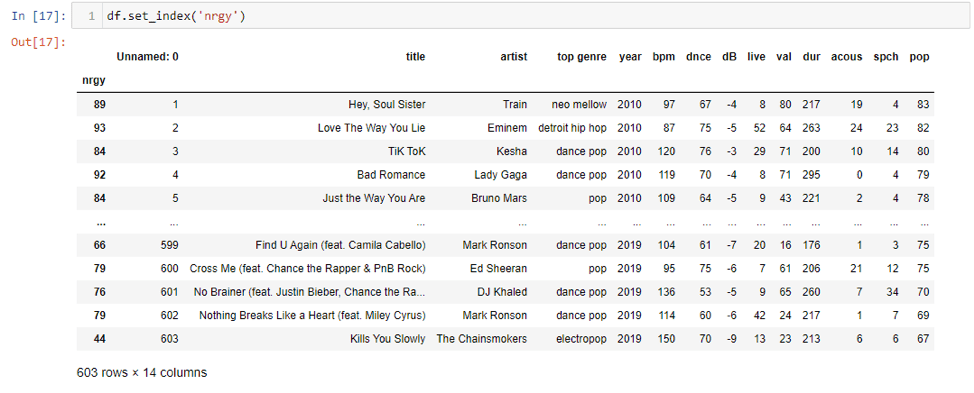
It is also possible to create an index on multiple columns. If we wanted an index on a columns “artist” and “year”, we could do it by passing the string names as a list parameter to our original set index method.
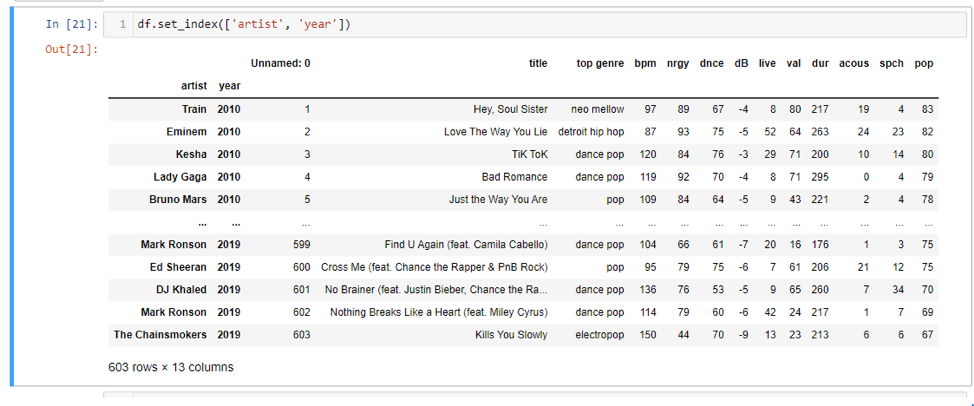
Up till now, you may have noticed a few points, which I will point out:
- An index is an additional access path, which could be used to efficiently retrieve data.
- An index may or may not be built on a column with unique values.
- An index may be built on one more column.
- An index may be built on either ordered or unordered items.
Categories of Indexing
Let us investigate the categories of indexes.
- Primary Indexes: have ordered files and built on unique columns.
- Clustered Indexes: have ordered files and built on non-unique columns.
- Secondary Indexes: have unordered files and are built on either unique or non-unique columns.
You may only build a single Primary or Clustered index on a table. Meaning that the files will be ordered based on a single index only. You may build multiple Secondary indices on a table since they do not require the files to change their order. Advantages of indexing
Since the main purpose of creating and using an index access path is to give us an efficient way to access the data of our choice, we will be looking at it as our main advantage as well.
- An index allows us to quickly locate, and access data based on the indexed columns, without having to scan through the entire file. This can significantly speed up query performance, especially for large files, by reducing the amount of data that needs to be searched and processed.
- With an index, we can jump directly to the relevant portion of the data, reducing the amount of data that needs to be processed and improving access speed.
- Indexes can also help reduce the amount of disk I/O (input/output) needed for data access. By providing a more focused and smaller subset of data to be read from disk, indexes can help minimize the amount of data that needs to be read, resulting in reduced disk I/O and improved overall performance.
Best Practices for Indexing in Python
Efficient and accurate indexing is essential when working with large datasets in Python. Here are some best practices to optimize your indexing techniques and avoid common errors:
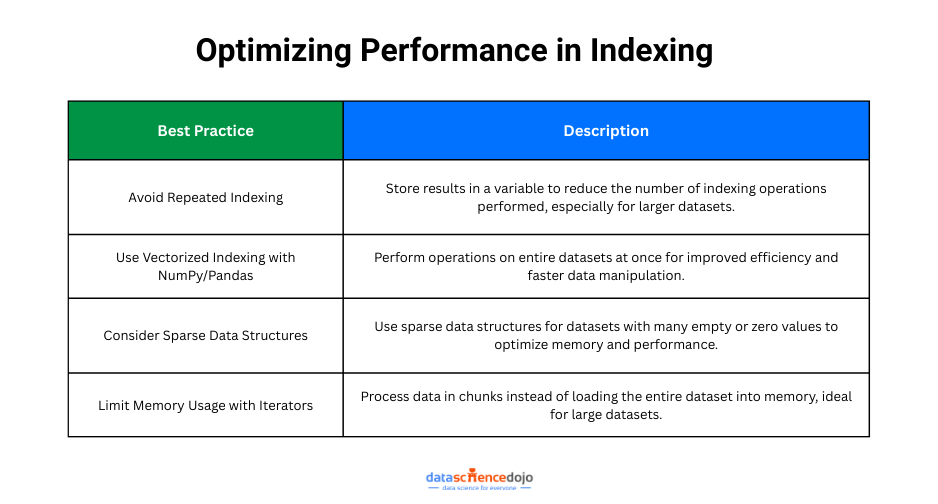
Tips on Optimizing Performance with Large Datasets
Avoid Repeated Indexing: Accessing data multiple times can be inefficient. Instead of repeatedly accessing the same index in a dataset, it’s better to store the result in a variable once and reuse it. This minimizes the number of operations performed, especially in larger datasets.
Use Vectorized Indexing with NumPy and Pandas: Libraries like NumPy and pandas offer vectorized indexing, meaning that they can perform operations on entire datasets at once, without needing loops. This is far more efficient than traditional Python indexing and can significantly speed up data manipulation, especially when dealing with large arrays or tables.
Consider Sparse Data Structures: When working with datasets that contain a lot of zeros or missing values, using sparse data structures is a smart choice. These structures are specifically designed to optimize memory usage and performance when dealing with data that is mostly empty, helping reduce unnecessary overhead.
Limit Memory Usage with Iterators: For extremely large datasets that cannot fit entirely into memory, using iterators can be an effective solution. Iterators allow you to process chunks of data sequentially, avoiding the need to load the entire dataset into memory at once.

How to Avoid Common Indexing Mistakes
Out-of-Range Errors: One of the most common indexing errors occurs when trying to access an index that is outside the valid range of the dataset. Always check that your index is within the bounds of the data (i.e., greater than or equal to zero and less than the length of the data) before trying to access it.
Incorrect Slicing: Slicing allows you to extract a portion of data from a collection, but it’s easy to mistakenly assume the last index in a slice is included. Remember that Python slicing is exclusive of the upper bound, meaning the slice ends before the specified index. This common mistake can lead to unexpected results, so it’s important to understand how slices work to ensure accurate data extraction.
Avoid Modifying Data During Iteration: Modifying a dataset (such as removing or adding elements) while iterating over it can cause unpredictable behavior. It’s best to avoid changing the dataset during iteration or, if necessary, iterate over a copy of the dataset to avoid unintended side effects.
Beware of Indexing with Floats: Indexing in Python requires integers, not floating-point numbers. Attempting to use a floating-point value as an index will lead to an error. If you ever have a float as an index, make sure to convert it to an integer, as only whole numbers can represent positions in a list or array.
Costs of Indexing
- Index Access will not always improve performance. It will depend on the design decisions. It is possible a column frequently accessed in 2023, is the least frequently accessed column in 2026. The previously built index might simply become useless for us.
- For example, a local library keeps a record of their books according to the shelf they are assigned to and stored on. In 2018, the old librarian asked an expert to create an index based on Book ID, assigned to each book at the time when it is stored in the library. The access time per book decreased drastically for that year. A new librarian, hired in 2022, decided to reorder books by their year number and subject. It became slower to access a book through the previously built index as compared to the combination of book year and subject, simply because the order of the books was changed.
- In addition, there will be an added storage cost to the files you have already stored. While the size of an index will be mostly smaller than the size of our base tables, the space a dense index can occupy for large tables may still be a factor to consider.
- Lastly, there will be a maintenance cost attached to an index you have built. You will need to update the index entries whenever insert, update, and delete operations are performed for base table. If a table has a high rate of DML operations, the index maintenance cost will also be extremely high.
While making decisions regarding index creation, you need to consider three things:
1. Index Column Selection: the column on which you will build the index. It is recommended to select the column frequently accessed.
2. Index Table Selection: the table that requires an index to be built upon. It is recommended to use a table with the least number of DML operations.
3. Index Type Selection: the type of index which will give the greatest performance benefit. You may want to look into the types of indices which exist for this decision, few examples include: Bitmap Index, B Tree Index, Hash Index, Partial Index, and Composite Index .
All these factors can be answered by analyzing your access patterns. To put it simply, just look for the table that is most frequently accessed, and which columns are most frequently accessed.
In aNutshell
In conclusion, while indexing can give you a huge performance benefit, in terms of data access, an expert needs to understand the structure and problem before making the appropriate decision whether an index is needed or not, and if needed, then for which table, column(/s), and the index type.
