

This blog will cover how to build a recommendation system using Python libraries to perform web scrapping and carry out text transformation. It will teach you how to create your own dataset and further build a content-based recommendation system.
Introduction
The purpose of Data Science (DS) and Artificial Intelligence (AI) is to add value to a business by utilizing data and applying applicable programming skills. In recent years, Netflix, Amazon, Uber Eats, and other companies have made it possible for people to avail certain commodities with only a few clicks while sitting at home. However, in order to provide users with the most authentic experience possible, these platforms have developed recommendation systems that provide users with a variety of options based on their interests and preferences.
In general, recommendation systems are algorithms that curate data and provide consumers with appropriate material. There are three main types of recommendation engines:
- Collaborative filtering: Collaborative filtering collects data regarding user behavior, activities, and preferences to predict what a person will like, based on their similarity to other users.
- Content-based filtering: This algorithms analyze the possibility of objects being related to each other using statistics, and then offers possible outcomes to the user based on the highest probabilities.
- Hybrid of the two. In a hybrid recommendation engine, natural language processing tags can be generated for each product or item (movie, song), and vector equations are used to calculate the similarity of products.
Building a recommendation system using Python
In this blog, we will walk through the process of scraping a web page for data and using it to develop a recommendation system, using built-in python libraries. Scraping the website to extract useful data will be the first component of the blog. Moving on, text transformation will be performed to alter the extracted data and make it appropriate for our recommendation system to use.
Finally, our content-based recommender system will calculate the cosine similarity of each blog with the rest of the blogs and then suggest three comparable blogs for each blog post.
First step: Web scrapping
The purpose of going through the web scrapping process is to teach how to automate data entry for a recommender system. Knowing how to extract data from the internet will allow you to develop skills to create your own dataset using an entire webpage. Now, let us perform web scraping on the blogs page of online.datasciencedojo.com.
In this blog, we will extract relevant information to make up our dataset. From the first page, we will extract the URL, name, and description of each blog. By extracting the URL, we will have access to redirect our algorithm to each blog page and extract the name and description from the metadata.
The code below uses multiple python libraries and extracts all the URLs from the first page. In this case, it will return ten URLs. For building better concepts regarding web scrapping, I would suggest exploring and playing with these libraries to better understand their functionalities.
Note: The for loop is used to extract URLs from multiple pages.
import requests
import lxml.html
from lxml import objectify
from bs4 import BeautifulSoup
#List for storing urls
urls_final = []
#Extract the metadata of the page
for i in range(1):
url = 'https://online.datasciencedojo.com/blogs/?blogpage='+str(i)
reqs = requests.get(url)
soup = BeautifulSoup(reqs.text, 'lxml')
#Temporary lists for storing temporary data
urls_temp_1 = []
urls_temp_2=[]
temp=[]
#From the metadata, get the relevant information.
for h in soup.find_all('a'):
a = h.get('href')
urls_temp_1.append(a)
for i in urls_temp_1:
if i != None :
if 'blogs' in i:
if 'blogpage' in i:
None
else:
if 'auth' in i:
None
else:
urls_temp_2.append(i)
[temp.append(x) for x in urls_temp_2 if x not in temp]
for i in temp:
if i=='https://online.datasciencedojo.com/blogs/':
None
else:
urls_final.append(i)
print(urls_final)
Output
['https://online.datasciencedojo.com/blogs/regular-expresssion-101/',
'https://online.datasciencedojo.com/blogs/python-libraries-for-data-science/',
'https://online.datasciencedojo.com/blogs/shareable-data-quotes/',
'https://online.datasciencedojo.com/blogs/machine-learning-roadmap/',
'https://online.datasciencedojo.com/blogs/employee-retention-analytics/',
'https://online.datasciencedojo.com/blogs/jupyter-hub-cloud/',
'https://online.datasciencedojo.com/blogs/communication-data-visualization/',
'https://online.datasciencedojo.com/blogs/tracking-metrics-with-prometheus/',
'https://online.datasciencedojo.com/blogs/ai-webmaster-content-creators/',
'https://online.datasciencedojo.com/blogs/grafana-for-azure/']Once we have the URLs, we move towards processing the metadata of each blog for extracting their name and description.
#Getting the name and description
name=[]
descrip_temp=[]
#Now use each url to get the metadata of each blog post
for j in urls_final:
url = j
response = requests.get(url)
soup = BeautifulSoup(response.text)
#Extract the name and description from each blog
metas = soup.find_all('meta')
name.append([ meta.attrs['content'] for meta in metas if 'property' in meta.attrs and meta.attrs['property'] == 'og:title' ])
descrip_temp.append([ meta.attrs['content'] for meta in metas if 'name' in meta.attrs and meta.attrs['name'] == 'description' ])
print(name[0])
print(descrip_temp[0])
Output:
['RegEx 101 - beginner’s guide to understand regular expressions']
['A regular expression is a sequence of characters that specifies a search pattern in a text. Learn more about Its common uses in this regex 101 guide.']
Second step: Text transformation
Similar to any task involving text, exploratory data analysis (EDA) is a fundamental part of any algorithm. In order to prepare data for our recommender system, data must be cleaned and transformed. For this purpose, we will be using built-in python libraries to remove stop words and transform data.
The code below uses the regex library to perform text transformation by removing punctuations, emojis, and more. Furthermore, we have imported a natural language toolkit (nlkt) to remove stop words.
Note: Stop words are a set of commonly used words in a language. Examples of stop words in English are “a”, “the”, “is”, “are” etc. They are so frequently used in the text that they hold a minimal amount of useful information.
import nltk
from nltk.corpus import stopwords
nltk.download("stopwords")
import re
#Removing stop words and cleaning data
stop_words = set(stopwords.words("english"))
descrip=[]
for i in descrip_temp:
for j in i:
text = re.sub("@\S+", "", j)
text = re.sub(r'[^\w\s]', '', text)
text = re.sub("\$", "", text)
text = re.sub("@\S+", "", text)
text = text.lower()
descrip.append(text)Following this, we will be creating a bag of words. If you are not familiar with it, a bag of words is a representation of text that describes the occurrence of words within a document. It involves two things: A vocabulary of known words, and a measure of the presence of those words. For our data, it will represent all the keywords words in the dataset and calculate which words are used in each blog and the number of occurrences they have. The code below uses a built-in function to extract keywords.
from keras.preprocessing.text import Tokenizer
#Building BOW
model = Tokenizer()
model.fit_on_texts(descrip)
bow = model.texts_to_matrix(descrip, mode='count')
bow_keys=f'Key : {list(model.word_index.keys())}'
For building better concepts, here are all the extracted keywords.
"Key : ['data', 'analytics', 'science', 'hr', 'azure', 'use', 'analysis', 'dojo',
'launched', 'offering', 'marketplace', 'learn', 'libraries', 'article', 'machine', 'learning', 'work', 'trend', 'insights', 'step',
'help', 'set', 'content', 'creators', 'webmasters', 'regular', 'expression', 'sequence', 'characters', 'specifies', 'search', 'pattern',
'text', 'common', 'uses', 'regex', '101', 'guide', 'blog', 'covers', '6', 'famous', 'python', 'easy', 'extensive', 'documentation',
'perform', 'computations', 'faster', 'enlists', 'quotes', 'analogy', 'importance', 'adoption', 'wrangling', 'privacy', 'security', 'future',
'find', 'start', 'journey', 'kinds', 'projects', 'along', 'way', 'succeed', 'complex', 'field', 'classification', 'regression', 'tree',
'applied', 'companys', 'great', 'resignation', 'era', 'economic', 'triggered', 'covid19', 'pandemic', 'changed', 'relationship', 'offices',
'workers', 'explains', 'overcoming', 'refers', 'collection', 'employee', 'reporting', 'actionable', 'click', 'code', 'explanation', 'jupyter',
'hub', 'preinstalled', 'exploration', 'modeling', 'instead', 'loading', 'clients', 'bullet', 'points', 'longwinded', 'firms',
'visualization', 'tools', 'illustrate', 'message', 'prometheus', 'powerful', 'monitoring', 'alert', 'system', 'artificial', 'intelligence',
'added', 'ease', 'job', 'wonder', 'us', 'introducing', 'different', 'inventions', 'ai', 'helping', 'grafanas', 'harvest', 'leverages', 'power',
'microsoft', 'services', 'visualize', 'query', 'alerts', 'promoting', 'teamwork', 'transparency']"The code below assigns each keyword an index value and calculates the frequency of each word being used per blog. When building a recommendation system, these keywords and their frequencies for each blog will act as the input. Based on similar keywords, our algorithm will link blog posts together into similar categories. In this case, we will have 10 blogs converted into rows and 139 keywords converted into columns.
import pandas as pd
#Creating df
df_name=pd.DataFrame(name)
df_name.rename(columns = {0:'Blog'}, inplace = True)
df_count=pd.DataFrame(bow)
frames=[df_name,df_count]
result=pd.concat(frames,axis=1)
result=result.set_index('Blog')
result=result.drop([0], axis=1)
for i in range(len(bow)):
result.rename(columns = {i+1:i}, inplace = True)
result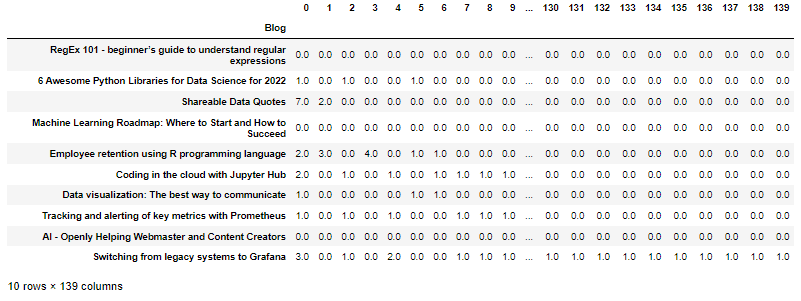
Third step: Cosine similarity
Whenever we are performing some tasks involving natural language processing and want to estimate the similarity between texts, we use some pre-defined metrics that are famous for providing numerical evaluations for this purpose. These metrics include:
- Euclidean Distance
- Cosine similarity
- Jaccard similarity
- Pearson similarity
While all four of them can be used to evaluate a similarity index between text documents, we will be using cosine similarity for our task. Cosine similarity, in data analysis, measures the similarity between two vectors of an inner product space. It is often used to measure document similarity in text analysis.It measures the cosine of the angle between two vectors and determines a numerical value indicating the probability of those vectors being in the same direction. The code alongside the heatmap shown below visualizes the cosine similarity index for all the blogs.
from sklearn.metrics.pairwise import cosine_similarity
import seaborn as sns
#Calculating cosine similarity
df_name=df_name.convert_dtypes(str)
temp_df=df_name['Blog']
sim_df = pd.DataFrame(cosine_similarity(result, dense_output=True))
for i in range(len(name)):
sim_df.rename(columns = {i:temp_df[i]},index={i:temp_df[i]}, inplace = True)
ax = sns.heatmap(sim_df)
Fourth step: Evaluation
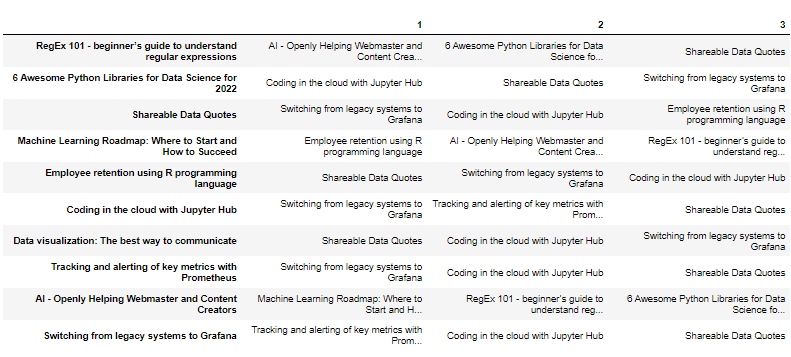
In the code below, our recommender system will extract the three most similar blogs for each blog using Pandas DataFrame.
Note: For each blog, the blog itself is also recommended because it was calculated to be the most similar blog, with the maximum cosine similarity index, 1.
Conclusion
This blog post covered a beginner’s method of building a recommendation system using python. While there are other methods to develop recommender systems, the first step is to outline the requirements of the task at hand. To learn more about this, experiment with the code and try to extract data from another web page or enroll in our Python for Data Science course and learn all the required concepts regarding Python fundamentals.

Written by Muhammad Taimoor