Billions of users use various social media daily and see a lot of new suggestions there. The content includes text, images, videos, and so on depending on the social platform. Do you know how that content is suggested?
We will learn about it in this blog.
Social Media Recommendation System
It is an algorithm that suggests relevant products to users based on a variety of factors. Sometimes, when you search for a certain product on a website you notice that you start receiving several suggestions of similar products, there is a system behind this. It is generally used to target potential users more efficiently and improve the user experience by suggesting new items, saving users’ time, and narrowing down the set of choices.
Learn about Data Science here
Watch the video to see what a recommendation system is and how it is used in various real-world applications.
Now that we know the concept, let’s dive deeper into a real-world application to better comprehend it.
YouTube’s Recommendation System Journey
YouTube has over 800 million videos, which is about 17,810 years of continuous video watching. It is hard for a user to repeatedly search for certain sorts of videos from millions of videos. This problem is solved by recommendation systems, which provide relevant videos based on what you are currently watching.
The system also works when you open YouTube’s home page and do not watch any videos. In this case, it shows the mixture of the subscribed, most up-to-date, promoted, and most recently watched videos.
Let’s discuss the journey of the recommendation system on YouTube.
In 2008, YouTube’s recommendation system ranked videos based on popularity. The issue with this approach was sometimes violent or racy videos get popular. To avoid this, YouTube built classifiers to identify this type of content and avoid recommending them. After a couple of years, YouTube started to incorporate video watch time in its recommendation system.
The reason for this was that users often watched different types of videos and there were different recommendations for them. Later, YouTube took surveys where users rated the watched videos and answered the questions upon giving low or high stars.
Soon, YouTube’s management realized that everyone did not fill out the survey. So, YouTube trained a machine learning model on completed surveys and predicted the survey responses. YouTube did not stop there; they started to consider the likes/dislikes and share information to make the recommender system better.
Nowadays, they are also using classifiers to identify authoritative and borderline (doesn’t quite violate community) content to make a better recommender system.
Read more about social media algorithms in this blog
Before diving deep into the technical details, let’s first discuss common types of recommendation systems.
Classification of Recommendation System
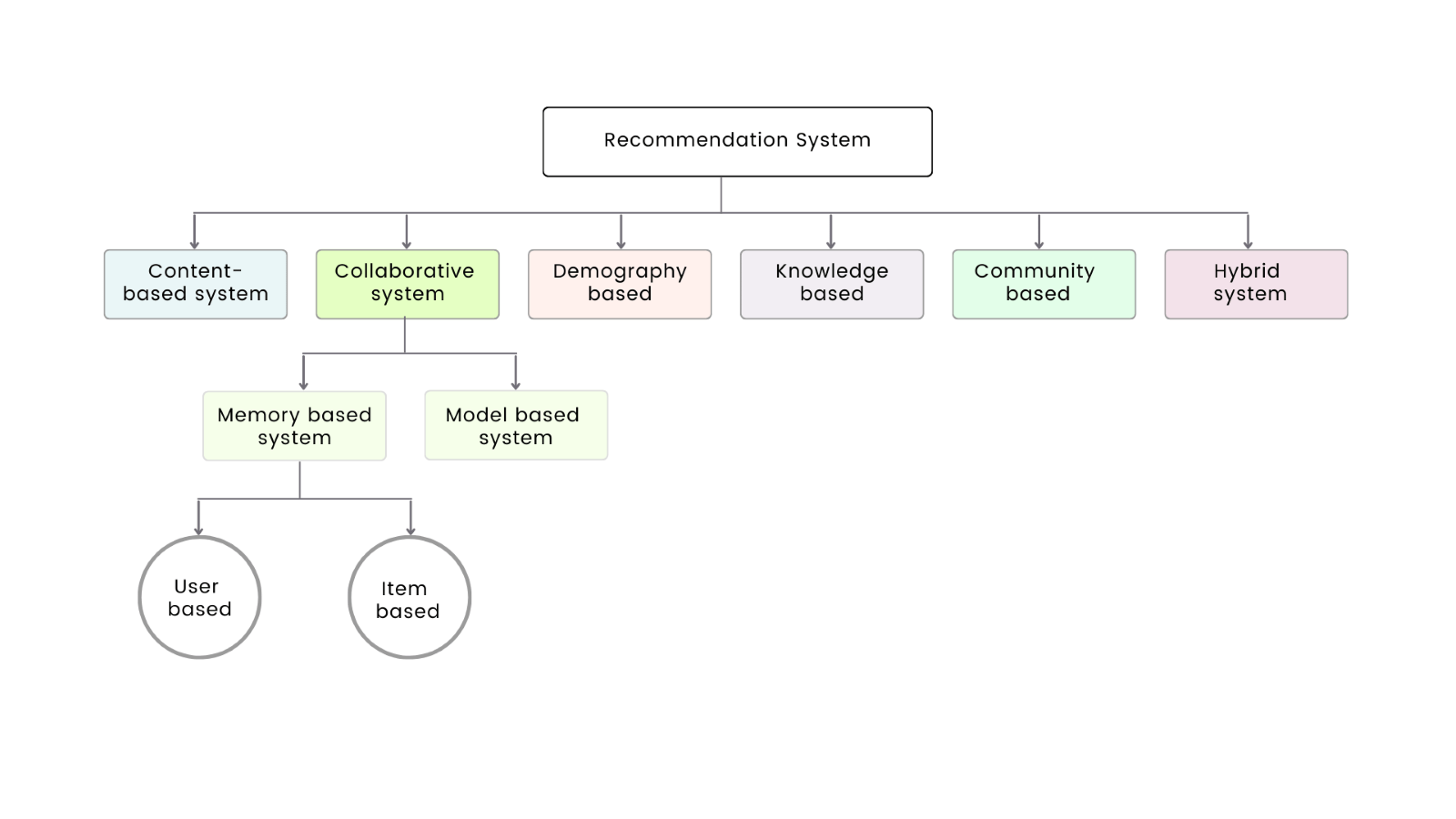
These types of recommendation systems are widely used in industry to solve different problems. We will go through these briefly.
1. Content-Based Recommendation System
According to the user’s past behavior or explicit feedback, content-based filtering uses item features (such as keywords, categories, etc.) to suggest additional items that are similar to what they already enjoy.
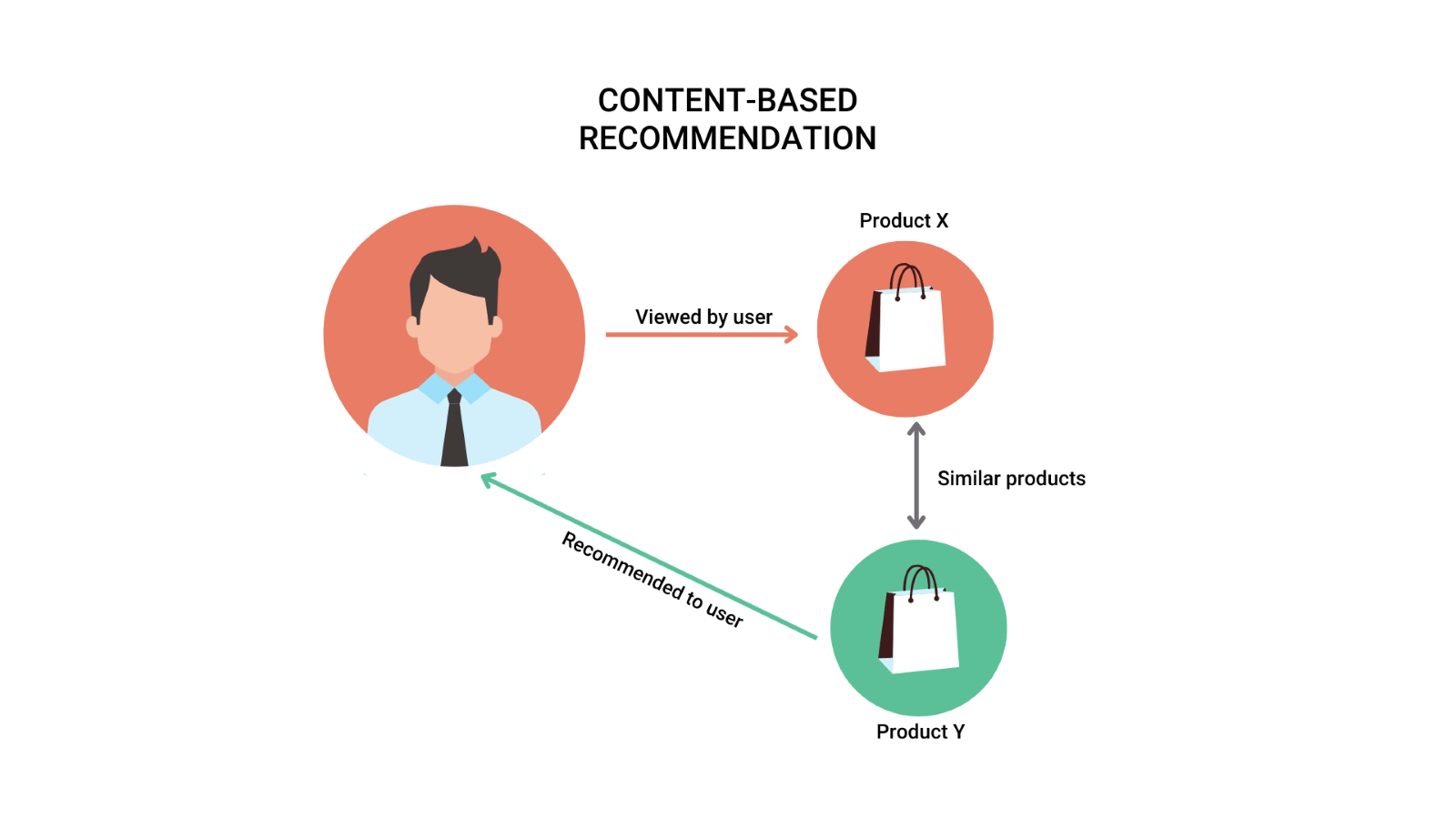
2. Collaborative Recommendation System
Collaborative filtering gives information based on interactions and data acquired by the system from other users. It is divided into two types: memory-based, and model-based systems.
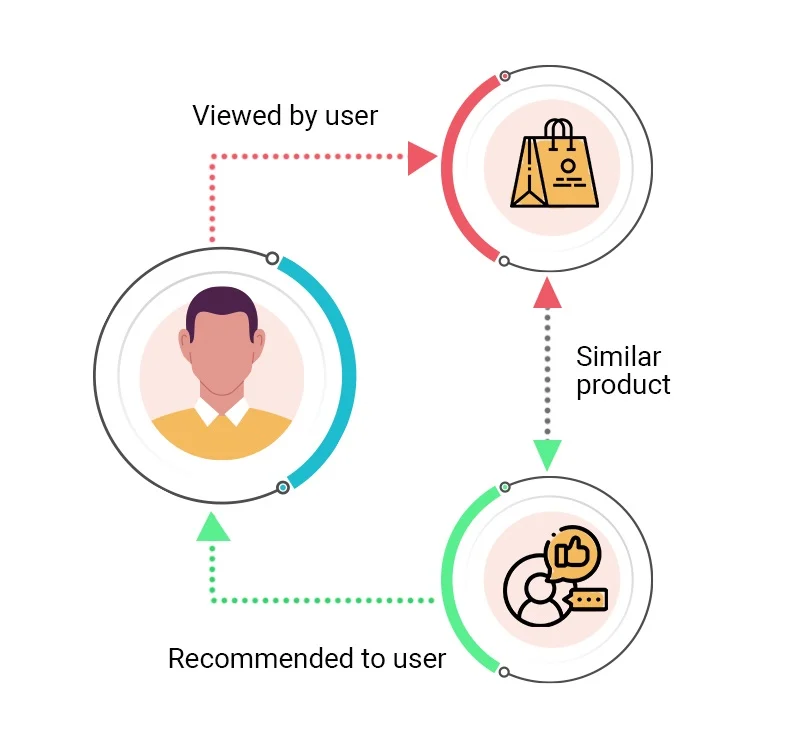
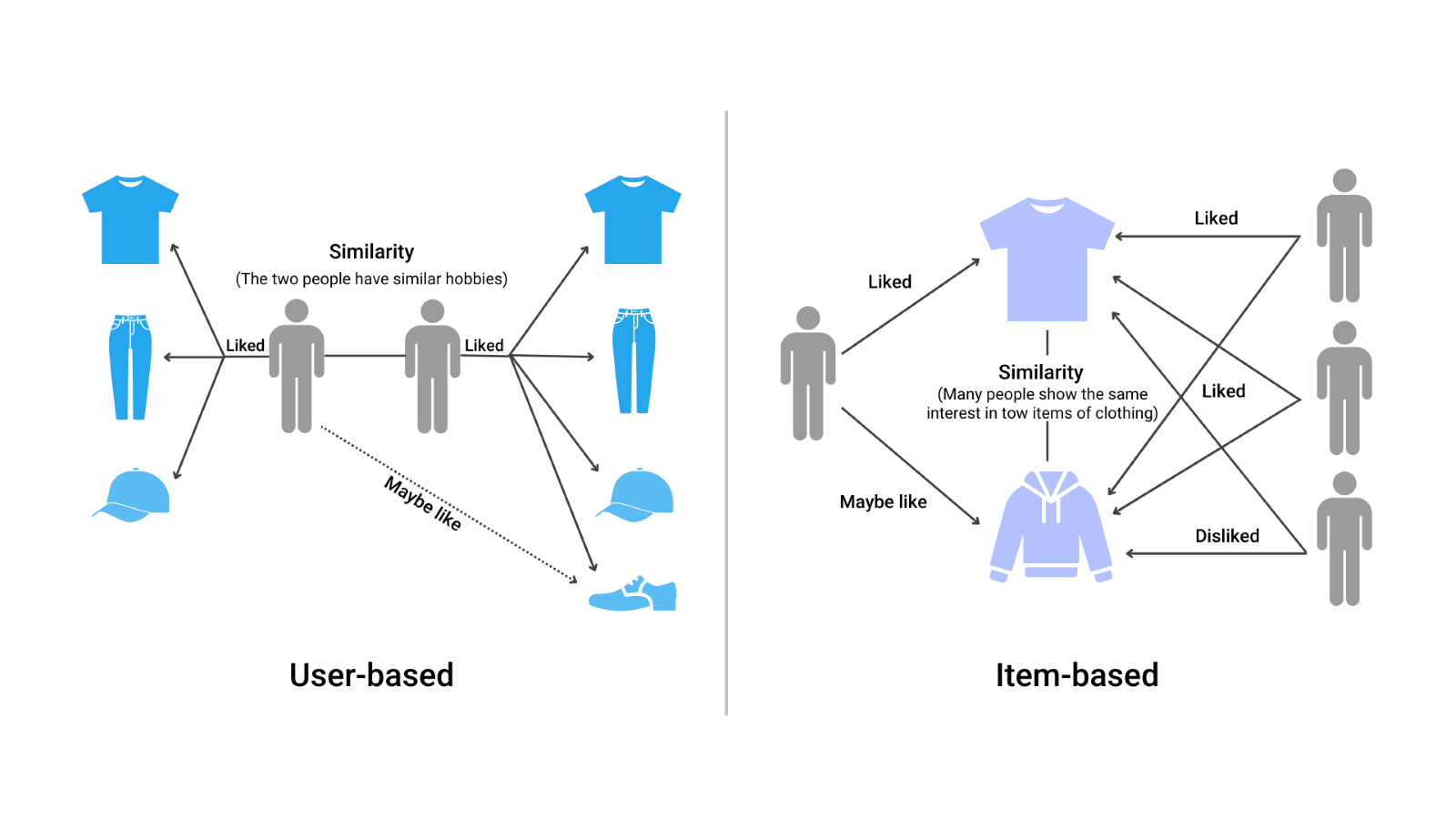
a) Memory-Based System
This mechanism is further classified as user-based and item-based filtering. In the user-based approach, recommendations are made based on the user’s preferences that are similar to the preferences of other users. In the item-based approach, recommendations are made based on items similar to other items the active user likes.
Let’s see the illustration below to understand the difference:
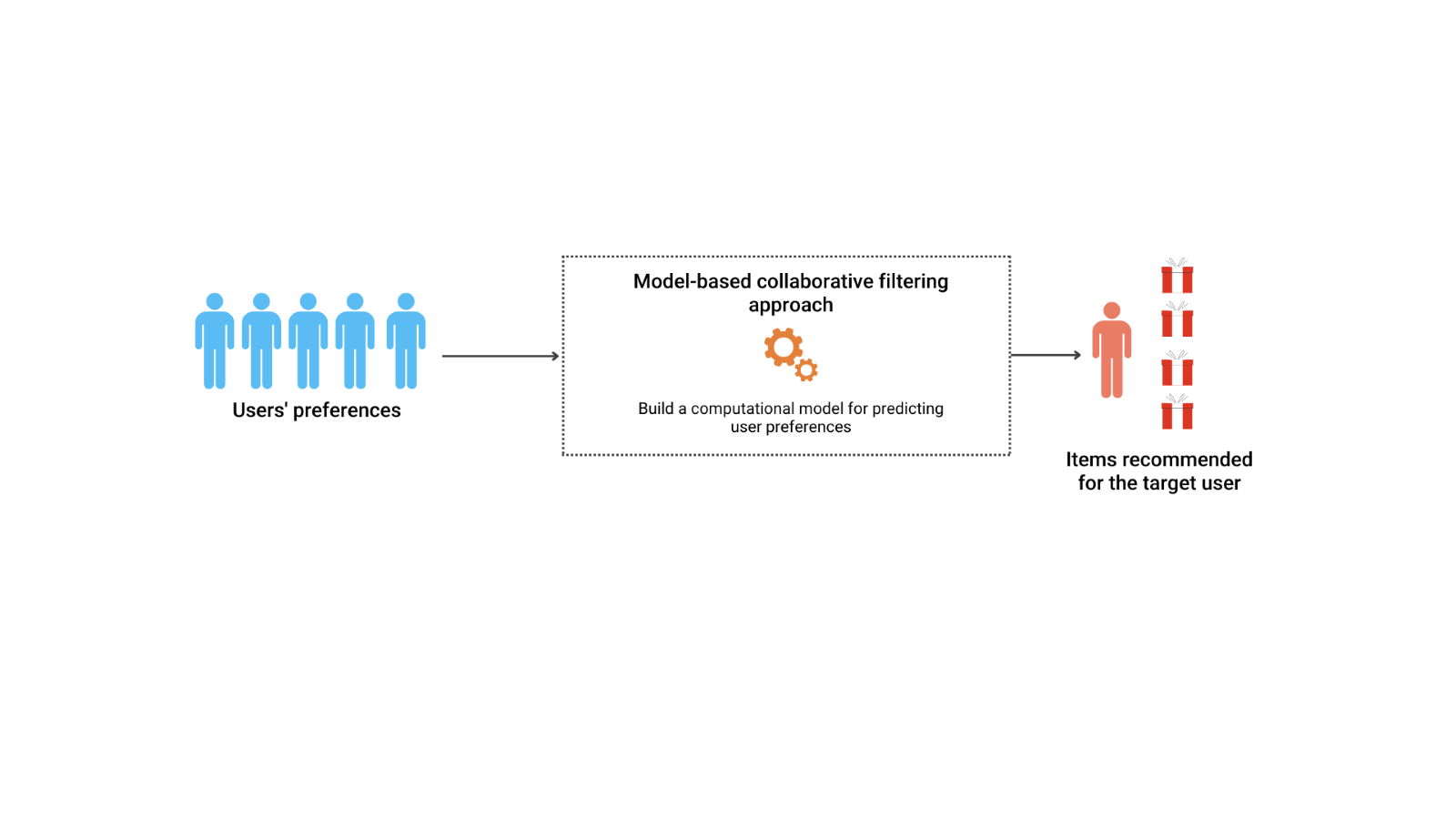
b) Model-Based System
This mechanism provides recommendations by developing machine learning models from users’ ratings. A few commonly used machine learning models are clustering-based, matrix factorization-based, and deep learning models.
2. Demographic-Based Recommendation System
This system provides recommendations based on user demographic attributes, such as age, sex, and location. This system uses demographic information, such as a user’s age, gender, and location, to provide personalized recommendations. This type of system uses data about a user’s characteristics to suggest items that may be of particular interest to them.
For example, a recommendation system might use a user’s age and location to suggest events or activities in the user’s area that might be of interest to someone in their age group.
3. Knowledge-Based Recommendation System
This system offers recommendations based on queries made by the user rather than a user’s rating history. Shortly, it is based on explicit knowledge of the item variety, user preference, and suggestion criteria. This strategy is suited for complex domains where products are not acquired frequently, such as houses and automobiles.
4. Community-Based Recommendation System
This system provides recommendations based on user-interacted items within a community that shares a common interest. A community-based recommendation system is a tool that uses the interactions and preferences of a group of people with a shared interest to provide personalized recommendations to individual users.
This type of system takes into account the collective experiences and opinions of the community in order to provide personalized recommendations.
5. Hybrid Recommendation System
This system is a combination of two or more discussed recommendation systems such as content-based, collaborative-based, and so on. Sometimes a single recommendation system cannot solve an issue, thus we must combine two or more recommendation systems.
We now have a high-level understanding of the various recommendation systems. Recall the YouTube discussion, what do you think, about which recommendation method suits YouTube the most?
It is a memory-based collaborative recommendation system. YouTube can use an item-based approach to suggest videos based on other similar videos using users’ ratings (clicked on and watched videos). To determine the most similar match, we can use matrix factorization. This is a class of collaborative recommendation systems to find the relationship between items’ and users’ entities. However, this approach has numerous limitations, such as
- Not being suitable for complex relations in the users and items
- Always recommend popular items
- Cold start problem (cannot anticipate items and users that we have never encountered in training data)
- Can only use limited information (only user IDs and item IDs)
To address the shortcomings of the matrix factorization method, deep neural networks are designed and used by YouTube. Deep learning is based on artificial neural networks, which enable computers to comprehend and make decisions in the same way that the human brain does.
Let’s watch the video below to gain a better understanding of deep learning.
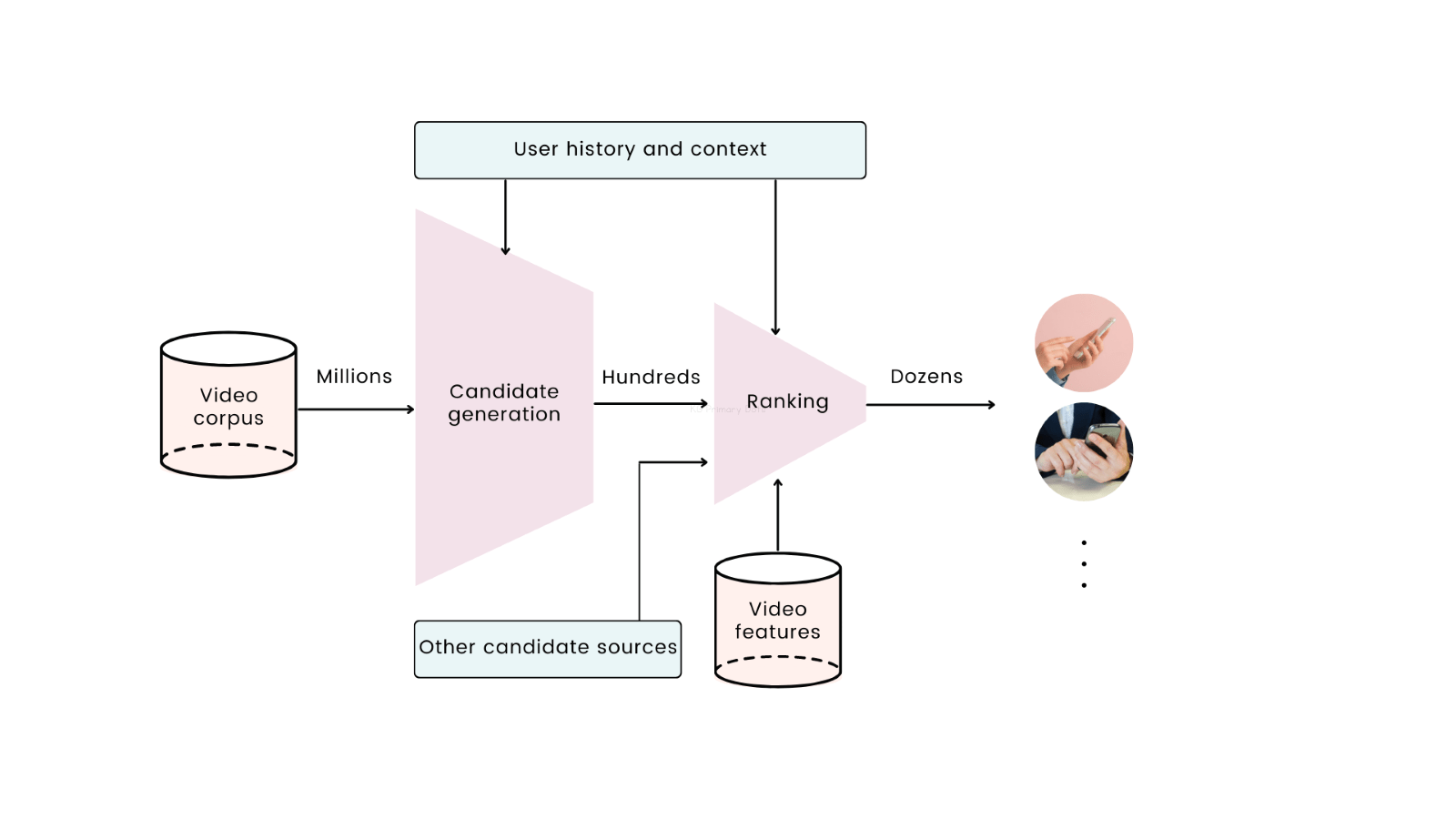
YouTube uses the deep learning model for its video recommendation system. They provide users’ watch history and context to the deep neural network. The network then learns from the provided data and uses the softmax classifier (used for multiclass classification) to differentiate among the videos. This model provides hundreds of videos from a pool of over 800 million videos. This procedure was named “candidate generation” by YouTube.
But we just need to reveal a few of them to a certain user. So, YouTube created a ranking system in which they provide a rank (score) to each of a few hundred videos. They used the same deep learning model that assigns a score to each video for this. The score may be based on the video that the user watched from any channel and/or the most recently watched video topic.
Summary
We studied different recommendation systems that can be used to address various real-world challenges. These systems help to connect people with resources and information that may not have been easily discoverable otherwise, making them a useful tool for solving these challenges.
We discussed the journey of YouTube’s recommendation system, a collaborative system used by YouTube, and examined how YouTube performed well using deep learning in their systems.