

Data Science Dojo is offering DBT for FREE on Azure Marketplace packaged with support for various data warehouses and data lakes to be configured from CLI.
What does DBT stands for?
Traditionally, data engineers had to process extensive data available at multiple data clouds in the same available cloud environments. The next task was to migrate the data and then transform it as per the requirements, but Data migration was a task not easy to do so. DBT short for Data Build Tool, allows the analysts and engineers to manipulate massive amounts of data from various significant cloud warehouses to be processed reliably at a single workstation using modular SQL.
It is basically the “T” in ELT for data transformation in diverse data warehouses.
ELT vs ETL – Insights of both terms
Now what do these two terms mean? Have a look at the table below:
|
|
ELT |
ETL |
| 1. | Stands for Extraction Load Transform | Stands for Extraction Transform Load |
| 2. | Supports structured, unstructured, semi structured and raw type of data | Requires relational and structured dataset |
| 3. | New technology, so it’s difficult to find experts or to create data pipelines | Old process, used for over 20 years now |
| 4. | Dataset is extracted from sources and warehoused in the destination and then transformed | After extraction, data is brought into the staging area where’s its transformed and then loaded into target system |
| 5. | Quick data loading time because data is integrated at target system once and then transformed | Takes more time as it’s a multistage process involving a staging area for transformation and twice loading operations |
Use cases for ELT
Since dbt relates closely to ELT process, let’s discuss its use cases:
- Associations with huge volumes of information: Meteorological frameworks like weather forecasters gather, examine and utilize a lot of information consistently. Organizations with enormous exchange volumes additionally fall into this classification. The ELT process considers faster exchange of data
- Associations needing quick accessibility: Stock trades produce and utilize a lot of data continuously, where postponements can be destructive.
Challenges for Data Build Tool (DBT)
Data distributed across multiple data centers and the ability to transform those volumes at a single place was a big challenge.
Then testing and documenting the workflow was another problem.
Therefore, an engine that could cater to the multiple disjointed data warehouses for data transformation would be suitable for the data engineers. Additionally, testing the complex data pipeline with the same agent would do wonders.
Working of DBT
Data Build Tool is a partially open-source platform for transforming and modeling data obtained from your data warehouses all in one place. It allows the usage of simple SQL to manipulate data acquired from different sources. Users can document their files and can generate DAG diagrams thereby identifying the lineage of workflow using dbt docs. Automated tests can be run to detect flaws and missing entries in the data models as well. Ultimately, you can deploy the transformed data model to any other warehouse. DBT serves pleasantly in the cutting-edge information stack and is considered cloud agnostic meaning it operates with several significant cloud environments.
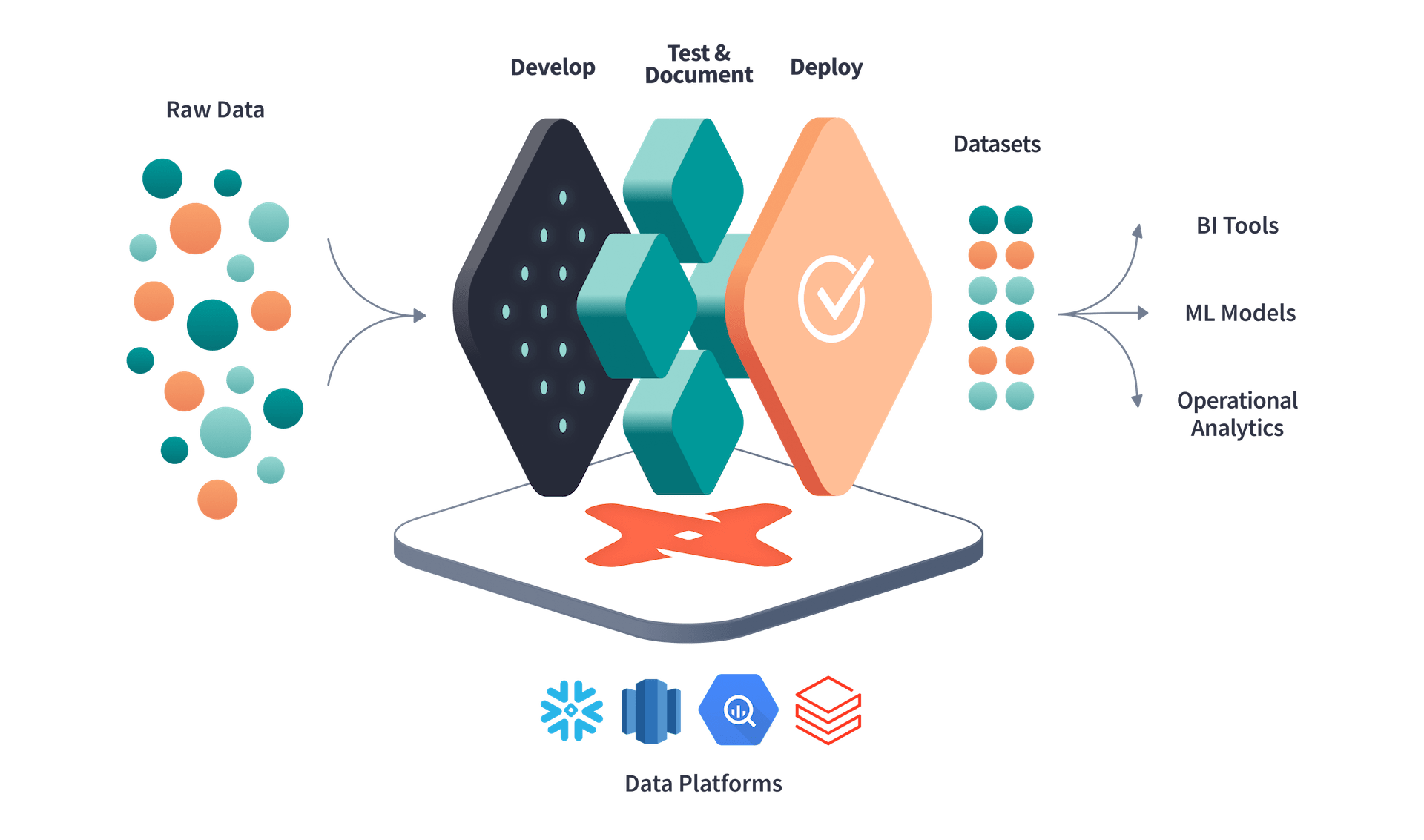
(Picture Courtesy: https://www.getdbt.com/ )
Important aspects of DBT
- DBT enables data analysts with the feasibility to take over the task of data engineers. With modular SQL at hand, analysts can take ownership of data transformation and eventually create visualizations upon it
- It’s cloud agnostic which means that DBT can handle multiple significant cloud environments with their warehouses such as BigQuery, Redshift, and Snowflake to process mission-critical data
- Users can maintain a profile specifying connections to different data sources along with schema and threads
- Users can document their work and can generate DAG diagrams to visualize their workflow
- Through the snapshot feature, you can take a copy of your data at any point in time for a variety of reasons such as tracing changes, time intervals, etc.
What Data Science Dojo has for you
DBT instance packaged by Data Science Dojo comes with pre-installed plugins which are ready to use from CLI without the burden of installation. It provides the flexibility to connect with different warehouses, load the data, transform it using analysts’ favorite language – SQL and finally deploy it to the data warehouse again or export it to data analysis tools.
- Ubuntu VM having dbt Core installed to be used from Command Line Interface (CLI)
- Database: PostgreSQL
- Support for BigQuery
- Support for Redshift
- Support for Snowflake
- Robust integrations
- A web interface at port 8080 is spun up by dbt docs to visualize the documentation and DAG workflow
- Several data models as samples are provided after initiating a new project
This dbt offer is compatible with the following cloud providers:
- GCP
- Snowflake
- AWS
Disclaimer: The service in consideration is the free open-source version which operates from CLI. The paid features as stated officially by DBT are not endorsed in this offer.
Conclusion
Incoherent sources, data consistency problems, and conflicting definitions for measurements and enterprise details lead to disarray, excess endeavors, and unfortunate data being dispersed for decision-making. DBT resolves all these issues. It was built with version control in mind. It has enabled data analysts to take on the role of data engineers. Any developer with good SQL skills is able to operate on the data – this is in fact the beauty of this tool.
At Data Science Dojo, we deliver data science education, consulting, and technical services to increase the power of data. Therefore, to enhance your data engineering and analysis skills and make the most out of this tool, use the Data Science Bootcamp by Data Science Dojo, your ideal companion in your journey to learn data science!
Click on the button below to head over to the Azure Marketplace and deploy DBT for FREE by clicking on “Get it now”.

Note: You’ll have to sign up to Azure, for free, if you do not have an existing account.