

Welcome to Data Science Dojo’s weekly newsletter, “The Data-Driven Dispatch“.
This week, we’ll understand the very basis of how LLMs function by decoding vector embeddings.
Imagine you’re trying to remember a dish from a long-ago meal. You can’t recall the name, but you distinctly remember the unique blend of flavors—perhaps a mix of spicy and sweet, with a hint of something exotic like saffron.
Typically, you might try searching on the browser with phrases like “dish with sweet and spicy flavors and saffron.”
However, it will return recipes or dishes that just happen to contain the terms in your query, but not necessarily capture the dish you remember.
However, when you share this vague description with ChatGPT, things work differently.
Instead of just matching keywords, it analyzes the meaning behind your words and how they connect to various dishes. This capability of LLMs is powered by vector embeddings.
Let’s dive deeper into what vector embeddings are, how they enable semantic search and more.

What are Vector Embeddings? How Do They Capture the Meaning Behind Words?
To understand vector embeddings fully, let us start small.
Let’s suppose that we have a 2-dimensional space where each dimension represents the taste characteristics of a particular dish i.e. sweet, and sour.
Then, we plot different dishes as vectors in that space. Let’s visualize it:
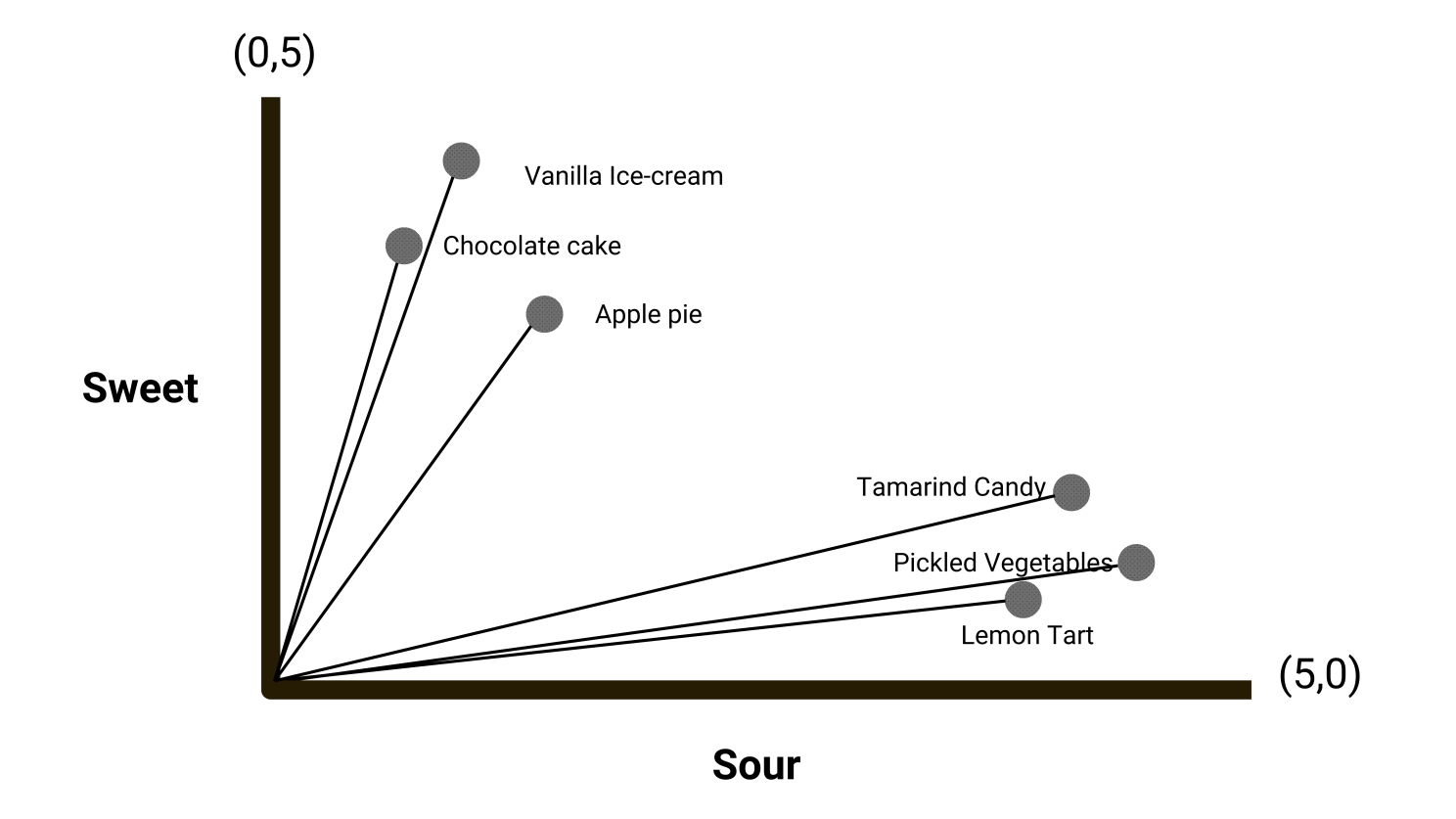
Here, we can determine different attributes of the dishes plotted i.e. sweetness and sourness. Moreover, we can also see that the sweeter dishes are closer together, and the sourer dishes are next to each other.
Let’s say, we add more dimensions to understand other aspects of the taste of the dishes plotted such as bitter, salty, and savory.
Or, one step ahead, we add more dimensions to comprehend how the food looks, feels, smells, etc.
As we keep on increasing the dimensions, we keep on understanding the meaning of the words that are represented as vectors in more depth.
The words or phrases with common meanings have less semantic distances and vice versa.
And voila, that is what vector embeddings are.
They are representations of words in the form of vectors in a high-dimensional space where the position of a vector is determined by its semantic meaning.

OpenAI’s embedding model, Ada-002 has 1536 dimensions. Such amounts of dimensions allow the model to understand your queries through their meaning.
How Vector Embeddings Enable Semantic Search
Embeddings open the door to a powerful tool: semantic search. This means searching based on the underlying meaning rather than relying solely on exact keywords.
How does that work?

Consider this scenario: Imagine you have a vast collection of documents stored on Google Drive, over a million. You could generate a vector embedding for each of these documents and keep them in what is known as a vector database (or vector store).
Now, instead of the typical keyword-based search, your queries could look something like:
Document about a groundbreaking AI experiment mentioned in a newsletter.
Here’s what happens next: The system would generate a vector embedding for your search query, essentially plotting this “point” in our expansive vector space.
Using the vector database, it would then identify the nearest “points” to our query’s representation, based on their semantic proximity. And there you have it! You’d find the documents discussing the specific AI experiment you remembered reading about.
Recommended Read:


A Step-by-Step Tutorial to Understand Vector Databases
Want more clarity to digest this topic entirely?
Here’s a comprehensive tutorial by Syed Muhammad Hani, a Data Scientist at Data Science Dojo. He introduces vector embeddings, how they empower vector databases, and their vast applications.

To connect with LLM and Data Science Professionals, join our discord server now!

Let us know in the comments if you can relate!


Beyond Embeddings: Learn About the Architecture of LLMs
Embeddings are one of the building blocks of large language models. However, you need to understand more areas such as the transformer architecture, attention mechanisms, prompt engineering, etc. to understand LLMs completely.
Here’s a short, live course that can help you master the underlying architecture of LLM applications

Learn more about the curriculum on the website.

Here are headlines in the AI-verse for this week.
- Meta releases Llama 3 and claims it’s among the best open models available. Read more
- Microsoft releases Phi-3 small language models with big potential. Read more
- Apple renews talks with OpenAI for iPhone generative AI features. Read more
- A morning with the Rabbit R1: a fun, funky, unfinished AI gadget. Read more
- Mistral backer leads £12m round in UK AI startup Jigsaw. Read more