

Welcome to Data Science Dojo’s weekly newsletter, “The Data-Driven Dispatch“.
Have you chatted with ChatGPT for a while only to think it’s the dumbest thing to exist on the planet? Well, no offense, that happens a lot of times. Then, how can there be so much hype for something so dumb?
Well, the answer lies in creating a difference between the tools that use LLMs and the technology of LLMs in itself.
Here’s the deal: Large language models are very powerful. However, the tools that use them can sometimes not leverage them fully. To avoid such dumb encounters, there are several methods that bolster the performance of LLM-powered tools.
This includes Fine-tuning (akin to specializing in a single field), Reinforcement Learning from Human Feedback RLHF(akin to grooming from human feedback), and finally, Retrieval-Augmented Generation (akin to googling information).
Let’s explore these approaches. One important factor to keep in mind is that no one approach is better than another, it’s the use case in hand that matters.

Mckinsey says that generative AI will improve the productivity of the labor force by automating 30% of work by 2030. But how can this be possible if the contemporary gen AI tools are nothing more than GIGO – garbage in, garbage out?
Hence different approaches to improve the performance of LLM-powered tools are crucial. Let’s explore these approaches one by one.
Approach 1: Fine-Tuning
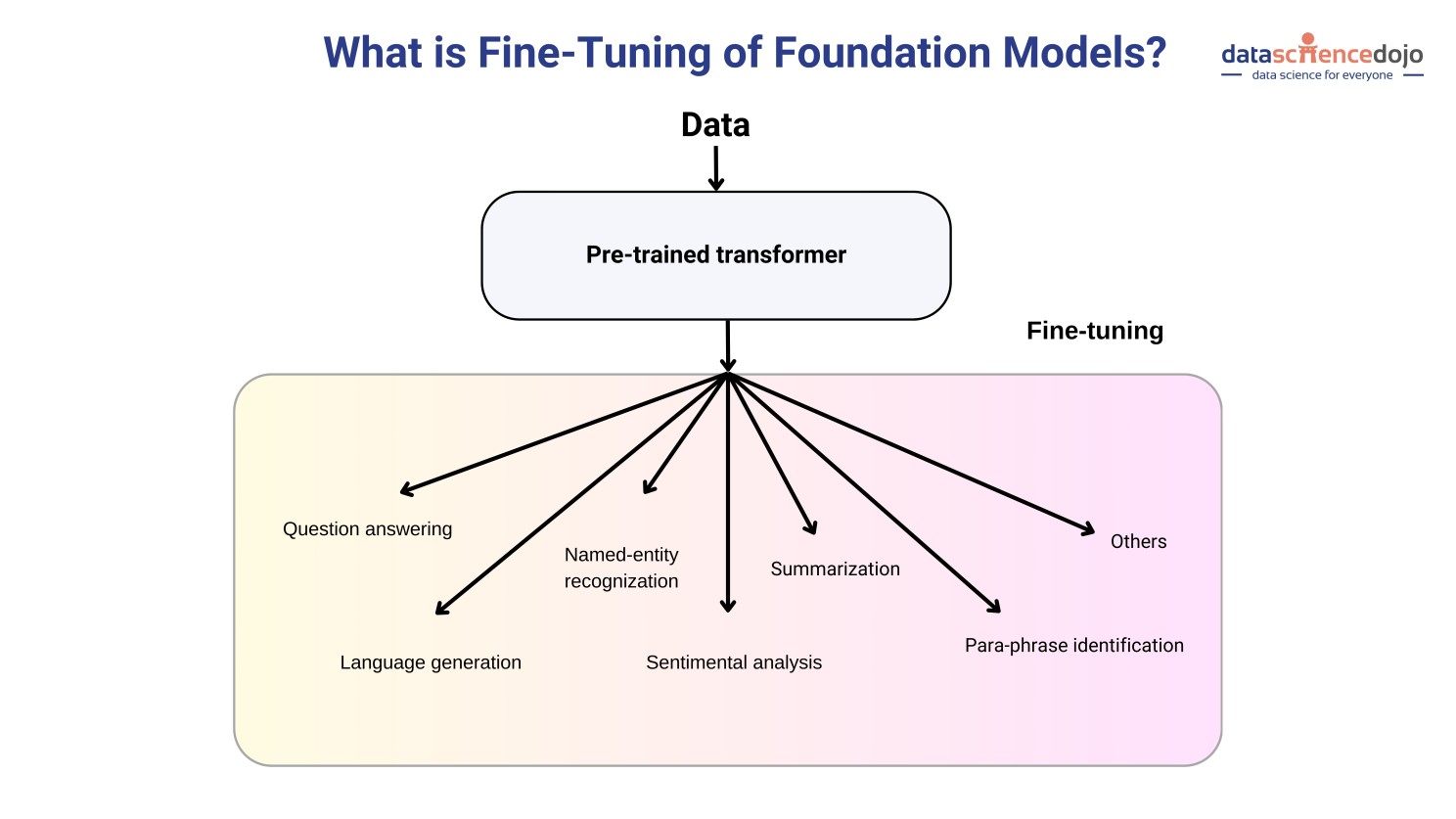
Fine-tuning is a more general process of adjusting a pre-trained model to perform better on a specific task or dataset such as medicine, marketing, etc.
How It Works: The model’s parameters are slightly adjusted to better suit the new data or task. It’s like tweaking a pre-trained model so that it performs better in a new context.
Read: All you need to know about fine-tuning LLMs
Use Cases of Fine-Tuning LLMs:
Models like GPT-3.5 Turbo by OpenAI and Llama 3 by Meta are widely fine-tuned to excel in domain-specific tasks.
Their advanced capabilities, and the efficiency of the fine-tuning process, allow us to tailor models for specific tasks more effectively than ever before. We can use fine-tuned models to create customized chatbots, content creation, sentiment analysis, and more. Watch how to fine-tune Llama 2
Approach 2: Reinforcement Learning from Human Feedback RLHF
RLHF is akin to learning social etiquette, manners, or personal development skills from feedback received from others. It is a specialized form of training where the model is refined based on feedback or corrections from humans.
How It Works: Initially, a user expresses their preferences among different responses provided by the model to the same prompt. For instance, if a user prefers shorter summaries, they would rank such responses higher.
Subsequently, a reward mechanism is established. This system allocates rewards to the model for generating outcomes that align more closely with the user’s stated preferences.
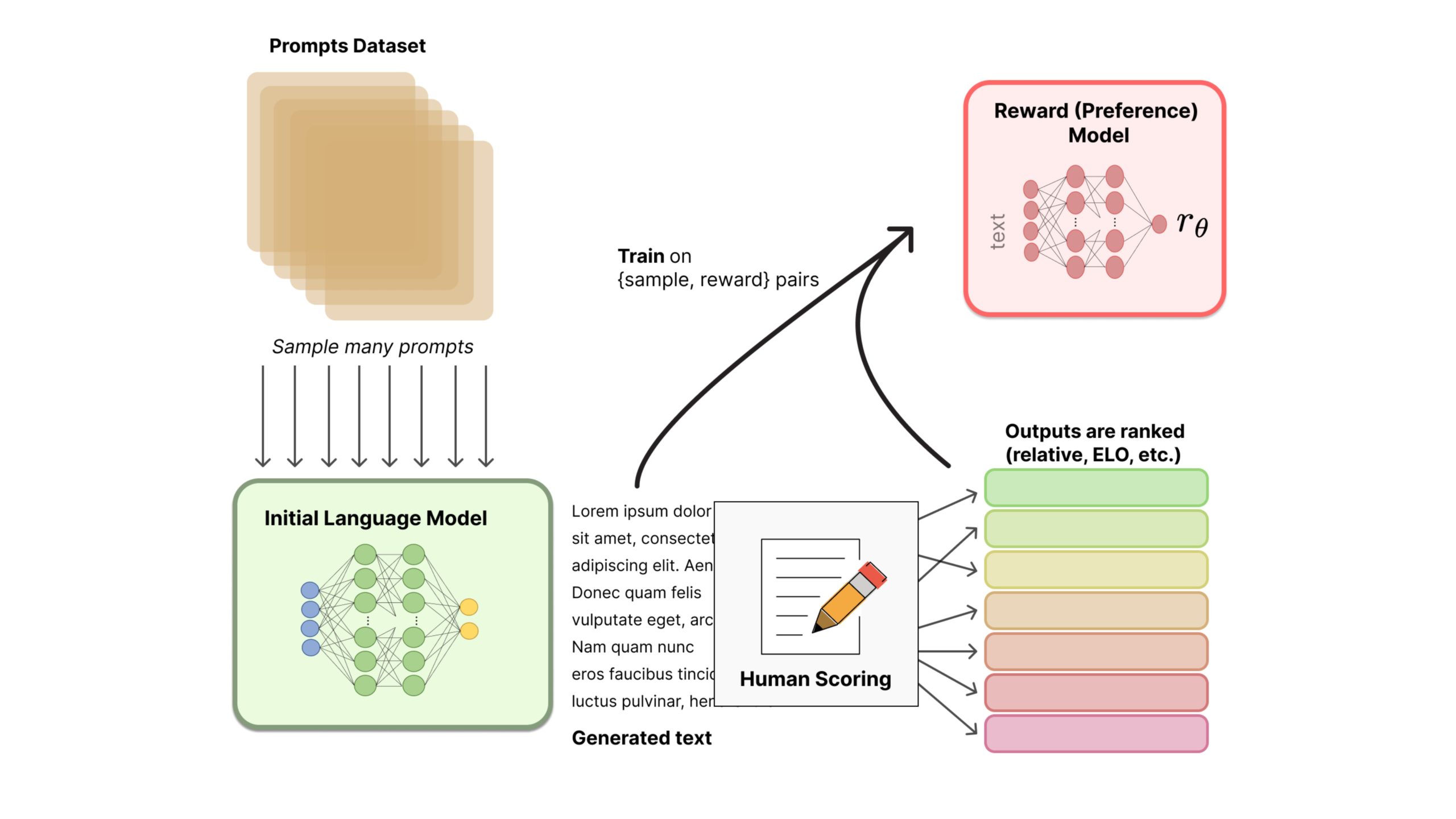
Finally, the model enters a reinforcement learning loop. The objective of this loop is to maximize the rewards by continuously adapting and refining its responses to better match the user’s preferences.
Purpose: This method is particularly focused on aligning the model’s outputs with human values, preferences, ethical guidelines, and desired behaviors.
Use Cases for RLHF:
RLHF is particularly recommended in scenarios where traditional reinforcement learning faces challenges due to complex or subjective goals, or where direct feedback from human interaction is crucial for training the model. This includes decision-making, complex game development, recommendation systems, autonomous vehicles, etc.
Approach 3: Retrieval-Augmented Generation RAG
RAG is a technique that combines the power of a pre-trained language model with a retrieval system, like a search engine. It’s used to improve the model’s ability to provide accurate and relevant information, especially for question-answering tasks, and precisely beat the fear of hallucination at the core.
How It Works: In RAG, when the model receives a query or a prompt, it first uses a retrieval system to fetch relevant documents or data from a large corpus (like Wikipedia or a specialized database). Then, it uses this retrieved information to generate a response.
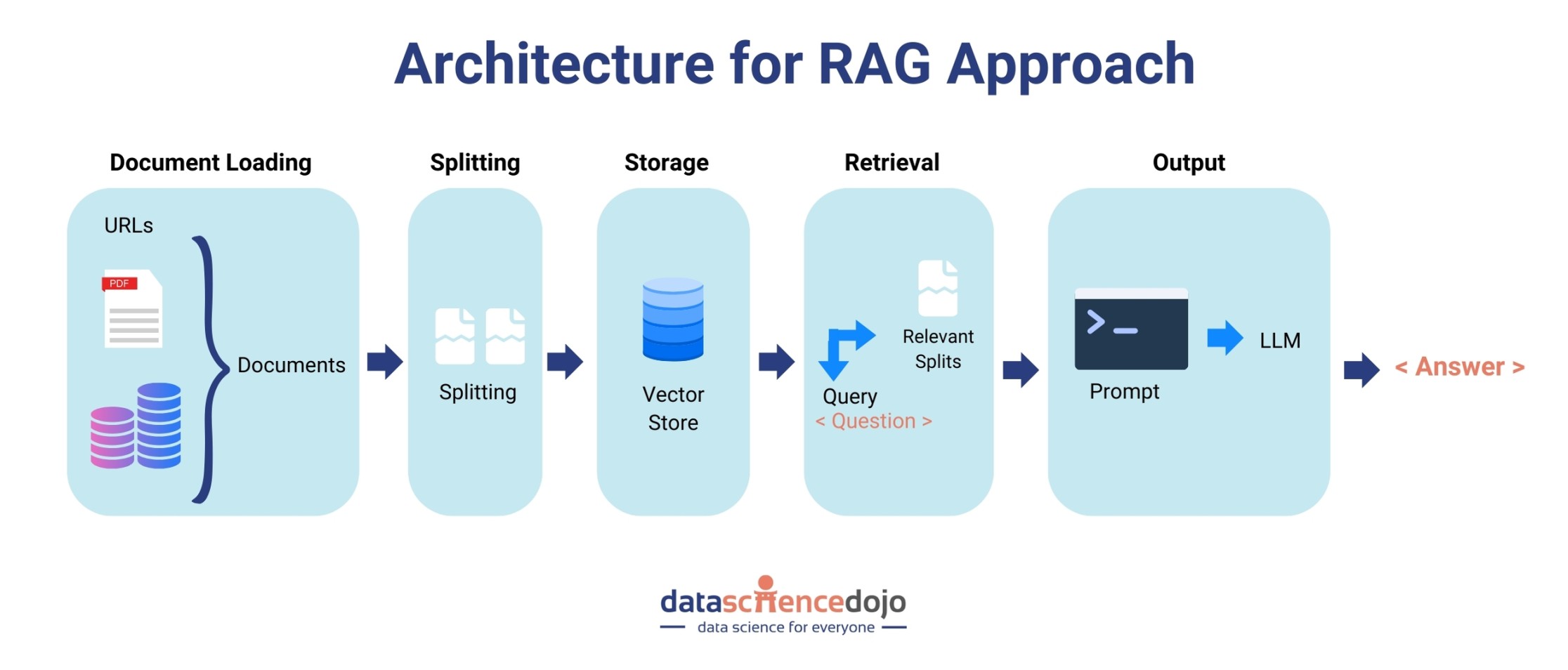
Purpose: The main goal of RAG is to enhance the model’s responses with up-to-date, accurate, and contextually relevant information that may not be contained in its initial training data. Read how to optimize RAG efficiency with Llama Index
Use Cases for RAG:
The RAG approach is recommended where the integration of extensive, diverse information sources with generative capabilities is crucial. This includes question-answering, text completion, text summarization, chatting with custom data, creating agents, and translation

Maximize the Potential of LLMs with RAG – Understand How:
The use of RAG has gained momentum because of how significantly it improves the accuracy of the model. If you want to learn how RAG can be implemented in LLMs, get on this fire-side chat featuring experts including Raja Iqbal, Sam Partee, Taimur Rashid, and Daniel Svonava.
Agreeably, RAG and other approaches do allow us to cater to very crucial issues related to LLMs. However, it must be noted that at the end of the day, challenges related to LLMs are not only technical. There are numerous other issues arising from human behavior, ethical, social, legal, and cultural side.

The atmosphere here seems intense. Let’s lighten the mood with a meme!


Extensive Bootcamp to Build High-Performing Models
Want to get on a journey from good to great? Working with experts will serve you the best. Data Science Dojo’s Large Language Models Bootcamp brings an exciting opportunity to learn how to build end-to-end LLM-powered applications.

If you have any questions about the bootcamp, you can book a meeting with our advisors!

Finally, let’s wrap up the day with some interesting things happening in the AI world.
- Microsoft released its newest small language model, Phi-2: It has 2 billion parameters, and it beats Meta’s Llama-2 and Mistral. Read more
- Google’s launch of Gemini AI was overshadowed by criticism for misleading metrics and questionable demonstration authenticity. Read more
- Google unveils MedLM, a family of healthcare-focused generative AI models. Read more
- Mistral AI introduces Mixtral 8x7B: A powerful sparse mixture-of-experts model, alongside a major funding milestone. Read more
- Google DeepMind used a large language model to solve an unsolvable math problem. Read more