
Welcome to Data Science Dojo’s weekly newsletter, “The Data-Driven Dispatch“.
In our last dispatch, we discussed the basics of Retrieval-Augmented Generation (RAG) and its role in boosting large language model efficiency. Read more
This time, we’re taking things a notch higher.
We’re exploring the nitty-gritty of putting a RAG model to work in LLM applications at an advanced level.
Here’s the deal: crafting a prototype of a RAG application is one thing, but ensuring it runs smoothly, handles a heap of data, and scales up is a whole different ball game.
But it’s more than just getting the setup right. As you roll out your application to more users, the real challenge is to optimize the system for top-notch speed and accuracy.
In this edition, we’ll dig into the typical hurdles that hold back RAG-based LLM applications from hitting their stride, along with some clever fixes to get past these roadblocks.

Breaking Down The RAG Model into “R”, “A”, & “G”
From data ingestion to response generation, your inner workings have to be robust. Overlooking even a minor aspect could significantly compromise its performance, and you’d practically miss the opportunity to satisfy the users.
To understand the challenges clearly, we will divide the challenges into the three main stages of the RAG pipeline.
- Data Ingestion
- Retrieval
- Generation

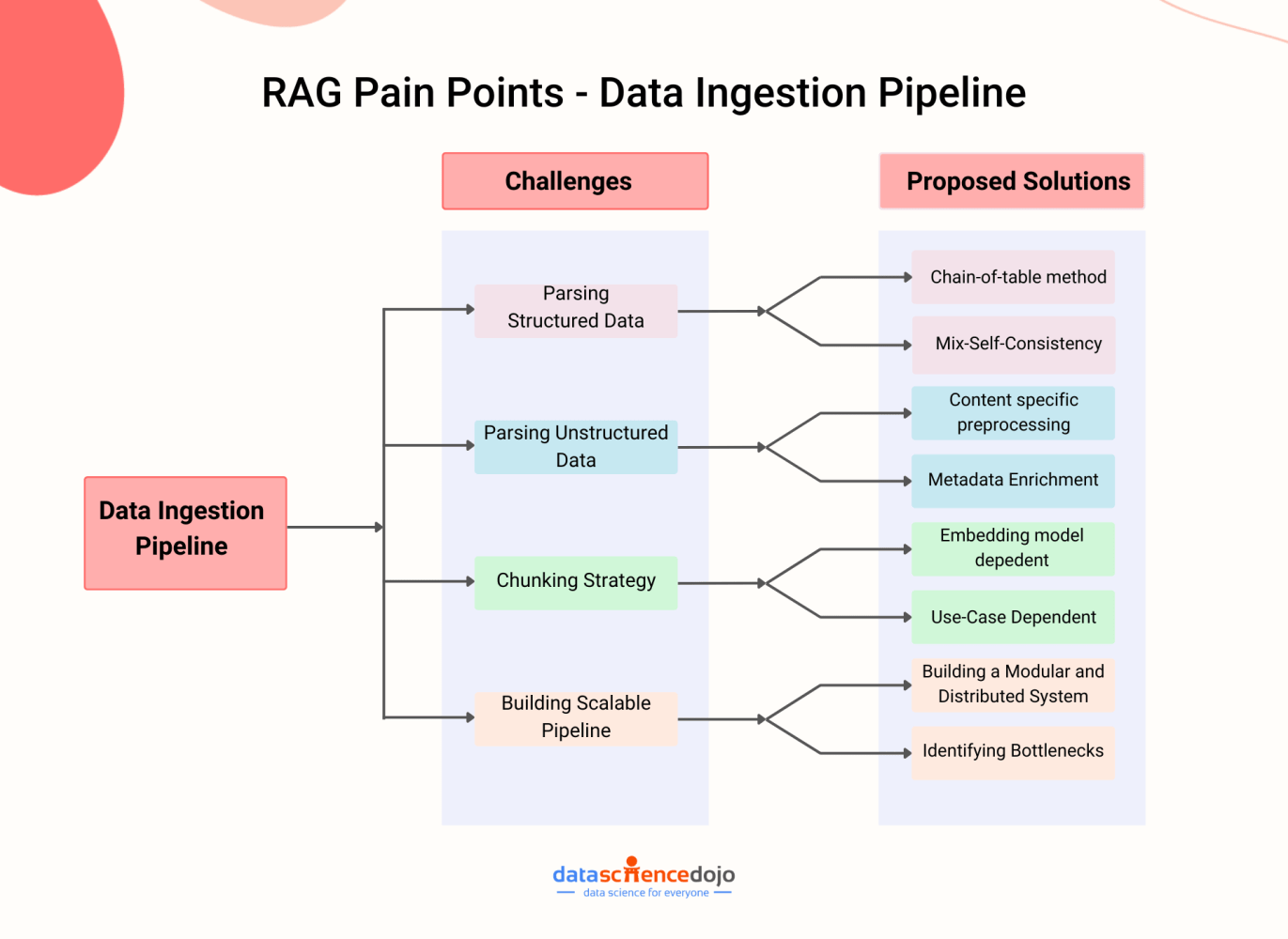
Stage 1 – Data Ingestion Pipeline:
The ingestion stage is a preparation step for building a RAG pipeline, similar to the data cleaning and preprocessing steps in a machine learning pipeline.
The efficiency and effectiveness of the data ingestion phase significantly influence the overall performance of the system.
Here are some common challenges faced during the data ingestion stage and how you can fix them.
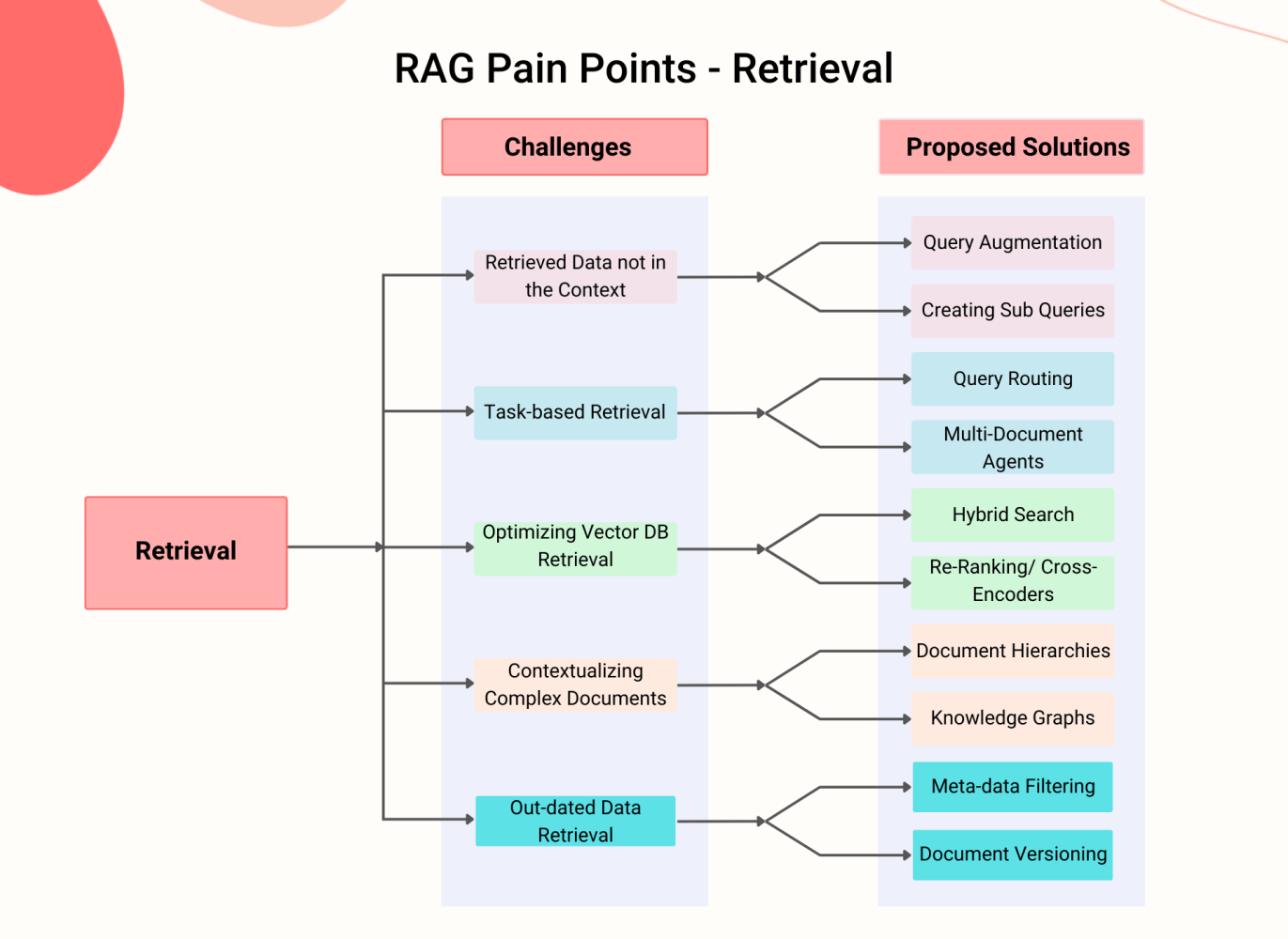
Stage 2 – Retrieval
The retrieval stage involves the process of accessing and extracting information from external knowledge sources, such as databases, documents, and knowledge graphs.
If the information is retrieved accurately and in the right format, then the responses generated will be correct as well.
However, you know the catch. Effective retrieval is a pain, and you can encounter several issues during this important stage.
Read more: Optimize RAG Efficiency with LlamaIndex
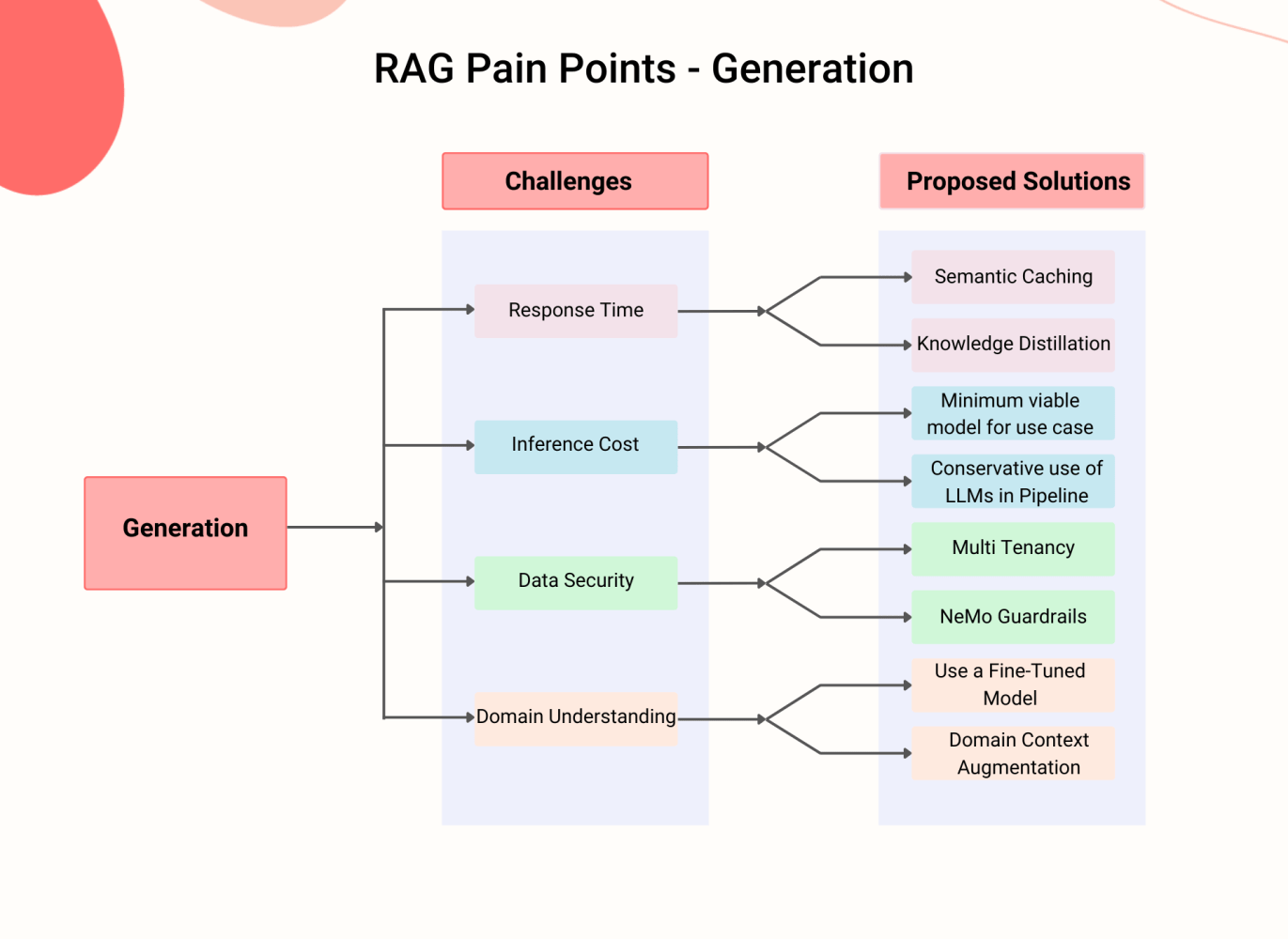
Stage 3 – Generation:
The generation stage is critical, where the system produces responses.
It’s essential that these responses are not only accurate and in the correct format but also generated with efficiency, minimizing both time and computational resources.
In essence, each step of the RAG Pipeline, from data preparation through to response generation, must be executed with precision and efficiency.
This ensures the system operates robustly, delivering accurate and timely results while optimizing resource usage.
Interesting Read: RAG vs finetuning: Which is the best tool for optimized LLM performance?

Live Talk Coming Up: 10 Challenges in Building RAG-Based LLM Applications
Getting practitioner’s insights is one of the best ways to learn. Here’s your chance to learn from industry expert, Raja Iqbal, Founder of Data Science Dojo.
Raja’s been collaborating with exceptional teams to craft impactful RAG-enhanced Large Language Model applications.

To join us live, get your slot booked!
Hear It From the RAG-Guru Himself: LlamaIndex Founder, Jerry Liu
The most awaited podcast of the season is here. To answer all of your questions about Fine-tuning Vs. retrieval-augmented generation, LlamaIndex Vs. LangChain, and more, we had the privilege to have Jerry Liu, CEO at LlamaIndex at our podcast, Future of Data and AI. He shared his insights on some burning questions in the LLM world.
Subscribe to our podcast on Spotify and stay in the loop with conversations from the front lines of LLM innovation!

You just learned about the coolest tech of our time! Time for a chill pill.



Live Course: Mastering LangChain for RAG Applications
LangChain stands as a premier framework for implementing the RAG model in LLM applications. For those aiming to excel in LangChain, we present a comprehensive course that bridges theory and practice, delivered by seasoned experts with extensive experience in developing LLM applications.
Learn more about the curriculum and the instructors here.

Finally, let’s end the week with some interesting news in the AI-verse.
- OpenAI is tipped to become the first privately held trillion-dollar startup. Read more
- Apple announces its big annual conference, where it could reveal its AI strategy. Read more
- Nvidia Unveils Earth-2 for Advanced Climate Predictions. Read more
- Google will now let you use AI to build travel itineraries for your vacations. Read more
- Sakana AI Unveils Technique for Faster, Cheaper Generative Model Creation. Read more
Until we meet again, take care!