Large language models hold the promise of transforming multiple industries, but they come with a set of potential risks. These risks of large language models include subjectivity, bias, prompt vulnerabilities, and more.
In this blog, we’ll explore these challenges and present best practices to mitigate them, covering the use of guardrails, defensive UX design, LLM caching, user feedback, and data selection for fair and equitable results. Join us as we navigate the landscape of responsible LLM deployment.
Key Challenges of Large Language Models
While LLMs are impressive in many ways, they come with significant challenges that can’t be ignored.
LLMs are trained on massive amounts of text and code, but that does not mean they always generate content that’s useful or relevant to everyone. Since different people have different perspectives, cultural backgrounds, and needs, LLMs lack true human understanding.
As a result, their responses may feel off, misaligned, or even completely irrelevant, especially when dealing with subjective topics like opinions, ethics, or personal preferences.
Bias Arising from Reinforcement Learning from Human Feedback (RHLF)
Many LLMs rely on Reinforcement Learning from Human Feedback (RLHF) to fine-tune their responses. The catch, however, is that human feedback is not perfect since it can be biased. This can lead to responses that favor certain viewpoints, reinforce stereotypes, or unintentionally discriminate against certain groups.
As a result, LLMs learn biased policies, reiterating those concepts rather than providing neutral, fair, or balanced perspectives.
Imagine asking an LLM a simple question, and it accidentally reveals parts of its internal instructions or system prompts. This is called prompt leaking and poses a serious risk. It occurs when an LLM reveals its internal prompt or instructions to the user.
Attackers can exploit this weakness to extract information about how the model works or uncover sensitive data that should not be accessible. In security-sensitive applications, this could expose proprietary business logic or confidential user information.
Prompt Injection: The AI Hackers’ Trick
What if someone could trick an LLM into doing something it wasn’t designed to do? It is called prompt injection, where an attacker can inject malicious code into an LLM’s prompt.
It can cause an LLM to generate harmful or misleading content and bypass safety filters. It is one of the biggest challenges in ensuring that LLMs remain secure and trustworthy.
Jailbreaks: Bypassing AI’s Safety Barriers
A jailbreak is a successful attempt to trick an LLM into generating harmful or unexpected content. This can be done by providing the LLM with carefully crafted prompts or by exploiting vulnerabilities in the LLM’s code. A jailbreak occurs when someone finds a way to override an LLM’s built-in restrictions.
Skilled attackers can craft clever prompts that push the model past its safety limits. This can have serious consequences, such as spreading misinformation or generating dangerous advice.
Inference Costs
Inference cost is the cost of running a language model to generate text. It is driven by several factors, including the size, the complexity of the task, and the hardware used to run the model. LLMs are typically very large and complex models, which means that they require a lot of computational resources to run.
Hence, every time you generate text, the model requires powerful hardware, cloud resources, and electricity, adding up to high costs for businesses. These expenses can make large-scale AI adoption challenging, particularly for smaller companies that can’t afford the hefty price tag of running state-of-the-art LLMs.
Curious about LLMs, their risks, and how they are reshaping the future? Tune in to our Future of Data and AI podcast now!
Quick Quiz
Test your knowledge of large language models
Hallucinations
LLMs hallucinate when they generate false information while sounding factual. There are several factors that can contribute to hallucinations in LLMs, including the limited contextual understanding of LLMs, noise in the training data, and the complexity of the task.
When pushed too far, LLMs may fabricate facts, citations, or research, leading to misinformation in critical fields. Other potential risks of LLMs include privacy violations and copyright infringement. These are serious problems that companies need to be aware of before implementing LLMs.
Listen to this talk to understand how these challenges plague users as well as pose a significant threat to society.
Thankfully, there are several measures that can be taken to overcome these challenges.
Best Practices to Mitigate These Challenges
Here are some best practices that can be followed to overcome the potential risks of LLMs.
1. Using Guardrails
Guardrails are technical mechanisms that can be used to prevent large language models from generating harmful or unexpected content. For example, guardrails can be used to prevent LLMs from generating content that is biased, offensive, or inaccurate.
Guardrails can be implemented in a variety of ways. For example, one common approach is to use blacklists and whitelists. Blacklists are lists of words and phrases that a language model is prohibited from generating. Whitelists are lists of words and phrases that the large language model is encouraged to generate.
Another approach to guardrails is to use filters. Filters can be used to detect and remove harmful content from the model’s output. For example, a filter could be used to detect and remove hate speech from the LLM’s output.
2. Defensive UX
Defensive UX is a design approach that can be used to make it difficult for users to misuse LLMs. For example, defensive UX can be used to make it clear to users that LLMs are still under development and that their output should not be taken as definitive.
One way to implement defensive UX is to use warnings and disclaimers. For example, a warning could be displayed to users before they interact with it, informing them of the limitations of large language models and the potential for bias and error.
Another way to implement defensive UX is to provide users with feedback mechanisms. For example, a feedback mechanism could allow users to report harmful or biased content to the developers of the LLM.
3. Using LLM Caching
LLM caching reduces the risk of prompt leakage by isolating user sessions and temporarily storing interactions within a session, enabling the model to maintain context and improve conversation flow without revealing specific user details.
This improves efficiency, limits exposure to cached data, and reduces unintended prompt leakage. However, it’s crucial to exercise caution to protect sensitive information and ensure data privacy when using large language models.
4. User Feedback
User feedback can be used to identify and mitigate bias in LLMs. It can also be used to improve the relevance of LLM-generated content. One way to collect user feedback is to survey users after they have interacted with an LLM. The survey could ask users to rate the quality of the LLM’s output and identify any biases or errors.
Another way to collect user feedback is to allow users to provide feedback directly to the developers of the LLM. This feedback could be provided via a feedback form or a support ticket.
5. Using Data that Promotes Fairness and Equality
It is of paramount importance for machine learning models, particularly Large Language Models, to be trained on data that is both credible and advocates fairness and equality. Credible data ensures the accuracy and reliability of model-generated information, safeguarding against the spread of false or misleading content.
To do so, training on data that upholds fairness and equality is essential to minimize biases within LLMs, preventing the generation of discriminatory or harmful outputs, promoting ethical responsibility, and adhering to legal and regulatory requirements.
Overcome the Risks of Large Language Models
In conclusion, LLMs offer immense potential but come with inherent risks, including subjectivity, bias, prompt vulnerabilities, and more. This blog has explored these challenges and provided a set of best practices to mitigate them.
These practices encompass implementing guardrails to prevent harmful content, utilizing defensive user experience (UX) design to educate users and provide feedback mechanisms, employing LLM caching to enhance user privacy, collecting user feedback to identify and rectify bias, and, most crucially, training LLMs on data that champions fairness and equality.
By following these best practices, we can navigate the landscape of responsible LLM deployment, promote ethical AI development, and reduce the societal impact of biased or unfair AI systems.
If you’re interested to learn large language models (LLMs), you’re in the right place. LLMs are all the rage these days, and for good reason. They’re incredibly powerful tools that can be used to do a wide range of things, from generating text to translating languages to writing code.
LLMs can be used to build a variety of applications, such as chatbots, virtual assistants, and translation tools. They can also be used to improve the performance of existing NLP tasks, such as text summarization and machine translation.
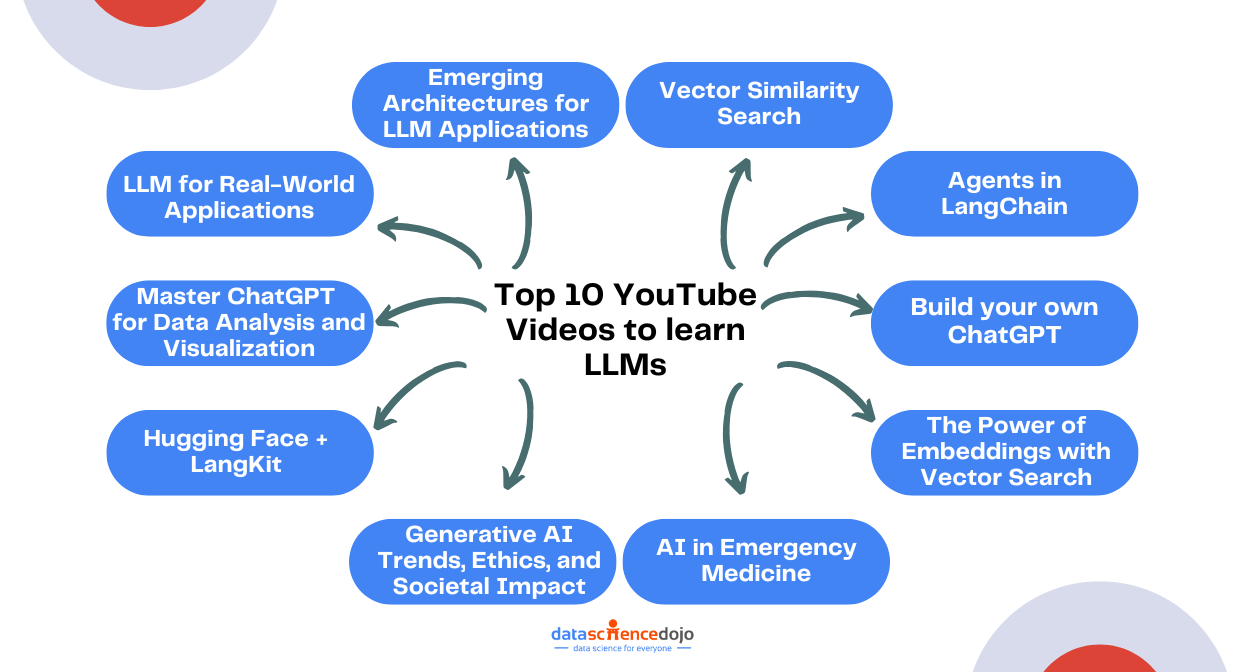
In this blog post, we are going to share the top 10 YouTube videos for learning about LLMs. These videos cover everything from the basics of how LLMs work to how to build and deploy your own LLM. Experts in the field teach these concepts, giving you the assurance of receiving the latest information.
1. LLM for Real-World Applications
Custom LLMs are trained on your specific data. This means that they can be tailored to your specific needs. For example, you could train a custom LLM on your customer data to improve your customer service experience.
LLMs are a powerful tool that can be used to improve your business in a number of ways. If you’re not already using LLMs in your business, I encourage you to check out the video above to learn more about their potential applications.
In this video, you will learn about the following:
What are LLMs and how do they work?
What are the different types of LLMs?
What are some of the real-world applications of LLMs?
How can you get started with using LLMs in your own work?
2. Emerging Architectures for LLM Applications
In this video, you will learn about the latest approaches to building custom LLM applications. This means that you can build an LLM that is tailored to your specific needs. You will also learn about the different tools and technologies that are available, such as LangChain.
Applications like Bard, ChatGPT, Midjourney, and DallE have entered some applications like content generation and summarization. However, there are inherent challenges for a lot of tasks that require a deeper understanding of trade-offs like latency, accuracy, and consistency of responses.
Any serious applications of LLMs require an understanding of nuances in how LLMs work, embeddings, vector databases, retrieval augmented generation (RAG), orchestration frameworks, and more.
In this video, you will focus on these questions to learn large language models.
What are the challenges of using LLMs in real-world applications?
What are some of the emerging architectures for LLM applications?
How can these architectures be used to overcome the challenges of using LLMs in real-world applications?
3. Vector Similarity Search
This video explains what vector databases are and how they can be used for vector similarity searches. Vector databases are a type of database that stores data in the form of vectors. Vectors are mathematical objects that represent the direction and magnitude of a force or quantity.
A vector similarity search is the process of finding similar vectors in a vector database. Vector similarity search can be used for a variety of tasks, such as image retrieval, text search, and recommendation systems.
In this video, you will learn about the following:
What are vector databases?
What is vector similarity search?
How can vector databases be used for vector similarity searches?
What are some of the benefits of using vector databases for vector similarity searches?
This video explains what LangChain agents are and how they can be used to build AI applications. LangChain agents are a type of artificial intelligence that can be used to build AI applications. They are based on large language models (LLMs), which are a type of artificial intelligence that can generate and understand human language.
In this video, you will learn about the following:
What are LangChain agents?
How can LangChain agents be used to build AI applications?
What are some of the benefits of using LangChain agents to build AI applications?
5. Build your own ChatGPT
This video shows how to use the ChatGPT API to build your own AI application. ChatGPT is a large language model (LLM) that can be used to generate text, translate languages, and answer questions in an informative way.
In this video, you will learn about the following:
What is the ChatGPT API?
How can the ChatGPT API be used to build AI applications?
What are some of the benefits of using the ChatGPT API to build AI applications?
6. The Power of Embeddings with Vector Search
Embeddings are a powerful tool for representing data in an easy-to-understand way for machine learning algorithms. Vector search is a technique for finding similar vectors in a database. Together, embeddings and vector search can be used to solve a wide range of problems, such as image retrieval, text search, and recommendation systems.
Key learning outcomes:
What are embeddings and how do they work?
What is vector search and how is it used?
How can embeddings and vector search be used to solve real-world problems?
7. AI in Emergency Medicine
Artificial intelligence (AI) is rapidly transforming the field of emergency medicine. AI is being used to develop new diagnostic tools, improve the efficiency of care delivery, and even predict patient outcomes.
Key learning outcomes:
What are the latest advances in AI in emergency medicine?
How is AI being used to improve patient care?
What are the challenges and opportunities of using AI in emergency medicine?
8. Generative AI Trends, Ethics, and Societal Impact
Generative AI is a type of AI that can create new content, such as text, images, and music. Generative AI is rapidly evolving and has the potential to revolutionize many industries. However, it also raises important ethical and societal questions.
Key learning outcomes:
What are the latest trends in generative AI?
What are the potential benefits and risks of generative AI?
How can we ensure that generative AI is used responsibly and ethically?
9. Hugging Face + LangKit
Hugging Face and LangKit are two popular open-source libraries for natural language processing (NLP). Hugging Face provides a variety of pre-trained NLP models, while LangKit provides a set of tools for training and deploying NLP models.
Key learning outcomes:
What are Hugging Face and LangKit?
How can Hugging Face and LangKit be used to build NLP applications?
What are some of the benefits of using Hugging Face and LangKit?
10. Master ChatGPT for Data Analysis and Visualization!
ChatGPT is a large language model that can be used for a variety of tasks, including data analysis and visualization. In this video, you will learn how to use ChatGPT to perform common data analysis tasks, such as data cleaning, data exploration, and data visualization.
Key learning outcomes:
How to use ChatGPT to perform data analysis tasks
How to use ChatGPT to create data visualizations
How to use ChatGPT to communicate your data findings
These are the major outcomes of learning large language models.
Final Words
LLMs can help you build your own large language models, like ChatGPT. They can also help you use custom language models to grow your business. For example, you can use custom language models to improve customer service, develop new products and services, automate marketing and sales tasks, and improve the quality of your content.
So, what are you waiting for? Start learning about LLMs today!
Unlocking the potential of large language models like GPT-4 reveals a Pandora’s box of privacy concerns. Unintended data leaks sound the alarm, demanding stricter privacy measures.
Generative Artificial Intelligence (AI) has garnered significant interest, with users considering its application in critical domains such as financial planning and medical advice. However, this excitement raises a crucial question:
Can we truly trust these large language models (LLMs)?
Sanmi Koyejo and Bo Li, experts in computer science, delve into this question through their research, evaluating GPT-3.5 and GPT-4 models for trustworthiness across multiple perspectives.
Koyejo and Li’s study takes a comprehensive look at eight trust perspectives: toxicity, stereotype bias, adversarial robustness, out-of-distribution robustness, robustness on adversarial demonstrations, privacy, machine ethics, and fairness. While the newer models exhibit reduced toxicity on standard benchmarks, the researchers find that they can still be influenced to generate toxic and biased outputs, highlighting the need for caution in sensitive areas.
The illusion of perfection
Contrary to the common perception of LLMs as flawless and capable, the research underscores their vulnerabilities. These models, such as GPT-3.5 and GPT-4, though capable of extraordinary feats like natural conversations, fall short of the trust required for critical decision-making. Koyejo emphasizes the importance of recognizing these models as machine learning systems with inherent vulnerabilities, emphasizing that expectations need to align with the current reality of AI capabilities.
Unveiling the black box: Understanding the inner workings
A critical challenge in the realm of artificial intelligence is the enigmatic nature of model training, a conundrum that Koyejo and Li’s evaluation brought to light. They shed light on the lack of transparency in the training processes of AI models, particularly emphasizing the opacity surrounding popular models.
Many of these models are proprietary and concealed in a shroud of secrecy, leaving researchers and users grappling to comprehend their intricate inner workings. This lack of transparency poses a significant hurdle in understanding and analyzing these models comprehensively.
To tackle this issue, the study adopted the approach of a “Red Team,” mimicking a potential adversary. By stress-testing the models, the researchers aimed to unravel potential pitfalls and vulnerabilities. This proactive initiative provided invaluable insights into areas where these models could falter or be susceptible to malicious manipulation. It also underscored the necessity for greater transparency and openness in the development and deployment of AI models.
Toxicity and adversarial prompts
One of the key findings of the study pertained to the levels of toxicity exhibited by GPT-3.5 and GPT-4 under different prompts. When presented with benign prompts, these models showed a significant reduction in toxic outputs, indicating a degree of control and restraint. However, a startling revelation emerged when the models were subjected to adversarial prompts – their toxicity probability surged to an alarming 100%.
This dramatic escalation in toxicity under adversarial conditions raises a red flag regarding the model’s susceptibility to malicious manipulation. It underscores the critical need for vigilant monitoring and cautious utilization of AI models, particularly in contexts where toxic outputs could have severe real-world consequences.
Additionally, this finding highlights the importance of ongoing research to devise mechanisms that can effectively mitigate toxicity, making these AI systems safer and more reliable for users and society at large.
Bias and privacy concerns
Addressing bias in AI systems is an ongoing challenge, and despite efforts to reduce biases in GPT-4, the study uncovered persistent biases towards specific stereotypes. These biases can have significant implications in various applications where the model is deployed. The danger lies in perpetuating harmful societal prejudices and reinforcing discriminatory behaviors.
Furthermore, privacy concerns have emerged as a critical issue associated with GPT models. Both GPT-3.5 and GPT-4 have been shown to inadvertently leak sensitive training data, raising red flags about the privacy of individuals whose data is used to train these models. This leakage of information can encompass a wide range of private data, including but not limited to email addresses and potentially even more sensitive information like Social Security numbers.
The study’s revelations emphasize the pressing need for ongoing research and development to effectively mitigate biases and improve privacy measures in AI systems like GPT-4. Developers and researchers must work collaboratively to identify and rectify biases, ensuring that AI models are more inclusive and representative of diverse perspectives.
To enhance privacy, it is crucial to implement stricter controls on data usage and storage during the training and usage of these models. Stringent protocols should be established to safeguard against the inadvertent leaking of sensitive information. This involves not only technical solutions but also ethical considerations in the development and deployment of AI technologies.
Fairness in predictions
The assessment of GPT-4 revealed worrisome biases in the model’s predictions, particularly concerning gender and race. These biases highlight disparities in how the model perceives and interprets different attributes of individuals, potentially leading to unfair and discriminatory outcomes in applications that utilize these predictions.
In the context of gender and race, the biases uncovered in the model’s predictions can perpetuate harmful stereotypes and reinforce societal inequalities. For instance, if the model consistently predicts higher incomes for certain genders or races, it could inadvertently reinforce existing biases related to income disparities.
The study underscores the importance of ongoing research and vigilance to ensure fairness in AI predictions. Fairness assessments should be an integral part of the development and evaluation of AI models, particularly when these models are deployed in critical decision-making processes. This includes a continuous evaluation of the model’s performance across various demographic groups to identify and rectify biases.
Moreover, it’s crucial to promote diversity and inclusivity within the teams developing these AI models. A diverse team can provide a range of perspectives and insights necessary to address biases effectively and create AI systems that are fair and equitable for all users.
Conclusion: Balancing potential with caution
Koyejo and Li acknowledge the progress seen in GPT-4 compared to GPT-3.5 but caution against unfounded trust. They emphasize the ease with which these models can generate problematic content and stress the need for vigilant, human oversight, especially in sensitive contexts. Ongoing research and third-party risk assessments will be crucial in guiding the responsible use of generative AI. Maintaining a healthy skepticism, even as the technology evolves, is paramount.
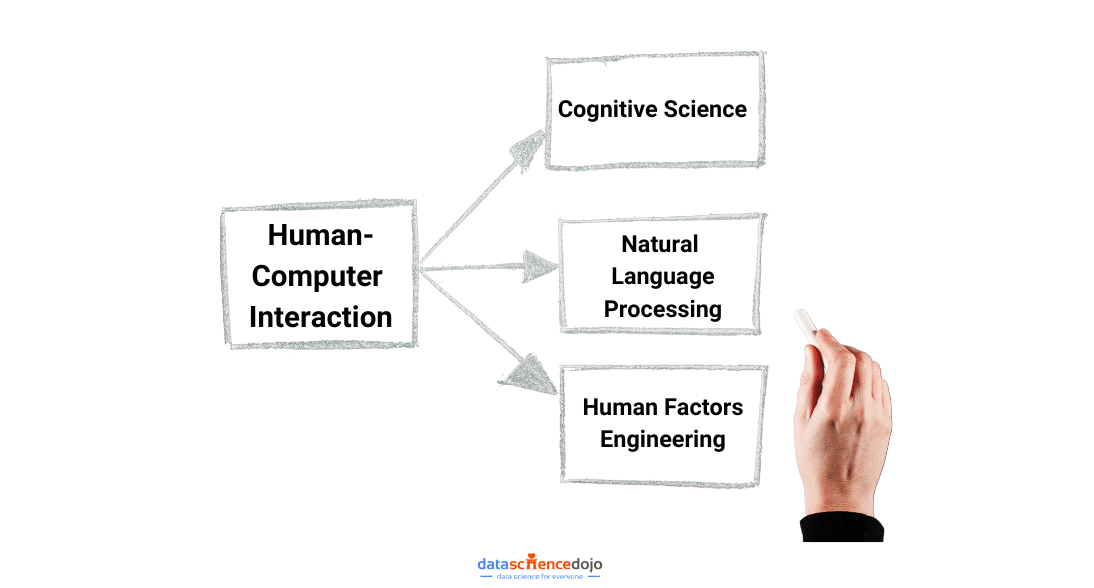
Ever talked to a computer and felt like it really got you? That’s the magic of human-computer interaction powered by Large Language Models (LLMs). These advanced AIs, like GPT-3, can chat, answer questions, and even write stories that sound almost human.
But while it all seems amazing, there’s more to the story. How do these models actually work? And what challenges come with using them in our everyday lives?
In this blog, we’ll dive into how LLMs are changing the way we interact with computers, making conversations smoother and smarter — and we’ll also explore some of the tricky parts that come with this powerful technology.
Human-Computer Interaction: How LLMs Master Language at Scale?
At their core, LLMs are intricate neural networks engineered to comprehend and craft human language on an extraordinary scale. These colossal models ingest vast and diverse datasets, spanning literature, news, and social media dialogues from the internet.
Their primary mission? Predicting the next word or token in a sentence based on the preceding context. Through this predictive prowess, they acquire grammar, syntax, and semantic acumen, enabling them to generate coherent, contextually fitting text.
This training hinges on countless neural network parameter adjustments, fine-tuning their knack for spotting patterns and associations within the data.
Challenges of Large Language Models
Consequently, when prompted with text, these models draw upon their immense knowledge to produce human-like responses, serving diverse applications from language understanding to content creation. Yet, such incredible power also raises valid concerns deserving closer scrutiny.
Ethical Concerns Surrounding Large Language Models:
Large Language Models (LLMs) like GPT-3 have raised numerous ethical and social implications that need careful consideration.
These transformative AI systems, while undeniably powerful, have cast a spotlight on a spectrum of concerns that extend beyond their technical capabilities. Here are some of the key concerns:
1. Bias and Fairness:
LLMs are often trained on large datasets that may contain biases present in the text. This can lead to models generating biased or unfair content. Addressing and mitigating bias in LLMs is a critical concern, especially when these models are used in applications that impact people’s lives, such as in hiring processes or legal contexts.
In 2016, Microsoft launched a chatbot called Tay on Twitter. Tay was designed to learn from its interactions with users and become more human-like over time. However, within hours of being launched, Tay was flooded with racist and sexist language. As a result, Tay began to repeat this language, and Microsoft was forced to take it offline.
LLMs can generate highly convincing fake news, disinformation, and propaganda. One of the gravest concerns surrounding the deployment of Large Language Models (LLMs) lies in their capacity to produce exceptionally persuasive counterfeit news articles, disinformation, and propaganda.
These AI systems possess the capability to fabricate text that closely mirrors the style, tone, and formatting of legitimate news reports, official statements, or credible sources. This issue was brought forward in this research.
3. Dependency and Deskilling:
Excessive reliance on Large Language Models (LLMs) for various tasks presents multifaceted concerns, including the erosion of critical human skills. Overdependence on AI-generated content may diminish individuals’ capacity to perform tasks independently and reduce their adaptability in the face of new challenges.
In scenarios where LLMs are employed as decision-making aids, there’s a risk that individuals may become overly dependent on AI recommendations. This can impair their problem-solving abilities, as they may opt for AI-generated solutions without fully understanding the underlying rationale or engaging in critical analysis.
4. Privacy and Security Threats:
Large Language Models (LLMs) pose significant privacy and security threats due to their capacity to inadvertently leak sensitive information, profile individuals, and re-identify anonymized data. They can be exploited for data manipulation, social engineering, and impersonation, leading to privacy breaches, cyberattacks, and the spread of false information.
LLMs enable the generation of malicious content, automation of cyberattacks, and obfuscation of malicious code, elevating cybersecurity risks. Addressing these threats requires a combination of data protection measures, cybersecurity protocols, user education, and responsible AI development practices to ensure the responsible and secure use of LLMs.
5. Lack of Accountability:
The lack of accountability in the context of Large Language Models (LLMs) arises from the inherent challenge of determining responsibility for the content they generate. This issue carries significant implications, particularly within legal and ethical domains.
When AI-generated content is involved in legal disputes, it becomes difficult to assign liability or establish an accountable party, which can complicate legal proceedings and hinder the pursuit of justice.
Moreover, in ethical contexts, the absence of clear accountability mechanisms raises concerns about the responsible use of AI, potentially enabling malicious or unethical actions without clear repercussions.
Thus, addressing this accountability gap is essential to ensure transparency, fairness, and ethical standards in the development and deployment of LLMs.
6. Filter Bubbles and Echo Chambers:
Large Language Models (LLMs) contribute to filtering bubbles and echo chambers by generating content that aligns with users’ existing beliefs, limiting exposure to diverse viewpoints.
This can hinder healthy public discourse by isolating individuals within their preferred information bubbles and reducing engagement with opposing perspectives, posing challenges to shared understanding and constructive debate in society.
Navigating the Solutions: Mitigating Flaws in Large Language Models
As we delve deeper into the world of AI and language technology, it’s crucial to confront the challenges posed by Large Language Models (LLMs). In this section, we’ll explore innovative solutions and practical approaches to address the flaws we discussed.
Our goal is to harness the potential of LLMs while safeguarding against their negative impacts. Let’s dive into these solutions for responsible and impactful use.
1. Set Clear Ethical Guidelines:
Establish comprehensive and ongoing bias audits of LLMs during development. This involves reviewing training data for biases, diversifying training datasets, and implementing algorithms that reduce biased outputs. Include diverse perspectives in AI ethics and development teams and promote transparency in the fine-tuning process.
Guardrails AI can enforce policies designed to mitigate bias in LLMs by establishing predefined fairness thresholds. For example, it can restrict the model from generating content that includes discriminatory language or perpetuates stereotypes. It can also encourage the use of inclusive and neutral language.
Guardrails serve as a proactive layer of oversight and control, enabling real-time intervention and promoting responsible, unbiased behavior in LLMs.
Develop and promote robust fact-checking tools and platforms to counter misinformation. Encourage responsible content generation practices by users and platforms. Collaborate with organizations that specialize in identifying and addressing misinformation.
Enhance media literacy and critical thinking education to help individuals identify and evaluate credible sources.
Additionally, Guardrails can combat misinformation in Large Language Models (LLMs) by implementing real-time fact-checking algorithms that flag potentially false or misleading information, restricting the dissemination of such content without additional verification.
These guardrails work in tandem with the LLM, allowing for the immediate detection and prevention of misinformation, thereby enhancing the model’s trustworthiness and reliability in generating accurate information.
3. Promote Human-AI Collaboration:
To address dependency and deskilling caused by over-reliance on AI systems, it’s essential to promote human-AI collaboration that augments human abilities rather than replacing them. This means positioning AI, including LLMs, as a supportive tool that empowers users to be more productive, creative, and efficient, rather than making them passive recipients of AI-generated outputs.
Organizations should invest in lifelong learning and reskilling programs to help individuals adapt to the rapid advancements in AI. These programs can equip users with the skills to critically engage with AI tools, ensuring they retain essential decision-making and problem-solving capabilities.
Additionally, fostering a culture of responsible AI use is crucial. Users should be encouraged to view AI as an enhancement tool—a partner in their tasks—rather than a complete solution. This mindset shift can help prevent skill degradation and maintain human agency in decision-making processes.
4. Strengthening Data Privacy & AI Security:
Strengthen data anonymization techniques to protect sensitive information. Implement robust cybersecurity measures to safeguard against AI-generated threats. Developing and adhering to ethical AI development standards to ensure privacy and security are paramount considerations.
Moreover, Guardrails can enhance privacy and security in Large Language Models (LLMs) by enforcing strict data anonymization techniques during model operation, implementing robust cybersecurity measures to safeguard against AI-generated threats, and educating users on recognizing and handling AI-generated content that may pose security risks.
These guardrails provide continuous monitoring and protection, ensuring that LLMs prioritize data privacy and security in their interactions, contributing to a safer and more secure AI ecosystem.
5. Enforcing AI Accountability:
Establish clear legal frameworks for AI accountability, addressing issues of responsibility and liability. Develop digital signatures and metadata for AI-generated content to trace sources.
Promote transparency in AI development by documenting processes and decisions. Encourage industry-wide standards for accountability in AI use. Guardrails can address the lack of accountability in Large Language Models (LLMs) by enforcing transparency through audit trails that record model decisions and actions, thereby holding AI accountable for its outputs.
6. Encourage Interdisciplinary Collaboration:
Promote diverse content recommendation algorithms that expose users to a variety of perspectives. Encourage cross-platform information sharing to break down echo chambers. Invest in educational initiatives that expose individuals to diverse viewpoints and promote critical thinking to combat the spread of filter bubbles and echo chambers.
In a Nutshell
The path forward requires vigilance, collaboration, and an unwavering commitment to harness the power of LLMs while mitigating their pitfalls.
By championing fairness, transparency, and responsible AI use, we can unlock a future where these linguistic giants elevate society, enabling us to navigate the evolving digital landscape with wisdom and foresight. The use of Guardrails for AI is paramount in AI applications, safeguarding against misuse and unintended consequences.
The journey continues, and it’s one we embark upon with the collective goal of shaping a better, more equitable, and ethically sound AI-powered world.
Sentiment analysis, a dynamic process, extracts opinions, emotions, and attitudes from text. Its versatility spans numerous realms, but one shining application is marketing.
Here, sentiment analysis or text sentiment evaluation becomes the compass guiding marketing campaigns. By deciphering customer responses, it measures campaign effectiveness.
The insights gleaned from this process become invaluable ammunition for campaign enhancement, enabling precise targeting and ultimately yielding superior results.
In this digital age, where every word matters, text sentiment evaluation stands as a cornerstone in understanding and harnessing the power of language for strategic marketing success. It’s the art of turning words into results, and it’s transforming the marketing landscape.
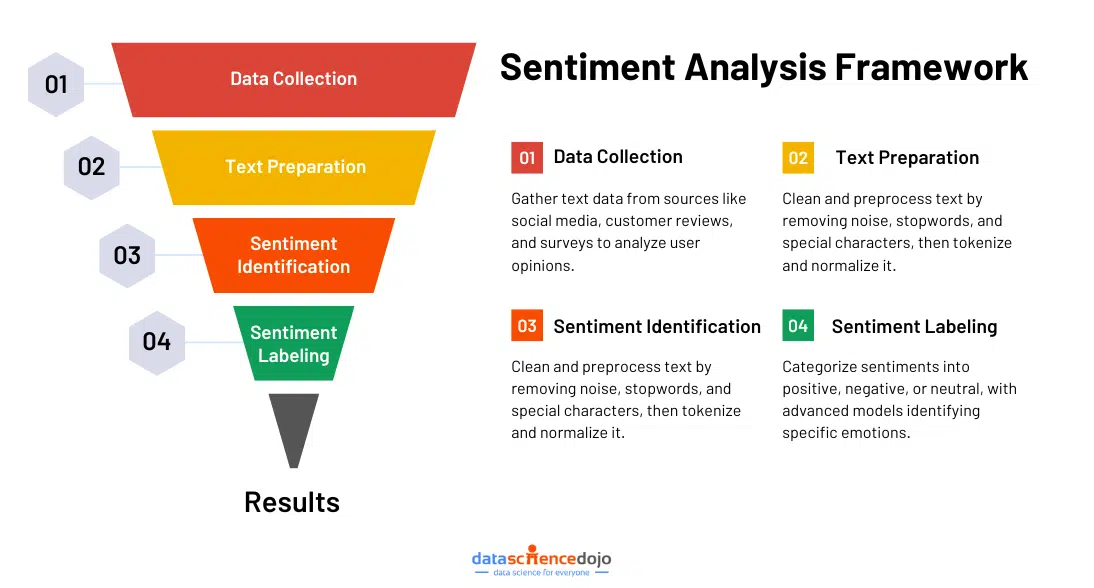
Under the lens: How does sentiment analysis work?
Sentiment analysis operates by breaking down text into smaller components, identifying their sentiment, and then aggregating these sentiments to determine the overall tone of the text. This process involves multiple techniques, each contributing to a more accurate interpretation of emotions and opinions.
1. Identifying Sentiment in Words or Phrases
The first step is analyzing individual words or phrases to determine their emotional tone. This can be done using different methods:
Lexicon-Based Analysis – This method relies on predefined dictionaries of words labeled with sentiment values (e.g., “happy” = positive, “terrible” = negative).
Machine Learning Models – AI models trained on large datasets learn to recognize patterns in sentiment based on past examples.
Natural Language Processing (NLP) – NLP techniques help analyze sentence structure, context, and even nuances like sarcasm or negation (e.g., “not bad” should be positive, not negative).
2. Aggregating Sentiments to Determine Overall Tone
Once individual words or phrases are classified, their sentiments are combined to evaluate the overall emotion of the text. This can be done using:
Sentiment Scoring – Assigning numerical values to words (e.g., -1 for negative, 0 for neutral, +1 for positive) and calculating an overall sentiment score.
Sentiment Classification – Categorizing the entire text into broad sentiment labels like positive, negative, or neutral, sometimes with additional granularity (e.g., very positive, slightly negative).
More advanced sentiment analysis also considers sentence structure, context, and intensity to refine accuracy. For example, the phrase “I love the product, but the delivery was awful” contains both positive and negative sentiments, requiring aspect-based sentiment analysis to evaluate different components separately.
In the next section, we’ll explore the different types of sentiment analysis in more detail, examining how each method helps refine sentiment detection and provide deeper insights.
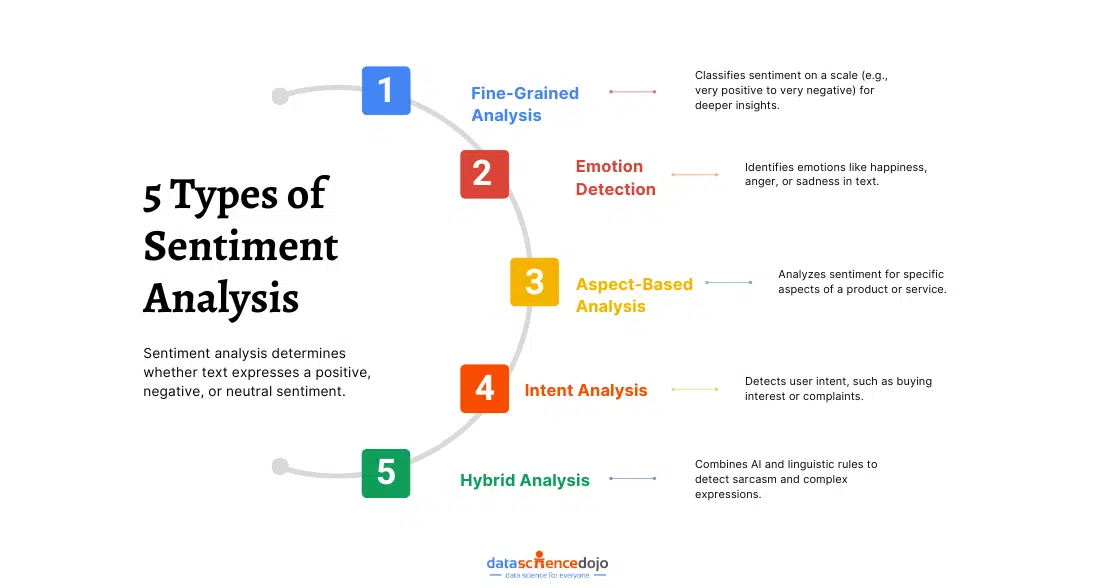
Sentiment analysis isn’t just about labeling something as positive or negative—it goes much deeper than that. Depending on the context and the level of detail needed, there are different types of mood analysis that help businesses, researchers, and organizations understand emotions, opinions, and even user intent.
Let’s break them down one by one.
1. Fine-Grained Sentiment Analysis
Sometimes, just knowing whether feedback is positive or negative isn’t enough. Fine-grained sentiment analysis takes a more detailed approach by classifying sentiments on a scale.
For example, if you’re analyzing product reviews, you might want to differentiate between:
Very Positive – “I absolutely love this product! Best purchase ever!”
Positive – “This product is good, does what it says.”
Neutral – “It’s okay, nothing special.”
Negative – “Didn’t meet my expectations.”
Very Negative – “Terrible! Would never buy again!”
This method is especially useful in surveys, online reviews, and social media monitoring, where understanding the degree of satisfaction or dissatisfaction can be crucial.
2. Emotion Detection Sentiment Analysis
Basic sentiment analysis tells you if a statement is positive or negative, but emotion detection takes it a step further by identifying which emotion is being expressed. This can include:
Happiness – “This news made my day!”
Anger – “I’m so frustrated with this service!”
Sadness – “This was a huge disappointment.”
Fear – “I’m really worried about this change.”
Surprise – “Wow, I didn’t see that coming!”
This type of sentiment analysis is often used in customer support to identify frustrated users or in marketing to gauge emotional reactions to products and campaigns. AI models use emotional dictionaries and machine learning to classify emotions based on word choices and sentence structures.
Not all opinions are straightforward. Sometimes, people feel positive about one aspect of a product or service but negative about another.
For example, if someone writes a review about a hotel saying: “The rooms were spacious and clean, but the service was extremely slow.”
Regular sentiment analysis might label this as neutral since it has both positive and negative aspects. But aspect-based sentiment analysis breaks it down further:
Rooms – Positive sentiment
Service – Negative sentiment
This method is particularly useful for businesses that need to pinpoint what exactly customers like or dislike. It helps in making targeted improvements rather than general assumptions about customer feedback.
4. Intent-Based Sentiment Analysis
Not all text is just expressing emotion—sometimes, people are hinting at their intentions. Intent-based sentiment analysis helps determine whether a user is expressing:
A need for action – “I need a new laptop. Any recommendations?” (Buying Intent)
A complaint – “My internet keeps disconnecting. So frustrating!” (Frustration, needs resolution)
A suggestion – “It would be great if this app had a dark mode.” (Feature Request)
This is widely used in customer service, marketing, and sales. If a business can detect buying intent in social media or online forums, they can engage with potential customers at the right moment. Similarly, recognizing frustration can help companies respond to complaints quickly and improve customer satisfaction.
5. Hybrid Sentiment Analysis
AI is powerful, but sometimes, it struggles with nuances like sarcasm, slang, or double meanings. That’s where hybrid sentiment analysis comes in—it combines:
Machine learning models – To detect patterns and sentiment from vast amounts of data
Linguistic rules – Predefined rules for detecting sarcasm, slang, or complex expressions
For example, if someone says: “Oh great, another software update that makes everything slower.”
A basic sentiment model might label this as positive because of the word great, but a hybrid system would recognize the sarcasm and classify it as negative.
This method is widely used in industries where high accuracy is required, such as healthcare, finance, and social media monitoring.
In the ever-evolving landscape of marketing, understanding how your audience perceives your campaigns is essential for success. Sentiment analysis, a powerful tool in the realm of data analytics, enables you to gauge public sentiment surrounding your brand and marketing efforts.
Here’s a step-by-step guide on how to effectively use sentiment analysis to track the effectiveness of your marketing campaigns:
1.Identify Your Data Sources
Begin by identifying the sources from which you’ll gather data for sentiment analysis. These sources may include:
Social Media: Monitor platforms like Twitter, Facebook, Instagram, and LinkedIn for mentions, comments, and shares related to your campaigns.
Online Reviews: Scrutinize reviews on websites such as Yelp, Amazon, or specialized industry review sites.
Customer Surveys: Conduct surveys to directly gather feedback from your audience.
Customer Support Tickets: Review tickets submitted by customers to gauge their sentiments about your products or services.
2.Choose a Sentiment Analysis Tool or Service
Selecting the right sentiment analysis tool is crucial. There are various options available, each with its own set of features. Consider factors like accuracy, scalability, and integration capabilities. Some popular tools and services include:
Before feeding data into your chosen tool, ensure it’s clean and well-prepared. This involves:
Removing irrelevant or duplicate data to avoid skewing results.
Correcting errors such as misspelled words or incomplete sentences.
Standardizing text formats for consistency.
4.Train the Sentiment Analysis Tool
To improve accuracy, train your chosen sentiment analysis tool on your specific data. This involves providing labeled examples of text as either positive, negative, or neutral sentiment. The tool will learn from these examples and become better at identifying sentiment in your context.
5.Analyze the Results
Once your tool is trained, it’s time to analyze the sentiment of the data you’ve collected. The results can provide valuable insights, including:
Overall Sentiment Trends: Determine whether the sentiment is predominantly positive, negative, or neutral.
Campaign-Specific Insights: Break down sentiment by individual marketing campaigns to see which ones resonate most with your audience.
Identify Key Topics: Discover what aspects of your products, services, or campaigns are driving sentiment.
6. Act on Insights
The true value of sentiment analysis lies in its ability to guide your marketing strategies. Use the insights gained to:
Adjust campaign messaging to align with positive sentiment trends.
Address issues highlighted by negative sentiment.
Identify opportunities for improvement based on neutral sentiment feedback.
Continuously refine your marketing campaigns to better meet customer expectations.
Benefits Of Using Sentiment Analysis To Track Campaigns
There are many benefits to using sentiment analysis to track marketing campaigns. Here are a few of the most important benefits:
Improved decision-making: Sentiment analysis can help marketers make better decisions about their marketing campaigns. By understanding how customers are responding to their campaigns, marketers can make more informed decisions about how to allocate their resources.
Increased ROI: Mood analysis can help marketers increase the ROI of their marketing campaigns. By targeting campaigns more effectively and optimizing ad campaigns, marketers can get better results from their marketing spend.
Improved customer experience: Sentiment analysis can help marketers improve the customer experience. By identifying areas where customer satisfaction can be improved, marketers can make changes to their products, services, and marketing campaigns to create a better experience for their customers.
Real-Life Scenarios: LLM & Sentiment Analysis
LLMs have several advantages over traditional sentiment analysis methods. They are more accurate, can handle more complex language, and can be trained on a wider variety of data. This makes them well-suited for use in marketing, where the goal is to understand the nuances of customer sentiment.
One example of how LLMs are being used in marketing is by Twitter. Twitter uses LLMs to analyze tweets about its platform and its users. This information is then used to improve the platform’s features and to target ads more effectively.
Another example is Netflix. Netflix uses LLMs to analyze customer reviews of its movies and TV shows. This information is then used to recommend new content to customers and to improve the overall user experience.
Recap:
Mood analysis is a powerful tool that can be used to track the effectiveness of marketing campaigns. By understanding how customers are responding to their campaigns, marketers can make better decisions, increase ROI, and improve the customer experience.
If you are looking to improve the effectiveness of your marketing campaigns, I encourage you to consider using sentiment /mood analysis. It is a powerful tool that can help you get better results from your marketing efforts.
Sentiment analysis is the process of identifying and extracting subjective information from text, such as opinions, appraisals, emotions, or attitudes. It is a powerful tool that can be used in a variety of applications, including marketing.
In marketing, mood analysis can be used to:
Understand customer sentiment towards a product, service, or brand.
Identify opportunities to improve customer satisfaction.
Monitor social media for mentions of a brand or product.
Target marketing campaigns more effectively.
In a Nutshell
In conclusion, sentiment analysis, coupled with the power of Large Language Models, is a dynamic duo that can elevate your marketing strategies to new heights. By understanding and acting upon customer sentiments, you can refine your campaigns, boost ROI, and enhance the overall customer experience.
Embrace this technological synergy to stay ahead in the ever-evolving world of marketing.
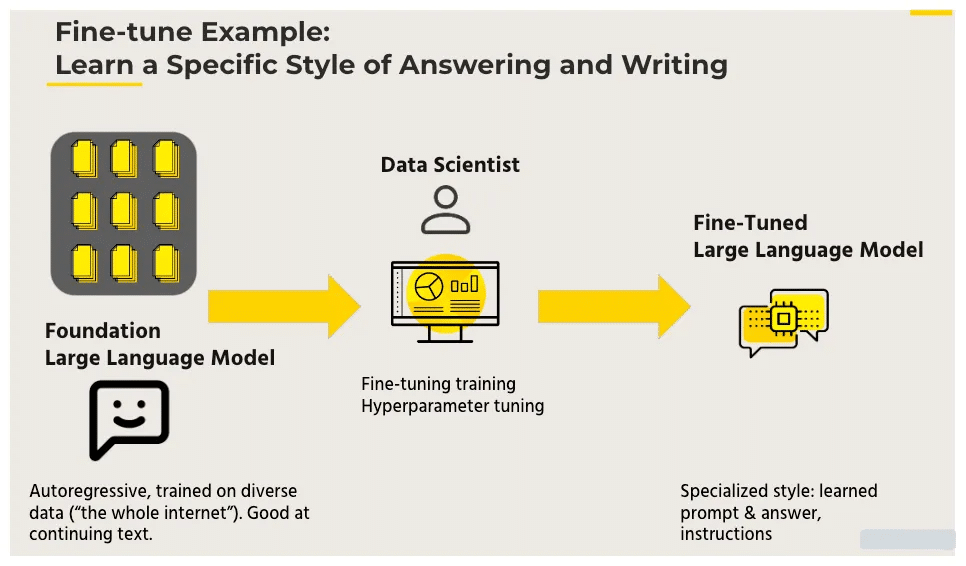
Pre-trained large language models (LLMs) offer many capabilities but aren’t universal. When faced with a task beyond their abilities, fine-tuning LLMs become an option. This process involves retraining LLMs on new data. While it can be complex and costly, it’s a potent tool for organizations using LLMs. Understanding fine-tuning, even if not doing it yourself, aids in informed decision-making.
Large language models (LLMs) are pre-trained on massive datasets of text and code. This allows them to learn a wide range of tasks, such as text generation, translation, and question-answering. However, LLMs are often not well-suited for specific tasks without fine-tuning.
source: gettectonic.com
Fine-tuning LLM
Fine-tuning is the process of adjusting the parameters of an LLM to a specific task. This is done by training the model on a dataset of data that is relevant to the task. The amount of fine-tuning required depends on the complexity of the task and the size of the dataset.
By exposing the model to domain-specific data, fine-tuning allows it to adapt its responses, improve accuracy, and generate more contextually appropriate outputs.
The extent of fine-tuning LLMs required depends on multiple factors:
Task Complexity: More intricate tasks, such as medical diagnosis or legal document analysis, require deeper fine-tuning compared to general tasks like sentiment analysis.
Dataset Size & Quality: A well-structured and extensive dataset ensures better adaptation, while a limited or noisy dataset may yield suboptimal results.
Model Architecture: Larger models may require more computational resources and training time, whereas smaller models might fine-tune faster but with reduced capabilities.
Fine-tuning enhances the model’s ability to understand industry-specific terminology, follow structured formats, and generate responses aligned with the desired use case. This makes it a valuable approach for businesses and researchers looking to tailor LLMs for specialized applications.
There are a number of ways to fine-tune LLMs. One common approach is to use supervised learning. This involves providing the model with a dataset of labeled data, where each data point is a pair of input and output. The model learns to map the input to the output by minimizing a loss function.
Another approach to fine-tuning LLMs is to use reinforcement learning. This involves providing the model with a reward signal for generating outputs that are desired. The model learns to generate desired outputs by maximizing the reward signal.
Fine-Tuning Techniques for LLMs
Fine-tuning is the process of adjusting the parameters of an LLM to a specific task. This is done by training the model on a dataset of data that is relevant to the task. The amount of fine-tuning required depends on the complexity of the task and the size of the dataset. There are two main fine-tuning techniques for LLMs: repurposing and full fine-tuning.
1. Repurposing
Repurposing is a technique where you use an LLM for a task that is different from the task it was originally trained on. For example, you could use an LLM that was trained for text generation for sentiment analysis.
To repurpose an LLM, you first need to identify the features of the input data that are relevant to the task you want to perform. Then, you need to connect the LLM’s embedding layer to a classifier model that can learn to map these features to the desired output.
Repurposing is a less computationally expensive fine-tuning technique than full fine-tuning. However, it is also less likely to achieve the same level of performance.
Technique
Description
Computational Cost
Performance
Repurposing
Use an LLM for a task that is different from the task it was originally trained on.
Less
Less
Full Fine-tuning
Train the entire LLM on a dataset of data that is relevant to the task you want to perform.
More
More
2. Full Fine-Tuning
Full fine-tuning is a technique where you train the entire LLM on a dataset of data that is relevant to the task you want to perform. This is the most computationally expensive fine-tuning technique, but it is also the most likely to achieve the best performance.
To full fine-tune an LLM, you need to create a dataset of data that contains examples of the input and output for the task you want to perform. Then, you need to train the LLM on this dataset using a supervised learning algorithm.
The choice of fine-tuning technique depends on the specific task you want to perform and the resources you have available. If you are short on computational resources, you may want to consider repurposing. However, if you are looking for the best possible performance, you should full fine-tune the LLM.
Large language models (LLMs) are pre-trained on massive datasets of text and code. This allows them to learn a wide range of tasks, such as text generation, translation, and question-answering. However, LLMs are often not well-suited for specific tasks without fine-tuning.
Fine-tuning is the process of adjusting the parameters of an LLM to a specific task. This is done by training the model on a dataset of data that is relevant to the task. The amount of fine-tuning required depends on the complexity of the task and the size of the dataset.
There are two main types of fine-tuning for LLMs: unsupervised and supervised.
Unsupervised Fine-Tuning
Unsupervised fine-tuning is a technique where you train the LLM on a dataset of data that does not contain any labels. This means that the model does not know what the correct output is for each input. Instead, the model learns to predict the next token in a sequence or to generate text that is similar to the text in the dataset.
Unsupervised fine-tuning is a less computationally expensive fine-tuning technique than supervised fine-tuning. However, it is also less likely to achieve the same level of performance.
Supervised Fine-Tuning
Supervised fine-tuning is a technique where you train the LLM on a dataset of data that contains labels. This means that the model knows what the correct output is for each input. The model learns to map the input to the output by minimizing a loss function.
Supervised fine-tuning is a more computationally expensive fine-tuning technique than unsupervised fine-tuning. However, it is also more likely to achieve the best performance.
The choice of fine-tuning technique depends on the specific task you want to perform and the resources you have available. If you are short on computational resources, you may want to consider unsupervised fine-tuning. However, if you are looking for the best possible performance, you should supervise fine-tuning the LLM.
Here is a table that summarizes the key differences between unsupervised and supervised fine-tuning:
Technique
Description
Computational Cost
Performance
Unsupervised Fine-tuning
Train the LLM on a dataset of data that does not contain any labels.
Less
Less
Supervised Fine-tuning
Train the LLM on a dataset of data that contains labels.
More
More
Reinforcement Learning from Human Feedback (RLHF) for LLMs
There are two main approaches to fine-tuning LLMs: supervised fine-tuning and reinforcement learning from human feedback (RLHF).
1. Supervised Fine-Tuning
Supervised fine-tuning is a technique where you train the LLM on a dataset of data that contains labels. This means that the model knows what the correct output is for each input. The model learns to map the input to the output by minimizing a loss function.
2. Reinforcement Learning from Human Feedback (RLHF)
RLHF is a technique where you use human feedback to fine-tune the LLM. The basic idea is that you give the LLM a prompt and it generates an output. Then, you ask a human to rate the output. The rating is used as a signal to fine-tune the LLM to generate higher-quality outputs.
RLHF is a more complex and expensive fine-tuning technique than supervised fine-tuning. However, it can be more effective for tasks that are difficult to define or for which there is not enough labeled data.
PEFT is a set of techniques that try to reduce the number of parameters that need to be updated during fine-tuning. This can be done by using a smaller dataset, using a simpler model, or using a technique called low-rank adaptation (LoRA).
LoRA is a technique that uses a low-dimensional matrix to represent the space of the downstream task. This matrix is then fine-tuned instead of the entire LLM. This can significantly reduce the amount of computation required for fine-tuning.
PEFT is a promising approach for fine-tuning LLMs. It can make fine-tuning more affordable and efficient, which can make it more accessible to a wider range of users.
When Not to Use LLM Fine-Tuning
Large language models (LLMs) are pre-trained on massive datasets of text and code. This allows them to learn a wide range of tasks, such as text generation, translation, and question answering. However, LLM fine-tuning is not always necessary or desirable.
Here are some cases where you might not want to use LLM fine-tuning:
The model is not available for fine-tuning. Some LLMs are only available through application programming interfaces (APIs) that do not allow fine-tuning.
You don’t have enough data to fine-tune the model. Fine-tuning an LLM requires a large dataset of labeled data. If you don’t have enough data, you may not be able to achieve good results with fine-tuning.
The data is constantly changing. If the data that the LLM is being used on is constantly changing, fine-tuning may not be able to keep up. This is especially true for tasks such as machine translation, where the vocabulary and grammar of the source language can change over time.
The application is dynamic and context-sensitive. In some cases, the output of an LLM needs to be tailored to the specific context of the user or the situation. For example, a chatbot that is used in a customer service application would need to be able to understand the customer’s intent and respond accordingly. Fine-tuning an LLM for this type of application would be difficult, as it would require a large dataset of labeled data that captures the different contexts in which the chatbot would be used.
In these cases, you may want to consider using a different approach, such as:
Using a smaller, less complex model. Smaller models are less computationally expensive to train and fine-tune, and they may be sufficient for some tasks.
Using a transfer learning approach. Transfer learning is a technique where you use a model that has been trained on a different task to initialize a model for a new task. This can be a more efficient way to train a model for a new task, as it can help the model to learn faster.
Using in-context learning or retrieval augmentation. In-context learning or retrieval augmentation is a technique where you provide the LLM with context during inference time. This can help the LLM to generate more accurate and relevant outputs.
Wrapping Up
In conclusion, fine-tuning LLMs is a powerful tool for tailoring these models to specific tasks. Understanding its nuances and options, including repurposing and full fine-tuning, helps optimize performance. The choice between supervised and unsupervised fine-tuning depends on resources and task complexity. Additionally, reinforcement learning from human feedback (RLHF) and parameter-efficient fine-tuning (PEFT) offer specialized approaches. While fine-tuning enhances LLMs, it’s not always necessary, especially if the model already fits the task. Careful consideration of when to use fine-tuning is essential in maximizing the efficiency and effectiveness of LLMs for specific applications.
One might wonder as to exactly how prevalent LLMs are in our personal and professional lives. For context, while the world awaited the clash of Barbenheimer on the silver screen, there was a greater conflict brewing in the background.
SAG-AFTRA, the American labor union representing approximately 160,000 media professionals worldwide (some main members include George Clooney. Tom Hanks, and Meryl Streep among many others) launched a strike in part to call for tightening regulations on the use of artificial intelligence in creative projects. This came as the world witnessed growing concern regarding the rapid advancements of artificial intelligence, which in particular is being led by Large Language Models (LLMs).
Few concepts have garnered as much attention and concern as LLMs. These AI-powered systems have taken the stage as linguistic juggernauts, demonstrating remarkable capabilities in understanding and generating human-like text.
However, instead of fearing these advancements, you can harness the power of LLMs to not just survive but thrive in this new era of AI dominance and make sure you stay ahead of the competition. In this article, we’ll show you how. But before we jump into that, it is imperative to gain a basic understanding of what LLM’s primarily are.
What are large language models?
Picture this: an AI assistant who can converse with you as if a seasoned expert in countless subjects. That’s the essence of a Large Language Model (LLM). This AI marvel is trained on an extensive array of texts from books, articles, websites, and conversations.
It learns the intricate nuances of language, grammar, and context, enabling it to answer queries, draft content, and even engage in creative pursuits like storytelling and poetry. While LLMs might seem intimidating at first glance, they’re tools that can be adapted to enhance your profession.
Embracing large language models across professions
1. Large language models and software development
Automating code generation: LLMs can be used to generate code automatically, which can save developers a significant amount of time and effort. For example, LLMs can be used to generate boilerplate code, such as class declarations and function definitions. They can also be used to generate code that is customized to specific requirements.
Generating test cases: LLMs can be used to generate test cases for software. This can help to ensure that software is thoroughly tested and that bugs are caught early in the development process. For example, LLMs can be used to generate inputs that are likely to cause errors, or they can be used to generate test cases that cover all possible paths through a piece of code.
Writing documentation: LLMs can be used to write documentation for software. This can help to make documentation more comprehensive and easier to understand. For example, LLMs can be used to generate summaries of code, or they can be used to generate interactive documentation that allows users to explore the code in a more dynamic way.
Designing software architectures: LLMs can be used to design software architectures. This can help to ensure that software is architected in a way that is efficient, scalable, and secure. For example, LLMs can be used to analyze code to identify potential bottlenecks, or they can be used to generate designs that are compliant with specific security standards.
Real-life use cases in software development
Google AI has used LLMs to develop a tool called Bard that can help developers write code more efficiently. Bard can generate code, translate languages, and answer questions about code.
Microsoft has used LLMs to develop a tool called GitHub Copilot that can help developers write code faster and with fewer errors. Copilot can generate code suggestions, complete unfinished code, and fix bugs.
The company AppSheet has used LLMs to develop a tool called AppSheet AI that can help developers create mobile apps without writing any code. AI can generate code, design user interfaces, and test apps.
2. Building beyond imagination: Large language models and architectural innovation
Analyzing crop data: LLMs can be used to analyze crop data, such as yield data, weather data, and soil data. This can help farmers to identify patterns and trends, and to make better decisions about crop rotation, planting, and irrigation.
Optimizing yields: LLMs can be used to optimize yields by predicting crop yields, identifying pests and diseases, and recommending optimal farming practices.
Managing pests: LLMs can be used to manage pests by identifying pests, predicting pest outbreaks, and recommending pest control methods.
Personalizing recommendations: LLMs can be used to personalize recommendations for farmers, such as recommending crops to plant, fertilizers to use, and pest control methods to employ.
Generating reports: LLMs can be used to generate reports on crop yields, pest outbreaks, and other agricultural data. This can help farmers to track their progress and make informed decisions.
Chatbots: LLMs can be used to create chatbots that can answer farmers’ questions about agriculture. This can help farmers to get the information they need quickly and easily.
Real-life scenarios in agriculture
The company Indigo Agriculture is using LLMs to develop a tool called Indigo Scout that can help farmers to identify pests and diseases in their crops. Indigo Scout uses LLMs to analyze images of crops and to identify pests and diseases that are not visible to the naked eye.
The company BASF is using LLMs to develop a tool called BASF FieldView Advisor that can help farmers to optimize their crop yields. BASF FieldView Advisor uses LLMs to analyze crop data and to recommend optimal farming practices.
The company John Deere is using LLMs to develop a tool called John Deere See & Spray that can help farmers to apply pesticides more accurately. John Deere See & Spray uses LLMs to analyze images of crops and to identify areas that need to be sprayed.
3. Powering progress: Large language models and energy industry
Analyzing energy data: LLMs can be used to analyze energy data, such as power grid data, weather data, and demand data. This can help energy companies to identify patterns and trends, and to make better decisions about energy production, distribution, and consumption.
Optimizing power grids: LLMs can be used to optimize power grids by predicting demand, identifying outages, and routing power. This can help to improve the efficiency and reliability of power grids.
Developing new energy technologies: LLMs can be used to develop new energy technologies, such as solar panels, wind turbines, and batteries. This can help to reduce our reliance on fossil fuels and to transition to a clean energy future.
Managing energy efficiency: LLMs can be used to manage energy efficiency by identifying energy leaks, recommending energy-saving measures, and providing feedback on energy consumption. This can help to reduce energy costs and emissions.
Creating educational content: LLMs can be used to create educational content about energy, such as videos, articles, and quizzes. This can help to raise awareness about energy issues and to promote energy literacy.
Real-life scenarios in the energy sector
The company Griddy is using LLMs to develop a tool called Griddy Insights that can help energy consumers to understand their energy usage and to make better decisions about their energy consumption. Griddy Insights uses LLMs to analyze energy data and to provide personalized recommendations for energy saving.
The company Siemens is using LLMs to develop a tool called MindSphere Asset Analytics that can help energy companies to monitor and maintain their assets. MindSphere Asset Analytics uses LLMs to analyze sensor data and to identify potential problems before they occur.
The company Google is using LLMs to develop a tool called DeepMind Energy that can help energy companies to develop new energy technologies. DeepMind Energy uses LLMs to simulate energy systems and to identify potential improvements.
4. LLMs: The Future of Architecture and Construction?
Generating designs: LLMs can be used to generate designs for buildings, structures, and other infrastructure. This can help architects and engineers to explore different possibilities and to come up with more creative and innovative designs.
Optimizing designs: LLMs can be used to optimize designs for efficiency, sustainability, and cost-effectiveness. This can help to ensure that buildings are designed to meet the needs of their users and to minimize their environmental impact.
Automating tasks: LLMs can be used to automate many of the tasks involved in architecture and construction, such as drafting plans, generating estimates, and managing projects. This can save time and money, and it can also help to improve accuracy and efficiency.
Communicating with stakeholders: LLMs can be used to communicate with stakeholders, such as clients, engineers, and contractors. This can help to ensure that everyone is on the same page and that the project is completed on time and within budget.
Analyzing data: LLMs can be used to analyze data related to architecture and construction, such as building codes, environmental regulations, and cost data. This can help to make better decisions about design, construction, and maintenance.
Real-life scenarios in architecture and construction
The company Gensler is using LLMs to develop a tool called Gensler AI that can help architects design more efficient and sustainable buildings. Gensler AI can analyze data on building performance and generate design recommendations.
The company Houzz has used LLMs to develop a tool called Houzz IQ that can help users find real estate properties that match their needs. Houzz IQ can analyze data on property prices, market trends, and zoning regulations to generate personalized recommendations.
The company Opendoor has used LLMs to develop a chatbot called Opendoor Bot that can answer questions about real estate. Opendoor Bot can be used to provide 24/7 customer service and to help users find real estate properties.
Large Language Models Across Professions
5. LLMs: The future of logistics
Optimizing supply chains: LLMs can be used to optimize supply chains by identifying bottlenecks, predicting demand, and routing shipments. This can help to improve the efficiency and reliability of supply chains.
Managing inventory: LLMs can be used to manage inventory by forecasting demand, tracking stock levels, and identifying out-of-stock items. This can help to reduce costs and improve customer satisfaction.
Planning deliveries: LLMs can be used to plan deliveries by taking into account factors such as traffic conditions, weather, and fuel prices. This can help to ensure that deliveries are made on time and within budget.
Communicating with customers: LLMs can be used to communicate with customers about shipments, delays, and other issues. This can help to improve customer satisfaction and reduce the risk of complaints.
Automating tasks: LLMs can be used to automate many of the tasks involved in logistics, such as processing orders, generating invoices, and tracking shipments. This can save time and money, and it can also help to improve accuracy and efficiency.
Real-life scenarios and logistics
The company DHL is using LLMs to develop a tool called DHL Blue Ivy that can help to optimize supply chains. DHL Blue Ivy uses LLMs to analyze data on demand, inventory, and transportation costs to identify ways to improve efficiency.
The company Amazon is using LLMs to develop a tool called Amazon Scout that can deliver packages autonomously. Amazon Scout uses LLMs to navigate around obstacles and to avoid accidents.
The company Uber Freight is using LLMs to develop a tool called Uber Freight Einstein that can help to match shippers with carriers. Uber Freight Einstein uses LLMs to analyze data on shipments, carriers, and rates to find the best possible match.
6. Crafting connection: Large Language Models and Marketing
If you are a journalist or content creator, chances are that you’ve faced the challenge of sifting through an overwhelming volume of data to uncover compelling stories. Here’s how LLMs can offer you more than just assistance:
Enhanced Research Efficiency: Imagine having a virtual assistant that can swiftly scan through extensive databases, articles, and reports to identify relevant information for your stories. LLMs excel in data processing and retrieval, ensuring that you have the most accurate and up-to-date facts at your fingertips. This efficiency not only accelerates the research process but also enables you to focus on in-depth investigative journalism.
Deep-Dive Analysis: LLMs go beyond skimming the surface. They can analyze patterns and correlations within data that might be challenging for humans to spot. By utilizing these insights, you can uncover hidden trends and connections that form the backbone of groundbreaking stories. For instance, if you’re investigating customer buying habits in the last fiscal quarter, LLMs can identify patterns that might lead to a new perspective or angle for your study.
Generating Data-Driven Content: In addition to assisting with research, LLMs can generate data-driven content based on large datasets. They can create reports, summaries, and infographics that distill complex information into easily understandable formats. This skill becomes particularly handy when covering topics such as scientific research, economic trends, or public health data, where presenting numbers and statistics in an accessible manner is crucial.
Hyper-Personalization: LLMs can help tailor content to specific target audiences. By analyzing past engagement and user preferences, these models can suggest the most relevant angles, language, and tone for your content. This not only enhances engagement but also ensures that your stories resonate with diverse readerships.
Fact-Checking and Verification: Ensuring the accuracy of information is paramount in journalism. LLMs can assist in fact-checking and verification by cross-referencing information from multiple sources. This process not only saves time but also enhances the credibility of your work, bolstering trust with your audience.
7. Words unleashed: Large language models and content
8 seconds. That is all the time you have as a marketer to catch the attention of your subject. If you are successful, you then have to retain it. LLMs offer you a wealth of possibilities that can elevate your campaigns to new heights:
Efficient Copy Generation: LLMs excel at generating textual content quickly. Whether it’s drafting ad copy, social media posts, or email subject lines, these models can help marketers create a vast amount of content in a short time. This efficiency proves particularly beneficial during time-sensitive campaigns and product launches.
A/B Testing Variations: With LLMs, you can rapidly generate different versions of ad copies, headlines, or taglines. This enables you to perform A/B testing on a larger scale, exploring a variety of messaging approaches to identify which resonates best with your audience. By fine-tuning your content through data-driven experimentation, you can optimize your marketing strategies for maximum impact.
Adapting to Platform Specifics: Different platforms have unique engagement dynamics. LLMs can assist in tailoring content to suit the nuances of various platforms, ensuring that your message aligns seamlessly with each channel’s characteristics. For instance, a tweet might require concise wording, while a blog post can be more in-depth. LLMs can adapt content length, tone, and style accordingly.
Content Ideation: Stuck in a creative rut? LLMs can be a valuable brainstorming partner. By feeding them relevant keywords or concepts, you can prompt them to generate a range of creative ideas for campaigns, slogans, or content themes. While these generated ideas serve as starting points, your creative vision remains pivotal in shaping the final concept.
Enhancing SEO Strategy: LLMs can assist in optimizing content for search engines. They can identify relevant keywords and phrases that align with trending search queries. Tools such as Ahref for Keyword search are already commonly used by SEO strategists which use LLM strategies at the backend. This ensures that your content is not only engaging but also discoverable, enhancing your brand’s online visibility.
8. Healing with data: Large language models in healthcare
The healthcare industry is also witnessing the transformative influence of LLMs. If you are in the healthcare profession, here’s how these AI agents can be of use to you:
Staying Current with Research: LLMs serve as valuable research assistants, efficiently scouring through a sea of articles, clinical trials, and studies to provide summaries and insights. This allows healthcare professionals to remain updated with the latest breakthroughs, ensuring that patient care is aligned with the most recent medical advancements.
Efficient Documentation: The administrative workload on healthcare providers can be overwhelming. LLMs step in by assisting in transcribing patient notes, generating reports, and documenting medical histories. This streamlined documentation process ensures that medical professionals can devote more time to direct patient interaction and critical decision-making.
Patient-Centered Communication: Explaining intricate medical concepts to patients in an easily understandable manner is an art. LLMs aid in transforming complex jargon into accessible language, allowing patients to comprehend their conditions, treatment options, and potential outcomes. This improved communication fosters trust and empowers patients to actively participate in their healthcare decisions.
9. Knowledge amplified: Large language models in education
Perhaps the possibilities with LLMs are nowhere as exciting as in the Edtech Industry. These AI tools hold the potential to reshape the way educators impart knowledge, empower students, and tailor learning experiences. If you are related to academia, here’s what LLMs may hold for you:
Diverse Content Generation: LLMs are adept at generating a variety of educational content, ranging from textbooks and study guides to interactive lessons and practice quizzes. This enables educators to access a broader spectrum of teaching materials that cater to different learning styles and abilities.
Simplified Complex Concepts: Difficult concepts that often leave students perplexed can be presented in a more digestible manner through LLMs. These AI models have the ability to break down intricate subjects into simpler terms, using relatable examples that resonate with students. This ensures that students grasp foundational concepts before delving into more complex topics.
Adaptive Learning: LLMs can assess students’ performance and adapt learning materials accordingly. If a student struggles with a particular concept, the AI can offer additional explanations, resources, and practice problems tailored to their learning needs. Conversely, if a student excels, the AI can provide more challenging content to keep them engaged.
Personalized Feedback: LLMs can provide instant feedback on assignments and assessments. They can point out areas that need improvement and suggest resources for further study. This timely feedback loop accelerates the learning process and allows students to address gaps in their understanding promptly.
Enriching Interactive Learning: LLMs can contribute to interactive learning experiences. They can design simulations, virtual labs, and interactive exercises that engage students and promote hands-on learning. This interactivity fosters deeper understanding and retention.
Engaging Content Creation: Educators can collaborate with LLMs to co-create engaging educational content. For instance, an AI can help a history teacher craft captivating narratives or a science teacher can use an AI to design interactive experiments that bring concepts to life.
A collaborative future
It’s undeniable that LLMs are changing the professional landscape. Even now, proactive software companies are taking steps to update their SDLC’s to integrate AI and LLM’s as much as possible to increase efficiency. Marketers are also at the forefront, using LLMs to test tons of copies to find just the right one. It is incredibly likely that LLMs have already seeped into your industry; you just have to enter a few search strings on your search engine to find out.
However, it’s crucial to view them not as adversaries but as collaborators. Just as calculators did not replace mathematicians but enhanced their work, LLMs can augment your capabilities. They provide efficiency, data analysis, and generation support, but the core expertise and creativity that you bring to your profession remain invaluable.
Empowering the future
In the face of concerns about AI’s impact on the job market, a proactive approach is essential. Large Language Models, far from being a threat, are tools that can empower you to deliver better results. Rather than replacing jobs, they redefine roles and offer avenues for growth and innovation. The key lies in understanding the potential of these AI systems and utilizing them to augment your capabilities, ultimately shaping a future where collaboration between humans and AI is the driving force behind progress.
So, instead of fearing change, harness the potential of LLMs to pioneer a new era of professional excellence.
Large Language Model Ops also known as LLMOps isn’t just a buzzword; it’s the cornerstone of unleashing LLM potential. From data management to model fine-tuning, LLMOps ensures efficiency, scalability, and risk mitigation. As LLMs redefine AI capabilities, mastering LLMOps becomes your compass in this dynamic landscape.
What is LLMOps?
LLMOps, which stands for Large Language Model Ops, encompasses the set of practices, techniques, and tools employed for the operational management of large language models within production environments.
Consequently, there is a growing need to establish best practices for effectively integrating these models into operational workflows. LLMOps facilitates the streamlined deployment, continuous monitoring, and ongoing maintenance of large language models. Similar to traditional Machine Learning Ops (MLOps), LLMOps necessitates a collaborative effort involving data scientists, DevOps engineers, and IT professionals. To acquire insights into building your own LLM, refer to our resources.
Development to production workflow LLMs
Large Language Models (LLMs) represent a novel category of Natural Language Processing (NLP) models that have significantly surpassed previous benchmarks across a wide spectrum of tasks, including open question-answering, summarization, and the execution of nearly arbitrary instructions. While the operational requirements of MLOps largely apply to LLMOps, training and deploying LLMs present unique challenges that call for a distinct approach to LLMOps.
LLMOps MLOps for Large Language Model
What are the components of LLMOps?
The scope of LLMOps within machine learning projects can vary widely, tailored to the specific needs of each project. Some projects may necessitate a comprehensive LLMOps approach, spanning tasks from data preparation to pipeline production.
1. Exploratory Data Analysis (EDA)
Data collection: The first step in LLMOps is to collect the data that will be used to train the LLM. This data can be collected from a variety of sources, such as text corpora, code repositories, and social media.
Data cleaning: Once the data is collected, it needs to be cleaned and prepared for training. This includes removing errors, correcting inconsistencies, and removing duplicate data.
Data exploration: The next step is to explore the data to better understand its characteristics. This includes looking at the distribution of the data, identifying outliers, and finding patterns.
2. Data prep and prompt engineering
Data preparation: The data that is used to train an LLM needs to be prepared in a specific way. This includes tokenizing the data, removing stop words, and normalizing the text.
Prompt engineering: Prompt engineering is the process of creating prompts that are used to generate text with the LLM. The prompts need to be carefully crafted to ensure that the LLM generates the desired output.
3. Model fine-tuning
Model training: Once the data is prepared, the LLM is trained. This is done by using a machine learning algorithm to learn the patterns in the data.
Model evaluation: Once the LLM is trained, it needs to be evaluated to see how well it performs. This is done by using a test set of data that was not used to train the LLM.
Model fine-tuning: If the LLM does not perform well, it can be fine-tuned. This involves adjusting the LLM’s parameters to improve its performance.
4. Model review and governance
Model review: Once the LLM is fine-tuned, it needs to be reviewed to ensure that it is safe and reliable. This includes checking for bias, safety, and security risks.
Model governance: Model governance is the process of managing the LLM throughout its lifecycle. This includes tracking its performance, making changes to it as needed, and retiring it when it is no longer needed.
5. Model inference and serving
Model inference: Once the LLM is reviewed and approved, it can be deployed into production. This means that it can be used to generate text or answer questions.
Model serving: Model serving is the process of making the LLM available to users. This can be done through a variety of ways, such as a REST API or a web application.
6. Model monitoring with human feedback
Model monitoring: Once the LLM is deployed, it needs to be monitored to ensure that it is performing as expected. This includes tracking its performance, identifying any problems, and making changes as needed.
Human feedback: Human feedback can be used to improve the performance of the LLM. This can be done by providing feedback on the text that the LLM generates, or by identifying any problems with the LLM’s performance.
LLMOps vs MLOps
Feature
LLMOps
MLOps
Computational resources
Requires more specialized hardware and compute resources
Can be run on a variety of hardware and compute resources
Transfer learning
Often uses a foundation model and fine-tunes it with new data
Can be trained from scratch
Human feedback
Often uses human feedback to evaluate performance
Can use automated metrics to evaluate performance
Hyperparameter tuning
Tuning is important for reducing the cost and computational power requirements of training and inference
Tuning is important for improving accuracy or other metrics
Performance metrics
Uses a different set of standard metrics and scoring
Uses well-defined performance metrics, such as accuracy, AUC, F1 score, etc.
Prompt engineering
Critical for getting accurate, reliable responses from LLMs
Not as critical, as traditional ML models do not take prompts
Building LLM chains or pipelines
Often focuses on building these pipelines, rather than building new LLMs
Can focus on either building new models or building pipelines
Best practices for LLMOps implementation
LLMOps covers a broad spectrum of tasks, ranging from data preparation to pipeline production. Here are seven key steps to ensure a successful adoption of LLMOps:
1. Data Management and Security
Data is a critical component in LLM training, making robust data management and stringent security practices essential. Consider the following:
Data Storage: Employ suitable software solutions to handle large data volumes, ensuring efficient data retrieval across the entire LLM lifecycle.
Data Versioning: Maintain a record of data changes and monitor development through comprehensive data versioning practices.
Data Encryption and Access Controls: Safeguard data with transit encryption and enforce access controls, such as role-based access, to ensure secure data handling.
Exploratory Data Analysis (EDA): Continuously prepare and explore data for the machine learning lifecycle, creating shareable visualizations and reproducible datasets.
Prompt Engineering: Develop reliable prompts to generate accurate queries from LLMs, facilitating effective communication.
In LLMOps, efficient training, evaluation, and management of LLM models are paramount. Here are some recommended practices:
Selection of Foundation Model: Choose an appropriate pre-trained model as the starting point for customization, taking into account factors like performance, size, and compatibility.
Few-Shot Prompting: Leverage few-shot learning to expedite model fine-tuning for specialized tasks without extensive training data, providing a versatile and efficient approach to utilizing large language models.
Model Fine-Tuning: Optimize model performance using established libraries and techniques for fine-tuning, enhancing the model’s capabilities in specific domains.
Model Inference and Serving: Manage the model refresh cycle and ensure efficient inference request times while addressing production-related considerations during testing and quality assurance stages.
Model Monitoring with Human Feedback: Develop robust data and model monitoring pipelines that incorporate alerts for detecting model drift and identifying potential malicious user behavior.
Model Evaluation and Benchmarking: Establish comprehensive data and model monitoring pipelines, including alerts to identify model drift and potentially malicious user behavior. This proactive approach enhances model reliability and security.
3. Deployment
Achieve seamless integration into the desired environment while optimizing model performance and accessibility with these tips:
Cloud-Based and On-Premises Deployment: Choose the appropriate deployment strategy based on considerations such as budget, security, and infrastructure requirements.
Adapting Existing Models for Specific Tasks: Tailor pre-trained models for specific tasks, as this approach is cost-effective. It also applies to customizing other machine learning models like natural language processing (NLP) or deep learning models.
4. Monitoring and Maintenance
LLMOps ensures sustained performance and adaptability over time:
Improving Model Performance: Establish tracking mechanisms for model and pipeline lineage and versions, enabling efficient management of artifacts and transitions throughout their lifecycle.
By implementing these best practices, organizations can enhance their LLMOps adoption and maximize the benefits of large language models in their operational workflows.
Why is LLMOps Essential?
Large language models (LLMs) are a type of artificial intelligence (AI) that are trained on massive datasets of text and code. They can be used for a variety of tasks, such as text generation, translation, and question answering. However, LLMs are also complex and challenging to deploy and manage. This is where LLMOps comes in.
LLMOps is the set of practices and tools that are used to deploy, manage, and monitor LLMs. It encompasses the entire LLM development lifecycle, from experimentation and iteration to deployment and continuous improvement.
LLMOps is essential for a number of reasons. First, it helps to ensure that LLMs are deployed and managed in a consistent and reliable way. This is important because LLMs are often used in critical applications, such as customer service chatbots and medical diagnosis systems.
Second, LLMOps helps to improve the performance of LLMs. By monitoring the performance of LLMs, LLMOps can identify areas where they can be improved. This can be done by tuning the LLM’s parameters, or by providing it with more training data.
Third, LLMOps helps to mitigate the risks associated with LLMs. LLMs are trained on massive datasets of text and code, and this data can sometimes contain harmful or biased information. LLMOps can help to identify and remove this information from the LLM’s training data.
What are the benefits of LLMOps?
The primary benefits of LLMOps are efficiency, scalability, and risk mitigation.
Efficiency: LLMOps can help to improve the efficiency of LLM development and deployment. This is done by automating many of the tasks involved in LLMOps, such as data preparation and model training.
Scalability: LLMOps can help to scale LLM development and deployment. This is done by making it easier to manage and deploy multiple LLMs.
Risk mitigation: LLMOps can help to mitigate the risks associated with LLMs. This is done by identifying and removing harmful or biased information from the LLM’s training data, and by monitoring the performance of the LLM to identify any potential problems.
In summary, LLMOps is essential for managing the complexities of integrating LLMs into commercial products. It offers significant advantages in terms of efficiency, scalability, and risk mitigation. Here are some specific examples of how LLMOps can be used to improve the efficiency, scalability, and risk mitigation of LLM development and deployment:
Efficiency: LLMOps can automate many of the tasks involved in LLM development and deployment, such as data preparation and model training. This can free up data scientists and engineers to focus on more creative and strategic tasks.
Scalability: LLMOps can help to scale LLM development and deployment by making it easier to manage and deploy multiple LLMs. This is important for organizations that need to deploy LLMs in a variety of applications and environments.
Risk mitigation: LLMOps can help to mitigate the risks associated with LLMs by identifying and removing harmful or biased information from the LLM’s training data. It can also help to monitor the performance of the LLM to identify any potential problems.
In a nutshell
In conclusion, LLMOps is a critical discipline for organizations that want to successfully deploy and manage large language models. By implementing the best practices outlined in this blog, organizations can ensure that their LLMs are deployed and managed in a consistent and reliable way and that they are able to maximize the benefits of these powerful models.
Unlocking the Power of LLM Use-Cases: AI applications now excel at summarizing articles, weaving narratives, and sparking conversations, all thanks to advanced large language models.
A large language model, abbreviated as LLM, represents a deep learning algorithm with the capability to identify, condense, translate, forecast, and generate text as well as various other types of content. These abilities are harnessed by drawing upon extensive knowledge extracted from massive datasets.
Large language models, which are a prominent category of transformer models, have proven to be exceptionally versatile. They extend beyond simply instructing artificial intelligence systems in human languages and find application in diverse domains like deciphering protein structures, composing software code, and many other multifaceted tasks.
Furthermore, apart from enhancing natural language processing applications such as translation, chatbots, and AI-powered assistants, large language models are also being employed in healthcare, software development, and numerous other fields for various practical purposes.
Language serves as a conduit for various forms of communication. In the vicinity of computers, code becomes the language. Large language models can be effectively deployed in these linguistic domains or scenarios requiring diverse communication.
These models significantly expand the purview of AI across industries and businesses, poised to usher in a new era of innovation, ingenuity, and efficiency. They possess the potential to generate intricate solutions to some of the world’s most intricate challenges.
For instance, an AI system leveraging large language models can acquire knowledge from a database of molecular and protein structures. It can then employ this knowledge to propose viable chemical compounds, facilitating groundbreaking discoveries in vaccine and treatment development.
LLM Use-Cases: 10 industries revolutionized by large language models
Large language models are also instrumental in creating innovative search engines, educational chatbots, and composition tools for music, poetry, narratives, marketing materials, and beyond. Without wasting time, let delve into top 10 LLM use-cases:
1. Marketing and Advertising
Personalized marketing: LLMs can be used to generate personalized marketing content, such as email campaigns and social media posts. This can help businesses to reach their target customers more effectively and efficiently. For example, an LLM could be used to generate a personalized email campaign for customers who have recently abandoned their shopping carts. The email campaign could include information about the products that the customer was interested in, as well as special offers and discounts.
Chatbots: LLMs can be used to create chatbots that can interact with customers in a natural way. This can help businesses to provide customer service 24/7 without having to hire additional staff. For example, an LLM could be used to create a chatbot that can answer customer questions about products, services, and shipping.
Content creation: LLMs can be used to create marketing content, such as blog posts, articles, and social media posts. This content can be used to attract attention, engage customers, and promote products and services. For example, an LLM could be used to generate a blog post about a new product launch or to create a social media campaign that encourages customers to share their experiences with the product.
Targeting ads: LLMs can be used to target ads to specific audiences. This can help businesses to reach their target customers more effectively and efficiently. For example, an LLM could be used to target ads to customers who have shown interest in similar products or services.
Measuring the effectiveness of marketing campaigns: LLMs can be used to measure the effectiveness of marketing campaigns by analyzing customer data and social media activity. This information can be used to improve future marketing campaigns.
Generating creative text formats: LLMs can be used to generate different creative text formats, such as poems, code, scripts, musical pieces, email, letters, etc. This can be used to create engaging and personalized marketing content.
Here are some other use cases for large language models in marketing and advertising:
Content creation: LLMs can be used to create marketing content, such as blog posts, articles, and social media posts. This content can be used to attract attention, engage customers, and promote products and services.
Measuring the effectiveness of marketing campaigns: LLMs can be used to measure the effectiveness of marketing campaigns by analyzing customer data and social media activity. This information can be used to improve future marketing campaigns.
Targeting ads: LLMs can be used to target ads to specific audiences. This can help businesses to reach their target customers more effectively and efficiently.
10 industries and LLM Use-Cases
2. Retail and eCommerce
A large language model can be used to analyze customer data, such as past purchases, browsing history, and social media activity, to identify patterns and trends. This information can then be used to generate personalized recommendations for products and services. For example, an LLM could be used to recommend products to customers based on their interests, needs, and budget.
Here are some other use cases for large language models in retail and eCommerce:
Answering customer inquiries: LLMs can be used to answer customer questions about products, services, and shipping. This can help to free up human customer service representatives to handle more complex issues.
Assisting with purchases: LLMs can be used to guide customers through the purchase process, such as by helping them to select products, add items to their cart, and checkout.
Fraud detection: LLMs can be used to identify fraudulent activity, such as credit card fraud or identity theft. This can help to protect businesses from financial losses.
3. Education
Large language models can be used to create personalized learning experiences for students. This can help students to learn at their own pace and focus on the topics that they are struggling with. For example, an LLM could be used to create a personalized learning plan for a student who is struggling with math. The plan could include specific exercises and activities that are tailored to the student’s needs.
Answering student questions
Large language models can be used to answer student questions in a natural way. This can help students to learn more effectively and efficiently. For example, an LLM could be used to answer a student’s question about the history of the United States. The LLM could provide a comprehensive and informative answer, even if the question is open-ended or challenging.
Generating practice problems and quizzes
Large language models can be used to generate practice problems and quizzes for students. This can help students to review the material that they have learned and prepare for exams. For example, an LLM could be used to generate a set of practice problems for a student who is taking a math test. The problems would be tailored to the student’s level of understanding and would help the student to identify any areas where they need more practice.
Here are some other use cases for large language models in education:
Grading student work: LLMs can be used to grade student work, such as essays and tests. This can help teachers to save time and focus on other aspects of teaching.
Creating virtual learning environments: LLMs can be used to create virtual learning environments that can be accessed by students from anywhere. This can help students to learn at their own pace and from anywhere in the world.
Translating textbooks and other educational materials: LLMs can be used to translate textbooks and other educational materials into different languages. This can help students to access educational materials in their native language.
4. Healthcare
Large language models (LLMs) are being used in healthcare to improve the diagnosis, treatment, and prevention of diseases. Here are some of the ways that LLMs are being used in healthcare:
Medical diagnosis: LLMs can be used to analyze medical records and images to help diagnose diseases. For example, an LLM could be used to identify patterns in medical images that are indicative of a particular disease.
Patient monitoring: LLMs can be used to monitor patients’ vital signs and other health data to identify potential problems early on. For example, an LLM could be used to track a patient’s heart rate and blood pressure to identify signs of a heart attack.
Drug discovery: LLMs can be used to analyze scientific research to identify new drug targets and to predict the effectiveness of new drugs. For example, an LLM could be used to analyze the molecular structure of a disease-causing protein to identify potential drug targets.
Personalized medicine: LLMs can be used to personalize treatment plans for patients by taking into account their individual medical history, genetic makeup, and lifestyle factors. For example, an LLM could be used to recommend a specific drug to a patient based on their individual risk factors for a particular disease.
Virtual reality training: LLMs can be used to create virtual reality training environments for healthcare professionals. This can help them to learn new skills and to practice procedures without putting patients at risk.
5. Finance
Large language models (LLMs) are being used in finance to improve the efficiency, accuracy, and transparency of financial markets. Here are some of the ways that LLMs are being used in finance:
Financial analysis: LLMs can be used to analyze financial reports, news articles, and other financial data to help financial analysts make informed decisions. For example, an LLM could be used to identify patterns in financial data that could indicate a change in the market.
Risk assessment: LLMs can be used to assess the risk of lending money to borrowers or investing in a particular company. For example, an LLM could be used to analyze a borrower’s credit history and financial statements to assess their risk of defaulting on a loan.
Trading: LLMs can be used to analyze market data to help make improved trading decisions. For example, an LLM could be used to identify trends in market prices and to predict future price movements.
Fraud detection: LLMs can be used to detect fraudulent activity, such as money laundering or insider trading. For example, an LLM could be used to identify patterns in financial transactions that are indicative of fraud.
Compliance: LLMs can be used to help financial institutions comply with regulations. For example, an LLM could be used to identify potential violations of anti-money laundering regulations.
6. Law
Technology has greatly transformed the legal field, streamlining tasks like research and document drafting that once consumed lawyers’ time.
Legal research: LLMs can be used to search and analyze legal documents, such as case law, statutes, and regulations. This can help lawyers to find relevant information more quickly and easily. For example, an LLM could be used to search for all cases that have been decided on a particular legal issue.
Document drafting: LLMs can be used to draft legal documents, such as contracts, wills, and trusts. This can help lawyers to produce more accurate and consistent documents. For example, an LLM could be used to generate a contract that is tailored to the specific needs of the parties involved.
Legal analysis: LLMs can be used to analyze legal arguments and to identify potential weaknesses. This can help lawyers to improve their legal strategies. For example, an LLM could be used to analyze a precedent case and to identify the key legal issues that are relevant to the case at hand.
Litigation support: LLMs can be used to support litigation by providing information, analysis, and insights. For example, an LLM could be used to identify potential witnesses, to track down relevant evidence, or to prepare for cross-examination.
Compliance: LLMs can be used to help organizations comply with regulations by identifying potential violations and providing recommendations for remediation. For example, an LLM could be used to identify potential violations of anti-money laundering regulations.
The media and entertainment industry embraces a data-driven shift towards consumer-centric experiences, with LLMs poised to revolutionize personalization, monetization, and content creation.
Personalized recommendations: LLMs can be used to generate personalized recommendations for content, such as movies, TV shows, and news articles. This can be done by analyzing user preferences, consumption patterns, and social media signals.
Intelligent content creation and curation: LLMs can be used to generate engaging headlines, write compelling copy, and even provide real-time feedback on content quality. This can help media organizations to streamline content production processes and improve overall content quality.
Enhanced engagement and monetization: LLMs can be used to create interactive experiences, such as interactive storytelling and virtual reality. This can help media organizations to engage users in new and innovative ways.
Targeted advertising and content monetization: LLMs can be used to generate insights that inform precise ad targeting and content recommendations. This can help media organizations to maximize ad revenue.
Bigwigs with LLM – Netflix uses LLMs to generate personalized recommendations for its users. The New York Times uses LLMs to write headlines and summaries of its articles. The BBC uses LLMs to create interactive stories that users can participate in. Spotify uses LLMs to recommend music to its users.
8. Military
Synthetic training data: LLMs can be used to generate synthetic training data for military applications. This can be used to train machine learning models to identify objects and patterns in images and videos. For example, LLMs can be used to generate synthetic images of tanks, ships, and aircraft.
Natural language processing: LLMs can be used to process natural language text, such as reports, transcripts, and social media posts. This can be used to extract information, identify patterns, and generate insights. For example, LLMs can be used to extract information from a report on a military operation.
Machine translation: LLMs can be used to translate text from one language to another. This can be used to communicate with allies and partners, or to translate documents and media. For example, LLMs can be used to translate a military briefing from English to Arabic.
Chatbots: LLMs can be used to create chatbots that can interact with humans in natural language. This can be used to provide customer service, answer questions, or conduct research. For example, LLMs can be used to create a chatbot that can answer questions about military doctrine.
Cybersecurity: LLMs can be used to detect and analyze cyberattacks. This can be used to identify patterns of malicious activity, or to generate reports on cyberattacks. For example, LLMs can be used to analyze a network traffic log to identify a potential cyberattack.
9. HR
Recruitment: LLMs can be used to automate the recruitment process, from sourcing candidates to screening resumes. This can help HR teams to save time and money and to find the best candidates for the job.
Employee onboarding: LLMs can be used to create personalized onboarding experiences for new employees. This can help new employees to get up to speed quickly and feel more welcome.
Performance management: LLMs can be used to provide feedback to employees and to track their performance. This can help managers to identify areas where employees need improvement and to provide them with the support they need to succeed.
Training and development: LLMs can be used to create personalized training and development programs for employees. This can help employees to develop the skills they need to succeed in their roles.
Employee engagement: LLMs can be used to survey employees and to get feedback on their work experience. This can help HR teams to identify areas where they can improve the employee experience.
Here is a specific example of how LLMs are being used in HR today: The HR company, Mercer, is using LLMs to automate the recruitment process. This is done by using LLMs to screen resumes and to identify the best candidates for the job. This has helped Mercer to save time and money and to find the best candidates for their clients.
10. Fashion
How LLMs are being used in fashion today? The fashion brand, Zara, is using LLMs to generate personalized fashion recommendations for its users. This is done by analyzing user data, such as past purchases, social media activity, and search history. This has helped Zara to improve the accuracy and relevance of its recommendations and to increase customer satisfaction.
Personalized fashion recommendations: LLMs can be used to generate personalized fashion recommendations for users based on their style preferences, body type, and budget. This can be done by analyzing user data, such as past purchases, social media activity, and search history.
Trend forecasting: LLMs can be used to forecast fashion trends by analyzing social media data, news articles, and other sources of information. This can help fashion brands to stay ahead of the curve and create products that are in demand.
Design automation: LLMs can be used to automate the design process for fashion products. This can be done by generating sketches, patterns, and prototypes. This can help fashion brands to save time and money, and to create products that are more innovative and appealing.
Virtual try-on: LLMs can be used to create virtual try-on experiences for fashion products. This can help users to see how a product would look on them before they buy it. This can help to reduce the number of returns and improve the customer experience.
Customer service: LLMs can be used to provide customer service for fashion brands. This can be done by answering questions about products, processing returns, and resolving complaints. This can help to improve the customer experience and reduce the workload on customer service representatives.
Wrapping up
In conclusion, large language models (LLMs) are shaping a transformative landscape across various sectors, from marketing and healthcare to education and finance. With their capabilities in personalization, automation, and insight generation, LLMs are poised to redefine the way we work and interact in the digital age. As we continue to explore their vast potential, we anticipate breakthroughs, innovation, and efficiency gains that will drive us toward a brighter future.
Large language models (LLMs) are AI models that can generate text, translate languages, write different kinds of creative content, and answer your questions in an informative way. They are trained on massive amounts of text data, and they can learn to understand the nuances of human language.
In this blog, we will take a deep dive into LLMs, including their building blocks, such as embeddings, transformers, and attention. We will also discuss the different applications of LLMs, such as machine translation, question answering, and creative writing.
To test your knowledge of LLM terms, we have included a crossword or quiz at the end of the blog. So, what are you waiting for? Let’s crack the code of large language models!
LLMs are typically built using a transformer architecture. Transformers are a type of neural network that are well-suited for natural language processing tasks. They are able to learn long-range dependencies between words, which is essential for understanding the nuances of human language.
They are typically trained on clusters of computers or even on cloud computing platforms. The training process can take weeks or even months, depending on the size of the dataset and the complexity of the model.
20 Essential LLM Terms for Crafting Applications
1. Large language model (LLM)
Large language models (LLMs) are AI models that can generate text, translate languages, write different kinds of creative content, and answer your questions in an informative way. The building blocks of an LLM are embeddings, transformers, attention, and loss functions.
Embeddings are vectors that represent the meaning of words or phrases. Transformers are a type of neural network that is well-suited for NLP tasks. Attention is a mechanism that allows the LLM to focus on specific parts of the input text. The loss function is used to measure the error between the LLM’s output and the desired output. The LLM is trained to minimize the loss function.
2. OpenAI
OpenAI is a non-profit research company that develops and deploys artificial general intelligence (AGI) in a safe and beneficial way. AGI is a type of artificial intelligence that can understand and reason like a human being. OpenAI has developed a number of LLMs, including GPT-3, Jurassic-1 Jumbo, and DALL-E 2.
GPT-3 is a large language model that can generate text, translate languages, write different kinds of creative content, and answer your questions in an informative way. Jurassic-1 Jumbo is a larger language model that is still under development. It is designed to be more powerful and versatile than GPT-3. DALL-E 2 is a generative AI model that can create realistic images from text descriptions.
3. Generative AI
Generative AI is a type of AI that can create new content, such as text, images, or music. LLMs are a type of generative AI. They are trained on large datasets of text and code, which allows them to learn the patterns of human language. This allows them to generate text that is both coherent and grammatically correct.
Generative AI has a wide range of potential applications. It can be used to create new forms of art and entertainment, to develop new educational tools, and to improve the efficiency of businesses. It is still a relatively new field, but it is rapidly evolving.
4. ChatGPT
ChatGPT is a large language model (LLM) developed by OpenAI. It is designed to be used in chatbots. ChatGPT is trained on a massive dataset of text and code, which allows it to learn the patterns of human conversation. This allows it to hold conversations that are both natural and engaging. ChatGPT is also capable of answering questions, providing summaries of factual topics, and generating different creative text formats.
5. Bard
Bard is a large language model (LLM) developed by Google AI. It is still under development, but it has been shown to be capable of generating text, translating languages, and writing different kinds of creative content. Bard is trained on a massive dataset of text and code, which allows it to learn the patterns of human language. This allows it to generate text that is both coherent and grammatically correct. Bard is also capable of answering your questions in an informative way, even if they are open-ended, challenging, or strange.
6. Foundation models
Foundation models are a family of large language models (LLMs) developed by Google AI. They are designed to be used as a starting point for developing other AI models. Foundation models are trained on massive datasets of text and code, which allows them to learn the patterns of human language. This allows them to be used to develop a wide range of AI applications, such as chatbots, machine translation, and question-answering systems.
7. LangChain
LangChain is a text-to-image diffusion model that can be used to generate images from text descriptions. It is based on the Transformer model and is trained on a massive dataset of text and images. LangChain is still under development, but it has the potential to be a powerful tool for creative expression and problem-solving.
8. Llama Index
Llama Index is a data framework for large language models (LLMs). It provides tools to ingest, structure, and access private or domain-specific data. LlamaIndex can be used to connect LLMs to a variety of data sources, including APIs, PDFs, documents, and SQL databases. It also provides tools to index and query data, so that LLMs can easily access the information they need.
Llama Index is a relatively new project, but it has already been used to build a number of interesting applications. For example, it has been used to create a chatbot that can answer questions about the stock market, and a system that can generate creative text formats, like poems, code, scripts, musical pieces, email, and letters.
9. Redis
Redis is an in-memory data store that can be used to store and retrieve data quickly. It is often used as a cache for web applications, but it can also be used for other purposes, such as storing embeddings. Redis is a popular choice for NLP applications because it is fast and scalable.
10. Streamlit
Streamlit is a framework for creating interactive web apps. It is easy to use and does not require any knowledge of web development. Streamlit is a popular choice for NLP applications because it allows you to quickly and easily build web apps that can be used to visualize and explore data.
11. Cohere
Cohere is a large language model (LLM) developed by Google AI. It is known for its ability to generate human-quality text. Cohere is trained on a massive dataset of text and code, which allows it to learn the patterns of human language. This allows it to generate text that is both coherent and grammatically correct. Cohere is also capable of translating languages, writing different kinds of creative content, and answering your questions in an informative way.
12. Hugging Face
Hugging Face is a company that develops tools and resources for NLP. It offers a number of popular open-source libraries, including Transformer models and datasets. Hugging Face also hosts a number of online communities where NLP practitioners can collaborate and share ideas.
LLM Crossword
13. Midjourney
Midjourney is a LLM developed by Midjourney. It is a text-to-image AI platform that uses a large language model (LLM) to generate images from natural language descriptions. The user provides a prompt to Midjourney, and the platform generates an image that matches the prompt. Midjourney is still under development, but it has the potential to be a powerful tool for creative expression and problem-solving.
14. Prompt Engineering
Prompt engineering is the process of crafting prompts that are used to generate text with LLMs. The prompt is a piece of text that provides the LLM with information about what kind of text to generate.
Prompt engineering is important because it can help to improve the performance of LLMs. By providing the LLM with a well-crafted prompt, you can help the model to generate more accurate and creative text. Prompt engineering can also be used to control the output of the LLM. For example, you can use prompt engineering to generate text that is similar to a particular style of writing, or to generate text that is relevant to a particular topic.
When crafting prompts for LLMs, it is important to be specific, use keywords, provide examples, and be patient. Being specific helps the LLM to generate the desired output, but being too specific can limit creativity.
Using keywords helps the LLM focus on the right topic, and providing examples helps the LLM learn what you are looking for. It may take some trial and error to find the right prompt, so don’t give up if you don’t get the desired output the first time.
Embeddings are a type of vector representation of words or phrases. They are used to represent the meaning of words in a way that can be understood by computers. LLMs use embeddings to learn the relationships between words.
Embeddings are important because they can help LLMs to better understand the meaning of words and phrases, which can lead to more accurate and creative text generation. Embeddings can also be used to improve the performance of other NLP tasks, such as natural language understanding and machine translation.
Fine-tuning is the process of adjusting the parameters of a large language model (LLM) to improve its performance on a specific task. Fine-tuning is typically done by feeding the LLM a dataset of text that is relevant to the task.
For example, if you want to fine-tune an LLM to generate text about cats, you would feed the LLM a dataset of text that contains information about cats. The LLM will then learn to generate text that is more relevant to the task of generating text about cats.
Fine-tuning can be a very effective way to improve the performance of an LLM on a specific task. However, it can also be a time-consuming and computationally expensive process.
17. Vector databases
Vector databases are a type of database that is optimized for storing and querying vector data. Vector data is data that is represented as a vector of numbers. For example, an embedding is a vector that represents the meaning of a word or phrase.
Vector databases are often used to store embeddings because they can efficiently store and retrieve large amounts of vector data. This makes them well-suited for tasks such as natural language processing (NLP), where embeddings are often used to represent words and phrases.
Vector databases can be used to improve the performance of fine-tuning by providing a way to store and retrieve large datasets of text that are relevant to the task. This can help to speed up the fine-tuning process and improve the accuracy of the results.
18. Natural Language Processing (NLP)
Natural Language Processing (NLP) is a field of computer science that deals with the interaction between computers and human (natural) languages. NLP tasks include text analysis, machine translation, and question answering. LLMs are a powerful tool for NLP. NLP is a complex field that covers a wide range of tasks. Some of the most common NLP tasks include:
Text analysis: This involves extracting information from text, such as the sentiment of a piece of text or the entities that are mentioned in the text.
For example, an NLP model could be used to determine whether a piece of text is positive or negative, or to identify the people, places, and things that are mentioned in the text.
Machine translation: This involves translating text from one language to another.
For example, an NLP model could be used to translate a news article from English to Spanish.
Question answering: This involves answering questions about text.
For example, an NLP model could be used to answer questions about the plot of a movie or the meaning of a word.
Speech recognition: This involves converting speech into text.
For example, an NLP model could be used to transcribe a voicemail message.
Text generation: This involves generating text, such as news articles or poems.
For example, an NLP model could be used to generate a creative poem or a news article about a current event.
19. Tokenization
Tokenization is the process of breaking down a piece of text into smaller units, such as words or subwords. Tokenization is a necessary step before LLMs can be used to process text. When text is tokenized, each word or subword is assigned a unique identifier. This allows the LLM to track the relationships between words and phrases.
There are many different ways to tokenize text. The most common way is to use word boundaries. This means that each word is a token. However, some LLMs can also handle subwords, which are smaller units of text that can be combined to form words.
For example, the word “cat” could be tokenized as two subwords: “c” and “at”. This would allow the LLM to better understand the relationships between words, such as the fact that “cat” is related to “dog” and “mouse”.
20. Transformer models
Transformer models are a type of neural network that is well-suited for NLP tasks. They are able to learn long-range dependencies between words, which is essential for understanding the nuances of human language. Transformer models work by first creating a representation of each word in the text. This representation is then used to calculate the relationship between each word and the other words in the text.
The Transformer model is a powerful tool for NLP because it can learn the complex relationships between words and phrases. This allows it to perform NLP tasks with a high degree of accuracy. For example, a Transformer model could be used to translate a sentence from English to Spanish while preserving the meaning of the sentence.
Embeddings transform raw data into meaningful vectors, revolutionizing how AI systems understand and process language,” notes industry expert Frank Liu. These are the cornerstone of large language models (LLM) which are trained on vast datasets, including books, articles, websites, and social media posts.
By learning the intricate statistical relationships between words, phrases, and sentences, LLMs generate text that mirrors the patterns found in their training data.
This comprehensive guide delves into the world of embeddings, explaining their various types, applications, and future advancements. Whether you’re a beginner or an expert, this exploration will provide a deep understanding of how embeddings enhance AI capabilities, making LLMs more efficient and effective in processing natural language data.
Join us as we uncover their essential role in the evolution of AI.
What are Embeddings?
Embeddings are numerical representations of words or phrases in a high-dimensional vector space. These representations map discrete objects (such as words, sentences, or images) into a continuous latent space, capturing their relationship. They are a fundamental component in the field of Natural Language Processing (NLP) and machine learning.
By converting words into vectors, they enable machines to understand and process human language in a more meaningful way. Think of embeddings as a way to organize a library. Instead of arranging books alphabetically, you place similar books close to each other based on their content.
Similarly, embeddings position words into a vector in a high-dimensional latent space so that words with similar meanings are closer together. This helps ML models understand and process text more effectively. For example, the vector for “apple” would be closer to “fruit” than to “car”.
They translate textual data into vectors within a continuous latent space, enabling the measurement of similarities through metrics like cosine similarity and Euclidean distance.
This transformation is crucial because it enables models to perform mathematical operations on text data, thereby facilitating tasks such as clustering, classification, and regression.
It helps to interpret and generate human language with greater accuracy and context-awareness. Techniques such as Azure OpenAI facilitate their creation, empowering language models with enhanced capabilities.
Embeddings are used to represent words as vectors of numbers, which can then be used by machine learning models to understand the meaning of text. These have evolved over time from the simplest one-hot encoding approach to more recent semantic approaches.
When converting data into meaningful numerical representations, different types of embeddings help machines process and interpret information more effectively. Let’s explore the key types of embeddings and how they power various AI applications.
Word Embeddings
Word embeddings represent individual words as vectors of numbers in a high-dimensional space. These vectors capture semantic meanings and relationships between words, making them fundamental in NLP tasks.
By positioning words in such a space, it places similar words closer together, reflecting their semantic relationships. This allows machine learning models to understand and process text more effectively.
Word embeddings help classify texts into categories like spam detection or sentiment analysis by understanding the context of the words used. They enable the generation of concise summaries by capturing the essence of the text.
It allows models to provide accurate answers based on the context of the query and facilitates the translation of text from one language to another by understanding the semantic meaning of words and phrases.
Sentence embeddings represent entire sentences as vectors, capturing the context and meaning of the sentence as a whole. Unlike word embeddings, which only capture individual word meanings, sentence embeddings consider the relationships between words within a sentence, providing a more comprehensive understanding of the text.
These are used to categorize larger text units like sentences or entire documents, making the classification process more accurate. They help generate summaries by understanding the overall context and key points of the document.
Models are also enabled to answer questions based on the context of entire sentences or documents. They improve translation quality by preserving the context and meaning of sentences during translation.
Graph Embeddings
Graph embeddings represent nodes in a graph as vectors, capturing the relationships and structures within the graph. These are particularly useful for tasks that involve network analysis and relational data.
For instance, in a social network graph, it can represent users and their connections, enabling tasks like community detection, link prediction, and recommendation systems.
By transforming the complex relationships in graphs into numerical vectors, ML models can process and analyze graph data efficiently. One of the key advantages is their ability to preserve the structural information of the graph, which is critical for accurately capturing the relationships between nodes.
This capability makes them suitable for a wide range of applications beyond social networks, such as biological network analysis, fraud detection, and knowledge graph completion.
Tools like DeepWalk and Node2Vec have been developed to generate graph embeddings by learning from the graph’s structure, further enhancing the ability to analyze and interpret complex graph data.
Image and Audio Embeddings
Images are represented as vectors by extracting features from them, while audio signals are converted into numerical representations by embeddings. These are crucial for tasks involving visual and auditory data.
Embeddings for images are used in tasks like image classification, object detection, and image retrieval, while those for audio are applied in speech recognition, music genre classification, and audio search.
These are powerful tools in NLP and machine learning, enabling machines to understand and process various forms of data. By transforming text, images, and audio into numerical representations, they enhance the performance of numerous tasks, making them indispensable in the field of artificial intelligence.
Choosing the right embedding type depends on the nature of your data and the task at hand. You can use:
Word embeddings to capture individual word meanings
Sentence and document embeddings for a broader context
Graph embeddings to analyze networks and connections
Image and audio embeddings for tasks like classification and retrieval
Understanding the strengths of each embedding type ensures you select the best approach for optimizing your AI models and improving performance across different applications.
Classic Approaches to Embeddings
In the early days of natural language processing (NLP), embeddings were simply one-hot encoded. Zero vector represents each word with a single one at the index that matches its position in the vocabulary.
1. One-hot Encoding
One-hot encoding is the simplest approach to embedding words. It represents each word as a vector of zeros, with a single one at the index corresponding to the word’s position in the vocabulary. For example, if we have a vocabulary of 10,000 words, then the word “cat” would be represented as a vector of 10,000 zeros, with a single one at index 0.
One-hot encoding is a simple and efficient way to represent words as vectors of numbers. However, it does not take into account the context in which words are used. This can be a limitation for tasks such as text classification and sentiment analysis, where the context of a word can be important for determining its meaning.
For example, the word “cat” can have multiple meanings, such as “a small furry mammal” or “to hit someone with a closed fist.” In one-hot encoding, these two meanings would be represented by the same vector. This can make it difficult for machine learning models to learn the correct meaning of words.
2. TF-IDF
TF-IDF (term frequency-inverse document frequency) is a statistical measure that is used to quantify the importance of process and creates a pre-trained model that can be fine-tuned using a smaller dataset for specific tasks.
This reduces the need for labeled data and training time while achieving good results in natural language processing tasks of a word in a document. It is a widely used technique in NLP for tasks such as text classification, information retrieval, and machine translation.
TF-IDF is calculated by multiplying the term frequency (TF) of a word in a document by its inverse document frequency (IDF). TF measures the number of times a word appears in a document, while IDF measures how rare a word is in a corpus of documents.
The TF-IDF score for a word is high when the word appears frequently in a document and when the word is rare in the corpus. This means that TF-IDF scores can be used to identify words that are important in a document, even if they do not appear very often.
Understanding TF-IDF with an Example
Here is an example of how TF-IDF can be used to create word embeddings. Let’s say we have a corpus of documents about cats. We can calculate the TF-IDF scores for all of the words in the corpus. The words with the highest TF-IDF scores will be the words that are most important in the corpus, such as “cat,” “dog,” “fur,” and “meow.”
We can then create a vector for each word, where each element of the vector represents the TF-IDF score for that word. The TF-IDF vector for the word “cat” would be high, while the TF-IDF vector for the word “dog” would also be high, but not as high as the TF-IDF vector for the word “cat.”
The TF-IDF can then be used by a machine-learning model to classify documents about cats. The model would first create a vector representation of a new document. Then, it would compare the vector representation of the new document to the TF-IDF word embeddings. The document would be classified as a “cat” document if its vector representation is most similar to the TF-IDF word embeddings for “cat.”
Count-based and TF-IDF
To address the limitations of one-hot encoding, count-based and TF-IDF techniques were developed. These techniques take into account the frequency of words in a document or corpus.
Count-based techniques simply count the number of times each word appears in a document. TF-IDF techniques take into account both the frequency of a word and its inverse document frequency.
Count-based and TF-IDF techniques are more effective than one-hot encoding at capturing the context in which words are used. However, they still do not capture the semantic meaning of words.
Capturing Local Context with N-grams
To capture the semantic meaning of words, n-grams can be used. N-grams are sequences of n-words. For example, a 2-gram is a sequence of two words.
N-grams can be used to create a vector representation of a word. The vector representation is based on the frequencies of the n-grams that contain the word.
N-grams are a more effective way to capture the semantic meaning of words than count-based or TF-IDF techniques. However, they still have some limitations. For example, they are not able to capture long-distance dependencies between words.
Semantic Encoding Techniques
Semantic encoding techniques are the most recent approach to embedding words. These techniques use neural networks to learn vector representations of words that capture their semantic meaning.
One of the most popular semantic encoding techniques is Word2Vec. Word2Vec uses a neural network to predict the surrounding words in a sentence. The network learns to associate words that are semantically similar with similar vector representations.
Semantic encoding techniques are the most effective way to capture the semantic meaning of words. They are able to capture long-distance dependencies between words, and they are able to learn the meaning of words even if they have never been seen before. Here are some major semantic encoding techniques;
1. ELMo: Embeddings from Language Models
ELMo is a type of word embedding that incorporates both word-level characteristics and contextual semantics. It is created by taking the outputs of all layers of a deep bidirectional language model (bi-LSTM) and combining them in a weighted fashion. This allows ELMo to capture the meaning of a word in its context, as well as its own inherent properties.
The intuition behind ELMo is that the higher layers of the bi-LSTM capture context, while the lower layers capture syntax. This is supported by empirical results, which show that ELMo outperforms other word embeddings on tasks such as POS tagging and word sense disambiguation.
ELMo is trained to predict the next word in a sequence of words, a task called language modeling. This means that it has a good understanding of the relationships between words. When assigning an embedding to a word, ELMo takes into account the words that surround it in the sentence. This allows it to generate different vectors for the same word depending on its context.
Understanding ELMo with Example
For example, the word “play” can have multiple meanings, such as “to perform” or “a game.” In standard word embeddings, each instance of the word “play” would have the same representation.
However, ELMo can distinguish between these different meanings by taking into account the context in which the word appears. In the sentence “The Broadway play premiered yesterday,” for example, ELMo would assign the word “play” a vector that reflects its meaning as a theater production.
ELMo has been shown to be effective for a variety of natural language processing tasks, including sentiment analysis, question answering, and machine translation. It is a powerful tool that can be used to improve the performance of NLP models.
2. GloVe
GloVe is a statistical method for learning word embeddings from a corpus of text. GloVe is similar to Word2Vec, but it uses a different approach to learning the vector representations of words.
How does GloVe work?
GloVe works by creating a co-occurrence matrix. The co-occurrence matrix is a table that shows how often two words appear together in a corpus of text. For example, the co-occurrence matrix for the words “cat” and “dog” would show how often the words “cat” and “dog” appear together in a corpus of text.
GloVe then uses a machine learning algorithm to learn the vector representations of words from the co-occurrence matrix. The machine learning algorithm learns to associate words that appear together frequently with similar vector representations.
Word2Vec is a semantic encoding technique that is used to learn vector representations of words. Word vectors represent word meaning and can enhance machine learning models for tasks like text classification, sentiment analysis, and machine translation.
Word2Vec works by training a neural network on a corpus of text. The neural network is trained to predict the surrounding words in a sentence. The network learns to associate words that are semantically similar with similar vector representations.
There are two main variants of Word2Vec:
Continuous Bag-of-Words (CBOW): The CBOW model predicts the surrounding words in a sentence based on the current word. For example, the model might be trained to predict the words “the” and “dog” given the word “cat”.
Skip-gram: The skip-gram model predicts the current word based on the surrounding words in a sentence. For example, the model might be trained to predict the word “cat” given the words “the” and “dog”.
Key Application of Word2Vec
Word2Vec has been shown to be effective for a variety of tasks, including;
Text Classification: Word2Vec can be used to train a classifier to classify text into different categories, such as news articles, product reviews, and social media posts.
Sentiment Analysis: Word2Vec can be used to train a classifier to determine the sentiment of text, such as whether it is positive, negative, or neutral.
Machine Translation: Word2Vec can be used to train a machine translation model to translate text from one language to another.
Word2Vec vs Dense Word Embeddings
Word2Vec is a neural network model that learns to represent words as vectors of numbers. Word2Vec is trained on a large corpus of text, and it learns to predict the surrounding words in a sentence.
Word2Vec can be used to create dense word embeddings that are vectors that have a fixed size, regardless of the size of the vocabulary. This makes them easy to use with machine learning models.
These have been shown to be effective in a variety of NLP tasks, such as text classification, sentiment analysis, and machine translation.
Understanding Variations in Text Embeddings
An established process can lead to a text embedding to suggest similar words. This means that every time you input the same text into the model, the same results are produced.
Most traditional embedding models like Word2Vec, GloVe, or fastText operate in this manner leading a text embedding to suggest similar words for similar inputs. However, the results can vary in the following cases:
Random Initialization: Some models might include layers or components with randomly initialized weights that aren’t set to a fixed value or re-used across sessions. This can result in different outputs each time.
Contextual Embeddings: Models like BERT or GPT generate these where the embedding for the same word or phrase can differ based on its surrounding context. If you input the phrase in different contexts, the embeddings will vary.
Non-deterministic Settings: Some neural network configurations or training settings can introduce non-determinism. For example, if dropout (randomly dropping units during training to prevent overfitting) is applied during the embedding generation, it could lead to variations.
Model Updates: If the model itself is updated or retrained, even with the same architecture and training data, slight differences in training dynamics (like changes in batch ordering or hardware differences) can lead to different model parameters and thus different embeddings.
Floating-Point Precision: Differences in floating-point precision, which can vary based on the hardware (like CPU vs. GPU), can also lead to slight variations in the computed vector representations.
So, while many models are deterministic, several factors can lead to differences in the embeddings of the same text under different conditions or configurations.
Real-Life Examples in Action
Vector embeddings have become an integral part of numerous real-world applications, enhancing the accuracy and efficiency of various tasks. Here are some compelling examples showcasing their power:
E-commerce Personalized Recommendations
Platforms use these vector representations to offer personalized product suggestions. By representing products and users as vectors in a high-dimensional space, e-commerce platforms can analyze user behavior, preferences, and purchase history to recommend products that align with individual tastes.
This method enhances the shopping experience by providing relevant suggestions, driving sales, and customer satisfaction. For instance, embeddings help platforms like Amazon and Zalando understand user preferences and deliver tailored product recommendations.
Chatbots and Virtual Assistants
Embeddings enable better understanding and processing of user queries. Modern chatbots and virtual assistants, such as those powered by GPT-3 or other large language models, utilize these to comprehend the context and semantics of user inputs.
This allows them to generate accurate and contextually relevant responses, improving user interaction and satisfaction. For example, chatbots in customer support can efficiently resolve queries by understanding the user’s intent and providing precise answers.
Companies analyze social media posts to gauge public sentiment. By converting text data into vector representations, businesses can perform sentiment analysis to understand public opinion about their products, services, or brand.
This analysis helps in tracking customer satisfaction, identifying trends, and making informed marketing decisions. Tools powered by embeddings can scan vast amounts of social media data to detect positive, negative, or neutral sentiments, providing valuable insights for brands.
Healthcare Applications
Embeddings assist in patient data analysis and diagnosis predictions. In the healthcare sector, these are used to analyze patient records, medical images, and other health data to aid in diagnosing diseases and predicting patient outcomes.
For instance, specialized tools like Google’s Derm Foundation focus on dermatology, enabling accurate analysis of skin conditions by identifying critical features in medical images. These help doctors make informed decisions, improving patient care and treatment outcomes.
These examples illustrate the transformative impact of embeddings across various industries, showcasing their ability to enhance personalization, understanding, and analysis in diverse applications. By leveraging this tool, businesses can unlock deeper insights and deliver more effective solutions to their customers.
LLMs are typically built using a transformer architecture. Transformers are a type of neural network that is well-suited for NLP tasks. They are able to learn long-range dependencies between words, which is essential for understanding the nuances of human language.
LLMs are so large that they cannot be run on a single computer. They are typically trained on clusters of computers or even on cloud computing platforms. The training process can take weeks or even months, depending on the size of the dataset and the complexity of the model.
One of the key technologies that makes LLMs so powerful is vector embeddings. These embeddings allow the model to represent words, sentences, and even entire documents as numerical vectors in a high-dimensional space. By doing so, LLMs can efficiently process meaning, recognize patterns, and retrieve relevant information.
LLMs rely on multiple core components that work together to process and generate human-like text. One of the most fundamental building blocks is vector embeddings. However, embeddings are just one part of a much larger system that enables LLMs to understand, learn, and generate language effectively.
To fully grasp how LLMs function, it is essential to explore the other key components that power them. Below is an explanation of these building blocks of LLMs.
1. Embeddings
These are continuous vector representations of words or tokens that capture their semantic meanings in a high-dimensional space. They allow the model to convert discrete tokens into a format that can be processed by the neural network. LLMs learn embeddings during training to capture relationships between words, like synonyms or analogies.
2. Tokenization
Tokenization is the process of converting a sequence of text into individual words, subwords, or tokens that the model can understand. LLMs use subword algorithms like BPE or wordpiece to split text into smaller units that capture common and uncommon words. This approach helps to limit the model’s vocabulary size while maintaining its ability to represent any text sequence.
3. Attention
Attention mechanisms in LLMs, particularly the self-attention mechanism used in transformers, allow the model to weigh the importance of different words or phrases.
By assigning different weights to the tokens in the input sequence, the model can focus on the most relevant information while ignoring less important details. This ability to selectively focus on specific parts of the input is crucial for capturing long-range dependencies and understanding the nuances of natural language.
4. Pre-training
Pre-training is the process of training an LLM on a large dataset, usually unsupervised or self-supervised, before fine-tuning it for a specific task. During pretraining, the model learns general language patterns, relationships between words, and other foundational knowledge.
The process creates a pre-trained model that can be fine-tuned using a smaller dataset for specific tasks. This reduces the need for labeled data and training time while achieving good results in natural language processing tasks (NLP).
5. Transfer learning
Transfer learning is the technique of leveraging the knowledge gained during pretraining and applying it to a new, related task. In the context of LLMs, transfer learning involves fine-tuning a pre-trained model on a smaller, task-specific dataset to achieve high performance on that task.
The benefit of transfer learning is that it allows the model to benefit from the vast amount of general language knowledge learned during pretraining, reducing the need for large labeled datasets and extensive training for each new task.
While the building blocks of LLMs work together to enable powerful language understanding and generation, they are not without challenges. Since embeddings are the most crucial foundation of these models, let’s explore the key challenges associated with them.
Challenges and Limitations of Embeddings
Vector embeddings, while powerful, come with several inherent challenges and limitations that can impact their effectiveness in various applications. Understanding these challenges is crucial for optimizing their use in real-world scenarios.
Context Sensitivity
Capturing the full context of words or phrases remains challenging, especially when it comes to polysemy (words with multiple meanings) and varying contexts. Enhancing context sensitivity through advanced models like BERT or GPT-3, which consider the surrounding text to better understand the intended meaning, is crucial. Fine-tuning these models on domain-specific data can also help improve context sensitivity.
Scalability Issues
Handling large datasets can be difficult due to the high dimensionality of embeddings, leading to increased storage and retrieval times. Utilizing vector databases like Milvus, Pinecone, and Faiss, which are optimized for storing and querying high-dimensional vector data, can address these challenges.
These databases use techniques like vector compression and approximate nearest neighbor search to manage large datasets efficiently.
Training embeddings is resource-intensive, requiring significant computational power and time, especially for large-scale models. Leveraging pre-trained models and fine-tuning them on specific tasks can reduce computational costs. Using cloud-based services that offer scalable compute resources can also help manage these costs effectively.
Ethical Challenges
Addressing biases and non-deterministic outputs in training data is crucial to ensure fairness, transparency and consistency in AI applications.
Non-deterministic Outputs: Variability in results due to random initialization or training processes can hinder reproducibility. Using deterministic settings and seed initialization can improve consistency.
Bias in Embeddings: Models can inherit biases from training data, impacting fairness. By employing bias detection, mitigation strategies, and regular audits, ethical AI practices can be followed.
Future Advancement
Future advancements in embedding techniques are set to enhance their accuracy and efficiency significantly. New techniques are continually being developed to capture complex semantic relationships and contextual nuances better.
Techniques like ELMo, BERT, and GPT-3 have already made substantial strides in this field by providing deeper contextual understanding and more precise language representations. These advancements aim to improve the overall performance of AI applications, making them more intelligent and capable of understanding human language intricately.
Their integration with generative AI models is poised to revolutionize AI applications further. This combination allows for improved contextual understanding and the generation of more coherent and contextually relevant text.
For instance, models like GPT-3 enable the creation of high-quality text that captures nuanced understanding, enhancing applications in content creation, chatbots, and virtual assistants.
As these technologies continue to evolve, they promise to deliver richer, more sophisticated AI solutions that can handle a variety of data types, including text, images, and audio, ultimately leading to more comprehensive and insightful applications.
Large language models (LLMs) are one of the most exciting developments in artificial intelligence. They have the potential to revolutionize a wide range of industries, from healthcare to customer service to education. But in order to realize this potential, we need more people who know how to build and deploy LLM applications.
That’s where this blog comes in. In this blog, we’re going to discuss the importance of learning to build your own LLM application, and we’re going to provide a roadmap for becoming a large language model developer.
We believe this blog will be a valuable resource for anyone interested in learning more about LLMs and how to build and deploy Large Language Model applications. So, whether you’re a student, a software engineer, or a business leader, we encourage you to read on!
Why do I Need to Build a Custom LLM Application?
Here are some of the benefits of learning to build your own LLM application:
You’ll be able to create innovative new applications that can solve real-world problems.
You’ll be able to use LLMs to improve the efficiency and effectiveness of your existing applications.
You’ll be able to gain a competitive edge in your industry.
You’ll be able to contribute to the development of this exciting new field of artificial intelligence.
If you’re interested in learning more about LLMs and how to build and deploy LLM applications, then this blog is for you. We’ll provide you with the information you need to get started on your journey to becoming a large language model developer step by step.
1. Introduction to Generative AI
Generative AI is a type of artificial intelligence that can create new content, such as text, images, or music. Large language models (LLMs) are a type of generative AI that can generate text that is often indistinguishable from human-written text. In today’s business world, Generative AI is being used in a variety of industries, such as healthcare, marketing, and entertainment.
Introduction to Generative AI – LLM Bootcamp Data Science Dojo
For example, in healthcare, generative AI is being used to develop new drugs and treatments, and to create personalized medical plans for patients. In marketing, generative AI is being used to create personalized advertising campaigns and to generate product descriptions. In entertainment, generative AI is being used to create new forms of art, music, and literature.
2. Emerging Architectures for LLM Applications
There are a number of emerging architectures for LLM applications, such as Transformer-based models, graph neural networks, and Bayesian models. These architectures are being used to develop new LLM applications in a variety of fields, such as natural language processing, machine translation, and healthcare.
Emerging architectures for llm applications – LLM Bootcamp Data Science Dojo
There are a number of emerging architectures for LLM applications, such as Transformer-based models, graph neural networks, and Bayesian models. These architectures are being used to develop new LLM applications in a variety of fields, such as natural language processing, machine translation, and healthcare.
For example, Transformer-based models are being used to develop new machine translation models that can translate text between languages more accurately than ever before. Graph neural networks are being used to develop new fraud detection models that can identify fraudulent transactions more effectively. Bayesian models are being used to develop new medical diagnosis models that can diagnose diseases more accurately.
3. Embeddings
Embeddings are a type of representation that is used to encode words or phrases into a vector space. This allows LLMs to understand the meaning of words and phrases in context.
Embeddings – LLM Bootcamp Data Science Dojo
Embeddings are used in a variety of LLM applications, such as machine translation, question answering, and text summarization. For example, in machine translation, embeddings are used to represent words and phrases in a way that allows LLMs to understand the meaning of the text in both languages.
In question answering, embeddings are used to represent the question and the answer text in a way that allows LLMs to find the answer to the question. In text summarization, embeddings are used to represent the text in a way that allows LLMs to generate a summary that captures the key points of the text.
4. Attention Mechanism and Transformers
The attention mechanism is a technique that allows LLMs to focus on specific parts of a sentence when generating text. Transformers are a type of neural network that uses the attention mechanism to achieve state-of-the-art results in natural language processing tasks.
Attention mechanism and transformers – LLM Bootcamp Data Science Dojo
The attention mechanism is used in a variety of LLM applications, such as machine translation, question answering, and text summarization. For example, in machine translation, the attention mechanism is used to allow LLMs to focus on the most important parts of the source text when generating the translated text.
In answering the question, the attention mechanism is used to allow LLMs to focus on the most important parts of the question when finding the answer. In text summarization, the attention mechanism is used to allow LLMs to focus on the most important parts of the text when generating the summary.
5. Vector Databases
Vector databases are a type of database that stores data in vectors. This allows LLMs to access and process data more efficiently.
Vector databases – LLM Bootcamp Data Science Dojo
Vector databases are used in a variety of LLM applications, such as machine learning, natural language processing, and recommender systems.
For example, in machine learning, vector databases are used to store the training data for machine learning models. In natural language processing, vector databases are used to store the vocabulary and grammar for natural language processing models. In recommender systems, vector databases are used to store the user preferences for different products and services.
6. Semantic Search
Semantic search is a type of search that understands the meaning of the search query and returns results that are relevant to the user’s intent. LLMs can be used to power semantic search engines, which can provide more accurate and relevant results than traditional keyword-based search engines.
Semantic search – LLM Bootcamp Data Science Dojo
Semantic search is used in a variety of industries, such as e-commerce, customer service, and research. For example, in e-commerce, semantic search is used to help users find products that they are interested in, even if they don’t know the exact name of the product.
In customer service, semantic search is used to help customer service representatives find the information they need to answer customer questions quickly and accurately. In research, semantic search is used to help researchers find relevant research papers and datasets.
7. Prompt Engineering
Prompt engineering is the process of creating prompts that are used to guide LLMs to generate text that is relevant to the user’s task. Prompts can be used to generate text for a variety of tasks, such as writing different kinds of creative content, translating languages, and answering questions.
Prompt engineering – LLM Bootcamp Data Science Dojo
Prompt engineering is used in a variety of LLM applications, such as creative writing, machine translation, and question answering. For example, in creative writing, prompt engineering is used to help LLMs generate different creative text formats, such as poems, code, scripts, musical pieces, email, letters, etc.
In machine translation, prompt engineering is used to help LLMs translate text between languages more accurately. In answering questions, prompt engineering is used to help LLMs find the answer to a question more accurately.
8. Fine-Tuning of Foundation Models
Foundation models are large language models that are pre-trained on massive datasets. Fine-tuning is the process of adjusting the parameters of a foundation model to make it better at a specific task. Fine-tuning can be used to improve the performance of LLMs on a variety of tasks, such as machine translation, question answering, and text summarization.
Fine-tuning of Foundation Models – LLM Bootcamp Data Science Dojo
Foundation models are pre-trained on massive datasets. Fine-tuning is the process of adjusting the parameters of a foundation model to make it better at a specific task. Fine-tuning is used to improve the performance of LLMs on a variety of tasks, such as machine translation, question answering, and text summarization.
For example, LLMs can be fine-tuned to translate text between specific languages, to answer questions about specific topics, or to summarize text in a specific style.
9. Orchestration Frameworks
Orchestration frameworks are tools that help developers to manage and deploy LLMs. These frameworks can be used to scale LLMs to large datasets and to deploy them to production environments.
Orchestration frameworks – LLM Bootcamp Data Science Dojo
Orchestration frameworks are used to manage and deploy LLMs. These frameworks can be used to scale LLMs to large datasets and to deploy them to production environments. For example, orchestration frameworks can be used to manage the training of LLMs, to deploy LLMs to production servers, and to monitor the performance of LLMs
10. LangChain
LangChain is a framework for building LLM applications. It provides a number of features that make it easy to build and deploy LLM applications, such as a pre-trained language model, a prompt engineering library, and an orchestration framework.
Langchain – LLM Bootcamp Data Science Dojo
Overall, LangChain is a powerful and versatile framework that can be used to create a wide variety of LLM-powered applications. If you are looking for a framework that is easy to use, flexible, scalable, and has strong community support, then LangChain is a good option.
11. Autonomous Agents
Autonomous agents are software programs that can act independently to achieve a goal. LLMs can be used to power autonomous agents, which can be used for a variety of tasks, such as customer service, fraud detection, and medical diagnosis.
Attention mechanism and transformers – LLM Bootcamp Data Science Dojo
12. LLM Ops
LLM Ops is the process of managing and operating LLMs. This includes tasks such as monitoring the performance of LLMs, detecting and correcting errors, and upgrading Large Language Models to new versions.
LLM Ops – LLM Bootcamp Data Science Dojo
13. Recommended Projects
Recommended projects – LLM Bootcamp Data Science Dojo
There are a number of recommended projects for developers who are interested in learning more about LLMs. These projects include:
Chatbots: LLMs can be used to create chatbots that can hold natural conversations with users. This can be used for a variety of purposes, such as customer service, education, and entertainment. For example, the Google Assistant uses LLMs to answer questions, provide directions, and control smart home devices.
Text generation: LLMs can be used to generate text, such as news articles, creative writing, and code. This can be used for a variety of purposes, such as marketing, content creation, and software development. For example, the OpenAI GPT-3 language model has been used to generate realistic-looking news articles and creative writing.
Translation: LLMs can be used to translate text from one language to another. This can be used for a variety of purposes, such as travel, business, and education. For example, the Google Translate app uses LLMs to translate text between over 100 languages.
Question answering: LLMs can be used to answer questions about a variety of topics. This can be used for a variety of purposes, such as research, education, and customer service. For example, the Google Search engine uses LLMs to provide answers to questions that users type into the search bar.
Code generation: LLMs can be used to generate code, such as Python scripts and Java classes. This can be used for a variety of purposes, such as software development and automation. For example, the GitHub Copilot tool uses LLMs to help developers write code more quickly and easily.
Data analysis: LLMs can be used to analyze large datasets of text and code. This can be used for a variety of purposes, such as fraud detection, risk assessment, and customer segmentation. For example, the Palantir Foundry platform uses LLMs to analyze data from a variety of sources to help businesses make better decisions.
Creative writing: LLMs can be used to generate creative text formats, such as poems, code, scripts, musical pieces, email, letters, etc. This can be used for a variety of purposes, such as entertainment, education, and marketing. For example, the Bard language model can be used to generate different creative text formats, such as poems, code, scripts, musical pieces, email, letters, etc.
LLM Bootcamp: Learn to Build Your Own Applications
Data Science Dojo’s Large Language Models Bootcamp will teach you everything you need to know to build and deploy your own LLM applications. You’ll learn about the basics of LLMs, how to train LLMs, and how to use LLMs to build a variety of applications.
The bootcamp will be taught by experienced instructors who are experts in the field of large language models. You’ll also get hands-on experience with LLMs by building and deploying your own applications.
If you’re interested in learning more about LLMs and how to build and deploy LLM applications, then I encourage you to enroll in Data Science Dojo’s Large Language Models Bootcamp. This bootcamp is the perfect way to get started on your journey to becoming a large language model developer.
The next generation of Language Model Systems (LLMs) and LLM chatbots are expected to offer improved accuracy, expanded language support, enhanced computational efficiency, and seamless integration with emerging technologies. These advancements indicate a higher level of versatility and practicality compared to the previous models.
While AI solutions do present potential benefits such as increased efficiency and cost reduction, it is crucial for businesses and society to thoroughly consider the ethical and social implications before widespread adoption.
Recent strides in LLMs have been remarkable, and their future appears even more promising. Although we may not be fully prepared, the future is already unfolding, demanding our adaptability to embrace the opportunities it presents.
Back to basics: Understanding large language models
LLM, standing for Large Language Model, represents an advanced language model that undergoes training on an extensive corpus of text data. By employing deep learning techniques, LLMs can comprehend and produce human-like text, making them highly versatile for a range of applications.
These include text completion, language translation, sentiment analysis, and much more. One of the most renowned LLMs is OpenAI’s GPT-3, which has received widespread recognition for its exceptional language generation capabilities.
Large language models knowledge test
Challenges in traditional AI chatbot development: Role of LLMs
The current practices for building AI chatbots have limitations when it comes to scalability. Initially, the process involves defining intents, collecting related utterances, and training an NLU model to predict user intents. As the number of intents increases, managing and disambiguating them becomes difficult.
Additionally, designing deterministic conversation flows triggered by detected intents becomes challenging, especially in complex scenarios that require multiple interconnected layers of chat flows and intent understanding. To overcome these challenges, Large Language Models (LLMs) come to the rescue.
Building an efficient LLM application using vector embeddings
Vector embeddings are a type of representation that can be used to capture the meaning of text. They are typically created by training a machine learning model on a large corpus of text. The model learns to associate each word with a vector of numbers. These numbers represent the meaning of the word in relation to other words in the corpus.
LLM chatbots can be built using vector embeddings by first creating a knowledge base of text chunks. Each text chunk should represent a distinct piece of information that can be queried. The text chunks should then be embedded into vectors using a vector embedding model. The resulting vector representations can then be stored in a vector database.
Break down your knowledge base into smaller, manageable chunks. Each chunk should represent a distinct piece of information that can be queried.
Gather data from various sources, such as Confluence documentation and PDF reports.
The chunks should be well-defined and have clear boundaries. This will make it easier to extract the relevant information when querying the knowledge base.
The chunks should be stored in a way that makes them easy to access. This could involve using a hierarchical file system or a database.
Step 2: Text into vectors
Use an embedding model to convert each chunk of text into a vector representation.
The embedding model should be trained on a large corpus of text. This will ensure that the vectors capture the meaning of the text.
The vectors should be of a fixed length. This will make it easier to store and query them.
Step 3: Store vector embeddings
Save the vector embeddings obtained from the embedding model in a Vector Database.
The Vector Database should be able to store and retrieve the vectors efficiently.
The Vector Database should also be able to index the vectors so that they can be searched by keyword.
Step 4: Preserve original text
Ensure you store the original text that corresponds to each vector embedding.
This text will be vital for retrieving relevant information during the querying process.
The original text can be stored in a separate database or file system.
Step 5: Embed the question
Use the same embedding model to transform the question into a vector representation.
The vector representation of the question should be similar to the vector representations of the chunks of text
that contains the answer.
Step 6: Perform a query
Query the Vector Database using the vector embedding generated from the question.
Retrieve the relevant context vectors to aid in answering the query.
The context vectors should be those that are most similar to the vector representation of the question.
Step 7: Retrieve similar vectors
Conduct an Approximate Nearest Neighbor (ANN) search in the Vector Database to find the most similar vectors to the query embedding.
Retrieve the most relevant information from the previously selected context vectors.
The ANN search will return a list of vectors that are most similar to the query embedding.
The most relevant information from these vectors can then be used to answer the question.
Step 8: Map vectors to text chunks
Associate the retrieved vectors with their corresponding text chunks to link numerical representations to actual content.
This will allow the LLM to access the original text that corresponds to the vector representations.
The mapping between vectors and text chunks can be stored in a separate database or file system.
Step 9: Generate the answer
Pass the question and retrieved-context text chunks to the Large Language Model (LLM) via a prompt.
Instruct the LLM to use only the provided context for generating the answer, ensuring prompt engineering aligns with expected boundaries.
The LLM will use the question and context text chunks to generate an answer.
The answer will be in natural language and will be relevant to the question.
Building AI chatbots to address real challenges
We are actively exploring the AI chatbot landscape to help businesses tackle their past challenges with conversational automation.
Certain fundamental aspects of chatbot building are unlikely to change, even as AI-powered chatbot solutions become more prevalent. These aspects include:
Designing task-specific conversational experiences: Regardless of where a customer stands in their journey, businesses must focus on creating tailored experiences for end users. AI-powered chatbots do not eliminate the need to design seamless experiences that alleviate pain points and successfully acquire, nurture, and retain customers.
Optimizing chatbot flows based on user behavior: AI chatbots continually improve their intelligence over time, attracting considerable interest in the market. Nevertheless, companies still need to analyze the bot’s performance and optimize parts of the flow where conversion rates may drop, based on user interactions. This holds true whether the chatbot utilizes AI or not.
Integrating seamlessly with third-party platforms: The development of AI chatbot solutions does not negate the necessity for easy integration with third-party platforms. Regardless of the data captured by the bot, it is crucial to handle and utilize that information effectively in the tech stacks or customer relationship management (CRM) systems used by the teams. Seamless integration remains essential.
Providing chatbot assistance on different channels: AI-powered chatbots can and should be deployed across various channels that customers use, such as WhatsApp, websites, Messenger, and more. The use of AI does not undermine the fundamental requirement of meeting customers where they are and engaging them through friendly conversations.
Developing LLM chatbots with LangChain
Conversational chatbots have become an essential component of many applications, offering users personalized and seamless interactions. To build successful chatbots, the focus lies in creating ones that can understand and generate human-like responses.
With LangChain’s advanced language processing capabilities, you can create intelligent chatbots that outperform traditional rule-based systems.
Step 1: Import necessary libraries
To get started, import the required libraries, including LangChain’s LLMChain and OpenAI for language processing.
Step 2: Using prompt template
Utilize the PromptTemplate and ConversationBufferMemory to create a chatbot template that generates jokes based on user input. This allows the chatbot to store and retrieve chat history, ensuring contextually relevant responses.
Step 3: Setting up the chatbot
Instantiate the LLMChain class, leveraging the OpenAI language model for generating responses. Utilize the ‘llm_chain.predict()’ method to generate a response based on the user’s input.
By combining LangChain’s LLM capabilities with prompt templates and chat history, you can create sophisticated and context-aware conversational chatbots for a wide range of applications.
Customizing LLMs with LangChain’s finetuning
Finetuning is a crucial process where an existing pre-trained LLM undergoes additional training on specific datasets to adapt it to a particular task or domain. By exposing the model to task-specific data, it gains a deeper understanding of the target domain’s nuances, context, and complexities.
This refinement process allows developers to enhance the model’s performance, increase accuracy, and make it more relevant to real-world applications.
Introducing LangChain’s finetuning capabilities
LangChain elevates finetuning to new levels by offering developers a comprehensive framework to train LLMs on custom datasets. With a user-friendly interface and a suite of tools, the fine-tuning process becomes simplified and accessible.
LangChain supports popular LLM architectures, including GPT-3, empowering developers to work with cutting-edge models tailored to their applications. With LangChain, customizing and optimizing LLMs is now easily within reach.
The fine-tuning workflow with LangChain
1. Data Preparation
Customize your dataset to fine-tune an LLM for your specific task. Curate a labeled dataset aligning with your target application, containing input-output pairs or suitable format.
2. Configuring Parameters
In LangChain interface, specify desired LLM architecture, layers, size, and other parameters. Define model’s capacity and performance balance.
3. Training Process
LangChain utilizes distributed computing resources for efficient LLM training. Initiate training, optimizing the pipeline for resource utilization and faster convergence. The model learns from your dataset, capturing task-specific nuances and patterns.
To start the fine-tuning process with LangChain, import required libraries and dependencies. Initialize the pre-trained LLM and fine-tune on your custom dataset.
4. Evaluation
After the fine-tuning process of the LLM, it becomes essential to evaluate its performance. This step involves assessing how well the model has adapted to the specific task. Evaluating the fine-tuned model is done using appropriate metrics and a separate test dataset.
The evaluation results can provide insights into the effectiveness of the fine-tuned LLM. Metrics like accuracy, precision, recall, or domain-specific metrics can be measured to assess the model’s performance.
LLM-powered applications: Top 4 real-life use cases
Explore real-life examples and achievements of LLM-powered applications, demonstrating their impact across diverse industries. Discover how LLMs and LangChain have transformed customer support, e-commerce, healthcare, and content generation, resulting in enhanced user experiences and business success.
LLMs have revolutionized search algorithms, enabling chatbots to understand the meaning of words and retrieve more relevant content, leading to more natural and engaging customer interactions.
LLM-powered applications Real-life use cases.
Companies must view chatbots and LLMs as valuable tools for specific tasks and implement use cases that deliver tangible benefits to maximize their impact. As businesses experiment and develop more sophisticated chatbots, customer support and experience are expected to improve significantly in the coming years
1. Customer support:
LLM-powered chatbots have revolutionized customer support, offering personalized assistance and instant responses. Companies leverage LangChain to create chatbots that comprehend customer queries, provide relevant information, and handle complex transactions. This approach ensures round-the-clock support, reduces wait times, and boosts customer satisfaction.
2. e-Commerce:
Leverage LLMs to elevate the e-commerce shopping experience. LangChain empowers developers to build applications that understand product descriptions, user preferences, and buying patterns. Utilizing LLM capabilities, e-commerce platforms deliver personalized product recommendations, address customer queries, and even generate engaging product descriptions, driving sales and customer engagement.
3. Healthcare:
In the healthcare industry, LLM-powered applications improve patient care, diagnosis, and treatment processes. LangChain enables intelligent virtual assistants that understand medical queries, provide accurate information, and assist in patient triaging based on symptoms. These applications grant faster access to healthcare information, reduce burdens on providers, and empower patients to make informed health decisions.
4. Content generation:
LLMs are valuable tools for content generation and creation. LangChain facilitates applications that generate creative and contextually relevant content, like blog articles, product descriptions, and social media posts. Content creators benefit from idea generation, enhanced writing efficiency, and maintaining consistent tone and style.
These real-world applications showcase the versatility and impact of LLM-powered solutions in various industries. By leveraging LangChain’s capabilities, developers create innovative solutions, streamline processes, enhance user experiences, and drive business growth.
Ethical and social implications of LLM chatbots:
Large language models chatbot
Privacy: LLM chatbots are trained on large amounts of data, which could include personal information. This data could be used to track users’ behavior or to generate personalized responses. It is important to ensure that this data is collected and used ethically.
Bias: LLM chatbots are trained on data that reflects the biases of the real world. This means that they may be biased in their responses. For example, an LLM chatbot trained on data from the internet may be biased towards certain viewpoints or demographics. It is important to be aware of these biases and to take steps to mitigate them.
Misinformation: LLM chatbots can be used to generate text that is misleading or false. This could be used to spread misinformation or to manipulate people. It is important to be aware of the potential for misinformation when interacting with LLM chatbots.
Emotional manipulation: LLM chatbots can be used to manipulate people’s emotions. This could be done by using emotional language or by creating a sense of rapport with the user. It is important to be aware of the potential for emotional manipulation when interacting with LLM chatbots.
Job displacement: LLM chatbots could potentially displace some jobs. For example, LLM chatbots could be used to provide customer service or to answer questions. It is important to consider the potential impact of LLM chatbots on employment when developing and deploying this technology.
In addition to the ethical and social implications listed above, there are also a few other potential concerns that need to be considered. For example, LLM chatbots could be used to create deepfakes, which are videos or audio recordings that have been manipulated to make it look or sound like someone is saying or doing something they never said or did. Deepfakes could be used to spread misinformation or to damage someone’s reputation.
Another potential concern is that LLM chatbots could be used to create addictive or harmful experiences. For example, an LLM chatbot could be used to create a virtual world that is very attractive to users, but that is also very isolating or harmful. It is important to be aware of these potential concerns and to take steps to mitigate them.
In a nutshell
Building a chatbot using Large Language Models is an exciting and promising endeavor. Despite the challenges ahead, the rewards, such as enhanced customer engagement, operational efficiency, and potential cost savings, are truly remarkable. So, it’s time to dive into the coding world, get to work, and transform your visionary chatbot into a reality!
The dojo way: Large language models bootcamp
Data Science Dojo’s LLM Bootcamp is a specialized program designed for creating LLM-powered applications. This intensive course spans just 40 hours, offering participants a chance to acquire essential skills.
Focused on the practical aspects of LLMs in natural language processing, the bootcamp emphasizes using libraries like Hugging Face and LangChain.
Participants will gain expertise in text analytics techniques, including semantic search and Generative AI. Additionally, they’ll gain hands-on experience in deploying web applications on cloud services. This program caters to professionals seeking to enhance their understanding of Generative AI, covering vital principles and real-world implementation without requiring extensive coding skills.
Large language models (LLMs) are a type of artificial intelligence (AI) that are trained on a massive dataset of text and code. Learn LLMs to generate text, translate languages, write different kinds of creative content, and answer your questions in an informative way.
Before we dive into the impact Large Language Models will create on different areas of work, let’s test your knowledge in the domain. Take our quiz for your current understanding and learn LLMs further.
Learn LLM Quiz: Test Your Knowledge Now!
Are you interested in leveling up your knowledge of Large Language Models? Click below:
Why are LLMs the Next Big Thing to Learn About?
Knowing about LLMs can be important for scaling your career in a number of ways.
LLMs are becoming increasingly powerful and sophisticated. As LLMs become more powerful and sophisticated, they are being used in a variety of applications, such as machine translation, chatbots, and creative writing. This means that there is a growing demand for people who understand how to use LLMs effectively.
Prompt engineering is a valuable skill that can be used to improve the performance of LLMs in a variety of tasks. By understanding how to engineer prompts, you can get the most out of LLMs and use them to accomplish a variety of tasks. This is a valuable skill that can be used to improve the performance of LLMs in a variety of tasks.
Learning about LLMs and prompt engineering can help you to stay ahead of the curve in the field of AI. As LLMs become more powerful and sophisticated, they will have a significant impact on a variety of industries. By understanding how LLMs work, you will be better prepared to take advantage of this technology in the future.
Here are some specific examples of how knowing about LLMs can help you to scale your career:
If you are a software engineer, you can use LLMs to automate tasks, such as code generation and testing. This can free up your time to focus on more strategic work.
If you are a data scientist, you can use LLMs to analyze large datasets and extract insights. This can help you to make better decisions and improve your business performance.
If you are a marketer, you can use LLMs to create personalized content and generate leads. This can help you to reach your target audience and grow your business.
Overall, knowing about LLMs can be a valuable asset for anyone who is looking to scale their career. By understanding how LLMs work and how to use them effectively, you can become a more valuable asset to your team and your company.
Here are some additional reasons why knowing about LLMs can be important for scaling your career:
LLMs are becoming increasingly popular. As LLMs become more popular, there will be a growing demand for people who understand how to use them effectively. This means that there will be more opportunities for people who have knowledge of LLMs.
LLMs are a rapidly developing field. The field of LLMs is constantly evolving, and there are new developments happening all the time. This means that there is always something new to learn about LLMs, which can help you to stay ahead of the curve in your career.
LLMs are a powerful tool that can be used to solve a variety of problems. LLMs can be used to solve a variety of problems, from machine translation to creative writing. This means that there are many different ways that you can use your knowledge of LLMs to make a positive impact in the world.
LLM, like ChatGPT, LaMDA, PaLM, etc., are advanced computer programs trained on vast textual data. They excel in tasks like text generation, speech-to-text, and sentiment analysis, making them valuable tools in NLP. The parameters enhance their ability to predict word sequences, improving accuracy and handling complex relationships.
In this blog, we will explore the 7 best LLMs in 2024 that have revamped the digital landscape for modern-day businesses.
Introducing Large Language Models (LLMs) in NLP
Natural Language Processing (NLP) has seen a surge in popularity due to computers’ capacity to handle vast amounts of natural text data. NLP has been applied in technologies like speech recognition and chatbots. Combining NLP with advanced Machine Learning techniques led to the emergence of powerful Large Language Models (LLMs).
Trained on massive datasets of text, reaching millions or billions of data points, these models demand significant computing power. To put it simply, if regular language models are like gardens, Large Language Models are like dense forests.
Here’s your one-stop guide to LLMs and their applications
How do LLMs Work?
LLMs, powered by the transformative architecture of Transformers, work wonders with textual data. These Neural Networks are adept at tasks like language translation, text generation, and answering questions. Transformers can efficiently scale and handle vast text corpora, even in the billions or trillions.
Unlike sequential RNNs, they can be trained in parallel, utilizing multiple resources simultaneously for faster learning. A standout feature of Transformers is their self-attention mechanism, enabling them to understand language meaningfully, grasping grammar, semantics, and context from extensive text data.
The invention of Transformers revolutionized AI and NLP, leading to the creation of numerous LLMs utilized in various applications like chat support, voice assistants, chatbots, and more.
Now, that we have explored the basics of LLMs, let’s look into the list of 10 best large language models to explore and use.
1. GPT-4
GPT-4 is the latest and most advanced LLM from OpenAI. With over a 170 trillion parameter count, it is one of the largest language models in the GPT series. It can tackle a wide range of tasks, including text generation, translation, summarization, and question-answering.
A visual comparison of the size of GPT-3 and GPT-4 – Source: Medium
The GPT-4 LLM represents a significant advancement in the field of AI and NLP. Let’s look at some of its key features and applications.
Key Features
What sets GPT-4 apart is its human-level performance on a wide array of tasks, making it a game-changer for businesses seeking automation solutions. With its unique multimodal capabilities, GPT-4 can process both text and images, making it perfect for tasks like image captioning and visual question answering.
Boasting over 170 trillion parameters, GPT-4 possesses an unparalleled learning capacity, surpassing all other language models. Moreover, it addresses the accuracy challenge by being trained on a massive dataset of text and code, reducing inaccuracies and providing more factual information.
GPT-4’s impressive fluency and creativity in generating text make it a versatile tool for tasks ranging from writing news articles and generating marketing copy to crafting captivating poems and stories.
Moreover, it is integrated into Microsoft Bing’s AI chatbot and is available in ChatGPT Plus. It is also expected to be incorporated into Microsoft Office products, enhancing their functionalities with AI-driven features.
Applications
Content Creation:
GPT-4 excels in generating high-quality content, including blog posts, articles, and creative writing. Its ability to generate language and images makes it particularly useful for multimedia content creation.
Customer Support:
Businesses use GPT-4 for customer support through chatbots that provide accurate and contextually relevant responses. This reduces wait times and improves the overall customer service experience.
Translation and Multilingual Support:
GPT-4’s proficiency in multiple languages allows for accurate and contextually appropriate translations, making it a valuable tool for global communication.
Coding and Debugging:
Developers utilize GPT-4 for coding assistance, including generating code snippets, debugging, and providing step-by-step guidance on complex programming tasks.
Its vast training data and advanced understanding enable GPT-4 to offer personalized user experiences, adjusting content based on individual preferences and behaviors.
Education and Training:
GPT-4 can be used in educational settings to provide explanations of complex concepts in simple terms, generate educational content, and even simulate interactive learning experiences.
Thus, GPT-4 stands out as a powerful tool in the realm of AI, capable of transforming how businesses operate and interact with their customers. Its versatility and advanced capabilities make it a valuable asset across multiple domains.
2. PaLM 2
PaLM 2 (Bison-001) is a large language model from Google AI. It is focused on commonsense reasoning and advanced coding. PaLM 2 has also been shown to outperform GPT-4 in reasoning evaluations, and it can also generate code in multiple languages.
An example of question-answering with PaLM 2 – Source: Google Cloud
Key Features
PaLM 2 is an exceptional language model equipped with commonsense reasoning capabilities, enabling it to draw inferences from extensive data and conduct valuable research in AI, NLP, and machine learning.
It boasts an impressive 540 billion parameters, making it one of the largest and most powerful language models available today. Moreover, with advanced coding skills, it can proficiently generate code in various programming languages like Python, Java, and C++, making it an invaluable asset for developers.
Its transformer architecture can process vast amounts of textual data, enabling it to generate responses with high accuracy. The model was trained on specialized TPU 4 Pods, which are custom hardware designed by Google specifically for machine learning tasks, enhancing the model’s training efficiency and performance.
Another notable feature of PaLM 2 is its multilingual competence, as it can comprehend and generate text in more than 20 languages. Moreover, it excels in reasoning and comprehending complex topics across various domains, including formal logic, mathematics, and coding. This makes it versatile in handling a wide range of tasks.
Unlike some other models, PaLM 2 is a closed-source model, meaning that its code is not publicly accessible. However, it is integrated into various Google products, such as the AI chatbot Bard. Nevertheless, PaLM 2’s combined attributes make it a powerful and versatile tool with a multitude of applications across various domains.
Applications
AI Chatbots:
PaLM 2 powers Google’s AI chatbot Bard, providing quick, accurate, and engaging conversational responses. This application showcases its ability to handle large-scale interactive dialogues effectively.
Content Generation:
The model’s advanced language generation capabilities make it suitable for creating high-quality content, from articles and blog posts to marketing copy and creative writing.
Machine Translation:
PaLM 2’s proficiency in multiple languages allows it to perform accurate and contextually appropriate translations, facilitating better global communication.
Coding Assistance:
With its understanding of coding languages and formal logic, PaLM 2 can assist in code generation, debugging, and providing solutions to complex programming problems.
Mathematics and Formal Logic:
The model’s ability to comprehend and reason through complex mathematical and logical problems makes it a valuable tool for educational purposes, research, and technical problem-solving.
Data Analysis and Visualization:
PaLM 2 can analyze data and generate visual representations such as graphs and charts, aiding in data-driven decision-making processes.
Thus, PaLM 2 stands out due to its massive scale and advanced architecture, enabling it to handle a diverse array of tasks with high accuracy and sophistication. Its integration into products like Google’s AI chatbot Bard highlights its practical applications in real-world scenarios, making it a powerful tool in various domains.
3. Claude 3.5
Claude 3.5 is a large language model developed by Anthropic, representing a significant advancement in AI capabilities.
Here are the main key features and applications of Claude 3.5.
Key Features
Claude 3.5 Sonnet sets a new standard for LLMs by outperforming the previously best GPT-4o by a wide margin on nearly every benchmark. It excels in tasks that demand deep reasoning, extensive knowledge, and precise coding skills.
The model not only delivers faster performance but is also more cost-effective compared to its predecessors, making it a practical choice for various applications. It exhibits superior performance in graduate-level reasoning, coding, multilingual math, and text reasoning.
Claude 3.5 also excels at vision tasks which adds to its versatility in handling diverse types of data inputs. Anthropic ensures the broad availability of Claude 3.5, making it easily integrable through APIs, contrasting with OpenAI’s exclusive availability on Azure.
Position of Claude 3.5 in the Anthropic’s LLM family – Source: Anthropic
Applications
Website Creation and Management:
Claude 3.5 simplifies website management by automating tedious tasks, allowing site owners to focus on higher-level strategies and marketing content creation. It can autonomously respond to customer inquiries, and provide real-time analytics without manually sifting through dashboards.
SEO Optimization:
The model handles technical optimization to deliver SEO improvements and site speed enhancements in the background. It recommends and implements changes to boost site performance.
Customer Engagement:
Claude 3.5 transforms site monetization by maximizing customer engagement. By analyzing visitor behaviors, the AI model can deliver personalized content, optimize product suggestions for eCommerce platforms, and curate articles that resonate with each visitor.
Ad Customization:
The model curates ads tailored to visitor demographics and behaviors to optimize ad revenue. Its customization capabilities can help improve customer retention, amplifying revenue from sales, memberships, and advertising.
Campaign Optimization:
Claude 3.5 can identify ideal audience segments and auto-optimize campaigns for peak performance. For SEO, it crafts content aligned to prime search terms.
Email Marketing:
Businesses can automate email marketing campaigns using Claude’s ability to auto-segment contacts and deploy behavior-triggered email messages, enhancing user engagement.
Content Creation:
The model can autonomously craft and refine landing pages by employing A/B testing for better conversions, ensuring the content is both effective and engaging.
Claude 3.5 Sonnet is a versatile AI assistant designed to simplify website creation, management, and optimization. With its advanced natural language capabilities and improved performance metrics, it stands out as a powerful tool for enhancing business operations and customer engagement.
Cohere is an advanced large language model developed by a Canadian startup of the same name. It is known for its versatile capabilities and customizable features, which make it suitable for various applications. Its Cohere Command model stands out for accuracy, making it a great option for businesses.
An example of Cohere being used as a conversational agent – Source: Cohere Documentation
Below are some key features and applications of the LLM.
Key Features
Moreover, Cohere offers accurate and robust models, trained on extensive text and code datasets. The Cohere Command model, tailored for enterprise generative AI, is accurate, robust, and user-friendly.
For businesses seeking reliable generative AI models, Cohere proves to be an excellent choice. Being open-source and cloud-based, Cohere ensures easy integration and wide accessibility for all teams. This feature supports real-time collaboration, version control, and project communication.
Cohere’s models can be trained and tailored to suit a wide range of applications, from blogging and content writing to more complex tasks requiring deep contextual understanding. The company offers a range of models, including Cohere Generate, Embed, and Rerank, each designed for different aspects of language processing.
Cohere stands out for its adaptability and ease of integration into various business processes, offering solutions that solve real-world problems with advanced AI capabilities.
Applications
Website Creation:
Effective Team Collaboration: Cohere streamlines web development processes by providing tools for real-time coordination, version control, and project communication.
Content Creation: The model can produce text, translate languages, and write various kinds of creative content, saving web development teams significant time and effort.
Monetization:
Paid Website Access: Cohere’s payment processing tool can be used to offer different levels of access to visitors, such as a basic plan for free and a premium plan for a monthly fee.
Subscription Services: Businesses can monetize additional services or features for an added charge, such as advanced collaboration tools or more storage space.
Marketing:
Creating Creative Content: Marketing teams can craft creative content for ad copies, social media posts, and email campaigns, enhancing the impact of their promotional strategies.
Personalizing Content: Content can be tailored to distinct audiences using Cohere’s multilingual, multi-accent, and sentiment analysis capabilities, making marketing initiatives more relevant and effective.
Tracking Campaign Effectiveness: The Cohere API can integrate with other AI marketing tools to track the effectiveness of marketing campaigns, processing the campaign data to deliver actionable insights.
Enterprise Applications:
Semantic Analysis and Contextual Search: Cohere’s advanced semantic analysis allows companies to securely feed their company information and find answers to specific queries, streamlining intelligence gathering and data analysis activities.
Content Generation, Summarization, and Classification: It supports the generation, summarization, and classification of content across over 100 languages, making it a robust tool for global enterprises.
Advanced Data Retrieval: The model includes features for advanced data retrieval and re-ranking, enhancing the accuracy and relevance of search results within enterprise applications.
Cohere is a powerful and flexible LLM, particularly suited for enterprises that require robust AI solutions for content creation, marketing, and data analysis.
5. Falcon-40 B
Falcon-40B is an advanced large language model developed by the Technology Innovation Institute (TII), UAE. It is recognized for its robust capabilities in natural language processing and generation. It is the first open-source large language model on this list, and it has outranked all the open-source models released so far, including LLaMA, StableLM, MPT, and more.
Some of its key features and applications include:
Key Features
Falcon has been open-sourced with an Apache 2.0 license, making it accessible for both commercial and research use. It has a transformer-based, causal decoder-only architecture similar to GPT-3, which enables it to generate contextually accurate content and handle natural language tasks effectively.
The Falcon-40B-Instruct model is fine-tuned for most use cases, including chat. The model uses a custom pipeline to curate and process data from diverse online sources, ensuring access to a broad range of relevant data.
The model has been primarily trained in English, German, Spanish, and French, but it can also work in Italian, Portuguese, Polish, Dutch, Romanian, Czech, and Swedish languages.
Falcon-40B can be used to analyze medical literature, aiding researchers and healthcare professionals in extracting valuable insights from vast amounts of medical texts.
Patient Records Analysis:
The model is capable of analyzing patient records, which can help in identifying patterns and making informed medical decisions.
Sentiment Analysis:
Businesses use Falcon-40B for sentiment analysis in marketing, allowing them to better understand customer feelings and opinions about their products or services.
Translation:
Falcon-40B’s multilingual capabilities make it suitable for translation tasks, facilitating communication across different languages.
Chatbots:
The model is used to develop advanced chatbots that can engage in more natural and interactive conversations with users.
Game Development and Creative Writing:
Falcon-40B is utilized in game development for generating dialogue and narratives, as well as in creative writing to assist authors in crafting stories.
Content Generation:
It is used for generating high-quality natural language outputs for various applications, including content creation for blogs, articles, and social media posts.
Interactive Applications:
Falcon-40B’s conversational nature makes it ideal for interactive applications, enhancing user experience through more engaging interactions.
Falcon-40B stands out due to its open-source nature, high-quality data processing, and advanced architecture, making it a versatile tool for a wide range of applications in natural language understanding and generation.
6. Gemini
Gemini, a model developed by Google, is notable for its multimodal capabilities. It is a versatile and powerful AI model designed to handle various tasks, including text generation, translation, and image processing.
The architecture and training strategies of Gemini emphasize extensive contextual understanding, a feature that sets it apart from many other models. These capabilities make Gemini suitable for applications requiring a nuanced understanding of different data formats.
The LLM is integrated into many Google applications and products, such as Google Docs, Sheets, Gmail, and Slides. This integration allows users to leverage its capabilities directly within these tools, enhancing productivity and functionality.
Gemini can generate high-quality graphics relevant to the website’s content. These graphics can be used to create eye-catching headers, CTA buttons, and other elements that make a website more visually appealing.
It can also produce AI-powered ad copy and promotional materials tailored to the website’s content and target audience. This helps increase brand awareness, drive traffic, and generate leads. Moreover, Gemini’s proficiency in multilingual translation allows for effortless catering to a global audience through localized content.
An example of function calling with Gemini – Source: Medium
Applications
Website Creation:
Generating High-Quality Graphics: Gemini can create relevant and visually appealing graphics for websites, enhancing their aesthetic appeal and user engagement.
Effective Layouts: By analyzing content and traffic patterns, Gemini can design effective and user-friendly website layouts.
Monetization:
Improving Appearances: Gemini can suggest design changes tailored to the website’s target audience, making it more likely for visitors to take action while browsing the site.
Creating AI-Powered Ad Copy: The model can generate ad copy and promotional materials that are tailored to the website’s content and target audience, driving traffic and generating leads.
Marketing:
AI-Powered Ad Copy Production: Gemini can produce promotional content tailored to the target audience, which helps increase brand awareness and lead generation.
Effective Layouts for Ads: The model can create layouts for ads and promotional materials that are easy to read and understand, ensuring that the message of the ad is clear and concise.
Google Workspace AI Assistant:
Gemini serves as an AI assistant within Google Workspace, helping users find and draft documents, analyze spreadsheet data, write personalized emails, build presentations, and more.
Dynamic and Interactive Content Creation:
Gemini can produce high-quality, contextually relevant content from articles to blog posts based on user prompts and its training data. The model can power interactive Q&A sections, dynamic FAQ sections, and AI chatbots on websites to engage visitors and provide real-time answers.
Gemini’s integration with Google’s ecosystem and its multimodal capabilities make it a powerful tool for website creation, marketing, and improving user experiences across various platforms.
7. LLaMA 2
LLaMA is a series of the best LLMs developed by Meta. The models are trained on a massive dataset of text and code, and they can perform a variety of tasks, including text generation, translation, summarization, and question-answering.
LLaMA 2 is the latest LLM in the series that is designed to assist with various business tasks, from generating content to training AI chatbots.
Below are some of the key features and applications of LLaMA 2.
Key Features
LLaMA 2 is an open-source model, available for free for both research and commercial use. Users can download it to their desktop and customize it according to their needs. The model is trained on a relatively small number of parameters, making it fast in terms of prompt processing and response time, making it a great option for smaller businesses that want an adaptable and efficient LLM.
The LLM is designed to be fine-tuned using company and industry-specific data. It can be customized to meet the specific needs of users without requiring extensive computational resources. Moreover, it excels in reading comprehension, making it effective for tasks that require understanding and processing large amounts of text.
The model performs well in reasoning and coding tests, indicating its capability to handle complex tasks and provide accurate outputs.
Applications
Content Generation:
LLaMA 2 can generate high-quality content, making it useful for creating articles, blog posts, social media content, and other forms of digital content.
Training AI Chatbots:
The model can be used to train AI chatbots, enabling businesses to provide automated customer support and interact with users more effectively.
Company-Wide Search Engines:
It can be integrated to enhance company-wide search engines, allowing for more efficient retrieval of information across an organization.
Text Auto-Completion:
LLaMA 2 can assist in auto-completing text, which is useful for drafting emails, documents, and other written communications.
Data Analysis:
The model can be leveraged for data analysis tasks, helping businesses to interpret and make sense of their data more efficiently.
Translation:
LLaMA 2 supports text translation, making it a valuable tool for businesses operating in multiple languages and needing to communicate across linguistic barriers.
Overall, LLaMA 2 stands out due to its open-source nature, efficiency, and adaptability, making it a suitable choice for various business applications, particularly for smaller enterprises looking for a cost-effective and customizable LLM solution.
This concludes our list of 7 best large language models that you can explore for an advanced user experience and business management.
Wrapping Up
In conclusion, Large Language Models (LLMs) are transforming the landscape of natural language processing, redefining human-machine interactions. Advanced models like GPT-3, GPT-4, Gopher, PALM, LAMDA, and others hold great promise for the future of NLP.
Their continuous advancement will enhance machine understanding of human language, leading to significant impacts across various industries and research domains.
Want to stay updated and in sync with the LLM and AI conversations? Join our Discord Community today to stay in touch!
Over the past few years, a shift has shifted from Natural Language Processing (NLP) to the emergence of Large Language Models (LLMs). This evolution is fueled by the exponential expansion of available data and the successful implementation of the Transformer architecture.
Transformers, a type of Deep Learning model, have played a crucial role in the rise of LLMs. The flexibility they offer has led to the idea of LLM finance, healthcare, e-commerce, and much more.
Significance of Large Language Models
Large Language Models (LLMs) are revolutionizing the AI landscape by enabling machines to understand and generate human-like language. Trained on vast datasets, LLMs excel at tasks like summarizing, translating, predicting, and creating content with high accuracy. Their ability to recognize linguistic patterns and apply them contextually has made them invaluable across industries.
LLMs automate language tasks, such as drafting articles, answering customer queries, or translating languages, which increases efficiency and reduces human intervention. This capability has made them essential tools in areas like customer service, content creation, and research.
Beyond operational tasks, LLMs are enhancing creativity and productivity. They assist in generating ideas, drafting copy, and even conducting research, fostering innovation across sectors like healthcare, finance, and education. Their versatility makes them integral to improving workflows and driving new business opportunities.
Overall, LLMs are reshaping industries by enabling scalable solutions, improving decision-making, and unlocking new forms of creativity. Their continued development promises even greater capabilities in the future, making them essential tools for businesses and researchers alike.
LLMs in finance – Source Semantic Scholars
Applications of LLMs in the Finance Industry
Applications of Large Language Models (LLMs) in the finance industry have gained significant traction in recent years. LLMs, such as GPT-4, BERT, RoBERTa, and specialized models like BloombergGPT, have demonstrated their potential to revolutionize various aspects of the fintech sector.
These cutting-edge technologies offer several benefits and opportunities for both businesses and individuals within the finance industry.
1. Fraud Detection and Prevention:
LLMs significantly enhance fraud detection in the financial sector by analyzing vast amounts of transaction data in real-time. They can quickly identify patterns of normal behavior and spot deviations that could indicate fraud, such as unusual spending patterns or transactions from unfamiliar locations. By learning from historical fraud data, LLMs improve over time, allowing them to detect emerging fraud schemes.
These models can also help minimize false positives by refining their understanding of legitimate customer behavior, providing more accurate fraud alerts and reducing disruption to legitimate transactions.
2. Risk Assessment and Management:
LLMs provide financial institutions with the tools to assess and manage risk more accurately. By analyzing data from a range of sources, including transaction histories, customer profiles, and external market data, LLMs can help assess the likelihood of loan defaults or investment risks. They can also analyze shifts in macroeconomic conditions, allowing businesses to adjust their strategies to mitigate risk proactively.
Additionally, LLMs can evaluate creditworthiness by considering more than just traditional credit scores, incorporating alternative data sources such as payment histories or even social media activity. This approach helps provide a more holistic view of potential risks, allowing for better decision-making and financial forecasting.
3. Personalized Customer Service:
AI-powered chatbots and virtual assistants fueled by LLMs are transforming customer service in the finance industry by providing personalized, instant responses to a wide range of customer queries. These models use natural language processing to understand and respond to complex questions in a conversational manner, helping customers with everything from basic account inquiries to personalized financial advice.
By continuously learning from interactions, these systems can offer increasingly relevant and specific advice, improving customer satisfaction. Moreover, LLMs allow for 24/7 availability, reducing wait times and enabling clients to resolve issues outside of traditional business hours.
4. Efficient Onboarding:
LLMs streamline the onboarding process by guiding customers through registration, verifying their identities, and recommending personalized financial products. AI models can help customers navigate the often complex world of financial products by offering real-time, tailored suggestions based on their preferences and financial situations.
Moreover, these models can automate paperwork, answer questions, and provide instant clarifications, reducing onboarding time and friction. This results in a more efficient process, higher conversion rates, and better customer retention as clients feel more supported from the moment they interact with a financial institution.
5. Advanced Financial Advice:
LLMs enable financial advisors to provide clients with data-driven, personalized advice by analyzing both individual financial data and broader market trends. These models can evaluate a client’s risk tolerance, financial goals, and historical investment performance to suggest suitable financial strategies. LLMs can also help by running simulations and providing projections, assisting clients in making better-informed decisions about retirement, investments, and wealth management.
For financial advisors, LLMs automate much of the research and analysis, freeing up time to focus on more strategic, relationship-building aspects of their work. This results in a more efficient advisory process and higher-quality advice for clients.
6. News Analysis and Sentiment Detection:
LLMs are adept at processing vast amounts of financial news, including articles, social media posts, and financial reports, to identify trends, market sentiment, and public opinions. By evaluating the tone and sentiment of news articles, LLMs can alert traders and investors to shifts in market conditions that may signal opportunities or risks.
For example, if LLMs detect a sudden negative shift in sentiment surrounding a particular company or industry, financial professionals can act quickly, making adjustments to their portfolios in real-time. This capability is invaluable for traders who need to stay ahead of market-moving news.
7. Data Analysis and Predictive Analytics:
LLMs excel at analyzing historical financial data and making predictions about future trends, from stock prices to economic shifts. These models can process data faster and more accurately than traditional methods, identifying patterns that might otherwise be missed. By applying machine learning algorithms, LLMs can predict market trends, assess investment opportunities, and optimize portfolios.
With their ability to handle massive datasets, LLMs also enable more precise forecasting, reducing the uncertainty inherent in financial decision-making. This predictive power enhances risk management, allowing institutions to anticipate potential issues before they arise and adjust strategies accordingly.
How Large Language Models Can Automate Financial Services?
Large language models have the potential to automate various financial services, including customer support and financial planning. These models, such as GPT (Generative Pre-trained Transformer), have been developed specifically for the financial services industry to accelerate digital transformation and improve competitiveness.
One example of a large language model designed for banking is SambaNova GPT Banking.
This solution aims to address the deep learning deployment gap in the banking sector by jump-starting banks’ deep learning language capabilities in a matter of weeks, rather than years [1]. By subscribing to GPT Banking, banks can leverage the technology to perform various tasks:
1. Sentiment Analysis:
GPT Banking can scan social media, press, and blogs to understand market, investor, and stakeholder sentiment.
2. Entity Recognition:
It reduces human error by classifying documents and minimizing manual and repetitive work.
3. Language Generation:
The model can process, transcribe, and prioritize claims, extract necessary information, and create documents to enhance customer satisfaction.
4. Language Translation:
GPT Banking enables language translation to expand the customer base. The deployment of large language models like GPT Banking offers several benefits to financial institutions:
5. Efficiency and Time-saving:
By automating routine tasks, these models can enhance efficiency and productivity for financial service providers. AI-powered assistants can handle activities such as scheduling appointments, answering frequently asked questions, and providing essential financial advice, allowing human professionals to focus on more strategic and value-added tasks.
6. Personalized Customer Experience:
Large language models can provide instant and personalized responses to customer queries, enabling financial advisors to deliver real-time information and tailor advice to individual clients. This enhances the overall client experience and satisfaction.
7. Competitive Advantage:
Embracing AI technologies like large language models can give financial institutions a competitive edge. Early adopters can differentiate themselves by leveraging the power of AI to enhance their client experience, improve efficiency, and stay ahead of their competitors in the rapidly evolving financial industry.
Upscaling Financial Sector with LLM Finance
It’s worth noting that large language models can handle natural language processing tasks in diverse domains, and LLMs in the finance sector, can be used for applications like robo-advising, algorithmic trading, and low-code development.
These models leverage vast amounts of training data to simulate human-like understanding and generate relevant responses, enabling sophisticated interactions between financial advisors and clients.
Overall, large language models have the potential to significantly streamline financial services by automating tasks, improving efficiency, enhancing customer experience, and providing a competitive edge to financial institutions.
With rapid LLM development, the digital world is integrating new changes and components. The advanced features offered by large language models enable businesses to enhance their overall presence and efficiency in the modern-day digital market.
In this blog, we will explore the advent of smarter chatbots – one of the many useful impacts of LLM development in modern times.
Understanding LLMs
A large language model is a computer program that is trained and learns from a large amount of data. The machine is capable of understanding and generating human-like text based on the patterns and knowledge accumulated during the training process.
In the library, for example, a young person or child may read various books, articles, and writings from a wide variety of authors. Reading and comprehending all that information requires a great deal of time.
In time, you will become familiar with a wide range of topics, and you will be able to answer questions about them and discuss them in meaningful and logical ways.
Large language models follow similar principles. The program reads and analyzes a vast amount of text, including books, websites, and articles. Therefore, it is able to learn the meaning of words, the structure of words, and the relation between them.
In response to the input it receives, the model will be capable of providing explanations, generating responses, or initiating conversations based on the information it receives after training. On the basis of the text that is provided, the system is able to generate coherent and relevant responses by using context.
Large language models and chatbots
The purpose of a large language model is to create a computer program that can generate human-like text based on the knowledge it has acquired through reading.
Artificial intelligence systems that are capable of understanding and generating human language are known as large Language Models (LLMs). In order to learn the nuances of language and to respond coherently and pertinently, deep learning algorithms are used along with a large amount of data. An LLM is generally able to predict what words will follow words already typed.
By typing a few keywords into the search box, Google’s BERT system can predict what you will be searching for. The BERT algorithm has been trained on 3.3 million words and contains 340 million parameters so that it can understand and respond to what is entered into the search box.
One of the most widely known LLMs today is ChatGPT, which was developed by OpenAI. The service has been registered by more than one million users since it was first made available to the public. A little over two months after the company’s launch, Instagram reached a million downloads, whereas Spotify took five months to reach that level.
It is no wonder that ChatGPT has experienced explosive growth due to its ability to mimic human responses as closely as possible. A total of 300 million words and 175 billion parameters have been analyzed by BERT’s machine learning algorithms, which far exceed the training model used by the model.
Most Popular LLMs (Large Language Models)
It is currently commonplace for multiple companies to develop large language models that have been trained on billions of variables and datasets. However, we are going to take a look at some of the top LLM programs right now:
A large language model that was released in 2020, Generative Pre-trained Transformer 3 (GPT-3), has grown in popularity over the years. As part of its development, OpenAI developed the GPT-3 code which has now been licensed to Microsoft for modification and usage.
A prompt is given to GPT-3 and it produces very accurate human-like text output based on deep learning. AI chatbot ChatGPT is based on GPT-3.5, one of the most popular AI chatbots. As well as offering a public API, ChatGPT provides an API through which the results of chats may be integrated and received.
A Google AI language model called Bidirectional Encoder Representations from Transformers (BERT) was introduced in 2018. A notable feature of this NLP model is that it finds relevance in both sides (left/right) of a word at the same time. Pre-trained plain text data sources, such as Wikipedia, are used by BERT to understand a prompt in a deeper and more meaningful way.
In 2022, Google developed a conversational large language model in the form of Language Model for Dialogue Applications (LaMDA). As part of the training process, it utilizes a decoding-only transformer language model as well as a text corpus consisting of 1.56 trillion words that have been pre-trained on both documents and dialogues. In addition to providing a Generic Language API to integrate with third-party applications, LaMDA powers Google’s conversational AI chatbot – Bard.
By 2022, Google AI had developed a large language model based on artificial intelligence called Pathways Language Model (PALM). This system is trained by using a variety of high-quality datasets, which include filtered web pages, books, Wikipedia articles, news articles, source code taken from GitHub repositories, and social media communications.
A large language model meta-AI (LLaMA) is expected to be developed in Facebook by 2023. It is similar to other large language models that LLaMA models generate text indefinitely based on a sequence of words. By using texts from 20 of the world’s most popular languages, the developers trained the LLaMA model using Latin and Cyrillic alphabets.
OpenAI created the Generated Pretrained Transformer 4 (GPT-4) model to model multimodal large languages. In addition to taking images and text as inputs, it is an improved version of GPT-3. A number of APIs can be used, images can be generated, and webpages can be accessed and summarized using GPT-4. In addition, ChatGPT Plus is powered by it.
Influence of LLM Development on the E-Commerce Industry
Show customers what they want: LMs can analyze customer data, such as browsing history, purchase patterns, and preferences, to make highly personalized product recommendations. They can improve customer satisfaction by understanding customers’ needs and preferences.
Dedicated Shopping Assistant: It can act as a virtual shopping assistant, assisting customers with navigation through product catalogs, answering questions, and providing guidance. Language Models provide customers with an interactive and personalized shopping experience by allowing them to communicate in natural language.
Search & Discover like Humans: They are capable of understanding complex search queries and providing accurate and relevant search results. A better search experience on e-commerce platforms is enabled as a result of this. Customers are able to find products more quickly and easily.
Save Time with negligible human intervention: Chatbots are used to provide customer service based on LMs. In addition to handling order tracking, returns, and general product inquiries, customer service representatives can also handle several types of inquiries from customers. By implementing Language Models that can provide real-time responses, customer service can be improved, and human intervention can be reduced.
Read, Learn, and then Decide: A LM is capable of producing natural language product descriptions that are engaging to the reader. Customers are also able to gain an understanding of the product’s features, benefits, and applications as well as make informed decisions.
Customer Emotions Matter: Customer reviews and feedback can be analyzed by LMs in order to gain insight and better understand customer sentiment. E-commerce platforms are able to identify trends, improve product quality, and address customer concerns in a timely manner through this process.
Zero Language Barrier: LMs are capable of assisting in the translation of foreign languages, breaking down language barriers for international customers. Thus, empowering e-commerce platforms to widen their prospects and reach a global audience and thereby, expand their customer base.
Voice of the Customer: LMs facilitate voice-based shopping experiences thanks to advancements in speech recognition technology. In order to provide customers with a convenient and hands-free shopping experience, voice commands are available for searching for products, adding items to their shopping carts, and completing purchases.
Learn from the Present, Prepare for the Future: In order to obtain insight into customer sentiment, LMs analyze customer reviews and feedback and analyze customer feedback. A company’s e-commerce platform can use this process to identify trends, improve product quality, and respond to customer complaints in a timely manner as a result of their efforts.
Conventional chatbots are typically developed through the use of specific frameworks or programming languages.
The definition of explicit rules and the updating of those rules periodically are essential in order to deal with new scenarios. It requires significant computational resources and expertise to develop, train, and maintain LLM-based chatbots.
Aspect
LLM-based Chatbots
Traditional Chatbots
Technology
Based on advanced deep learning
Rule-based or scripted approaches
architectures (e.g., GPT)
Language Understanding
A better understanding of natural
Limited ability for complex
language and context
language understanding
Conversational Ability
More human-like and coherent conversations
Prone to scripted responses and struggles with complex dialogs
Personalization
Offers more personalized experiences
Lacks advanced personalization
Training and Adaptability
Requires extensive pre-training
Requires manual rule updates for
and fine-tuning on specific tasks
new scenarios
Limitations
Can generate incorrect or misleading
Less prone to generating
responses, lacks common sense
incorrect or unexpected responses
Development and Maintenance
Requires significant computational
Developed using specific
Developing LLM-based Chatbots requires high-quality Annotated Data
A large language model (LLM) is a powerful tool that enables you to enhance your ability to understand natural language and generate text that appears human-like. As a result of these sophisticated models, chatbots in various fields, including the e-commerce industry, could be revolutionized in terms of how they interact with users. A chatbot that is based on LLM will likely be more effective if the training data it receives is of high quality.
Annotating data is an essential component of preparing training data for LLMs. A dataset is labelled or tagged with annotations in order for machine learning algorithms to understand it. LLM-based chatbots are developed by annotating text with data such as intent, entities, sentiment, and dialogue structure. Based on this annotated data, the bot can provide users with relevant answers to their queries and engage in meaningful dialogue with them.
In order to train LLM-based chatbots, the quality of annotated data is of paramount importance. Annotations of high quality help the chatbot understand users’ queries accurately, understand the nuances of their language, and respond appropriately to them. It is possible that chatbots will be unable to interpret complex language structures, comprehend the intent of the user, or generate coherent and contextually relevant responses without well-annotated data.
The process of data annotation requires annotators who are skilled at interpreting and labeling data accurately as well as having a deep understanding of language. The annotators are capable of capturing subtle nuances, idioms, and context by utilizing their expertise in linguistics and domain knowledge. Their meticulous labeling and annotation of the data during the training process provide the LLM with the guidance it needs to learn from the examples and generalize from them.
LLM-based chatbots benefit from highly annotated data in numerous ways:
Understanding language: As a result of annotations, users are able to gain an understanding of the meaning, intent, and entities represented in their queries. As a result, the chatbot is capable of understanding nuances in the language of a user, interpreting their intent accurately, and providing relevant information based on their input.
Understanding context: A chatbot can understand the conversation flow based on annotations, which provide context cues. The chatbot develops a greater understanding of a conversation by annotating dialogue structure and conversation context, thereby ensuring more coherent and contextually relevant responses.
Enhanced response generation:
When annotations are of high quality, they contribute to the production of more accurate and contextually appropriate responses. LLM-based chatbots are trained on well-annotated data in order to generate text that is human-like and aligns with the conversation’s intention and context.
Expertise in a specific domain:
It is also possible to tailor data annotations for specific e-commerce domains. In order to be able to provide users with more accurate and informed responses, the chatbot acquires domain knowledge from product descriptions, customer reviews, and other domain-specific sources.
As a result, it cannot be overstated just how important it is to use high-quality annotated data to train LLM-based chatbots. It provides the basis for the development of these chatbots’ abilities to understand and respond to natural language. An e-commerce business should partner with a data annotation company that specializes in LLM training in order to ensure the accuracy, performance, and effectiveness of their chatbot solutions. An LLM-based chatbot can provide outstanding customer service, personalized suggestions, and seamless interaction as a result of quality annotations.
Final thoughts
The article describes how large language models (LLMs) affect the e-commerce industry. A LLM, such as GPT-3 or BERT, is an advanced deep-learning model capable of interpreting and generating human-like text after extensive training on large datasets. By understanding natural language, engaging in conversations, personalizing, and performing improved search functions, they have revolutionized chatbot technology.
Data that has been labeled with annotations such as intent, entities, sentiment, and dialogue structure is required for the training of LLM-based chatbots. With well-annotated data, chatbots can provide contextually relevant responses to users based on their questions, take into account nuances in language, and understand nuances in user queries. The article emphasizes the importance of partnering with companies that specialize in LLM training to ensure the effectiveness and accuracy of chatbot solutions in e-commerce.
Data Science Dojo’s Large Language Models Bootcamp
Introducing Data Science Dojo’s Large Language Models Bootcamp, a specialized 40-hour program for creating LLM-powered applications. This intensive course concentrates on practical aspects of LLMs in natural language processing, utilizing libraries like Hugging Face and LangChain.
Participants will master text analytics techniques, including semantic search and Generative AI. Perfect for professionals seeking to enhance their understanding of Generative AI, the program covers essential principles and real-world implementation without the need for extensive coding skills.
The buzz surrounding large language models is wreaking havoc and for all the good reason! The game-changing technological marvels have got everyone talking and have to be topping the charts in 2023.
Here is an LLM guide for beginners to understand the basics of large language models, their benefits, and a list of best LLM models you can choose from.
What are Large Language Models?
A large language model (LLM) is a machine learning model capable of performing various natural language processing (NLP) tasks, including text generation, text classification, question answering in conversational settings, and language translation.
The term “large” in this context refers to the model’s extensive set of parameters, which are the values it can autonomously adjust during the learning process. Some highly successful LLMs possess hundreds of billions of these parameters.
LLMs undergo training with vast amounts of data and utilize self-supervised learning to predict the next token in a sentence based on its context. They can be used to perform a variety of tasks, including:
Natural language understanding: LLMs can understand the meaning of text and code, and can answer questions about it.
Natural language generation: LLMs can generate text that is similar to human-written text.
Translation: LLMs can translate text from one language to another.
Summarization: LLMs can summarize text into a shorter, more concise version.
Question answering: LLMs can answer questions about text.
Code generation: LLMs can generate code, such as Python or Java code.
Understanding Large Language Models
Best LLM Models You Can Choose From
Let’s explore a range of noteworthy large language models that have made waves in the field:
Large language models (LLMs) have revolutionized the field of natural language processing (NLP) by enabling a wide range of applications from text generation to coding assistance. Here are some of the best examples of LLMs:
1. GPT-4
GPT-4 – Source: LinkedIn
Developer: OpenAI
Overview: The latest model in OpenAI’s GPT series, GPT-4, has over 170 trillion parameters. It can process and generate both language and images, analyze data, and produce graphs and charts.
Applications: Powers Microsoft Bing’s AI chatbot, used for detailed text generation, data analysis, and visual content creation.
2. BERT (Bidirectional Encoder Representations from Transformers)
Google BERT – Source: Medium
Developer: Google
Overview: BERT is a transformer-based model that can understand the context and nuances of language. It features 342 million parameters and has been employed in various NLP tasks such as sentiment analysis and question-answering systems.
Applications: Query understanding in search engines, sentiment analysis, named entity recognition, and more.
3. Gemini
Google Gemini – Source: Google
Developer: Google
Overview: Gemini is a family of multimodal models that can handle text, images, audio, video, and code. It powers Google’s chatbot (formerly Bard) and other AI features throughout Google’s apps.
Applications: Text generation, creating presentations, analyzing data, and enhancing user engagement in Google Workspace.
Overview: Claude focuses on constitutional AI, ensuring outputs are helpful, harmless, and accurate. The latest iteration, Claude 3.5 Sonnet, understands nuance, humor, and complex instructions better than earlier versions.
Applications: General-purpose chatbots, customer service, and content generation.
Overview: PaLM is a 540 billion parameter transformer-based model. It is designed to handle reasoning tasks, such as coding, math, classification, and question answering.
Applications: AI chatbot Bard, secure eCommerce websites, personalized user experiences, and creative content generation.
6. Falcon
Falcon – Source: LinkedIn
Developer: Technology Innovation Institute
Overview: Falcon is an open-source autoregressive model trained on a high-quality dataset. It has a more advanced architecture that processes data more efficiently.
Applications: Multilingual websites, business communication, and sentiment analysis.
7. LLaMA (Large Language Model Meta AI)
LLaMA – Source: LinkedIn
Developer: Meta
Overview: LLaMA is open-source and comes in various sizes, with the largest version having 65 billion parameters. It was trained on diverse public data sources.
Applications: Query resolution, natural language comprehension, and reading comprehension in educational platforms.
Overview: Cohere offers high accuracy and robustness, with models that can be fine-tuned for specific company use cases. It is not restricted to a single cloud provider, offering greater flexibility.
9. LaMDA (Language Model for Dialogue Applications)
LaMDA – Source: LinkedIn
Developer: Google DeepMind
Overview: LaMDA can engage in conversation on any topic, providing coherent and in-context responses.
Applications: Conversational AI, customer service chatbots, and interactive dialogue systems.
These LLMs illustrate the versatility and power of modern AI models, enabling a wide range of applications that enhance user interactions, automate tasks, and provide valuable insights.
As we assess these models’ performance and capabilities, it’s crucial to acknowledge their specificity for particular NLP tasks. The choice of the optimal model depends on the task at hand.
Large language models exhibit impressive proficiency across various NLP domains and hold immense potential for transforming customer engagement, operational efficiency, and beyond.
What are the Benefits of LLMs?
LLMs have a number of benefits over traditional AI methods. They are able to understand the meaning of text and code in a much more sophisticated way. This allows them to perform tasks that would be difficult or impossible for traditional AI methods.
LLMs are also able to generate text that is very similar to human-written text. This makes them ideal for applications such as chatbots and translation tools. The key benefits of LLMs can be listed as follows:
Large language models (LLMs) offer numerous benefits across various applications, significantly enhancing operational efficiency, content generation, data analysis, and more. Here are some of the key benefits of LLMs:
Operational Efficiency:
LLMs streamline many business tasks, such as customer service, market research, document summarization, and content creation, allowing organizations to operate more efficiently and focus on strategic initiatives.
Content Generation:
They are adept at generating high-quality content, including email copy, social media posts, sales pages, product descriptions, blog posts, articles, and more. This capability helps businesses maintain a consistent content pipeline with reduced manual effort.
Intelligent Automation:
LLMs enable smarter applications through intelligent automation. For example, they can be used to create AI chatbots that generate human-like responses, enhancing user interactions and providing immediate customer support.
Enhanced Scalability:
LLMs can scale content generation and data analysis tasks, making it easier for businesses to handle large volumes of data and content without proportionally increasing workforce size.
Customization and Fine-Tunability:
These models can be fine-tuned with specific company- or industry-related data, enabling them to perform specialized tasks and provide more accurate and relevant outputs.
Data Analysis and Insights:
LLMs can analyze large datasets to extract meaningful insights, summarize documents, and even generate reports. This capability is invaluable for decision-making processes and strategic planning.
Multimodal Capabilities:
Some advanced LLMs, such as Gemini, can handle multiple modalities, including text, images, audio, and video, broadening the scope of applications and making them suitable for diverse tasks.
Language Translation:
LLMs facilitate multilingual communication by providing high-quality translations, thus helping businesses reach a global audience and operate in multiple languages.
Improved User Engagement:
By generating human-like text and understanding context, LLMs enhance user engagement on websites, in applications, and through chatbots, leading to better customer experiences and satisfaction.
Security and Privacy:
Some LLMs, like PaLM, are designed with privacy and data security in mind, making them ideal for sensitive projects and ensuring that data is protected from unauthorized access.
Overall, LLMs provide a powerful foundation for a wide range of applications, enabling businesses to automate time-consuming tasks, generate content at scale, analyze data efficiently, and enhance user interactions.
Applications for Large Language Models
1. Streamlining Language Generation in IT
Discover how generative AI can elevate IT teams by optimizing processes and delivering innovative solutions. Witness its potential in:
Recommending and creating knowledge articles and forms
Updating and editing knowledge repositories
Real-time translation of knowledge articles, forms, and employee communications
Crafting product documentation effortlessly
2. Boosting Efficiency with Language Summarization
Explore how generative AI can revolutionize IT support teams, automating tasks and expediting solutions. Experience its benefits in:
Extracting topics, symptoms, and sentiments from IT tickets
Clustering IT tickets based on relevant topics
Generating narratives from analytics
Summarizing IT ticket solutions and lengthy threads
Condensing phone support transcripts and highlighting critical solutions
3. Unleashing Code and Data Generation Potential
Witness the transformative power of generative AI in IT infrastructure and chatbot development, saving time by automating laborious tasks such as:
Suggesting conversation flows and follow-up patterns
Generating training data for conversational AI systems
Testing knowledge articles and forms for relevance
Assisting in code generation for repetitive snippets from online sources
The future possibilities of LLMs are very exciting. They have the potential to revolutionize the way we interact with computers. They could be used to create new types of applications, such as chatbots that can understand and respond to natural language, or translation tools that can translate text with near-human accuracy.
LLMs could also be used to improve our understanding of the world. They could be used to analyze large datasets of text and code and to identify patterns and trends that would be difficult or impossible to identify with traditional methods.
Wrapping up
LLMs represent a highly potent and promising technology that presents numerous possibilities for various applications. While still in the development phase, these models have the capacity to fundamentally transform our interactions with computers.
Data Science Dojo specializes in delivering a diverse array of services aimed at enabling organizations to harness the capabilities of Large Language Models. Leveraging our extensive expertise and experience, we provide customized solutions that perfectly align with your specific needs and goals.