Whether you are a startup building your first AI-powered product or a global enterprise managing sensitive data at scale, one challenge remains the same: how to build smarter, faster, and more secure AI without breaking the bank or giving up control.
That’s exactly where Llama 4 comes in! A large language model (LLM) that is more than just a technical upgrade.
It provides a strategic advantage for teams of all sizes. With its Mixture-of-Experts (MoE) architecture, support for up to 10 million tokens of context, and native multimodal input, Llama 4 offers GPT-4-level capabilities, and that too without the black box.
Now, your AI tools can remember everything a user has done over the past year. Your team can ask one question and get answers from PDFs, dashboards, or even screenshots all at once. And the best part? You can run it on your own servers, keeping your data private and in your control.

In this blog, we’ll break down why Llama 4 is such a big deal in the AI world. You’ll learn about its top features, how it can be used in real life, the different versions available, and why it could change the game for companies of all sizes.
What Makes Llama 4 Different from Previous Llama Models?
Building on the solid foundation of its predecessors, Llama 4 introduces groundbreaking features that set it apart in terms of performance, efficiency, and versatility. Let’s break down what makes this model a true game-changer.
Evolution from Llama 2 and Llama 3
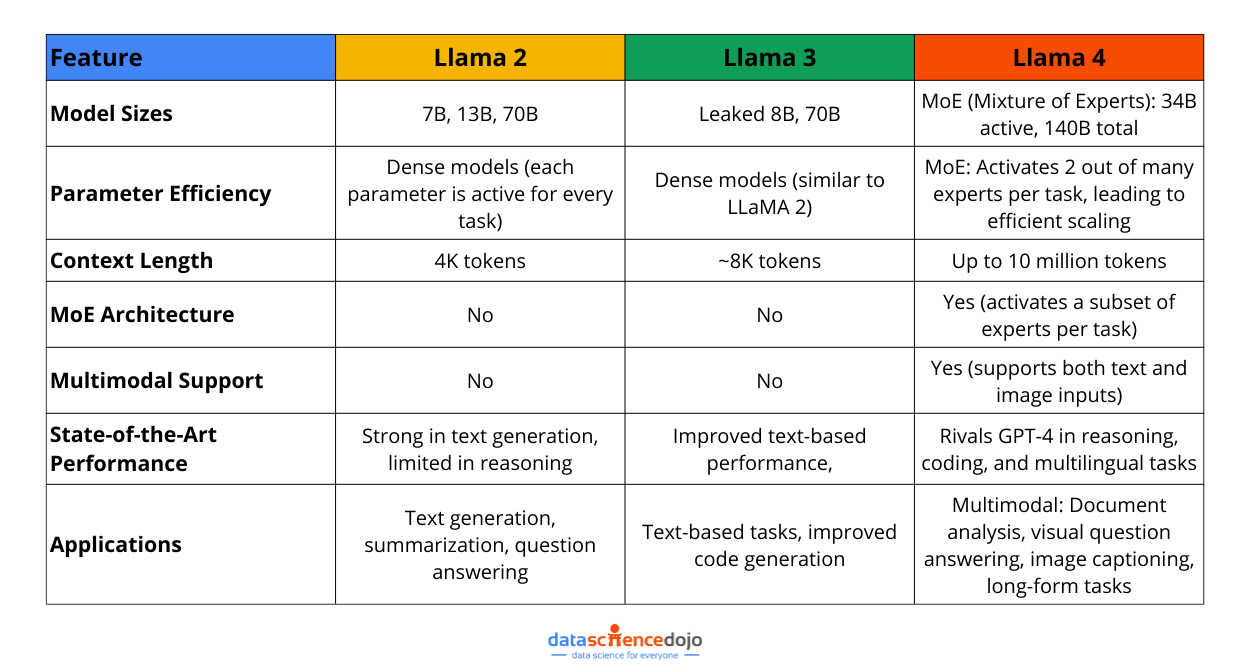
To understand how far the model has come, let’s look at how it compares to Llama 2 and Llama 3. While the earlier Llama models brought exciting advancements in the world of open-source LLMs, Llama 4 brings in a whole new level of efficiency. Its architecture and other related features make it stand out among the other LLMs in the Llama family.
Explore the Llama 3 model debate
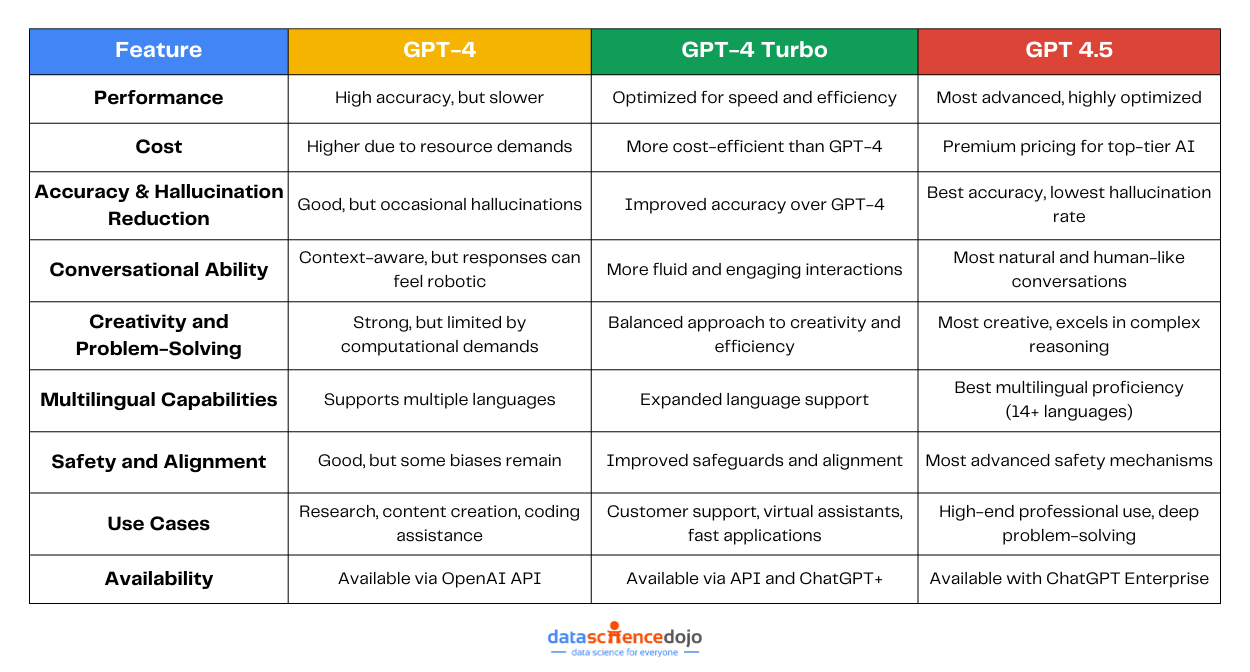
Here’s a quick comparison of Llama 2, Llama 3, and Llama 4:
Introduction of Mixture-of-Experts (MoE)
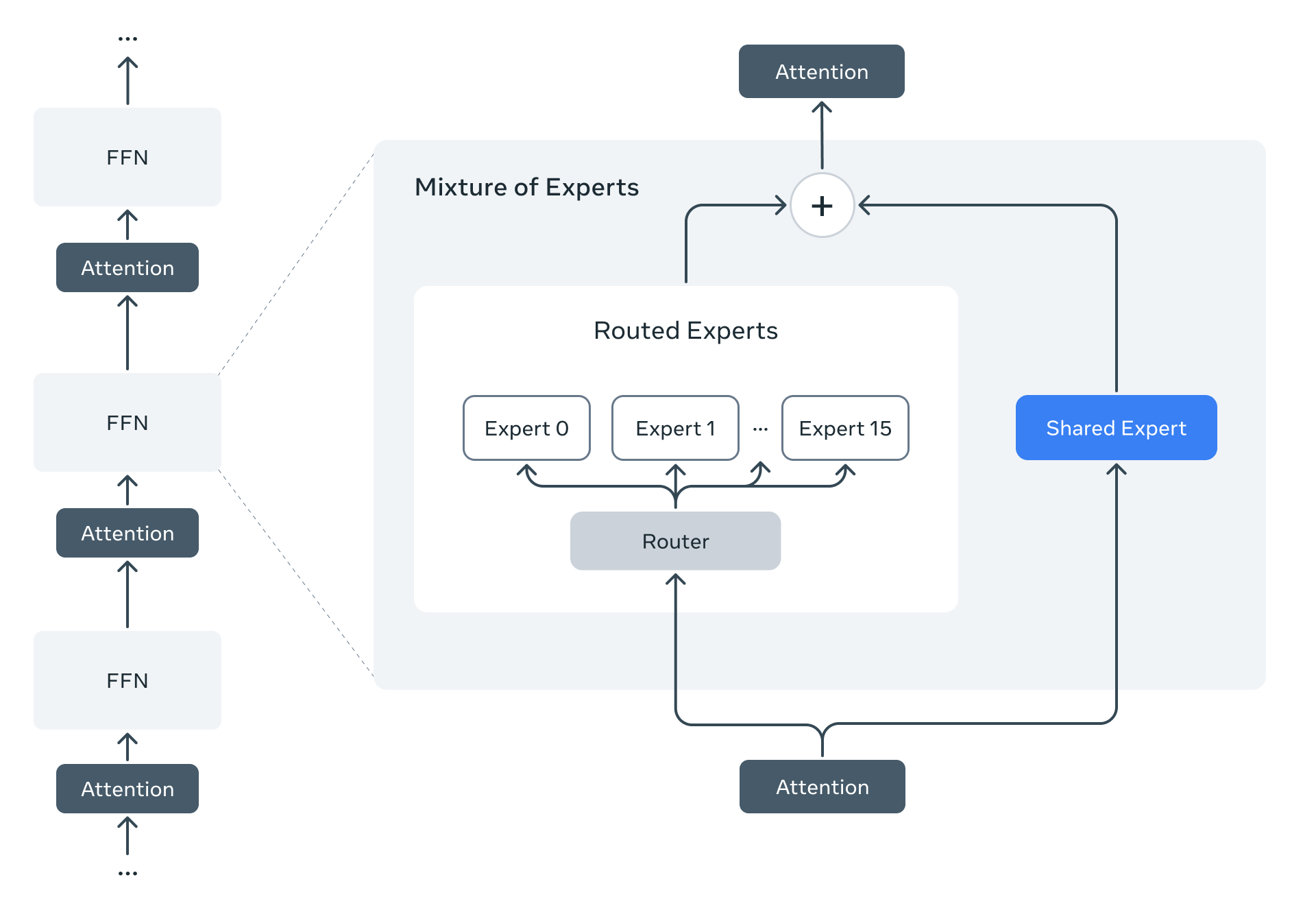
One of the biggest breakthroughs in Llama 4 is the introduction of the Mixture-of-Experts (MoE) architecture. This is a significant shift from earlier models that used traditional dense networks, where every parameter was active for every task.
With MoE, only 2 out of many experts are activated at any time, making the model more efficient. This results in less computational requirement for every task, enabling faster responses while maintaining or even improving accuracy. The MoE architecture allows Llama 4 to scale more effectively and handle complex tasks at reduced operational costs.
Increased Context Length
Alongside the MoE architecture, the context length of the new Llama model is also something to talk about. With its ability to process up to 10 million tokens, Llama 4 has made a massive jump from its predecessors.
The expanded context window means Llama 4 can maintain context over longer documents or extended conversations. It can remember more details and process complex information in a single pass. This makes it perfect for tasks like:
- Long-form document analysis (e.g., academic papers, legal documents)
- Multi-turn conversations that require remembering context over hours or days
- Multi-page web scraping, where extracting insights from vast amounts of content is needed
The ability to keep track of increased data is a game-changer for industries where deep understanding and long-term context retention are crucial.
Explore the context window paradox in LLMs
Multimodal Capabilities
Where Llama 2 and Llama 3 focused on text-only tasks, Llama 4 takes it a step further with multimodal capabilities. It enabled the LLM to process both text and image inputs, opening up a wide range of applications for the model. Such as:
- Document parsing: Reading, interpreting, and extracting insights from documents that include images, charts, and graphs
- Image captioning: Generating descriptive captions based on the contents of images
- Visual question answering: Allowing users to ask questions about images, like “What is this graph showing?” or “What’s the significance of this chart?”
This multimodal ability opens up new doors for AI to solve complex problems that involve both visual and textual data.
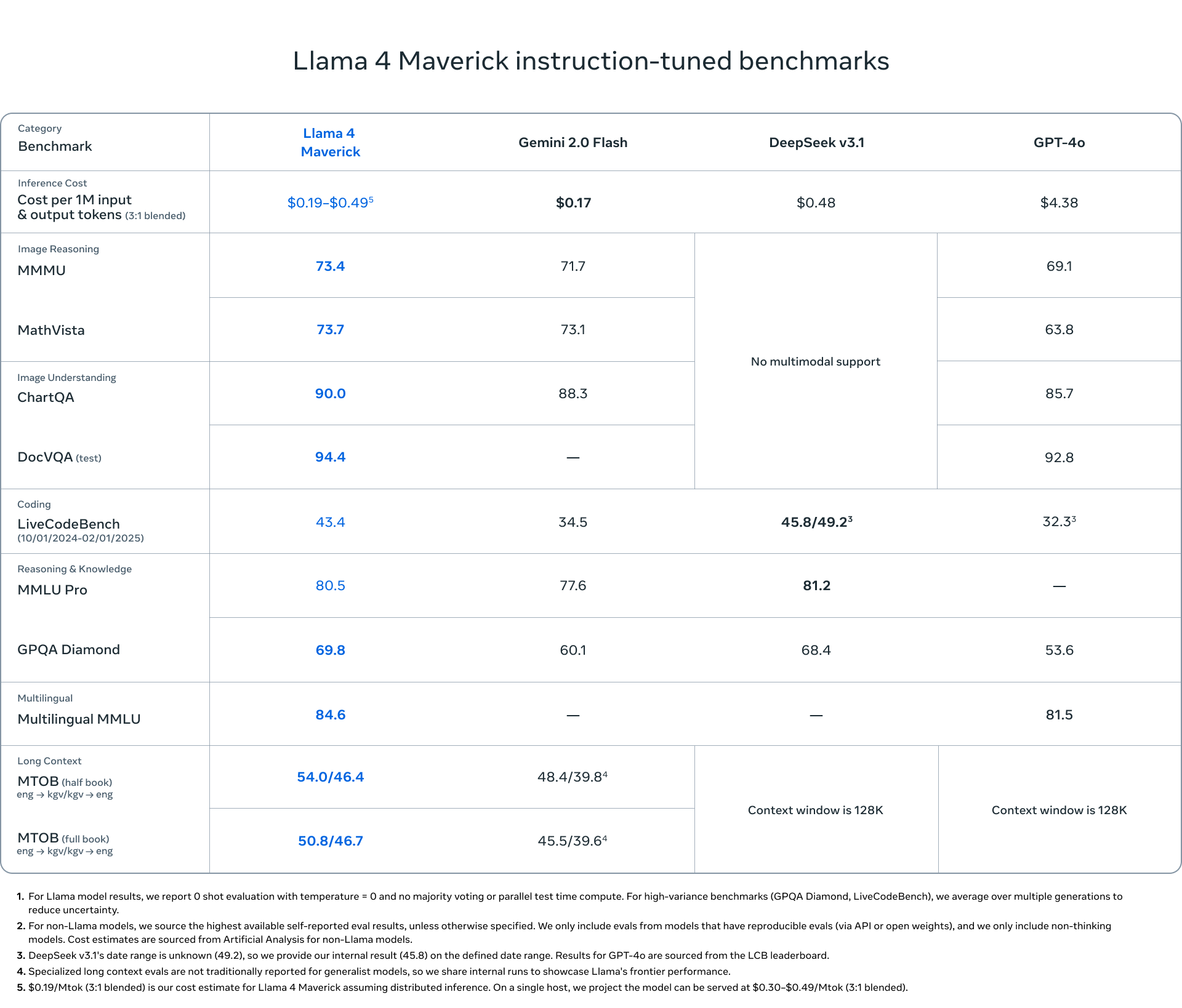
State-of-the-Art Performance
When it comes to performance, Llama 4 holds its own against the biggest names in the AI world, such as GPT-4 and Claude 3. In certain benchmarks, especially around reasoning, coding, and multilingual tasks, Llama 4 rivals or even surpasses these models.
-
Reasoning: The expanded context and MoE architecture allow Llama 4 to think through more complicated problems and arrive at accurate answers.
-
Coding: Llama 4 is better equipped for programming tasks, debugging code, and even generating more sophisticated algorithms.
-
Multilingual tasks: With support for many languages, Llama 4 performs excellently in translation, multilingual content generation, and cross-lingual reasoning.
This makes Llama 4 a versatile language model that can handle a broad range of tasks with impressive accuracy and speed.

In short, Llama 4 redefines what a large language model can do. The MoE architecture brings efficiency, the massive context window enables deeper understanding, and the multimodal capabilities allow for more versatile applications.
When compared to Llama 2 and Llama 3, it’s clear that Llama 4 is a major leap forward, offering both superior performance and greater flexibility. This makes it a game-changer for enterprises, startups, and researchers alike.
Exploring the Llama 4 Variants
One of the most exciting parts of Meta’s Llama 4 release is the range of model variants tailored for different use cases. Whether you’re a startup looking for fast, lightweight AI or a research lab aiming for high-powered computing, there’s a Llama 4 model built for your needs.
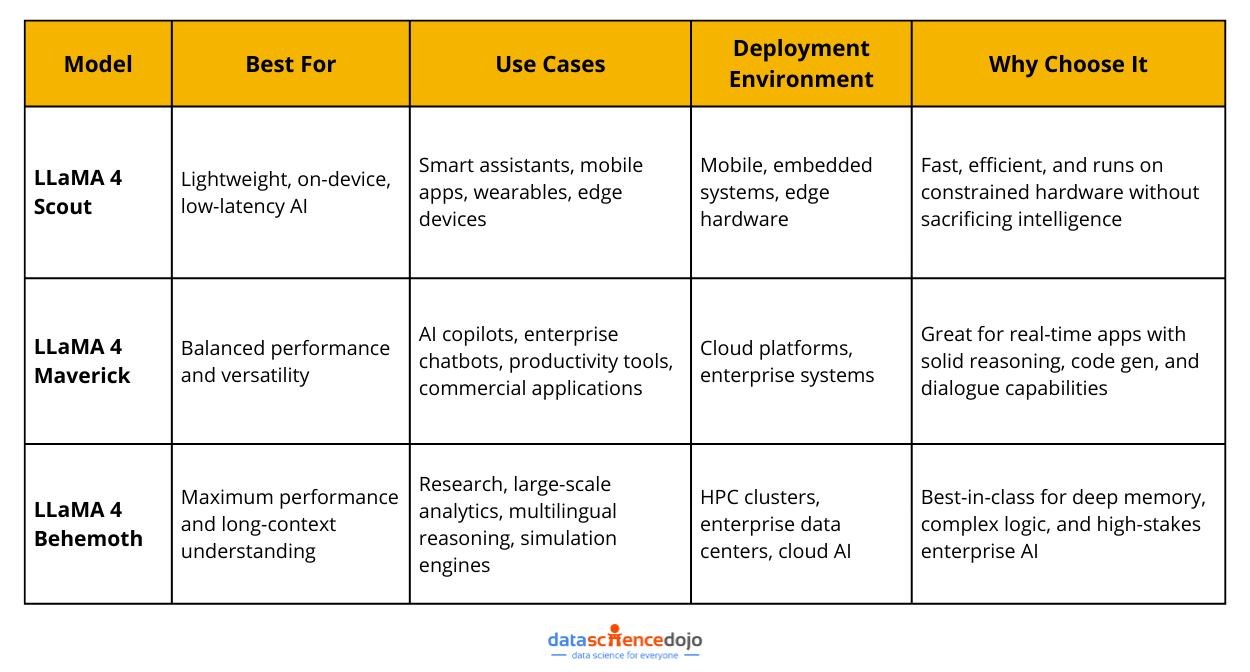
Let’s take a closer look at the key variants: Behemoth, Maverick, and Scout.
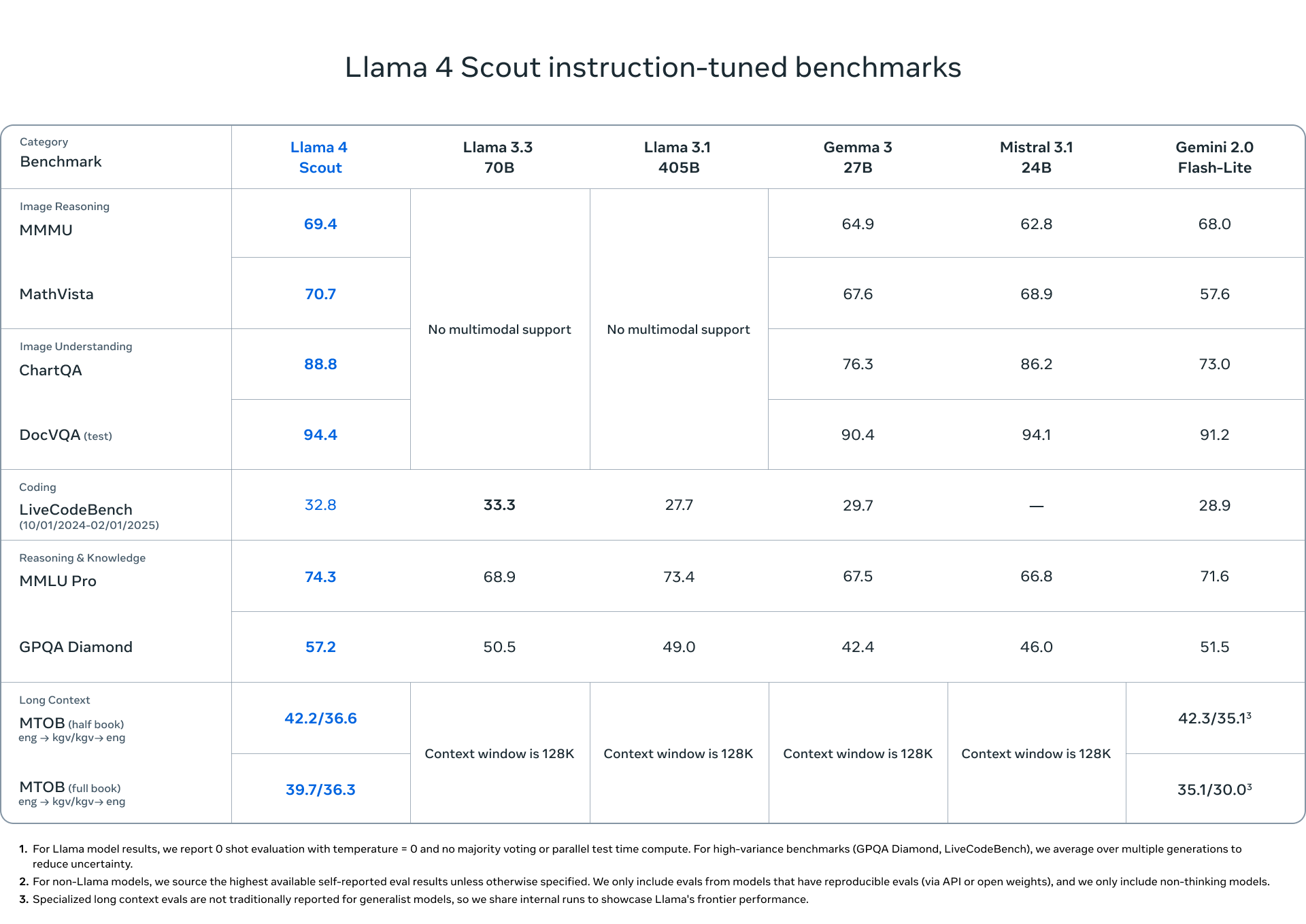
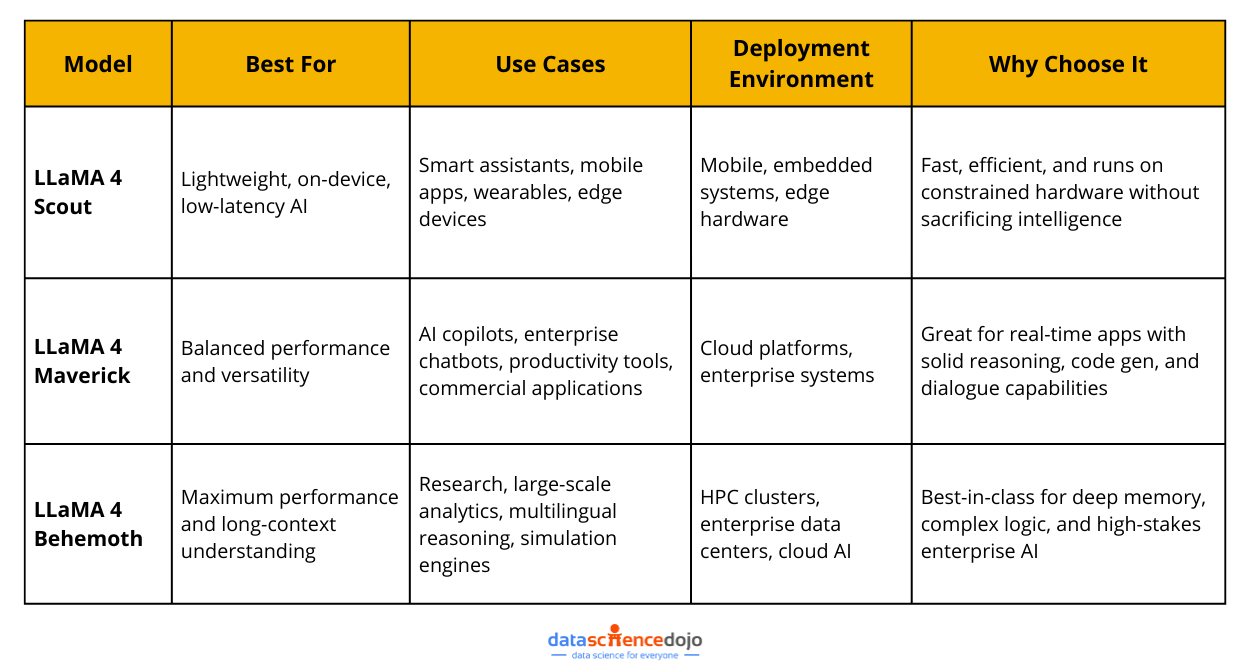
1. Llama 4 Scout: The Lightweight Variant
With our growing reliance and engagement through edge devices like mobile phones, there is an increased demand for models that operate well in mobile and edge applications. This is where Llama 4 Scout steps as this lightweight model is designed for such applications.
Scout is designed to operate efficiently in environments with limited computational resources, making it perfect for real-time systems and portable devices. Its speed and responsiveness, with a compact architecture, make it a promising choice.
It runs with 17 billion active parameters and 109 billion total parameters while ensuring smooth operation even on devices with limited hardware capabilities.
Built for the Real-Time World
Llama 4 Scout is a suitable choice for real-time response tasks where you want to avoid latency at all costs. This makes it a good choice for applications like real-time feedback systems, smart assistants, and mobile devices. Since it is optimized for low-latency environments, it works incredibly well in such applications.
It also brings energy-efficient AI performance, making it a great fit for battery-powered devices and constrained compute environments. Thus, Llama 4 Scout brings the power of LLMs to small-scale applications while ensuring speed and efficiency.
If you’re a developer building for mobile platforms, smartwatches, IoT systems, or anything that operates in the field, Scout should be on your radar. It’s especially useful for teams that want their AI to run on-device, rather than relying on cloud calls.
You can also learn about edge computing and its impact on data science
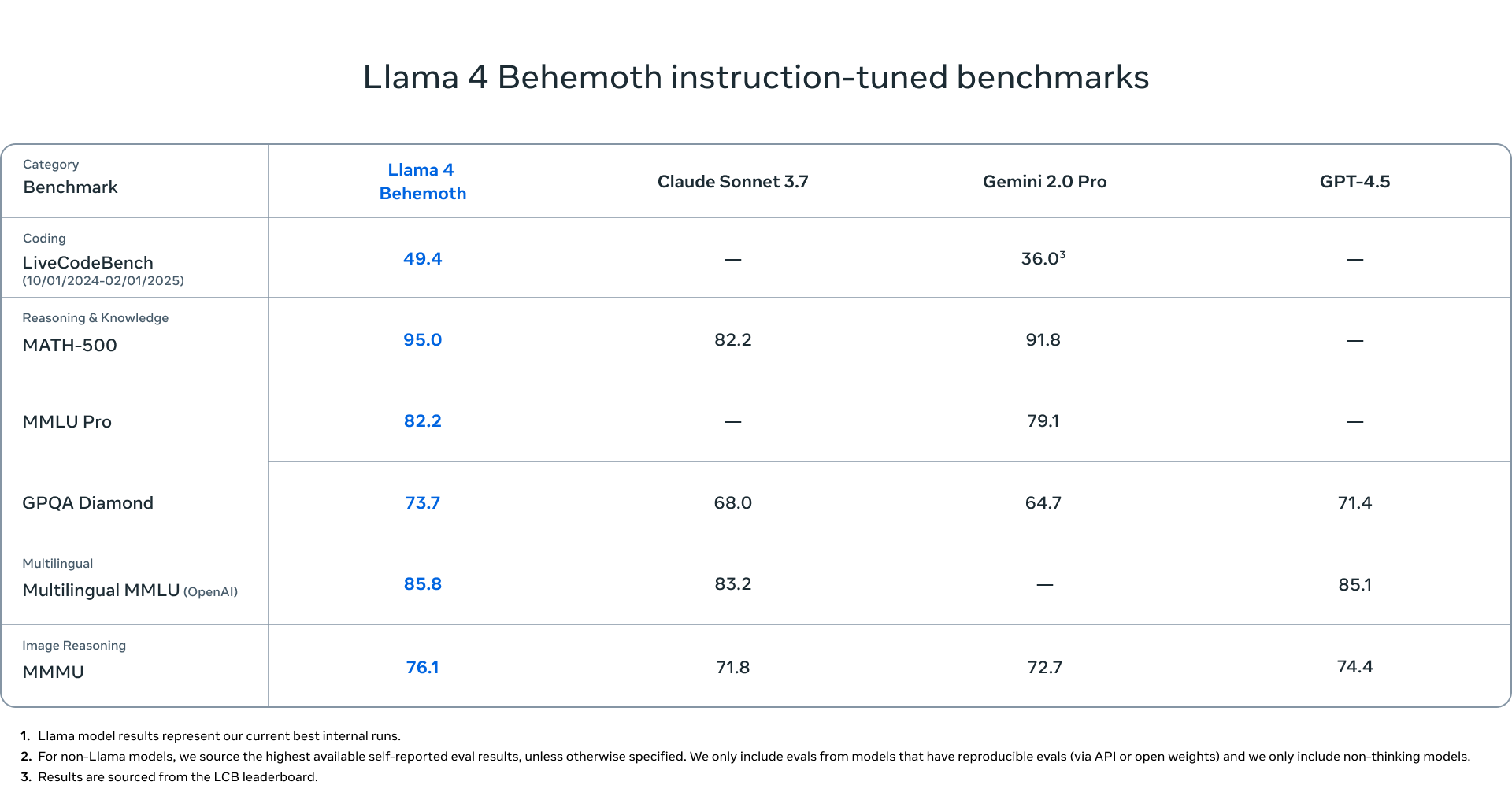
2. Llama 4 Behemoth: The Powerhouse
If Llama 4 Scout is the lightweight champion among the variants, Llama 4 Behemoth is the language model operating at the other end of the spectrum. It is the largest and most capable of Meta’s Llama 4 lineup, bringing exceptional computational abilities to complex AI challenges.
With 288 billion active parameters and 2 trillion total parameters, Behemoth is designed for maximum performance at scale. This is the kind of model you bring in when the stakes are high, the data is massive, and the margin for error is next to none.
Designed for Big Thinking
Behemoth’s massive parameter count ensures deep understanding and nuanced responses, even for highly complex queries. Thus, the LLM is ideal for high-performing computing, enterprise-level AI systems, and cutting-edge research. This makes it a model that organizations can rely on for AI innovation at scale.
Llama 4 Behemoth is a robust and intelligent language model that can handle multilingual reasoning, long-context processing, and advanced research applications. Thus, it is ideal for high-stakes domains like medical research, financial modeling, large-scale analytics, or even AI safety research, where depth, accuracy, and trustworthiness are critical.
3. Llama 4 Maverick: The Balanced Performer
Not every application needs a giant model like Behemoth, nor can they always run on the ultra-lightweight Scout. Thus, for the ones following the middle path, there is Llama 4 Maverick. Built for versatility, it is an ideal choice for teams that need production-grade AI to scale, respond quickly, and integrate easily into day-to-day tools.
With 17 billion active parameters and 400 billion total parameters, Maverick has enough to handle demanding tasks like code generation, logical reasoning, and dynamic conversations. It is the right balance between strength and speed that enables it to run and deploy smoothly in enterprise settings.
Made for the Real World
This mid-sized variant is optimized for commercial applications and built to solve real business problems. Whether you’re enhancing a customer service chatbot, building a smart productivity assistant, or powering an AI copilot for your sales team, Maverick is ready to plug in and go.
Its architecture is optimized for low latency and high throughput, ensuring consistent performance even in high-traffic environments. Maverick can deliver high-quality outputs without consuming huge compute resources. Thus, it is perfect for companies that need reliable AI performance with a balance of speed, accuracy, and efficiency.
Choosing the Right Variant
These variants ensure that Llama 4 can cater to a diverse range of industries and applications. Hence, you can find the right model for your scale, use case, and compute budget. Whether you’re a researcher, a business owner, or a developer working on mobile solutions, there’s a Llama 4 model designed to meet your needs.
Each variant is not just a smaller or larger version of the same model, but it is purpose-built to provide optimized performance for the task at hand. This flexibility makes Llama 4 not just a powerful AI tool but also an accessible one that can transform workflows across the board.
Here’s a quick overview of the three models to assist you in choosing the right variant for your use:
How is Llama 4 Reshaping the AI Landscape?
While we have explored each variant of Llama 4 in detail, you still wonder what makes it a key player in the AI market. Just like every development within the AI world leaves a lasting mark on its future, Llama 4 will also play its part in reshaping its landscape. Some key factors to consider in this would be:
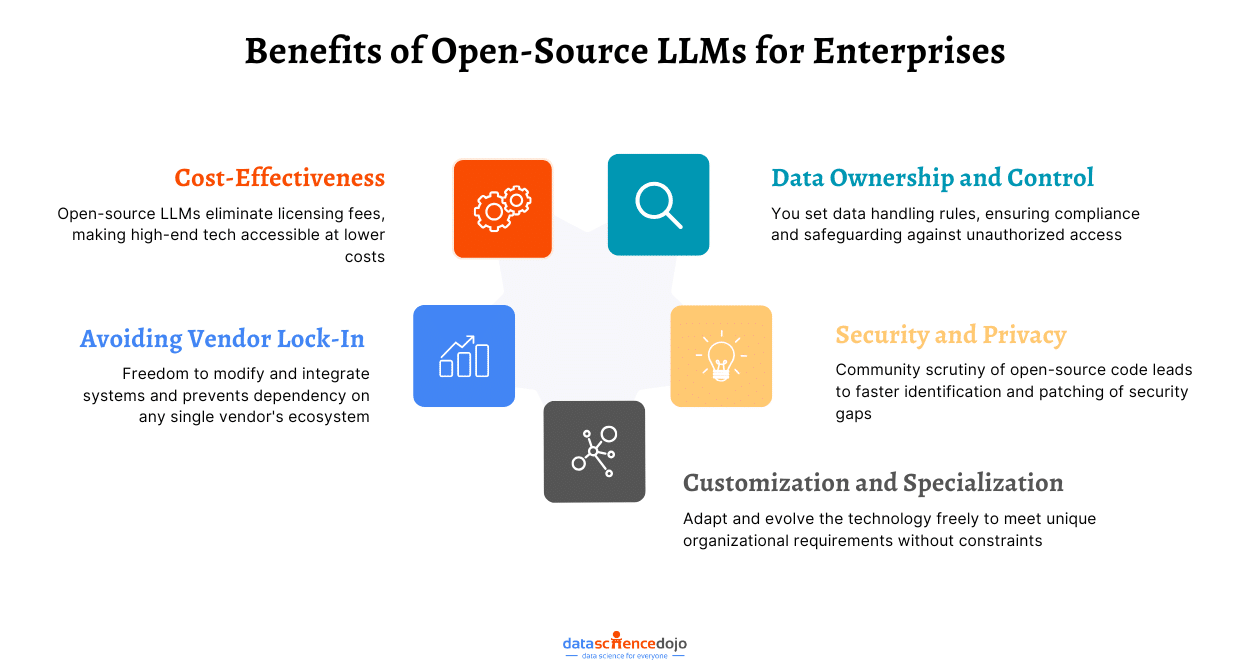
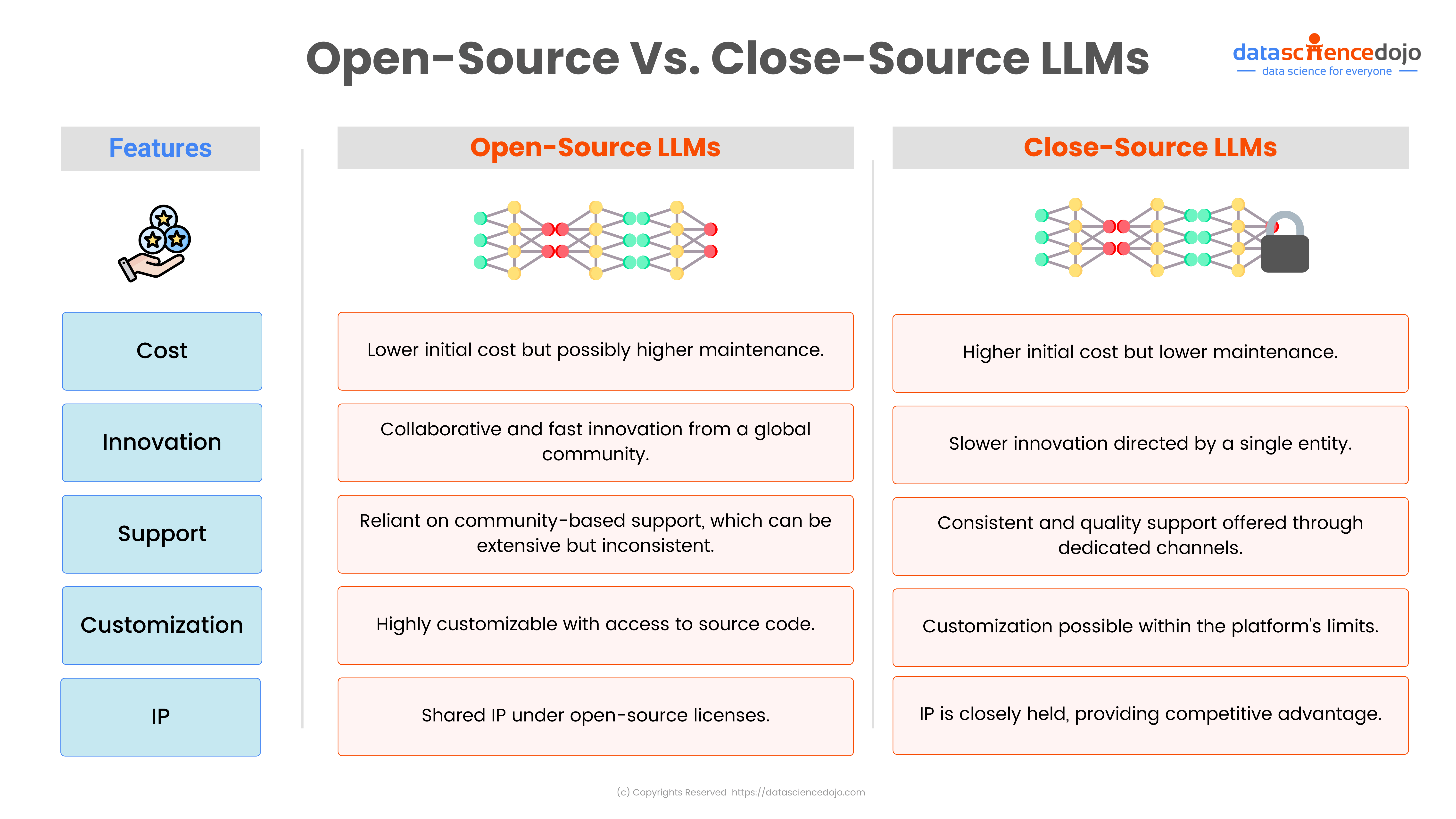
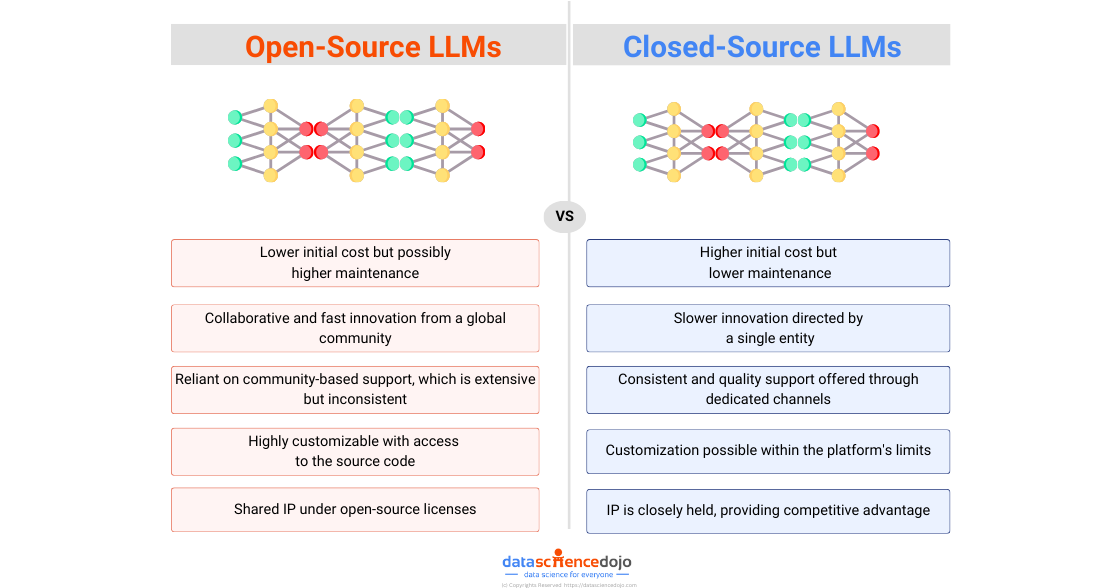
Open, Accessible, and Scalable: At its core, Llama 4 is open-source, and that changes everything. Developers and companies no longer need to rely solely on expensive APIs or be locked into proprietary platforms. Whether you are a two-person startup or a university research lab, you can now run state-of-the-art AI locally or in your own cloud, without budget constraints.
Learn all you need to know about open-source LLMs
Efficiency, Without Compromise: The Mixture-of-Experts (MoE) architecture only activates the parts of the model it needs for any given task. This means less compute, faster responses, and lower costs while maintaining top-tier performance. For teams with limited hardware or smaller budgets, this opens the door to enterprise-grade AI without enterprise-sized bills.
No More Context Limits: A massive 10 million-token context window is a great leap forward. It is enough to load entire project histories, books, research papers, or a year’s worth of conversations at once. Long-form content generation, legal analysis, and deep customer interactions are now possible with minimal loss of context.
Driving Innovation Across Industries: Whether it’s drafting legal memos, analyzing clinical trials, assisting in classroom learning, or streamlining internal documentation, Llama 4 can plug into workflows across multiple industries. Since it can be fine-tuned and deployed flexibly, teams can adapt it to exactly what they need.

A Glimpse Into What’s Next
We are entering a new era where open-source innovation is accelerating, and companies are building on that momentum. As AI continues to evolve, we can expect the rise of domain-specific models for industries like healthcare and finance, and the growing reality of edge AI with models that can run directly on mobile and embedded devices.
And that’s just the beginning. The future of AI is being shaped by:
- Hybrid architectures combining dense and sparse components for smarter, more efficient performance.
- Million-token context windows that enable persistent memory, deeper conversations, and more context-aware applications.
- LLMs as core infrastructure, powering everything from internal tools and AI copilots to fully autonomous agents.

Thus, with Llama 4, Meta has not just released a model, but given the world a launchpad for the next generation of intelligent systems.