The ongoing battle ‘Bard vs ChatGPT’ continues as the two prominent contenders in the generative AI landscape which have garnered substantial interest. As the rivalry between these platforms escalates, it continues to captivate the attention of both enthusiasts and experts.
These AI models are transforming how we interact with technology, offering unprecedented capabilities in understanding and generating human-like text. This blog delves into a detailed comparison of Bard and ChatGPT, exploring their features, applications, and the role of chatbots in modern technology.

What are Chatbots?
Chatbots are revolutionizing the way we interact with technology. These artificial intelligence (AI) programs are designed to simulate human conversation through text or voice interactions as software applications. They are programmed to understand and respond to user queries, provide information, and assistance, or perform specific tasks.
Two of the most popular chatbots on the market today are Bard vs ChatGPT. Both chatbots are capable of carrying on conversations with humans, but they have different strengths and weaknesses. As a cornerstone of modern digital communication, offering businesses and users a seamless way to interact with technology. Their evolution and integration into various platforms have transformed how we access information and services.
Role in AI and Technology
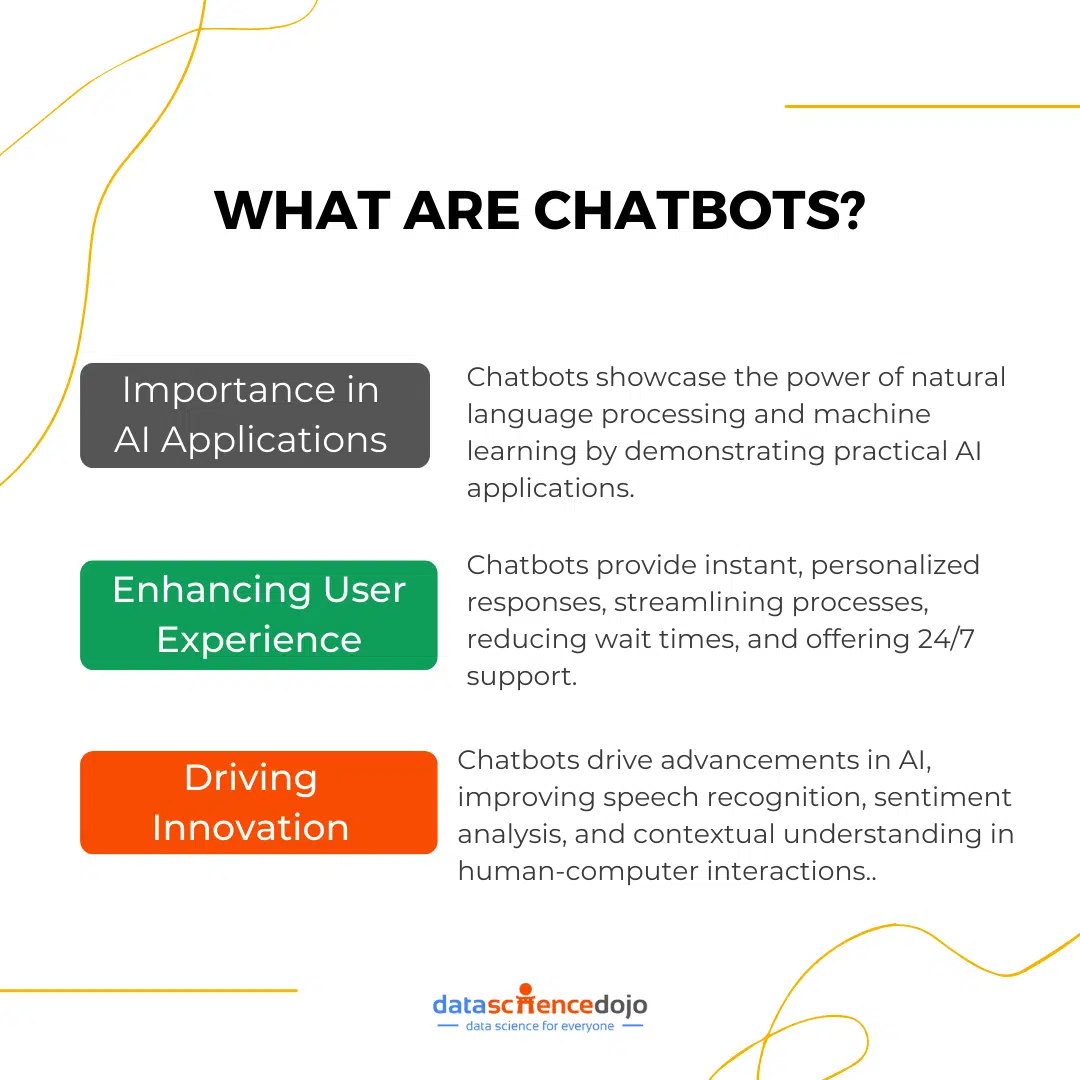
- Importance in AI Applications: Chatbots play a crucial role in the field of AI by demonstrating the practical application of natural language processing and machine learning. They serve as a bridge between humans and machines, facilitating seamless communication and interaction.
- Enhancing User Experience: By providing instant and personalized responses, chatbots enhance user experience across various platforms. They streamline processes, reduce wait times, and offer 24/7 support, making them invaluable tools for businesses and consumers alike.
- Driving Innovation: The development and deployment of chatbots drive innovation in AI and technology. They push the boundaries of what is possible in human-computer interaction, leading to advancements in speech recognition, sentiment analysis, and contextual understanding.
Chatbots have evolved from simple rule-based systems to sophisticated AI-driven applications. Their role in AI and technology is pivotal, as they enhance user experiences and drive innovation across industries. Understanding the different types of chatbots helps businesses choose the right solution to meet their specific needs.
Dive deep into 5 free tools for detecting ChatGPT
ChatGPT
ChatGPT was created by OpenAI and is based on the GPT-3 language model. It is trained on a massive dataset of text and code, and is able to generate text, translate languages, write different kinds of creative content, and answer your questions in an informative way.
Developed by OpenAI, ChatGPT has become a cornerstone in the field of conversational AI, offering a wide array of applications and functionalities that cater to diverse industries.
Explore 10 innovative ways to monetize using AI
ChatGPT, short for “Chat Generative Pre-trained Transformer,” is an AI language model designed to generate human-like text based on the input it receives. It is part of the GPT (Generative Pre-trained Transformer) family, which has been at the forefront of AI research and development.
The journey of ChatGPT began with the release of the original GPT model, which laid the foundation for subsequent iterations. Each version of GPT has built upon the successes and learnings of its predecessors, culminating in the sophisticated capabilities of ChatGPT.
Key Features
ChatGPT is renowned for its core functionalities and strengths, which make it a versatile tool for various applications. Some of the key features include:
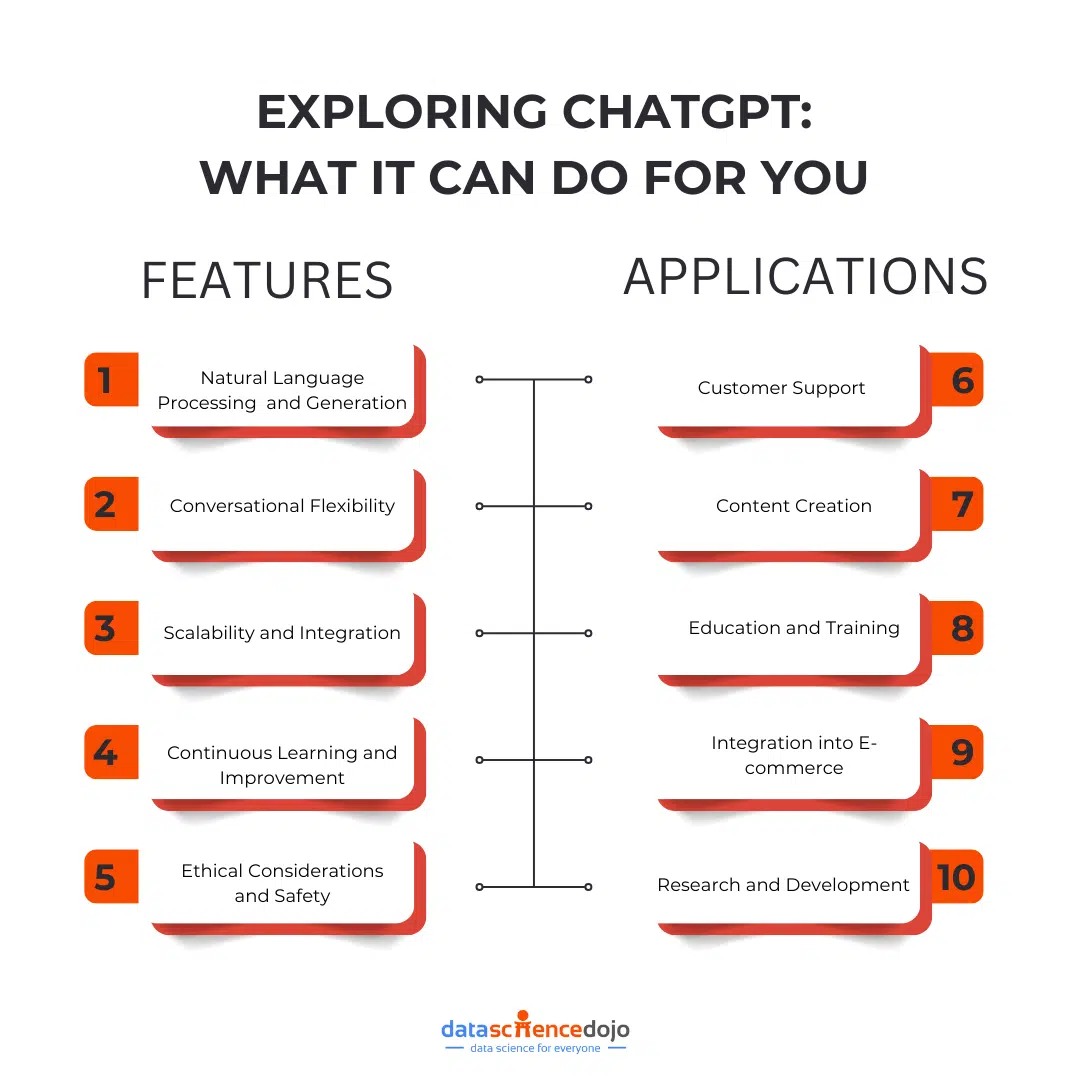
- Natural Language Understanding and Generation: ChatGPT excels in understanding context and generating coherent, contextually relevant responses. Its ability to process and produce text that closely resembles human language is a testament to its advanced natural language processing capabilities.
- Conversational Flexibility: One of ChatGPT’s standout features is its adaptability to different conversational styles and tones. Whether engaging in casual dialogue or providing detailed explanations, ChatGPT can adjust its responses to suit the context and audience.
- Scalability and Integration: ChatGPT is designed to be easily integrated into various platforms and applications. Its scalability allows businesses to deploy it across multiple channels, enhancing user engagement and interaction.
- Continuous Learning and Improvement: OpenAI has implemented mechanisms for continuous learning and improvement in ChatGPT. Through user feedback and ongoing research, the model is regularly updated to enhance its performance and address any limitations.
- Ethical Considerations and Safety: OpenAI prioritizes ethical considerations in the development of ChatGPT. The model is equipped with safety measures to minimize harmful outputs and ensure responsible use, reflecting OpenAI’s commitment to creating AI that benefits society.

Applications
ChatGPT’s versatility is reflected in its wide range of applications across various sectors. Some of the key features include:
- Customer Support: Many businesses leverage ChatGPT to enhance their customer support services. By providing instant, accurate responses to customer inquiries, ChatGPT helps improve customer satisfaction and streamline support operations.
- Content Creation: Content creators and marketers use ChatGPT to generate engaging and relevant content. From drafting articles and social media posts to creating product descriptions, ChatGPT assists in producing high-quality content efficiently.
- Education and Training: In the education sector, ChatGPT serves as a valuable tool for personalized learning experiences. It can assist students with homework, provide explanations on complex topics, and offer language learning support.
- E-commerce: E-commerce platforms integrate ChatGPT to enhance the shopping experience. By offering personalized product recommendations and assisting with purchase decisions, ChatGPT helps drive sales and improve customer loyalty.
- Research and Development: Researchers and developers use ChatGPT to explore new possibilities in AI and machine learning. Its capabilities in language processing and generation open up avenues for innovation and experimentation.
ChatGPT is a powerful AI model that has transformed the landscape of conversational AI. Its development by OpenAI, coupled with its robust features and diverse applications.
Bard
Bard is a large language model from Google AI, trained on a massive dataset of text and code. It can generate text, translate languages, write different kinds of creative content, and answer your questions in an informative way.
One of Bard’s strengths is its access to real-time information. Bard is able to access and process information from the internet in real-time, which means that it can provide up-to-date information on a wide range of topics. It accesses and processes information from other sources, such as books, articles, and websites.
Bard is an advanced AI language model developed to facilitate seamless and intuitive interactions between humans and machines. Unlike traditional AI models, Bard is specifically engineered to excel in creative and language-intensive tasks.
The development of Bard was driven by the need for an AI model that could understand and generate text with a high degree of creativity and contextual awareness. Its creators focused on building a model that not only processes language but also appreciates the subtleties and intricacies of human expression.
Key Features
Bard’s core functionalities and strengths make it a standout model in the AI landscape. Following are some major features:
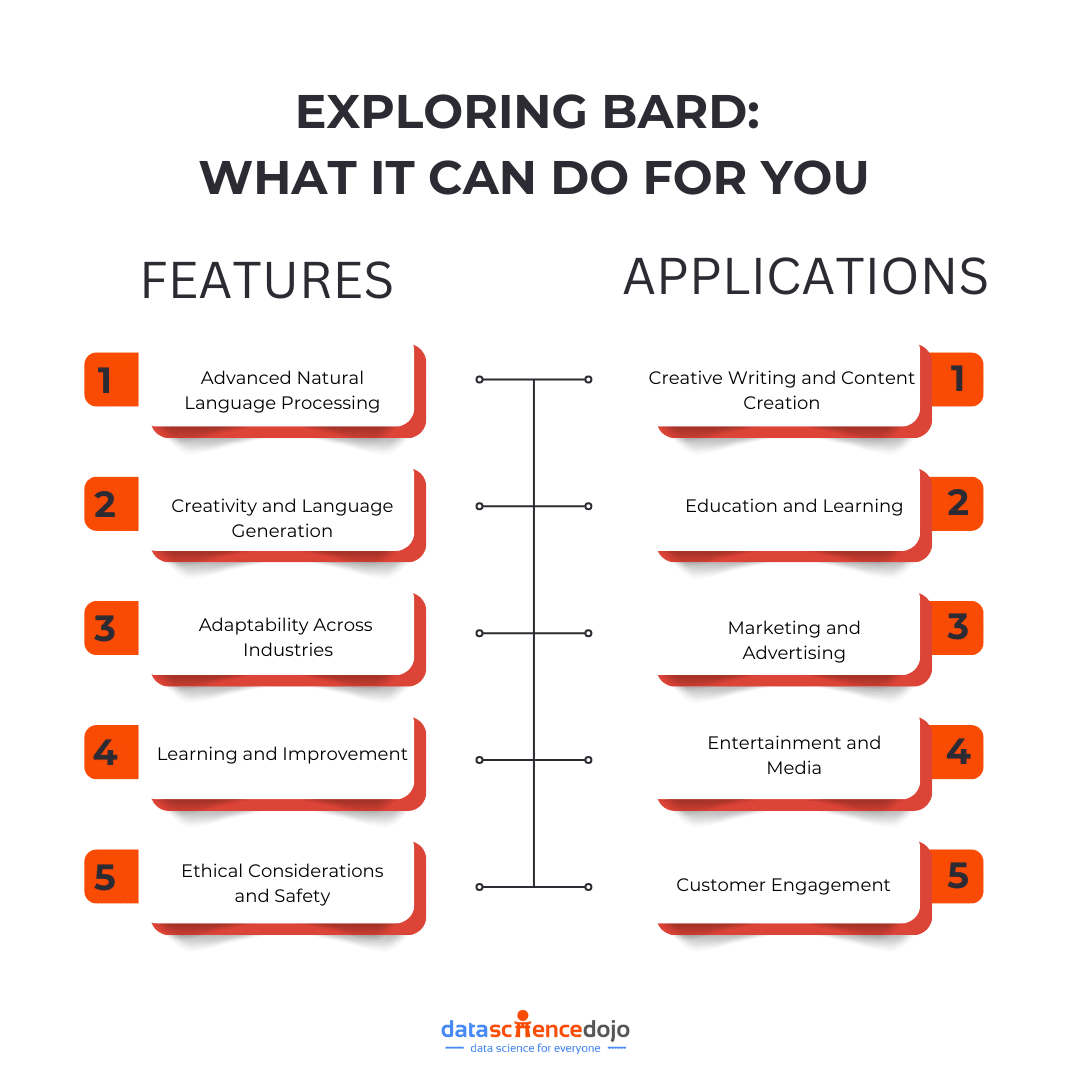
- Advanced Natural Language Processing: Bard is equipped with sophisticated natural language processing capabilities, allowing it to understand and generate text that is both coherent and contextually relevant. Its ability to grasp the nuances of language makes it ideal for tasks that require a deep understanding of context and meaning.
- Creativity and Language Generation: One of Bard’s defining features is its ability to generate creative and original content. Whether crafting poetry, writing stories, or composing music, Bard’s creative prowess sets it apart from other AI models.
- Adaptability Across Industries: Bard’s versatility allows it to be applied across a wide range of industries, from entertainment and media to education and marketing. Its adaptability ensures that it can meet the specific needs of different sectors, providing tailored solutions that enhance communication and engagement.
- Learning and Improvement: Bard is designed to learn from interactions and improve over time. This continuous learning process enables it to refine its responses and adapt to changing user needs, ensuring that it remains a valuable tool for businesses and developers.
- Ethical Considerations and Safety: The development of Bard is guided by a commitment to ethical AI practices. Safety measures are in place to minimize the risk of harmful outputs, ensuring that Bard is used responsibly and for the benefit of society.
Applications
Bard’s unique capabilities have led to its adoption in various applications and sectors. Some of the few applications are:
- Creative Writing and Content Creation: Bard is widely used in the creative industries for tasks such as writing scripts, generating story ideas, and composing music. Its ability to produce original and engaging content makes it a valuable tool for writers, artists, and content creators.
- Education and Learning: In the education sector, Bard is used to develop interactive learning materials and personalized educational content. Its ability to generate creative and informative text supports educators in delivering engaging and effective learning experiences.
- Marketing and Advertising: Bard’s creative capabilities are leveraged in marketing and advertising to craft compelling copy and develop innovative campaigns. Its ability to generate unique and persuasive content helps businesses capture the attention of their target audience.
- Entertainment and Media: The entertainment industry utilizes Bard to create immersive and interactive experiences. From developing video game narratives to generating dialogue for virtual characters, Bard’s creative potential enhances the storytelling process.
- Customer Engagement: Businesses use Bard to enhance customer engagement through personalized and creative interactions. Its ability to generate contextually relevant responses helps build stronger connections with customers and improve overall satisfaction.
Bard is a powerful AI model that excels in creative and language-intensive tasks. Its development and unique features make it a valuable asset for industries seeking to enhance communication and engagement through innovative AI-driven solutions.
Bard vs ChatGPT: Strengths and Weaknesses
Following comparison provides insights into the differences between Bard and GPT across various aspects, helping users understand their unique strengths and applications.

ChatGPT
Strengths: One of ChatGPT’s most notable strengths is its ability to generate creative text formats. Whether it’s writing poems, code, scripts, musical pieces, emails, or letters, ChatGPT’s output often mirrors human-written text.
This capability makes it an invaluable tool for content creators and those seeking innovative solutions. Additionally, ChatGPT excels at answering questions, providing comprehensive and informative responses even to open-ended, challenging, or unusual queries.
Weaknesses: Despite its creative prowess, ChatGPT has some notable weaknesses. A significant concern is its tendency to generate factually incorrect text. This issue arises because ChatGPT is trained on a vast dataset, which includes inaccurate information.
Consequently, it can sometimes produce misleading or incorrect content. Another limitation is its lack of access to real-time information. Trained on data up to 2021, ChatGPT may provide outdated or inaccurate information, limiting its utility in scenarios requiring current data.
Bard
Strengths: Bard’s strength lies in its ability to generate accurate text. Trained on a carefully curated dataset, Bard is less likely to produce factually incorrect content compared to ChatGPT. This focus on accuracy makes Bard a reliable choice for tasks where precision is paramount, such as technical writing or data-driven content.
Weaknesses: However, Bard is not without its weaknesses. One of its primary limitations is its lack of creativity. While Bard excels in generating factually accurate text, it often struggles to produce content that is engaging or imaginative.
Its output can be dry and difficult to follow, which may not appeal to users seeking creative or captivating content. Additionally, Bard’s limited availability poses a challenge. Currently accessible only to a select group of users, it remains unclear when Bard will be widely available to the general public.
In summary, both ChatGPT and Bard offer distinct advantages and face unique challenges. ChatGPT shines in creative applications but may falter in accuracy and real-time relevance. Conversely, Bard excels in precision but lacks the creative flair and widespread accessibility. Users must weigh these factors to determine which tool aligns best with their specific needs and objectives.

Chatbots in Action
Chatbots have revolutionized the way businesses interact with customers, providing instant, personalized, and efficient communication. The integration of advanced AI models like Bard and ChatGPT has further enhanced the capabilities of chatbots, making them indispensable tools across various sectors.
Integration with Bard and ChatGPT
The integration of Bard and ChatGPT into chatbot applications has significantly elevated their functionality and effectiveness:
- Enhanced Conversational Abilities: By leveraging the natural language processing capabilities of Bard and ChatGPT, chatbots can engage in more human-like conversations. These models enable chatbots to understand context, interpret user intent, and generate responses that are coherent and contextually appropriate.
- Creative and Contextual Interactions: Bard’s creative prowess allows chatbots to engage users with imaginative and engaging content. Whether crafting personalized messages or generating creative responses, Bard enhances the chatbot’s ability to connect with users on a deeper level.
- Scalability and Flexibility: ChatGPT’s scalability ensures that chatbots can handle a large volume of interactions simultaneously, making them ideal for businesses with high customer engagement. The flexibility of these models allows chatbots to be customized for specific industries and use cases, providing tailored solutions that meet unique business needs.
Benefits of AI-driven chatbots
AI-driven chatbots offer numerous advantages that enhance business operations and customer experiences:
- 24/7 Availability: AI chatbots provide round-the-clock support, ensuring that customers can access assistance at any time. This constant availability improves customer satisfaction and reduces response times.
- Cost Efficiency: By automating routine inquiries and tasks, AI chatbots reduce the need for human intervention, leading to significant cost savings for businesses. This efficiency allows companies to allocate resources to more complex and value-added activities.
- Personalized Customer Experiences: AI chatbots can analyze user data to deliver personalized interactions, enhancing the customer experience. By tailoring responses to individual preferences and needs, chatbots build stronger relationships with users.
- Improved Accuracy and Consistency: AI-driven chatbots provide accurate and consistent responses, minimizing the risk of human error. This reliability ensures that customers receive the correct information and support every time.
Industry Applications
Chatbots powered by Bard and ChatGPT are utilized across a wide range of industries, each benefiting from their unique capabilities:
- Retail and E-commerce: In the retail sector, chatbots assist customers with product recommendations, order tracking, and customer support. By providing personalized shopping experiences, chatbots drive sales and enhance customer loyalty.
- Healthcare: Healthcare providers use chatbots to offer patients information on medical conditions, appointment scheduling, and medication reminders. These chatbots improve patient engagement and streamline healthcare services.
- Finance and Banking: Financial institutions leverage chatbots to assist customers with account inquiries, transaction details, and financial advice. By providing secure and efficient support, chatbots enhance the customer experience in the financial sector.
- Travel and Hospitality: In the travel industry, chatbots help customers with booking inquiries, itinerary planning, and travel updates. These chatbots enhance the travel experience by providing timely and relevant information.
Industry Expert Opinions
The integration of AI models like Bard and ChatGPT into chatbots has garnered attention from industry experts, who recognize their transformative potential.
Quotes from AI Experts: Dr. Jane Smith, AI Researcher says “The integration of Bard and ChatGPT into chatbots represents a significant advancement in AI technology. These models enable chatbots to deliver more personalized and engaging interactions, setting a new standard for customer communication.”
CEO of Tech Innovation, John Doe states, “AI-driven chatbots are revolutionizing the way businesses operate. By harnessing the power of Bard and ChatGPT, companies can provide exceptional customer service while optimizing their resources.”
Case Studies: A leading retail company implemented ChatGPT-powered chatbots to enhance their customer support services. The chatbots handled over 80% of customer inquiries, resulting in a 30% increase in customer satisfaction and a 20% reduction in operational costs.
A healthcare provider integrated Bard into their chatbot system to offer patients creative and informative health content. The chatbot’s ability to generate personalized wellness tips and reminders improved patient engagement and adherence to treatment plans.
In summary, the integration of Bard and ChatGPT into chatbots has transformed the landscape of customer interaction. With their advanced capabilities and diverse applications, AI-driven chatbots are poised to continue shaping the future of communication across industries.
ChatGPT vs Bard: Which AI chatbot is right for you?
Chatbots are still in their early stages of development, but they can potentially revolutionize how we interact with technology. As chatbots become more sophisticated, they will become increasingly useful and popular. In the future, it is likely that chatbots will be used in a wide variety of settings, including customer service, education, healthcare, and entertainment. Chatbots have the potential to make our lives easier, more efficient, and more enjoyable.

When it comes to AI language models, the battle of ChatGPT vs Bard is a hot topic in the tech community. But, which AI chatbot is right for you? It depends on what you are looking for. If you are looking for a chatbot that can generate creative text formats, then ChatGPT is a good option. However, if you are looking for a chatbot that can provide accurate information, then Bard is a better option. Ultimately, the best way to decide which AI chatbot is right for you is to try them both out and see which one you prefer.