Want to know how to become a Data scientist? Use data to uncover patterns, trends, and insights that can help businesses make better decisions.
Imagine you’re trying to figure out why your favorite coffee shop is always busy on Tuesdays. A data scientist could analyze sales data, customer surveys, and social media trends to determine the reason. They might find that it’s because of a popular deal or event on Tuesdays.
In essence, data scientists use their skills to turn raw data into valuable information that can be used to improve products, services, and business strategies.
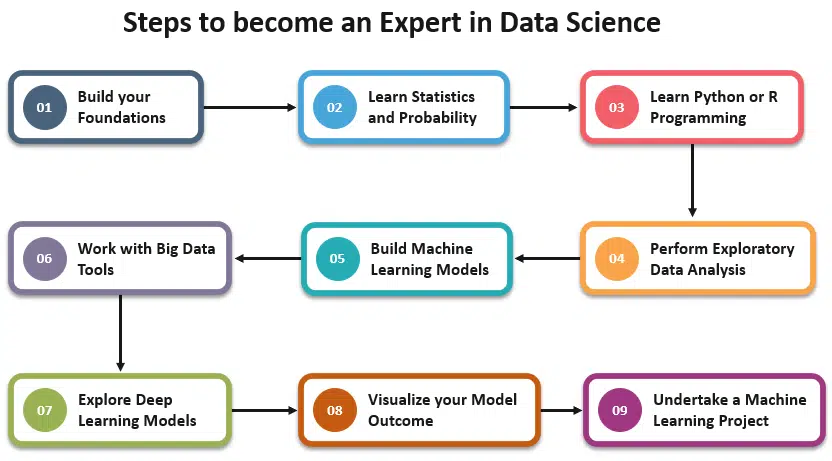
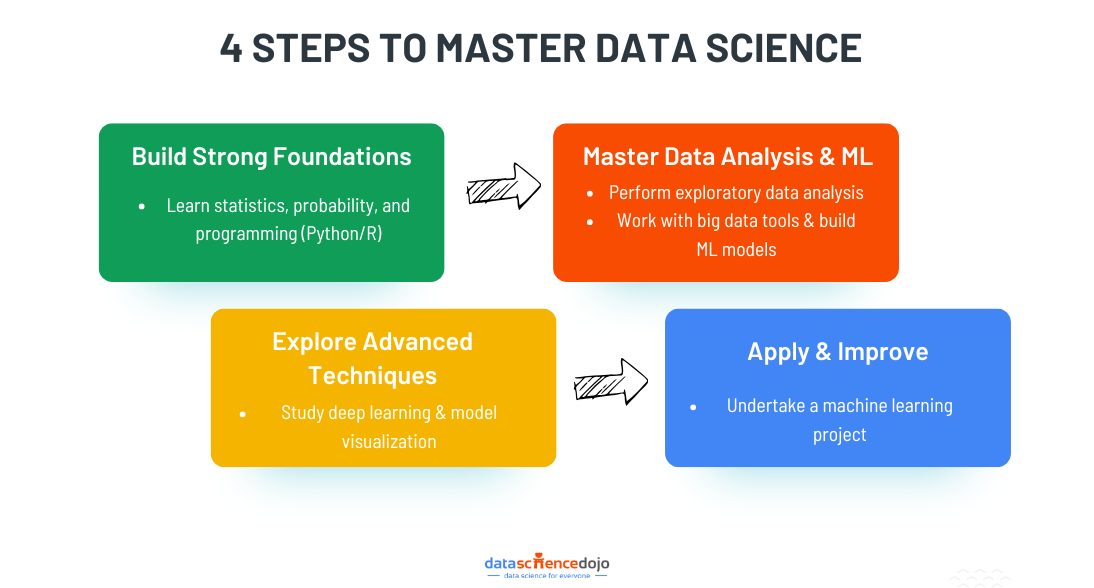
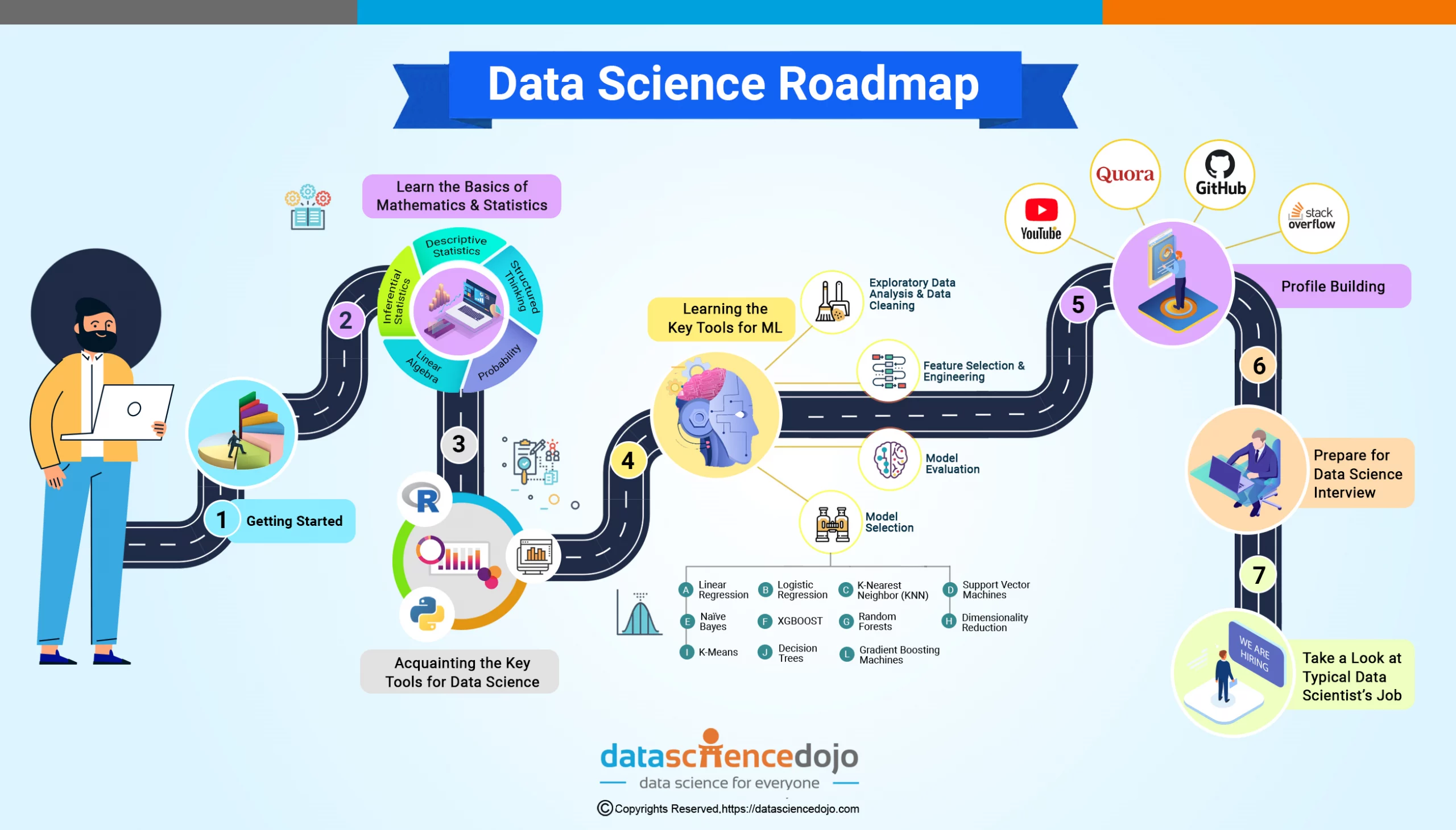
Key Concepts to Master Data Science
Data science is driving innovation across different sectors. By mastering key concepts, you can contribute to developing new products, services, and solutions.
Programming Skills
Think of programming as the detective’s notebook. It helps you organize your thoughts, track your progress, and automate tasks.
- Python, R, and SQL: These are the most popular programming languages for data science. They are like the detective’s trusty notebook and magnifying glass.
An Easy Start to Learning R Programming
- Libraries and Tools: Libraries like Pandas, NumPy, Scikit-learn, Matplotlib, Seaborn, and Tableau are like specialized tools for data analysis, visualization, and machine learning.
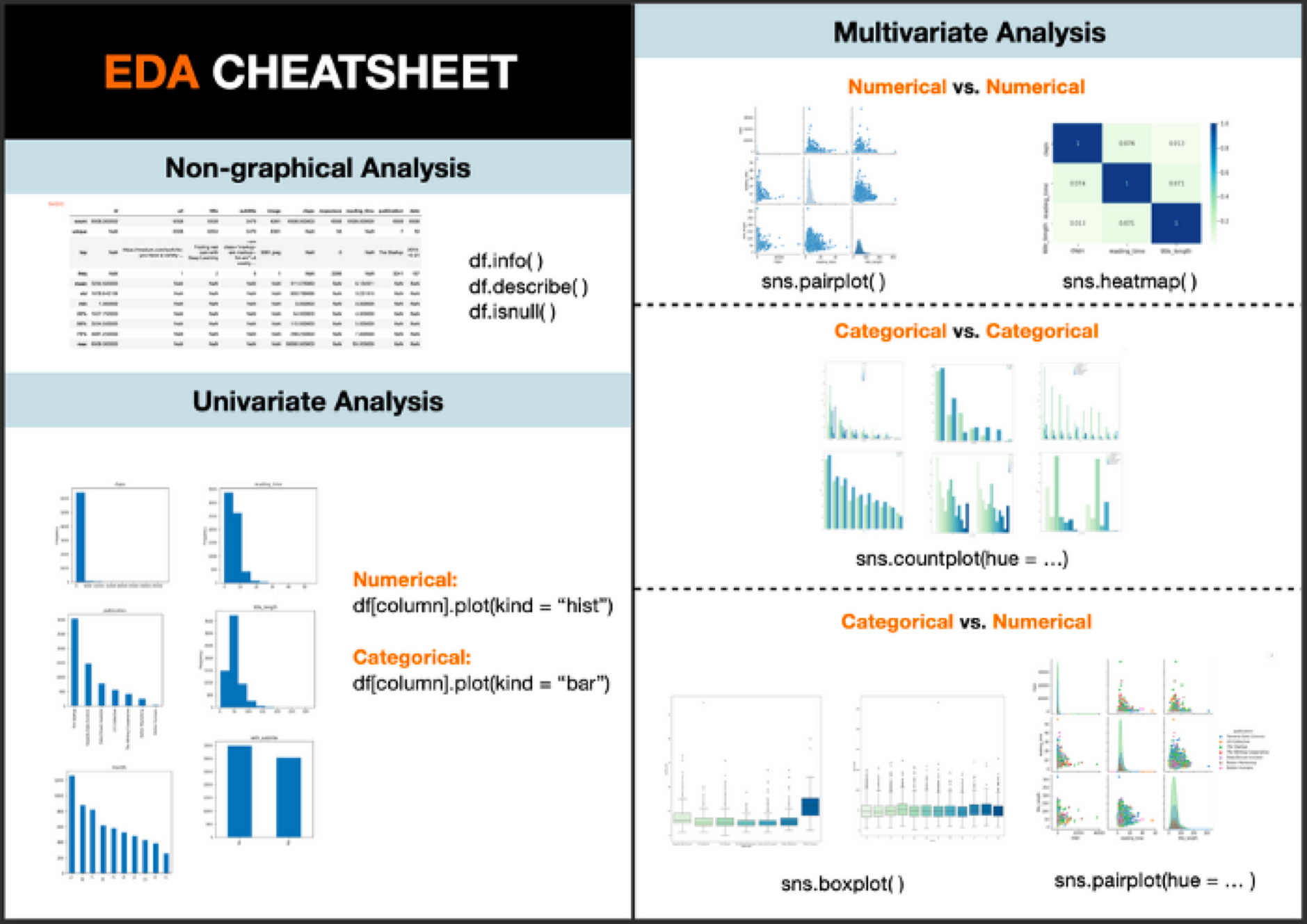
Data Cleaning and Preprocessing
Before analyzing data, it often needs a cleanup. This is like dusting off the clues before examining them.
- Missing Data: Filling in missing pieces of information.
- Outliers: Identifying and dealing with unusual data points.
- Normalization: Making data consistent and comparable.
Learn About Data Preprocessing in detail
Machine Learning
Machine learning is like teaching a computer to learn from experience. It’s like training a detective to recognize patterns and make predictions.
- Algorithms: Decision trees, random forests, logistic regression, and more are like different techniques a detective might use to solve a case.
- Overfitting and Underfitting: These are common problems in machine learning, like getting too caught up in small details or missing the big picture.
Data Visualization
Think of data visualization as creating a visual map of the data. It helps you see patterns and trends that might be difficult to spot in numbers alone.
- Tools: Matplotlib, Seaborn, and Tableau are like different mapping tools.
Big Data Technologies
It would help if you had special tools to handle large datasets efficiently.
- Hadoop and Spark: These are like powerful computers that can process huge amounts of data quickly.
Also Learn About Big Data Problems
Soft Skills
Apart from technical skills, a data scientist needs soft skills like:
- Problem-solving: The ability to think critically and find solutions.
- Communication: Explaining complex ideas clearly and effectively.
In essence, a data scientist is a detective who uses a combination of tools and techniques to uncover insights from data. They need a strong foundation in statistics, programming, and machine learning, along with good communication and problem-solving skills.
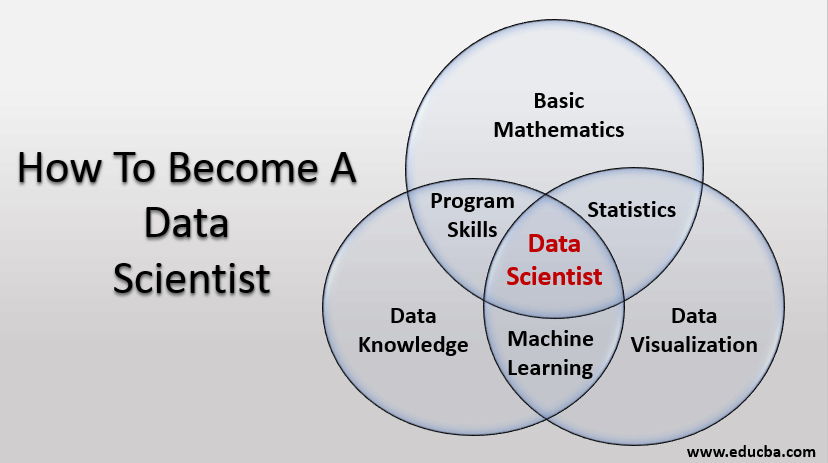
The Importance of Statistics
Statistics is the foundation of data science. It’s like the detective’s toolkit, providing the tools to analyze and interpret data. Think of it as the ability to read between the lines of the data and uncover hidden patterns.
- Data Analysis and Interpretation: Data scientists use statistics to understand what the data is telling them. It’s like deciphering a secret code.
- Meaningful Insights: Statistics helps to extract valuable information from the data, turning raw numbers into actionable insights.
- Data-Driven Decisions: Based on these insights, data scientists can make informed decisions that drive business growth.
- Model Selection: Statistics helps choose the right tools (models) for the job.
- Handling Uncertainty: Data is often messy and incomplete. Statistics helps deal with this uncertainty.
- Communication: Data scientists need to explain their findings to others. Statistics provides the language to do this effectively.
In essence, a data scientist is a detective who uses a combination of tools and techniques to uncover insights from data. They need a strong foundation in statistics, programming, and machine learning, along with good communication and problem-solving skills.
How a Data Science Bootcamp Can Help a Data Scientist
A data science bootcamp can significantly enhance a data scientist’s skills in several ways:
- Accelerated Learning: Bootcamps offer a concentrated, immersive experience that allows data scientists to quickly acquire new knowledge and skills. This can be particularly beneficial for those looking to expand their expertise or transition into a data science career.
- Hands-On Experience: Bootcamps often emphasize practical projects and exercises, providing data scientists with valuable hands-on experience in applying their knowledge to real-world problems. This can help solidify their understanding of concepts and improve their problem-solving abilities.
- Industry Exposure: Bootcamps often feature guest lectures from industry experts, giving data scientists exposure to real-world applications of data science and networking opportunities. This can help them broaden their understanding of the field and connect with potential employers.
- Skill Development: Bootcamps cover a wide range of data science topics, including programming languages (Python, R), machine learning algorithms, data visualization, and statistical analysis. This comprehensive training can help data scientists develop a well-rounded skillset and stay up-to-date with the latest advancements in the field.
- Career Advancement: By attending a data science bootcamp, data scientists can demonstrate their commitment to continuous learning and professional development. This can make them more attractive to employers and increase their chances of career advancement.
- Networking Opportunities: Bootcamps provide a platform for data scientists to connect with other professionals in the field, exchange ideas, and build valuable relationships. This can lead to new opportunities, collaborations, and mentorship.
In summary, a data science bootcamp can be a valuable investment for data scientists looking to improve their skills, advance their careers, and stay competitive in the rapidly evolving field of data science.

Learn How AI is Empowering the Education Industry
To stay connected with the data science community and for the latest updates, join our Discord channel today!