

This blog covers the 6 famous Python libraries for data science that are easy to use, have extensive documentation, and can perform computations faster.

Data scientist is the sexiest job of the 21st century, but what is a data scientist without data? Harvard Business Review labels data as the new oil. There is a massive dearth of people qualified for data-related jobs. As a beginner, you can be tempted to wet your feet in the ever-evolving field of data science.
However, Python is a programming language that can be easily learned. Sometimes, your pseudocode can directly be converted into Python code.
Python is increasingly used in data science-related tasks and is becoming the de-facto standard because it is easy to learn, easy to debug, has a rich userbase, is object-oriented, and is easy to interpret. However, you can get lost in the intricacies and subtleties of the many available specialized packages.
Fret not, because we have you covered!
You might be tempted to learn about many of these libraries, but there are some libraries that are frequently used in the domain of data science given their versatility and ease of use.
PRO TIP: Join our Python for data science course today to enhance your data science skillset!
In this blog, we will be going over the 6 most commonly used python libraries for data science:
NumPy

Be it the creation of vectors and arrays, performing some matrix multiplication, or performing singular value decomposition, NumPy is a linear algebra-based library that provides a vast repertoire of mathematical routines at your disposal.
NumPy is a library that deals with vectors, and matrices and offers fast operations. It provides various functions such as array indexing and broadcasting, consumes less memory, and is convenient.
Behind the hood, it uses multiple optimization algorithms to accelerate typically slow operations such as matrix multiplication. The automatic broadcasting takes care of different array sizes and makes life very convenient ultimately making it one of the most famous Python libraries for data science.
Pandas

Handling complex data, indexing into the data, cleaning and handling null values, merging and joining datasets, Pandas is a python library that is both easy and intuitive. Since it is built on top of NumPy, it can perform tasks that would otherwise take a lot of time.
Usually, by using native Python functionality, it becomes tough to iterate over thousands of tuples to perform some pre-processing, but by using Pandas’ wrappers, these tasks can be done in significantly less time.
Moreover, Pandas is widely used for data analysis and looking into the summary statistics, and inferring some patterns from data, which can help answer or validate our assumptions and hypothesis.
SciKit-Learn
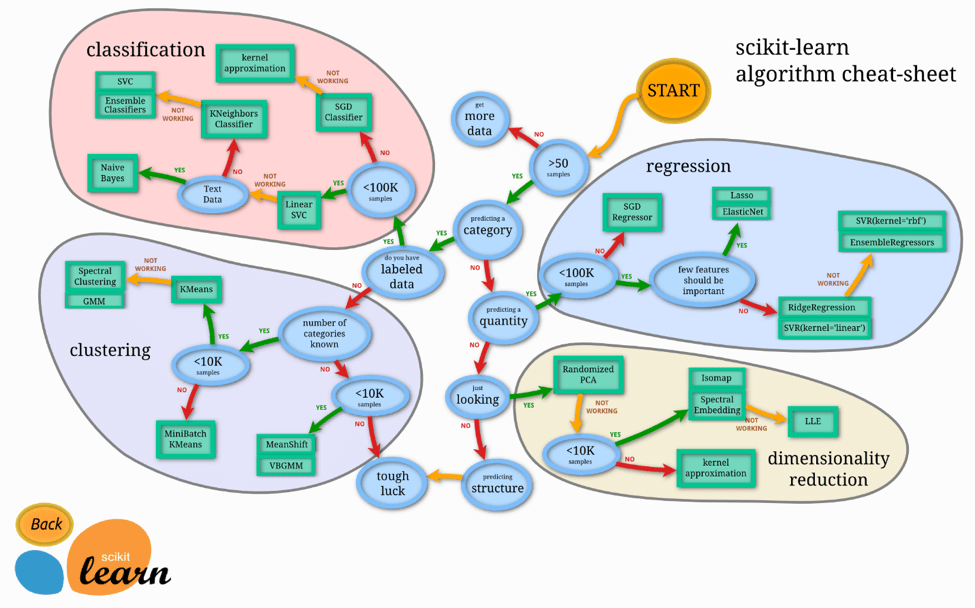
If you want to train complex machine learning models or have an ensemble of different ML models with an intuitive and easy-to-use interface, Scikit-learn is your friend. The beauty of Scikit-learn is that it provides a similar interface for every machine learning algorithm, which makes the library very intuitive to use and can easily extend the current learning algorithms by using custom cost functions and optimization algorithms.
The library also offers various optimization algorithms to tune the model’s hyperparameters. Therefore, Scikit-learn stays one of the most popular machine learning libraries for Python.
Keras

Machine learning and deep learning have become immensely popular in recent days due to ever-increasing computing power and that is why you see complicated models being developed, and Keras is a Python library for data science to do that.
Keras is a static graph-based machine learning library. One of the distinguishing features is that the computational graph of a network, once formed, will be fixed, and will not be changed on the run-time, which means that the variables will be locked at the run time, making the models very efficient.
Moreover, the Keras application programming interface is highly abstracted, which makes Keras very easy to use once you have a good grasp of Python. It is used to build custom machine learning models and is widely used in the machine learning community for research and deployment purposes.
SciPy
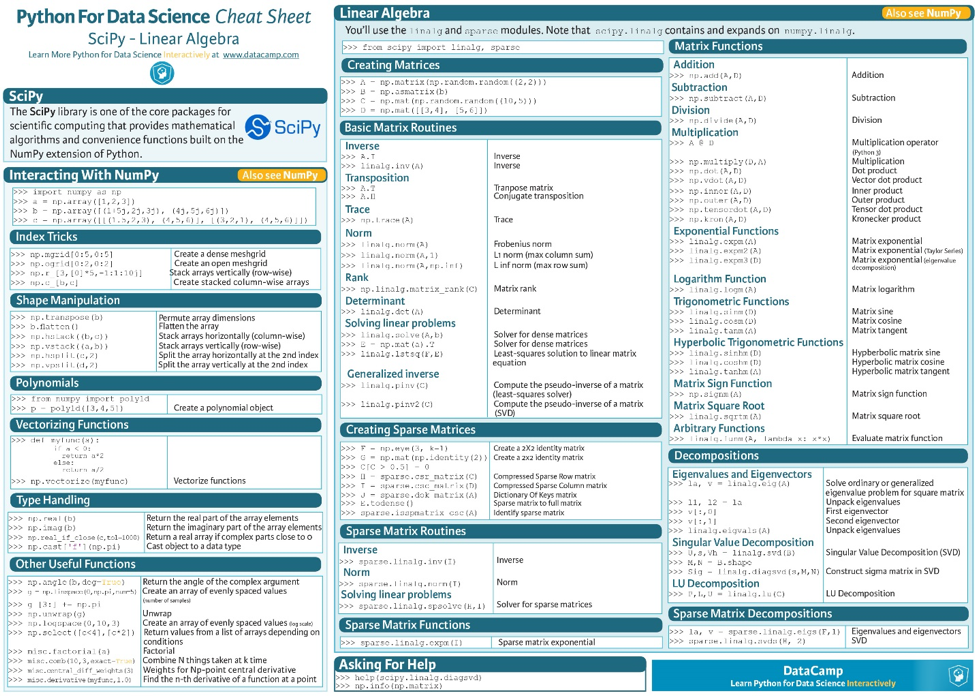
Testing whether your assumption is valid or not to make a fundamental decision about a product’s life cycle is an important task. As SciPy is written in various low-level languages such as C, C++, and Fortran, the speed gains are tremendous compared to a library written in a high-level language. Moreover, Scipy extends the functionality of NumPy by providing access to structures that can be used to store sparse data in a highly optimized fashion and perform computations on it.
The open-source nature of Scipy allows anyone to look at the source code, find bugs or optimize the numerical algorithms further. Hence, SciPy remains one of the most popular libraries for statistical tasks.
PyTorch
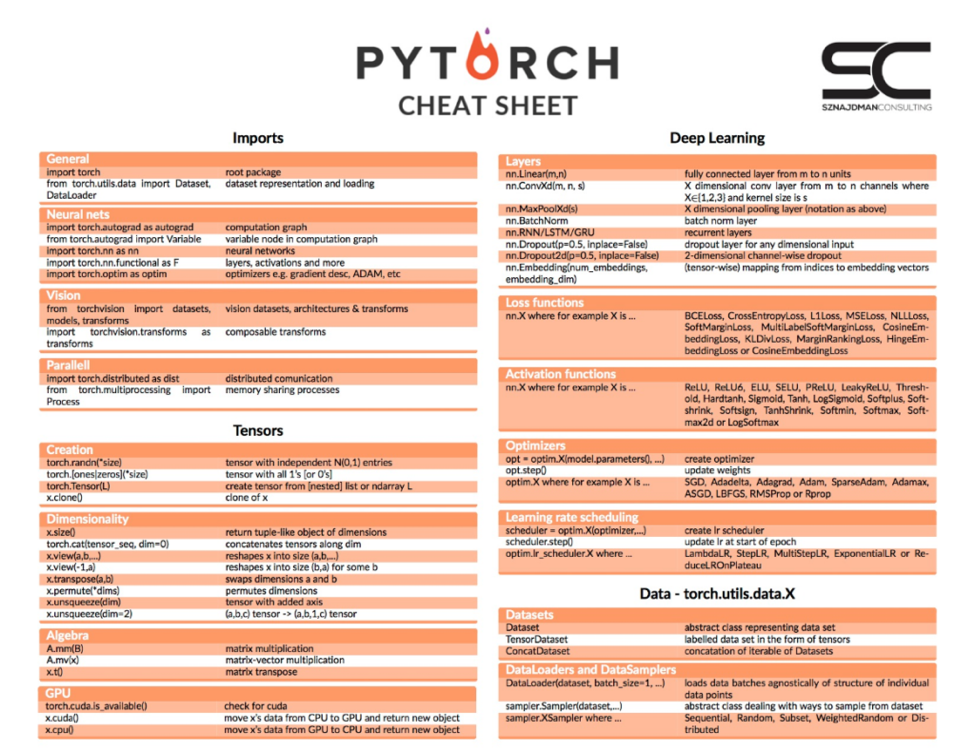
PyTorch is a dynamic graph-based machine learning library developed by Facebook to aid in their model development and deployment purposes. The variables, including layers, can be changed during the iterations, making the neural networks easier to debug and providing more flexibility.
Moreover, for people having access to GPUs, this library offers a remarkably simple flag to switch between GPU and CPU, which makes the life of programmers extremely easy by making the code portable.
Learn more about Python in boosting your data science career
