Machine learning is the way of the future. Discover the importance of data collection, finding the right skill sets, performance evaluation, and security measures to optimize your next machine learning project.
Billions of users use various social media daily and see a lot of new suggestions there. The content includes text, images, videos, and so on depending on the social platform. Do you know how that content is suggested?
We will learn about it in this blog.
Social media recommendation system:
It is an algorithm that suggests relevant products to users based on a variety of factors. Sometimes, when you search for a certain product on a website you notice that you start receiving several suggestions of similar products, there is a system behind this. It is generally used to target potential users more efficiently and improve the user experience by suggesting new items, saving users’ time, and narrowing down the set of choices.
Now that we know the concept, let’s dive deeper into a real-world application to better comprehend it.
YouTube’s recommendation system journey
YouTube has over 800 million videos, which is about 17,810 years of continuous video watching. It is hard for a user to repeatedly search for certain sorts of videos from millions of videos. This problem is solved by recommendation systems, which provide relevant videos based on what you are currently watching.
The system also works when you open YouTube’s home page and do not watch any videos. In this case, it shows the mixture of the subscribed, most up-to-date, promoted, and most recently watched videos.
Let’s discuss the journey of the recommendation system on YouTube.
In 2008, YouTube’s recommendation system ranked videos based on popularity. The issue with this approach was sometimes violent or racy videos get popular. To avoid this, YouTube built classifiers to identify this type of content and avoid recommending them. After a couple of years, YouTube started to incorporate video watch time in its recommendation system.
The reason for this was that users often watched different types of videos and there were different recommendations for them. Later, YouTube took surveys where users rated the watched videos and answered the questions upon giving low or high stars.
Soon, YouTube’s management realized that everyone did not fill out the survey. So, YouTube trained a machine learning model on completed surveys and predicted the survey responses. YouTube did not stop there; they started to consider the likes/dislikes and share information to make the recommender system better.
Nowadays, they are also using classifiers to identify authoritative and borderline (doesn’t quite violate community) content to make a better recommender system.
Before diving deep into the technical detail, let’s first discuss common types of recommendation systems.
Classification of recommendation system:
Recommendation system
These types of recommendation systems are widely used in industry to solve different problems. We will go through these briefly.
1. Content-based recommendation system
According to the user’s past behavior or explicit feedback, content-based filtering uses item features (such as keywords, categories, etc.) to suggest additional items that are similar to what they already enjoy.
Content based recommendation system
2. Collaborative recommendation system
Collaborative filtering gives information based on interactions and data acquired by the system from other users. It is divided into two types: memory-based, and model-based systems.
a) Memory-based system
This mechanism is further classified as user-based and item-based filtering. In the user-based approach, recommendations are made based on the user’s preferences that are similar to the preferences of other users. In the item-based approach, recommendations are made based on items similar to other items the active user likes.
Let’s see the below illustration to understand the difference:
User-based and item-based recommendation system
b) Model-based system
This mechanism provides recommendations by developing machine learning models from users’ ratings. A few commonly used machine learning models are clustering-based, matrix factorization-based, and deep learning models.
Model-based system
2. Demographic-based recommendation system
This system provides recommendations based on user demographic attributes, such as age, sex, and location. This system uses demographic information, such as a user’s age, gender, and location, to provide personalized recommendations. This type of system uses data about a user’s characteristics to suggest items that may be of particular interest to them.
For example, a recommendation system might use a user’s age and location to suggest events or activities in the user’s area that might be of interest to someone in their age group.
3. Knowledge-based recommendation system
This system offers recommendations based on queries made by the user rather than a user’s rating history. Shortly, it is based on explicit knowledge of the item variety, user preference and suggestion criteria. This strategy is suited for complex domains where products are not acquired frequently, such as houses and automobiles.
4. Community-based recommendation system
This system provides recommendations based on user-interacted items within a community that shares a common interest. A community-based recommendation system is a tool that uses the interactions and preferences of a group of people with a shared interest to provide personalized recommendations to individual users.
This type of system takes into account the collective experiences and opinions of the community in order to provide personalized recommendations.
5. Hybrid recommendation system
This system is a combination of two or more discussed recommendation systems such as content-based, collaborative-based, and so on. Sometimes a single recommendation system cannot solve an issue, thus we must combine two or more recommendation systems.
We now have a high-level understanding of the various recommendation systems. Recall the YouTube discussion, what do you think, which recommendation method suits YouTube the most.
It is a memory-based collaborative recommendation system. YouTube can use an item-based approach to suggest videos based on other similar videos using users’ ratings (clicked on and watched videos). To determine the most similar match, we can use matrix factorization. This is a class of collaborative recommendation systems to find the relationship between items’ and users’ entities. However, this approach has numerous limitations, such as
Not being suitable for complex relations in the users and items
Always recommend popular items
Cold start problem (cannot anticipate items and users that we have never encountered in training data)
Can only use limited information (only user IDs and item IDs)
To address the shortcomings of the matrix factorization method, deep neural networks are designed and used by YouTube. Deep learning is based on artificial neural networks, which enable computers to comprehend and make decisions in the same way that the human brain does.
Let’s watch the video below to gain a better understanding of deep learning.
YouTube uses the deep learning model for its video recommendation system. They provide users’ watch history and context to the deep neural network. The network then learns from the provided data and usesthe softmaxclassifier(used for multiclass classification) to differentiate among the videos. This model provides hundreds of videos from a pool of over 800 million videos. This procedure was named “candidate generation” by YouTube.
But we just need to reveal a few of them to a certain user. So, YouTube created a ranking system in which they provide a rank (score) to each of a few hundred videos. They used the same deep learning model that assigns a score to each video for this. The score may be based on the video that the user watched from any channel and/or the most recently watched video topic.
We studied different recommendation systems that can be used to address various real-world challenges. These systems help to connect people with resources and information that may not have been easily discoverable otherwise, making them a useful tool for solving these challenges.
We discussed the journey of YouTube’s recommendation system, a collaborative system used by YouTube, and examined how YouTube performed well using deep learning in their systems.
In this blog, we will have a look at the list of top 10 Machine Learning Demos offered by Data Science Dojo that will provide ease to use ML (Machine Learning) techniques free.
With more people entering Data Science, Machine Learning and Artificial Intelligence are among the top emerging areas of work in the 21st century. Many people are opting for this area for them.
The other perspective to view the situation is to utilize these innovative technologies in business. For this reason, recently Data Science Dojo has revamped its platform called Machine Learning Demos. The primary benefit of using these demos is that a few of them are programmed on Azure APIs while others are trained on different ML models, and we can easily use them free of cost.
Machine learning demos from DSD
DSD offers a lot of training and boot camps Data Science Bootcamps to get started with the field, so these demos are also an add-on to our teaching.
So, if you are interested in exploring the practical applications of this modern tech, this set of free ML demos can help you a lot in many ways. The top ones are listed below go and check them out:
Top 10 machine learning demos – Data Science Dojo
1. Cleanse stop words:
This demo uses the Azure services for the backend while according to the user point of view, it has quite easy to use Interface and we can use this demo to make text data cleaner for ML models. Go to Cleanse Stop words demo input your text data and get the cleaned text in just one click.
Cleanse stop words
2. Text entity extractor:
Entity extraction helps to sort the unstructured data and find valuable information from the given text. This demo is based on Azure API. It’s simple UI (User Interface) provides an effortless way to use azure services for entity extraction. Go to Text Entity Extractor demo and just input your text to categorize it based on semantic type.
Text entity extractor
3. Opinion mining:
Sentiment analysis, also referred to as opinion mining, is one of the key techniques in Natural Language Processing (NLP). The business view of opinion mining is highly appreciable as it leads to extracting sentiments from customers’ feedback. This demo is based on Azure Text API while its UI efficiently separates the praises and complaints from the given text. Try Opinion Mining Demo!
Opinion mining
4. American sign language detection:
Systems for recognizing sign language are being developed to make it easier for signers and non-signers to communicate. This demo is built on Python famous package called Mediapipe with some other packages like Tensorflow, Cvzone and Numpy. Go to Sign Language demo, and when the user inputs an alphabet using the right hand in the camera it detects the alphabet.
American sign language detection
5. Wikipedia article scrape:
Besides the fact that Wikipedia is free, it is an also open multilingual content online encyclopedia. This demo is based on famous python packages Wikipedia and Worcloud. This demo really helps in research to find the articles. Go to Wikipedia Article Scrape, and give the article name and language code and scrape the article to extract content, linked articles etc.
Wikipedia article scrape
6. Credit card streamer:
We have a few Data streaming demos; Credit Card Streamer is one from that category. This demo is based on Azure SDK in python, give the endpoint string of Event Hub, and set the stream, it will connect this app to Event Hub and your swipes send to Azure Event Hub. Go to Credit Card Streamer and try.
Credit card streamer
7. Paraphrasing:
The basic objective of paraphrasing is to translate the original message into your own words to demonstrate that you have understood the paragraph sufficiently to restate it.
Paraphrasing
This demo is built on Python, and it uses a transformer library with some other famous Python packages like PyTorch, timm, sentence piece, and sentence-splitter. Go to the Paraphrasing demo, it uses natural language processing to create a paraphrasing of your input text.
8. Titanic survival predictor:
This demo is unique from our predictive demos category and is based on Azure API. It will predict that the person would survive the Titanic Disaster based on the given required inputs. The backend is built on Python while the UI gives the message based on chances of survival. Go to the Titanic Survival Predictor demo and try it once (just for curiosity 😊)
Titanic survival predictor
9. Question generator:
This demo is built on a Python library transformer. Transformers package contains over 30 pre-trained models and 100 languages, along with eight major architectures for natural language understanding (NLU) and natural language generation (NLG).
Question generator
In educational purposes, we can use this demo. It saves teachers time and effort to make a quiz related to the given content. Go to Question Generator demo, just give the context of the question and the correct answer then click submit, this demo automatically generates the Question based on given inputs.
10. Bike sharing demand predictor:
The last demo we are going to discuss in this blog is also from the list of predictive demos category. This demo uses Azure API for predicting the demand of bike sharing while the UI allows you to change the inputs dynamically from sliders. Must go and check Bike Sharing Demand Predictor.
Bike sharing demand predictor
Stay updated for interesting ML demos
Recently in 2022, we have revamped our demo site completely. And now we have 29+ demos on our site. We have categorized them into categories for the ease of users so that they can pick the demo based on tasks, these are only a few top ML demos, other than these, we do have many informative and interesting demos on this site.
Once you are familiar with data-driven tasks it is most important to utilize them for improving our businesses, we have received a lot of positive feedback from the customers this year that motivates us to improve and add more advanced demos to our site. I assure you; it is worth it to use, go, and explore:
Statistical distributions help us understand a problem better by assigning a range of possible values to the variables, making them very useful in data science and machine learning. Here are 6 types of distributions with intuitive examples that often occur in real-life data.
In statistics, a distribution is simply a way to understand how a set of data points are spread over some given range of values.
For example, distribution takes place when the merchant and the producer agree to sell the product during a specific time frame. This form of distribution is exhibited by the agreement reached between Apple and AT&T to distribute their products in the United States.
Types of probability distribution – Data Science Dojo
Types of statistical distributions
There are several statistical distributions, each representing different types of data and serving different purposes. Here we will cover several commonly used distributions.
A normal distribution also known as “Gaussian Distribution” shows the probability density for a population of continuous data (for example height in cm for all NBA players). Also, it indicates the likelihood that any NBA player will have a particular height. Let’s say fewer players are much taller or shorter than usual; most are close to average height.
The spread of the values in our population is measured using a metric called standard deviation. The Empirical Rule tells us that:
68.3% of the values will fall between1 standard deviation above and below the mean
95.5% of the values will fall between2 standard deviations above and below the mean
99.7% of the values will fall between3 standard deviations above and below the mean
Let’s assume that we know that the mean height of all players in the NBA is 200cm and the standard deviation is 7cm. If Le Bron James is 206 cm tall, what proportion of NBA players is he taller than? We can figure this out! LeBron is 6cm taller than the mean (206cm – 200cm). Since the standard deviation is 7cm, he is 0.86 standard deviations (6cm / 7cm) above the mean.
Our value of 0.86 standard deviations is called the z-score. This shows that James is taller than 80.5% of players in the NBA!
This can be converted to a percentile using the probability density function (or a look-up table) giving us our answer. A probability density function (PDF) defines the random variable’s probability of coming within a distinct range of values.
2. t-distribution
A t-distribution is symmetrical around the mean, like a normal distribution, and its breadth is determined by the variance of the data. A t-distribution is made for circumstances where the sample size is limited, but a normal distribution works with a population. With a smaller sample size, the t-distribution takes on a broader range to account for the increased level of uncertainty.
The number of degrees of freedom, which is determined by dividing the sample size by one, determines the curve of a t-distribution. The t-distribution tends to resemble a normal distribution as sample size and degrees of freedom increase because a bigger sample size increases our confidence in estimating the underlying population statistics.
For example, suppose we deal with the total number of apples sold by a shopkeeper in a month. In that case, we will use the normal distribution. Whereas, if we are dealing with the total amount of apples sold in a day, i.e., a smaller sample, we can use the t distribution.
3. Binomial distribution
A Binomial Distribution can look a lot like a normal distribution’s shape. The main difference is that instead of plotting continuous data, it plots a distribution of two possible discrete outcomes, for example, the results from flipping a coin. Imagine flipping a coin 10 times, and from those 10 flips, noting down how many were “Heads”. It could be any number between 1 and 10. Now imagine repeating that task 1,000 times.
If the coin, we are using is indeed fair (not biased to heads or tails) then the distribution of outcomes should start to look at the plot above. In the vast majority of cases, we get 4, 5, or 6 “heads” from each set of 10 flips, and the likelihood of getting more extreme results is much rarer!
4. Bernoulli distribution
The Bernoulli Distribution is a special case of Binomial Distribution. It considers only two possible outcomes, success, and failure, true or false. It’s a really simple distribution, but worth knowing! In the example below we’re looking at the probability of rolling a 6 with a standard die.
If we roll a die many, many times, we should end up with a probability of rolling a 6, 1 out of every 6 times (or 16.7%) and thus a probability of not rolling a 6, in other words rolling a 1,2,3,4 or 5, 5 times out of 6 (or 83.3%) of the time!
5. Discrete uniform distribution: All outcomes are equally likely
Uniform distribution is represented by the function U(a, b), where a and b represent the starting and ending values, respectively. Like a discrete uniform distribution, there is a continuous uniform distribution for continuous variables.
In statistics, uniform distribution refers to a statistical distribution in which all outcomes are equally likely. Consider rolling a six-sided die. You have an equal probability of obtaining all six numbers on your next roll, i.e., obtaining precisely one of 1, 2, 3, 4, 5, or 6, equaling a probability of 1/6, hence an example of a discrete uniform distribution.
As a result, the uniform distribution graph contains bars of equal height representing each outcome. In our example, the height is a probability of 1/6 (0.166667).
The drawbacks of this distribution are that it often provides us with no relevant information. Using our example of a rolling die, we get the expected value of 3.5, which gives us no accurate intuition since there is no such thing as half a number on a dice. Since all values are equally likely, it gives us no real predictive power.
It is a distribution in which all events are equally likely to occur. Below, we’re looking at the results from rolling a die many, many times. We’re looking at which number we got on each roll and tallying these up. If we roll the die enough times (and the die is fair) we should end up with a completely uniform probability where the chance of getting any outcome is exactly the same
6. Poisson distribution
A Poisson Distribution is a discrete distribution similar to the Binomial Distribution (in that we’re plotting the probability of whole numbered outcomes) Unlike the other distributions we have seen however, this one is not symmetrical – it is instead bounded between 0 and infinity.
For example, a cricket chirps two times in 7 seconds on average. We can use the Poisson distribution to determine the likelihood of it chirping five times in 15 seconds. A Poisson process is represented with the notation Po(λ), where λ represents the expected number of events that can take place in a period.
The expected value and variance of a Poisson process is λ. X represents the discrete random variable. A Poisson Distribution can be modeled using the following formula.
The Poisson distribution describes the number of events or outcomes that occur during some fixed interval. Most commonly this is a time interval like in our example below where we are plotting the distribution of sales per hour in a shop.
Conclusion:
Data is an essential component of the data exploration and model development process. We can adjust our Machine Learning models to best match the problem if we can identify the pattern in the data distribution, which reduces the time to get to an accurate outcome.
Indeed, specific Machine Learning models are built to perform best when certain distribution assumptions are met. Knowing which distributions, we’re dealing with may thus assist us in determining which models to apply.
Data Science Dojo is offering Locust for FREE on Azure Marketplace packaged with pre-configured Python interpreter and Locust web server for load testing.
Why and when do we perform testing?
Testing is an evaluation and confirmation that a software application or product performs as intended. The purpose of testing is to determine whether the application satisfies business requirements and whether the product is market ready. Applications can be subjected to automated testing to see if they meet the demands. Scripted sequences are used in this method of software testing, and testing tools carry them out.
The merits of automated testing are:
Bugs can be avoided
Development costs can be reduced
Performance can be improved till requirement
Application quality can be enhanced
Development time can be saved
Testing is usually the last phase of the SDLC (Software Development Life Cycle)
What is load testing and why choose Locust?
Performance testing is one of several types of software testing. Load testing is an example of performance testing to evaluate performance under real-life load conditions. It involves the following stages:
Define crucial metrics and scenarios
Plan the test load model
Write test scenarios
Execute test by swarming load
Analyze the test results
It is a modern load testing framework. The major reason senior testers prefer it over other tools like JMeter is because it uses an event-based approach for testing rather than thread based. This results in less consumption of resources and thus saves costs.
Pro Tip: Join our 6-months instructor-led Data Science Bootcamp to master data science skills
Challenges faced by QA teams
Before such feasible testing tools, the job of testing teams was not much easier as it is now. Swarming a large number of users to direct as a load on a website was expensive and time-consuming.
Apart from this, monitoring the testing process in real time was not prevalent either. Complete analytics were usually drawn after the whole testing process concludes, which again required patience.
The testers needed a platform through which they can evaluate quality of product and its compliance with the specified requirements under different loads without the prolonged wait and high expense.
Working of Locust
Locust is an open-source web-based load testing tool. It is based on python and is used to evaluate the functionality and behavior of the web application. For the quality assurance process in any business, load testing is an extremely critical element to assure that the website remains up during traffic influx as it will eventually contribute to the success of the company. Through Locust, web testers can determine the potential of the website to withstand the number of concurrent users. With the power of python, you can develop a set of test scenarios and functions that imitate many users and can observe performance charts on web UI.
Figure 1: A sample locustfile.py
The self.client.get function points to the pages of a website that you want to target. You can find this code file and further breakdownhere. The host domain, users and the spawn rate for the load testing are supplied at the web interface. After running the locust command, the web server is started at 8089.
Figure 2: Locust web interface
It also allows you to capture different metrics during the testing process in real-time.
Figure 3: Graphs with metrics visualizations
Key characteristics of Locust
An interactive user-friendly web UI is started after executing the file through which you can perform load testing
Locust is an open-source load-testing tool. It is extremely useful for web app testers, QA teams and software testing managers
You can capture various metrics like response time, visualized in charts in real-time as the testing occurs
Achieve increased throughput and high availability by writing test codes in pre-configured python interpreter
You can easily scale up the number of users for extensive production level load testing of web applications
What Data Science Dojo provides
Locust instance packaged by Data Science Dojo comes with a pre-configured python interpreter to write test files, and a Locust web UI server to generate the desired amount of load at specific rates without the burden of installation.
Features included in this offer:
VM configured with Locust application which can start a web server with rich UX/UI
Provides several interactive metrics graphs to visualize the testing results
Provides real-time monitoring support
Ability to download requests statistics, failures, exceptions, and test reports
Feature to swarm multiple users at the desired spawn rate
Support for python language to write complex workflows
Utilizes event-based approach to use fewer resources
Through Locust, load testing has been easier than ever. It has saved time and cost for businesses as QA engineers and web testers can perform testing now with few clicks and few lines of easy code.
Conclusion
Locust can be used to test any web application. By swarming many clients spawning at a specific rate, the functionality of a website can be assured that it can manage concurrent users. To achieve extensive load testing, you can use multi-cores on Azure Virtual Machine. Also, the Its web interface calculates metrics for every test run and visualizes them as well. This might slow down the server if you have hundreds upon hundreds of active test units requesting multiple pages. The CPU and RAM usage may also be affected but through Azure Virtual Machine this problem is taken care of.
At Data Science Dojo, we deliver data science education, consulting, and technical services to increase the power of data. We are adding a free Locust application dedicated specifically for testing operations on Azure Marketplace. Now hurry up install this offer by Data Science Dojo, your ideal companion in your journey to learn data science!
Click on the button below to head over to the Azure Marketplace and deploy Locust for FREE by clicking on “Try now”
Note: You will have to sign up to Azure, for free, if you do not have an existing account.
With the surge in demand and interest in AI and machine learning, many contemporary trends are emerging in this space. As a tech professional, this blog will excite you to see what’s next in the realm of Artificial Intelligence and Machine Learning trends.
Emerging AI and machine learning trends
Data security and regulations
In today’s economy, data is the main commodity. To rephrase, intellectual capital is the most precious asset that businesses must safeguard. The quantity of data they manage, as well as the hazards connected with it, is only going to expand after the emergence of AI and ML. Large volumes of private information are backed up and archived by many companies nowadays, which poses a growing privacy danger. Don Evans, CEO of Crewe Foundation
The future currency is data. In other words, it’s the most priceless resource that businesses must safeguard. The amount of data they handle, and the hazards attached to it will only grow when AI and ML are brought into the mix. Today’s businesses, for instance, back up and store enormous volumes of sensitive customer data, which is expected to increase privacy risks by 2023.
Overlap of AI and IoT
There is a blurring of boundaries between AI and the Internet of Things. While each technology has merits of its own, only when they are combined can they offer novel possibilities? Smart voice assistants like Alexa and Siri only exist because AI and the Internet of Things have come together. Why, therefore, do these two technologies complement one another so well?
The Internet of Things (IoT) is the digital nervous system, while Artificial Intelligence (AI) is the decision-making brain. AI’s speed at analyzing large amounts of data for patterns and trends improves the intelligence of IoT devices. As of now, just 10% of commercial IoT initiatives make use of AI, but that number is expected to climb to 80% by2023. Josh Thill, Founder of Thrive Engine
AI ethics: Understanding biased AI and associated ethical dilemmas
Why then do these two technologies complement one other so well? IoT and AI can be compared to the brain and nervous system of the digital world, respectively. IoT systems have become more sophisticated thanks to AI’s capacity to quickly extract insights from data. Software developers and embeddedengineers now have another reason to include AI/ML skills in their resumes because of this development in AI and machine learning.
Augmented Intelligence
The growth of augmented intelligence should be a relieving trend for individuals who may still be concerned about AI stealing their jobs. It combines the greatest traits of both people and technology, offering businesses the ability to raise the productivity and effectiveness of their staff.
40% of infrastructure and operations teams in big businesses will employ AI-enhanced automation by 2023, increasing efficiency. Naturally, for best results, their staff should be knowledgeable in data science and analytics or have access to training in the newest AI and ML technologies.
Moving on from the concept of Artificial Intelligence to Augmented Intelligence, where decisions models are blended artificial and human intelligence, where AI finds, summarizes, and collates information fromacross the information landscape – for example, company’s internal data sources. This information is presented to the human operator, who can make a human decision based on that information.This trend is supported by recent breakthroughs in Natural Language Processing (NLP) and Natural Language Understanding (NLU). Kuba Misiorny, CTO of Untrite Ltd
Transparency
Despite being increasingly commonplace, there are trust problems with AI. Businesses will want to utilize AI systems more frequently, and they will want to do so with greater assurance. Nobody wants to put their trust in a system they don’t fully comprehend.
As a result, in 2023 there will be a stronger push for the deployment of AI in a visible and specified manner. Businesses will work to grasp how AI models and algorithms function, but AI/ML software providers will need to make complex ML solutions easier for consumers to understand.
The importance of experts who work in the trenches of programming and algorithm development will increase as transparency becomes a hot topic in the AI world.
Composite AI
Composite AI is a new approach that generates deeper insights from any content and data by fusing different AI technologies. Knowledge graphs are much more symbolic, explicitly modeling domain knowledge and, when combined with the statistical approach of ML, create a compelling proposition. Composite AI expands the quality and scope of AI applications and, as a result, is more accurate, faster, transparent, and understandable, and delivers better results to the user. Dorian Selz, CEO of Squirro
It’s a major advance in the evolution of AI and marrying content with context and intent allows organizations to get enormous value from the ever-increasing volume of enterprise data. Composite AI will be a major trend for 2023 and beyond.
Continuous focus on healthcare
There has been concern that AI will eventually replace humans in the workforce ever since the concept was first proposed in the 1950s. Throughout 2018, a deep learning algorithm was constructed that demonstrated accurate diagnosis utilizing a dataset consisting of more than 50,000 normal chest pictures and 7,000 scans that revealed active Tuberculosis. Since then, I believe that the healthcare business has mostly made use of Machine Learning (ML) and Deep Learning applications of artificial intelligence. Marie Ysais, Founder of Ysais Digital Marketing
Pathology-assisted diagnosis, intelligent imaging, medical robotics, and the analysis of patient information are just a few of the many applications of artificial intelligence in the healthcareindustry. Leading stakeholders in the healthcare industry have been presented with advancements and machine-learning models from some of the world’s largest technology companies. Next year, 2023, will be an important year to observe developments in the field of artificial intelligence.
Algorithmic decision-making
Advanced algorithms are taking on the skills of human doctors, and while AI may increase productivity in the medical world, nothing can take the place of actual doctors. Even in robotic surgery, the whole procedure is physician-guided. AI is a good supplement to physician-led health care. The future of medicine will be high-tech with a human touch.
No-code tools
The low-code/No Code ML revolution accelerates creating a new breed of Citizen AI. These tools fuel mainstream ML adoption in businesses that were previously left out of the first ML wave (mostly taken advantage of by BigTech and other large institutions with even larger resources). Maya Mikhailov Founder of Savvi AI
Low-code intelligent automation platforms allow business users to build sophisticated solutions that automate tasks, orchestrate workflows, and automate decisions. They offer easy-to-use, intuitive drag-and-drop interfaces, all without the need to write a line of code. As a result, low-code intelligent automation platforms are popular with tech-savvy business users, who no longer need to rely on professional programmers to design their business solutions.
Cognitive analytics
Cognitive analytics is another emerging trend that will continue to grow in popularity over the next few years. The ability for computers to analyze data in a way that humans can understand is something that has been around for a while now but is only recently becoming available in applications such as Google Analytics or Siri—and it’ll only get better from here!
Virtual assistants
Virtual assistants are another area where NLP is being used to enable more natural human-computer interaction. Virtual assistants like Amazon Alexa and Google Assistant are becoming increasingly common in homes and businesses. In 2023, we can expect to see them become even more widespreadas they evolve and improve. Idrees Shafiq-Marketing Research Analyst at Astrill
Virtual assistants are becoming increasingly popular, thanks to their convenience and ability to provide personalized assistance. In 2023, we can expect to see even more people using virtual assistants, as they become more sophisticated and can handle a wider range of tasks. Additionally, we can expect to see businesses increasingly using virtual assistants for customer service, sales, and marketing tasks.
Information security (InfoSec)
The methods and devices used by companies to safeguard information fall under the category of information security. It comprises settings for policies that are essentially designed to stop the act of stopping unlawful access to, use of, disclosure of, disruption of, modification of, an inspection of, recording of, or data destruction.
With AI models that cover a broad range of sectors, from network and security architecture to testing and auditing, AI prediction claims that it is a developing and expandingfield. To safeguard sensitive data from potential cyberattacks, information security procedures are constructed on the three fundamental goals of confidentiality, integrity, and availability, or the CIA. Daniel Foley, Founder of Daniel Foley SEO
Wearable devices
The continued growth of the wearable market. Wearable devices, such as fitness trackers and smartwatches, are becoming more popular as they become more affordable and functional. These devices collect data that can be used by AI applications to provide insights into user behavior. Oberon, Founder, and CEO of Very Informed
Process discovery
It can be characterized as a combination of tools and methods with heavy reliance on artificial intelligence (AI) and machine learning to assess the performance of persons participating in the business process. In comparison to prior versions of process mining, these goes further in figuring outwhat occurs when individuals interact in different ways with various objects to produce business process events.
The methodologies and AI models vary widely, from clicks of the mouse for specific reasons to opening files, papers, web pages, and so forth. All of this necessitates various information transformation techniques. The automated procedure using AI models is intended to increase the effectiveness of commercial procedures. Salim Benadel, Director at Storm Internet
Robotic Process Automation, or RPA.
An emerging tech trend that will start becoming more popular is Robotic Process Automation or RPA. It is like AI and machine learning, and it is used for specific types of job automation. Right now, it is primarily used for things like data handling, dealing with transactions, processing/interpreting job applications, and automated email responses. It makes many businesses processes much faster and more efficient, and as time goes on, increased processes will be taken over by RPA. Maria Britton, CEO of Trade Show Labs
Robotic process automation is an application of artificial intelligence that configures a robot (software application) to interpret, communicate and analyze data. This form of artificial intelligence helps to automate partially or fully manual operations that are repetitive and rule based. Percy Grunwald, Co-Founder of Hosting Data
Generative AI
Most individuals say AI is good for automating normal, repetitive work. AI technologies and applications are being developed to replicate creativity, one of the most distinctive human skills. Generative AI algorithms leverage existing data (video, photos, sounds, or computer code) to create new, non-digital material.
Deepfake films and the Metaphysic act on America’s Got Talent have popularized the technology. In 2023, organizations will increasingly employ it to manufacture fake data. Synthetic audio and video data can eliminate the need to record film and speech on video. Simply write what you want the audience to see and hear, and the AI creates it. Leonidas Sfyris
With the rise of personalization in video games, new content has become increasingly important. Companies are not able to hire enough artists to constantly create new themes for all the different characters so the ability to put in a concept like a cowboy and then the art assets created for all their characters becomes a powerful tool.
Observability in practice
By delving deeply into contemporary networked systems, Applied Observability facilitates the discovery and resolution of issues more quickly and automatically. Applied observability is a method for keeping tabs on the health of a sophisticated structure by collecting and analyzing data in real time to identify and fix problems as soon as they arise.
Utilize observability for application monitoring and debugging. Telemetry data including logs, metrics, traces, and dependencies are collected by Observability. The data is then correlated in actuality to provide responders with full context for the incidents they’re called to. Automation, machine learning, and artificial intelligence (AIOps) might be used to eliminate the need for human interaction in problem-solving. Jason Wise, Chief Editor at Earthweb
Natural Language Processing
As more and more business processes are conducted through digital channels, including social media, e-commerce, customer service, and chatbots, NLP will become increasingly important for understanding user intent and producing the appropriate response.
Read more about NLP tasks and techniques in this blog:
In 2023, we can expect to see increased use of Natural Language Processing (NLP) for communication and data analysis. NLP has already seen widespread adoption in customer service chatbots, but it may also be utilized for data analysis, such as extracting information from unstructured texts oranalyzing sentiment in large sets of customer reviews. Additionally, deep learning algorithms have already shown great promise in areas such as image recognition and autonomous vehicles.
In the coming years, we can expect to see these algorithms applied to various industries such as healthcare formedical imaging analysis and finance for stock market prediction. Lastly, the integration of AI tools into various industries will continue to bring about both exciting opportunities and ethical considerations. Nicole Pav, AI Expert.
Do you know any other AI and Machine Learning trends
Share with us in comments if you know about any other trending or upcoming AI and machine learning.
In this blog, we have gathered the top 10 machine learning books. Learning this subject is a challenge for beginners. Take your learning experience one step ahead with these top-rated ML books on Amazon.
Top 10 Machine learning books – Data Science dojo
1. Machine Learning: 4 Books in 1
Machine learning – 4 books in 1 by Samuel Hack
Machine Learning: 4 Books in 1 is a complete guide for beginners to master the basics of Python programming and understand how to
build artificial intelligence through data science. This book includes four books: Introduction to Machine Learning, Python Programming for
Beginners, Data Science for Beginners, and Artificial Intelligence for Beginners. It covers everything you need to know about machine learning, including supervised and unsupervised learning, regression and classification, feature engineering, model selection, and more. Muhammad Junaid – Marketing manager, BTIP
With clear explanations and practical examples, this book will help you quickly learn the essentials of machine learning and start building your own AI applications.
2. Mathematics for Machine Learning
Mathematics for machine learning
Mathematics for Machine Learning is a tool that helps you understand the mathematical foundations of machine learning, so that you
can build better models and algorithms. It covers topics such as linear algebra, probability, optimization, and statistics. With this book, you
will be able to learn the mathematics needed to develop machine learning models and algorithms. Daniel – Founder, Gadget FAQs
This book is excellent for brushing up your mathematics knowledge required for ML. It is very concise while still providing enough details to help readers determine important parts. This is the go-to if you need to review some concepts or brush up on my knowledge in general.
This book is not recommended if you have absolutely no prior math experience though as it can be hard to digest and sometimes, they would skip parts here and there in proofs and examples. Especially for the probability section, the concepts will be very hard to grasp without prior knowledge
3. Linear Algebra and Optimization for Machine Learning
Linear algebra for Machine learning
This textbook provides a comprehensive introduction to linear algebra and optimization, two fundamental topics in machine learning. It
covers both theory and applications and is suitable for students with little or no background in mathematics. Allan McNabb, VP – Image Building Media
The book begins with a review of basic linear algebra, before moving on to more advanced topics such as matrix decompositions, eigenvalues and eigenvectors, singular value decomposition, and least squares methods. Optimization techniques are then introduced, including gradient descent, Newton’s Method, conjugate gradient methods, and interior point methods.
4. The Hundred-Page Machine Learning Book
Hundred page machine learning book
If we have to teach machine learning to someone in juts few weeks, it is a lot better not to bother starting from scratch, instead hand over this book to the learners, because no doubt Andriy Burkov does a better job than we could do to quickly teach this vast subject in a limited time.
The book has a litany of rave reviews from some of the biggest names in tech, with scores more five-star reviews to boot, and you can see why. Burkov keeps his lessons concise and as easy to understand as possible given the subject matter, but still drills down into the details where necessary. Overall, the book excels at linking together complicated and sometimes seemingly unrelated concepts into a coherent whole. Peter, CEO and founder – Lantech
The book is very well organized, giving the reader an introduction and discussion on the mathematical notation used, a well written chapter that discusses several quite common algorithms, talks about best practices (like feature engineering, breaking up the data into multiple sets, and tuning the model’s hyperparameters), digs deeper into supervised learning, discusses unsupervised learning, and gives you a taste of a variety of other related topics.
This is a well-rounded book, far more so than most books I’ve read on machine learning or artificial intelligence. After reading through this, you will feel like you can competently discuss the subject, read one of the simpler machine learning research papers, and not be totally lost on the mathematics involved. The language used is concise and reads very well, showing very tight editing
5. Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow by Aurélien Géron
Hands-on machine learning book
It’s good for new programmers without over-simplifying. I’d recommend it for really getting into practice exercises. It’s a book you need to take your time with, but you’ll learn a lot from it. One thing observed by the learners of this book as a con is that the quality of the print varies, but the quality of its content makes it more than worth it. Chris Martinez – Founder of Idiomatic
This book covers many topics of ML and explains them with good examples. However, it should be a little bit tough for a beginner. Similarly, it could not be the best book for an advanced reader because it gives pointers for advanced topics but does not go in-depth like mathematical explanation. In summary, it is an excellent book if you are looking for real-life examples with python code and you have a good basic idea in ML.
6. Machine Learning for Absolute Beginners by Oliver Theobald
Machine learning for beginners by Oliver Theobald
Machine Learning is easy only when you have the right teacher and an appropriate reference book. Most of us fail to understand the importance of simple concepts that help us understand complex ones. Therefore, I recommend using Oliver Theobald’s *Machine Learning for Absolute Beginners *as the base reference book. Layla Acharya – Owner at Edwize
This book uses simple language to explain to the reader and teaches Machine learning from the scratch. Although non-technical people will find this book more relatable, people wanting to make a career in the machine learning field can benefit equally. It also has good references that can help a person who wants to learn like an expert.
7. Deep Learning for Coders with Fastai and PyTorch: AI Applications Without a PhD by Jeremy Howard and Sylvain Gugger
Deep learning for coders with fastai and PyTorch
This book is very well-rated, and it’s helped me a lot in understanding the basics of deep learning.
The main reason readers suggest this book is because it’s very accessible and easy to follow. As the authors themselves say, you don’t need a PhD to understand and use the concepts in the book, and it follows a top-down approach (starting with the applications and working backwards to the theory). So, you’ll first have fun building cool applications and then gradually learn the underlying theory as you go. Ed Shway – Owner & Writer at ByteXD.com
Fast AI have kept updating their courses and library, so you might want to check out their website (https://www.fast.ai/) for the latest and greatest Just this July they released a latest version of the course that the book is associated with (https://course.fast.ai/).
Furthermore, the book also comes in a free online version https://github.com/fastai/fastbook. Since the *Fast AI team put all this effort and made every resource available for free, you can be sure they’re in it for the love of the game and to help the community*, rather than to make a quick buck. So, this book is definitely worth your time.
The first practical applications it teaches you is in computer vision – you’ll build an image classifier, which you can use to tell apart different
kinds of images. For example, you can use it to distinguish between different kinds of animals. It will be very easy to follow along and build
this classifier yourself.
8. Bayesian Reasoning and Machine Learning by David Barber
Bayesian reasoning and machine learning book
It’s a real must-have for beginners interested in deepening their knowledge of machine learning in an engaging way. The book covers topics such as dynamic and probabilistic models, approximate interference, graphical models, Naive Bayes algorithms, and more. What makes it worth checking out is the fact that the book is full of examples and exercises, which makes it a hands-on guide full of useful practice rather than dry theoretical frameworks. Marcin Gwizdala – Chief Technical Officer – Tidio
For relative beginners, Bayesian techniques began in the 1700s to model how a degree of belief should be modified to account for new evidence. The techniques and formulas were largely discounted and ignored until the modern era of computing, pattern recognition and AI, now machine learning.
The formula answers how the probabilities of two events are related when represented inversely, and more broadly, gives a precise mathematical model for the inference process itself (under uncertainty), where deductive reasoning and logic becomes a subset (under certainty, or when values can resolve to 0/1 or true/false, yes/no etc. In “odds” terms (useful in many fields including optimal expected utility functions in decision theory), posterior odds = prior odds * the Bayes Factor.
9. Deep Learning with PyTorch: Build, train, and tune neural networks using Python tools by Eli Stevens, Luca Antiga, Thomas Viehmann
Deep learning with Pytorch
This book provides a good and fairly complete description of the basic principles and abstractions of one of the most popular frameworks for
Machine Learning – PyTorch.
It’s great that this book is written by the creator and key contributors of PyTorch, unlike many books that claim to be a definitive treatise, it is not overloaded with non-essential details, the emphasis is on making the book practical. The book gives a reader a deep understanding of the framework and methods for building and training models on it (with advanced best practices) describing what is under the hood. Vitalii Kudelia, TUTU – Machine Learning Scientist
There is an example of solving a real-world problem in this book, it analyzes the problem of searching for malignant tumors on a computer
diagram with an analysis of approaches, possible errors, options for improvements, and provides code examples.
It also includes options for translating the model into production, using the models in other programming languages, and on mobile devices.
As a result, the book is highly useful for understanding and mastering the framework. Mastering PyTorch helps not only in computer vision, but also in other areas of deep learning, such as, for example, natural language processing.
10. Introduction to Machine Learning by Ethem Alpaydin
Intro to machine learning book by Ethem Alpaydin
This comprehensive text covers everything from the basics of linear algebra to more advanced topics like support vector machines. In addition to being an excellent resource for students, Alpaydin’s book is also very accessible for practitioners who want to learn more about this exciting field. Rajesh Namase – Co-Founder and Tech Blogger
For learners, this is the best book for machine learning for a number of reasons. First, the book provides a clear and concise introduction to the basics of machine learning. Second, it covers a wide range of topics in machine learning, including supervised and unsupervised learning, feature selection, and model selection.
Third, the book is well-written and easy to understand. Finally, the book includes exercises and solutions at the end of each
chapter, which is extremely helpful for readers who want to learn more about machine learning.
Share more machine learning books with us
If you have read any other interesting machine learning books, share with us in the comments below and let us help the learners to begin with computer vision.
What can be a better way to spend your days listening to interesting bits about trending AI and Machine learning topics? Here’s a list of the 10 best AI and ML podcasts.
Top 10 trending Data and AI Podcasts 2024
1. Future of Data and AI Podcast
Hosted by Data Science Dojo
Throughout history, we’ve chased the extraordinary. Today, the spotlight is on AI—a game-changer, redefining human potential, augmenting our capabilities and fueling creativity. Curious about AI and how it is reshaping the world? You’re right where you need to be. The Future of Data and AI podcast hosted by the CEO and Chief Data Scientist at Data Science Dojo, dives deep into the trends and developments in AI and technology, weaving together the past, present and future. It explores the profound impact of AI on the society, through the lens of the most brilliant and inspiring minds in the industry.
2. The TWIML AI Podcast (formerly This Week in Machine Learning & Artificial Intelligence)
Hosted by Sam Charrington
Artificial intelligence and machine learning are fundamentally altering how organizations run and how individuals live. It is important to discuss the latest innovations in these fields to gain the most benefit from technology. The TWIML AI Podcast outreaches a large and significant audience of ML/AI academics, data scientists, engineers, tech-savvy business, and IT (Information Technology) leaders, as well as the best minds and gather the best concepts from the area of ML and AI.
The podcast is hosted by a renowned industry analyst, speaker, commentator, and thought leader Sam Charrington. Artificial intelligence, deep learning, natural language processing, neural networks, analytics, computer science, data science, and other technologies are discussed.
3. The AI Podcast
Hosted by NVIDIA
One individual, one interview, one account. This podcast examines the effects of AI on our world. The AI podcast creates a real-time oral history of AI that has amassed 3.4 million listens and has been hailed as one of the best AI and machine learning podcasts. They always bring you a new story and a new 25-minute interview every two weeks. Consequently, regardless of the difficulties, you are facing in marketing, mathematics, astrophysics, paleo history, or simply trying to discover an automated way to sort out your kid’s growing Lego pile, listen in and get inspired.
4. DataFramed
Hosted by DataCamp
DataFramed is a weekly podcast exploring how artificial intelligence and data are changing the world around us. On this show, we invite data & AI leaders at the forefront of the data revolution to share their insights and experiences into how they lead the charge in this era of AI. Whether you’re a beginner looking to gain insights into a career in data & AI, a practitioner needing to stay up-to-date on the latest tools and trends, or a leader looking to transform how your organization uses data & AI, there’s something here for everyone.
5. Data Skeptic
Hosted by Kyle Polich
Data Skeptic launched as a podcast in 2014. Hundreds of interviews and tens of millions of downloads later, it is a widely recognized authoritative source on data science, artificial intelligence, machine learning, and related topics.
The Data Skeptic Podcast features interviews and discussion of topics related to data science, statistics, machine learning, artificial intelligence and the like, all from the perspective of applying critical thinking and the scientific method to evaluate the veracity of claims and efficacy of approaches. Data Skeptic runs in seasons. By speaking with active scholars and business leaders who are somehow involved in our season’s subject, we probe it.
Data Skeptic is a boutique consulting company in addition to its podcast. Kyle participates directly in each project the team undertakes. Our work primarily focuses on end-to-end machine learning, cloud infrastructure, and algorithmic design.
Artificial Intelligence and Machine Learning podcast
6. Last Week in AI
Hosted by Skynet Today
Tune in to Last Week in AI for your weekly dose of insightful summaries and discussions on the latest advancements in AI, deep learning, robotics, and beyond. Whether you’re an enthusiast, researcher, or simply curious about the cutting-edge developments shaping our technological landscape, this podcast offers insights on the most intriguing topics and breakthroughs from the world of artificial intelligence.
7. Everyday AI
Hosted by Jordan Wilson
Discover The Everyday AI podcast, your go-to for daily insights on leveraging AI in your career. Hosted by Jordan Wilson, a seasoned martech expert, this podcast offers practical tips on integrating AI and machine learning into your daily routine. Stay updated on the latest AI news from tech giants like Microsoft, Google, Facebook, and Adobe, as well as trends on social media platforms such as Snapchat, TikTok, and Instagram. From software applications to innovative tools like ChatGPT and Runway ML, The Everyday AI has you covered.
8. Learning Machines 101
Smart machines employing artificial intelligence and machine learning are prevalent in everyday life. The objective of this podcast series is to inform students and instructors about the advanced technologies introduced by AI and the following:
How do these devices work?
Where do they come from?
How can we make them even smarter?
And how can we make them even more human-like
9. Practical AI: Machine Learning, Data Science
Hosted by Changelog Media
Making artificial intelligence practical, productive, and accessible to everyone. Practical AI is a show in which technology professionals, businesspeople, students, enthusiasts, and expert guests engage in lively discussions about Artificial Intelligence and related topics (Machine Learning, Deep Learning, Neural Networks, GANs (Generative adversarial networks), MLOps (machine learning operations) (machine learning operations), AIOps, and more).
The focus is on productive implementations and real-world scenarios that are accessible to everyone. If you want to keep up with the latest advances in AI, while keeping one foot in the real world, then this is the show for you!
10. The Artificial Intelligence Podcast
Hosted by Dr. Tony Hoang
The Artificial intelligence podcast talks about the latest innovations in the artificial intelligence and machine learning industry. The recent episode of the podcast discusses text-to-image generator, Robot dog, soft robotics, voice bot options, and a lot more.
Have we missed any of your favorite podcasts?
Do not forget to share in comments the names of your most favorite AI and ML podcasts. Read this amazing blog if you want to know about Data Science podcasts.
In this blog, we will discuss the top 8 Machine Learning algorithms that will help you to receive and analyze input data to predict output values within an acceptable range
Top 8 machine learning algorithms explained
1. Linear Regression
Linear regression – Machine learning algorithm – Data Science Dojo
Linear regression is a simple machine learning model and chances are you are already aware of it! Do you remember plotting the line y=mx+c in your introductory algebra class? This is an equation of a straight line where m is its gradient and c is the point where the line crosses the y-axis. Using this equation, you’re able to estimate the value of y for any given value of x. Similarly, linear regression involves estimating the relationship between independent variables (x) and a dependent variable(y).
2. Logistic Regression
Logistic regression – Machine learning algorithm – Data Science Dojo
Just like linear regression, logistic regression is a machine learning model used to determine the relationship between a dependent variable and one or more independent variables. However, this model is used for classification analysis. This is because logistic regression predicts the probability of an event occurring. For a probability greater than 0.5, a value of 1 is assigned, and for less than that 0. For example, you can use logistic regression to predict whether a student will pass (1) an exam, or they will fail (0).
3. Decision Trees
Linear regression – Machine learning algorithm – Data Science Dojo
Decision tree is a supervised machine learning model that repeatedly splits the data based on a question corresponding to the features. The model learns the best way to reduce randomness and drafts a decision tree that can be used to predict the category of an item based on answering a selection of questions. For example, in the case of whether it will rain today or not, the questions can be whether it is sunny, did it rain yesterday, whether it is windy, and so on.
4. Random Forest
Random forest – Machine learning algorithm – Data Science Dojo
Random Forest is a machine learning algorithm that works similarly to a decision tree. The difference is that random forest uses multiple decision trees to make a prediction and hence decreases overfitting. The process of majority voting is carried out and the class selected by most trees is assigned to an item. For example, if two trees predict it to be 0, and one tree predicts it to be 1, then the class of 0 will be assigned to the item.
5. K-Nearest Neighbor
K-nearest neighbor – Machine learning algorithm – Data Science Dojo
K-Nearest Neighbor is another simple machine learning algorithm that classifies new cases based on the category/class of the data points nearest to the new data point. That is, if most neighbors of an unknown item belong to class 1, then we assign class 1 to this unknown item. The number of neighbors to take into consideration is the value K assigned. If k=10, we will look at the 10 nearest neighbors of this item. The nearest neighbors are determined by measuring the distance using distance measures such as Euclidean distance, and the nearest are those that have the shortest distance.
6. Support Vector Machine
Support vector machine – Machine learning algorithm – Data Science Dojo
Support vector machines by dividing the data points using a hyperplane which is a straight line. The points donated by the blue diamond form one class on the left side of the plane and the points donated by the green circle represent another class on the right side of the plane. If we want to predict the class of a new point, we can simply determine it by whether it lies on the left or right side of the hyperplane and where it is within the margin.
7. K-Means clustering
K-means clustering – Machine learning algorithm
K-means clustering is an unsupervised machine learning algorithm. That means it is used to work with data points whose class is not already known. We can use the clustering algorithm to group similar items into clusters. The number of clusters is determined by the value of K assigned. For example, you assign K=3. Three clusters are selected at random, and we adjust them until they are highly distinct from one another. Distinct clusters will have points similar to each other but these points will be distinct from points in another cluster.
Naïve Bayes is a probabilistic machine learning model based on the Bayes theorem that assumes that all the features are independent of one another. Conditional probability refers to the probability of an outcome occurring if it is given that another event has occurred. This algorithm predicts the probability that an item belongs to a particular class and is assigned the class with the highest probability.
Share more Machine Learning algorithms with us
Have we missed any Machine Learning algorithm that you would like to learn about? Share with us in the comments below
Data Science Dojo is offering Apache Zeppelin for FREE on Azure Marketplace packaged with pre-installed interpreters and backends to make Machine Learning easier than ever.
Introduction
How cumbersome and tiring it is to install different tools to perform your desired ML tasks and then look after the integration and dependency issues. Already getting headaches? Worry not, because Data Science Dojo’s Apache Zeppelin instance fixes all of that. But before we delve further into it, let’s get to know some basics.
What are Machine Learning Operations?
Machine Learning is a branch of Artificial Intelligence that deals with models that produce outcomes based on some learned pre-existing data. It provides automation and reduces the workload of users. ML converges with Data Science and Engineering and that gives birth to some necessary operations to be performed to acquire the output of any task.
These operations include ETL (Extraction, Transform, Load) or ELT, drawing interactive visualizations, running queries, training and testing ML models and several other functions.
Pro Tip: Join our 6-months instructor-led Data Science Bootcamp to master machine learning skills.
Challenges for individuals
Wanting to explore and visualize your data but not knowing the methodology of the new tool is not only a red flag but also demands extraneous skills to be learnt to proceed with your job. Or you would have to switch among different environments to achieve your goal which is again – time-consuming, and needless to say time is of the essence for data scientists and engineers when they must deliver a task.
In this scenario, switching from one tool to another which you may know how to use or may not, is time and cost intensive. What if a data driven interactive environment having several interpreters ready to be worked with in one place is provided and you just select your favorite language and break the ice?
ML Operations with Apache Zeppelin
Apache Zeppelin is an open-source tool that equips you with a web-based notebook that can be used for data processing and querying, handling big data, training and testing models, interactive data analytics, visualization, and exploration. Vibrant designs and pictures generated can save time for users in the identification of key patterns in data and ultimately accelerates the decision-making processes.
It contains different pre-installed interpreters but also allows you to plug in your own various language backends for desirability. Apache Zeppelin supports many data sources which allow you to synthesize your data to visualize into interactive plots and charts. You can also create dynamic forms in your notebook and can share your notebook with collaborators.
Zeppelin delivers an optimized and interactive UI that enhances the plots, charts, and other diagrams. You can also create dynamic forms in your notebook along with other markdowns to fancify your note
It’s open-source and allows vendors to make Zeppelin highly customized according to use-case requirements that vary from industry to industry
The choice to select a learned backend from a variety of pre-installed ones or the feasibility to add your own customizable language adds to the user-friendliness, flexibility, and adaptability
It supports Big Data databases like Hive and Spark. It also provides support for web sockets so you can share your web page by echoing the output of the browser and creating live reports
Zeppelin provides an in-build job manager who keeps track of the condition or status of various notebooks
What Data Science Dojo has for you
Our Zeppelin instance serves as a web-accessible programming environment with miscellaneous pre-installed interpreters. In our service users can switch between different interpreters like processing data with python and then visualizing it by querying with SQL. The pre-installed backends provide the feasibility to perform the task using your accustomed language instead of learning a new tool.
A web-accessible Zeppelin environment
Several pre-installed language-backends/interpreters
Various tutorial notebooks containing codes for understandability
A Job manager responsible for monitoring the status of the notebooks
A Notebook Repos feature to manage your notebook repositories’ settings
Ability to import notes from JSON file or URL
In-build functionality to add and modify your own customized interpreters
Efficient resource requirement for processing, visualizing, and training large data was one of the areas of concern when working on traditional desktop environments. The other area of concern includes the burden of working with non-familiar backends or switching among different accustomed environments. With our Zeppelin instance, both concerns are put to rest.
When coupled with Microsoft Azure services and processing speed, it outperforms the traditional counterparts because data-intensive computations aren’t performed locally, but in the cloud. You can collaborate and share notebooks with various stakeholders within and outside the company while monitoring the status of each
At Data Science Dojo, we deliver data science education, consulting, and technical services to increase the power of data. We are therefore adding a free Zeppelin Notebook Environment dedicated specifically for Machine Learning and Data Science operations on Azure Market Place. Don’t wait to install this offer by Data Science Dojo, your ideal companion in your journey to learn data science!
Click on the button below to head over to the Azure Marketplace and deploy Apache Zeppelin for FREE by clicking on “Get it now”.
Note: You’ll have to sign up to Azure, for free, if you do not have an existing account.
Be it Netflix, Amazon, or another mega-giant, their success stands on the shoulders of experts, analysts are busy deploying machine learning through supervised, unsupervised, and reinforcement successfully.
The tremendous amount of data being generated via computers, smartphones, and other technologies can be overwhelming, especially for those who do not know what to make of it. To make the best use of data researchers and programmers often leverage machine learning for an engaging user experience.
Many advanced techniques that are coming up every day for data scientists of all supervised, and unsupervised, reinforcement learning is leveraged often. In this article, we will briefly explain what supervised, unsupervised, and reinforcement learning is, how they are different, and the relevant uses of each by well-renowned companies.
Supervised machine learning is used for making predictions from data. To be able to do that, we need to know what to predict, which is also known as the target variable. The datasets where the target label is known are called labeled datasets to teach algorithms that can properly categorize data or predict outcomes. Therefore, for supervised learning:
We need to know the target value
Targets are known in labeled datasets
Let’s look at an example: If we want to predict the prices of houses, supervised learning can help us predict that. For this, we will train the model using characteristics of the houses, such as the area (sq ft.), the number of bedrooms, amenities nearby, and other similar characteristics, but most importantly the variable that needs to be predicted – the price of the house.
A supervised machine learning algorithm can make predictions such as predicting the different prices of the house using the features mentioned earlier, predicting trends of future sales, and many more.
Sometimes this information may be easily accessible while other times, it may prove to be costly, unavailable, or difficult to obtain, which is one of the main drawbacks of supervised learning.
Saniye Alabeyi, Senior Director Analyst at Garnet calls Supervised learning the backbone of today’s economy, stating:
“Through 2022, supervised learning will remain the type of ML utilized most by enterprise IT leaders” (Source).
Types of problems:
Supervised learning deals with two distinct kinds of problems:
Classification problems
Regression problems
Classification problem: In the case of classification problems, examples are classified into one or more classes/ categories.
For example, if we are trying to predict that a student will pass or fail based on their past profile, the prediction output will be “pass/fail.” Classification problems are often resolved using algorithms such as Naïve Bayes, Support Vector Machines, Logistic Regression, and many others.
Regression problem: A problem in which the output variable is either a real or continuous value, s is defined as a regression problem. Bringing back the student example, if we are trying to predict that a student will pass or fail based on their past profuse, the prediction output will be numeric, such as “68%” likely to score.
Predicting the prices of houses in an area is an example of a regression problem and can be solved using algorithms such as linear regression, non-linear regression, Bayesian linear regression, and many others.
Why Amazon, Netflix, and YouTube are great fans of supervised learning
Recommender systems are a notable example of supervised learning. E-commerce companies such as Amazon, streaming sites like Netflix, and social media platforms such as TikTok, Instagram, and even YouTube among many others make use of recommender systems to make appropriate recommendations to their target audience.
Unsupervised learning
Imagine receiving swathes of data with no obvious pattern in it. A dataset with no labels or target values cannot come up with an answer to what to predict. Does that mean the data is all waste? Nope! The dataset likely has many hidden patterns in it.
Unsupervised learning studies the underlying patterns and predicts the output. In simple terms, in unsupervised learning, the model is only provided with the data in which it looks for hidden or underlying patterns.
Unsupervised learning is most helpful for projects where individuals are unsure of what they are looking for in data. It is used to search for unknown similarities and differences in data to create corresponding groups.
An application of unsupervised learning is the categorization of users based on their social media activities.
Commonly used unsupervised machine learning algorithms include K-means clustering, neural networks, principal component analysis, hierarchical clustering, and many more.
Reinforcement learning
Another type of machine learning is reinforcement learning.
In reinforcement learning, algorithms learn in an environment on their own. The field has gained quite some popularity over the years and has produced a variety of learning algorithms.
Reinforcement learning is neither supervised nor unsupervised as it does not require labeled data or a training set. It relies on the ability to monitor the response to the actions of the learning agent.
Most used in gaming, robotics, and many other fields, reinforcement learning makes use of a learning agent. A start state and an end state are involved. For the learning agent to reach the final or end stage, different paths may be involved.
An agent may also try to manipulate its environment and may travel from one state to another
On success, the agent is rewarded but does not receive any reward or appreciation for failure
Amazon has robots picking and moving goods in warehouses because of reinforcement learning
Numerous IT companies including Google, IBM, Sony, Microsoft, and many others have established research centers focused on projects related to reinforcement learning.
Social media platforms like Facebook have also started implementing reinforcement learning models that can consider different inputs such as languages, integrate real-world variables such as fairness, privacy, and security, and more to mimic human behavior and interactions. (Source)
Amazon also employs reinforcement learning to teach robots in its warehouses and factories how to pick up and move goods.
Comparison between supervised, unsupervised, and reinforcement learning
Caption: Differences between supervised, unsupervised, and reinforcement learning algorithms
Supervised learning
Unsupervised learning
Reinforcement learning
Definition
Makes predictions from data
Segments and groups data
Reward-punishment system and interactive environment
Types of data
Labelled data
Unlabeled data
Acts according to a policy with a final goal to reach (No or predefined data)
Commercial value
High commercial and business value
Medium commercial and business value
Little commercial use yet
Types of problems
Regression and classification
Association and Clustering
Exploitation or Exploration
Supervision
Extra supervision
No
No supervision
Algorithms
Linear Regression, Logistic Regression, SVM, KNN and so forth
K – Means clustering,
C – Means, Apriori
Q – Learning,
SARSA
Aim
Calculate outcomes
Discover underlying patterns
Learn a series of action
Application
Risk Evaluation, Forecast Sales
Recommendation System, Anomaly Detection
Self-Driving Cars, Gaming, Healthcare
Which is the better Machine Learning technique?
We learned about the three main members of the machine learning family essential for deep learning. Other kinds of learning are also available such as semi-supervised learning, or self-supervised learning.
Supervised, unsupervised, and reinforcement learning, are all used for different to complete diverse kinds of tasks. No single algorithm exists that can solve every problem, as problems of different natures require different approaches to resolve them.
Despite the many differences between the three types of learning, all of these can be used to build efficient and high-value machine learning and Artificial Intelligence applications. All techniques are used in different areas of research and development to help solve complex tasks and resolve challenges.
Was this article helpful? Let us know in the comments below.
If you would like to learn more about data science, machine learning, and artificial intelligence, visit the Data Science Dojo blog.
In today’s blog, we will try to understand the working behind social media algorithms and focus on the top 6 social media platforms. Algorithms are a part of machine learning which has also become a key area to measure success of digital marketing; these are written by coders to learn human actions. It specifies the behavior of data by using a mathematical set of rules
According to the latest data for 2022, users worldwide spend 147 minutes, on average every day on social media. The use of social media is booming with every passing day. We get hooked up on the content of our interest. But you cannot deny that it is often surprising to experience the content we just discussed with our friends or family.
Social media algorithms sort posts on a user’s feed based on their interest rather than the publishing time. Every content creator desires to get the maximum impressions on their social media postings or their marketing campaigns. That’s where the need to develop quality content comes in. Social media users only experience the content that the algorithms figure out to be most relevant for them.
1. Insights into Facebook algorithm
Facebook had 2.934 billion monthly active users in July 2022.
Anna Stepanov, Head of Facebook App Integrity said “News Feed uses personalized ranking, which considers thousands of unique signals to understand what’s most meaningful to you. Our aim isn’t to keep you scrolling on Facebook for hours on end, but to give you an enjoyable experience that you want to return to.”
On Facebook, which means that the average reach for an organic post is down over 5 percent while the engagement rate is just 0.25 percent which drops to 0.08 percent if you have over 100k followers.
Facebook’s algorithm is not static, it has evolved over the years with the objective to keep its users engaged with the platform. In 2022, Facebook adopted the idea of showing stories to users instead of news, like before. So, what we see on Facebook is no longer a newsfeed but “feed” only.
Further, it works mainly on 3 ranking signals:
Interactivity:
The more you interact with the posts from one of your friends or family members, Facebook is going to show you their activities relatively more on your feed.
Interest:
If you like content about cars or automobiles, there’s a high chance Facebook algorithm will push relevant posts to your feed. This happens because we search, like, interact or spend most of our time seeing the content we like.
Impressions:
Viral or popular content becomes a part of everyone’s Facebook. That’s because the Facebook algorithm promotes content that is in general liked by its users. So, you’re also more likely to see what’s everyone talking about today.
2. How does YouTube algorithm work
There are 2.1 billion monthly active YouTube users worldwide. When you open YouTube, you see multiple streaming options. YouTube says that in 2022, homepages and suggested videos are usually the top sources of traffic for most channels.
The broad selection is narrowed on the user homepage on the basis of two main types of ranking signals.
Performance:
When a video is uploaded on YouTube, the algorithm evaluates it on the basis of a few key metrics:
Click-through rate
Average view duration
Average percentage viewed
Likes and dislikes
Viewer surveys
If a video gains good viewership and engagement by the regular followers of the channel, then the YouTube algorithm will offer that video to more users on YouTube.
Personalization:
The second-ranking signal for YouTube is personalization. In case you love watching DIY videos, YouTube algorithm processes to keep you hooked on the platform by suggesting interesting DIY videos to you.
Personalization works based on a user’s watch history or the channels you subscribed to lately. It tracks your past behavior and figures out your most preferred streaming options.
Lastly, you must not forget that YouTube acts as a search engine too. So, what you type in the search bar plays a major role in shortlisting the top videos for you.
3. Instagram algorithm explained
In July 2022, Instagram reached 1.440 billion users around the world according to the global advertising audience reach numbers.
The main content on Instagram revolves around posts, stories, and reels. Instagram CEO Adam Mosseri said, “We want to make the most of your time, and we believe that using technology [the Instagram algorithm] to personalize your experience is the best way to do that.”
Let’s shed some light to the Instagram’s top 3 ranking factors for year 2022:
Interactivity:
Every account holder or influencer on Instagram runs after followers. Because that’s the core to getting your content viewed by the users. To get something on our Instagram feed we need to follow other accounts. As much as our interaction with someone’s content occurs, we will be able to see more of their postings.
Interest:
This ranking factor has more influence on reels feed and explore page. The more you show interest in watching a specific type of content and tap on it, the more of that category will be shown to you. And it’s not essential to follow someone to see their postings on reels and explore the page.
Information:
How relevant is the content uploaded on Instagram? This highlights the value of content posted by anyone. If people are talking about it, engaging with it, and sharing it on their stories, you are also going to see it on your feed.
4. Guide to Pinterest algorithm
Being the 15th most active social media platform, Pinterest had 433 million monthly active users in July 2022.
Pinterest is popular amongst audiences who are more likely interested in home décor, aesthetics, food, and style inspirations. This platform carries a slightly different purpose of use than the above-mentioned social media platforms. Therefore, the algorithm works with distinct ranking factors for Pinterest.
Pinterest algorithm promotes pins having:
High-quality images and visually appealing designs
Proper use of keywords in the pin descriptions so that pins come up in search results.
Increased activity on Pinterest and engagement with other users.
Needless to mention, the algorithm weighs more for the pins that are similar to a user’s past pins and search activities.
5. Working process behind LinkedIn algorithm
There are 849.6 million users with LinkedIn in July 2022. LinkedIn is a platform for professionals. People use it to build their social networks and have the right connections that can help them succeed in their careers.
To maintain the authenticity and relevance of connections for professionals, the LinkedIn algorithm processes billions of posts per day to keep the platform valuable for its users. LinkedIn’s ranking factors are mainly these:
Spam:
LinkedIn considers post as spam if it contains a lot of links, has multiple grammatical errors, and consists of bad vocabulary. Also, avoid using hashtags like #comment, #like, or #follow can flag the system, too.
Low-quality posts:
There are billions of posts uploaded on LinkedIn every day. The algorithm works to filter out the best for users to engage with. Low-quality posts are not spam but they lack value as compared to other posts. It is evaluated based on the engagement a post receives.
High-quality content:
You wonder what’s the criteria to create high-quality posts on LinkedIn? Here are some tips to remember:
Easy to read posts
Encourages responses with a question
Uses three or fewer hashtags
Incorporates strong keywords
Tag responsive people to the post
Moreover, LinkedIn appreciates consistency in posts, so it’s recommended to keep your followers engaged not only with informative posts but also conversing with users in the comments section.
6. A sneak peek at the TikTok algorithm
TikTok will have 750 million monthly users worldwide in 2022. In the past couple of years, this social media platform has gained popularity for all the right reasons. The TikTok algorithm is considered as a recommendation system for its users.
We have found one great explanation of TikTok “For You” page algorithm by the platform itself:
“A stream of videos curated to your interests, making it easy to find content and creators you love … powered by a recommendation system that delivers content to each user that is likely to be of interest to that particular user.”
Key ranking factors for the TikTok algorithm are:
User interactions:
This factor is like the Instagram algorithm, but mainly concerns the following actions of users:
Which accounts do you follow
Comments you’ve posted
Videos you’ve reported as inappropriate
Longer videos you watch all the way to the end (aka video completion rate)
Content you create on your own account
Creators you’ve hidden
Videos you’ve liked or shared on the app
Videos you’ve added to your favorites
Videos you’ve marked as “Not Interested”
Interests you’ve expressed by interacting with organic content and ads
Video information:
Videos with missing information, incorrect captions, titles, and tags are buried under hundreds of videos being uploaded on TikTok every minute. On the discover tab, your video information signals tend to seek for:
Captions
Sounds
Hashtags*
Effects
Trending topics
TikTok account settings:
TikTok algorithm optimizes the audience for your video based on the options you selected while creating your account. Some of the device and account settings that decide audience for your videos are:
Language preference
Country setting (you may be more likely to see content from people in your own country)
Type of mobile device
Categories of interest you selected as a new user
Social media algorithms relation with content quality
Apart from all the key ranking factors for each platform, we discussed in this blog, one thing remains ascertain for all i.e., maintain content quality. Every social media platform is algorithm bsed which means it only filters out the best quality content for visitors.
No matter which platform you focus on growing your business or your social network, it highly relies on the meaningful content you provide your connections.
If we missed your favorite social media platform, don’t worry, let us know in the comments and we will share its algorithm in the next blog.
What’s better than a data scientist? Well, humor is based on their pain, of course.Here’s a list of over 50 data science memes to help you get through the week.
When thinking of Data Scientists and researchers, the first things that usually come to mind are algorithms, techniques, and programming languages. However, there’s a completely different aspect of data science that is often ignored: the far more entertaining side of the field.
Moreover, a Data Scientist’s job can become extremely stressful. In such tiring times, it is especially important to take a step back and take a breather.
To help our fellow data scientists or anyone who may be planning on joining the ranks, we have compiled a list of memes from Reddit to brighten your day. So, if you ever need a break from training your model or just from life in general, bookmark this article and go over the list.
Previously, we also compiled a list of data science, machine learning, statistics, and artificial intelligence jokes. The internet is filled with hidden gems such as these, so we thought it would be a great idea to compile them in one place.
List of 50+ memes compiled for some mid-week laughs:
1. Let’sbegin with the basic ‘data scientist’ starter pack:
2. Been there, done that. More times than I’d like to admit.
3. This may or may not be helpful for your next job interview. Try at your own risk.
4. It’s safe to say, we only see the good boy.
5. Oh no! The cat’s been let out of the bag.
6. I am somewhat of an expert myself in data science and machine learning.
7. I’ll admit Neural Networks do look a bit spooky. It’s just the way they are.
8. Shh! You can be anything you want to be. Don’t let anyone else tell you otherwise.
9. Everyone here at Data Science Dojo.
10. I am ashamed to admit that this has happened way too often.
11. I really thought it would be simpler.
12. Don’t get me wrong, I like mathematics, but why does the universe keep testing me like this?
13. I study data science memes more than actual books.
14. The only 10-year challenge that really matters.
15. Shh! What they don’tknowwon’t hurt them.
16. Days when the programming blues kick in, don’t you wish you could skip and just get away from everything?
17. Do you know what the funeral director did with Alan Turing’s dead body? He encrypted it.
18. Human know all. Human smart. Machine dumb.
19. Overfittingis the bane of my existence.
20. Almost had us there in the first half.
21. Why does Python live on land? Because it is above C-level. (Cries in high-level languages)
22. The two look nothing alike.
23. This is the only thing I really care about most days.
24. Most data scientists just want to watch the world burn.
25. Anytime a data scientist shares a meme in the family group chat.
26. Follow us for more intellectual content on Machine Learning.
27. This is what Data Scientists areup to all day long.
28. Revealingto the world what Artificial Intelligence really is.
29. Life is just a constant battle between what they want vs what they give.
30. Every single company ever. (Not us though)
31. What is your idea of a perfect date? I like DD-MM-YYYY.
32. Spoiler alert: Anakin may have been evil, but we did not think he was this evil.
33. Gaussian is the only way to go.
34. This is what everyone means when they talk about the algorithm.
35. The ingredients needed to create the perfect data scientist.
36. I am somewhat of an R programmer myself.
37. This is the only way to attain deep self-actualization.
38. This is what would happen if a Data Scientist were to become a parent.
39. We all know he is a very good boy who can take care of himself.
40. Some deep learnings just do not deep learn the way other deep learnings do.
41. Skipping any step may prove to be fatal.
42. The four stages of deep learning – the four stages before a disaster.
43. The greatest question in the universe that needs to be answered asap.
44. Let us be honest here, research and mathematics are extremely scary.
45. Data scientists spend 80% of their time collecting, cleaning, and preparing data.
46. If you know, you know.
47. This is a tough one.
48. BRB, we need to edit our resumes now.
49. A dog’s projected growth based on trends is not a sight anyone would like to see.
50. Mathematics – the only OG in the universe.
51. This hits on a different level.
52. Have you ever tried a data science pickup line? They may work. Sometimes.
53. Please don’t tell HR.
54. If it works, it works.55. One can never go wrong with a tweet.
56. Please do not let our engineering team hear about this.
57. Data science summarized in a single photograph:
58. Data Scientist mantra: I am not everyone else’s perception of me.
59. Sometimes at night, I can still hear the data.
60. The positively skewed graph does not get along with the negatively skewed one.
61. My model’s been training for the past 999999 days, now.
62. Testing is one word I do not enjoy hearing about.
63. Please understand the importance of the p-value.
64. As a cat person myself, I support this graph.65. Our future looks very much like this.
66. Data scientists all day, every day.
67. Machine learning, good. Data science, bad.
68. When you sometimes make an oopsie.
69. “I was rooting for you. We were all rooting for you. How dare you?” – Tyra Banks.
70. We like one more than the other.
71. Everyone wants to become a data scientist, but no one wants to clean the data.
72. Should we tell him?
73. Wait until they find out.
74. I honestly do not.
75. Machines are becoming smarter every day.
76. We, data scientists, just love complicating our lives.
77. I may look like I know stuff, but I really do not.
78. Move along. Nothing to see here.
79. Python may be great, but C++ has my heart.
80. So that’s what happened.
81. One just simply cannot.
82. Models really do not make good children.
83. Ah! The satisfaction of days like this.
84. Gradients just like to panic, a lot.
85. Even Mr. Rogers approves.
We hope you enjoyed these funny data science memes.
Let us know which meme was your favorite in the comments below and share it with other data scientists. Also, feel free to share a relatable meme of your own.
Confused about which machine learning conferences you should attend? Here are our top 10 picks for the remaining months of 2022.
For aspiring data scientists, machine learners, and researchers, conferences are a great way to network, highlight their own work, and learn from others. This article highlights the top 10machine learning conferences that you should attend if you are in Asia or are planning to visit soon.
1. ACAIT 2022: The 6th Asian Conference on Artificial Intelligence Technology – Changzhou, China
Taking place in the southern Jiangsu province of China, on the 4th of November, the ACAIT is a joint endeavor of the Institute of Electrical and Electronics Engineers (IEEE), Chinese Association for Artificial Intelligence (CAAI), and Changzhou Institute of Technology (CIT).
The conference invites significant and original research work from the world of artificial intelligence. The main aim of the conference is to provide an international forum for researchers to share their ideas and achievements in the field of artificial intelligence.
The conference covers all major topics from AI-related brain and cognitive sciences to machine Cognition and Pattern Recognition, Big data and knowledge engineering, Robotics, swarm intelligence, and even the Internet of Things.
Further details regarding the conference can be found here.
2. 4th Asian Conference on Machine Learning (ACML 2022) – Hyderabad, India
Taking place between 12th to 14th December in Hyderabad, India, the ACML abides by the post-pandemic laws and will be conducted virtually, as well as allow in-person interactions.
Focusing on theoretical and practical aspects of machine learning, the conference encourages researchers from around the globe to join and be a part of the conversation.
The conference will cover general machine learning topics such as supervised learning and reinforcement learning, and even dive deeper into Deep Learning, Probabilistic Methods, theoretical frameworks, and much more.
Further details regarding the conference can be found here.
3. The 29th International Conference on Computational Linguistics – Gyeongju, Republic of Korea
One of the most popular conferences on natural language processing and computational linguistics, COLING is expected to be held on October 12-17, 2022, in Gyeongju, South Korea.
The conference has been held every year since 1965. Participants from both top-ranked research centers and emerging countries attend this conference as it provides equal opportunities to researchers from educational institutes and academia, as well as from the corporate sector.
COLING focuses on all aspects of natural language processing and computation.
Not only is this one of the most prestigious conferences on NLP and computational linguistics, but it is also heavily sponsored by names such as LG Electronics, Hyundai, Google, and Apple, among many others.
Further details regarding the conference can be found here.
4. IROS 2022: International Conference on Intelligent Robots and Systems – Kyoto, Japan
One of the flagship conferences of the robotics community, IROS is one of the world’s oldest forums for the global robotics community to explore intelligent robots and systems. Held every year in Kyoto, Japan since 1987, the conference will be held on 23-27 October.
Not only does the conference feature numerous research works from various international authors, but the conference also includes workshops and training, as well as multiple guest lectures by professionals in academia and industry.
Further details regarding the conference can be found here.
5. ACCV 2022: The 16th Asian Conference on Computer Vision
The Asian Conference on Computer Vision (AACV) 2022 focuses on computer vision and pattern recognition and will be held on 4-8 December in Macau, China.
The biennial international conference is sponsored by the Asian Federation of Computer Vision and provides like-minded individuals an opportunity to discuss the latest problems, solutions, and technologies in the field of computer vision and other similar areas.
The conference proceedings are published by Springer as Lecture Notes. Moreover, the award-winning papers are invited for publication in a special issue of the International Journal of Computer Vision (IJCV).
6. The 29th International Conference on Neural Information Processing (ICONIP 2022), New Delhi, India
One of the leading international conferences in the fields of pattern recognition, neuroscience, intelligent control, information security, and brain-machine interface, the ICONIP will be held in New Delhi, India on 22nd -26th November 2022.
It is the annual flagship conference organized by the Asia Pacific Neural Network Society (APNNS), which strives towards bridging the gap between educational institutions and industry.
The conference provides an international forum for anyone working in neuroscience, neural networks, deep learning, and other similar fields.
The conference is divided into four categories: Theory and Algorithms, Computational and Cognitive Neurosciences, Human-Centered Computing, and other machine learning applications.
Further details on the conference can be found here.
7. The 19th Pacific Rim International Conference on Artificial Intelligence (PRICAI) – Shanghai, China
A biennial international conference, the PRICAI focuses on AI theories, technologies, and their applications in areas of social and economic importance, specifically focusing on countries in the Pacific Rim. Held since 1990, PRICAI will take place on 10-13th November, in the financial hub of China – Shanghai.
The conference focuses on all things related to AI, machine learning, data mining, robotics, computer vision, and much more.
Further information regarding the conference can be found here.
8. The 4th International Conference on Data-driven Optimization of Complex Systems (DOCS2022) – Chengdu, China
Focused on data-driven optimization, learning and control, and their applications to complex systems, DOCS 2022 will be held 23-25th September, Chengdu, Sichuan, China.
The conference focuses on topics ranging from data-driven machine learning, optimization, decision-making, analysis, and application.
Further details on the conference can be found here.
9. The 9th IEEE International Conference on Data Science and Advanced Analytics (DSAA) – Shenzhen, China
Widely recognized as a dedicated flagship annual conference, the International Conference on Data Science and Advanced Analytics (DSAA) will be held in Shenzhen, China on the 13th –16th of October 2022.
The conference not only focuses on computing and information/intelligence sciences but also considers their relationship with statistics, and the crossover of data science and analytics.
An interesting aspect of this conference is that it is a dual-track conference with both a research track and an application track. Further details regarding these different tracks can be found here.
While more details on the conference can be found here.
10. The 5th International Conference on Intelligent Autonomous Systems (ICoIAS 2022) – Dalian, China
The ICoIAS conference focuses on intelligent autonomous systems that play a significant role in multiple control and engineering applications.
The conference will be held on 23-25 September at the Dalian Maritime University, Dalian, China, in collaboration with Tianjin University, the IEEE Computational Intelligence Society, and The Institution of Engineers, Singapore.
The conference focuses on distinct aspects of intelligent autonomous systems. Moreover, IEEE fellows from all over the world are expected to attend the conference as guest speakers.
For further information regarding the conference, click here.
Was this list helpful? Let us know in the comments below. If you would like to find similar conferences in a different area, click here.
If you are interested in learning more about machine learning and data science, click here.
The bike-sharing dataset will be a perfect example to build a Random Forest model in Azure Machine Learning and R in this custom R models’ blog.
The bike-sharing dataset includes the number of bikes rented for different weather conditions. From the dataset, we can build a model that will predict how many bikes will be rented during certain weather conditions.
About Azure machine learning data
Azure Machine Learning Studio has a couple of dozen built-in machine learning algorithms. But what if you need an algorithm that is not there? What if you want to customize certain algorithms? Azure can use any R or Python-based machine learning package and associated algorithms! It’s called the “create model” module. With it, you can leverage the entire open-sourced R and Python communities.
The Bike Sharing dataset is a great data set for exploring Azure ML’s new R-script and R-model modules. The R-script allows for easy feature engineering from date-times and the R-model module lets us take advantage of R’s random Forest library. The data can be obtained from Kaggle; this tutorial specifically uses their “train” dataset.
The Bike Sharing dataset has 10,886 observations, each one about a specific hour from the first 19 days of each month from 2011 to 2012. The dataset consists of 11 columns that record information about bike rentals: date-time, season, working day, weather, temp, “feels like” temp, humidity, wind speed, casual rentals, registered rentals, and total rentals.
Feature engineering & preprocessing
There is an untapped wealth of prediction power hidden in the “DateTime” column. However, it needs to be converted from its current form. Conveniently, Azure ML has a module for running R scripts, which can take advantage of R’s built-in functionality for extracting features from the date-time data.
Since Azure ML automatically converts date-time data to date-time objects, it is easiest to convert the “DateTime” column to a string before sending it to the R script module. The date-time conversion function expects a string, so converting beforehand avoids formatting issues.
We now select an R-Script Module to run our feature engineering script. This module allows us to import our dataset from Azure ML, add new features, and then export our improved data set. This module has many uses beyond our use in the tutorial, which help with cleaning data and creating graphs.
Our goal is to convert the DateTime column of strings into date-time objects in R, so we can take advantage of their built-in functionality. R has two internal implementations of date-times: POSIXlt and POSIXct. We found Azure ML had problems dealing with POSIXlt, so we recommend using POSIXct for any date-time feature engineering.
The function as.POSIXct converts the DateTime column from a string in the specified format to a POSIXct object. Then we use the built-in functions for POSIXct objects to extract the weekday, month, and quarter for each observation. Finally, we use substr() to snip out the year and hour from the newly formatted date-time data.
Remove problematic data
This dataset only has one observation where weather = 4. Since this is a categorical variable, R will result in an error if it ends up in the test data split. This is because R expects the number of levels for each categorical variable to equal the number of levels found in the training data split. Therefore, it must be removed.
#Bike sharing data set as input to the module
dataset <-maill.mapInputPort(1)
#extracting hour, weekday, month, and year fromthe dataset
dataset$datetime <- as.POSIXct(dataset$datetime, format = "%m/%d/%Y %I:%M:%S %p")
dataset$hour <- substr(dataset$datetime, 12,13)
dataset$weekday <- weekdays(dataset$datetime)
dataset$month <- months(dataset$datetime)
dataset$year <- substr(dataset$datetime, 1,4)
#Preserving the column order
Count <- dataset[,names(dataset) %in% c("count")]
OtherColumns <- dataset[,!names(dataset) %in% c("count")]
dataset <- cbind(OtherColumns,Count)
#Remova e single observation with weather = 4 to preventhe t scoring model from failing
dataset <- subset(dataset, weather != '4')
#Return the dataset after appending the new featuresmailml.mapOutputPort("dataset");
Define categorical variables
Before training our model, we must tell Azure ML which variables are categorical. To do this, we use the Metadata Editor. We used the column selector to choose the hour, weekday, month, year, season, weather, holiday, and working day columns.
Then we select “Make categorical” under the “Categorical” dropdown.
Drop low-value columns
Before creating our random forest, we must identify columns that add little-to-no value for predictive modeling. These columns will be dropped.
Since we are predicting the total count, the registered bike rental and casual bike rental columns must be dropped. Together, these values add upthe to total count, which would lead to a successful but uninformative model because the values would simply be summed to see the total count. One could train separate models to predict casual and registered bike rentals independently. Azure ML would make it very easy to include these models in our experiment after creating one for total count.
The third candidate for removal is the DateTime column. Each observation has a unique date-time, so this column just add noise to our model, especially since we extracted all the useful information (day of the week, time of day, etc.)
Now that the dropped columns have been chosen, drag in the “Project Columns” module to drop DateTime, casual, and registered. Launch the column selector and select “All columns” from the dropdown next to “Begin With.” Change “Include” to “Exclude” using the dropdown and then select the columns we are dropping.
Specify a response class
We must now directly tell Azure ML which attribute we want our algorithm to train to predict by casting that attribute as a “label”.
Start by dragging in a metadata editor. Use the column selector to specify “Count” and change the “Fields” parameter to “Labels.” A dataset can only have 1 label at a time for this to work.
Our model is now ready for machine learning!
Model building
Train your model
Here is where we take advantage of AzureMl’s newest feature: the Create R Model module. Now we can use R’s randomForest library and take advantage of its large number of adjustable parameters directly inside AzureML studio. Then, the model can be deployed in a web service. Previously, R models were nearly impossible to deploy to the web.
Similar to a native model in Azure ML, the Create R Model module connects to the Train Model module. The difference is the user must provide an R code for training and scoring separately. The training script goes under “Trainer R script” and takes in one dataset as an input and outputs a model. The dataset corresponds to whichever dataset gets input to the connected Train Module.
In this case, the dataset is our training split and the model output is a random forest. The scoring script goes under “Scorer R script” and has two inputs: a model and a dataset. These correspond to the model from the Train Model module and the dataset input to the Score Model module, which is the test split in this example.
The output is a data frame of the predicted values, which get appended to the original dataset. Make sure to appropriately label your outputs for both scripts as Azure ML expects exact variable names.
#Trainer R Script
#Input: dataset
#Output: model
library(randomForest)
model <- randomForest(Count ~ ., dataset)
#Scorer R Script
#Input: model, dataset
#Output: scores
library(randomForest)
scores <- data.frame(predict(model, subset(dataset, select = -c(Count))))
names(scores) <- c("Predicted Count")
Evaluate your model
Unfortunately, AzureML’s Evaluate Model Module does not support models that use the Create R Model module, yet. We assume this feature will be added in the near future.
In the meantime, we can import the results from the scored model (Score Model module) into an Execute R Script module and compute an evaluation using R. We calculated the MSE then exported our result back to AzureML as a data frame.
#Results as input to module
dataset1 <- maml.mapInputPort(1)
countMSE <- mean((dataset1$Count-dataset1["Predicted Count"])^2)
evaluation <- data.frame(countMSE)
#Output evaluation
maml.mapOutputPort("evaluation");
Data Science Dojo has launched Jupyter Hub for Machine Learning using Python offering to the Azure Marketplace with pre-installed machine learning libraries and pre-cloned GitHub repositories of famous machine learning books which help the learner to take the first steps into the field of machine learning.
What is machine learning?
Machine learning is a sub-field of Artificial Intelligence. It is an innovative technology that allows machines to learn from historical data and provide the best results to predict outcomes.
Machine learning using Python
Machine learning requires exploratory data analysis, data processing, and the training of data to predict outcomes. Python provides a vast number of libraries and frameworks that let the user collect, analyze and transform data by just using built-in functions provided by the library which makes coding easy and also saves a significant amount of time.
Machine learning using Python
PRO TIP: Join our 5-day instructor-led Python for Data Science training to enhance your machine learning skills.
Challenges for individuals
Individuals who are new to machine learning and want to excel in their path in machine learning usually lack computing as well as learning resources to gain hands-on experience with machine learning. A beginner in machine learning also faces compatibility issues while installing libraries.
What we provide
With just a single click, Jupyter Hub for Machine Learning using Python comes with pre-installed machine learning python libraries, which gives the learner an effortless coding environment in the Azure cloud and reduces the burden of installation. Moreover, this offer provides the learner with repositories of famous books on machine learning which contain chapter-wise notebooks which serve as a learning resource for a user in gaining hands-on experience with machine learning. The heavy computations required for Machine Learning applications are not performed on the user’s local machine. Instead, they are performed in the Azure cloud, which increases responsiveness and processing speed.
Listed below are the pre-installed machine learning python libraries and the sources of repositories of machine learning books provided by this offer:
Python libraries
Pandas
NumPy
scikit-learn
mlpack
matplotlib
SciPy
Theano
Pycaret
Orange3
seaborn
Repositories
Github repository of book ‘Python Machine Learning Book 1st Edition’, by author Sebastian Raschka.
Github repository of book ‘Python Machine Learning Book 2nd Edition’, by author Sebastian Raschka.
Github repository of the book ‘Hands-on Machine Learning with Scikit Learn, Keras, and TensorFlow’, by author Geron-Aurelien.
Jupyter Hub for Machine Learning using Python provides an in-browser coding environment with just a single click, hence providing ease of installation. Through this offer, a user can work on a variety of machine learning applications including stock market trading, email spam and malware filtering, product recommendations, online customer support, medical diagnosis, online fraud detection, and image recognition.
Jupyter Hub for Machine Learning using Python offered by Data Science Dojo is ideal to learn more about machine learning without the need to worry about configurations and computing resources. The heavy resource requirement for processing and training large data for these applications is no longer an issue as data-intensive computations are now performed on Microsoft Azure which increases processing speed.
At Data Science Dojo, we deliver data science education, consulting, and technical services to increase the power of data. We are therefore adding a free Jupyter Notebook Environment dedicated specifically for Machine Learning using Python. The offering leverages the power of Microsoft Azure services to run effortlessly with outstanding responsiveness. Install the Jupyter Hub offer now from the Azure Marketplace by Data Science Dojo, your ideal companion in your journey to learn data science!
This blog will cover how to build a recommendation system using Python libraries to perform web scrapping and carry out text transformation. It will teach you how to create your own dataset and further build a content-based recommendation system.
Introduction
A simple recommender system flow
The purpose of Data Science (DS) and Artificial Intelligence (AI) is to add value to a business by utilizing data and applying applicable programming skills. In recent years, Netflix, Amazon, Uber Eats, and other companies have made it possible for people to avail certain commodities with only a few clicks while sitting at home. However, in order to provide users with the most authentic experience possible, these platforms have developed recommendation systems that provide users with a variety of options based on their interests and preferences.
In general, recommendation systems are algorithms that curate data and provide consumers with appropriate material. There are three main types of recommendation engines:
Collaborative filtering: Collaborative filtering collects data regarding user behavior, activities, and preferences to predict what a person will like, based on their similarity to other users.
Content-based filtering: This algorithms analyze the possibility of objects being related to each other using statistics, and then offers possible outcomes to the user based on the highest probabilities.
Hybrid of the two. In a hybrid recommendation engine, natural language processing tags can be generated for each product or item (movie, song), and vector equations are used to calculate the similarity of products.
Building a recommendation system using Python
In this blog, we will walk through the process of scraping a web page for data and using it to develop a recommendation system, using built-in python libraries. Scraping the website to extract useful data will be the first component of the blog. Moving on, text transformation will be performed to alter the extracted data and make it appropriate for our recommendation system to use.
Finally, our content-based recommender system will calculate the cosine similarity of each blog with the rest of the blogs and then suggest three comparable blogs for each blog post.
Flow for recommendation system using web scrapping
First step: Web scrapping
The purpose of going through the web scrapping process is to teach how to automate data entry for a recommender system. Knowing how to extract data from the internet will allow you to develop skills to create your own dataset using an entire webpage. Now, let us perform web scraping on the blogs page of online.datasciencedojo.com.
In this blog, we will extract relevant information to make up our dataset. From the first page, we will extract the URL, name, and description of each blog. By extracting the URL, we will have access to redirect our algorithm to each blog page and extract the name and description from the metadata.
The code below uses multiple python libraries and extracts all the URLs from the first page. In this case, it will return ten URLs. For building better concepts regarding web scrapping, I would suggest exploring and playing with these libraries to better understand their functionalities.
Note: The for loop is used to extract URLs from multiple pages.
import requests
import lxml.html
from lxml import objectify
from bs4 import BeautifulSoup
#List for storing urls
urls_final = []
#Extract the metadata of the page
for i in range(1):
url = 'https://online.datasciencedojo.com/blogs/?blogpage='+str(i)
reqs = requests.get(url)
soup = BeautifulSoup(reqs.text, 'lxml')
#Temporary lists for storing temporary data
urls_temp_1 = []
urls_temp_2=[]
temp=[]
#From the metadata, get the relevant information.
for h in soup.find_all('a'):
a = h.get('href')
urls_temp_1.append(a)
for i in urls_temp_1:
if i != None :
if 'blogs' in i:
if 'blogpage' in i:
None
else:
if 'auth' in i:
None
else:
urls_temp_2.append(i)
[temp.append(x) for x in urls_temp_2 if x not in temp]
for i in temp:
if i=='https://online.datasciencedojo.com/blogs/':
None
else:
urls_final.append(i)
print(urls_final)
Output
['https://online.datasciencedojo.com/blogs/regular-expresssion-101/',
'https://online.datasciencedojo.com/blogs/python-libraries-for-data-science/',
'https://online.datasciencedojo.com/blogs/shareable-data-quotes/',
'https://online.datasciencedojo.com/blogs/machine-learning-roadmap/',
'https://online.datasciencedojo.com/blogs/employee-retention-analytics/',
'https://online.datasciencedojo.com/blogs/jupyter-hub-cloud/',
'https://online.datasciencedojo.com/blogs/communication-data-visualization/',
'https://online.datasciencedojo.com/blogs/tracking-metrics-with-prometheus/',
'https://online.datasciencedojo.com/blogs/ai-webmaster-content-creators/',
'https://online.datasciencedojo.com/blogs/grafana-for-azure/']
Once we have the URLs, we move towards processing the metadata of each blog for extracting their name and description.
#Getting the name and description
name=[]
descrip_temp=[]
#Now use each url to get the metadata of each blog post
for j in urls_final:
url = j
response = requests.get(url)
soup = BeautifulSoup(response.text)
#Extract the name and description from each blog
metas = soup.find_all('meta')
name.append([ meta.attrs['content'] for meta in metas if 'property' in meta.attrs and meta.attrs['property'] == 'og:title' ])
descrip_temp.append([ meta.attrs['content'] for meta in metas if 'name' in meta.attrs and meta.attrs['name'] == 'description' ])
print(name[0])
print(descrip_temp[0])
Output:
['RegEx 101 - beginner’s guide to understand regular expressions']
['A regular expression is a sequence of characters that specifies a search pattern in a text. Learn more about Its common uses in this regex 101 guide.']
Second step: Text transformation
Similar to any task involving text, exploratory data analysis (EDA) is a fundamental part of any algorithm. In order to prepare data for our recommender system, data must be cleaned and transformed. For this purpose, we will be using built-in python libraries to remove stop words and transform data.
The code below uses the regex library to perform text transformation by removing punctuations, emojis, and more. Furthermore, we have imported a natural language toolkit (nlkt) to remove stop words.
Note: Stop words are a set of commonly used words in a language. Examples of stop words in English are “a”, “the”, “is”, “are” etc. They are so frequently used in the text that they hold a minimal amount of useful information.
import nltk
from nltk.corpus import stopwords
nltk.download("stopwords")
import re
#Removing stop words and cleaning data
stop_words = set(stopwords.words("english"))
descrip=[]
for i in descrip_temp:
for j in i:
text = re.sub("@\S+", "", j)
text = re.sub(r'[^\w\s]', '', text)
text = re.sub("\$", "", text)
text = re.sub("@\S+", "", text)
text = text.lower()
descrip.append(text)
Following this, we will be creating a bag of words. If you are not familiar with it, a bag of words is a representation of text that describes the occurrence of words within a document. It involves two things: A vocabulary of known words, and a measure of the presence of those words. For our data, it will represent all the keywords words in the dataset and calculate which words are used in each blog and the number of occurrences they have. The code below uses a built-in function to extract keywords.
from keras.preprocessing.text import Tokenizer
#Building BOW
model = Tokenizer()
model.fit_on_texts(descrip)
bow = model.texts_to_matrix(descrip, mode='count')
bow_keys=f'Key : {list(model.word_index.keys())}'
For building better concepts, here are all the extracted keywords.
The code below assigns each keyword an index value and calculates the frequency of each word being used per blog. When building a recommendation system, these keywords and their frequencies for each blog will act as the input. Based on similar keywords, our algorithm will link blog posts together into similar categories. In this case, we will have 10 blogs converted into rows and 139 keywords converted into columns.
import pandas as pd
#Creating df
df_name=pd.DataFrame(name)
df_name.rename(columns = {0:'Blog'}, inplace = True)
df_count=pd.DataFrame(bow)
frames=[df_name,df_count]
result=pd.concat(frames,axis=1)
result=result.set_index('Blog')
result=result.drop([0], axis=1)
for i in range(len(bow)):
result.rename(columns = {i+1:i}, inplace = True)
result
Input for recommendation system
Third step: Cosine similarity
Whenever we are performing some tasks involving natural language processing and want to estimate the similarity between texts, we use some pre-defined metrics that are famous for providing numerical evaluations for this purpose. These metrics include:
Euclidean Distance
Cosine similarity
Jaccard similarity
Pearson similarity
While all four of them can be used to evaluate a similarity index between text documents, we will be using cosine similarity for our task. Cosine similarity, in data analysis, measures the similarity between two vectors of an inner product space. It is often used to measure document similarity in text analysis.It measures the cosine of the angle between two vectors and determines a numerical value indicating the probability of those vectors being in the same direction. The code alongside the heatmap shown below visualizes the cosine similarity index for all the blogs.
from sklearn.metrics.pairwise import cosine_similarity
import seaborn as sns
#Calculating cosine similarity
df_name=df_name.convert_dtypes(str)
temp_df=df_name['Blog']
sim_df = pd.DataFrame(cosine_similarity(result, dense_output=True))
for i in range(len(name)):
sim_df.rename(columns = {i:temp_df[i]},index={i:temp_df[i]}, inplace = True)
ax = sns.heatmap(sim_df)
Recommendation System Heatmap Output
Fourth step: Evaluation
In the code below, our recommender system will extract the three most similar blogs for each blog using Pandas DataFrame.
Note: For each blog, the blog itself is also recommended because it was calculated to be the most similar blog, with the maximum cosine similarity index, 1.
Output for content-based recommendation System Python
Conclusion
This blog post covered a beginner’s method of building a recommendation system using python. While there are other methods to develop recommender systems, the first step is to outline the requirements of the task at hand. To learn more about this, experiment with the code and try to extract data from another web page or enroll in our Python for Data Science course and learn all the required concepts regarding Python fundamentals.
Learn the difference between supervised ML, unsupervised ML, and reinforcement learning. Test your knowledge of machine learning techniques with an interactive infographic.
The quiz below was made to help you test your knowledge of supervised ML, unsupervised ML, and reinforcement learning while understanding which machine learning techniques fall under these categories. Try it or even embed it into your webpage!
Supervised machine learning techniques
In supervised machine learning models, we give the model a dataset with the answers (labels) to learn how to predict the label(s) for other examples where the labels are unknown.
Reinforcement learning
Reinforcement learning, on the other hand, is not trained with the answer. Instead, an agent is either penalized or rewarded for interacting with the environment. It learns from previous attempts and tries to maximize the reward with each attempt.
Unsupervised machine learning techniques
Unsupervised machine learning algorithms find hidden structures between the attributes (features) when the given dataset does not include labels. This is different from supervised learning; in that, we don’t tell the model what it needs to learn.
You can use Microsoft Azure ML or Amazon ML to build your machine learning model, but what’s the difference between the two approaches?
The idea is that you can use Microsoft Azure ML or Amazon ML to build a machine-learning model, and then use our demo to input values for the prediction.
Each ML program provides an endpoint that you can use to access the model and run predictions. Our demos interface with that endpoint and provide a graphic user interface for making predictions.
So, what’s the difference between the machine learning demos?
First of all, the backend is different. But we’ll keep this brief.
The graphic below shows what types of models can be run through the demo.
The cruise ship represents the Titanic classification model generated from our Azure ML tutorial.
The iris represents any classification model, such as a model used to predict species from a set of measurements.
The complicated graph represents a regression model. Regression models are used to predict a number given a set of input numbers.
AWS machine learning caller
You can see that the Titanic model can link to both demos, but the classification (iris) model only links to our Amazon demo. The numerical dataset does not work with either of our demos.
The demos are currently limited to classification models only (because linear regression models work differently and requires a different backend).
MLaaS: User perspectives
From the user perspective, the Titanic Survival Predictor is built for a specific purpose. It interfaces with the exact Titanic classification model that we created for Azure and is included as part of our bootcamp. Users can change all the tuning parameters and make the model unique.
However, the input variables, or “schema” to be labeled the same way as the original model or it won’t work.
So, if you rename one of the columns, the demo will have an error. However, since we published the Azure model online, it’s pretty easy to copy the model and change some parameters.
To get your predictive model to work with our Titanic Survival Predictor demo, you’ll need the following information:
Name (used to generate your own url)
Post URL (or endpoint)
API key
The AWS Machine Learning Caller is not built for a specific dataset like Titanic. It will work with any logistic regression model built in Amazon Machine Learning. When you input your access keys and model id, our demo automatically pulls the schema from Amazon.
It does not require a specific schema like our Titanic Survival Predictor.
To get your predictive model to work with our AWS Machine Learning Caller demo, you’ll need the following information:
Access key
Secret access key
AWS Account Region
AWS ML Model ID
Why do two machine learning demos do similar things?
These are training tools for our 5-day bootcamp. We use Microsoft Azure to teach classification models. The software has tools for data cleaning and manipulation. The way that the tools are laid out is visual and easy to understand. It provides a clear organization of the processes: input data, clean data, build a model, evaluate the model, and deploy the model.
Microsoft Azure has been a great way to teach the model-building process.
We’ve recently added Amazon Machine Learning to our curriculum. The program is simpler, where all the processes described above are automated. Amazon ML walks users through the process.
However, it does provide slightly different evaluation metrics than Microsoft Azure, so we use it to teach regression and classification models as well.
Help us get better!
We are always looking for ways to incorporate new tools into our curriculum. If there is a tool that you think we ought to have, please let us know in the comments.






















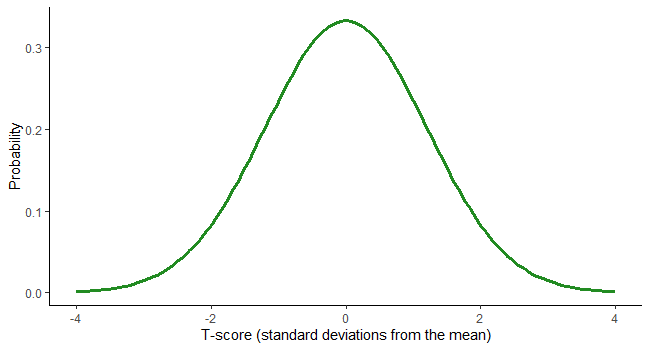

























































































 40. Some deep learnings just do not deep learn the way other deep learnings do.
40. Some deep learnings just do not deep learn the way other deep learnings do.













 55. One can never go wrong with a tweet.
55. One can never go wrong with a tweet.








 65. Our future looks very much like this.
65. Our future looks very much like this.








































