In the realm of statistics and machine learning, understanding various probability distributions is paramount. One such fundamental distribution is the Binomial Distribution.
This distribution is not only a cornerstone in probability theory but also plays a crucial role in various machine learning algorithms and applications.

In this blog, we will delve into the concept of binomial distribution, its mathematical formulation, and its significance in the field of machine learning.
What is Binomial Distribution?
The binomial distribution is a discrete probability distribution that describes the number of successes in a fixed number of independent and identically distributed Bernoulli trials.
A Bernoulli trial is a random experiment where there are only two possible outcomes:
- success (with probability ( p ))
- failure (with probability ( 1 – p ))
Mathematical Formulation
The probability of observing exactly k successes in n trials is given by the binomial probability formula:

Example 1: Tossing One Coin
Let’s start with a simple example of tossing a single coin.
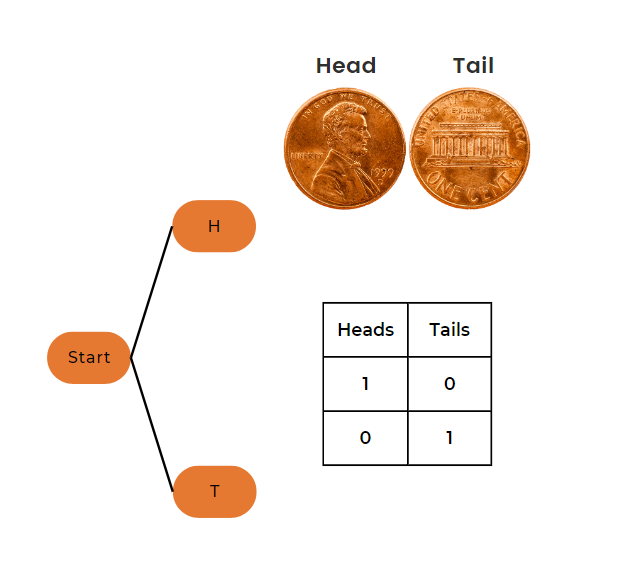
Parameters
- Number of trials (n) = 1
- Probability of heads (p) = 0.5
- Number of heads (k) = 1
Calculation
- Binomial coefficient
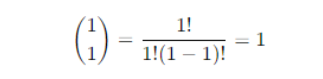
- Probability
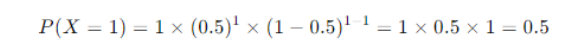
So, the probability of getting exactly one head in one toss of a coin is 0.5 or 50%.
Example 2: Tossing Two Coins
Now, let’s consider the case of tossing two coins.
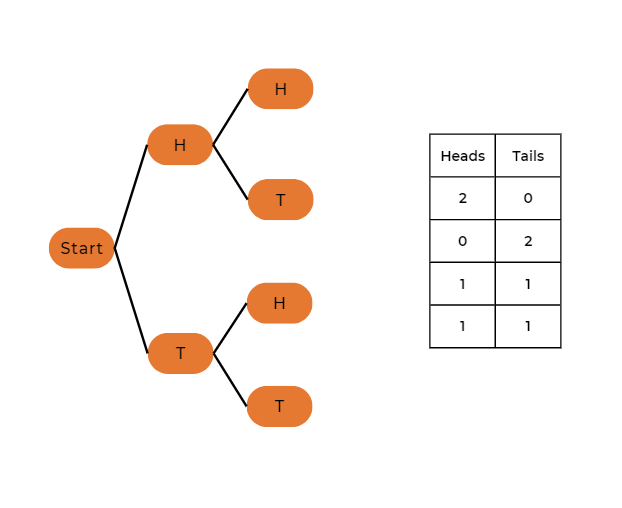
Parameters
- Number of trials (n) = 2
- Probability of heads (p) = 0.5
- Number of heads (k) = varies (0, 1, or 2)
Calculation for k = 0
- Binomial coefficient
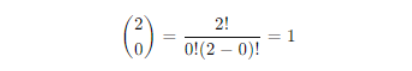
- Probability
P(X = 0) = 1 × (0.5)0 × (1 – 0.5)2 = 1 × 1 × 0.25 = 0.25
Calculation for k = 1
- Binomial coefficient
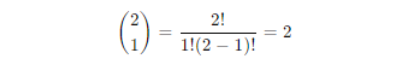
- Probability
P(X = 1) = 1 × (0.5)1 × (1 – 0.5)1 = 2 × 0.5 × 0.5 = 0.5
Calculation for k = 2
- Binomial coefficient
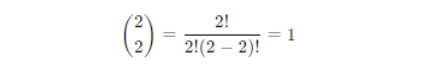
- Probability
P(X = 2) = 1 × (0.5)2 × (1 – 0.5)0 = 1 × 0.25 × 1 = 0.25
So, the probabilities for different numbers of heads in two-coin tosses are:
- P(X = 0) = 0.25 – no heads
- P(X = 1) = 0.5 – one head
- P(X = 2) = 0.25 – two heads

Detailed Example: Predicting Machine Failure
Let’s consider a more practical example involving predictive maintenance in an industrial setting. Suppose we have a machine that is known to fail with a probability of 0.05 during a daily checkup. We want to determine the probability of the machine failing exactly 3 times in 20 days.
Step-by-Step Calculation
1. Identify Parameters
- Number of trials (n) = 20 days
- Probability of success (p) = 0.05 – failure is considered a success in this context
- Number of successes (k) = 3 failures
2. Apply the Formula
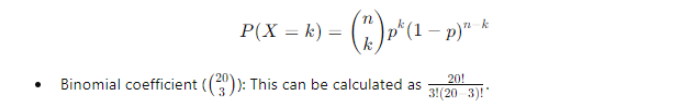
3. Compute Binomial Coefficient
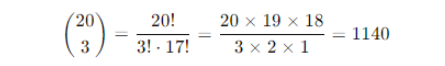
4. Calculate Probability
- Plugging the values into the binomial formula
![]()
- Substitute the values
P(X = 3) = 1140 × (0.05)3 × (0.95)17
- Calculate (0.05)3
(0.05)3 = 0.000125
- Calculate (0.95)17
(0.95)17 ≈ 0.411
5. Multiply all Components Together
P(X = 3) = 1140 × 0.000125 × 0.411 ≈ 0.0585
Therefore, the probability of the machine failing exactly 3 times in 20 days is approximately 0.0585 or 5.85%.
Role of Binomial Distribution in Machine Learning
The binomial distribution is integral to several aspects of machine learning, providing a foundation for understanding and modeling binary events, hypothesis testing, and beyond.
Let’s explore how it intersects with various machine-learning concepts and techniques.
Binary Classification
In binary classification problems, where the outcomes are often categorized as success or failure, the binomial distribution forms the underlying probabilistic model. For instance, if we are predicting whether an email is spam or not, each email can be thought of as a Bernoulli trial.
Algorithms like Logistic Regression and Support Vector Machines (SVM) are particularly designed to handle these binary outcomes.
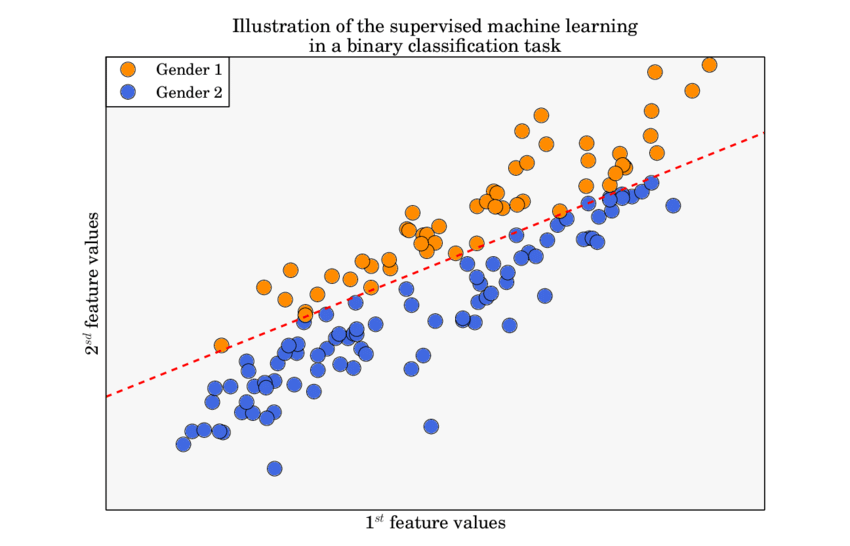
Understanding the binomial distribution helps in correctly interpreting the results of these classifiers. The performance metrics such as accuracy, precision, recall, and F1-score ultimately derive from the binomial probability model.
This understanding ensures that we can make informed decisions about model improvements and performance evaluation.
Hypothesis Testing
Statistical hypothesis testing, essential in validating machine learning models, often employs the binomial distribution to ascertain the significance of observed outcomes.
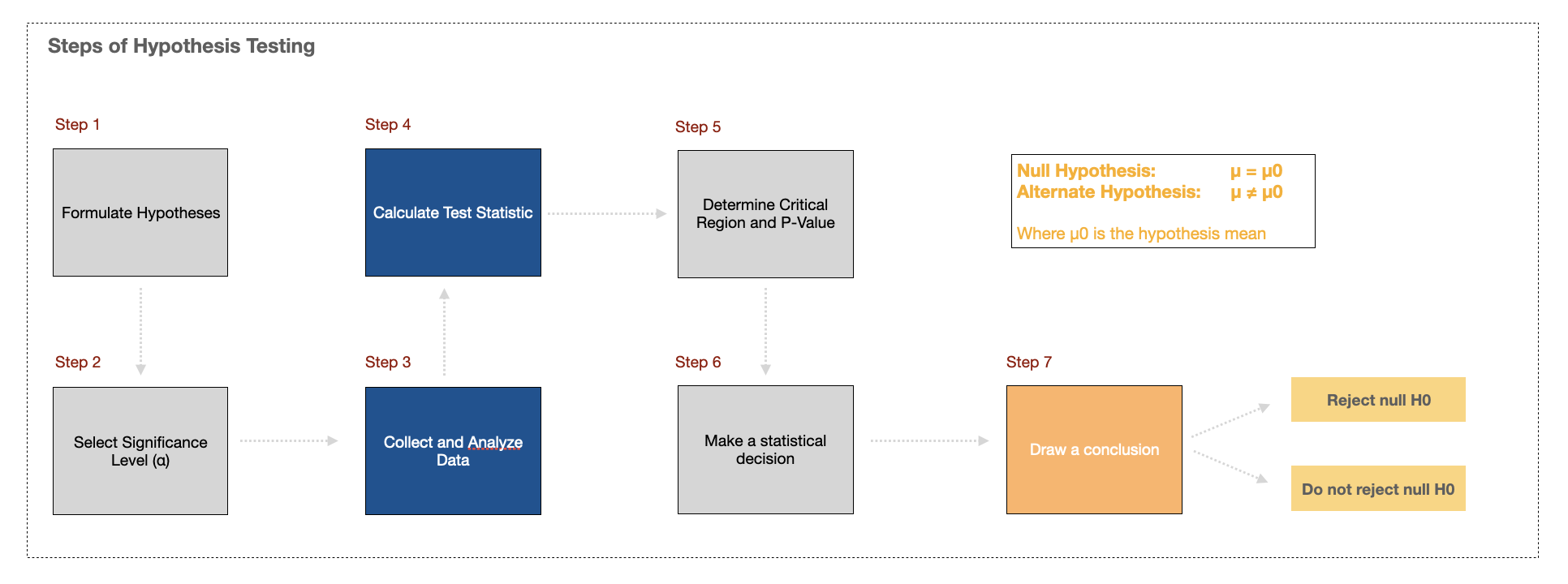
For instance, in A/B testing, which is widely used in machine learning for comparing model performance or feature impact, the binomial distribution helps in calculating p-values and confidence intervals.
You can also explore an ethical way of A/B testing
Consider an example where we want to determine if a new feature in a recommendation system improves user click-through rates. By modeling the click events as a binomial distribution, we can perform a hypothesis test to evaluate if the observed improvement is statistically significant or just due to random chance.
Generative Models
Generative models such as Naive Bayes leverage binomial distributions to model the probability of observing certain classes given specific features. This is particularly useful when dealing with binary or categorical data.
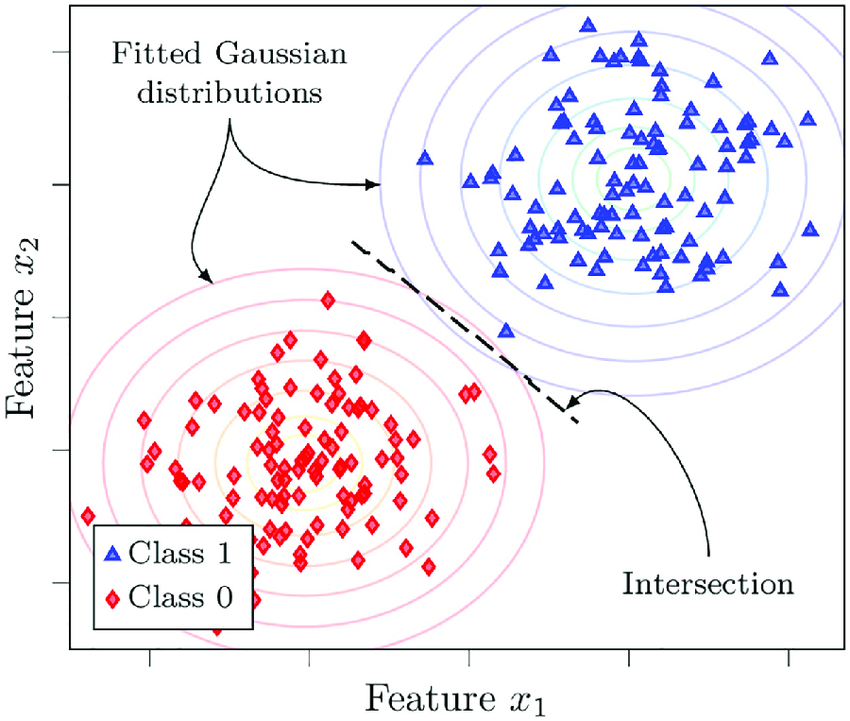
In text classification tasks, for example, the presence or absence of certain words (features) in a document can be modeled using binomial distributions to predict the document’s category (class).
By understanding the binomial distribution, we can better grasp how these models work under the hood, leading to more effective feature engineering and model tuning.
Also explore 7 different types of statistical distributions
Monte Carlo Simulations
Monte Carlo simulations, which are used in various machine learning applications for uncertainty estimation and decision-making, often rely on binomial distributions to model and simulate binary events over numerous trials.
These simulations can help in understanding the variability and uncertainty in model predictions, providing a robust framework for decision-making in the presence of randomness.
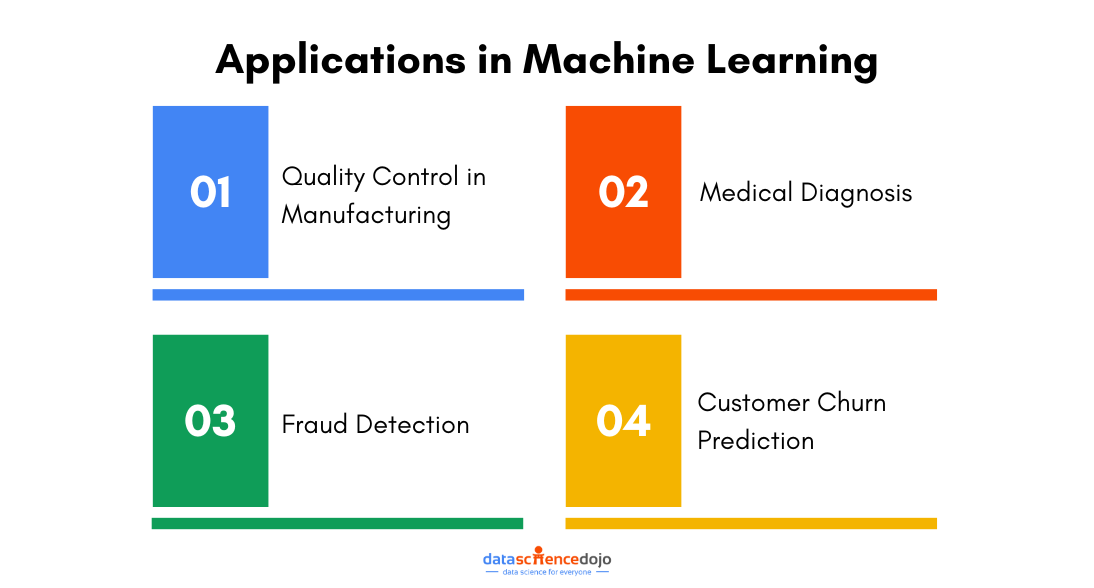
Practical Applications in Machine Learning
Quality Control in Manufacturing
In manufacturing, maintaining high-quality standards is crucial. Machine learning models are often deployed to predict the likelihood of defects in products.
Here, the binomial distribution is used to model the number of defective items in a batch. By understanding the distribution, we can set appropriate thresholds and confidence intervals to decide when to take corrective actions.
Explore Locust – a tool for quality assurance
Medical Diagnosis
In medical diagnosis, machine learning models assist in predicting the presence or absence of a disease based on patient data. The binomial distribution provides a framework for understanding the probabilities of correct and incorrect diagnoses.
This is critical for evaluating the performance of diagnostic models and ensuring they meet the necessary accuracy and reliability standards.
Fraud Detection
Fraud detection systems in finance and e-commerce rely heavily on binary classification models to distinguish between legitimate and fraudulent transactions. The binomial distribution aids in modeling the occurrence of fraud and helps in setting detection thresholds that balance false positives and false negatives effectively.
Learn how cybersecurity has revolutionized with the use of data science
Customer Churn Prediction
Predicting customer churn is vital for businesses to retain their customer base. Machine learning models predict whether a customer will leave (churn) or stay (retain). The binomial distribution helps in understanding the probabilities of churn events and in setting up retention strategies based on these probabilities.

Why Use Binomial Distribution?
Binomial distribution is a fundamental concept that finds extensive application in machine learning. From binary classification to hypothesis testing and generative models, understanding and leveraging this distribution can significantly enhance the performance and interpretability of machine learning models.
By mastering the binomial distribution, you equip yourself with a powerful tool for tackling a wide range of problems in statistics and machine learning.
Feel free to dive deeper into this topic, experiment with different values, and explore the fascinating world of probability distributions in machine learning!