In recent years, the landscape of artificial intelligence has been transformed by the development of large language models like GPT-3 and BERT, renowned for their impressive capabilities and wide-ranging applications.
However, alongside these giants, a new category of AI tools is making waves—the small language models (SLMs). These models, such as LLaMA 3, Phi 3, Mistral 7B, and Gemma, offer a potent combination of advanced AI capabilities with significantly reduced computational demands.
Why are Small Language Models Needed?
This shift towards smaller, more efficient models is driven by the need for accessibility, cost-effectiveness, and the democratization of AI technology.
Small language models require less hardware, lower energy consumption, and offer faster deployment, making them ideal for startups, academic researchers, and businesses that do not possess the immense resources often associated with big tech companies.
Moreover, their size does not merely signify a reduction in scale but also an increase in adaptability and ease of integration across various platforms and applications.
How Small Language Models Excel with Fewer Parameters?
Several factors explain why smaller language models can perform effectively with fewer parameters. Primarily, advanced training techniques play a crucial role. Methods like transfer learning enable these models to build on pre-existing knowledge bases, enhancing their adaptability and efficiency for specialized tasks.
For example, knowledge distillation from large language models to small language models can achieve comparable performance while significantly reducing the need for computational power.
Moreover, smaller models often focus on niche applications. By concentrating their training on targeted datasets, these models are custom-built for specific functions or industries, enhancing their effectiveness in those particular contexts.
For instance, a small language model trained exclusively on medical data could potentially surpass a general-purpose large model in understanding medical jargon and delivering accurate diagnoses.
However, it’s important to note that the success of a small language model depends heavily on its training regimen, fine-tuning, and the specific tasks it is designed to perform. Therefore, while small models may excel in certain areas, they might not always be the optimal choice for every situation.
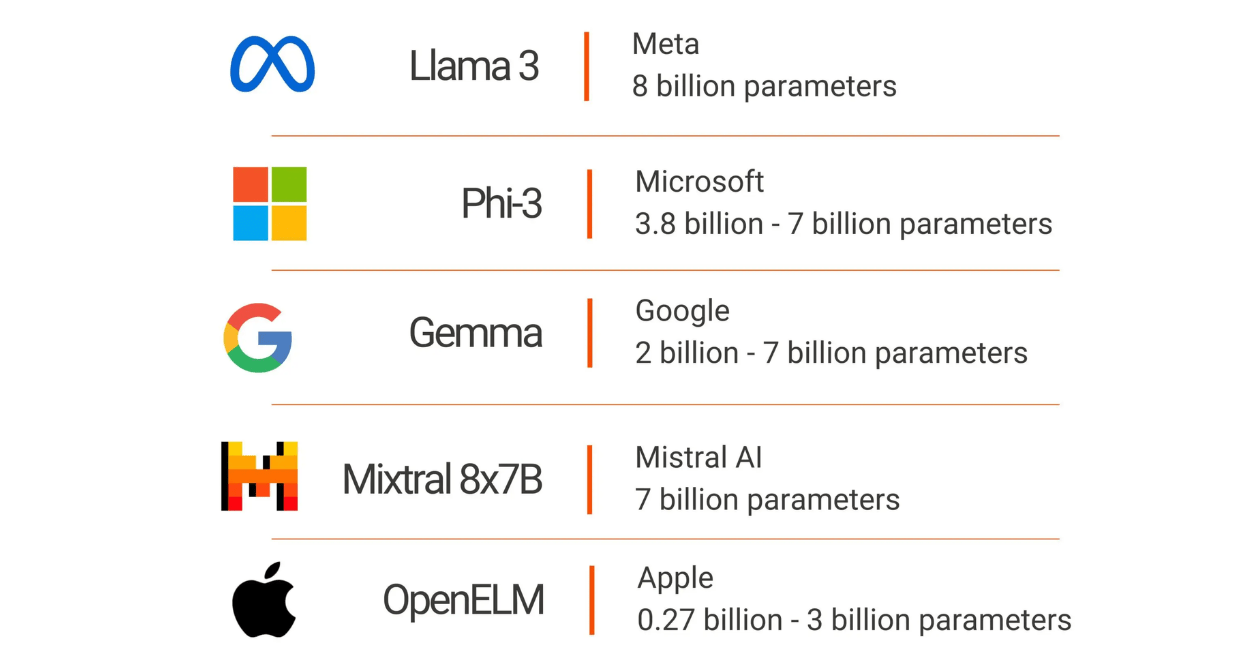
Best Small Language Models in 2024
Leading Small Language Models (SLMs)
1. Llama 3 by Meta
LLaMA 3 is an open-source language model developed by Meta. It’s part of Meta’s broader strategy to empower more extensive and responsible AI usage by providing the community with tools that are both powerful and adaptable.
This model builds upon the success of its predecessors by incorporating advanced training methods and architecture optimizations that enhance its performance across various tasks such as translation, dialogue generation, and complex reasoning.
Performance and Innovation
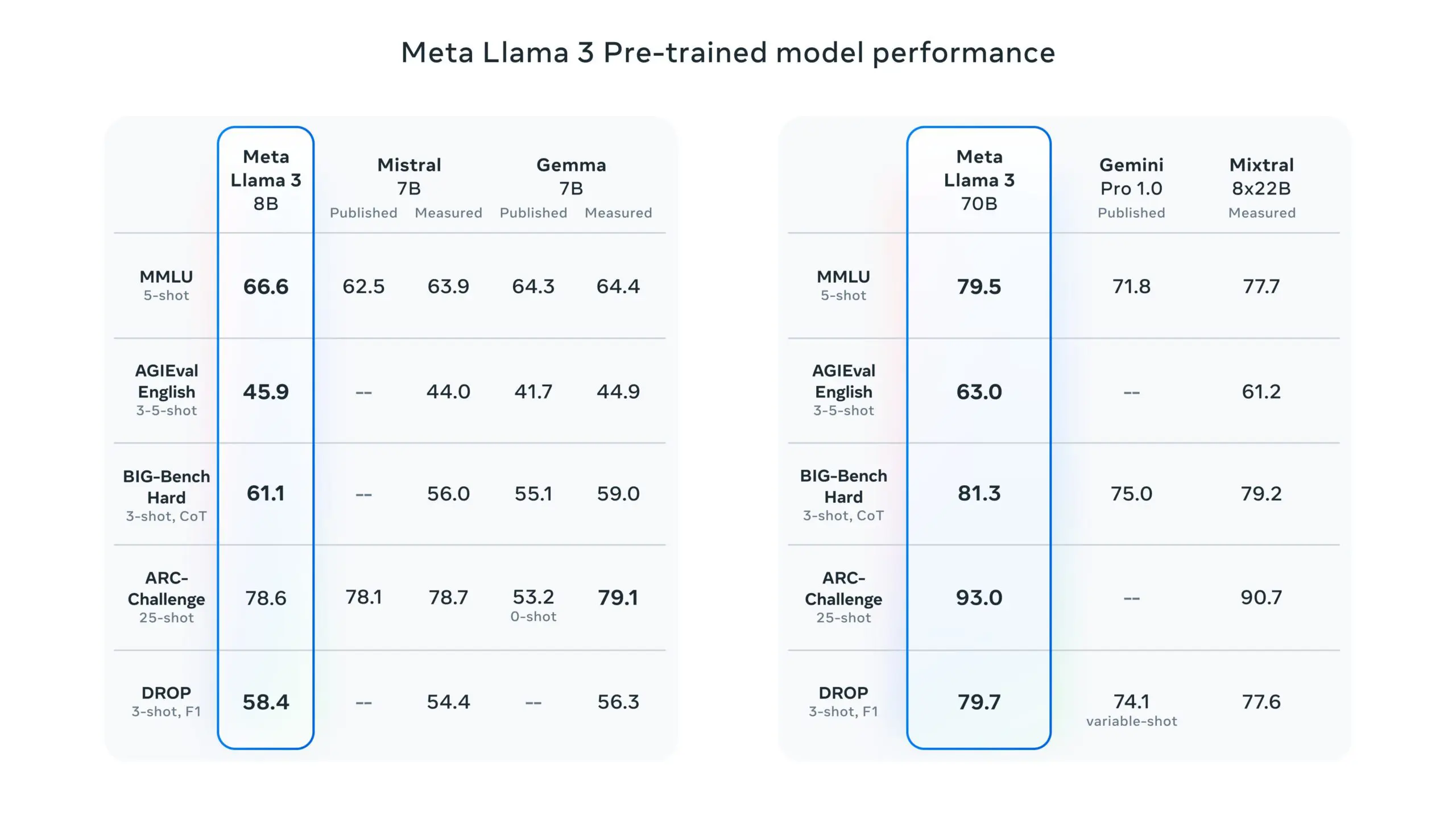
Meta’s LLaMA 3 has been trained on significantly larger datasets compared to earlier versions, utilizing custom-built GPU clusters that enable it to process vast amounts of data efficiently.
This extensive training has equipped LLaMA 3 with an improved understanding of language nuances and the ability to handle multi-step reasoning tasks more effectively. The model is particularly noted for its enhanced capabilities in generating more aligned and diverse responses, making it a robust tool for developers aiming to create sophisticated AI-driven applications.
Llama 3 pre-trained model performance – Source: Meta
Why LLaMA 3 Matters
The significance of LLaMA 3 lies in its accessibility and versatility. Being open-source, it democratizes access to state-of-the-art AI technology, allowing a broader range of users to experiment and develop applications.
This model is crucial for promoting innovation in AI, providing a platform that supports both foundational and advanced AI research. By offering an instruction-tuned version of the model, Meta ensures that developers can fine-tune LLaMA 3 to specific applications, enhancing both performance and relevance to particular domains.
Phi-3 is a pioneering series of SLMs developed by Microsoft, emphasizing high capability and cost-efficiency. As part of Microsoft’s ongoing commitment to accessible AI, Phi-3 models are designed to provide powerful AI solutions that are not only advanced but also more affordable and efficient for a wide range of applications.
These models are part of an open AI initiative, meaning they are accessible to the public and can be integrated and deployed in various environments, from cloud-based platforms like Microsoft Azure AI Studio to local setups on personal computing devices.
Performance and Significance
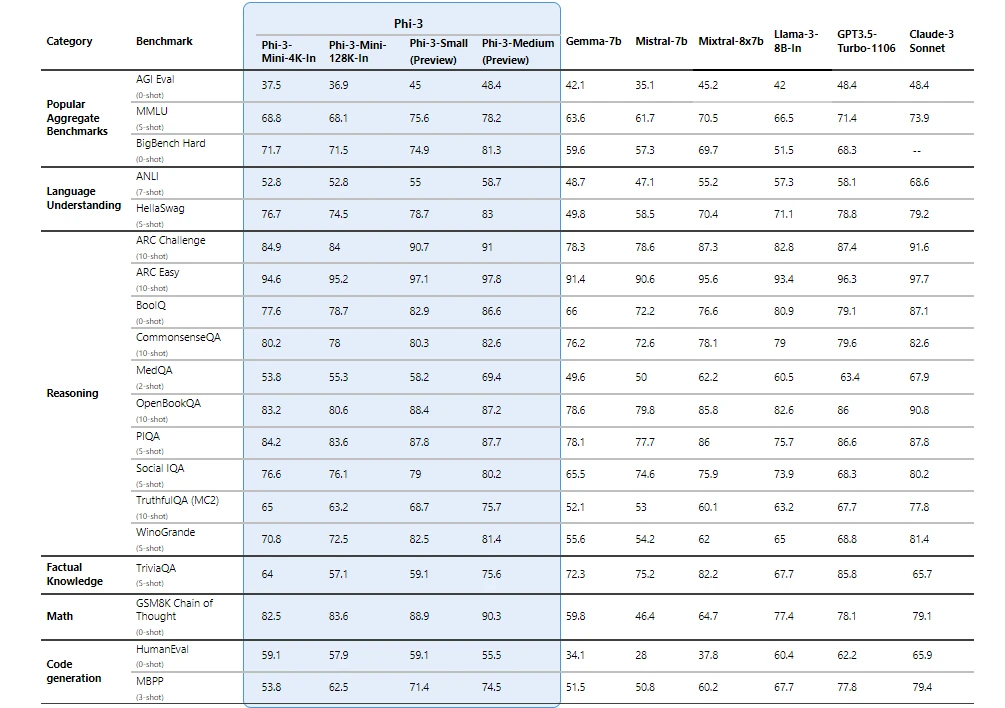
The Phi 3 models stand out for their exceptional performance, surpassing both similar and larger-sized models in tasks involving language processing, coding, and mathematical reasoning.
Notably, the Phi-3-mini, a 3.8 billion parameter model within this family, is available in versions that handle up to 128,000 tokens of context—setting a new standard for flexibility in processing extensive text data with minimal quality compromise.
Microsoft has optimized Phi 3 for diverse computing environments, supporting deployment across GPUs, CPUs, and mobile platforms, which is a testament to its versatility.
Additionally, these models integrate seamlessly with other Microsoft technologies, such as ONNX Runtime for performance optimization and Windows DirectML for broad compatibility across Windows devices.
Phi-3 family comparison with Gemma 7b, Mistral 7b, Mixtral 8x7b, Llama 3 – Source: Microsoft
Why Does Phi 3 Matter?
The development of Phi 3 reflects a significant advancement in AI safety and ethical AI deployment. Microsoft has aligned the development of these models with its Responsible AI Standard, ensuring that they adhere to principles of fairness, transparency, and security, making them not just powerful but also trustworthy tools for developers.
3. Mixtral 8x7B by Mistral AI
Mixtral, developed by Mistral AI, is a groundbreaking model known as a Sparse Mixture of Experts (SMoE). It represents a significant shift in AI model architecture by focusing on both performance efficiency and open accessibility.
Mistral AI, known for its foundation in open technology, has designed Mixtral to be a decoder-only model, where a router network selectively engages different groups of parameters, or “experts,” to process data.
This approach not only makes Mixtral highly efficient but also adaptable to a variety of tasks without requiring the computational power typically associated with large models.
Mixtral excels in processing large contexts up to 32k tokens and supports multiple languages including English, French, Italian, German, and Spanish.
It has demonstrated strong capabilities in code generation and can be fine-tuned to follow instructions precisely, achieving high scores on benchmarks like the MT-Bench.
What sets Mixtral apart is its efficiency—despite having a total parameter count of 46.7 billion, it effectively utilizes only about 12.9 billion per token, aligning it with much smaller models in terms of computational cost and speed.
Why Does Mixtral Matter?
The significance of Mixtral lies in its open-source nature and its licensing under Apache 2.0, which encourages widespread use and adaptation by the developer community.
This model is not only a technological innovation but also a strategic move to foster more collaborative and transparent AI development. By making high-performance AI more accessible and less resource-intensive, Mixtral is paving the way for broader, more equitable use of advanced AI technologies.
Mixtral’s architecture represents a step towards more sustainable AI practices by reducing the energy and computational costs typically associated with large models. This makes it not only a powerful tool for developers but also a more environmentally conscious choice in the AI landscape.
4. Gemma by Google
Gemma is a new generation of open models introduced by Google, designed with the core philosophy of responsible AI development. Developed by Google DeepMind along with other teams at Google, Gemma leverages the foundational research and technology that also gave rise to the Gemini models.
Technical Details and Availability
Gemma models are structured to be lightweight and state-of-the-art, ensuring they are accessible and functional across various computing environments—from mobile devices to cloud-based systems.
Google has released two main versions of Gemma: a 2 billion parameter model and a 7 billion parameter model. Each of these comes in both pre-trained and instruction-tuned variants to cater to different developer needs and application scenarios.
Gemma models are freely available and supported by tools that encourage innovation, collaboration, and responsible usage.
Why Does Gemma Matter?
Gemma models are significant not just for their technical robustness but for their role in democratizing AI technology. By providing state-of-the-art capabilities in an open model format, Google facilitates a broader adoption and innovation in AI, allowing developers and researchers worldwide to build advanced applications without the high costs typically associated with large models.
Moreover, Gemma models are designed to be adaptable, allowing users to tune them for specialized tasks, which can lead to more efficient and targeted AI solutions
5. OpenELM Family by Apple
OpenELM is a family of small language models developed by Apple. OpenELM models are particularly appealing for applications where resource efficiency is critical. OpenELM is open-source, offering transparency and the opportunity for the wider research community to modify and adapt the models as needed.
Performance and Capabilities
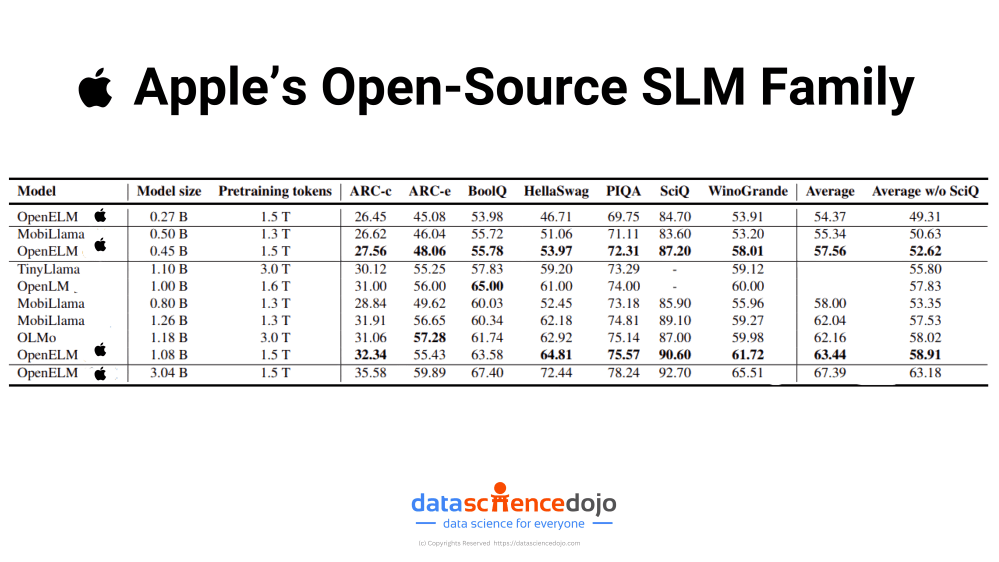
Despite their smaller size and open-source nature, it’s important to note that OpenELM models do not necessarily match the top-tier performance of some larger, more closed-source models. They achieve moderate accuracy levels across various benchmarks but may lag behind in more complex or nuanced tasks. For example, while OpenELM shows improved performance compared to similar models like OLMo in terms of accuracy, the improvement is moderate.
Why Does OpenELM Matter?
OpenELM represents a strategic move by Apple to integrate state-of-the-art generative AI directly into its hardware ecosystem, including laptops and smartphones.
By embedding these efficient models into devices, Apple can potentially offer enhanced on-device AI capabilities without the need to constantly connect to the cloud.
Apple’s Open-Source SLM family
This not only improves functionality in areas with poor connectivity but also aligns with increasing consumer demands for privacy and data security, as processing data locally minimizes the risk of exposure over networks.
Furthermore, embedding OpenELM into Apple’s products could give the company a significant competitive advantage by making their devices smarter and more capable of handling complex AI tasks independently of the cloud.
This can transform user experiences, offering more responsive and personalized AI interactions directly on their devices. The move could set a new standard for privacy in AI, appealing to privacy-conscious consumers and potentially reshaping consumer expectations in the tech industry.
The Future of Small Language Models
As we dive deeper into the capabilities and strategic implementations of small language models, it’s clear that the evolution of AI is leaning heavily towards efficiency and integration. Companies like Apple, Microsoft, and Google are pioneering this shift by embedding advanced AI directly into everyday devices, enhancing user experience while upholding stringent privacy standards.
This approach not only meets the growing consumer demand for powerful, yet private technology solutions but also sets a new paradigm in the competitive landscape of tech companies.
Welcome to the world of open source large language models (LLMs), where the future of technology meets community spirit. By breaking down the barriers of proprietary systems, open language models invite developers, researchers, and enthusiasts from around the globe to contribute to, modify, and improve upon the foundational models.
This collaborative spirit not only accelerates advancements in the field but also ensures that the benefits of AI technology are accessible to a broader audience. As we navigate through the intricacies of open-source language models, we’ll uncover the challenges and opportunities that come with adopting an open-source model, the ecosystems that support these endeavors, and the real-world applications that are transforming industries.
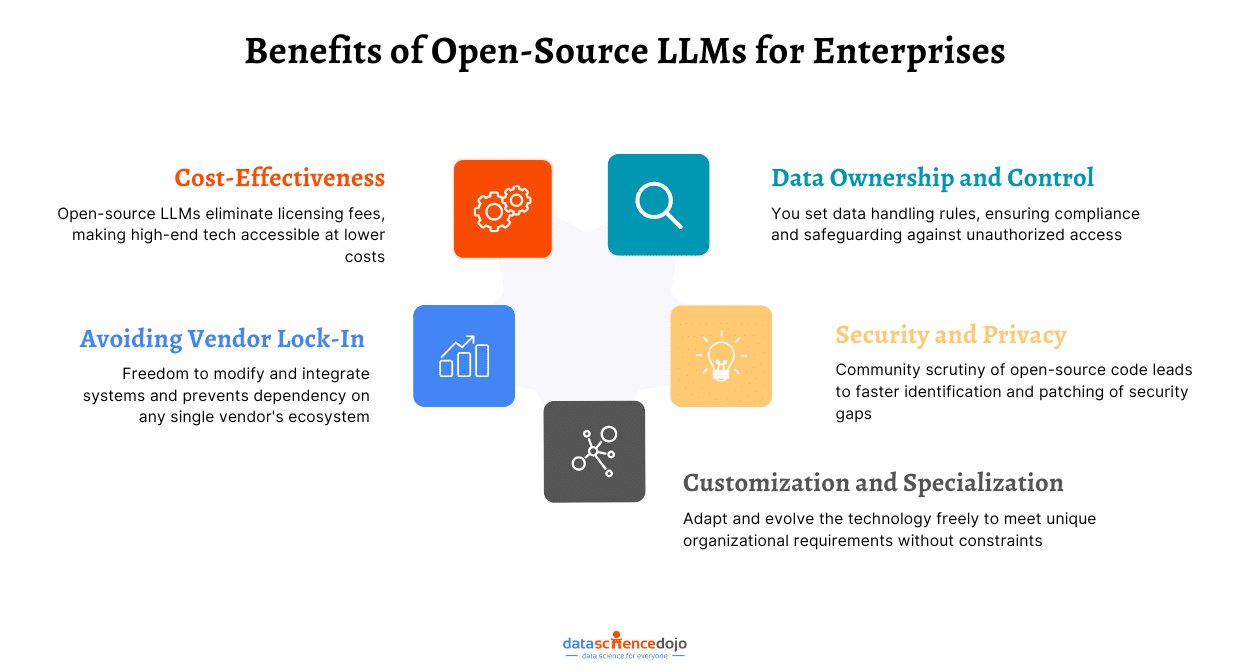
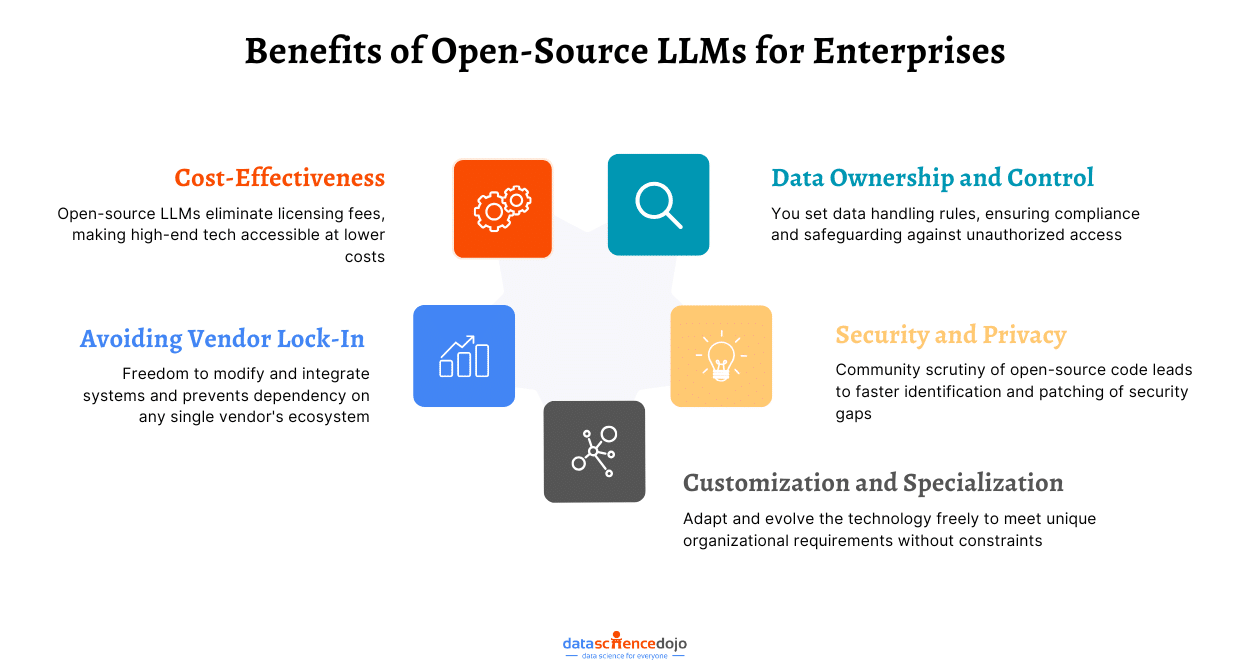
Benefits of Open Source LLMs
As soon as ChatGPT was revealed, OpenAI’s GPT models quickly rose to prominence. However, businesses began to recognize the high costs associated with closed-source models, questioning the value of investing in large models that lacked specific knowledge about their operations.
In response, many opted for smaller open LLMs, utilizing Retriever-And-Generator (RAG) pipelines to integrate their data, achieving comparable or even superior efficiency.
There are several advantages to closed-source large language models worth considering.
Cost-Effectiveness:
Open-source Large Language Models (LLMs) present a cost-effective alternative to their proprietary counterparts, offering organizations a financially viable means to harness AI capabilities.
No licensing fees are required, significantly lowering initial and ongoing expenses.
Organizations can freely deploy these models, leading to direct cost reductions.
Open large language models allow for specific customization, enhancing efficiency without the need for vendor-specific customization services.
Flexibility:
Companies are increasingly preferring the flexibility to switch between open and proprietary (closed) models to mitigate risks associated with relying solely on one type of model.
This flexibility is crucial because a model provider’s unexpected update or failure to keep the model current can negatively affect a company’s operations and customer experience.
Companies often lean towards open language models when they want more control over their data and the ability to fine-tune models for specific tasks using their data, making the model more effective for their unique needs.
Data Ownership and Control:
Companies leveraging open-source language models gain significant control and ownership over their data, enhancing security and compliance through various mechanisms. Here’s a concise overview of the benefits and controls offered by using open large language models:
Data hosting control:
Choice of data hosting on-premises or with trusted cloud providers.
Crucial for protecting sensitive data and ensuring regulatory compliance.
Internal data processing:
Avoids sending sensitive data to external servers.
Reduces the risk of data breaches and enhances privacy.
The open-source nature allows for code and process audits.
Ensures alignment with internal and external compliance standards.
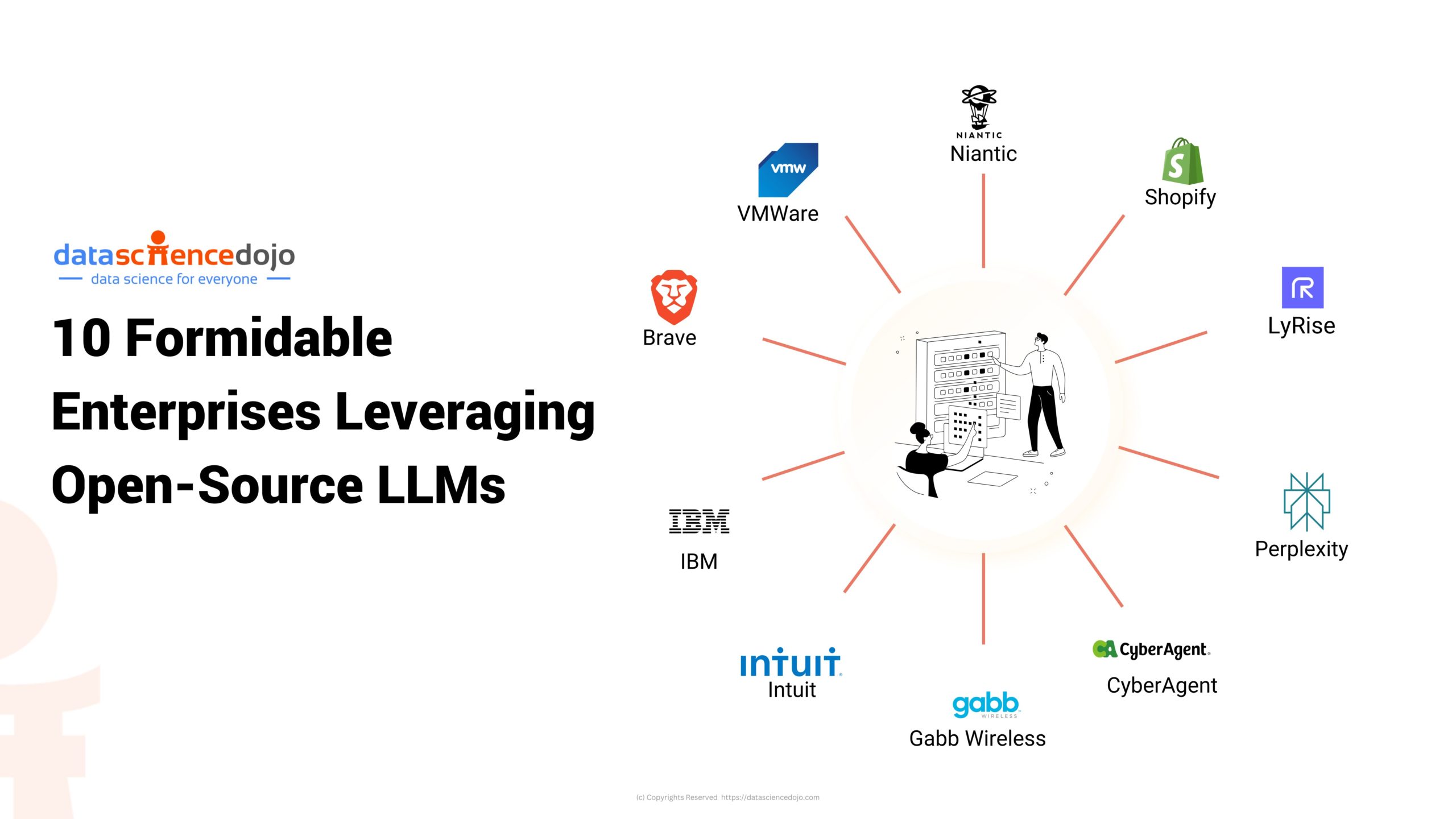
Enterprises Using Open Source LLMs
Here are examples of how different companies around the globe have started leveraging open language models.
VMWare
VMWare, a noted enterprise in the field of cloud computing and digitalization, has deployed an open language model called the HuggingFace StarCoder. Their motivation for using this model is to enhance the productivity of their developers by assisting them in generating code.
This strategic move suggests VMware’s priority for internal code security and the desire to host the model on their infrastructure. It contrasts with using an external system like Microsoft-owned GitHub’s Copilot, possibly due to sensitivities around their codebase and not wanting to give Microsoft access to it
Brave
Brave, the security-focused web browser company, has deployed an open-source large language model called Mixtral 8x7B from Mistral AI for their conversational assistant named Leo, which aims to differentiate the company by emphasizing privacy.
Previously, Leo utilized the Llama 2 model, but Brave has since updated the assistant to default to the Mixtral 8x7B model. This move illustrates the company’s commitment to integrating open LLM technologies to maintain user privacy and enhance their browser’s functionality.
Gab Wireless
Gab Wireless, the company focused on child-friendly mobile phone services, is using a suite of open-source models from Hugging Face to add a security layer to its messaging system. The aim is to screen the messages sent and received by children to ensure that no inappropriate content is involved in their communications.
This usage of open language models helps Gab Wireless ensure safety and security in children’s interactions, particularly with individuals they do not know.
IBM
IBM actively incorporates open models across various operational areas.
AskHR application: Utilizes IBM’s Watson Orchestration and open language models for efficient HR query resolution.
Consulting advantage tool: Features a “Library of Assistants” powered by IBM’s wasonx platform and open-source large language models, aiding consultants.
Marketing initiatives: Employs an LLM-driven application, integrated with Adobe Firefly, for innovative content and image generation in marketing.
Intuit
Intuit, the company behind TurboTax, QuickBooks, and Mailchimp, has developed its language models incorporating open LLMs into the mix. These models are key components of Intuit Assist, a feature designed to help users with customer support, analysis, and completing various tasks.
The company’s approach to building these large language models involves using open-source frameworks, augmented with Intuit’s unique, proprietary data.
Shopify
Shopify has employed publically available language models in the form of Shopify Sidekick, an AI-powered tool that utilizes Llama 2. This tool assists small business owners with automating tasks related to managing their commerce websites.
It can generate product descriptions, respond to customer inquiries, and create marketing content, thereby helping merchants save time and streamline their operations.
LyRise
LyRise, a U.S.-based talent-matching startup, utilizes open language models by employing a chatbot built on Llama, which operates similarly to a human recruiter. This chatbot assists businesses in finding and hiring top AI and data talent, drawing from a pool of high-quality profiles in Africa across various industries.
Niantic
Niantic, known for creating Pokémon Go, has integrated open-source large language models into its game through the new feature called Peridot. This feature uses Llama 2 to generate environment-specific reactions and animations for the pet characters, enhancing the gaming experience by making character interactions more dynamic and context-aware.
Perplexity
Here’s how Perplexity leverages open source LLMs
Response generation process:
When a user poses a question, Perplexity’s engine executes approximately six steps to craft a response. This process involves the use of multiple language models, showcasing the company’s commitment to delivering comprehensive and accurate answers.
In a crucial phase of response preparation, specifically the second-to-last step, Perplexity employs its own specially developed open-source language models. These models, which are enhancements of existing frameworks like Mistral and Llama, are tailored to succinctly summarize content relevant to the user’s inquiry.
The fine-tuning of these models is conducted on AWS Bedrock, emphasizing the choice of open models for greater customization and control. This strategy underlines Perplexity’s dedication to refining its technology to produce superior outcomes.
Partnership and API integration:
Expanding its technological reach, Perplexity has entered into a partnership with Rabbit to incorporate its open-source large language models into the R1, a compact AI device. This collaboration facilitated through an API, extends the application of Perplexity’s innovative models, marking a significant stride in practical AI deployment.
CyberAgent
CyberAgent, a Japanese digital advertising firm, leverages open language models with its OpenCALM initiative, a customizable Japanese language model enhancing its AI-driven advertising services like Kiwami Prediction AI. By adopting an open-source approach, CyberAgent aims to encourage collaborative AI development and gain external insights, fostering AI advancements in Japan.
Furthermore, a partnership with Dell Technologies has upgraded their server and GPU capabilities, significantly boosting model performance (up to 5.14 times faster), thereby streamlining service updates and enhancements for greater efficiency and cost-effectiveness.
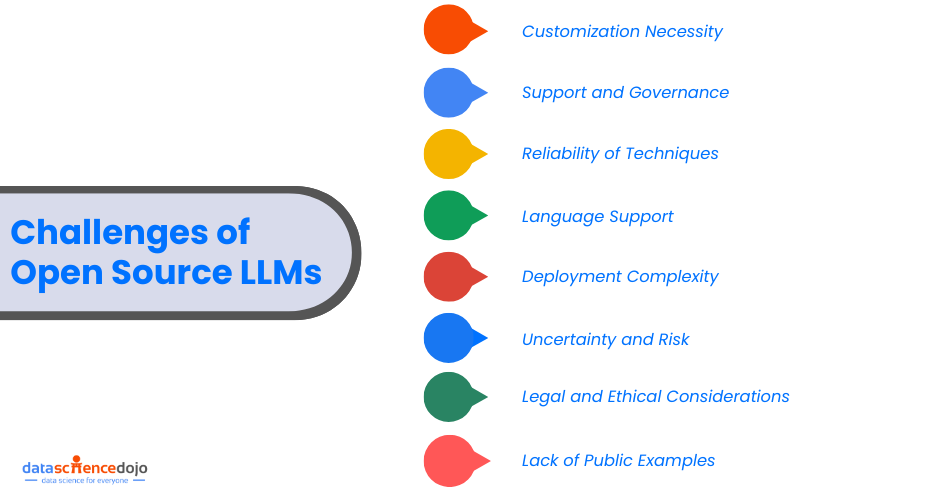
Challenges of Open Source LLMs
While open LLMs offer numerous benefits, there are substantial challenges that can plague the users.
Customization Necessity:
Open language models often come as general-purpose models, necessitating significant customization to align with an enterprise’s unique workflows and operational processes. This customization is crucial for the models to deliver value, requiring enterprises to invest in development resources to adapt these models to their specific needs.
Support and Governance:
Unlike proprietary models that offer dedicated support and clear governance structures, publically available large language models present challenges in managing support and ensuring proper governance. Enterprises must navigate these challenges by either developing internal expertise or engaging with the open-source community for support, which can vary in responsiveness and expertise.
Reliability of Techniques:
Techniques like Retrieval-Augmented Generation aim to enhance language models by incorporating proprietary data. However, these techniques are not foolproof and can sometimes introduce inaccuracies or inconsistencies, posing challenges in ensuring the reliability of the model outputs.
Language Support:
While proprietary models like GPT are known for their robust performance across various languages, open-source large language models may exhibit variable performance levels. This inconsistency can affect enterprises aiming to deploy language models in multilingual environments, necessitating additional effort to ensure adequate language support.
Deployment Complexity:
Deploying publically available language models, especially at scale, involves complex technical challenges. These range from infrastructure considerations to optimizing model performance, requiring significant technical expertise and resources to overcome.
Uncertainty and Risk:
Relying solely on one type of model, whether open or closed source, introduces risks such as the potential for unexpected updates by the provider that could affect model behavior or compliance with regulatory standards.
Legal and Ethical Considerations:
Deploying LLMs entails navigating legal and ethical considerations, from ensuring compliance with data protection regulations to addressing the potential impact of AI on customer experiences. Enterprises must consider these factors to avoid legal repercussions and maintain trust with their users.
The scarcity of publicly available case studies on the deployment of publically available LLMs in enterprise settings makes it challenging for organizations to gauge the effectiveness and potential return on investment of these models in similar contexts.
Overall, while there are significant potential benefits to using publically available language models in enterprise settings, including cost savings and the flexibility to fine-tune models, addressing these challenges is critical for successful deployment
Open Source LLMs: Driving Flexibility and Innovation
In conclusion, open-source language models represent a pivotal shift towards more accessible, customizable, and cost-effective AI solutions for enterprises. They offer a unique blend of benefits, including significant cost savings, enhanced data control, and the ability to tailor AI tools to specific business needs, while also presenting challenges such as the need for customization and navigating support complexities.
Through the collaborative efforts of the global open-source community and the innovative use of these models across various industries, enterprises are finding new ways to leverage AI for growth and efficiency.
However, success in this endeavor requires a strategic approach to overcome inherent challenges, ensuring that businesses can fully harness the potential of publically available LLMs to drive innovation and maintain a competitive edge in the fast-evolving digital landscape.
The race of big tech and startups to create the top language model has us eager to see how things change.
Different companies are training new models to achieve better accuracy, enhanced understanding of context, and more nuanced generation capabilities, pushing the boundaries of what AI can achieve in terms of natural language understanding and generation.
A standout approach in this field is employed by Mistral AI through its development of the Mixtral of Experts model.
Distinctive for its use of the Sparse Mixture of Experts (SMoE) technique, Mixtral amalgamates the expertise of various specialized models. Each of these models excels in different areas of data processing, enabling Mixtral to navigate the complexities of language with notable precision.
This article aims to provide an in-depth examination of Mixtral, including its operational framework, unique attributes, and performance metrics. We will explore how Mixtral differentiates itself from other models in the market and the advantages it offers.
How Does Mixtral of Experts Work?
The Mixtral of Experts’ 8x7B model is a smart tool that’s built to be really good at a bunch of different tasks. It does this by not using all its tools at once, but just a few at a time for each piece of information it looks at.
Mixtral AI Framework – Source: Mistral AI
Think of it like a toolbox where, out of 8 tools, it picks the best 2 for the job at hand. Each layer of this model has these 8 special tools or “experts,” and it chooses which ones to use based on what it’s working on. This way, it can be really efficient and do its job well without needing to use everything it has all at once.
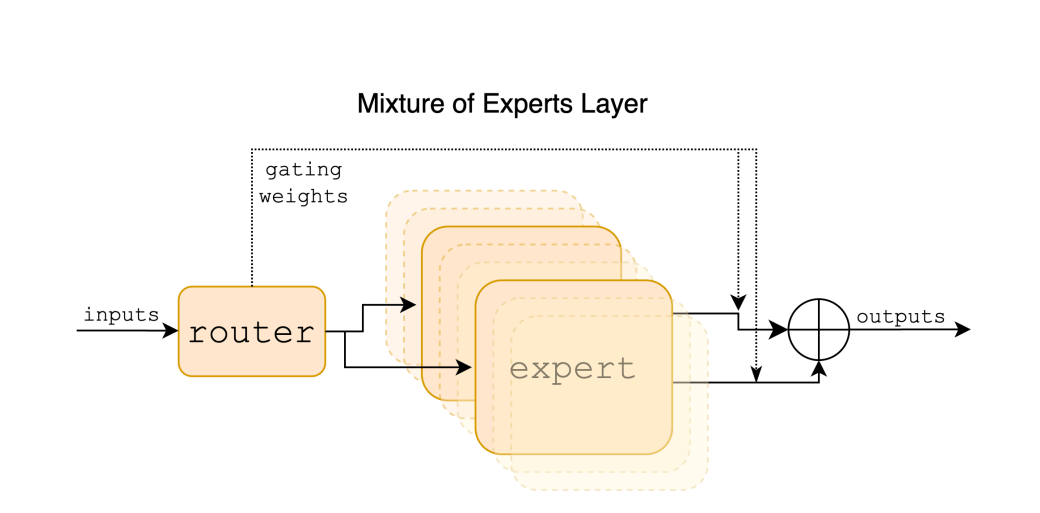
The process from the input through the router to the expert and the resulting output works as follows:
Input: A given input vector, representing a token from a sequence, enters the model. Each token is processed individually by going through the layers of the model. The input is part of a larger context, which can be a span of up to 32k tokens. Read how embeddings work here.
Router: After the initial input, the router within the Mixture of Experts layer determines which experts to engage for processing the token. Specifically, the router selects 2 out of the 8 available experts based on the token’s characteristics. This selection is done using a gating network that assigns weights to the experts, guiding which experts are to be used.
Experts: Once the experts are selected by the router, the input token is processed by these experts. Each expert consists of a standard feedforward block as found in a transformer architecture. The outputs of the two chosen experts are then combined through a weighted sum, where the weights are determined by the gating network’s output.
Output: The final output for the token is the combined result from the two experts it was routed to. Essentially, the output of the MoE layer is the weighted sum of the outputs of the expert networks.
This process is repeated for each token within the sequence, allowing the Mixtral model to effectively process and generate the response or continuation based on the input it receives.
Unique Attributes of Mixtral’s Approach
High Temporal Locality
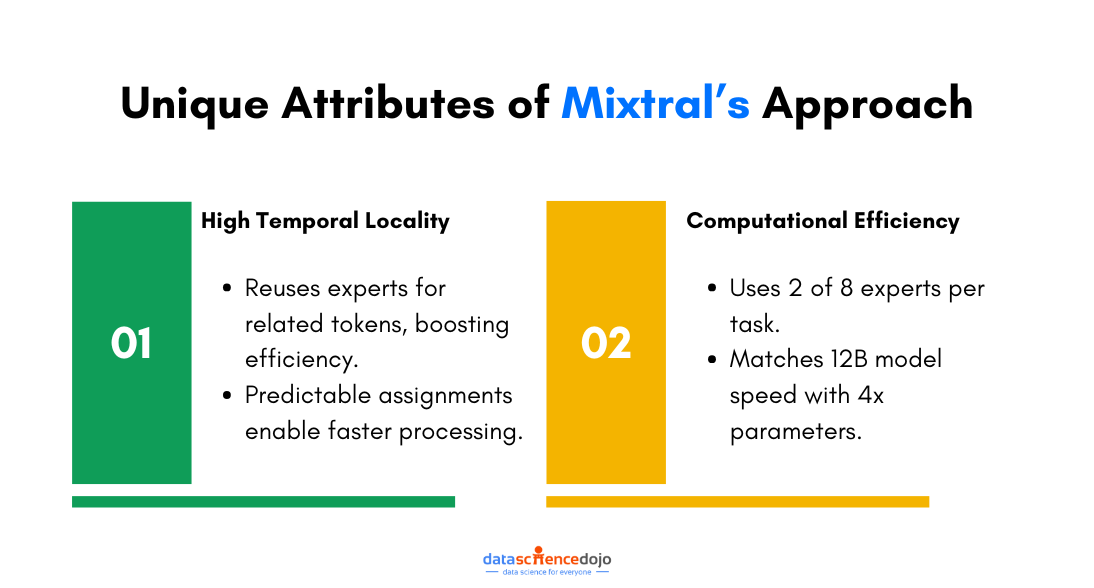
The interesting part is that Mixtral tends to pick the same expert or group of experts for words that are close together or related in some way i.e. the model possesses “high temporal locality”.
It’s like noticing that a certain part of your game has a lot of jumping, so you stick with the character who’s best at jumping for that whole section.
The implications of such high temporal locality are substantial for both training and inference efficiency. It suggests that expert assignments can be somewhat predicted over time, providing opportunities to optimize the model’s training and runtime performance.
For instance, the predictability in expert utilization can lead to more efficient caching strategies, wherein the outputs of frequently used experts are temporarily stored, thus speeding up computations for consecutive tokens that are routed to the same experts.
Computational Efficiency via Dual Expert Strategy
Mixtral uses only two out of eight experts to handle each piece of data it processes. This selective engagement is key for its computational efficiency, allowing it to work as fast as a model with 12 billion parameters, even though it has four times as many parameters in total.
Performance of Mixtral
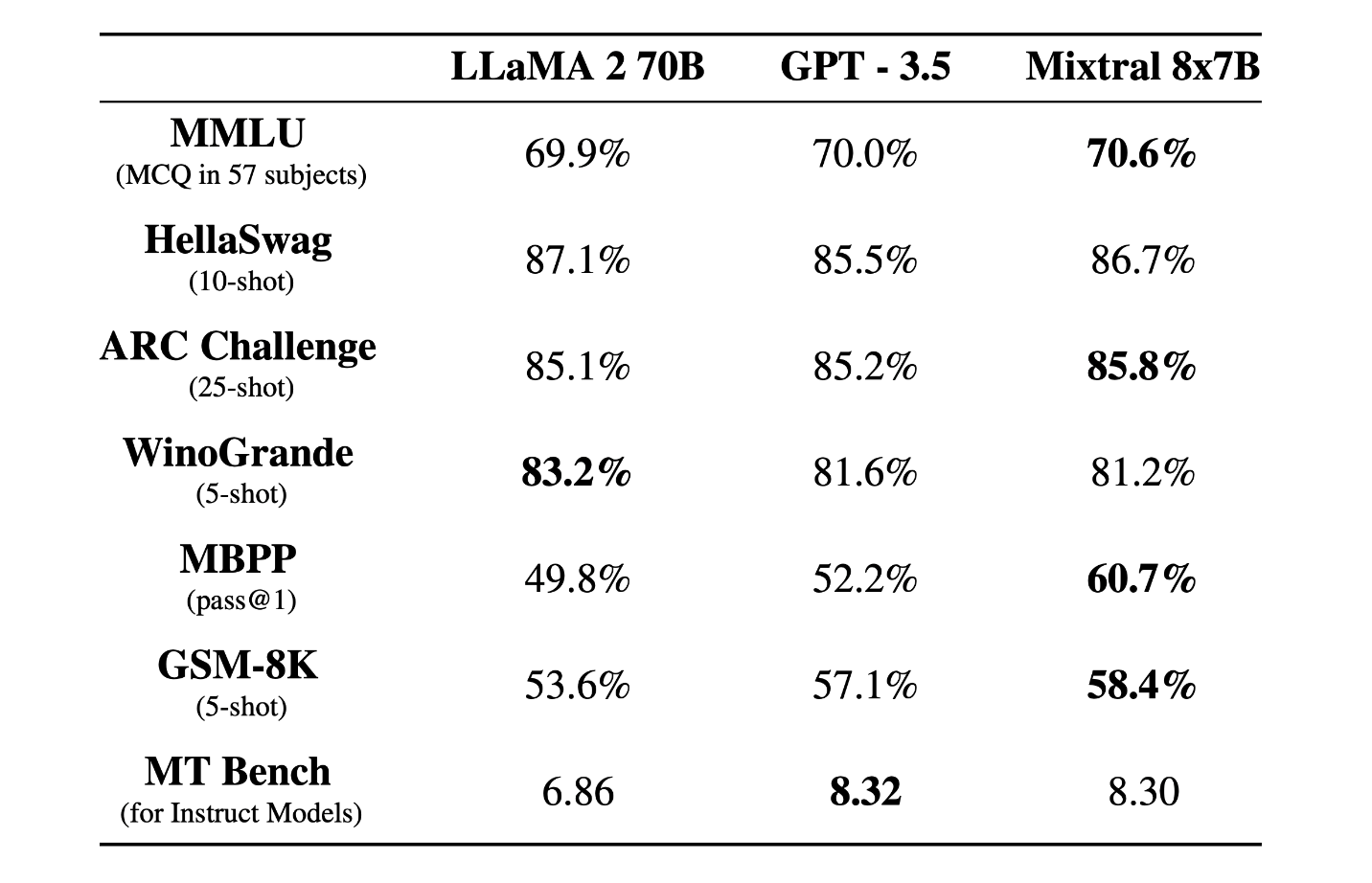
Mixtral 8x7B is compared directly with Llama 2 70B and GPT-3.5 and is found to perform similarly or above these models in benchmarks. Specifically, it scores higher on MMLU and does exceptionally well on MT-Bench.
Mixtral 8x7B Vs Llama 2 70b, ChatGPT 3.5 – Source: Mistral AI
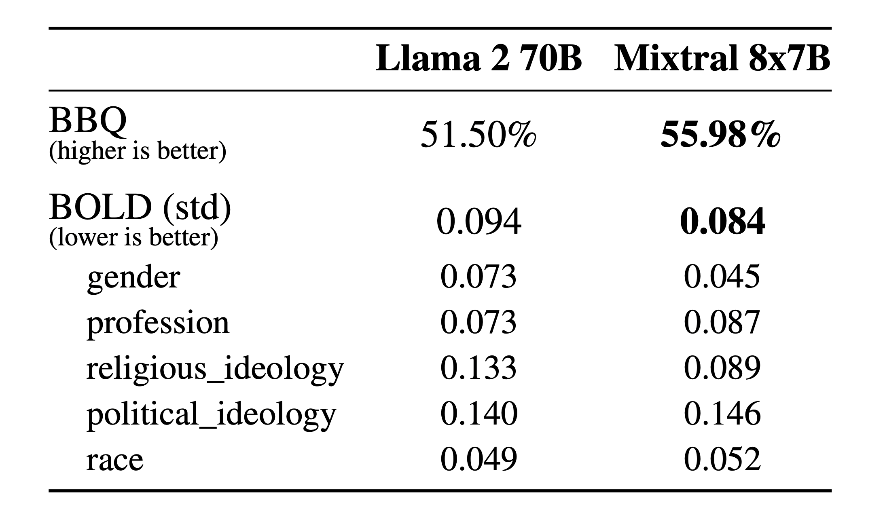
Hallucinations and Bias
In comparison with Llama 2, Mixtral of Experts exhibits reduced bias in the BBQ benchmark. Furthermore, it tends to show a more favorable outlook than Llama 2 in the BOLD benchmark, while maintaining comparable variations across different aspects.
Hallucinations – Mixtral 8x7B Vs Llama 2 70b – Source: Mistral AI
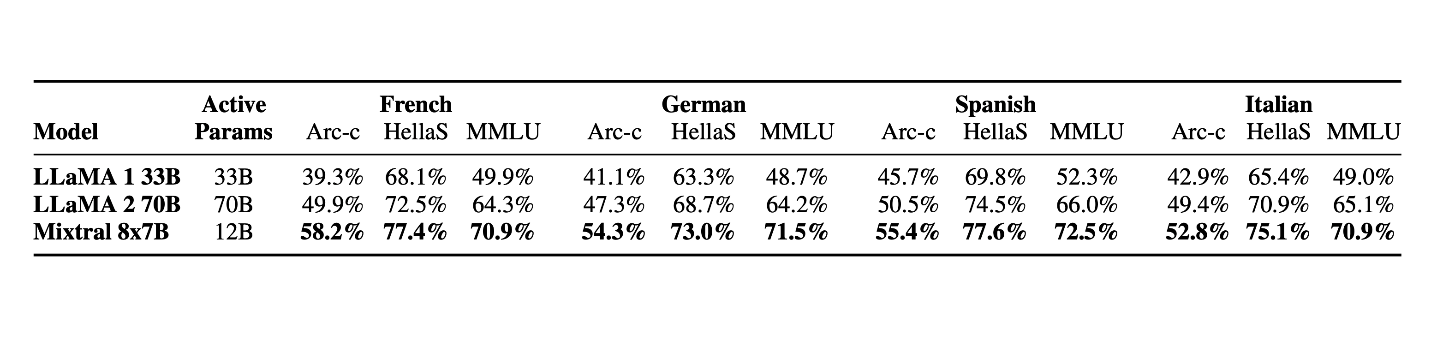
Mixtral vastly outperforms Llama 2 70B on multilingual benchmarks, demonstrating its strength in understanding and generating text across different languages
Mixtral 8x7B Vs Llama 2 70b, ChatGPT 3.5 – Source: Mistral AI
Mixtral: Revolutionizing AI Efficiency and Multilinguality
Mistral AI’s Mixtral model has carved out a niche for itself, showcasing the power and precision of the Sparse Mixture of Experts approach. As we’ve navigated through the intricacies of Mixtral, from its unique architecture to its standout performances on various benchmarks, it’s clear that this model is not just another entrant in the race to AI supremacy. It’s a harbinger of a nuanced, efficient future in large language models.
By strategically deploying only two of its eight available experts for each input token, the model achieves a balance between computational efficiency and deep, nuanced understanding that few others can claim. This approach not only enhances processing speed but also reduces bias and improves performance across languages, setting a new standard for what AI can achieve.
As we conclude our exploration of the genius of the Sparse Mixture of Experts by Mistral AI, it’s evident that this model represents a significant leap forward. Through its adept handling of complex language tasks, it stands as a testament to the potential of combining specialized expertise with smart, scalable architecture. The future of AI looks brighter with Mistral AI paving the way, promising models that are not only more efficient and versatile but also more understanding of the vast tapestry of human language.