

April 2024 marks a significant milestone with Meta releasing Llama 3, the newest member of the Llama family. This powerful large language model (LLM) is designed for advanced natural language processing (NLP). Since the launch of Llama 2 last year, the LLM market has seen rapid developments, with major releases like OpenAI’s GPT-4 and Anthropic’s Claude 3.
In this highly competitive and fast-evolving space, what is Llama 3? It’s Meta’s latest contribution to the world of AI, showcasing improved performance and a deeper understanding of language. With Llama 3, Meta once again solidifies its position in the rapidly advancing LLM market.

Let’s take a deeper look into the newly released LLM and evaluate its probable impact on the market.
What is Llama 3?
First things first—what is Llama 3? It is a text-generation open-source AI model that takes in a text input and generates a relevant textual response. It is trained on a massive dataset (15 trillion tokens of data to be exact), promising improved performance and better contextual understanding.
Thus, it offers better comprehension of data and produces more relevant outputs. The LLM is suitable for all NLP tasks usually performed by language models, including content generation, translating languages, and answering questions.
Since Llama 3 is an open-source model, it will be accessible to all for use. The model will be available on multiple platforms, including AWS, Databricks, Google Cloud, Hugging Face, Kaggle, IBM WatsonX, Microsoft Azure, NVIDIA NIM, and Snowflake.
Catch up on the history of the Llama family – Read in detail about Llama 2
Key Features Llama 3
Meta’s latest addition to its family of LLMs is a powerful tool, boosting several key features that enable it to perform more efficiently. Let’s look at the important features of Llama 3.
Strong Language Processing
The language model offers strong language processing with its enhanced understanding of the meaning and context of textual data. The high scores on benchmarks like MMLU indicate its advanced ability to handle tasks like summarization and question-answering efficiently.
It also offers a high level of proficiency in logical reasoning. The improved reasoning capabilities enable Llama 3 to solve puzzles and understand cause-and-effect relationships within the text. Hence, the enhanced understanding of language ensures the model’s ability to generate innovative and creative content.
Open-Source Accessibility
It is an open-source LLM, making it accessible to researchers and developers. They can access, modify, and build different applications using the LLM. It makes Llama 3 an important tool in the development of the field of AI, promoting innovation and creativity.
Large Context Window
The size of context windows for the language model has been doubled from 4096 to 8192 tokens. It makes the window approximately the size of 15 pages of textual data. The large context window offers improved insights for the LLM to portray a better understanding of data and contextual information within it.
Read more about the context window paradox in LLMs
Code Generation
Since Meta’s newest language model can generate different programming languages, this makes it a useful tool for programmers. Its increased knowledge of coding enables it to assist in code completion and provide alternative approaches in the code generation process.
While you explore Llama 3, also check out these 8 AI tools for code generation.
How Does Llama 3 Work?
Llama 3 is a powerful LLM that leverages useful techniques to process information. Its improved code enables it to offer enhanced performance and efficiency. Let’s review the overall steps involved in the language model’s process to understand information and generate relevant outputs.
Training
The first step is to train the language model on a huge dataset of text and code. It can include different forms of textual information, like books, articles, and code repositories. It uses a distributed file system to manage the vast amounts of data.
Underlying Architecture
It has a transformer-based architecture that excels at sequence-to-sequence tasks, making it well-suited for language processing. Meta has only shared that the architecture is optimized to offer improved performance of the language model.
Explore the different types of transformer architectures and their uses
Tokenization
The data input is also tokenized before it enters the model. Tokenization is the process of breaking down the text into smaller words called tokens. Llama 3 uses a specialized tokenizer called Tiktoken for the process, where each token is mapped to a numerical identifier. This allows the model to understand the text in a format it can process.
Processing and Inference
Once the data is tokenized and input into the language model, it is processed using complex computations. These mathematical calculations are based on the trained parameters of the model. Llama 3 uses inference, aligned with the prompt of the user, to generate a relevant textual response.
Safety and Security Measures
Since data security is a crucial element of today’s digital world, Llama 3 also focuses on maintaining the safety of information. Among its security measures is the use of tools like Llama Guard 2 and Llama Code Shield to ensure the safe and responsible use of the language model.
Llama Guard 2 analyzes the input prompts and output responses to categorize them as safe or unsafe. The goal is to avoid the risk of processing or generating harmful content.
Llama Code Shield is another tool that is particularly focused on the code generation aspect of the language model. It identifies security vulnerabilities in a code.

Hence, the LLM relies on these steps to process data and generate output, ensuring high-quality results and enhanced performance of the model. Since Llama 3 boasts of high performance, let’s explore the parameters are used to measure its enhanced performance.
What Are the Performance Parameters for Llama 3?
The performance of the language model is measured in relation to two key aspects: model size and benchmark scores.
Model Size
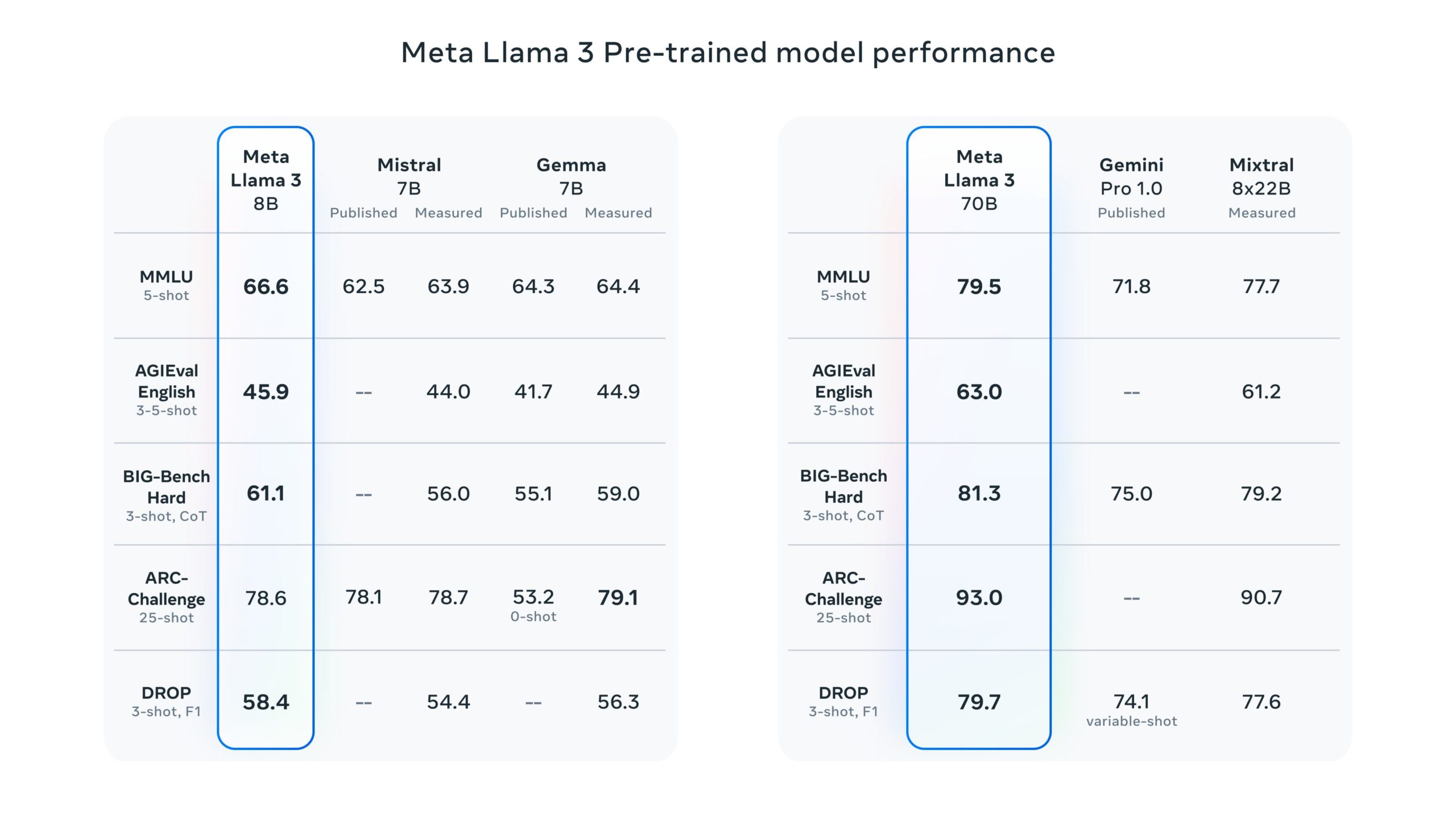
The model size of an LLM is defined by the number of parameters used for its training. Based on this concept, Llama 3 comes in two different sizes. Each model size comes in two different versions: a pre-trained (base) version and an instruct-tuned version.
8B
This model is trained using 8 billion parameters, hence the name 8B. Its smaller size makes it a compact and fast-processing model. It is suitable for use in situations or applications where the user requires quick and efficient results.
70B
The larger model of Llama 3 is trained on 70 billion parameters and is computationally more complex. It is a more powerful version that offers better performance, especially on complex tasks.
In addition to the model size, the LLM performance is also measured and judged by a set of benchmark scores.
You might also like: PaLM 2 vs Llama 2
Benchmark Scores
Meta claims that the language model achieves strong results on multiple benchmarks. Each one is focused on assessing the capabilities of the LLM in different areas. Some key benchmarks for Llama 3 are as follows:
MMLU (Massive Multitask Language Understanding)
It aims to measure the capability of an LLM to understand different languages. A high score indicates that the LLM has high language comprehension across various tasks. It typically tests the zero-shot language understanding to measure the range of general knowledge of a model due to its training.
MMLU spans a wide range of human knowledge, including 57 subjects. The score of the model is based on the percentage of questions the LLM answers correctly. The testing of Llama 3 uses:
- Zero-shot evaluation – to measure the model’s ability to apply knowledge in the model weights to novel tasks. The model is tested on tasks that the model has never encountered before.
- 5-shot evaluation – exposes the model to 5 sample tasks and then asks to answer an additional one. It measures the power of generalizability of the model from a small amount of task-specific information.
Another interesting read: Understanding LLM evaluation
ARC (Abstract Reasoning Corpus)
It evaluates a model’s ability to perform abstract reasoning and generalize its knowledge to unseen situations. ARC challenges models with tasks requiring them to understand abstract concepts and apply reasoning skills, measuring their ability to go beyond basic pattern recognition and achieve more human-like forms of reasoning and abstraction.
GPQA (General Propositional Question Answering)
It refers to a specific type of question-answering tasks that evaluate an LLM’s ability to answer questions that require reasoning and logic over factual knowledge. It challenges LLMs to go beyond simple information retrieval by emphasizing their ability to process information and use it to answer complex questions.
Strong performance in GPQA tasks suggests an LLM’s potential for applications requiring comprehension, reasoning, and problem-solving, such as education, customer service chatbots, or legal research.
Also learn about Orchestration frameworks
HumanEval
This benchmark measures an LLM’s proficiency in code generation. It emphasizes the importance of generating code that actually works as intended, allowing researchers and developers to compare the performance of different LLMs in code generation tasks.
Llama 3 uses the same setting of HumanEval benchmark – Pass@1 – as used for Llama 1 and 2. While it measures the coding ability of an LLM, it also indicates how often the model’s first choice of solution is correct.
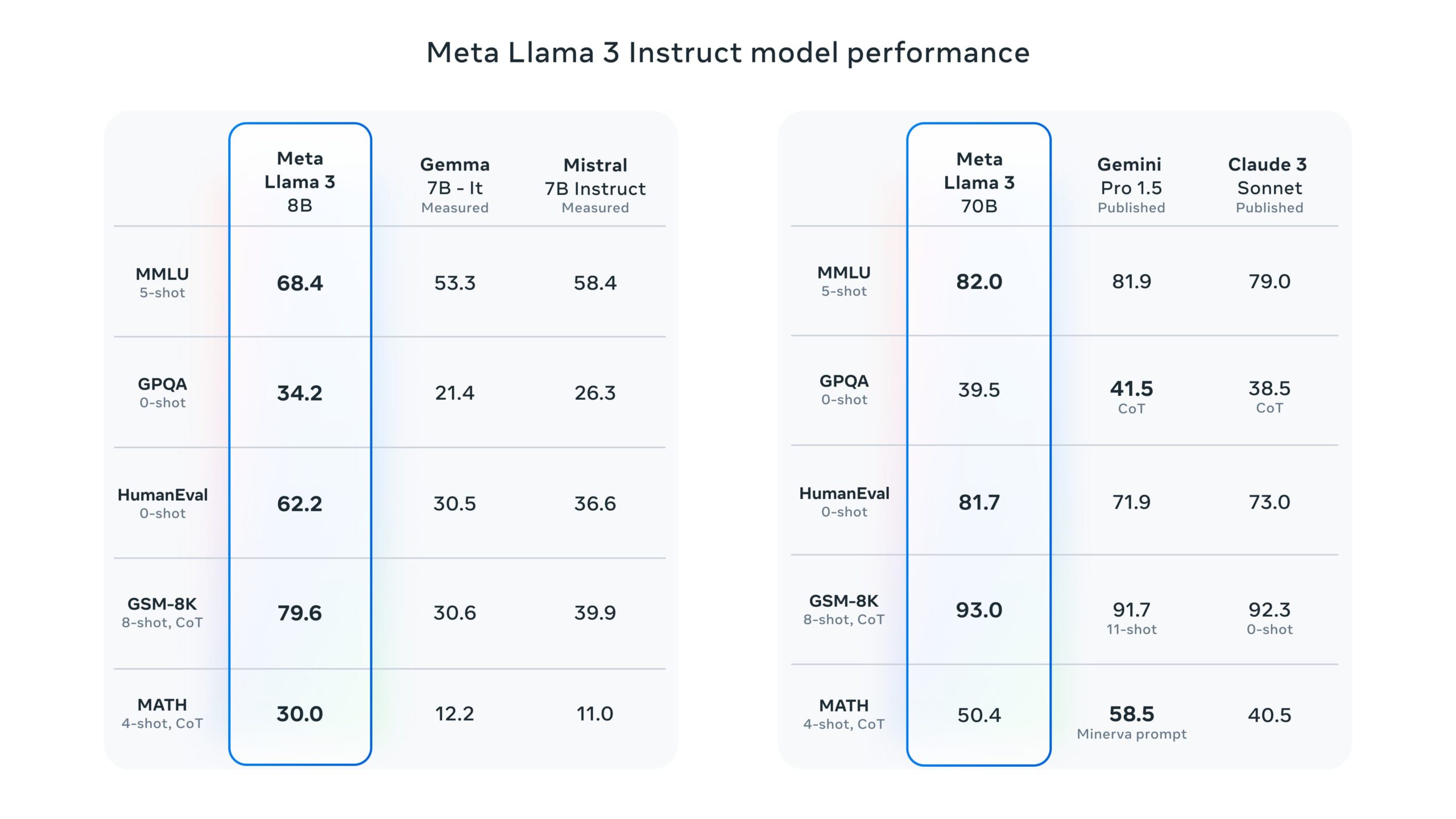
These are a few of the parameters that are used to measure the performance of an LLM. Llama 3 presents promising results across all these benchmarks alongside other tests like, MATH, GSM-8K, and much more. These parameters have determined Llama 3 as a high-performing LLM, promising its large-scale implementation in the industry.
Meta AI: A Real-World Application of Llama 3
While it is a new addition to Meta’s Llama family, the newest language model is the power behind the working of Meta AI. It is an AI assistant launched by Meta on all its social media platforms, leveraging the capabilities of Llama 3.
The underlying language model enables Meta AI to generate human-quality textual outputs, follow basic instructions to complete complex tasks, and process information from the real world through web search. All these features offer enhanced communication, better accessibility, and increased efficiency of the AI assistant.
It serves as a practical example of using Llama 3 to create real-world applications successfully. The AI assistant is easily accessible through all major social media apps, including Facebook, WhatsApp, and Instagram. It gives you access to real-time information without having to leave the application.
Moreover, Meta AI offers faster image generation, creating an image as you start typing the details. The results are high-quality visuals with the ability to do endless iterations to get the desired results.
With access granted in multiple countries – Australia, Canada, Ghana, Jamaica, Malawi, New Zealand, Nigeria, Pakistan, Singapore, South Africa, Uganda, Zambia, and Zimbabwe – Meta AI is a popular assistant across the globe.

Who Should Work with Llama 3?
Thus, Llama 3 offers new and promising possibilities for development and innovation in the field of NLP and generative AI. The enhanced capabilities of the language model can be widely adopted by various sectors like education, content creation, and customer service in the form of AI-powered tutors, writing assistants, and chatbots, respectively.
The key, however, remains to ensure responsible development that prioritizes fairness, explainability, and human-machine collaboration. If handled correctly, Llama 3 has the potential to revolutionize LLM technology and the way we interact with it.
The future holds a world where AI assists us in learning, creating, and working more effectively. It’s a future filled with both challenges and exciting possibilities, and Llama 3 is at the forefront of this exciting journey.