Python is a versatile and powerful programming language! Whether you’re a seasoned developer or just stepping into coding, Python’s simplicity and readability make it a favorite among programmers.
One of the main reasons for its popularity is the vast array of libraries and packages available for data manipulation, analysis, and visualization. But what truly sets it apart is the vast ecosystem of Python packages. It makes Python the go-to language for countless applications.
Learn the top 6 Popular Python libraries for Data Science
While its clean syntax and dynamic nature allow developers to bring their ideas to life with ease, the true magic it offers is in the form of Python packages. It is similar to having a toolbox filled with pre-built solutions for all of your problems.
In this blog, we’ll explore the top 15 Python packages that every developer should know about. So, buckle up and enhance your Python journey with these incredible tools! However, before looking at the list, let’s understand what Python packages are.

What are Python Packages?
Python packages are a fundamental aspect of the Python programming language. These packages are designed to organize and distribute code efficiently. These are collections of modules that are bundled together to provide a particular functionality or feature to the user.
Understand the difference between Java and Python
Common examples of widely used Python packages include pandaswhich groups modules for data manipulation and analysis, while matplotlib organizes modules for creating visualizations.
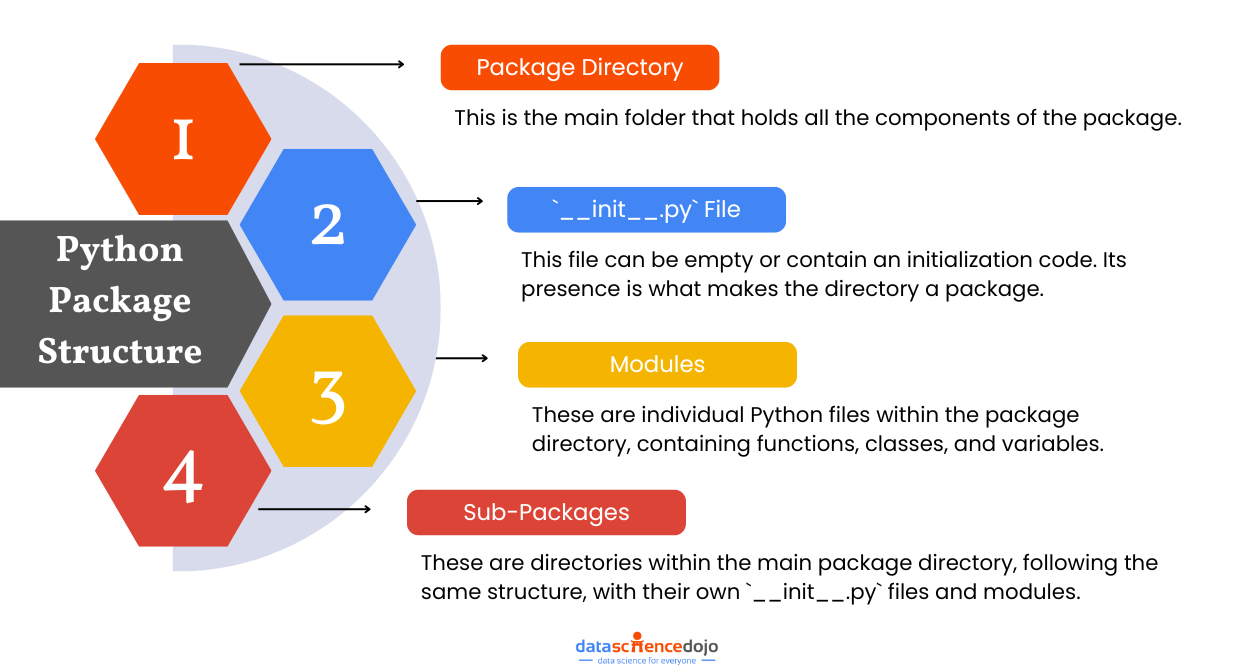
The Structure of a Python Package
A Python package refers to a directory that contains multiple modules and a special file named __init__.py. This file is crucial as it signals Python that the directory should be treated as a package. These packages enable you to logically group and distribute functionality, making your projects modular, scalable, and easier to maintain.
Here’s a simple breakdown of a typical package structure:
1. Package Directory: This is the main folder that holds all the components of the package.
2. `__init__.py` File: This file can be empty or contain an initialization code for the package. Its presence is what makes the directory a package.
3. Modules: These are individual Python files within the package directory. Each module can contain functions, classes, and variables that contribute to the package’s overall functionality.
4. Sub-packages: Packages can also contain sub-packages, which are directories within the main package directory. These sub-packages follow the same structure, with their own `__init__.py` files and modules.
The above structure is useful for developers to:
- Reuse code: Write once and use it across multiple projects
- Organize projects: Keep related functionality grouped together
- Prevent conflicts: Use namespaces to avoid naming collisions between modules
Thus, the modular approach not only enhances code readability but also simplifies the process of managing large projects. It makes Python packages the building blocks that empower developers to create robust and scalable applications.

Top 15 Python Packages You Must Explore
Let’s navigate through a list of some of the top Python packages that you should consider adding to your toolbox. For 2025, here are some essential Python packages to know across different domains, reflecting the evolving trends in data science, machine learning, and general development:
Core Libraries for Data Analysis
1. NumPy
Numerical Python, or NumPy, is a fundamental package for scientific computing in Python, providing support for large, multi-dimensional arrays and matrices. It is a core library widely used in data analysis, scientific computing, and machine learning.
NumPy introduces the ndarray object for efficient storage and manipulation of large datasets, outperforming Python’s built-in lists in numerical operations. It also offers a comprehensive suite of mathematical functions, including arithmetic operations, statistical functions, and linear algebra operations for complex numerical computations.
NumPy’s key features include broadcasting for arithmetic operations on arrays of different shapes. It can also interface with C/C++ and Fortran, integrating high-performance code with Python and optimizing performance.
NumPy arrays are stored in contiguous memory blocks, ensuring efficient data access and manipulation. It also supports random number generation for simulations and statistical sampling. As the foundation for many other data analysis libraries like Pandas, SciPy, and Matplotlib, NumPy ensures seamless integration and enhances the capabilities of these libraries.

2. Pandas
Pandas is a widely-used open-source library in Python that provides powerful data structures and tools for data analysis. Built on top of NumPy, it simplifies data manipulation and analysis with its two primary data structures: Series and DataFrame.
A Series is a one-dimensional labeled array, while a DataFrame is a two-dimensional table-like structure with labeled axes. These structures allow for efficient data alignment, indexing, and manipulation, making it easy to clean, prepare, and transform data.
Pandas also excels in handling time series data, performing group by operations, and integrating with other libraries like NumPy and Matplotlib. The package is essential for tasks such as data wrangling, exploratory data analysis (EDA), statistical analysis, and data visualization.
It offers robust input and output tools to read and write data from various formats, including CSV, Excel, and SQL databases. This versatility makes it a go-to tool for data scientists and analysts across various fields, enabling them to efficiently organize, analyze, and visualize data trends and patterns.
Learn to use Pandas agent of time-series analysis
3. Dask
Dask is a robust Python library designed to enhance parallel computing and efficient data analysis. It extends the capabilities of popular libraries like NumPy and Pandas, allowing users to handle larger-than-memory datasets and perform complex computations with ease.
Dask’s key features include parallel and distributed computing, which utilizes multiple cores on a single machine or across a distributed cluster to speed up data processing tasks. It also offers scalable data structures, such as arrays and dataframes, that manage datasets too large to fit into memory, enabling out-of-core computation.
Dask integrates seamlessly with existing Python libraries like NumPy, Pandas, and Scikit-learn, allowing users to scale their workflows with minimal code changes. Its dynamic task scheduler optimizes task execution based on available resources.
With an API that mirrors familiar libraries, Dask is easy to learn and use. It supports advanced analytics and machine learning workflows for training models on big data. Dask also offers interactive computing, enabling real-time exploration and manipulation of large datasets, making it ideal for data exploration and iterative analysis.

Visualization Tools
4. Matplotlib
Matplotlib is a plotting library for Python to create static, interactive, and animated visualizations. It is a foundational tool for data visualization in Python, enabling users to transform data into insightful graphs and charts.
It enables the creation of a wide range of plots, including line graphs, bar charts, histograms, scatter plots, and more. Its design is inspired by MATLAB, making it familiar to users, and it integrates seamlessly with other Python libraries like NumPy and Pandas, enhancing its utility in data analysis workflows.
Learn about easily building AI-based chatbots in Python
Key features of Matplotlib include its ability to produce high-quality, publication-ready figures in various formats such as PNG, PDF, and SVG. It also offers extensive customization options, allowing users to adjust plot elements like colors, labels, and line styles to suit their needs.
Matplotlib supports interactive plots, enabling users to zoom, pan, and update plots in real time. It provides a comprehensive set of tools for creating complex visualizations, such as subplots and 3D plots, and supports integration with graphical user interface (GUI) toolkits, making it a powerful tool for developing interactive applications.
Master the creation of a rule-based chatbot in Python
5. Seaborn
Seaborn is a Python data visualization library built on top of Matplotlib for aesthetically pleasing and informative statistical graphics. It provides a high-level interface for drawing attractive and informative statistical graphics. It simplifies the process of creating complex visualizations by offering built-in themes and color palettes.
The Python package is well-suited for visualizing data frames and arrays, integrating seamlessly with Pandas to handle data efficiently. Its key features include the ability to create a variety of plot types, such as heatmaps, violin plots, and pair plots, which are useful for exploring relationships in data.
Seaborn also supports complex visualizations like multi-plot grids, allowing users to create intricate layouts with minimal code. Its integration with Matplotlib ensures that users can customize plots extensively, combining the simplicity of Seaborn with the flexibility of Matplotlib to produce detailed and customized visualizations.
Also, read about Large Language Models and their Applications
6. Plotly
Plotly is a useful Python library for data analysis and presentation through interactive and dynamic visualizations. It allows users to create interactive plots that can be embedded in web applications, shared online, or used in Jupyter notebooks.
It supports diverse chart types, including line plots, scatter plots, bar charts, and more complex visualizations like 3D plots and geographic maps. Plotly’s interactivity enables users to hover over data points to see details, zoom in and out, and even update plots in real time, enhancing the user experience and making data exploration more intuitive.
Build a Recommendation System using Python easily
It enables users to produce high-quality, publication-ready graphics with minimal code with a user-friendly interface. It also integrates well with other Python libraries such as Pandas and NumPy.
Plotly also supports a wide array of customization options, enabling users to tailor the appearance of their plots to meet specific needs. Its integration with Dash, a web application framework, allows users to build interactive web applications with ease, making it a versatile tool for both data visualization and application development.
Machine Learning and Deep Learning
7. Scikit-learn
Scikit-learn is a Python library for machine learning with simple and efficient tools for data mining and analysis. Built on top of NumPy, SciPy, and Matplotlib, it provides a robust framework for implementing a wide range of machine-learning algorithms.
It is known for ease of use and clean API, making it accessible for both beginners and experienced practitioners. It supports various supervised and unsupervised learning algorithms, including classification, regression, clustering, and dimensionality reduction, allowing users to tackle diverse ML tasks.
Understand Machine Learning using Python in Cloud
Its comprehensive suite of tools for model selection, evaluation, and validation, such as cross-validation and grid search helps in optimizing model performance. It also offers utilities for data preprocessing, feature extraction, and transformation, ensuring that data is ready for analysis.
While Scikit-learn is primarily focused on traditional ML techniques, it can be integrated with deep learning frameworks like TensorFlow and PyTorch for more advanced applications. This makes Scikit-learn a versatile tool in the ML ecosystem, suitable for a range of projects from academic research to industry applications.
8. TensorFlow
TensorFlow is an open-source software library developed by Google dataflow and differentiable programming across various tasks. It is designed to be highly scalable, allowing it to run efficiently on multiple CPUs and GPUs, making it suitable for both small-scale and large-scale machine learning tasks.
It supports a wide array of neural network architectures and offers high-level APIs, such as Keras, to simplify the process of building and training models. This flexibility and robust performance make TensorFlow a popular choice for both academic research and industrial applications.
One of the key strengths of TensorFlow is its ability to handle complex computations and its support for distributed computing. It also provides tools for deploying models on various platforms, including mobile and edge devices, through TensorFlow Lite.
Moreover, TensorFlow’s community and extensive documentation offer valuable resources for developers and researchers, fostering innovation and collaboration. Its versatility and comprehensive features make TensorFlow an essential tool in the machine learning and deep learning landscape.
9. PyTorch
PyTorch is an open-source library developed by Facebook’s AI Research lab. It is known for dynamic computation graphs that allow developers to modify the network architecture, making it highly flexible for experimentation. This feature is especially beneficial for researchers who need to test new ideas and algorithms quickly.
It integrates seamlessly with Python for a natural and easy-to-use interface that appeals to developers familiar with the language. PyTorch also offers robust support for distributed training, enabling the efficient training of large models across multiple GPUs.
Through frameworks like TorchScript, it enables users to deploy models on various platforms like mobile devices. Its strong community support and extensive documentation make it accessible for both beginners and experienced developers.
Explore more about Retrieval Augmented Generation
Natural Language Processing (NLP)
10. NLTK
NLTK, or the Natural Language Toolkit, is a comprehensive Python library designed for working with human language data. It provides a range of tools and resources, including text processing libraries for tokenization, parsing, classification, stemming, tagging, and semantic reasoning.
It also includes a vast collection of corpora and lexical resources, such as WordNet, which are essential for linguistic research and development. Its modular design allows users to easily access and implement various NLP techniques, making it an excellent choice for both educational and research purposes.
Explore Natural Language Processing and its Applications
Beyond its extensive functionality, NLTK is known for its ease of use and well-documented tutorials, helping newcomers to grasp the basics of NLP. The library’s interactive features, such as graphical demonstrations and sample datasets, provide a hands-on learning experience.
11. SpaCy
SpaCy is a powerful Python library designed for production use, offering fast and accurate processing of large volumes of text. It offers features like tokenization, part-of-speech tagging, named entity recognition, dependency parsing, and more.
Unlike some other NLP libraries, SpaCy is optimized for performance, making it ideal for real-time applications and large-scale data processing. Its pre-trained models support multiple languages, allowing developers to easily implement multilingual NLP solutions.
One of SpaCy’s standout features is its focus on providing a seamless and intuitive user experience. It offers a straightforward API that simplifies the integration of NLP capabilities into applications. It also supports deep learning workflows, enabling users to train custom models using frameworks like TensorFlow and PyTorch.
SpaCy includes tools for visualizing linguistic annotations and dependencies, which can be invaluable for understanding and debugging NLP models. With its robust architecture and active community, it is a popular choice for both academic research and commercial projects in the field of NLP.

Web Scraping
12. BeautifulSoup
BeautifulSoup is a Python library designed for web scraping purposes, allowing developers to extract data from HTML and XML files with ease. It provides simple methods to navigate, search, and modify the parse tree, making it an excellent tool for handling web page data.
It is useful for parsing poorly-formed or complex HTML documents, as it automatically converts incoming documents to Unicode and outgoing documents to UTF-8. This flexibility ensures that developers can work with a wide range of web content without worrying about encoding issues.
BeautifulSoup integrates seamlessly with other Python libraries like requests, which are used to fetch web pages. This combination allows developers to efficiently scrape and process web data in a streamlined workflow.
The library’s syntax and comprehensive documentation make it accessible to both beginners and experienced programmers. Its ability to handle various parsing tasks, such as extracting specific tags, attributes, or text, makes it a versatile tool for projects ranging from data mining to web data analysis.
Bonus Additions to the List!
13. SQLAlchemy
SQLAlchemy is a Python library that provides a set of tools for working with databases using an Object Relational Mapping (ORM) approach. It allows developers to interact with databases using Python objects, making database operations more intuitive and reducing the need for writing raw SQL queries.
SQLAlchemy supports a wide range of database backends, including SQLite, PostgreSQL, MySQL, and Oracle, among others. Its ORM layer enables developers to define database schemas as Python classes, facilitating seamless integration between the application code and the database.
It offers a powerful Core system for those who prefer to work with SQL directly. This system provides a high-level SQL expression language for developers to construct complex queries. Its flexibility and extensive feature set make it suitable for both small-scale applications and large enterprise systems.
Learn how to evaluate time series in Python model predictions
14. OpenCV
OpenCV, short for Open Source Computer Vision Library, is a Python package for computer vision and image processing tasks. Originally developed by Intel, it was later supported by Willow Garage and is now maintained by Itseez. OpenCV is available for C++, Python, and Java.
It enables developers to perform operations on images and videos, such as filtering, transformation, and feature detection.
It supports a variety of image formats and is capable of handling real-time video capture and processing, making it an essential tool for applications in robotics, surveillance, and augmented reality. Its extensive functionality allows developers to implement complex algorithms for tasks like object detection, facial recognition, and motion tracking.
OpenCV also integrates well with other libraries and frameworks, such as NumPy, enhancing its performance and flexibility. This allows for efficient manipulation of image data using array operations.
Moreover, its open-source nature and active community support ensure continuous updates and improvements, making it a reliable choice for both academic research and industrial applications.
15. urllib
Urllib is a module in the standard Python library that provides a set of simple, high-level functions for working with URLs and web protocols. It allows users to open and read URLs, download data from the web, and interact with web services.
It supports various protocols, including HTTP, HTTPS, and FTP, enabling seamless communication with web servers. The library is particularly useful for tasks such as web scraping, data retrieval, and interacting with RESTful APIs.
The urllib package is divided into several modules, each serving a specific purpose. For instance:
urllib.requestis used for opening and reading URLsurllib.parseprovides functions for parsing and manipulating URL stringsurllib.errorhandles exceptions related to URL operationsurllib.robotparserhelps in parsing robots.txt files to determine if a web crawler can access a particular site
With its comprehensive functionality and ease of use, urllib is a valuable tool for developers looking to perform network-related tasks in Python, whether for simple data fetching or more complex web interactions.
Explore the top 6 Python libraries for data science
What is the Standard vs Third-Party Packages Debate?
In the Python ecosystem, packages are categorized into two main types: standard and third-party. Each serves a unique purpose and offers distinct advantages to developers. Before we dig deeper into the debate, let’s understand what is meant by these two types of packages.
What are Standard Packages?
These are the packages found in Python’s standard library and maintained by the Python Software Foundation. These are also included with every Python installation, providing essential functionalities like file I/O, system calls, and data manipulation. These are reliable, well-documented, and ensure compatibility across different versions.
What are Third-Party Packages?
These refer to packages developed by the Python community and are not a part of the standard library. They are often available through package managers like pip or repositories like Python Package Index (PyPI). These packages cover a wide range of functionalities.
Key Points of the Debate
While we understand the main difference between standard and third-party packages, their comparison can be analyzed from three main aspects.
It is crucial to understand these differences as you choose a package for your project. As for the choice you make, it often depends on the project’s requirements, but in many cases, a combination of both is used to access the full potential of Python.
Wrapping up
In conclusion, these Python packages are some of the most popular and widely used libraries in the Python data science ecosystem. They provide powerful and flexible tools for data manipulation, analysis, and visualization, and are essential for aspiring and practicing data scientists.
With the help of these Python packages, data scientists can easily perform complex data analysis and machine learning tasks, and create beautiful and informative visualizations.
Learn how to build AI-based chatbots in Python
If you want to learn more about data science and how to use these Python packages, we recommend checking out Data Science Dojo’s Python for Data Science course, which provides a comprehensive introduction to Python and its data science ecosystem.