Welcome to the world of databases, where the choice between SQL (Structured Query Language) and NoSQL (Not Only SQL) databases can be a significant decision.
Both SQL databases and NoSQL databases have their own unique characteristics and advantages, and understanding which one suits your needs is essential for a successful application or project.
In this blog, we’ll explore the defining traits, benefits, use cases, and key factors to consider when choosing between SQL and NoSQL databases. So, let’s dive in!
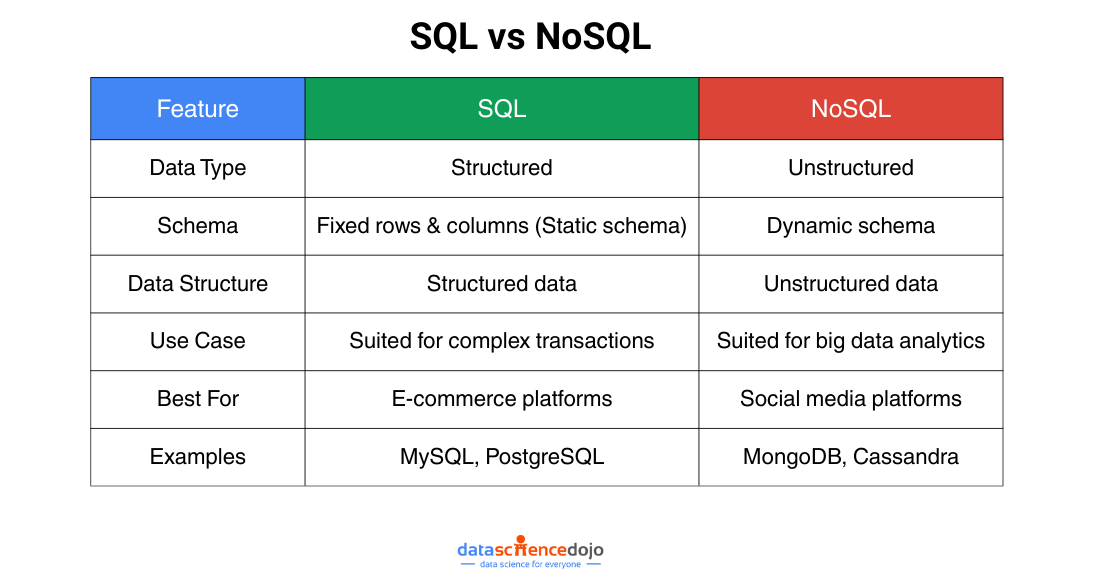
SQL Database
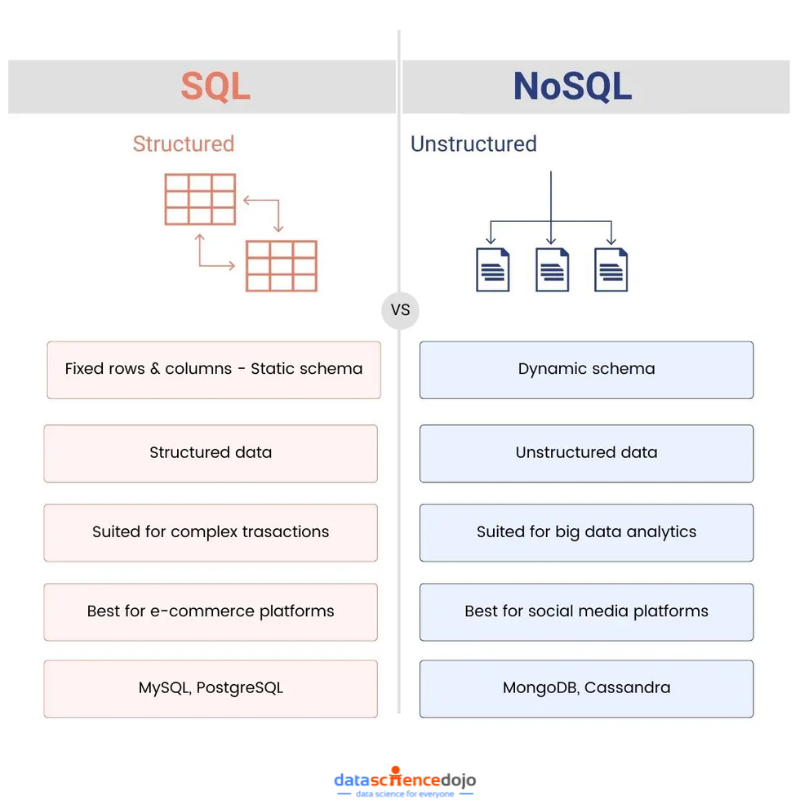
SQL databases are relational databases that store data in tables. Each table has a set of columns, and each column has a specific data type. SQL databases are well-suited for storing structured data, such as customer records, product inventory, and financial transactions.
Some of the benefits of SQL databases include:
- Strong consistency and data integrity: SQL databases enforce data integrity constraints, such as ensuring that no two customers can have the same customer ID.
- ACID properties for transactional support: SQL databases support ACID transactions, which guarantee that all or none of a set of database operations are performed. This is important for applications that require a high degree of data integrity, such as banking and financial services.
- Ability to perform complex queries using SQL: SQL is a powerful language that allows you to perform complex queries on your data. This can be useful for tasks such as reporting, analytics, and data mining.
Some of the popular SQL databases include:
- MySQL
- PostgreSQL
- Oracle
- Microsoft SQL Server
To understand which SQL database will work best for you, hop on to this video.
Data Storage Systems: Taking a look at Redshift, MySQL, PostGreSQL, Hadoop and others
NoSQL Databases
NoSQL databases are a type of database that does not use the traditional relational model. NoSQL databases are designed to store and manage large amounts of unstructured data.
Some of the benefits of NoSQL databases include:
- Scalability and high performance: NoSQL databases are designed to scale horizontally, which means that they can be easily increased in size by adding more nodes. This makes them well-suited for applications that need to handle large amounts of data.
- Flexibility in handling unstructured data: NoSQL databases are not limited to storing structured data. They can also store unstructured data, such as text, images, and videos. This makes them well-suited for applications that deal with large amounts of multimedia data.
- Horizontal scalability through sharding and replication: NoSQL databases can be horizontally scaled by sharding the data across multiple nodes. This means that the data is divided into smaller pieces and stored on different nodes. Replication is the process of copying the data to multiple nodes. This ensures that the data is always available, even if one node fails.
Some of the popular NoSQL databases include:
- MongoDB
- Cassandra
- DynamoDB
- Redis

Usage for Each Database
Now, let’s dive into the crux of the argument whereby we explore the cases where SQL databases work best and cases where NoSQL databases shine.
SQL databases excel in scenarios that require:
- Complex transactions with strict consistency requirements, such as financial systems or e-commerce platforms.
- Applications that heavily rely on relational data models, with interconnected data that necessitate robust integrity and relational operations.
NoSQL databases are well-suited for:
- Big data analytics and real-time streaming applications demand high scalability and performance.
- Content management systems, social media platforms, and IoT applications handle diverse and unstructured data types.
- Applications requiring rapid prototyping and agile development due to their schema flexibility.
Real-world examples highlight the versatility of SQL and NoSQL databases. SQL databases power major banking systems, airline reservation systems, and enterprise resource planning (ERP) solutions. NoSQL databases are commonly used by social media platforms like Facebook and Twitter, as well as streaming services like Netflix and Spotify.
Factors to Consider
Choosing between SQL and NoSQL databases can be a daunting task. With each option offering its own unique set of advantages, it’s important to consider several key factors before making a decision. These factors will help guide you towards the right database that aligns with your project’s requirements.
- Data structure: Evaluate whether your data has a well-defined structure and follows a relational model or if it is dynamic and unstructured.
- Scalability requirements: Consider the expected growth and scalability needs of your application. Determine if horizontal scalability through techniques like sharding and replication is crucial.
- Consistency requirements: Assess the level of consistency needed for your application. Determine if strong consistency or eventual consistency is more suitable.
- Development flexibility: Evaluate the flexibility required to adapt to changing data structures. Consider whether a rigid schema or schema flexibility is more important for your project.
- Integration requirements: Assess the compatibility of the database with your existing infrastructure and tools. Consider factors such as support for APIs, data connectors, and integration capabilities.
Conclusion
In the SQL vs. NoSQL debate, there is no one-size-fits-all answer. Each database type offers unique benefits and is suited for different use cases. Understanding your specific requirements, such as data structure, scalability, consistency, and development flexibility, is crucial in making an informed decision.
Recapitulating the main points discussed, SQL databases provide strong consistency, ACID compliance, and robust query capabilities, making them ideal for transactional systems. NoSQL databases offer scalability, flexibility with unstructured data, and high performance, making them well-suited for big data, real-time analytics, and applications with evolving data requirements.
Ultimately, it is encouraged to thoroughly evaluate your needs, consider the factors mentioned, and choose the appropriate database solution that aligns with your project’s objectives and requirements. In some cases, a hybrid approach combining SQL and NoSQL databases may be suitable to leverage the strengths of both worlds and cater to specific use cases.