In recent years, the landscape of artificial intelligence has been transformed by the development of large language models like GPT-3 and BERT, renowned for their impressive capabilities and wide-ranging applications.
Learn the comparative analysis between GPT-3.5 and GPT-4
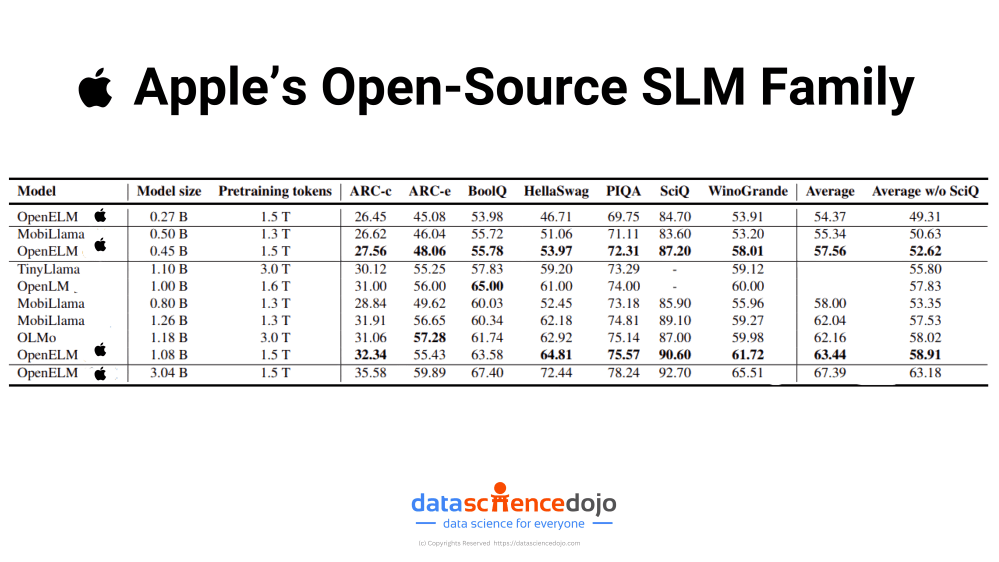
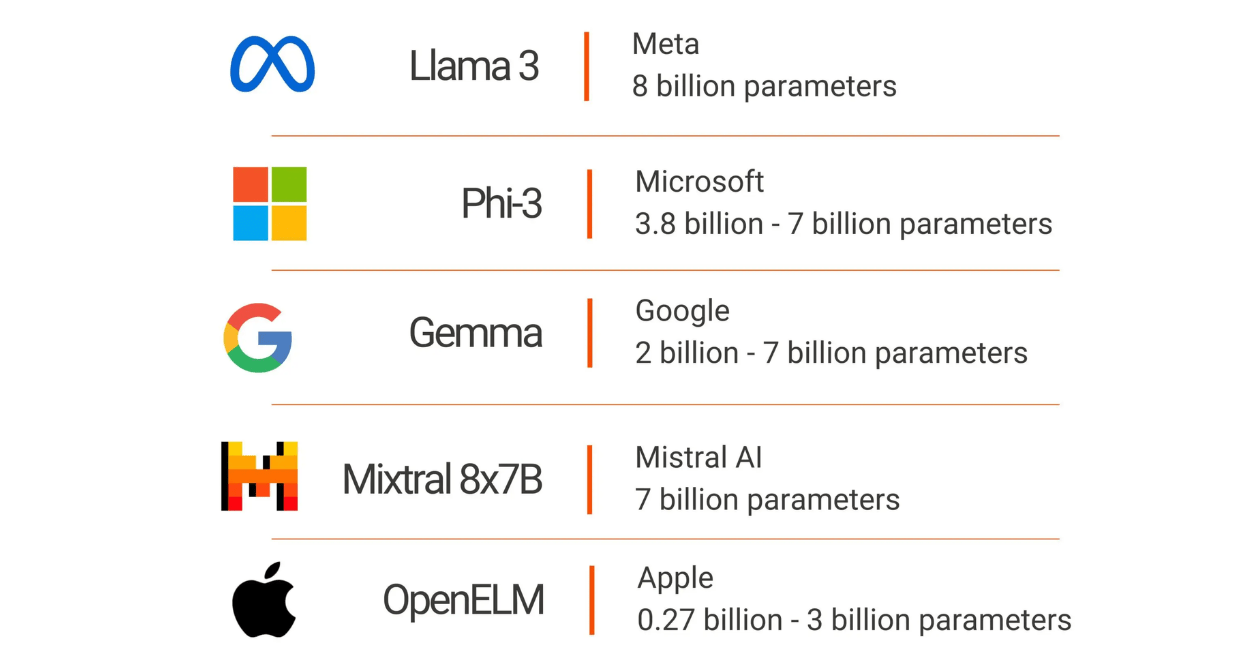
However, alongside these giants, a new category of AI tools is making waves—the small language models (SLMs). These models, such as LLaMA 3, Phi 3, Mistral 7B, and Gemma, offer a potent combination of advanced AI capabilities with significantly reduced computational demands.
Why are Small Language Models Needed?
This shift towards smaller, more efficient models is driven by the need for accessibility, cost-effectiveness, and the democratization of AI technology.
Small language models require less hardware, lower energy consumption, and offer faster deployment, making them ideal for startups, academic researchers, and businesses that do not possess the immense resources often associated with big tech companies.
Moreover, their size does not merely signify a reduction in scale but also an increase in adaptability and ease of integration across various platforms and applications.
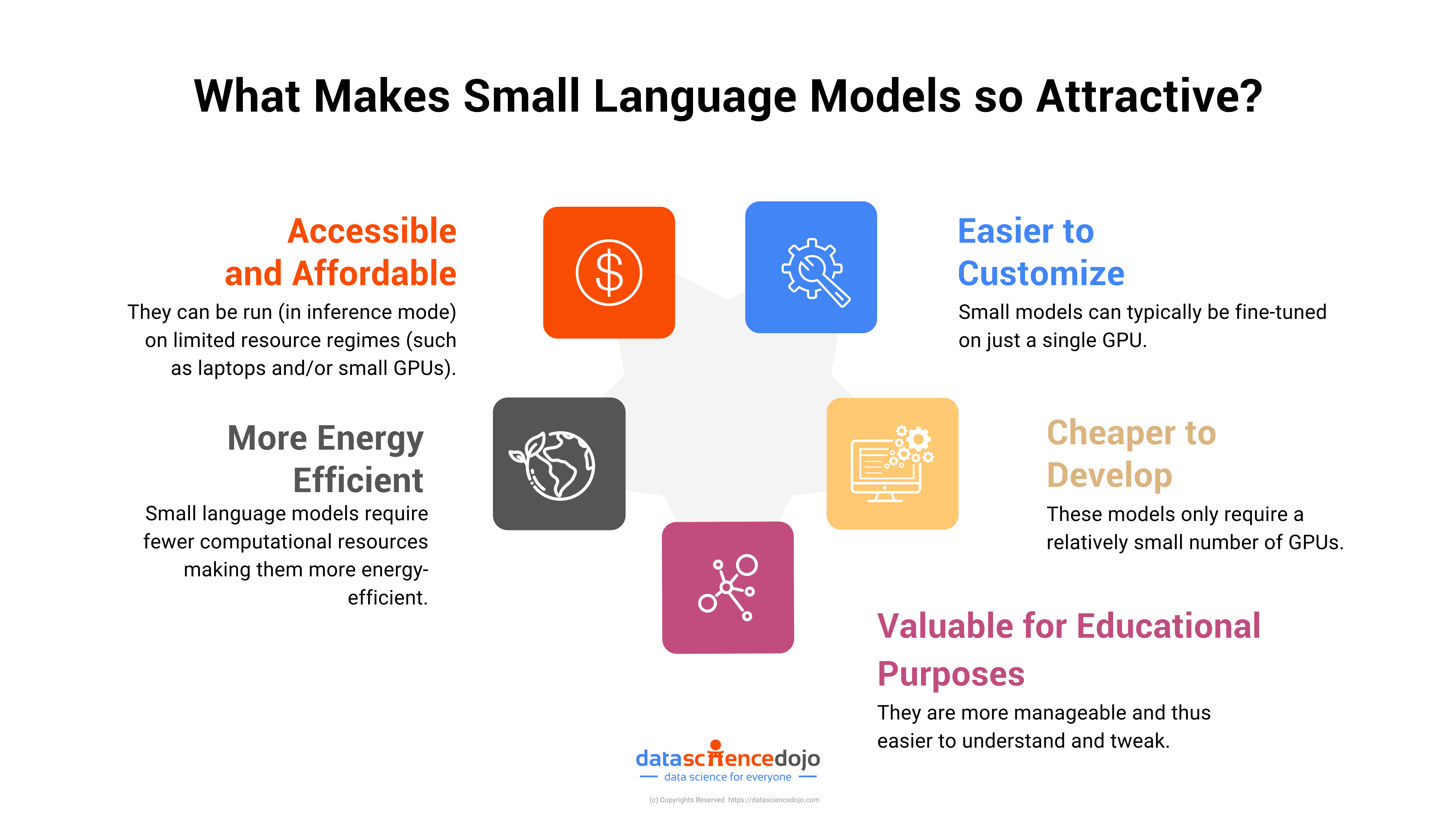
How Small Language Models Excel with Fewer Parameters?
Know more about Data Science in Healthcare

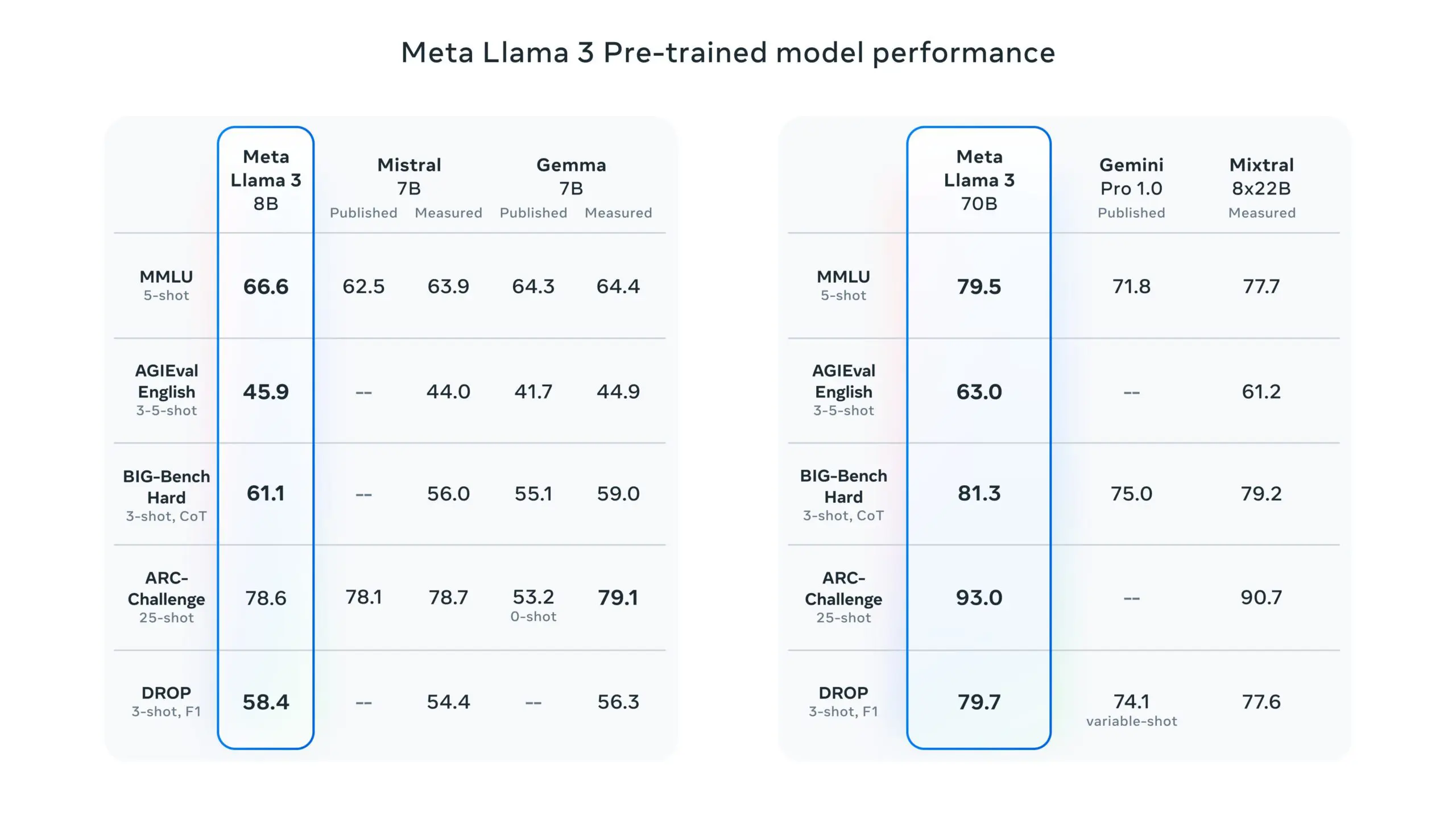
LLaMA 3 is an open-source language model developed by Meta. It’s part of Meta’s broader strategy to empower more extensive and responsible AI usage by providing the community with tools that are both powerful and adaptable.
This model builds upon the success of its predecessors by incorporating advanced training methods and architecture optimizations that enhance its performance across various tasks such as translation, dialogue generation, and complex reasoning.
Performance and Innovation
Meta’s LLaMA 3 has been trained on significantly larger datasets compared to earlier versions, utilizing custom-built GPU clusters that enable it to process vast amounts of data efficiently.
This extensive training has equipped LLaMA 3 with an improved understanding of language nuances and the ability to handle multi-step reasoning tasks more effectively. The model is particularly noted for its enhanced capabilities in generating more aligned and diverse responses, making it a robust tool for developers aiming to create sophisticated AI-driven applications.
Why LLaMA 3 Matters
The significance of LLaMA 3 lies in its accessibility and versatility. Being open-source, it democratizes access to state-of-the-art AI technology, allowing a broader range of users to experiment and develop applications.
This model is crucial for promoting innovation in AI, providing a platform that supports both foundational and advanced AI research. By offering an instruction-tuned version of the model, Meta ensures that developers can fine-tune LLaMA 3 to specific applications, enhancing both performance and relevance to particular domains.
Learn more about Meta’s Llama 3
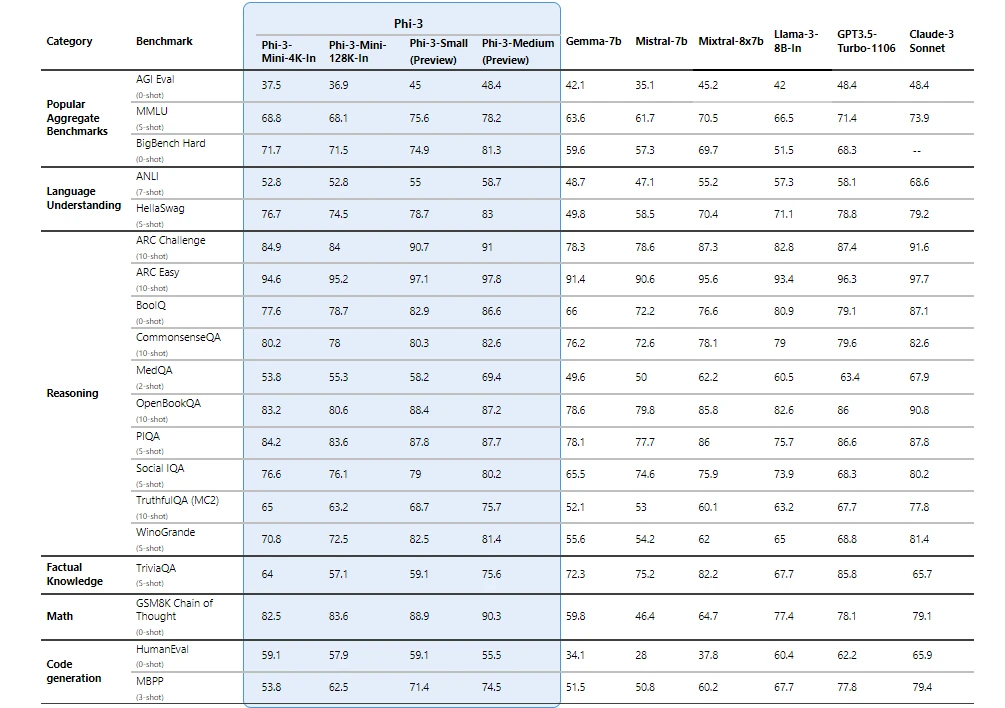
2. Phi 3 By Microsoft