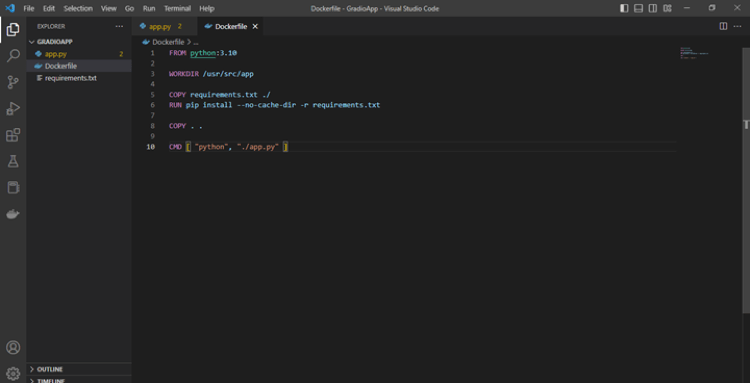
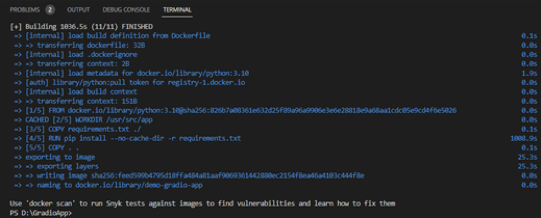
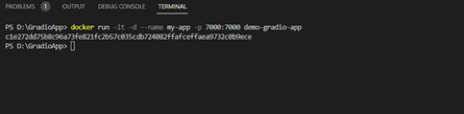
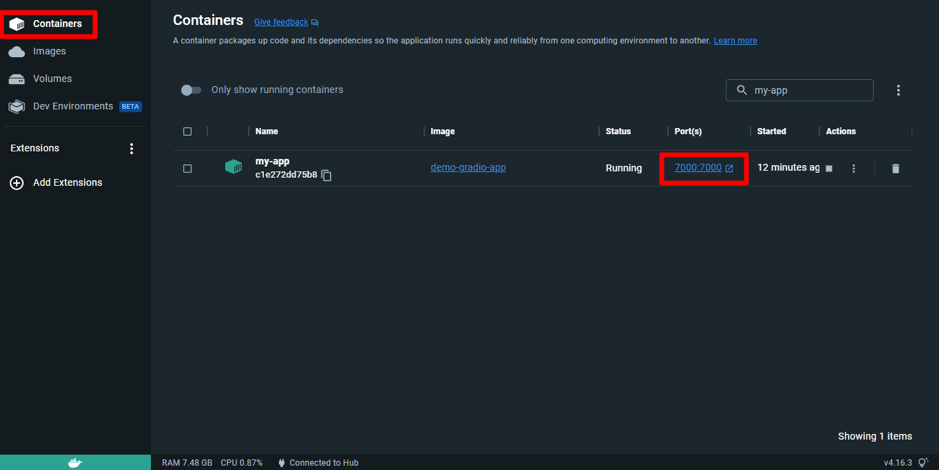
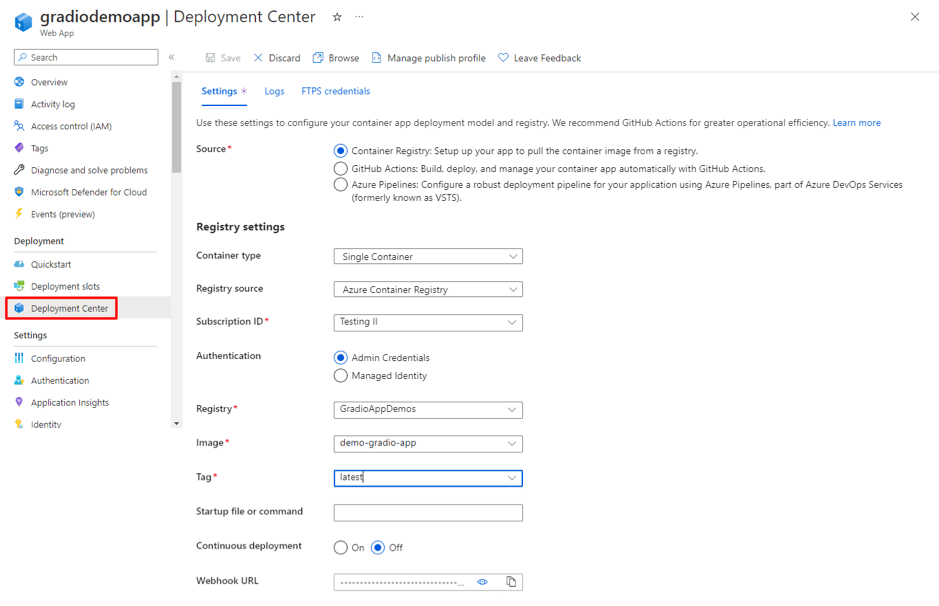
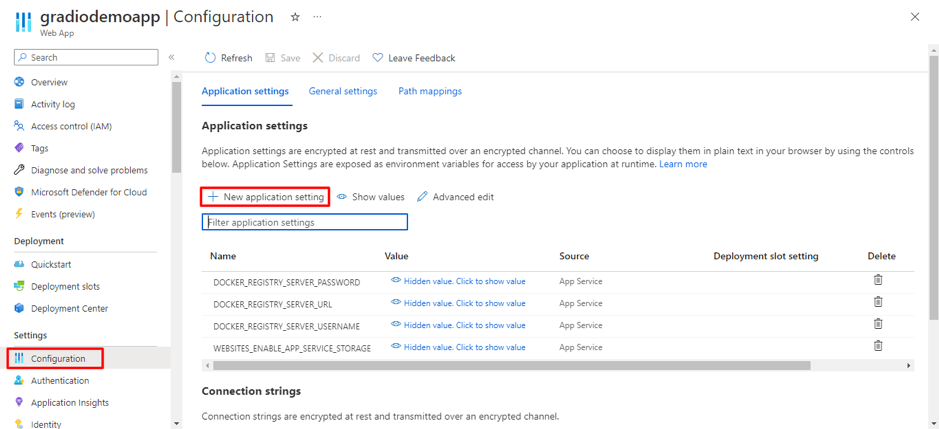
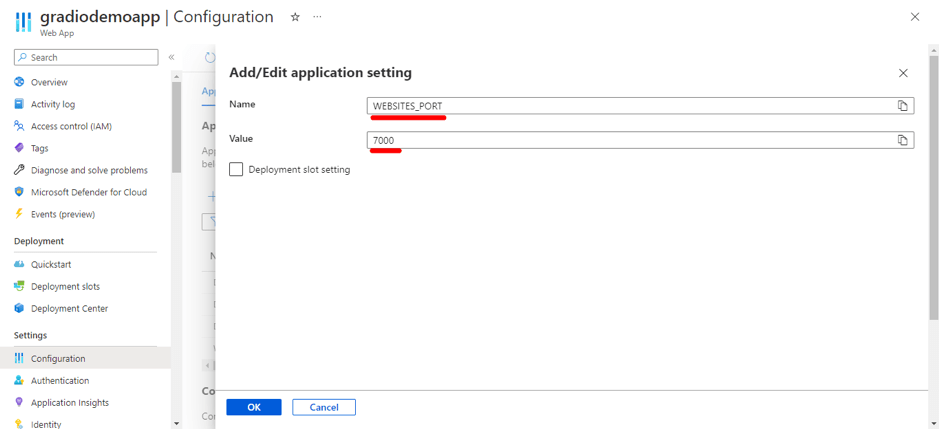
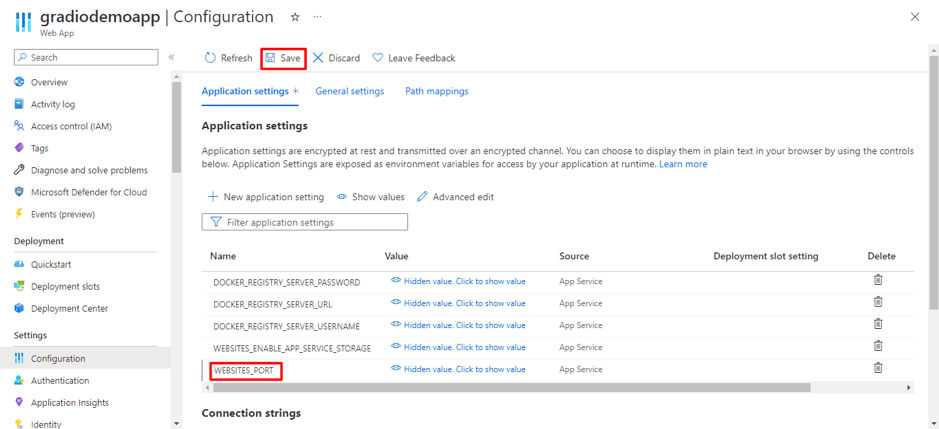
Data Science Dojo is offering Meltano CLI for FREE on Azure Marketplace preconfigured with Meltano, a platform that provides flexibility and scalability. It comprises four features, it is customizable, observable with a full view of data visualization, testable and versionable to track changes, and can easily be rolled back if needed.
It is somewhat of a tiring process to install the technology. Then look after the integration and dependency issues. Already feeling tired? It is somehow confusing to resolve the installation errors. Not to worry as Data Science Dojo’s Meltano CLI instance fixes all of that. But before we delve further into it, let us get to know some basics.
What is Meltano?
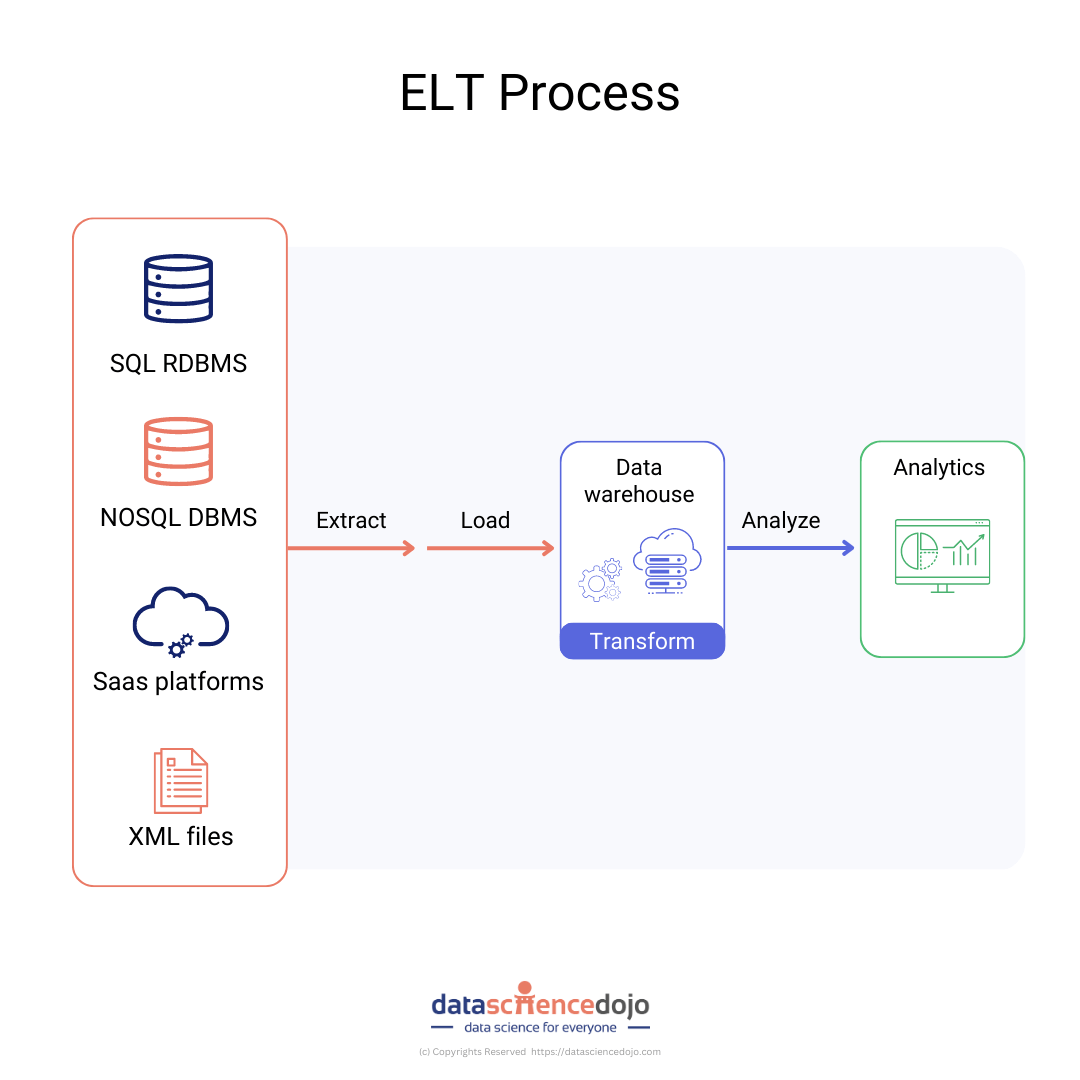
Meltano is an open-source Command Line Interface (CLI) tool that offers a flexible and scalable solution for Extract, Load, and Transform (ELT) processes. It is designed to assist data engineers in transforming, converting, and validating data in a simplified manner while ensuring accuracy and reliability.
The Meltano CLI can efficiently handle complex data engineering tasks, providing a user-friendly interface that simplifies the ELT process. It can also integrate with different data sources, enabling users to extract data from various sources, load it into a target destination, and transform it according to their specific requirements.
In addition, it offers a range of plugins that extend its capabilities and allow users to customize their ELT workflows. These plugins include extractors, loaders, and transformers, among others.
Challenges for individuals
Before Meltano CLI, there were several challenges associated with data integration that made the process difficult and time-consuming. Here are a few of the main challenges:
- Lack of Standardization: Data integration tools were often proprietary, which made it difficult to integrate different tools and workflows. This meant that organizations often had to use multiple tools to complete a data integration project.
- Complexity: Many data integration tools were complex and required extensive knowledge of programming and data architecture to use effectively. This made it difficult for non-technical users to participate in data integration projects.
- Scalability: As data volumes grew, many data integration tools struggled to handle the scale of the data. This led to slow and inefficient data integration processes.
- Cost: Many data integration tools were expensive, which made them inaccessible for smaller organizations with limited budgets.
- Limited Customization: Many data integration tools offered limited customization options, which made it difficult to adapt the tool to fit the unique needs of an organization.
All in all, it was designed to address many of these challenges by providing an open-source, flexible, and user-friendly tool that can be customized to fit the unique requirements of users.

Why Meltano?
Meltano CLI stands out as a data engineering tool. It provides flexibility and scalability. It comprises of four features, it is customizable, observable with a full view of data visualization, testable and versionable to track changes, and can easily be rolled back if needed.
Meltano CLI has solved many struggles that make it a compelling choice for many users, including:
- Open-source: It is free and open-source, which means that users can download, use, and modify the source code as per their needs.
- Easy-to-use: It is designed to be easy to use with a simple command-line interface and intuitive user interface. Users can easily configure, execute, and monitor data integration pipelines.
- Customizable: Meltano CLI offers a high degree of customization, allowing users to define custom transformations, connectors, and integrations.
- Modern stack: It is built using modern open-source technologies such as Python, Flask, and Vue.js, making it easy to extend and integrate with other tools.
- GitLab Integration: Meltano CLI is developed by GitLab, which means it can be easily integrated with GitLab for version control, collaboration, and continuous integration and deployment (CI/CD).
Overall, Meltano CLI is a powerful and flexible data integration tool that offers a unique set of features and benefits that may make it a good choice for certain data integration projects. However, the choice of tool ultimately depends on the specific needs and requirements of the project at hand.
Integrations
MeltanoHub is the primary location to find all plugins, including Singer taps and targets. It serves as a single source of truth for users, making it easy to discover and use plugins within Meltano. Additionally, users can contribute to the Hub by adding more plugins, which are immediately accessible.
The Hub is maintained by Meltano and the broader community, ensuring that it is continuously curated and up to date. This centralized platform simplifies the process of finding and using plugins, enabling users to enhance their data engineering workflows with ease.
Key features
Meltano CLI includes several features, including:
- Easy to setup and easy to use
- Pipeline creation and management
- Extract, transform, and load (ETL) processes
- Plugin management
- Visualization
- Configuration management
- Version control
- Testability
- Integration with other tools: It seamlessly integrates with other tools such as dbt, Singer, and Airflow, among others, to enhance your workflow.
What Data Science Dojo has for you?
Azure Virtual Machine is preconfigured with CLI plug-and-play functionality, so you do not have to worry about setting up the environment.
- Features include a zero-setup CLI platform that offers a high degree of customization, allowing users to define custom transformations, connectors, and integrations. It is designed to be easy to use with a simple command-line interface and intuitive user interface.
- Meltano CLI helps you efficiently transform, convert, and validate your data using a simplified process for data engineering, with the assurance of accuracy and reliability.
And many others which you check by taking a quick peek here: Meltano CLI on Azure Marketplace sets it apart from others is that it is an open-source, flexible, and scalable CLI for ELT+. It is customizable. It is also observable, provides a full view with detailed pipeline logs and statistics, and allows inspection of code for debugging. Meltano is versionable which allows easy tracking and rollback of changes. It is testable and only deploys to production once everything is green.
Moreover, Meltano CLI is a powerful and flexible data integration tool that offers many benefits over other tools on the market. Its open-source nature, ease of use, integration with other tools, reconfigurability, and community support make it a compelling choice for data integration projects.
Conclusion
The Meltano CLI comes with pre-configured Ubuntu 20.04 and a ready-to-use project, allowing for a plug-and-play experience without any setup required. By using Azure, the fault tolerance of data pipelines is increased, resulting in higher performance and faster content delivery.
The Meltano CLI provides an open-source, flexible, and scalable CLI for ELT+, allowing for efficient data transformation, conversion, and validation with accuracy and reliability. When combined with Microsoft Azure services, Meltano outperforms traditional methods by performing data-intensive computations in the cloud. Collaboration and sharing of notebooks with stakeholders is also possible.
At Data Science Dojo, we deliver data science education, consulting, and technical services to increase the power of data. We are therefore adding a free project Environment dedicated specifically to Data Integration and ELT on Azure Market Place. Do not wait to install this offer by Data Science Dojo, your ideal companion in your journey to learn data science!

Written by Insiyah Talib