
Data Science Dojo is offering Airbyte for FREE on Azure Marketplace packaged with a pre-configured web environment enabling you to quickly start the ELT process rather than spending time setting up the environment.
What is an ELT pipeline?
An ELT pipeline is a data pipeline that extracts (E) data from a source, loads (L) the data into a destination, and then transforms (T) data after it has been stored in the destination. The ELT process that is executed by an ELT pipeline is often used by the modern data stack to move data from across the enterprise into analytics systems.
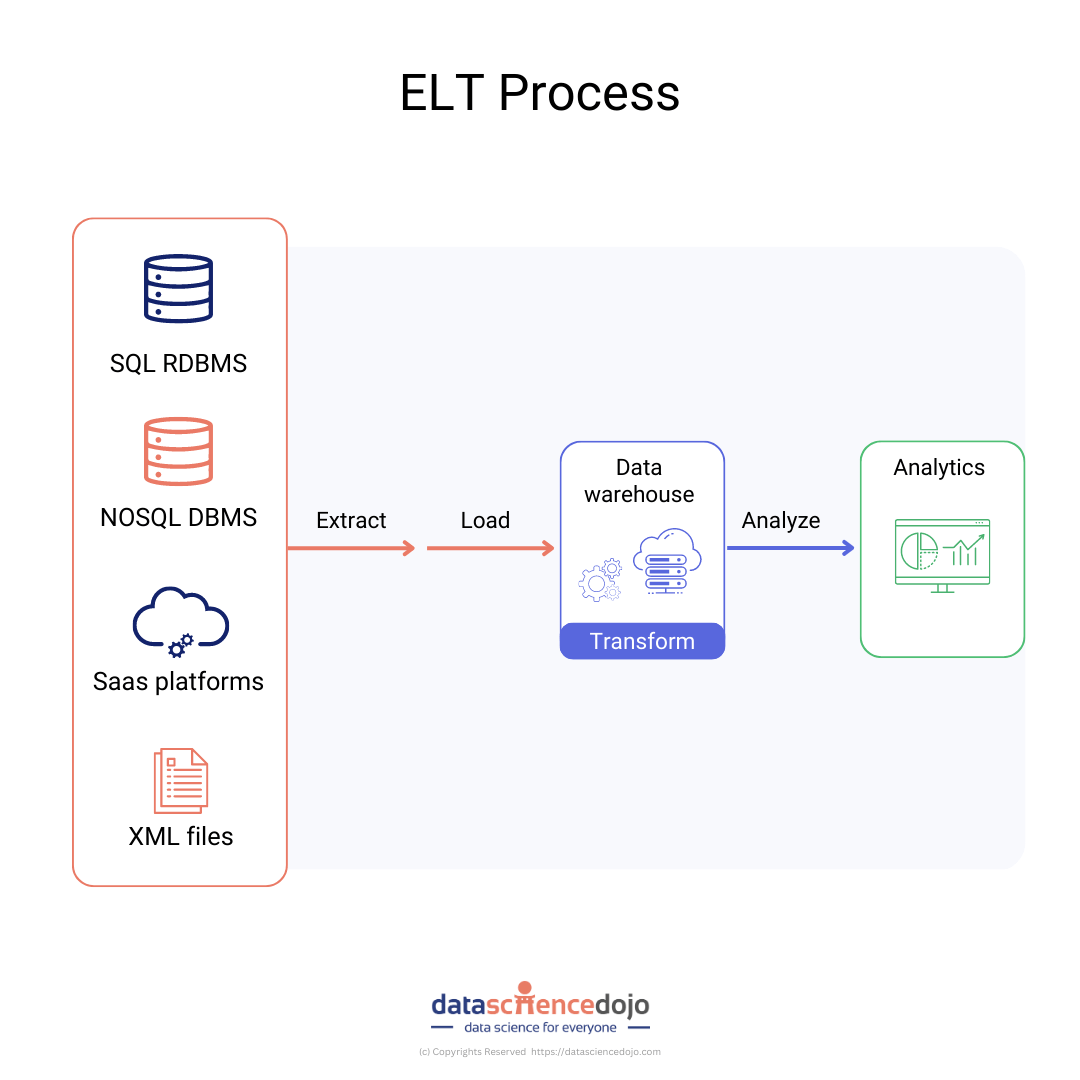
In other words, in the ELT approach, the transformation (T) of the data is done at the destination after the data has been loaded. The raw data that contains the data from a source record is stored in the destination as a JSON blob.
Airbyte’s architecture:
Airbyte is conceptually composed of two parts: platform and connectors.
The platform provides all the horizontal services required to configure and run data movement operations, for example, the UI, configuration API, job scheduling, logging, alerting, etc., and is structured as a set of microservices.
Connectors are independent modules that push/pull data to/from sources and destinations. Connectors are built under the Airbyte specification, which describes the interface with which data can be moved between a source and a destination using Airbyte. Connectors are packaged as Docker images, which allows total flexibility over the technologies used to implement them.
Obstacles for data engineers & developers
Collection and maintenance of data from different sources is itself a hectic task for data engineers and developers. Building a custom ELT pipeline for all of the data sources is a nightmare on top that not only consumes a lot of time for the engineers but also costs a lot.
In this scenario, a unified environment to deal with the quick data ingestions from various sources to various destinations would be great to tackle the mentioned challenges.
Methodology of Airbyte
Airbyte leverages DBT (data build tool) to manage and create SQL code that is used for transforming raw data in the destination. This step is sometimes referred to as normalization. An abstracted view of the data processing flow is given in the following figure:
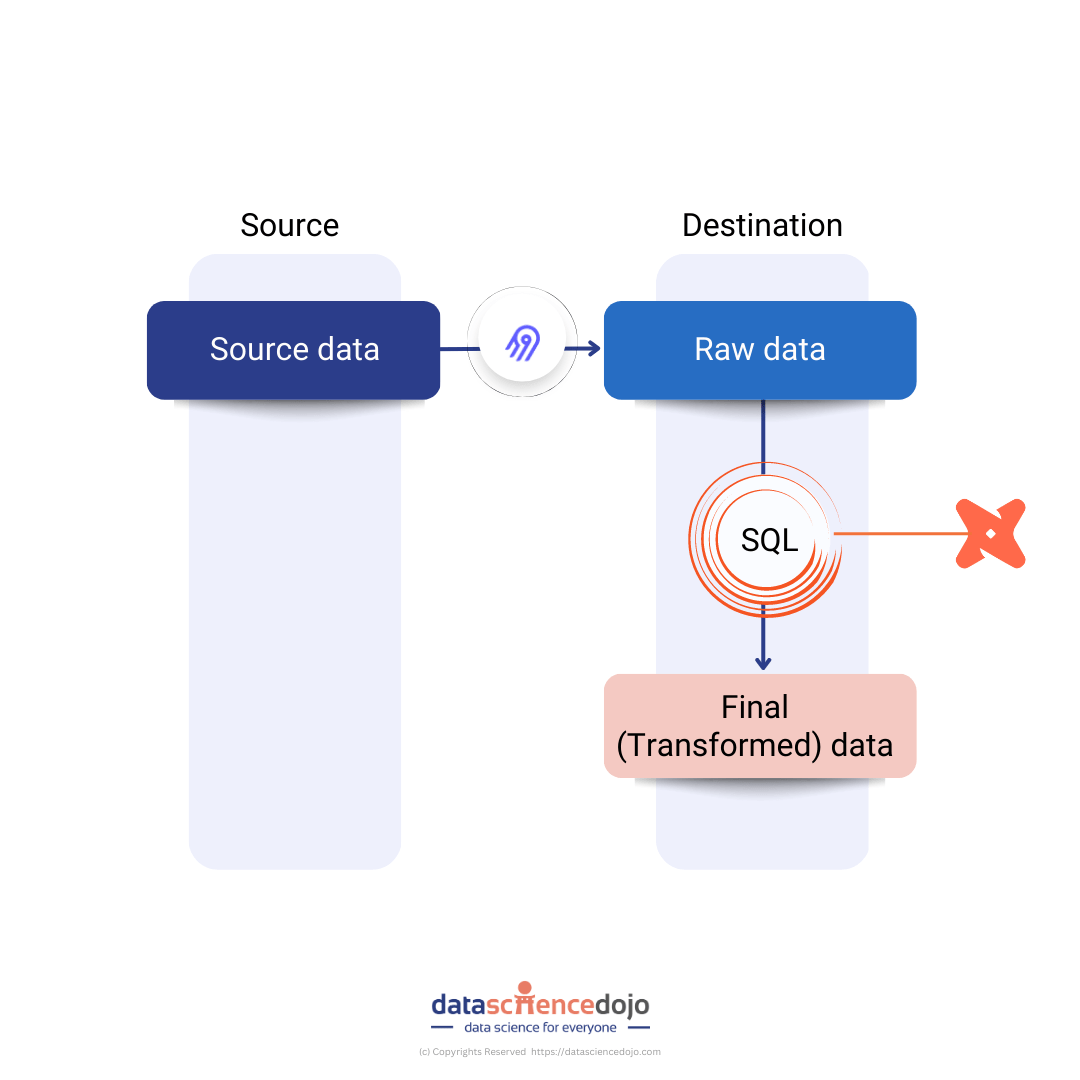
It is worth noting that the above illustration displays a core tenet of ELT philosophy, which is that data should be untouched as it moves through the extracting and loading stages so that the raw data is always available at the destination. Since an unmodified version of the data exists in the destination, it can be re-transformed in the future without the need for a resync of data from source systems.
Major features
Airbyte supports hundreds of data sources and destinations including:
- Apache Kafka
- Azure Event Hub
- Paste Data
- Other custom sources
By specifying credentials and adding extensions you can also ingest from and dump to:
- Azure Data Lake
- Google Cloud Storage
- Amazon S3 & Kinesis
Other major features that Airbyte offers:
- High extensibility: Use existing connectors to your needs or build a new one with ease.
- Customization: Entirely customizable, starting with raw data or from some suggestion of normalized data.
- Full-grade scheduler: Automate your replications with the frequency you need.
- Real-time monitoring: Logs all the errors in full detail to help you understand better.
- Incremental updates: Automated replications are based on incremental updates to reduce your data transfer costs.
- Manual full refresh: Re-syncs all your data to start again whenever you want.
- Debugging: Debug and Modify pipelines as you see fit, without waiting.
What does Data Science Dojo provide?
Airbyte instance packaged by Data Science Dojo serves as a pre-configured ELT pipeline that makes data integration pipelines a commodity without the burden of installation. It offers efficient data migration and supports a variety of data sources and destinations to ingest and dump data.
Features included in this offer:
- Airbyte service that is easily accessible from the web and has a rich user interface.
- Easy to operate and user-friendly.
- Strong community support due to the open-source platform.
- Free to use.
Conclusion
There are a ton of small services that aren’t supported on traditional data pipeline platforms. If you can’t import all your data, you may only have a partial picture of your business. Airbyte solves this problem through custom connectors that you can build for any platform and make them run quickly.
Install the Airbyte offer now from the Azure Marketplace by Data Science Dojo, your ideal companion in your journey to learn data science!
Click on the button below to head over to the Azure Marketplace and deploy Airbyte for FREE by clicking below:
