In the debate of LlamaIndex vs LangChain, developers can align their needs with the capabilities of both tools, resulting in an efficient application.
LLMs have become indispensable in various industries for tasks such as generating human-like text, translating languages, and providing answers to questions. At times, the LLM responses amaze you, as they are more prompt and accurate than humans. This demonstrates their significant impact on the technology landscape today.
As we delve into the arena of artificial intelligence, two tools emerge as pivotal enablers: LLamaIndex and LangChain. LLamaIndex offers a distinctive approach, focusing on data indexing and enhancing the performance of LLMs, while LangChain provides a more general-purpose framework, flexible enough to pave the way for a broad spectrum of LLM-powered applications.
Although both LlamaIndex and LangChain are capable of developing comprehensive generative AI applications, each focuses on different aspects of the application development process.
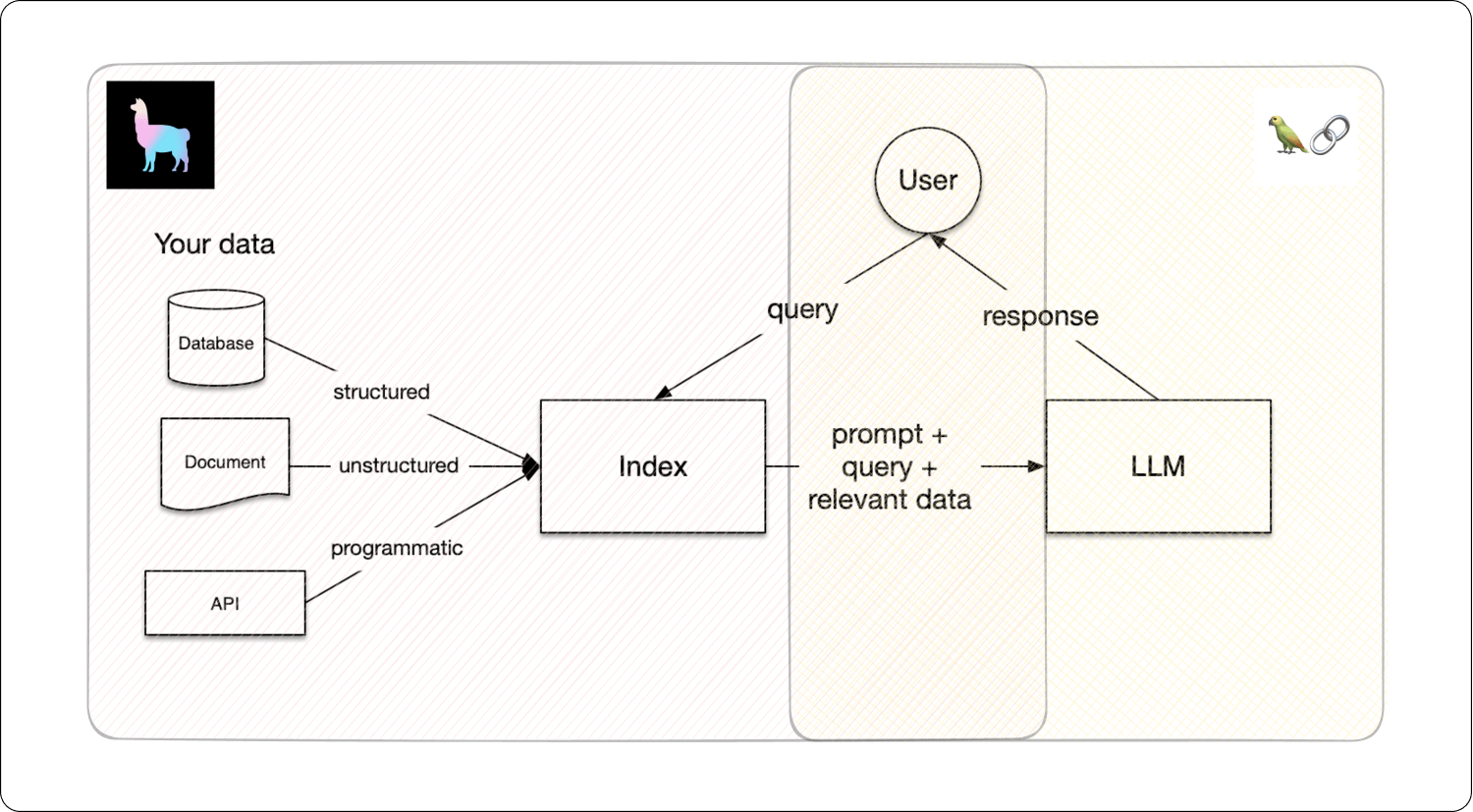
The figure below illustrates how LlamaIndex is more concerned with the initial stages of data handling—like loading, ingesting, and indexing to form a base of knowledge. In contrast, LangChain focuses on the latter stages, particularly on facilitating interactions between the AI (large language models, or LLMs) and users through multi-agent systems.
Source: Superwise.AI
Essentially, the combination of LlamaIndex’s data management capabilities with LangChain’s user interaction enhancement can lead to more powerful and efficient generative AI applications. Let’s begin by understanding each of the two framework’s roles in building LLMs.
LLamaIndex: The Bridge between Data and LLM Power
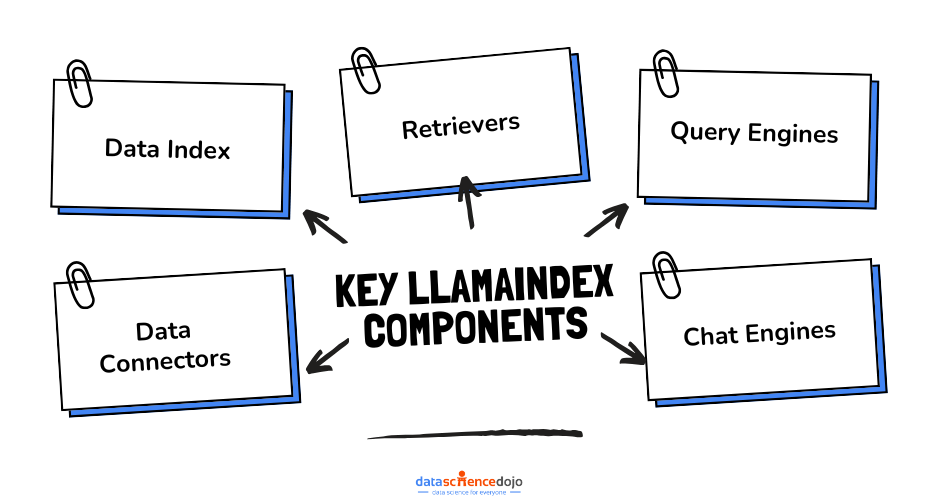
LLamaIndex steps forward as an essential tool, allowing users to build structured data indexes, use multiple LLMs for diverse applications, and improve data queries using natural language.
It stands out for its data connectors and index-building prowess, which streamline data integration by ensuring direct data ingestion from native sources, fostering efficient data retrieval, and enhancing the quality and performance of data used with LLMs.
LLamaIndex distinguishes itself with its engines, which create a symbiotic relationship between data sources and LLMs through a flexible framework. This remarkable synergy paves the way for applications like semantic search and context-aware query engines that consider user intent and context, delivering tailored and insightful responses.
Learn all about LlamaIndex from its Co-founder and CEO, Jerry Liu, himself!
LlamaIndex Features
LlamaIndex is an innovative tool designed to enhance the utilization of large language models (LLMs) by seamlessly connecting your data with the powerful computational capabilities of these models. It possesses a suite of features that streamline data tasks and amplify the performance of LLMs for a variety of applications, including:
Data Connectors:
Data connectors simplify the integration of data from various sources into the data repository, bypassing manual and error-prone extraction, transformation, and loading (ETL) processes.
These connectors enable direct data ingestion from native formats and sources, eliminating the need for time-consuming data conversions.
Advantages of using data connectors include automated enhancement of data quality, data security via encryption, improved data performance through caching, and reduced maintenance for data integration solutions.
Engines:
LLamaIndex Engines are the driving force that bridges LLMs and data sources, ensuring straightforward access to real-world information.
The engines are equipped with smart search systems that comprehend natural language queries, allowing for smooth interactions with data.
They are not only capable of organizing data for expeditious access but also enriching LLM-powered applications by adding supplementary information and aiding in LLM selection for specific tasks.
Data Agents:
Data agents are intelligent, LLM-powered components within LLamaIndex that perform data management effortlessly by dealing with various data structures and interacting with external service APIs.
These agents go beyond static query engines by dynamically ingesting and modifying data, adjusting to ever-changing data landscapes.
Building a data agent involves defining a decision-making loop and establishing tool abstractions for a uniform interaction interface across different tools.
LLamaIndex supports OpenAI Function agents as well as ReAct agents, both of which harness the strength of LLMs in conjunction with tool abstractions for a new level of automation and intelligence in data workflows.
The real strength of LLamaIndex is revealed through its wide array of integrations with other tools and services, allowing the creation of powerful, versatile LLM-powered applications.
Integrations with vector stores like Pinecone and Milvus facilitate efficient document search and retrieval.
LLamaIndex can also merge with tracing tools such as Graphsignal for insights into LLM-powered application operations and integrate with application frameworks such as Langchain and Streamlit for easier building and deployment.
Integrations extend to data loaders, agent tools, and observability tools, thus enhancing the capabilities of data agents and offering various structured output formats to facilitate the consumption of application results.
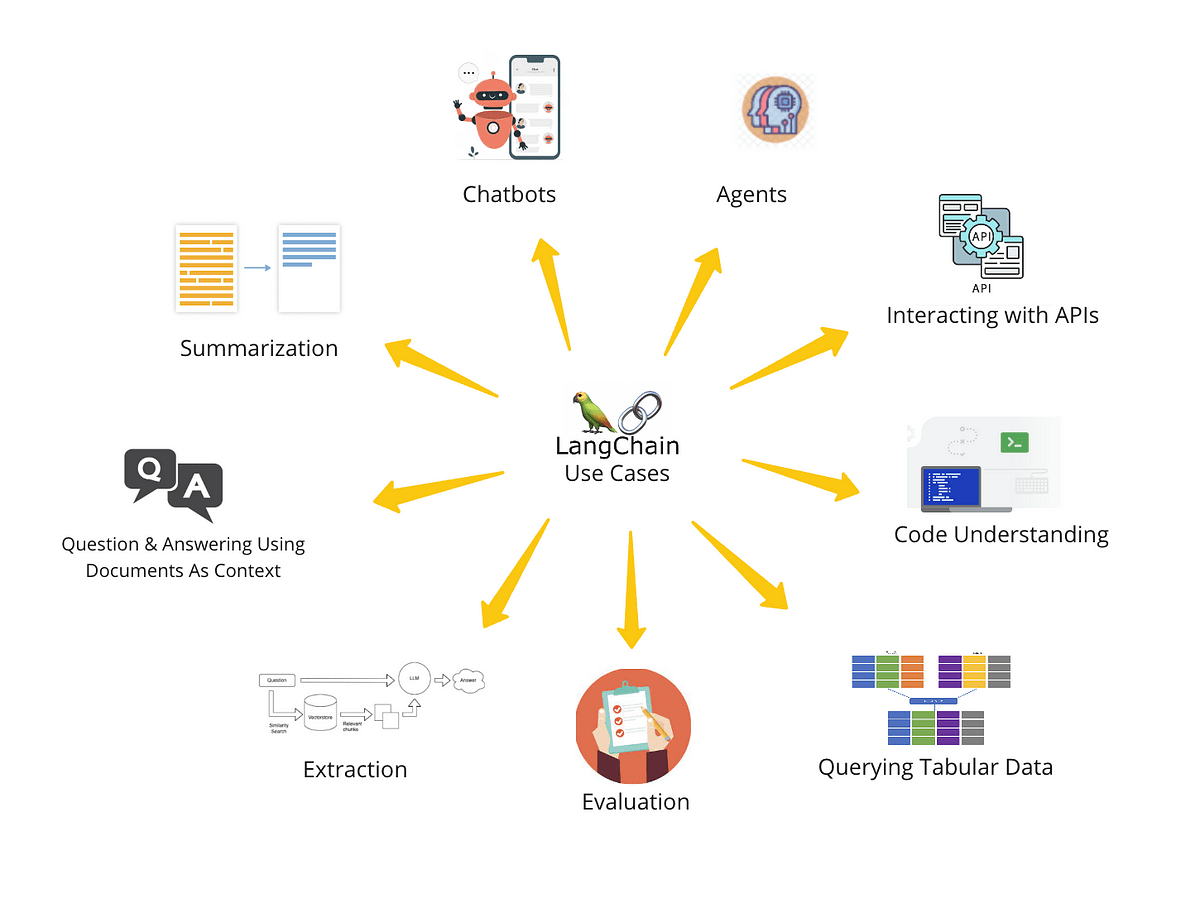
LangChain: The Flexible Architect for LLM-Infused Applications
In contrast, LangChain emerges as a master of versatility. It’s a comprehensive, modular framework that empowers developers to combine LLMs with various data sources and services.
LangChain thrives on its extensibility, wherein developers can orchestrate operations such as retrieval augmented generation (RAG), crafting steps that use external data in the generative processes of LLMs. With RAG, LangChain acts as a conduit, transporting personalized data during creation, embodying the magic of tailoring output to meet specific requirements.
Features of LangChain
Key components of LangChain include Model I/O, retrieval systems, and chains.
Model I/O:
LangChain’s Module Model I/O facilitates interactions with LLMs, providing a standardized and simplified process for developers to integrate LLM capabilities into their applications.
It includes prompts that guide LLMs in executing tasks, such as generating text, translating languages, or answering queries.
Multiple LLMs, including popular ones like the OpenAI API, Bard, and Bloom, are supported, ensuring developers have access to the right tools for varied tasks.
The input parsers component transforms user input into a structured format that LLMs can understand, enhancing the applications’ ability to interact with users.
One of the standout features of LangChain is the Retrieval Augmented Generation (RAG), which enables LLMs to access external data during the generative phase, providing personalized outputs.
Another core component is the Document Loaders, which provide access to a vast array of documents from different sources and formats, supporting the LLM’s ability to draw from a rich knowledge base.
Text embedding models are used to create text embeddings that capture the semantic meaning of texts, improving related content discovery.
Vector Stores are vital for efficient storage and retrieval of embeddings, with over 50 different storage options available.
Different retrievers are included, offering a range of retrieval algorithms from basic semantic searches to advanced techniques that refine performance.
LangChain introduces Chains, a powerful component for building more complex applications that require the sequential execution of multiple steps or tasks.
Chains can either involve LLMs working in tandem with other components, offer a traditional chain interface, or utilize the LangChain Expression Language (LCEL) for chain composition.
Both pre-built and custom chains are supported, indicating a system designed for versatility and expansion based on the developer’s needs.
The Async API is featured within LangChain for running chains asynchronously, reinforcing the usability of elaborate applications involving multiple steps.
Custom Chain creation allows developers to forge unique workflows and add memory (state) augmentation to Chains, enabling a memory of past interactions for conversation maintenance or progress tracking.
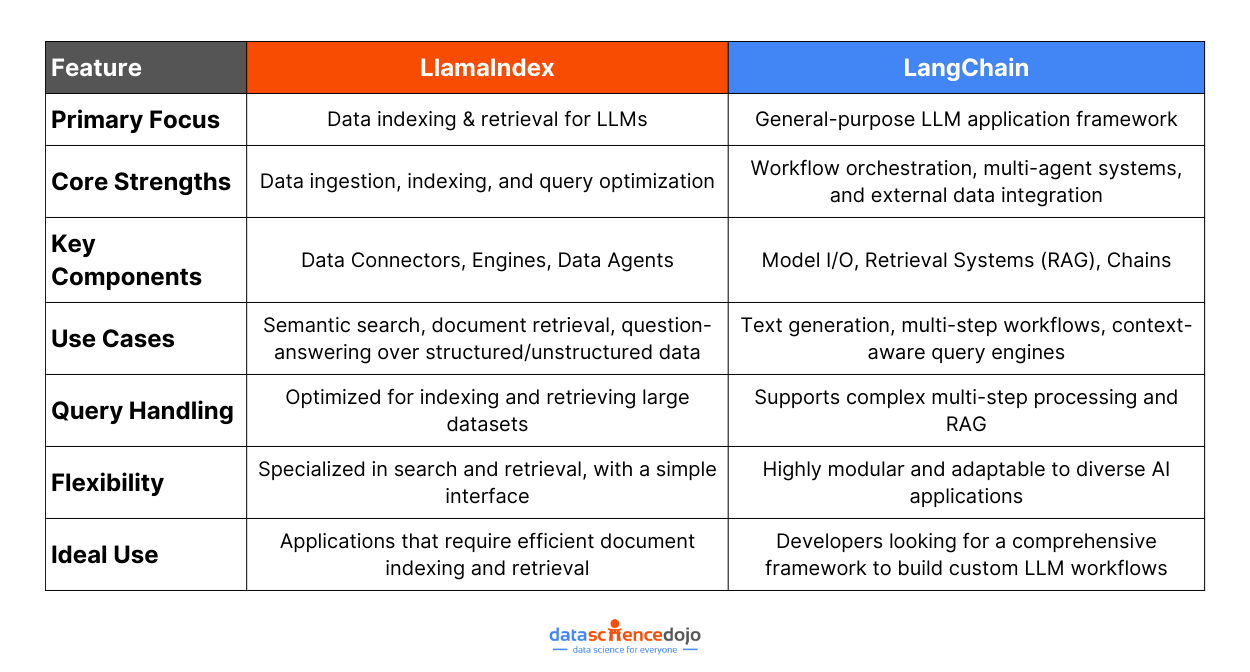
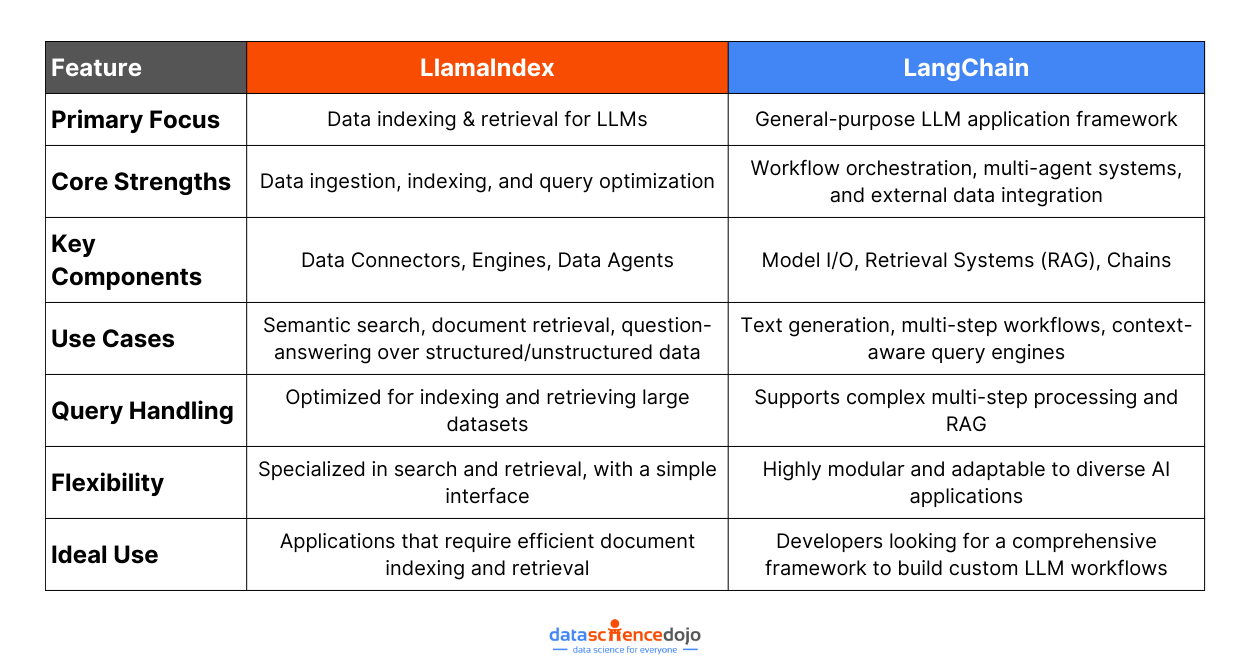
Comparing LLamaIndex and LangChain
When we compare LLamaIndex with LangChain, we see complementary visions that aim to maximize the capabilities of LLMs. LLamaIndex is the superhero of tasks that revolve around data indexing and LLM augmentation, like document search and content generation.
On the other hand, LangChain boasts its prowess in building robust, adaptable applications across a plethora of domains, including text generation, translation, and summarization.
As developers and innovators seek tools to expand the reach of LLMs, delving into the offerings of LLamaIndex and LangChain can guide them toward creating standout applications that resonate with efficiency, accuracy, and creativity.
Focused Approach vs Flexibility
LlamaIndex:
Purposefully crafted for search and retrieval applications, giving it an edge in efficient indexing and organizing data for swift access.
Features a simplified interface that allows querying LLMs straightforwardly, leading to pertinent document retrieval.
Optimized explicitly for indexing and retrieval, leading to higher accuracy and speed in search and summarization tasks.
Specialized in handling large amounts of data efficiently, making it highly suitable for dedicated search and retrieval tasks that demand robust performance.
Offers a simple interface designed primarily for constructing search and retrieval applications, facilitating straightforward interactions with LLMs for efficient document retrieval.
Specializes in the indexing and retrieval process, thus optimizing search and summarization capabilities to manage large amounts of data effectively.
Allows for creating organized data indexes, with user-friendly features that streamline data tasks and enhance LLM performance.
Presents a comprehensive and modular framework adept at building diverse LLM-powered applications with general-purpose functionalities.
Provides a flexible and extensible structure that supports a variety of data sources and services, which can be artfully assembled to create complex applications.
Includes tools like Model I/O, retrieval systems, chains, and memory systems, offering control over the LLM integration to tailor solutions for specific requirements.
Presents a comprehensive and modular framework adept at building diverse LLM-powered applications with general-purpose functionalities.
Provides a flexible and extensible structure that supports a variety of data sources and services, which can be artfully assembled to create complex applications.
Includes tools like Model I/O, retrieval systems, chains, and memory systems, offering control over the LLM integration to tailor solutions for specific requirements.
Use Cases and Case Studies
LlamaIndex is engineered to harness the strengths of large language models for practical applications, with a primary focus on streamlining search and retrieval tasks. Below are detailed use cases for LlamaIndex, specifically centered around semantic search, and case studies that highlight its indexing capabilities:
Semantic Search with LlamaIndex:
Tailored to understand the intent and contextual meaning behind search queries, it provides users with relevant and actionable search results.
Utilizes indexing capabilities that lead to increased speed and accuracy, making it an efficient tool for semantic search applications.
Empower developers to refine the search experience by optimizing indexing performance and adhering to best practices that suit their application needs.
Data Indexes: LlamaIndex’s data indexes are akin to a super-speedy assistant’ for data searches, enabling users to interact with their data through question-answering and chat functions efficiently.
Engines: At the heart of indexing and retrieval, LlamaIndex engines provide a flexible structure that connects multiple data sources with LLMs, thereby enhancing data interaction and accessibility.
Data Agents: LlamaIndex also includes data agents, which are designed to manage both “read” and “write” operations. They interact with external service APIs and handle unstructured or structured data, further boosting automation in data management.
Source: Medium
Due to its granular control and adaptability, LangChain’s framework is specifically designed to build complex applications, including context-aware query engines. Here’s how LangChain facilitates the development of such sophisticated applications:
Context-Aware Query Engines: LangChain allows the creation of context-aware query engines that consider the context in which a query is made, providing more precise and personalized search results.
Flexibility and Customization: Developers can utilize LangChain’s granular control to craft custom query processing pipelines, which is crucial when developing applications that require understanding the nuanced context of user queries.
Integration of Data Connectors: LangChain enables the integration of data connectors for effortless data ingestion, which is beneficial for building query engines that pull contextually relevant data from diverse sources.
Optimization for Specific Needs: With LangChain, developers can optimize performance and fine-tune components, allowing them to construct context-aware query engines that cater to specific needs and provide customized results, thus ensuring the most optimal search experience for users.
Which Framework Should I Choose? LlamaIndex vs LangChain
Understanding these unique aspects empowers developers to choose the right framework for their specific project needs:
Opt for LlamaIndex if you are building an application with a keen focus on search and retrieval efficiency and simplicity, where high throughput and processing of large datasets are essential.
Choose LangChain if you aim to construct more complex, flexible LLM applications that might include custom query processing pipelines, multimodal integration, and a need for highly adaptable performance tuning.
In conclusion, by recognizing the unique features and differences between LlamaIndex and LangChain, developers can more effectively align their needs with the capabilities of these tools, resulting in the construction of more efficient, powerful, and accurate search and retrieval applications powered by large language models.
Retrieval-Augmented Generation (RAG) has completely transformed how we search and interact with large language models (LLMs), making information retrieval smarter and more dynamic. But here’s the catch—one key factor that can make or break your RAG system’s performance is chunk size.
Get it wrong, and you might end up with incomplete answers or sluggish retrieval. Get it right, and your system runs like a well-oiled machine, delivering fast, accurate, and contextually rich responses.
So, how do you find that sweet spot for chunk size? That’s where LlamaIndex’s Response Evaluation tool comes in. In this article, we’ll walk you through how to leverage this powerful tool to fine-tune your RAG application and optimize chunk size for seamless, efficient retrieval. Let’s dive in!
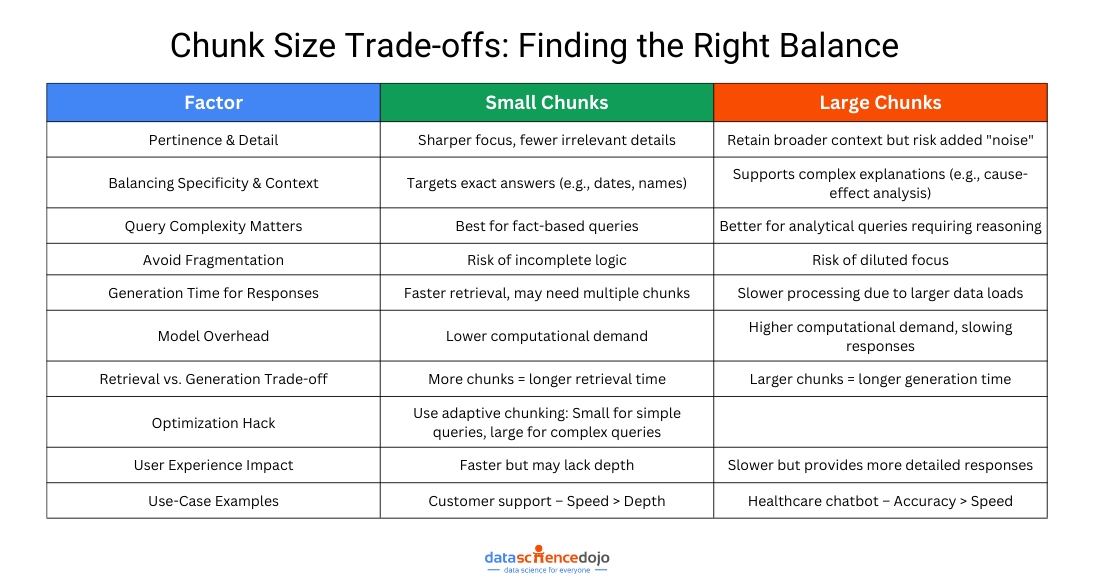
Why Chunk Size Matters in the RAG Application System?
When retrieving information, precision is everything. If your chunks are too small, key details might get lost. If they’re too large, the model might struggle to pinpoint the most relevant information quickly. This delicate balance directly affects how well your RAG system understands and responds to queries.
In this section, we’ll explore how chunk size affects pertinence and detail and response speed, helping you strike the perfect balance for seamless performance.
Pertinence and Detail
When retrieving information, detail and relevance go hand in hand. If a chunk is too small, it captures fine details but risks leaving out crucial context. If it’s too large, it ensures all necessary information is included but might overwhelm the model with unnecessary data.
Take a chunk size of 256 tokens—it creates more detailed, focused segments, but the downside is that important details might get split across multiple chunks, making retrieval less efficient.
On the other hand, a chunk size of 512 tokens keeps more context within each chunk, increasing the chances of retrieving all vital information at once. But if too much is packed into a single chunk, the model might struggle to pinpoint the most relevant parts.
To navigate this challenge, we look at two key factors:
Faithfulness: Does the model stick to the original source, or does it introduce inaccuracies (hallucinations)? A well-balanced chunk size helps keep responses grounded in reliable data.
Relevance: Is the retrieved information actually useful for answering the query? The right chunking ensures responses are clear, focused, and on-point.
By finding the ideal chunk size, you can create RAG applications that retrieves detailed yet relevant information—striking the perfect balance between accuracy and efficiency.
Generation Time for Responses
Chunk size doesn’t just determine what information gets retrieved—it also affects how quickly responses are generated. Larger chunks provide more context but require more processing power, potentially slowing down response time. Smaller chunks, on the other hand, allow for faster retrieval but may lack the full context needed for a high-quality answer.
Striking the right balance depends on your use case. If speed is the priority, such as in real-time applications, smaller chunks are the better choice. But if depth and accuracy matter more, slightly larger chunks help ensure completeness.
Ultimately, it’s all about optimization—finding the ideal chunk size that keeps responses fast, relevant, and contextually rich without unnecessary delays.
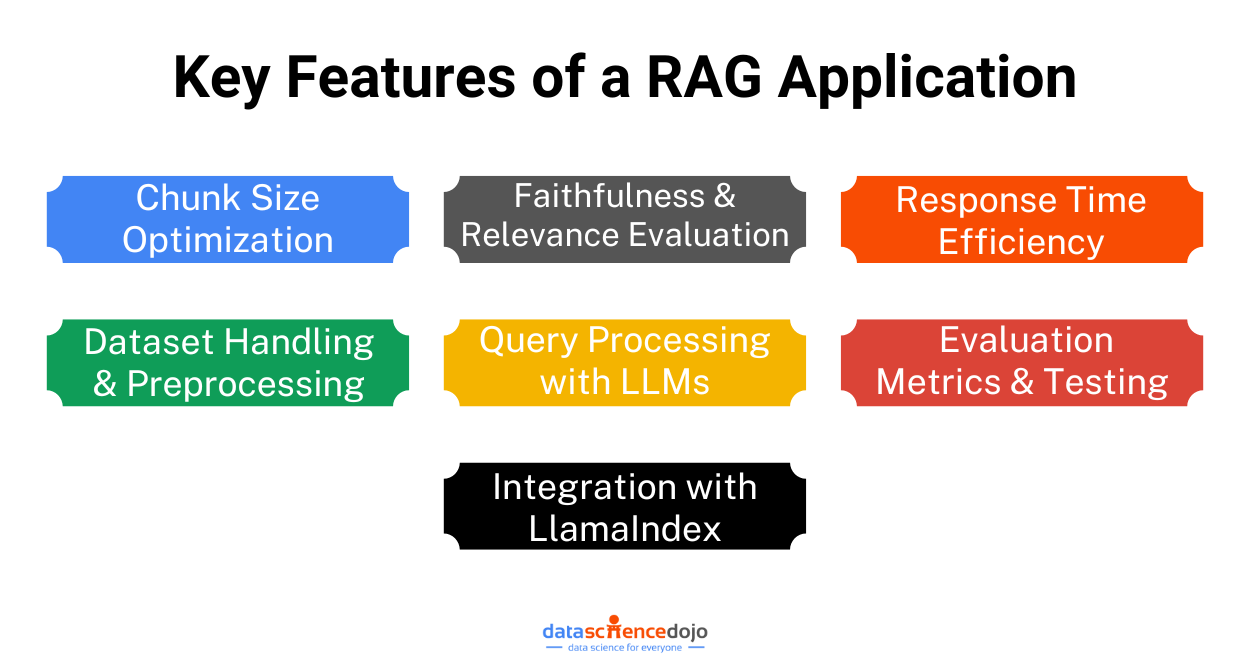
All About Application Evaluation
Evaluating a RAG system’s performance is just as important as fine-tuning its chunk size. However, traditional NLP evaluation methods—like BLEU or F1 scores—are becoming less reliable, as they don’t always align with human judgment. With the rapid advancements in LLMs, more sophisticated evaluation techniques are needed to ensure accuracy and relevance.
We’ve already touched on faithfulness and relevance earlier in this blog, but now it’s time to take a deeper dive into how these aspects can be effectively measured. Ensuring that a model retrieves accurate and relevant information is crucial for maintaining trust and usability, and that’s where dedicated evaluation mechanisms come into play.
Faithfulness Evaluation – This goes beyond just checking if a response is based on the retrieved chunks. It specifically identifies whether the model introduces hallucinations—statements that seem plausible but aren’t actually supported by the source data. A faithful response should strictly adhere to the retrieved information without adding anything misleading.
Relevance Evaluation – Even if a response is factually correct, it must also be useful and on-point. This evaluation ensures that the retrieved information directly answers the query, rather than providing vague or tangential details. A relevant response should closely align with what the user is asking for.
To put these evaluation methods into practice, we’ll configure GPT-3.5-turbo as our core evaluation tool. By leveraging its capabilities, we can systematically assess responses and refine our RAG system for both accuracy and efficiency.
In order to determine the appropriate chunk size, we will calculate metrics such as average response time, average faithfulness, and average relevancy across different chunk sizes.
Downloading Dataset
We will be using the IRS armed forces tax guide for this experiment.
mkdir is used to make a folder. Here we are making a folder named dataset in the root directory.
wget command is used for non-interactive downloading of files from the web. It allows users to retrieve content from web servers, supporting various protocols like HTTP, HTTPS, and FTP.
Load Dataset
SimpleDirectoryReader class will help us to load all the files in the dataset directory.
document[0:10] represents that we will only be loading the first 10 pages of the file for the sake of simplicity.
Defining the Question Bank
These questions will help us to evaluate metrics for different chunk sizes.
Establishing Evaluators
This code initializes an OpenAI language model (GPT-3.5-turbo) with temperature=0 settings and instantiates evaluators for measuring faithfulness and relevancy, utilizing the ServiceContext module with default configurations.
Main Evaluator Method
We will be evaluating each chunk size based on 3 metrics.
Next, the function initializes variables for tracking various metrics:
totalResponseTime: Tracks the cumulative response time for all questions.
totalFaithfulness: Tracks the cumulative faithfulness score for all questions.
totalRelevancy: Tracks the cumulative relevancy score for all questions.
It records the start time before querying the queryEngine for a response to the current question.
It calculates the elapsed time for the query by subtracting the start time from the current time.
The function evaluates the faithfulness of the response using faithfulnessLLM.evaluate_response and stores the result in the faithfulnessResult variable.
Similarly, it evaluates the relevancy of the response using relevancyLLM.evaluate_response and stores the result in the relevancyResult variable.
The function accumulates the elapsed time, faithfulness result, and relevancy result in their respective total variables.
After evaluating all the questions, the function computes the averages
Testing Different Chunk Sizes
To find out the best chunk size for our data, we have defined a list of chunk sizes then we will traverse through the list of chunk sizes and find out the average response time, average faithfulness, and average relevance with the help of the evaluator method.
After this, we will convert our data list into a data frame with the help of Pandas DataFrame class to view it in a fine manner.
From the illustration, it is evident that the chunk size of 128 exhibits the highest average faithfulness and relevancy while maintaining the second-lowest average response time.
Use LlamaIndex to Construct a RAG Application System
Selecting the right chunk size for a RAG system isn’t just a one-time decision—it’s an ongoing process of testing and refinement. While intuition can provide a starting point, real optimization comes from data-driven experimentation.
By leveraging LlamaIndex’s Response Evaluation module, we can systematically test different chunk sizes, analyze their impact on response time, faithfulness, and relevance, and make well-informed decisions. This ensures that our system strikes the right balance between speed, accuracy, and contextual depth.
At the end of the day, chunk size plays a pivotal role in a RAG system’s overall effectiveness. Taking the time to carefully evaluate and fine-tune it leads to a system that is not only faster and more reliable but also delivers more precise and contextually relevant responses.
Optimizing RAG Efficiency with LlamaIndex: Finding the Perfect Chunk Size
The integration of retrieval-augmented generation (RAG) has revolutionized the fusion of robust search capabilities with the LLM, amplifying the potential for dynamic information retrieval. Within the implementation of a RAG system, a pivotal factor governing its efficiency and performance lies in the determination of the optimal chunk size. How does one identify the most effective chunk size for seamless and efficient retrieval? This is precisely where the comprehensive assessment provided by the LlamaIndex Response Evaluation tool becomes invaluable. In this article, we will provide a comprehensive walkthrough, enabling you to discern the ideal chunk size through the powerful features of LlamaIndex’s Response Evaluation module.
Why chunk size matters
Selecting the appropriate chunk size is a crucial determination that holds sway over the effectiveness and precision of a RAG system in various ways:
Pertinence and Detail: Opting for a smaller chunk size, such as 256, results in more detailed segments. However, this heightened detail brings the potential risk that pivotal information might not be included in the foremost retrieved segments. On the contrary, a chunk size of 512 is likely to encompass all vital information within the leading chunks, ensuring that responses to inquiries are readily accessible. To navigate this challenge, we will employ the Faithfulness and Relevancy metrics. These metrics gauge the absence of ‘hallucinations’ and the ‘relevancy’ of responses concerning the query and the contexts retrieved, respectively.
Generation Time for Responses: With an increase in the chunk size, the volume of information directed into the LLM for generating a response also increases. While this can guarantee a more comprehensive context, it might potentially decelerate the system. Ensuring that the added depth doesn’t compromise the system’s responsiveness, is pivot.
Ultimately, finding the ideal chunk size boils down to achieving a delicate equilibrium. Capturing all crucial information while maintaining operational speed. It’s essential to conduct comprehensive testing with different sizes to discover a setup that aligns with the unique use case and dataset requirements.
Why evaluation?
The discussion surrounding evaluation in the field of NLP has been contentious, particularly with the advancements in NLP methodologies. Consequently, traditional evaluation techniques like BLEU or F1, once relied upon for assessing models, are now considered unreliable due to their limited correspondence with human evaluations. As a result, the landscape of evaluation practices continues to shift, emphasizing the need for cautious application.
In this blog, our focus will be on configuring the gpt-3.5-turbo model to serve as the central tool for evaluating the responses in our experiment. To facilitate this, we establish two key evaluators, Faithfulness Evaluator and Relevancy Evaluator, utilizing the service context. This approach aligns with the evolving standards of LLM evaluation, reflecting the need for more sophisticated and reliable evaluation mechanisms.
Faithfulness Evaluator: This evaluator is instrumental in determining whether the response was artificially generated and checks if the response from a query engine corresponds with any source nodes.
Relevancy Evaluator: This evaluator is crucial for gauging whether the query was effectively addressed by the response and examines whether the response, combined with source nodes, matches the query.
In order to determine the appropriate chunk size, we will calculate metrics such as average response time, average faithfulness, and average relevancy across different chunk sizes.
Setup
!pip install llama_index pypdf
import openai
import time
import pypdf
import pandas as pd
from llama_index.evaluation import (
RelevancyEvaluator,
FaithfulnessEvaluator,
)
from llama_index import (
SimpleDirectoryReader,
VectorStoreIndex,
ServiceContext
)
from llama_index.llms import OpenAI
OpenAI API Key
openai.api_key = ‘OPENAI_API_KEY’
Downloading Dataset
We will be using the IRS armed forces tax guide for this experiment.
mkdir is used to make a folder. Here we are making a folder named dataset in the root directory.
wget command is used for non-interactive downloading of files from the web. It allows users to retrieve content from web servers, supporting various protocols like HTTP, HTTPS, and FTP.
# we will first generate a set of 10 questions from first 10 pages.
documents = documents[0:10]
Defining Question Bank
These questions will help us to evaluate metrics for different chunk sizes.
questionBank = [‘What is the purpose of Publication 3 by the Internal Revenue Service?’,
‘How can individuals access forms and information related to taxes faster and easier?’,
‘What are some examples of income items that are excluded from gross income for servicemembers?’,
‘What is the definition of a combat zone and how does it affect the taxation of servicemembers?’,
‘How are travel expenses of Armed Forces Reservists treated for tax purposes?’,
‘What are some adjustments to income that individuals can make on their tax returns?’,
‘How does the Combat Zone Exclusion impact the reporting of combat zone pay?’,
‘What are some credits available to taxpayers, specifically related to children and dependents?’,
‘How is the Earned Income Credit calculated and who is eligible for it?’,
‘What are the requirements for claiming tax forgiveness related to terrorist or military action?’]
Establishing Evaluators
This code initializes an OpenAI language model (gpt-3.5-turbo) with temperature=0 settings and instantiate evaluators for measuring faithfulness and relevancy, utilizing the ServiceContext module with default configurations.
We will be evaluating each chunk size based on 3 metrics.
Average Response Time
Average Faithfulness
Average Relevancy
The function evaluator takes two parameters, chunkSize and questionBank.
It first initializes an OpenAI language model (llm) with the model set to gpt-3.5-turbo.
Then, it creates a serviceContext using the ServiceContext.from_defaults method, specifying the language model (llm) and the chunk size (chunkSize).
The function uses the VectorStoreIndex.from_documents method to create a vector index from a set of documents, with the service context specified.
It builds a query engine (queryEngine) from the vector index.
The total number of questions in the question bank is determined and stored in the variable totalQuestions.
Next, the function initializes variables for tracking various metrics:
totalResponseTime: Tracks the cumulative response time for all questions.
totalFaithfulness: Tracks the cumulative faithfulness score for all questions.
totalRelevancy: Tracks the cumulative relevancy score for all questions.
It records the start time before querying the queryEngine for a response to the current question.
It calculates the elapsed time for the query by subtracting the start time from the current time.
The function evaluates the faithfulness of the response using faithfulnessLLM.evaluate_response and stores the result in the faithfulnessResult variable.
Similarly, it evaluates the relevancy of the response using relevancyLLM.evaluate_response and stores the result in the relevancyResult variable.
The function accumulates the elapsed time, faithfulness result, and relevancy result in their respective total variables.
After evaluating all the questions, the function computes the averages
To find out the best chunk size for our data, we have defined a list of chunk sizes then we will traverse through the list of chunk sizes and find out the average response time, average faithfulness, and average relevance with the help of evaluator method. After this, we will convert our data list into a data frame with the help of Pandas DataFrame class to view it in a fine manner.
From the illustration, it is evident that the chunk size of 128 exhibits the highest average faithfulness and relevancy while maintaining the second-lowest average response time.
Conclusion
Identifying the best chunk size for a RAG system depends on a combination of intuition and empirical data. By utilizing LlamaIndex’s Response Evaluation module, we can experiment with different sizes and make well-informed decisions. When constructing a RAG system, it is crucial to remember that the chunk size plays a pivotal role. Therefore, it is essential to invest the necessary time to thoroughly evaluate and fine-tune the chunk size for optimal outcomes.
Optimizing RAG Efficiency with LlamaIndex: Finding the Perfect Chunk Size
The integration of retrieval-augmented generation (RAG) has revolutionized the fusion of robust search capabilities with the LLM, amplifying the potential for dynamic information retrieval. Within the implementation of a RAG system, a pivotal factor governing its efficiency and performance lies in the determination of the optimal chunk size. How does one identify the most effective chunk size for seamless and efficient retrieval? This is precisely where the comprehensive assessment provided by the LlamaIndex Response Evaluation tool becomes invaluable. In this article, we will provide a comprehensive walkthrough, enabling you to discern the ideal chunk size through the powerful features of LlamaIndex’s Response Evaluation module.
Why chunk size matters
Selecting the appropriate chunk size is a crucial determination that holds sway over the effectiveness and precision of a RAG system in various ways:
Pertinence and Detail: Opting for a smaller chunk size, such as 256, results in more detailed segments. However, this heightened detail brings the potential risk that pivotal information might not be included in the foremost retrieved segments. On the contrary, a chunk size of 512 is likely to encompass all vital information within the leading chunks, ensuring that responses to inquiries are readily accessible. To navigate this challenge, we will employ the Faithfulness and Relevancy metrics. These metrics gauge the absence of ‘hallucinations’ and the ‘relevancy’ of responses concerning the query and the contexts retrieved, respectively.
Generation Time for Responses: With an increase in the chunk size, the volume of information directed into the LLM for generating a response also increases. While this can guarantee a more comprehensive context, it might potentially decelerate the system. Ensuring that the added depth doesn’t compromise the system’s responsiveness, is pivot.
Ultimately, finding the ideal chunk size boils down to achieving a delicate equilibrium. Capturing all crucial information while maintaining operational speed. It’s essential to conduct comprehensive testing with different sizes to discover a setup that aligns with the unique use case and dataset requirements.
Why evaluation?
The discussion surrounding evaluation in the field of NLP has been contentious, particularly with the advancements in NLP methodologies. Consequently, traditional evaluation techniques like BLEU or F1, once relied upon for assessing models, are now considered unreliable due to their limited correspondence with human evaluations. As a result, the landscape of evaluation practices continues to shift, emphasizing the need for cautious application.
In this blog, our focus will be on configuring the gpt-3.5-turbo model to serve as the central tool for evaluating the responses in our experiment. To facilitate this, we establish two key evaluators, Faithfulness Evaluator and Relevancy Evaluator, utilizing the service context. This approach aligns with the evolving standards of LLM evaluation, reflecting the need for more sophisticated and reliable evaluation mechanisms.
Faithfulness Evaluator: This evaluator is instrumental in determining whether the response was artificially generated and checks if the response from a query engine corresponds with any source nodes.
Relevancy Evaluator: This evaluator is crucial for gauging whether the query was effectively addressed by the response and examines whether the response, combined with source nodes, matches the query.
In order to determine the appropriate chunk size, we will calculate metrics such as average response time, average faithfulness, and average relevancy across different chunk sizes.
Setup
!pip install llama_index pypdf
import openai
import time
import pypdf
import pandas as pd
from llama_index.evaluation import (
RelevancyEvaluator,
FaithfulnessEvaluator,
)
from llama_index import (
SimpleDirectoryReader,
VectorStoreIndex,
ServiceContext
)
from llama_index.llms import OpenAI
OpenAI API Key
openai.api_key = ‘OPENAI_API_KEY’
Downloading Dataset
We will be using the IRS armed forces tax guide for this experiment.
mkdir is used to make a folder. Here we are making a folder named dataset in the root directory.
wget command is used for non-interactive downloading of files from the web. It allows users to retrieve content from web servers, supporting various protocols like HTTP, HTTPS, and FTP.
# we will first generate a set of 10 questions from first 10 pages.
documents = documents[0:10]
Defining Question Bank
These questions will help us to evaluate metrics for different chunk sizes.
questionBank = [‘What is the purpose of Publication 3 by the Internal Revenue Service?’,
‘How can individuals access forms and information related to taxes faster and easier?’,
‘What are some examples of income items that are excluded from gross income for servicemembers?’,
‘What is the definition of a combat zone and how does it affect the taxation of servicemembers?’,
‘How are travel expenses of Armed Forces Reservists treated for tax purposes?’,
‘What are some adjustments to income that individuals can make on their tax returns?’,
‘How does the Combat Zone Exclusion impact the reporting of combat zone pay?’,
‘What are some credits available to taxpayers, specifically related to children and dependents?’,
‘How is the Earned Income Credit calculated and who is eligible for it?’,
‘What are the requirements for claiming tax forgiveness related to terrorist or military action?’]
Establishing Evaluators
This code initializes an OpenAI language model (gpt-3.5-turbo) with temperature=0 settings and instantiate evaluators for measuring faithfulness and relevancy, utilizing the ServiceContext module with default configurations.
We will be evaluating each chunk size based on 3 metrics.
Average Response Time
Average Faithfulness
Average Relevancy
The function evaluator takes two parameters, chunkSize and questionBank.
It first initializes an OpenAI language model (llm) with the model set to gpt-3.5-turbo.
Then, it creates a serviceContext using the ServiceContext.from_defaults method, specifying the language model (llm) and the chunk size (chunkSize).
The function uses the VectorStoreIndex.from_documents method to create a vector index from a set of documents, with the service context specified.
It builds a query engine (queryEngine) from the vector index.
The total number of questions in the question bank is determined and stored in the variable totalQuestions.
Next, the function initializes variables for tracking various metrics:
totalResponseTime: Tracks the cumulative response time for all questions.
totalFaithfulness: Tracks the cumulative faithfulness score for all questions.
totalRelevancy: Tracks the cumulative relevancy score for all questions.
It records the start time before querying the queryEngine for a response to the current question.
It calculates the elapsed time for the query by subtracting the start time from the current time.
The function evaluates the faithfulness of the response using faithfulnessLLM.evaluate_response and stores the result in the faithfulnessResult variable.
Similarly, it evaluates the relevancy of the response using relevancyLLM.evaluate_response and stores the result in the relevancyResult variable.
The function accumulates the elapsed time, faithfulness result, and relevancy result in their respective total variables.
After evaluating all the questions, the function computes the averages
To find out the best chunk size for our data, we have defined a list of chunk sizes then we will traverse through the list of chunk sizes and find out the average response time, average faithfulness, and average relevance with the help of evaluator method. After this, we will convert our data list into a data frame with the help of Pandas DataFrame class to view it in a fine manner.
From the illustration, it is evident that the chunk size of 128 exhibits the highest average faithfulness and relevancy while maintaining the second-lowest average response time.
Conclusion
Identifying the best chunk size for a RAG system depends on a combination of intuition and empirical data. By utilizing LlamaIndex’s Response Evaluation module, we can experiment with different sizes and make well-informed decisions. When constructing a RAG system, it is crucial to remember that the chunk size plays a pivotal role. Therefore, it is essential to invest the necessary time to thoroughly evaluate and fine-tune the chunk size for optimal outcomes.
Optimizing RAG Efficiency with LlamaIndex: Finding the Perfect Chunk Size
The integration of retrieval-augmented generation (RAG) has revolutionized the fusion of robust search capabilities with the LLM, amplifying the potential for dynamic information retrieval. Within the implementation of a RAG system, a pivotal factor governing its efficiency and performance lies in the determination of the optimal chunk size. How does one identify the most effective chunk size for seamless and efficient retrieval? This is precisely where the comprehensive assessment provided by the LlamaIndex Response Evaluation tool becomes invaluable. In this article, we will provide a comprehensive walkthrough, enabling you to discern the ideal chunk size through the powerful features of LlamaIndex’s Response Evaluation module.
Why chunk size matters
Selecting the appropriate chunk size is a crucial determination that holds sway over the effectiveness and precision of a RAG system in various ways:
Pertinence and Detail: Opting for a smaller chunk size, such as 256, results in more detailed segments. However, this heightened detail brings the potential risk that pivotal information might not be included in the foremost retrieved segments. On the contrary, a chunk size of 512 is likely to encompass all vital information within the leading chunks, ensuring that responses to inquiries are readily accessible. To navigate this challenge, we will employ the Faithfulness and Relevancy metrics. These metrics gauge the absence of ‘hallucinations’ and the ‘relevancy’ of responses concerning the query and the contexts retrieved, respectively.
Generation Time for Responses: With an increase in the chunk size, the volume of information directed into the LLM for generating a response also increases. While this can guarantee a more comprehensive context, it might potentially decelerate the system. Ensuring that the added depth doesn’t compromise the system’s responsiveness, is pivot.
Ultimately, finding the ideal chunk size boils down to achieving a delicate equilibrium. Capturing all crucial information while maintaining operational speed. It’s essential to conduct comprehensive testing with different sizes to discover a setup that aligns with the unique use case and dataset requirements.
Why evaluation?
The discussion surrounding evaluation in the field of NLP has been contentious, particularly with the advancements in NLP methodologies. Consequently, traditional evaluation techniques like BLEU or F1, once relied upon for assessing models, are now considered unreliable due to their limited correspondence with human evaluations. As a result, the landscape of evaluation practices continues to shift, emphasizing the need for cautious application.
In this blog, our focus will be on configuring the gpt-3.5-turbo model to serve as the central tool for evaluating the responses in our experiment. To facilitate this, we establish two key evaluators, Faithfulness Evaluator and Relevancy Evaluator, utilizing the service context. This approach aligns with the evolving standards of LLM evaluation, reflecting the need for more sophisticated and reliable evaluation mechanisms.
Faithfulness Evaluator: This evaluator is instrumental in determining whether the response was artificially generated and checks if the response from a query engine corresponds with any source nodes.
Relevancy Evaluator: This evaluator is crucial for gauging whether the query was effectively addressed by the response and examines whether the response, combined with source nodes, matches the query.
In order to determine the appropriate chunk size, we will calculate metrics such as average response time, average faithfulness, and average relevancy across different chunk sizes.
Setup
!pip install llama_index pypdf
import openai
import time
import pypdf
import pandas as pd
from llama_index.evaluation import (
RelevancyEvaluator,
FaithfulnessEvaluator,
)
from llama_index import (
SimpleDirectoryReader,
VectorStoreIndex,
ServiceContext
)
from llama_index.llms import OpenAI
OpenAI API Key
openai.api_key = ‘OPENAI_API_KEY’
Downloading Dataset
We will be using the IRS armed forces tax guide for this experiment.
mkdir is used to make a folder. Here we are making a folder named dataset in the root directory.
wget command is used for non-interactive downloading of files from the web. It allows users to retrieve content from web servers, supporting various protocols like HTTP, HTTPS, and FTP.
# we will first generate a set of 10 questions from first 10 pages.
documents = documents[0:10]
Defining Question Bank
These questions will help us to evaluate metrics for different chunk sizes.
questionBank = [‘What is the purpose of Publication 3 by the Internal Revenue Service?’,
‘How can individuals access forms and information related to taxes faster and easier?’,
‘What are some examples of income items that are excluded from gross income for servicemembers?’,
‘What is the definition of a combat zone and how does it affect the taxation of servicemembers?’,
‘How are travel expenses of Armed Forces Reservists treated for tax purposes?’,
‘What are some adjustments to income that individuals can make on their tax returns?’,
‘How does the Combat Zone Exclusion impact the reporting of combat zone pay?’,
‘What are some credits available to taxpayers, specifically related to children and dependents?’,
‘How is the Earned Income Credit calculated and who is eligible for it?’,
‘What are the requirements for claiming tax forgiveness related to terrorist or military action?’]
Establishing Evaluators
This code initializes an OpenAI language model (gpt-3.5-turbo) with temperature=0 settings and instantiate evaluators for measuring faithfulness and relevancy, utilizing the ServiceContext module with default configurations.
We will be evaluating each chunk size based on 3 metrics.
Average Response Time
Average Faithfulness
Average Relevancy
The function evaluator takes two parameters, chunkSize and questionBank.
It first initializes an OpenAI language model (llm) with the model set to gpt-3.5-turbo.
Then, it creates a serviceContext using the ServiceContext.from_defaults method, specifying the language model (llm) and the chunk size (chunkSize).
The function uses the VectorStoreIndex.from_documents method to create a vector index from a set of documents, with the service context specified.
It builds a query engine (queryEngine) from the vector index.
The total number of questions in the question bank is determined and stored in the variable totalQuestions.
Next, the function initializes variables for tracking various metrics:
totalResponseTime: Tracks the cumulative response time for all questions.
totalFaithfulness: Tracks the cumulative faithfulness score for all questions.
totalRelevancy: Tracks the cumulative relevancy score for all questions.
It records the start time before querying the queryEngine for a response to the current question.
It calculates the elapsed time for the query by subtracting the start time from the current time.
The function evaluates the faithfulness of the response using faithfulnessLLM.evaluate_response and stores the result in the faithfulnessResult variable.
Similarly, it evaluates the relevancy of the response using relevancyLLM.evaluate_response and stores the result in the relevancyResult variable.
The function accumulates the elapsed time, faithfulness result, and relevancy result in their respective total variables.
After evaluating all the questions, the function computes the averages
To find out the best chunk size for our data, we have defined a list of chunk sizes then we will traverse through the list of chunk sizes and find out the average response time, average faithfulness, and average relevance with the help of evaluator method. After this, we will convert our data list into a data frame with the help of Pandas DataFrame class to view it in a fine manner.
From the illustration, it is evident that the chunk size of 128 exhibits the highest average faithfulness and relevancy while maintaining the second-lowest average response time.
Conclusion
Identifying the best chunk size for a RAG system depends on a combination of intuition and empirical data. By utilizing LlamaIndex’s Response Evaluation module, we can experiment with different sizes and make well-informed decisions. When constructing a RAG system, it is crucial to remember that the chunk size plays a pivotal role. Therefore, it is essential to invest the necessary time to thoroughly evaluate and fine-tune the chunk size for optimal outcomes.
Optimizing RAG Efficiency with LlamaIndex: Finding the Perfect Chunk Size
The integration of retrieval-augmented generation (RAG) has revolutionized the fusion of robust search capabilities with the LLM, amplifying the potential for dynamic information retrieval. Within the implementation of a RAG system, a pivotal factor governing its efficiency and performance lies in the determination of the optimal chunk size. How does one identify the most effective chunk size for seamless and efficient retrieval? This is precisely where the comprehensive assessment provided by the LlamaIndex Response Evaluation tool becomes invaluable. In this article, we will provide a comprehensive walkthrough, enabling you to discern the ideal chunk size through the powerful features of LlamaIndex’s Response Evaluation module.
Why chunk size matters
Selecting the appropriate chunk size is a crucial determination that holds sway over the effectiveness and precision of a RAG system in various ways:
Pertinence and Detail: Opting for a smaller chunk size, such as 256, results in more detailed segments. However, this heightened detail brings the potential risk that pivotal information might not be included in the foremost retrieved segments. On the contrary, a chunk size of 512 is likely to encompass all vital information within the leading chunks, ensuring that responses to inquiries are readily accessible. To navigate this challenge, we will employ the Faithfulness and Relevancy metrics. These metrics gauge the absence of ‘hallucinations’ and the ‘relevancy’ of responses concerning the query and the contexts retrieved, respectively.
Generation Time for Responses: With an increase in the chunk size, the volume of information directed into the LLM for generating a response also increases. While this can guarantee a more comprehensive context, it might potentially decelerate the system. Ensuring that the added depth doesn’t compromise the system’s responsiveness, is pivot.
Ultimately, finding the ideal chunk size boils down to achieving a delicate equilibrium. Capturing all crucial information while maintaining operational speed. It’s essential to conduct comprehensive testing with different sizes to discover a setup that aligns with the unique use case and dataset requirements.
Why evaluation?
The discussion surrounding evaluation in the field of NLP has been contentious, particularly with the advancements in NLP methodologies. Consequently, traditional evaluation techniques like BLEU or F1, once relied upon for assessing models, are now considered unreliable due to their limited correspondence with human evaluations. As a result, the landscape of evaluation practices continues to shift, emphasizing the need for cautious application.
In this blog, our focus will be on configuring the gpt-3.5-turbo model to serve as the central tool for evaluating the responses in our experiment. To facilitate this, we establish two key evaluators, Faithfulness Evaluator and Relevancy Evaluator, utilizing the service context. This approach aligns with the evolving standards of LLM evaluation, reflecting the need for more sophisticated and reliable evaluation mechanisms.
Faithfulness Evaluator: This evaluator is instrumental in determining whether the response was artificially generated and checks if the response from a query engine corresponds with any source nodes.
Relevancy Evaluator: This evaluator is crucial for gauging whether the query was effectively addressed by the response and examines whether the response, combined with source nodes, matches the query.
In order to determine the appropriate chunk size, we will calculate metrics such as average response time, average faithfulness, and average relevancy across different chunk sizes.
Setup
!pip install llama_index pypdf
import openai
import time
import pypdf
import pandas as pd
from llama_index.evaluation import (
RelevancyEvaluator,
FaithfulnessEvaluator,
)
from llama_index import (
SimpleDirectoryReader,
VectorStoreIndex,
ServiceContext
)
from llama_index.llms import OpenAI
OpenAI API Key
openai.api_key = ‘OPENAI_API_KEY’
Downloading Dataset
We will be using the IRS armed forces tax guide for this experiment.
mkdir is used to make a folder. Here we are making a folder named dataset in the root directory.
wget command is used for non-interactive downloading of files from the web. It allows users to retrieve content from web servers, supporting various protocols like HTTP, HTTPS, and FTP.
# we will first generate a set of 10 questions from first 10 pages.
documents = documents[0:10]
Defining Question Bank
These questions will help us to evaluate metrics for different chunk sizes.
questionBank = [‘What is the purpose of Publication 3 by the Internal Revenue Service?’,
‘How can individuals access forms and information related to taxes faster and easier?’,
‘What are some examples of income items that are excluded from gross income for servicemembers?’,
‘What is the definition of a combat zone and how does it affect the taxation of servicemembers?’,
‘How are travel expenses of Armed Forces Reservists treated for tax purposes?’,
‘What are some adjustments to income that individuals can make on their tax returns?’,
‘How does the Combat Zone Exclusion impact the reporting of combat zone pay?’,
‘What are some credits available to taxpayers, specifically related to children and dependents?’,
‘How is the Earned Income Credit calculated and who is eligible for it?’,
‘What are the requirements for claiming tax forgiveness related to terrorist or military action?’]
Establishing Evaluators
This code initializes an OpenAI language model (gpt-3.5-turbo) with temperature=0 settings and instantiate evaluators for measuring faithfulness and relevancy, utilizing the ServiceContext module with default configurations.
We will be evaluating each chunk size based on 3 metrics.
Average Response Time
Average Faithfulness
Average Relevancy
The function evaluator takes two parameters, chunkSize and questionBank.
It first initializes an OpenAI language model (llm) with the model set to gpt-3.5-turbo.
Then, it creates a serviceContext using the ServiceContext.from_defaults method, specifying the language model (llm) and the chunk size (chunkSize).
The function uses the VectorStoreIndex.from_documents method to create a vector index from a set of documents, with the service context specified.
It builds a query engine (queryEngine) from the vector index.
The total number of questions in the question bank is determined and stored in the variable totalQuestions.
Next, the function initializes variables for tracking various metrics:
totalResponseTime: Tracks the cumulative response time for all questions.
totalFaithfulness: Tracks the cumulative faithfulness score for all questions.
totalRelevancy: Tracks the cumulative relevancy score for all questions.
It records the start time before querying the queryEngine for a response to the current question.
It calculates the elapsed time for the query by subtracting the start time from the current time.
The function evaluates the faithfulness of the response using faithfulnessLLM.evaluate_response and stores the result in the faithfulnessResult variable.
Similarly, it evaluates the relevancy of the response using relevancyLLM.evaluate_response and stores the result in the relevancyResult variable.
The function accumulates the elapsed time, faithfulness result, and relevancy result in their respective total variables.
After evaluating all the questions, the function computes the averages
To find out the best chunk size for our data, we have defined a list of chunk sizes then we will traverse through the list of chunk sizes and find out the average response time, average faithfulness, and average relevance with the help of evaluator method. After this, we will convert our data list into a data frame with the help of Pandas DataFrame class to view it in a fine manner.
From the illustration, it is evident that the chunk size of 128 exhibits the highest average faithfulness and relevancy while maintaining the second-lowest average response time.
Conclusion
Identifying the best chunk size for a RAG system depends on a combination of intuition and empirical data. By utilizing LlamaIndex’s Response Evaluation module, we can experiment with different sizes and make well-informed decisions. When constructing a RAG system, it is crucial to remember that the chunk size plays a pivotal role. Therefore, it is essential to invest the necessary time to thoroughly evaluate and fine-tune the chunk size for optimal outcomes.
Optimizing RAG Efficiency with LlamaIndex: Finding the Perfect Chunk Size
The integration of retrieval-augmented generation (RAG) has revolutionized the fusion of robust search capabilities with the LLM, amplifying the potential for dynamic information retrieval. Within the implementation of a RAG system, a pivotal factor governing its efficiency and performance lies in the determination of the optimal chunk size. How does one identify the most effective chunk size for seamless and efficient retrieval? This is precisely where the comprehensive assessment provided by the LlamaIndex Response Evaluation tool becomes invaluable. In this article, we will provide a comprehensive walkthrough, enabling you to discern the ideal chunk size through the powerful features of LlamaIndex’s Response Evaluation module.
Why chunk size matters
Selecting the appropriate chunk size is a crucial determination that holds sway over the effectiveness and precision of a RAG system in various ways:
Pertinence and Detail: Opting for a smaller chunk size, such as 256, results in more detailed segments. However, this heightened detail brings the potential risk that pivotal information might not be included in the foremost retrieved segments. On the contrary, a chunk size of 512 is likely to encompass all vital information within the leading chunks, ensuring that responses to inquiries are readily accessible. To navigate this challenge, we will employ the Faithfulness and Relevancy metrics. These metrics gauge the absence of ‘hallucinations’ and the ‘relevancy’ of responses concerning the query and the contexts retrieved, respectively.
Generation Time for Responses: With an increase in the chunk size, the volume of information directed into the LLM for generating a response also increases. While this can guarantee a more comprehensive context, it might potentially decelerate the system. Ensuring that the added depth doesn’t compromise the system’s responsiveness, is pivot.
Ultimately, finding the ideal chunk size boils down to achieving a delicate equilibrium. Capturing all crucial information while maintaining operational speed. It’s essential to conduct comprehensive testing with different sizes to discover a setup that aligns with the unique use case and dataset requirements.
Why evaluation?
The discussion surrounding evaluation in the field of NLP has been contentious, particularly with the advancements in NLP methodologies. Consequently, traditional evaluation techniques like BLEU or F1, once relied upon for assessing models, are now considered unreliable due to their limited correspondence with human evaluations. As a result, the landscape of evaluation practices continues to shift, emphasizing the need for cautious application.
In this blog, our focus will be on configuring the gpt-3.5-turbo model to serve as the central tool for evaluating the responses in our experiment. To facilitate this, we establish two key evaluators, Faithfulness Evaluator and Relevancy Evaluator, utilizing the service context. This approach aligns with the evolving standards of LLM evaluation, reflecting the need for more sophisticated and reliable evaluation mechanisms.
Faithfulness Evaluator: This evaluator is instrumental in determining whether the response was artificially generated and checks if the response from a query engine corresponds with any source nodes.
Relevancy Evaluator: This evaluator is crucial for gauging whether the query was effectively addressed by the response and examines whether the response, combined with source nodes, matches the query.
In order to determine the appropriate chunk size, we will calculate metrics such as average response time, average faithfulness, and average relevancy across different chunk sizes.
Setup
!pip install llama_index pypdf
import openai
import time
import pypdf
import pandas as pd
from llama_index.evaluation import (
RelevancyEvaluator,
FaithfulnessEvaluator,
)
from llama_index import (
SimpleDirectoryReader,
VectorStoreIndex,
ServiceContext
)
from llama_index.llms import OpenAI
OpenAI API Key
openai.api_key = ‘OPENAI_API_KEY’
Downloading Dataset
We will be using the IRS armed forces tax guide for this experiment.
mkdir is used to make a folder. Here we are making a folder named dataset in the root directory.
wget command is used for non-interactive downloading of files from the web. It allows users to retrieve content from web servers, supporting various protocols like HTTP, HTTPS, and FTP.
# we will first generate a set of 10 questions from first 10 pages.
documents = documents[0:10]
Defining Question Bank
These questions will help us to evaluate metrics for different chunk sizes.
questionBank = [‘What is the purpose of Publication 3 by the Internal Revenue Service?’,
‘How can individuals access forms and information related to taxes faster and easier?’,
‘What are some examples of income items that are excluded from gross income for servicemembers?’,
‘What is the definition of a combat zone and how does it affect the taxation of servicemembers?’,
‘How are travel expenses of Armed Forces Reservists treated for tax purposes?’,
‘What are some adjustments to income that individuals can make on their tax returns?’,
‘How does the Combat Zone Exclusion impact the reporting of combat zone pay?’,
‘What are some credits available to taxpayers, specifically related to children and dependents?’,
‘How is the Earned Income Credit calculated and who is eligible for it?’,
‘What are the requirements for claiming tax forgiveness related to terrorist or military action?’]
Establishing Evaluators
This code initializes an OpenAI language model (gpt-3.5-turbo) with temperature=0 settings and instantiate evaluators for measuring faithfulness and relevancy, utilizing the ServiceContext module with default configurations.
We will be evaluating each chunk size based on 3 metrics.
Average Response Time
Average Faithfulness
Average Relevancy
The function evaluator takes two parameters, chunkSize and questionBank.
It first initializes an OpenAI language model (llm) with the model set to gpt-3.5-turbo.
Then, it creates a serviceContext using the ServiceContext.from_defaults method, specifying the language model (llm) and the chunk size (chunkSize).
The function uses the VectorStoreIndex.from_documents method to create a vector index from a set of documents, with the service context specified.
It builds a query engine (queryEngine) from the vector index.
The total number of questions in the question bank is determined and stored in the variable totalQuestions.
Next, the function initializes variables for tracking various metrics:
totalResponseTime: Tracks the cumulative response time for all questions.
totalFaithfulness: Tracks the cumulative faithfulness score for all questions.
totalRelevancy: Tracks the cumulative relevancy score for all questions.
It records the start time before querying the queryEngine for a response to the current question.
It calculates the elapsed time for the query by subtracting the start time from the current time.
The function evaluates the faithfulness of the response using faithfulnessLLM.evaluate_response and stores the result in the faithfulnessResult variable.
Similarly, it evaluates the relevancy of the response using relevancyLLM.evaluate_response and stores the result in the relevancyResult variable.
The function accumulates the elapsed time, faithfulness result, and relevancy result in their respective total variables.
After evaluating all the questions, the function computes the averages
To find out the best chunk size for our data, we have defined a list of chunk sizes then we will traverse through the list of chunk sizes and find out the average response time, average faithfulness, and average relevance with the help of evaluator method. After this, we will convert our data list into a data frame with the help of Pandas DataFrame class to view it in a fine manner.
From the illustration, it is evident that the chunk size of 128 exhibits the highest average faithfulness and relevancy while maintaining the second-lowest average response time.
Conclusion
Identifying the best chunk size for a RAG system depends on a combination of intuition and empirical data. By utilizing LlamaIndex’s Response Evaluation module, we can experiment with different sizes and make well-informed decisions. When constructing a RAG system, it is crucial to remember that the chunk size plays a pivotal role. Therefore, it is essential to invest the necessary time to thoroughly evaluate and fine-tune the chunk size for optimal outcomes.
Optimizing RAG Efficiency with LlamaIndex: Finding the Perfect Chunk Size
The integration of retrieval-augmented generation (RAG) has revolutionized the fusion of robust search capabilities with the LLM, amplifying the potential for dynamic information retrieval. Within the implementation of a RAG system, a pivotal factor governing its efficiency and performance lies in the determination of the optimal chunk size. How does one identify the most effective chunk size for seamless and efficient retrieval? This is precisely where the comprehensive assessment provided by the LlamaIndex Response Evaluation tool becomes invaluable. In this article, we will provide a comprehensive walkthrough, enabling you to discern the ideal chunk size through the powerful features of LlamaIndex’s Response Evaluation module.
Why chunk size matters
Selecting the appropriate chunk size is a crucial determination that holds sway over the effectiveness and precision of a RAG system in various ways:
Pertinence and Detail: Opting for a smaller chunk size, such as 256, results in more detailed segments. However, this heightened detail brings the potential risk that pivotal information might not be included in the foremost retrieved segments. On the contrary, a chunk size of 512 is likely to encompass all vital information within the leading chunks, ensuring that responses to inquiries are readily accessible. To navigate this challenge, we will employ the Faithfulness and Relevancy metrics. These metrics gauge the absence of ‘hallucinations’ and the ‘relevancy’ of responses concerning the query and the contexts retrieved, respectively.
Generation Time for Responses: With an increase in the chunk size, the volume of information directed into the LLM for generating a response also increases. While this can guarantee a more comprehensive context, it might potentially decelerate the system. Ensuring that the added depth doesn’t compromise the system’s responsiveness, is pivot.
Ultimately, finding the ideal chunk size boils down to achieving a delicate equilibrium. Capturing all crucial information while maintaining operational speed. It’s essential to conduct comprehensive testing with different sizes to discover a setup that aligns with the unique use case and dataset requirements.
Why evaluation?
The discussion surrounding evaluation in the field of NLP has been contentious, particularly with the advancements in NLP methodologies. Consequently, traditional evaluation techniques like BLEU or F1, once relied upon for assessing models, are now considered unreliable due to their limited correspondence with human evaluations. As a result, the landscape of evaluation practices continues to shift, emphasizing the need for cautious application.
In this blog, our focus will be on configuring the gpt-3.5-turbo model to serve as the central tool for evaluating the responses in our experiment. To facilitate this, we establish two key evaluators, Faithfulness Evaluator and Relevancy Evaluator, utilizing the service context. This approach aligns with the evolving standards of LLM evaluation, reflecting the need for more sophisticated and reliable evaluation mechanisms.
Faithfulness Evaluator: This evaluator is instrumental in determining whether the response was artificially generated and checks if the response from a query engine corresponds with any source nodes.
Relevancy Evaluator: This evaluator is crucial for gauging whether the query was effectively addressed by the response and examines whether the response, combined with source nodes, matches the query.
In order to determine the appropriate chunk size, we will calculate metrics such as average response time, average faithfulness, and average relevancy across different chunk sizes.
Setup
!pip install llama_index pypdf
import openai
import time
import pypdf
import pandas as pd
from llama_index.evaluation import (
RelevancyEvaluator,
FaithfulnessEvaluator,
)
from llama_index import (
SimpleDirectoryReader,
VectorStoreIndex,
ServiceContext
)
from llama_index.llms import OpenAI
OpenAI API Key
openai.api_key = ‘OPENAI_API_KEY’
Downloading Dataset
We will be using the IRS armed forces tax guide for this experiment.
mkdir is used to make a folder. Here we are making a folder named dataset in the root directory.
wget command is used for non-interactive downloading of files from the web. It allows users to retrieve content from web servers, supporting various protocols like HTTP, HTTPS, and FTP.
# we will first generate a set of 10 questions from first 10 pages.
documents = documents[0:10]
Defining Question Bank
These questions will help us to evaluate metrics for different chunk sizes.
questionBank = [‘What is the purpose of Publication 3 by the Internal Revenue Service?’,
‘How can individuals access forms and information related to taxes faster and easier?’,
‘What are some examples of income items that are excluded from gross income for servicemembers?’,
‘What is the definition of a combat zone and how does it affect the taxation of servicemembers?’,
‘How are travel expenses of Armed Forces Reservists treated for tax purposes?’,
‘What are some adjustments to income that individuals can make on their tax returns?’,
‘How does the Combat Zone Exclusion impact the reporting of combat zone pay?’,
‘What are some credits available to taxpayers, specifically related to children and dependents?’,
‘How is the Earned Income Credit calculated and who is eligible for it?’,
‘What are the requirements for claiming tax forgiveness related to terrorist or military action?’]
Establishing Evaluators
This code initializes an OpenAI language model (gpt-3.5-turbo) with temperature=0 settings and instantiate evaluators for measuring faithfulness and relevancy, utilizing the ServiceContext module with default configurations.
We will be evaluating each chunk size based on 3 metrics.
Average Response Time
Average Faithfulness
Average Relevancy
The function evaluator takes two parameters, chunkSize and questionBank.
It first initializes an OpenAI language model (llm) with the model set to gpt-3.5-turbo.
Then, it creates a serviceContext using the ServiceContext.from_defaults method, specifying the language model (llm) and the chunk size (chunkSize).
The function uses the VectorStoreIndex.from_documents method to create a vector index from a set of documents, with the service context specified.
It builds a query engine (queryEngine) from the vector index.
The total number of questions in the question bank is determined and stored in the variable totalQuestions.
Next, the function initializes variables for tracking various metrics:
totalResponseTime: Tracks the cumulative response time for all questions.
totalFaithfulness: Tracks the cumulative faithfulness score for all questions.
totalRelevancy: Tracks the cumulative relevancy score for all questions.
It records the start time before querying the queryEngine for a response to the current question.
It calculates the elapsed time for the query by subtracting the start time from the current time.
The function evaluates the faithfulness of the response using faithfulnessLLM.evaluate_response and stores the result in the faithfulnessResult variable.
Similarly, it evaluates the relevancy of the response using relevancyLLM.evaluate_response and stores the result in the relevancyResult variable.
The function accumulates the elapsed time, faithfulness result, and relevancy result in their respective total variables.
After evaluating all the questions, the function computes the averages
To find out the best chunk size for our data, we have defined a list of chunk sizes then we will traverse through the list of chunk sizes and find out the average response time, average faithfulness, and average relevance with the help of evaluator method. After this, we will convert our data list into a data frame with the help of Pandas DataFrame class to view it in a fine manner.
From the illustration, it is evident that the chunk size of 128 exhibits the highest average faithfulness and relevancy while maintaining the second-lowest average response time.
Conclusion
Identifying the best chunk size for a RAG system depends on a combination of intuition and empirical data. By utilizing LlamaIndex’s Response Evaluation module, we can experiment with different sizes and make well-informed decisions. When constructing a RAG system, it is crucial to remember that the chunk size plays a pivotal role. Therefore, it is essential to invest the necessary time to thoroughly evaluate and fine-tune the chunk size for optimal outcomes.
Optimizing RAG Efficiency with LlamaIndex: Finding the Perfect Chunk Size
The integration of retrieval-augmented generation (RAG) has revolutionized the fusion of robust search capabilities with the LLM, amplifying the potential for dynamic information retrieval. Within the implementation of a RAG system, a pivotal factor governing its efficiency and performance lies in the determination of the optimal chunk size. How does one identify the most effective chunk size for seamless and efficient retrieval? This is precisely where the comprehensive assessment provided by the LlamaIndex Response Evaluation tool becomes invaluable. In this article, we will provide a comprehensive walkthrough, enabling you to discern the ideal chunk size through the powerful features of LlamaIndex’s Response Evaluation module.
Why chunk size matters
Selecting the appropriate chunk size is a crucial determination that holds sway over the effectiveness and precision of a RAG system in various ways:
Pertinence and Detail: Opting for a smaller chunk size, such as 256, results in more detailed segments. However, this heightened detail brings the potential risk that pivotal information might not be included in the foremost retrieved segments. On the contrary, a chunk size of 512 is likely to encompass all vital information within the leading chunks, ensuring that responses to inquiries are readily accessible. To navigate this challenge, we will employ the Faithfulness and Relevancy metrics. These metrics gauge the absence of ‘hallucinations’ and the ‘relevancy’ of responses concerning the query and the contexts retrieved, respectively.
Generation Time for Responses: With an increase in the chunk size, the volume of information directed into the LLM for generating a response also increases. While this can guarantee a more comprehensive context, it might potentially decelerate the system. Ensuring that the added depth doesn’t compromise the system’s responsiveness, is pivot.
Ultimately, finding the ideal chunk size boils down to achieving a delicate equilibrium. Capturing all crucial information while maintaining operational speed. It’s essential to conduct comprehensive testing with different sizes to discover a setup that aligns with the unique use case and dataset requirements.
Why evaluation?
The discussion surrounding evaluation in the field of NLP has been contentious, particularly with the advancements in NLP methodologies. Consequently, traditional evaluation techniques like BLEU or F1, once relied upon for assessing models, are now considered unreliable due to their limited correspondence with human evaluations. As a result, the landscape of evaluation practices continues to shift, emphasizing the need for cautious application.
In this blog, our focus will be on configuring the gpt-3.5-turbo model to serve as the central tool for evaluating the responses in our experiment. To facilitate this, we establish two key evaluators, Faithfulness Evaluator and Relevancy Evaluator, utilizing the service context. This approach aligns with the evolving standards of LLM evaluation, reflecting the need for more sophisticated and reliable evaluation mechanisms.
Faithfulness Evaluator: This evaluator is instrumental in determining whether the response was artificially generated and checks if the response from a query engine corresponds with any source nodes.
Relevancy Evaluator: This evaluator is crucial for gauging whether the query was effectively addressed by the response and examines whether the response, combined with source nodes, matches the query.
In order to determine the appropriate chunk size, we will calculate metrics such as average response time, average faithfulness, and average relevancy across different chunk sizes.
Setup
!pip install llama_index pypdf
import openai
import time
import pypdf
import pandas as pd
from llama_index.evaluation import (
RelevancyEvaluator,
FaithfulnessEvaluator,
)
from llama_index import (
SimpleDirectoryReader,
VectorStoreIndex,
ServiceContext
)
from llama_index.llms import OpenAI
OpenAI API Key
openai.api_key = ‘OPENAI_API_KEY’
Downloading Dataset
We will be using the IRS armed forces tax guide for this experiment.
mkdir is used to make a folder. Here we are making a folder named dataset in the root directory.
wget command is used for non-interactive downloading of files from the web. It allows users to retrieve content from web servers, supporting various protocols like HTTP, HTTPS, and FTP.
# we will first generate a set of 10 questions from first 10 pages.
documents = documents[0:10]
Defining Question Bank
These questions will help us to evaluate metrics for different chunk sizes.
questionBank = [‘What is the purpose of Publication 3 by the Internal Revenue Service?’,
‘How can individuals access forms and information related to taxes faster and easier?’,
‘What are some examples of income items that are excluded from gross income for servicemembers?’,
‘What is the definition of a combat zone and how does it affect the taxation of servicemembers?’,
‘How are travel expenses of Armed Forces Reservists treated for tax purposes?’,
‘What are some adjustments to income that individuals can make on their tax returns?’,
‘How does the Combat Zone Exclusion impact the reporting of combat zone pay?’,
‘What are some credits available to taxpayers, specifically related to children and dependents?’,
‘How is the Earned Income Credit calculated and who is eligible for it?’,
‘What are the requirements for claiming tax forgiveness related to terrorist or military action?’]
Establishing Evaluators
This code initializes an OpenAI language model (gpt-3.5-turbo) with temperature=0 settings and instantiate evaluators for measuring faithfulness and relevancy, utilizing the ServiceContext module with default configurations.
We will be evaluating each chunk size based on 3 metrics.
Average Response Time
Average Faithfulness
Average Relevancy
The function evaluator takes two parameters, chunkSize and questionBank.
It first initializes an OpenAI language model (llm) with the model set to gpt-3.5-turbo.
Then, it creates a serviceContext using the ServiceContext.from_defaults method, specifying the language model (llm) and the chunk size (chunkSize).
The function uses the VectorStoreIndex.from_documents method to create a vector index from a set of documents, with the service context specified.
It builds a query engine (queryEngine) from the vector index.
The total number of questions in the question bank is determined and stored in the variable totalQuestions.
Next, the function initializes variables for tracking various metrics:
totalResponseTime: Tracks the cumulative response time for all questions.
totalFaithfulness: Tracks the cumulative faithfulness score for all questions.
totalRelevancy: Tracks the cumulative relevancy score for all questions.
It records the start time before querying the queryEngine for a response to the current question.
It calculates the elapsed time for the query by subtracting the start time from the current time.
The function evaluates the faithfulness of the response using faithfulnessLLM.evaluate_response and stores the result in the faithfulnessResult variable.
Similarly, it evaluates the relevancy of the response using relevancyLLM.evaluate_response and stores the result in the relevancyResult variable.
The function accumulates the elapsed time, faithfulness result, and relevancy result in their respective total variables.
After evaluating all the questions, the function computes the averages
To find out the best chunk size for our data, we have defined a list of chunk sizes then we will traverse through the list of chunk sizes and find out the average response time, average faithfulness, and average relevance with the help of evaluator method. After this, we will convert our data list into a data frame with the help of Pandas DataFrame class to view it in a fine manner.
From the illustration, it is evident that the chunk size of 128 exhibits the highest average faithfulness and relevancy while maintaining the second-lowest average response time.
Conclusion
Identifying the best chunk size for a RAG system depends on a combination of intuition and empirical data. By utilizing LlamaIndex’s Response Evaluation module, we can experiment with different sizes and make well-informed decisions. When constructing a RAG system, it is crucial to remember that the chunk size plays a pivotal role. Therefore, it is essential to invest the necessary time to thoroughly evaluate and fine-tune the chunk size for optimal outcomes.
Optimizing RAG Efficiency with LlamaIndex: Finding the Perfect Chunk Size
The integration of retrieval-augmented generation (RAG) has revolutionized the fusion of robust search capabilities with the LLM, amplifying the potential for dynamic information retrieval. Within the implementation of a RAG system, a pivotal factor governing its efficiency and performance lies in the determination of the optimal chunk size. How does one identify the most effective chunk size for seamless and efficient retrieval? This is precisely where the comprehensive assessment provided by the LlamaIndex Response Evaluation tool becomes invaluable. In this article, we will provide a comprehensive walkthrough, enabling you to discern the ideal chunk size through the powerful features of LlamaIndex’s Response Evaluation module.
Why chunk size matters
Selecting the appropriate chunk size is a crucial determination that holds sway over the effectiveness and precision of a RAG system in various ways:
Pertinence and Detail: Opting for a smaller chunk size, such as 256, results in more detailed segments. However, this heightened detail brings the potential risk that pivotal information might not be included in the foremost retrieved segments. On the contrary, a chunk size of 512 is likely to encompass all vital information within the leading chunks, ensuring that responses to inquiries are readily accessible. To navigate this challenge, we will employ the Faithfulness and Relevancy metrics. These metrics gauge the absence of ‘hallucinations’ and the ‘relevancy’ of responses concerning the query and the contexts retrieved, respectively.
Generation Time for Responses: With an increase in the chunk size, the volume of information directed into the LLM for generating a response also increases. While this can guarantee a more comprehensive context, it might potentially decelerate the system. Ensuring that the added depth doesn’t compromise the system’s responsiveness, is pivot.
Ultimately, finding the ideal chunk size boils down to achieving a delicate equilibrium. Capturing all crucial information while maintaining operational speed. It’s essential to conduct comprehensive testing with different sizes to discover a setup that aligns with the unique use case and dataset requirements.
Why evaluation?
The discussion surrounding evaluation in the field of NLP has been contentious, particularly with the advancements in NLP methodologies. Consequently, traditional evaluation techniques like BLEU or F1, once relied upon for assessing models, are now considered unreliable due to their limited correspondence with human evaluations. As a result, the landscape of evaluation practices continues to shift, emphasizing the need for cautious application.
In this blog, our focus will be on configuring the gpt-3.5-turbo model to serve as the central tool for evaluating the responses in our experiment. To facilitate this, we establish two key evaluators, Faithfulness Evaluator and Relevancy Evaluator, utilizing the service context. This approach aligns with the evolving standards of LLM evaluation, reflecting the need for more sophisticated and reliable evaluation mechanisms.
Faithfulness Evaluator: This evaluator is instrumental in determining whether the response was artificially generated and checks if the response from a query engine corresponds with any source nodes.
Relevancy Evaluator: This evaluator is crucial for gauging whether the query was effectively addressed by the response and examines whether the response, combined with source nodes, matches the query.
In order to determine the appropriate chunk size, we will calculate metrics such as average response time, average faithfulness, and average relevancy across different chunk sizes.
Setup
!pip install llama_index pypdf
import openai
import time
import pypdf
import pandas as pd
from llama_index.evaluation import (
RelevancyEvaluator,
FaithfulnessEvaluator,
)
from llama_index import (
SimpleDirectoryReader,
VectorStoreIndex,
ServiceContext
)
from llama_index.llms import OpenAI
OpenAI API Key
openai.api_key = ‘OPENAI_API_KEY’
Downloading Dataset
We will be using the IRS armed forces tax guide for this experiment.
mkdir is used to make a folder. Here we are making a folder named dataset in the root directory.
wget command is used for non-interactive downloading of files from the web. It allows users to retrieve content from web servers, supporting various protocols like HTTP, HTTPS, and FTP.
# we will first generate a set of 10 questions from first 10 pages.
documents = documents[0:10]
Defining Question Bank
These questions will help us to evaluate metrics for different chunk sizes.
questionBank = [‘What is the purpose of Publication 3 by the Internal Revenue Service?’,
‘How can individuals access forms and information related to taxes faster and easier?’,
‘What are some examples of income items that are excluded from gross income for servicemembers?’,
‘What is the definition of a combat zone and how does it affect the taxation of servicemembers?’,
‘How are travel expenses of Armed Forces Reservists treated for tax purposes?’,
‘What are some adjustments to income that individuals can make on their tax returns?’,
‘How does the Combat Zone Exclusion impact the reporting of combat zone pay?’,
‘What are some credits available to taxpayers, specifically related to children and dependents?’,
‘How is the Earned Income Credit calculated and who is eligible for it?’,
‘What are the requirements for claiming tax forgiveness related to terrorist or military action?’]
Establishing Evaluators
This code initializes an OpenAI language model (gpt-3.5-turbo) with temperature=0 settings and instantiate evaluators for measuring faithfulness and relevancy, utilizing the ServiceContext module with default configurations.
We will be evaluating each chunk size based on 3 metrics.
Average Response Time
Average Faithfulness
Average Relevancy
The function evaluator takes two parameters, chunkSize and questionBank.
It first initializes an OpenAI language model (llm) with the model set to gpt-3.5-turbo.
Then, it creates a serviceContext using the ServiceContext.from_defaults method, specifying the language model (llm) and the chunk size (chunkSize).
The function uses the VectorStoreIndex.from_documents method to create a vector index from a set of documents, with the service context specified.
It builds a query engine (queryEngine) from the vector index.
The total number of questions in the question bank is determined and stored in the variable totalQuestions.
Next, the function initializes variables for tracking various metrics:
totalResponseTime: Tracks the cumulative response time for all questions.
totalFaithfulness: Tracks the cumulative faithfulness score for all questions.
totalRelevancy: Tracks the cumulative relevancy score for all questions.
It records the start time before querying the queryEngine for a response to the current question.
It calculates the elapsed time for the query by subtracting the start time from the current time.
The function evaluates the faithfulness of the response using faithfulnessLLM.evaluate_response and stores the result in the faithfulnessResult variable.
Similarly, it evaluates the relevancy of the response using relevancyLLM.evaluate_response and stores the result in the relevancyResult variable.
The function accumulates the elapsed time, faithfulness result, and relevancy result in their respective total variables.
After evaluating all the questions, the function computes the averages
To find out the best chunk size for our data, we have defined a list of chunk sizes then we will traverse through the list of chunk sizes and find out the average response time, average faithfulness, and average relevance with the help of evaluator method. After this, we will convert our data list into a data frame with the help of Pandas DataFrame class to view it in a fine manner.
From the illustration, it is evident that the chunk size of 128 exhibits the highest average faithfulness and relevancy while maintaining the second-lowest average response time.
Conclusion
Identifying the best chunk size for a RAG system depends on a combination of intuition and empirical data. By utilizing LlamaIndex’s Response Evaluation module, we can experiment with different sizes and make well-informed decisions. When constructing a RAG system, it is crucial to remember that the chunk size plays a pivotal role. Therefore, it is essential to invest the necessary time to thoroughly evaluate and fine-tune the chunk size for optimal outcomes.
Optimizing RAG Efficiency with LlamaIndex: Finding the Perfect Chunk Size
The integration of retrieval-augmented generation (RAG) has revolutionized the fusion of robust search capabilities with the LLM, amplifying the potential for dynamic information retrieval. Within the implementation of a RAG system, a pivotal factor governing its efficiency and performance lies in the determination of the optimal chunk size. How does one identify the most effective chunk size for seamless and efficient retrieval? This is precisely where the comprehensive assessment provided by the LlamaIndex Response Evaluation tool becomes invaluable. In this article, we will provide a comprehensive walkthrough, enabling you to discern the ideal chunk size through the powerful features of LlamaIndex’s Response Evaluation module.
Why chunk size matters
Selecting the appropriate chunk size is a crucial determination that holds sway over the effectiveness and precision of a RAG system in various ways:
Pertinence and Detail: Opting for a smaller chunk size, such as 256, results in more detailed segments. However, this heightened detail brings the potential risk that pivotal information might not be included in the foremost retrieved segments. On the contrary, a chunk size of 512 is likely to encompass all vital information within the leading chunks, ensuring that responses to inquiries are readily accessible. To navigate this challenge, we will employ the Faithfulness and Relevancy metrics. These metrics gauge the absence of ‘hallucinations’ and the ‘relevancy’ of responses concerning the query and the contexts retrieved, respectively.
Generation Time for Responses: With an increase in the chunk size, the volume of information directed into the LLM for generating a response also increases. While this can guarantee a more comprehensive context, it might potentially decelerate the system. Ensuring that the added depth doesn’t compromise the system’s responsiveness, is pivot.
Ultimately, finding the ideal chunk size boils down to achieving a delicate equilibrium. Capturing all crucial information while maintaining operational speed. It’s essential to conduct comprehensive testing with different sizes to discover a setup that aligns with the unique use case and dataset requirements.
Why evaluation?
The discussion surrounding evaluation in the field of NLP has been contentious, particularly with the advancements in NLP methodologies. Consequently, traditional evaluation techniques like BLEU or F1, once relied upon for assessing models, are now considered unreliable due to their limited correspondence with human evaluations. As a result, the landscape of evaluation practices continues to shift, emphasizing the need for cautious application.
In this blog, our focus will be on configuring the gpt-3.5-turbo model to serve as the central tool for evaluating the responses in our experiment. To facilitate this, we establish two key evaluators, Faithfulness Evaluator and Relevancy Evaluator, utilizing the service context. This approach aligns with the evolving standards of LLM evaluation, reflecting the need for more sophisticated and reliable evaluation mechanisms.
Faithfulness Evaluator: This evaluator is instrumental in determining whether the response was artificially generated and checks if the response from a query engine corresponds with any source nodes.
Relevancy Evaluator: This evaluator is crucial for gauging whether the query was effectively addressed by the response and examines whether the response, combined with source nodes, matches the query.
In order to determine the appropriate chunk size, we will calculate metrics such as average response time, average faithfulness, and average relevancy across different chunk sizes.
Setup
!pip install llama_index pypdf
import openai
import time
import pypdf
import pandas as pd
from llama_index.evaluation import (
RelevancyEvaluator,
FaithfulnessEvaluator,
)
from llama_index import (
SimpleDirectoryReader,
VectorStoreIndex,
ServiceContext
)
from llama_index.llms import OpenAI
OpenAI API Key
openai.api_key = ‘OPENAI_API_KEY’
Downloading Dataset
We will be using the IRS armed forces tax guide for this experiment.
mkdir is used to make a folder. Here we are making a folder named dataset in the root directory.
wget command is used for non-interactive downloading of files from the web. It allows users to retrieve content from web servers, supporting various protocols like HTTP, HTTPS, and FTP.
# we will first generate a set of 10 questions from first 10 pages.
documents = documents[0:10]
Defining Question Bank
These questions will help us to evaluate metrics for different chunk sizes.
questionBank = [‘What is the purpose of Publication 3 by the Internal Revenue Service?’,
‘How can individuals access forms and information related to taxes faster and easier?’,
‘What are some examples of income items that are excluded from gross income for servicemembers?’,
‘What is the definition of a combat zone and how does it affect the taxation of servicemembers?’,
‘How are travel expenses of Armed Forces Reservists treated for tax purposes?’,
‘What are some adjustments to income that individuals can make on their tax returns?’,
‘How does the Combat Zone Exclusion impact the reporting of combat zone pay?’,
‘What are some credits available to taxpayers, specifically related to children and dependents?’,
‘How is the Earned Income Credit calculated and who is eligible for it?’,
‘What are the requirements for claiming tax forgiveness related to terrorist or military action?’]
Establishing Evaluators
This code initializes an OpenAI language model (gpt-3.5-turbo) with temperature=0 settings and instantiate evaluators for measuring faithfulness and relevancy, utilizing the ServiceContext module with default configurations.
We will be evaluating each chunk size based on 3 metrics.
Average Response Time
Average Faithfulness
Average Relevancy
The function evaluator takes two parameters, chunkSize and questionBank.
It first initializes an OpenAI language model (llm) with the model set to gpt-3.5-turbo.
Then, it creates a serviceContext using the ServiceContext.from_defaults method, specifying the language model (llm) and the chunk size (chunkSize).
The function uses the VectorStoreIndex.from_documents method to create a vector index from a set of documents, with the service context specified.
It builds a query engine (queryEngine) from the vector index.
The total number of questions in the question bank is determined and stored in the variable totalQuestions.
Next, the function initializes variables for tracking various metrics:
totalResponseTime: Tracks the cumulative response time for all questions.
totalFaithfulness: Tracks the cumulative faithfulness score for all questions.
totalRelevancy: Tracks the cumulative relevancy score for all questions.
It records the start time before querying the queryEngine for a response to the current question.
It calculates the elapsed time for the query by subtracting the start time from the current time.
The function evaluates the faithfulness of the response using faithfulnessLLM.evaluate_response and stores the result in the faithfulnessResult variable.
Similarly, it evaluates the relevancy of the response using relevancyLLM.evaluate_response and stores the result in the relevancyResult variable.
The function accumulates the elapsed time, faithfulness result, and relevancy result in their respective total variables.
After evaluating all the questions, the function computes the averages
To find out the best chunk size for our data, we have defined a list of chunk sizes then we will traverse through the list of chunk sizes and find out the average response time, average faithfulness, and average relevance with the help of evaluator method. After this, we will convert our data list into a data frame with the help of Pandas DataFrame class to view it in a fine manner.
From the illustration, it is evident that the chunk size of 128 exhibits the highest average faithfulness and relevancy while maintaining the second-lowest average response time.
Conclusion
Identifying the best chunk size for a RAG system depends on a combination of intuition and empirical data. By utilizing LlamaIndex’s Response Evaluation module, we can experiment with different sizes and make well-informed decisions. When constructing a RAG system, it is crucial to remember that the chunk size plays a pivotal role. Therefore, it is essential to invest the necessary time to thoroughly evaluate and fine-tune the chunk size for optimal outcomes.
Optimizing RAG Efficiency with LlamaIndex: Finding the Perfect Chunk Size
The integration of retrieval-augmented generation (RAG) has revolutionized the fusion of robust search capabilities with the LLM, amplifying the potential for dynamic information retrieval. Within the implementation of a RAG system, a pivotal factor governing its efficiency and performance lies in the determination of the optimal chunk size. How does one identify the most effective chunk size for seamless and efficient retrieval? This is precisely where the comprehensive assessment provided by the LlamaIndex Response Evaluation tool becomes invaluable. In this article, we will provide a comprehensive walkthrough, enabling you to discern the ideal chunk size through the powerful features of LlamaIndex’s Response Evaluation module.
Why chunk size matters
Selecting the appropriate chunk size is a crucial determination that holds sway over the effectiveness and precision of a RAG system in various ways:
Pertinence and Detail: Opting for a smaller chunk size, such as 256, results in more detailed segments. However, this heightened detail brings the potential risk that pivotal information might not be included in the foremost retrieved segments. On the contrary, a chunk size of 512 is likely to encompass all vital information within the leading chunks, ensuring that responses to inquiries are readily accessible. To navigate this challenge, we will employ the Faithfulness and Relevancy metrics. These metrics gauge the absence of ‘hallucinations’ and the ‘relevancy’ of responses concerning the query and the contexts retrieved, respectively.
Generation Time for Responses: With an increase in the chunk size, the volume of information directed into the LLM for generating a response also increases. While this can guarantee a more comprehensive context, it might potentially decelerate the system. Ensuring that the added depth doesn’t compromise the system’s responsiveness, is pivot.
Ultimately, finding the ideal chunk size boils down to achieving a delicate equilibrium. Capturing all crucial information while maintaining operational speed. It’s essential to conduct comprehensive testing with different sizes to discover a setup that aligns with the unique use case and dataset requirements.
Why evaluation?
The discussion surrounding evaluation in the field of NLP has been contentious, particularly with the advancements in NLP methodologies. Consequently, traditional evaluation techniques like BLEU or F1, once relied upon for assessing models, are now considered unreliable due to their limited correspondence with human evaluations. As a result, the landscape of evaluation practices continues to shift, emphasizing the need for cautious application.
In this blog, our focus will be on configuring the gpt-3.5-turbo model to serve as the central tool for evaluating the responses in our experiment. To facilitate this, we establish two key evaluators, Faithfulness Evaluator and Relevancy Evaluator, utilizing the service context. This approach aligns with the evolving standards of LLM evaluation, reflecting the need for more sophisticated and reliable evaluation mechanisms.
Faithfulness Evaluator: This evaluator is instrumental in determining whether the response was artificially generated and checks if the response from a query engine corresponds with any source nodes.
Relevancy Evaluator: This evaluator is crucial for gauging whether the query was effectively addressed by the response and examines whether the response, combined with source nodes, matches the query.
In order to determine the appropriate chunk size, we will calculate metrics such as average response time, average faithfulness, and average relevancy across different chunk sizes.
Setup
!pip install llama_index pypdf
import openai
import time
import pypdf
import pandas as pd
from llama_index.evaluation import (
RelevancyEvaluator,
FaithfulnessEvaluator,
)
from llama_index import (
SimpleDirectoryReader,
VectorStoreIndex,
ServiceContext
)
from llama_index.llms import OpenAI
OpenAI API Key
openai.api_key = ‘OPENAI_API_KEY’
Downloading Dataset
We will be using the IRS armed forces tax guide for this experiment.
mkdir is used to make a folder. Here we are making a folder named dataset in the root directory.
wget command is used for non-interactive downloading of files from the web. It allows users to retrieve content from web servers, supporting various protocols like HTTP, HTTPS, and FTP.
# we will first generate a set of 10 questions from first 10 pages.
documents = documents[0:10]
Defining Question Bank
These questions will help us to evaluate metrics for different chunk sizes.
questionBank = [‘What is the purpose of Publication 3 by the Internal Revenue Service?’,
‘How can individuals access forms and information related to taxes faster and easier?’,
‘What are some examples of income items that are excluded from gross income for servicemembers?’,
‘What is the definition of a combat zone and how does it affect the taxation of servicemembers?’,
‘How are travel expenses of Armed Forces Reservists treated for tax purposes?’,
‘What are some adjustments to income that individuals can make on their tax returns?’,
‘How does the Combat Zone Exclusion impact the reporting of combat zone pay?’,
‘What are some credits available to taxpayers, specifically related to children and dependents?’,
‘How is the Earned Income Credit calculated and who is eligible for it?’,
‘What are the requirements for claiming tax forgiveness related to terrorist or military action?’]
Establishing Evaluators
This code initializes an OpenAI language model (gpt-3.5-turbo) with temperature=0 settings and instantiate evaluators for measuring faithfulness and relevancy, utilizing the ServiceContext module with default configurations.
We will be evaluating each chunk size based on 3 metrics.
Average Response Time
Average Faithfulness
Average Relevancy
The function evaluator takes two parameters, chunkSize and questionBank.
It first initializes an OpenAI language model (llm) with the model set to gpt-3.5-turbo.
Then, it creates a serviceContext using the ServiceContext.from_defaults method, specifying the language model (llm) and the chunk size (chunkSize).
The function uses the VectorStoreIndex.from_documents method to create a vector index from a set of documents, with the service context specified.
It builds a query engine (queryEngine) from the vector index.
The total number of questions in the question bank is determined and stored in the variable totalQuestions.
Next, the function initializes variables for tracking various metrics:
totalResponseTime: Tracks the cumulative response time for all questions.
totalFaithfulness: Tracks the cumulative faithfulness score for all questions.
totalRelevancy: Tracks the cumulative relevancy score for all questions.
It records the start time before querying the queryEngine for a response to the current question.
It calculates the elapsed time for the query by subtracting the start time from the current time.
The function evaluates the faithfulness of the response using faithfulnessLLM.evaluate_response and stores the result in the faithfulnessResult variable.
Similarly, it evaluates the relevancy of the response using relevancyLLM.evaluate_response and stores the result in the relevancyResult variable.
The function accumulates the elapsed time, faithfulness result, and relevancy result in their respective total variables.
After evaluating all the questions, the function computes the averages
To find out the best chunk size for our data, we have defined a list of chunk sizes then we will traverse through the list of chunk sizes and find out the average response time, average faithfulness, and average relevance with the help of evaluator method. After this, we will convert our data list into a data frame with the help of Pandas DataFrame class to view it in a fine manner.
From the illustration, it is evident that the chunk size of 128 exhibits the highest average faithfulness and relevancy while maintaining the second-lowest average response time.
Conclusion
Identifying the best chunk size for a RAG system depends on a combination of intuition and empirical data. By utilizing LlamaIndex’s Response Evaluation module, we can experiment with different sizes and make well-informed decisions. When constructing a RAG system, it is crucial to remember that the chunk size plays a pivotal role. Therefore, it is essential to invest the necessary time to thoroughly evaluate and fine-tune the chunk size for optimal outcomes.
Before we understand LlamaIndex, let’s step back a bit. Imagine a futuristic landscape where machines possess an extraordinary ability to understand and produce human-like text effortlessly. LLMs have made this vision a reality. Armed with a vast ocean of training data, these marvels of innovation have become the crown jewels of the tech world.
There is no denying that LLMs (Large Language Models) are currently the talk of the town! From revolutionizing text generation and reasoning, LLMs are trained on massive datasets and have been making waves in the tech vicinity.
One particular LLM has emerged as a true superstar. Back in November 2022, ChatGPT, an LLM developed by OpenAI, attracted a staggering one million users within 5 days of its beta launch.
Source:Chart: ChatGPT Sprints to One Million Users | Statista
When researchers and developers saw these stats they started thinking on how we can best feed/augment these LLMs with our own private data. They started thinking about different solutions.
Finetune your own LLM. You adapt an existing LLM by training your data. But, this is very costly and time-consuming.
Combining all the documents into a single large prompt for an LLM might be possible now with the increased token limit of 100k for models. However, this approach could result in slower processing times and higher computational costs.
Instead of inputting all the data, selectively provide relevant information to the LLM prompt. Choose the useful bits for each query instead of including everything.
Option 3 appears to be both relevant and feasible, but it requires the development of a specialized toolkit. Recognizing this need, efforts have already begun to create the necessary tools.
Introducing LlamaIndex
Recently a toolkit was launched for building applications using LLM, known as Langchain. LlamaIndex is built on top of Langchain to provide a central interface to connect your LLMs with external data.
Data Connectors: The data connector, known as the Reader, collects data from various sources and formats, converting it into a straightforward document format with textual content and basic metadata.
Data Index: It is a data structure facilitating efficient retrieval of pertinent information in response to user queries. At a broad level, Indices are constructed using Documents and serve as the foundation for Query Engines and Chat Engines, enabling seamless interactions and question-and-answer capabilities based on the underlying data. Internally, Indices store data within Node objects, which represent segments of the original documents.
Retrievers: Retrievers play a crucial role in obtaining the most pertinent information based on user queries or chat messages. They can be constructed based on Indices or as standalone components and serve as a fundamental element in Query Engines and Chat Engines for retrieving contextually relevant data.
Query Engines: A query engine is a versatile interface that enables users to pose questions regarding their data. By accepting natural language queries, the query engine provides comprehensive and informative responses.
Chat Engines: A chat engine serves as an advanced interface for engaging in interactive conversations with your data, allowing for multiple exchanges instead of a single question-and-answer format. Similar to ChatGPT but enhanced with access to a knowledge base, the chat engine maintains a contextual understanding by retaining the conversation history and can provide answers that consider the relevant past context.
Query Engine vs. Chat Engine: Key Differences
It is important to note that there is a significant distinction between a query engine and a chat engine. Although they may appear similar at first glance, they serve different purposes:
A query engine operates as an independent system that handles individual questions over the data without maintaining a record of the conversation history.
On the other hand, a chat engine is designed to keep track of the entire conversation history, allowing users to query both the data and previous responses. This functionality resembles ChatGPT, where the chat engine leverages the context of past exchanges to provide more comprehensive and contextually relevant answers
Customization: LlamaIndex offers customization options where you can modify the default settings, such as the utilization of OpenAI’s text-davinci-003 model. Users have the flexibility to customize the underlying language model (LLM) and other settings used in LlamaIndex, with support for various integrations and LangChain’s LLM modules.
Analysis: LlamaIndex offers a diverse range of analysis tools for examining indices and queries. These tools include features for analyzing token usage and associated costs. Additionally, LlamaIndex provides a Playground module, which presents a visual interface for analyzing token usage across different index structures and evaluating performance metrics.
Structured Outputs: LlamaIndex offers an assortment of modules that empower language models (LLMs) to generate structured outputs. These modules are available at various levels of abstraction, providing flexibility and versatility in producing organized and formatted results.
Evaluation: LlamaIndex provides essential modules for assessing the quality of both document retrieval and response synthesis. These modules enable the evaluation of “hallucination,” which refers to situations where the generated response does not align with the retrieved sources. A hallucination occurs when the model generates an answer without effectively grounding it in the given contextual information from the prompt.
Integrations: LlamaIndex offers a wide array of integrations with various toolsets and storage providers. These integrations encompass features such as utilizing vector stores, integrating with ChatGPT plugins, compatibility with Langchain, and the capability to trace with Graphsignal. These integrations enhance the functionality and versatility of LlamaIndex by allowing seamless interaction with different tools and platforms.
Callbacks: LlamaIndex offers a callback feature that assists in debugging, tracking, and tracing the internal operations of the library. The callback manager allows for the addition of multiple callbacks as required. These callbacks not only log event-related data but also track the duration and frequency of each event occurrence. Moreover, a trace map of events is recorded, providing valuable information that callbacks can utilize in a manner that best suits their specific needs.
Storage: LlamaIndex offers a user-friendly interface that simplifies the process of ingesting, indexing, and querying external data. By abstracting away complexities, LlamaIndex allows users to query their data with just a few lines of code. Behind the scenes, LlamaIndex provides the flexibility to customize storage components for different purposes. This includes document stores for storing ingested documents (represented as Node objects), index stores for storing index metadata, and vector stores for storing embedding vectors.The document and index stores utilize a shared key-value store abstraction, providing a common framework for efficient storage and retrieval of data
Now that we have explored the key components of LlamaIndex, let’s delve into its operational mechanisms and understand how it functions.
How Llama-Index Works
To begin, the first step is to import the documents into LlamaIndex, which provides various pre-existing readers for sources like databases, Discord, Slack, Google Sheets, Notion, and the one we will utilize today, the Simple Directory Reader, among others.[Text Wrapping Break][Text Wrapping Break]You can check for more here: Llama Hub (llama-hub-ui.vercel.app)
Once the documents are loaded, LlamaIndex proceeds to parse them into nodes, which are essentially segments of text. Subsequently, an index is constructed to enable quick retrieval of relevant data when querying the documents. The index can be stored in different formats, but we will opt for a Vector Store as it is typically the most useful when querying text documents without specific limitations.
LlamaIndex is built upon LangChain, which serves as the foundational framework for a wide range of LLM applications. While LangChain provides the fundamental building blocks, LlamaIndex is specifically designed to streamline the workflow described above.
Here is an example code showcasing the utilization of the SimpleDirectoryReader data loader in LlamaIndex, along with the integration of the OpenAI language model for natural language processing.
Installing the necessary libraries required to run the code.
Importing openai library and setting the secret API (Application Programming Interface) key.
Importing the SimpleDirectoryReader class from llama_index library and loading the data from it.
Importing SimpleNodeParser class from llama_index and parsing the documents into nodes – basically in chunks of text.
Importing VectorStoreIndex class from llama_index to create index from the chunks of text so that each time when a query is placed only relevant data is sent to OpenAI. In short, for the sake of cost effectiveness.
Conclusion
LlamaIndex, built on top of Langchain, offers a powerful toolkit for integrating external data with LLMs. By parsing documents into nodes, constructing an efficient index, and selectively querying relevant information, LlamaIndex enables cost-effective exploration of text data.
The provided code example demonstrates the utilization of LlamaIndex’s data loader and query engine, showcasing its potential for next-generation text exploration. For the notebook of the above code, refer to the source code available here.